 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bridging the Usability Gap: Theoretical and Methodological Advances for Spectral Learning of Hidden Markov Models
Feb 15, 2023
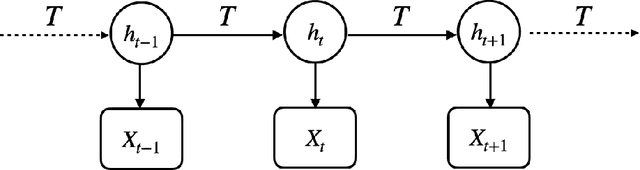
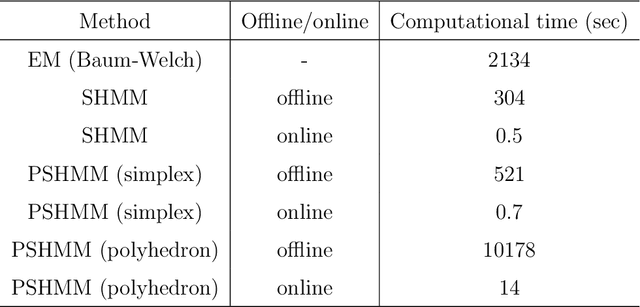
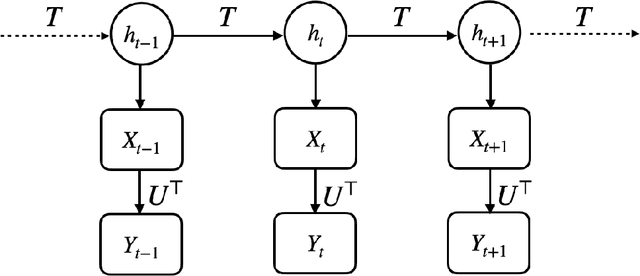
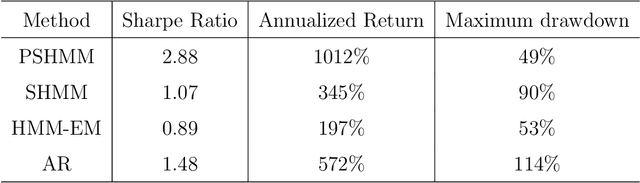
The Baum-Welch (B-W) algorithm is the most widely accepted method for inferring hidden Markov models (HMM). However, it is prone to getting stuck in local optima, and can be too slow for many real-time applications. Spectral learning of HMMs (SHMMs), based on the method of moments (MOM) has been proposed in the literature to overcome these obstacles. Despite its promises, asymptotic theory for SHMM has been elusive, and the long-run performance of SHMM can degrade due to unchecked propogation of error. In this paper, we (1) provide an asymptotic distribution for the approximate error of the likelihood estimated by SHMM, and (2) propose a novel algorithm called projected SHMM (PSHMM) that mitigates the problem of error propogation, and (3) develop online learning variantions of both SHMM and PSHMM that accommodate potential nonstationarity. We compare the performance of SHMM with PSHMM and estimation through the B-W algorithm on both simulated data and data from real world applications, and find that PSHMM not only retains the computational advantages of SHMM, but also provides more robust estimation and forecasting.
Enhancing Biogenic Emission Maps Using Deep Learning
Feb 15, 2023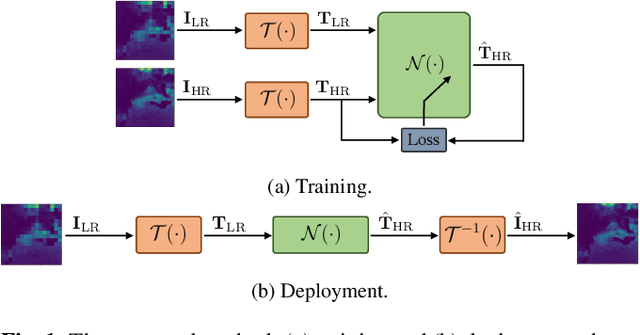
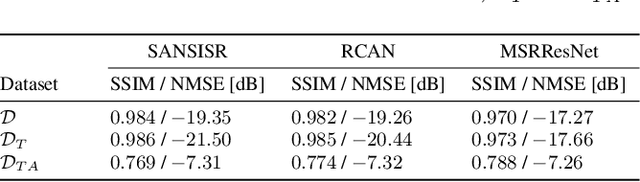
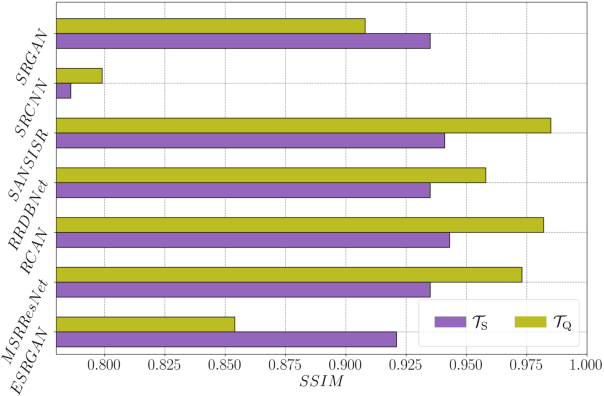
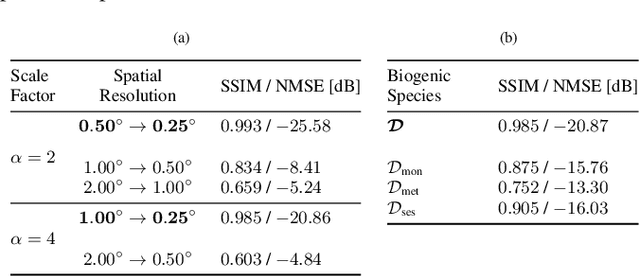
Biogenic Volatile Organic Compounds (BVOCs) play a critical role in biosphere-atmosphere interactions, being a key factor in the physical and chemical properties of the atmosphere and climate. Acquiring large and fine-grained BVOC emission maps is expensive and time-consuming, so most of the available BVOC data are obtained on a loose and sparse sampling grid or on small regions. However, high-resolution BVOC data are desirable in many applications, such as air quality, atmospheric chemistry, and climate monitoring. In this work, we propose to investigate the possibility of enhancing BVOC acquisitions, taking a step forward in explaining the relationships between plants and these compounds. We do so by comparing the performances of several state-of-the-art neural networks proposed for Single-Image Super-Resolution (SISR), showing how to adapt them to correctly handle emission data through preprocessing. Moreover, we also consider realistic scenarios, considering both temporal and geographical constraints. Finally, we present possible future developments in terms of Super-Resolution (SR) generalization, considering the scale-invariance property and super-resolving emissions from unseen compounds.
A Deep Learning Technique to Control the Non-linear Dynamics of a Gravitational-wave Interferometer
Feb 15, 2023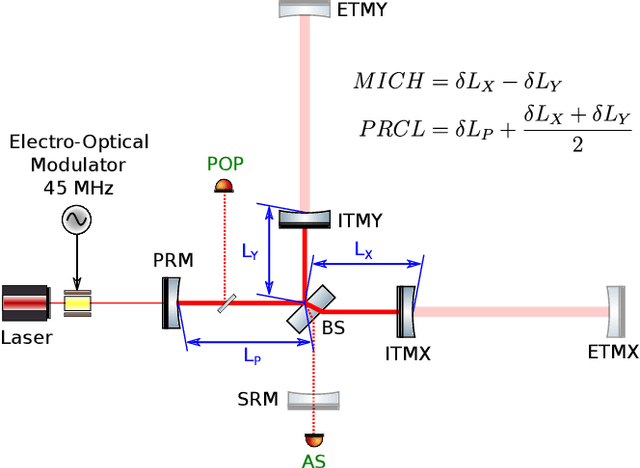
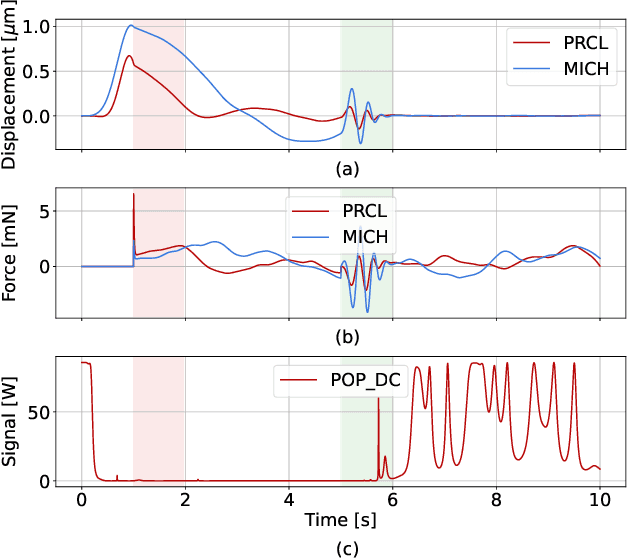
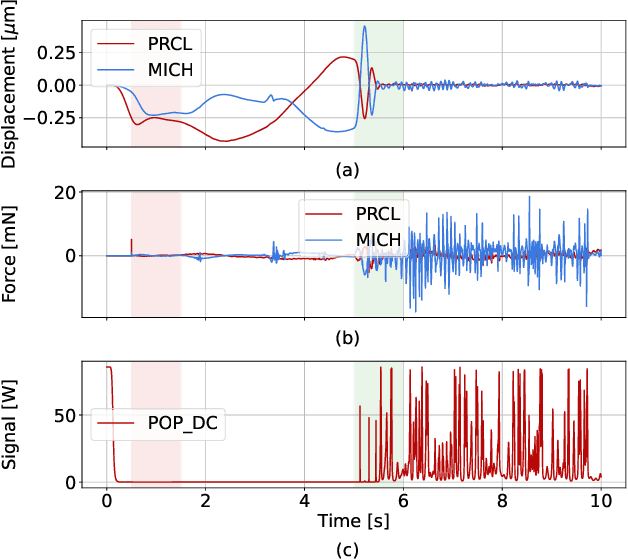
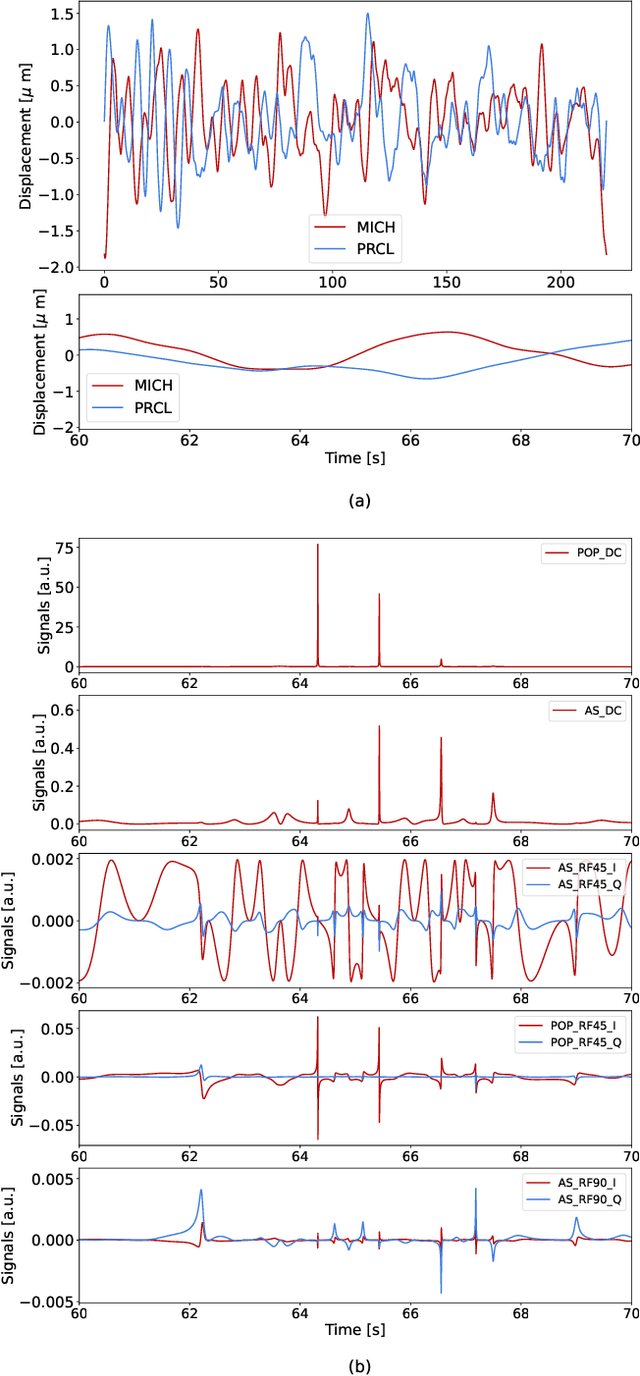
In this work we developed a deep learning technique that successfully solves a non-linear dynamic control problem. Instead of directly tackling the control problem, we combined methods in probabilistic neural networks and a Kalman-Filter-inspired model to build a non-linear state estimator for the system. We then used the estimated states to implement a trivial controller for the now fully observable system. We applied this technique to a crucial non-linear control problem that arises in the operation of the LIGO system, an interferometric gravitational-wave observatory. We demonstrated in simulation that our approach can learn from data to estimate the state of the system, allowing a successful control of the interferometer's mirror . We also developed a computationally efficient model that can run in real time at high sampling rate on a single modern CPU core, one of the key requirements for the implementation of our solution in the LIGO digital control system. We believe these techniques could be used to help tackle similar non-linear control problems in other applications.
OpenHLS: High-Level Synthesis for Low-Latency Deep Neural Networks for Experimental Science
Feb 15, 2023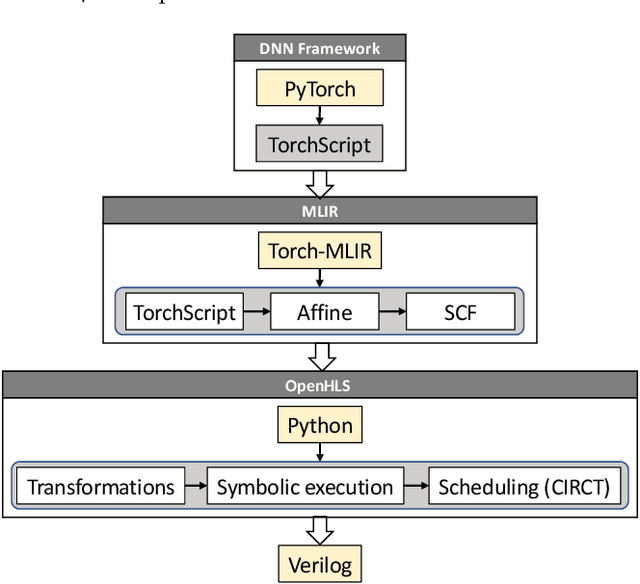

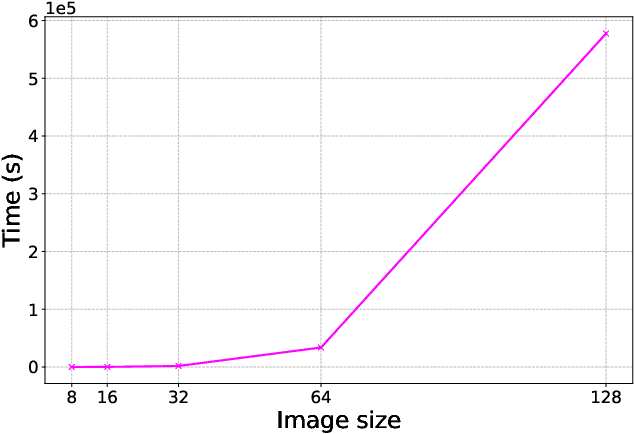

In many experiment-driven scientific domains, such as high-energy physics, material science, and cosmology, high data rate experiments impose hard constraints on data acquisition systems: collected data must either be indiscriminately stored for post-processing and analysis, thereby necessitating large storage capacity, or accurately filtered in real-time, thereby necessitating low-latency processing. Deep neural networks, effective in other filtering tasks, have not been widely employed in such data acquisition systems, due to design and deployment difficulties. We present an open source, lightweight, compiler framework, without any proprietary dependencies, OpenHLS, based on high-level synthesis techniques, for translating high-level representations of deep neural networks to low-level representations, suitable for deployment to near-sensor devices such as field-programmable gate arrays. We evaluate OpenHLS on various workloads and present a case-study implementation of a deep neural network for Bragg peak detection in the context of high-energy diffraction microscopy. We show OpenHLS is able to produce an implementation of the network with a throughput 4.8 $\mu$s/sample, which is approximately a 4$\times$ improvement over the existing implementation
Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction
Feb 15, 2023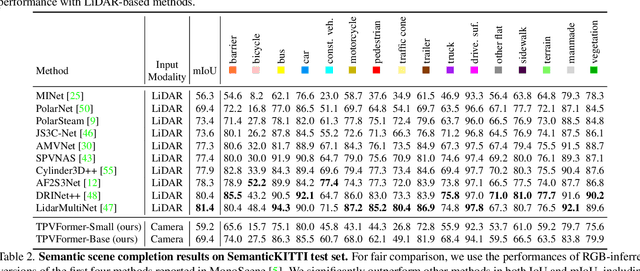
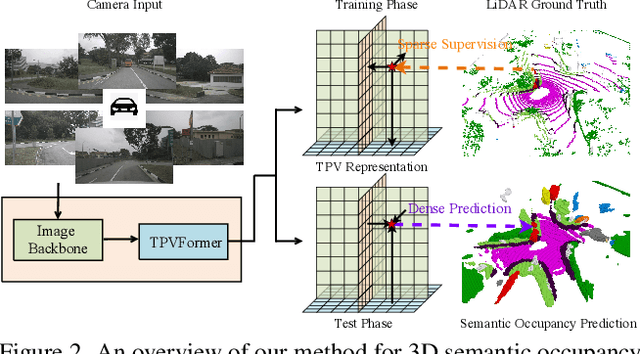
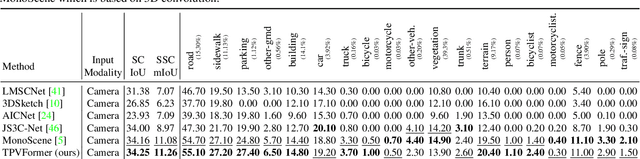
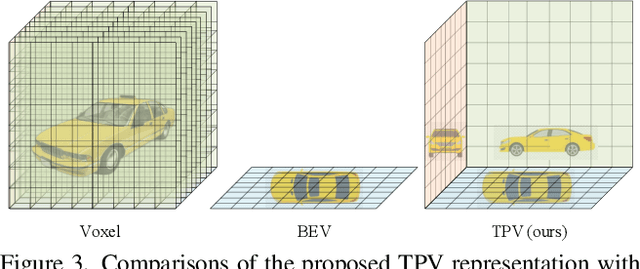
Modern methods for vision-centric autonomous driving perception widely adopt the bird's-eye-view (BEV) representation to describe a 3D scene. Despite its better efficiency than voxel representation, it has difficulty describing the fine-grained 3D structure of a scene with a single plane. To address this, we propose a tri-perspective view (TPV) representation which accompanies BEV with two additional perpendicular planes. We model each point in the 3D space by summing its projected features on the three planes. To lift image features to the 3D TPV space, we further propose a transformer-based TPV encoder (TPVFormer) to obtain the TPV features effectively. We employ the attention mechanism to aggregate the image features corresponding to each query in each TPV plane. Experiments show that our model trained with sparse supervision effectively predicts the semantic occupancy for all voxels. We demonstrate for the first time that using only camera inputs can achieve comparable performance with LiDAR-based methods on the LiDAR segmentation task on nuScenes. Code: https://github.com/wzzheng/TPVFormer.
Transformer-Patcher: One Mistake worth One Neuron
Jan 24, 2023
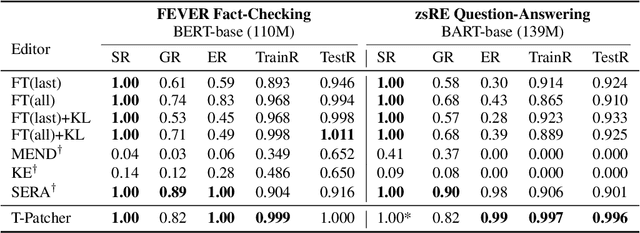
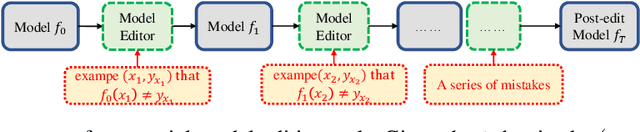
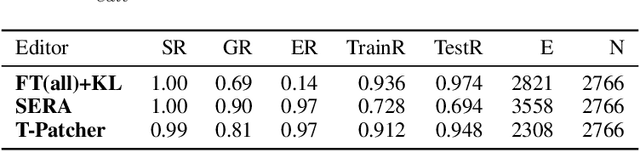
Large Transformer-based Pretrained Language Models (PLMs) dominate almost all Natural Language Processing (NLP) tasks. Nevertheless, they still make mistakes from time to time. For a model deployed in an industrial environment, fixing these mistakes quickly and robustly is vital to improve user experiences. Previous works formalize such problems as Model Editing (ME) and mostly focus on fixing one mistake. However, the one-mistake-fixing scenario is not an accurate abstraction of the real-world challenge. In the deployment of AI services, there are ever-emerging mistakes, and the same mistake may recur if not corrected in time. Thus a preferable solution is to rectify the mistakes as soon as they appear nonstop. Therefore, we extend the existing ME into Sequential Model Editing (SME) to help develop more practical editing methods. Our study shows that most current ME methods could yield unsatisfying results in this scenario. We then introduce Transformer-Patcher, a novel model editor that can shift the behavior of transformer-based models by simply adding and training a few neurons in the last Feed-Forward Network layer. Experimental results on both classification and generation tasks show that Transformer-Patcher can successively correct up to thousands of errors (Reliability) and generalize to their equivalent inputs (Generality) while retaining the model's accuracy on irrelevant inputs (Locality). Our method outperforms previous fine-tuning and HyperNetwork-based methods and achieves state-of-the-art performance for Sequential Model Editing (SME). The code is available at https://github.com/ZeroYuHuang/Transformer-Patcher.
Prompt Stealing Attacks Against Text-to-Image Generation Models
Feb 20, 2023


Text-to-Image generation models have revolutionized the artwork design process and enabled anyone to create high-quality images by entering text descriptions called prompts. Creating a high-quality prompt that consists of a subject and several modifiers can be time-consuming and costly. In consequence, a trend of trading high-quality prompts on specialized marketplaces has emerged. In this paper, we propose a novel attack, namely prompt stealing attack, which aims to steal prompts from generated images by text-to-image generation models. Successful prompt stealing attacks direct violate the intellectual property and privacy of prompt engineers and also jeopardize the business model of prompt trading marketplaces. We first perform a large-scale analysis on a dataset collected by ourselves and show that a successful prompt stealing attack should consider a prompt's subject as well as its modifiers. We then propose the first learning-based prompt stealing attack, PromptStealer, and demonstrate its superiority over two baseline methods quantitatively and qualitatively. We also make some initial attempts to defend PromptStealer. In general, our study uncovers a new attack surface in the ecosystem created by the popular text-to-image generation models. We hope our results can help to mitigate the threat. To facilitate research in this field, we will share our dataset and code with the community.
Learning Deep Semantics for Test Completion
Feb 20, 2023
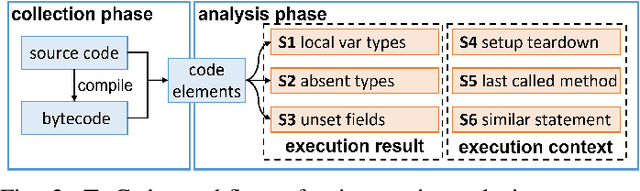
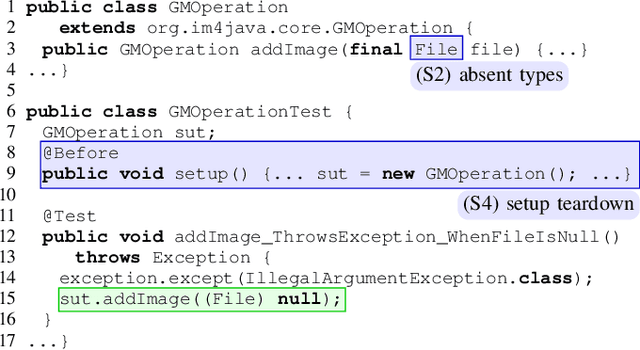
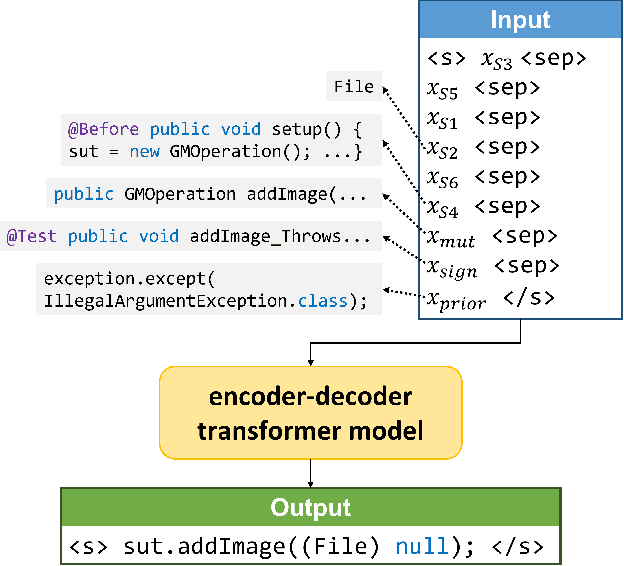
Writing tests is a time-consuming yet essential task during software development. We propose to leverage recent advances in deep learning for text and code generation to assist developers in writing tests. We formalize the novel task of test completion to automatically complete the next statement in a test method based on the context of prior statements and the code under test. We develop TeCo -- a deep learning model using code semantics for test completion. The key insight underlying TeCo is that predicting the next statement in a test method requires reasoning about code execution, which is hard to do with only syntax-level data that existing code completion models use. TeCo extracts and uses six kinds of code semantics data, including the execution result of prior statements and the execution context of the test method. To provide a testbed for this new task, as well as to evaluate TeCo, we collect a corpus of 130,934 test methods from 1,270 open-source Java projects. Our results show that TeCo achieves an exact-match accuracy of 18, which is 29% higher than the best baseline using syntax-level data only. When measuring functional correctness of generated next statement, TeCo can generate runnable code in 29% of the cases compared to 18% obtained by the best baseline. Moreover, TeCo is significantly better than prior work on test oracle generation.
Deep Reinforcement Learning for Cost-Effective Medical Diagnosis
Feb 20, 2023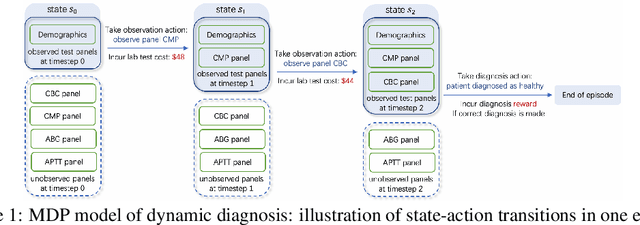

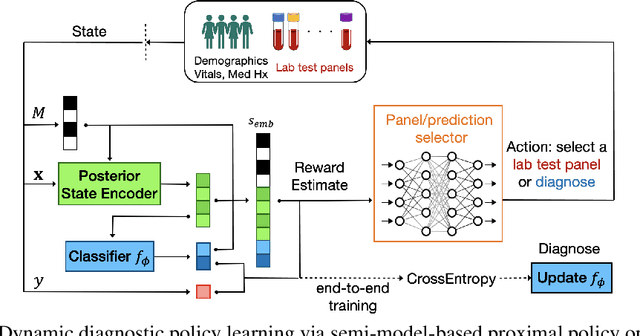
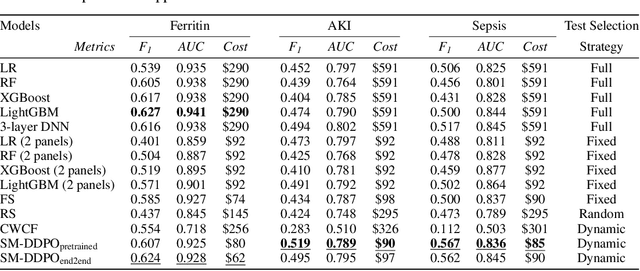
Dynamic diagnosis is desirable when medical tests are costly or time-consuming. In this work, we use reinforcement learning (RL) to find a dynamic policy that selects lab test panels sequentially based on previous observations, ensuring accurate testing at a low cost. Clinical diagnostic data are often highly imbalanced; therefore, we aim to maximize the $F_1$ score instead of the error rate. However, optimizing the non-concave $F_1$ score is not a classic RL problem, thus invalidates standard RL methods. To remedy this issue, we develop a reward shaping approach, leveraging properties of the $F_1$ score and duality of policy optimization, to provably find the set of all Pareto-optimal policies for budget-constrained $F_1$ score maximization. To handle the combinatorially complex state space, we propose a Semi-Model-based Deep Diagnosis Policy Optimization (SM-DDPO) framework that is compatible with end-to-end training and online learning. SM-DDPO is tested on diverse clinical tasks: ferritin abnormality detection, sepsis mortality prediction, and acute kidney injury diagnosis. Experiments with real-world data validate that SM-DDPO trains efficiently and identifies all Pareto-front solutions. Across all tasks, SM-DDPO is able to achieve state-of-the-art diagnosis accuracy (in some cases higher than conventional methods) with up to $85\%$ reduction in testing cost. The code is available at [https://github.com/Zheng321/Blood_Panel].
Multiagent Inverse Reinforcement Learning via Theory of Mind Reasoning
Feb 20, 2023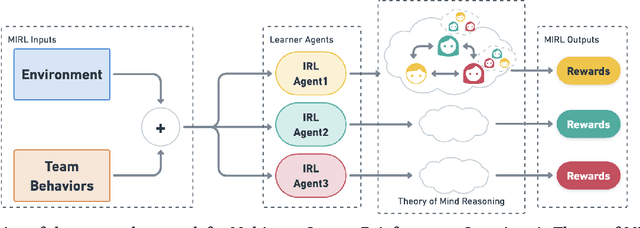
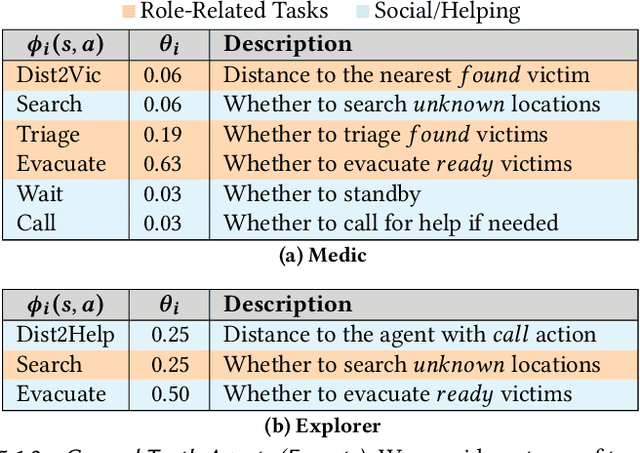


To understand how people interact with each other in collaborative settings, especially in situations where individuals know little about their teammates, Multiagent Inverse Reinforcement Learning (MIRL) aims to infer the reward functions guiding the behavior of each individual given trajectories of a team's behavior during task performance. Unlike current MIRL approaches, team members \emph{are not} assumed to know each other's goals a priori, rather they collaborate by adapting to the goals of others perceived by observing their behavior, all while jointly performing a task. To address this problem, we propose a novel approach to MIRL via Theory of Mind (MIRL-ToM). For each agent, we first use ToM reasoning to estimate a posterior distribution over baseline reward profiles given their demonstrated behavior. We then perform MIRL via decentralized equilibrium by employing single-agent Maximum Entropy IRL to infer a reward function for each agent, where we simulate the behavior of other teammates according to the time-varying distribution over profiles. We evaluate our approach in a simulated 2-player search-and-rescue operation where the goal of the agents, playing different roles, is to search for and evacuate victims in the environment. Results show that the choice of baseline profiles is paramount to the recovery of ground-truth rewards, and MIRL-ToM is able to recover the rewards used by agents interacting with either known and unknown teammates.