 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Binary Embedding-based Retrieval at Tencent
Feb 17, 2023
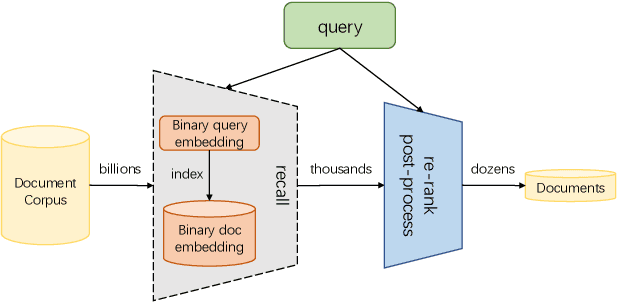

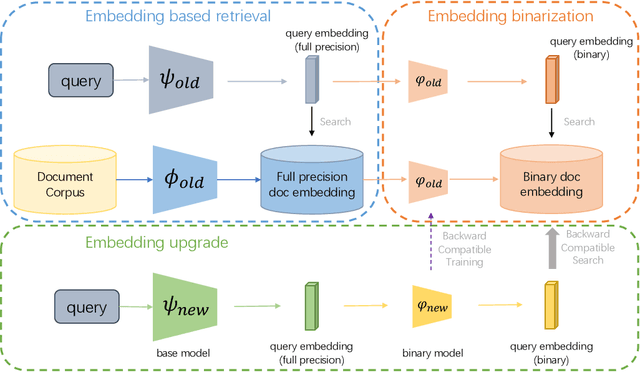

Large-scale embedding-based retrieval (EBR) is the cornerstone of search-related industrial applications. Given a user query, the system of EBR aims to identify relevant information from a large corpus of documents that may be tens or hundreds of billions in size. The storage and computation turn out to be expensive and inefficient with massive documents and high concurrent queries, making it difficult to further scale up. To tackle the challenge, we propose a binary embedding-based retrieval (BEBR) engine equipped with a recurrent binarization algorithm that enables customized bits per dimension. Specifically, we compress the full-precision query and document embeddings, formulated as float vectors in general, into a composition of multiple binary vectors using a lightweight transformation model with residual multilayer perception (MLP) blocks. We can therefore tailor the number of bits for different applications to trade off accuracy loss and cost savings. Importantly, we enable task-agnostic efficient training of the binarization model using a new embedding-to-embedding strategy. We also exploit the compatible training of binary embeddings so that the BEBR engine can support indexing among multiple embedding versions within a unified system. To further realize efficient search, we propose Symmetric Distance Calculation (SDC) to achieve lower response time than Hamming codes. We successfully employed the introduced BEBR to Tencent products, including Sogou, Tencent Video, QQ World, etc. The binarization algorithm can be seamlessly generalized to various tasks with multiple modalities. Extensive experiments on offline benchmarks and online A/B tests demonstrate the efficiency and effectiveness of our method, significantly saving 30%~50% index costs with almost no loss of accuracy at the system level.
Combining Generative Artificial Intelligence (AI) and the Internet: Heading towards Evolution or Degradation?
Feb 17, 2023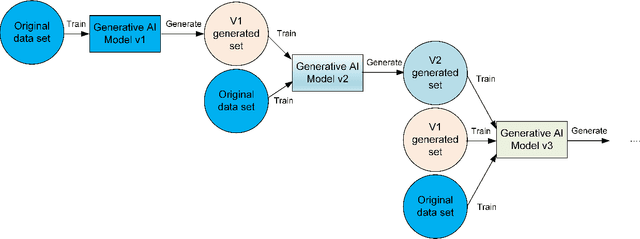



In the span of a few months, generative Artificial Intelligence (AI) tools that can generate realistic images or text have taken the Internet by storm, making them one of the technologies with fastest adoption ever. Some of these generative AI tools such as DALL-E, MidJourney, or ChatGPT have gained wide public notoriety. Interestingly, these tools are possible because of the massive amount of data (text and images) available on the Internet. The tools are trained on massive data sets that are scraped from Internet sites. And now, these generative AI tools are creating massive amounts of new data that are being fed into the Internet. Therefore, future versions of generative AI tools will be trained with Internet data that is a mix of original and AI-generated data. As time goes on, a mixture of original data and data generated by different versions of AI tools will populate the Internet. This raises a few intriguing questions: how will future versions of generative AI tools behave when trained on a mixture of real and AI generated data? Will they evolve with the new data sets or degenerate? Will evolution introduce biases in subsequent generations of generative AI tools? In this document, we explore these questions and report some very initial simulation results using a simple image-generation AI tool. These results suggest that the quality of the generated images degrades as more AI-generated data is used for training thus suggesting that generative AI may degenerate. Although these results are preliminary and cannot be generalised without further study, they serve to illustrate the potential issues of the interaction between generative AI and the Internet.
OTFS -- A Mathematical Foundation for Communication and Radar Sensing in the Delay-Doppler Domain
Feb 17, 2023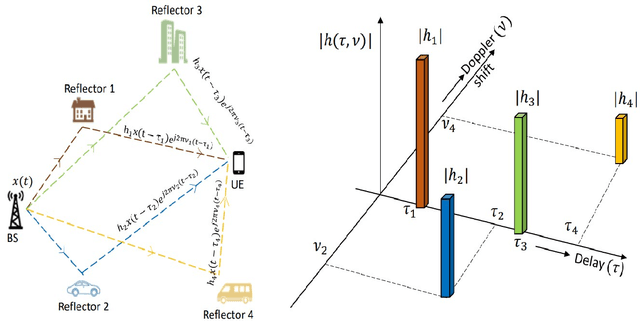
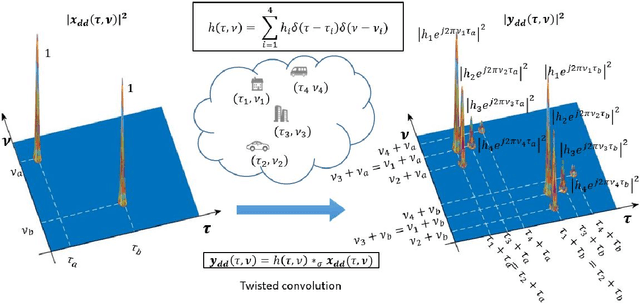
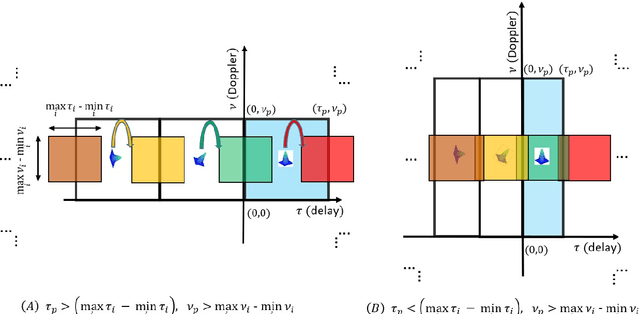
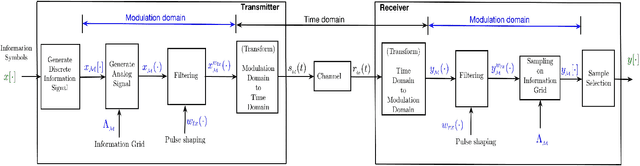
Orthogonal time frequency space (OTFS) is a framework for communication and active sensing that processes signals in the delay-Doppler (DD) domain. This paper explores three key features of the OTFS framework, and explains their value to applications. The first feature is a compact and sparse DD domain parameterization of the wireless channel, where the parameters map directly to physical attributes of the reflectors that comprise the scattering environment, and as a consequence these parameters evolve predictably. The second feature is a novel waveform / modulation technique, matched to the DD channel model, that embeds information symbols in the DD domain. The relation between channel inputs and outputs is localized, non-fading and predictable, even in the presence of significant delay and Doppler spread, and as a consequence the channel can be efficiently acquired and equalized. By avoiding fading, the post equalization SNR remains constant across all information symbols in a packet, so that bit error performance is superior to contemporary multi-carrier waveforms. Further, the OTFS carrier waveform is a localized pulse in the DD domain, making it possible to separate reflectors along both delay and Doppler simultaneously, and to achieve a high-resolution delay-Doppler radar image of the environment. In other words, the DD parameterization provides a common mathematical framework for communication and radar. This is the third feature of the OTFS framework, and it is ideally suited to intelligent transportation systems involving self-driving cars and unmanned ground/aerial vehicles which are self/network controlled. The OTFS waveform is able to support stable and superior performance over a wide range of user speeds.
A system for Human-AI collaboration for Online Customer Support
Jan 28, 2023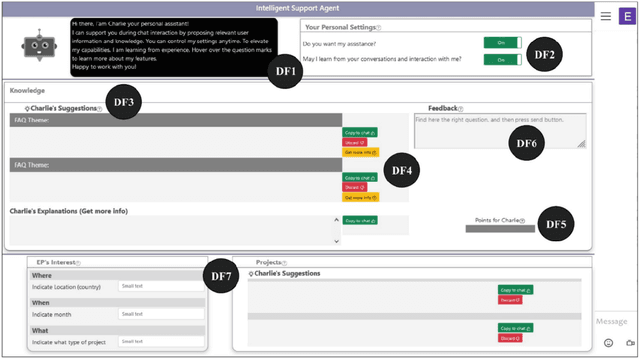
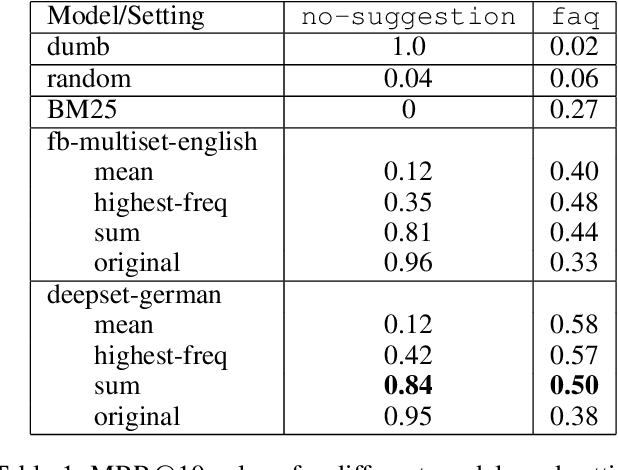
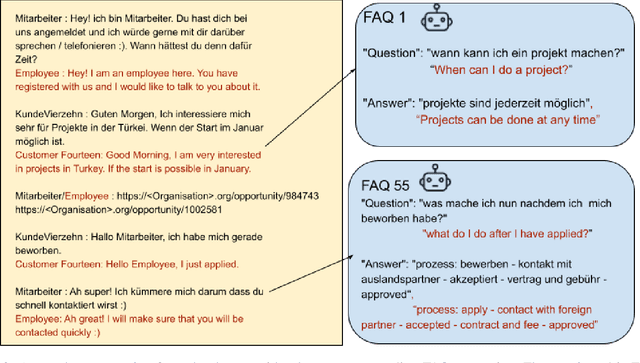
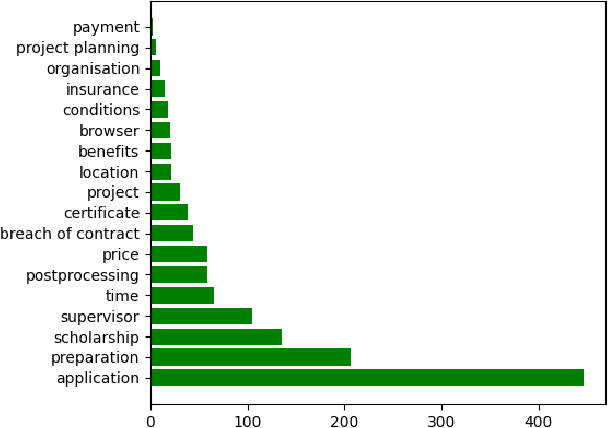
AI enabled chat bots have recently been put to use to answer customer service queries, however it is a common feedback of users that bots lack a personal touch and are often unable to understand the real intent of the user's question. To this end, it is desirable to have human involvement in the customer servicing process. In this work, we present a system where a human support agent collaborates in real-time with an AI agent to satisfactorily answer customer queries. We describe the user interaction elements of the solution, along with the machine learning techniques involved in the AI agent.
Don't overfit the history -- Recursive time series data augmentation
Jul 06, 2022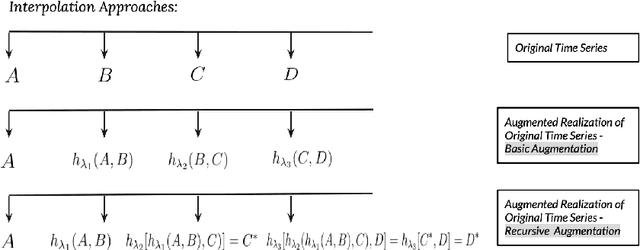

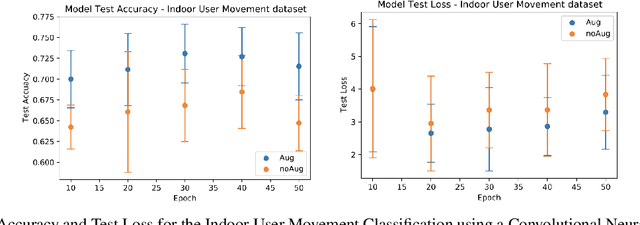
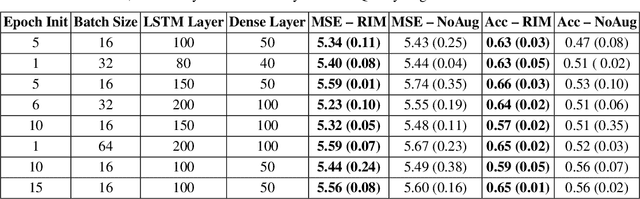
Time series observations can be seen as realizations of an underlying dynamical system governed by rules that we typically do not know. For time series learning tasks, we need to understand that we fit our model on available data, which is a unique realized history. Training on a single realization often induces severe overfitting lacking generalization. To address this issue, we introduce a general recursive framework for time series augmentation, which we call Recursive Interpolation Method, denoted as RIM. New samples are generated using a recursive interpolation function of all previous values in such a way that the enhanced samples preserve the original inherent time series dynamics. We perform theoretical analysis to characterize the proposed RIM and to guarantee its test performance. We apply RIM to diverse real world time series cases to achieve strong performance over non-augmented data on regression, classification, and reinforcement learning tasks.
Deep Temporal Contrastive Clustering
Dec 29, 2022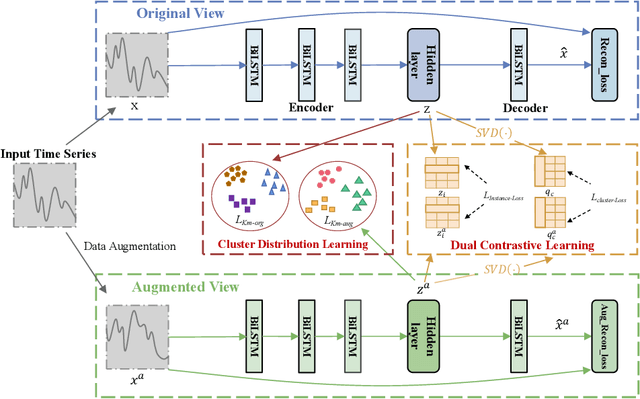
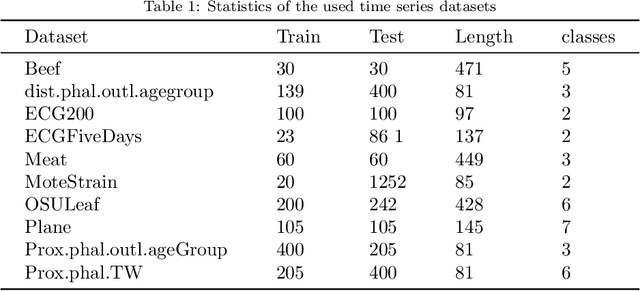
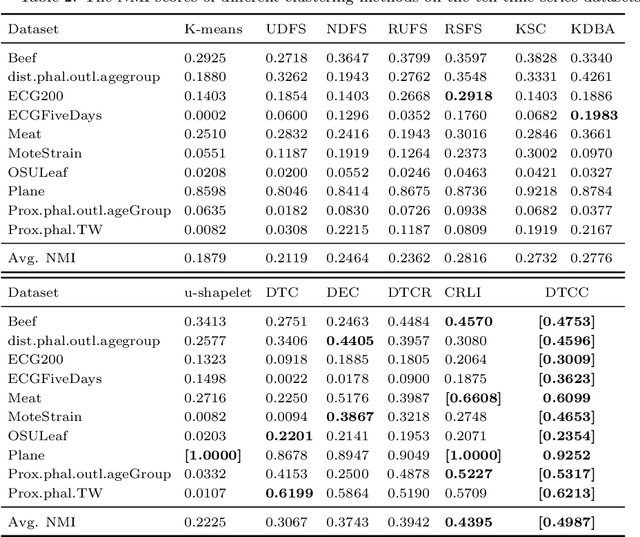
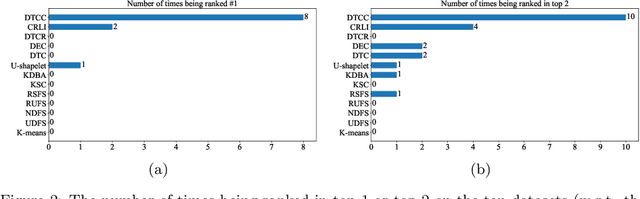
Recently the deep learning has shown its advantage in representation learning and clustering for time series data. Despite the considerable progress, the existing deep time series clustering approaches mostly seek to train the deep neural network by some instance reconstruction based or cluster distribution based objective, which, however, lack the ability to exploit the sample-wise (or augmentation-wise) contrastive information or even the higher-level (e.g., cluster-level) contrastiveness for learning discriminative and clustering-friendly representations. In light of this, this paper presents a deep temporal contrastive clustering (DTCC) approach, which for the first time, to our knowledge, incorporates the contrastive learning paradigm into the deep time series clustering research. Specifically, with two parallel views generated from the original time series and their augmentations, we utilize two identical auto-encoders to learn the corresponding representations, and in the meantime perform the cluster distribution learning by incorporating a k-means objective. Further, two levels of contrastive learning are simultaneously enforced to capture the instance-level and cluster-level contrastive information, respectively. With the reconstruction loss of the auto-encoder, the cluster distribution loss, and the two levels of contrastive losses jointly optimized, the network architecture is trained in a self-supervised manner and the clustering result can thereby be obtained. Experiments on a variety of time series datasets demonstrate the superiority of our DTCC approach over the state-of-the-art.
Reconfigurable Data Glove for Reconstructing Physical and Virtual Grasps
Jan 18, 2023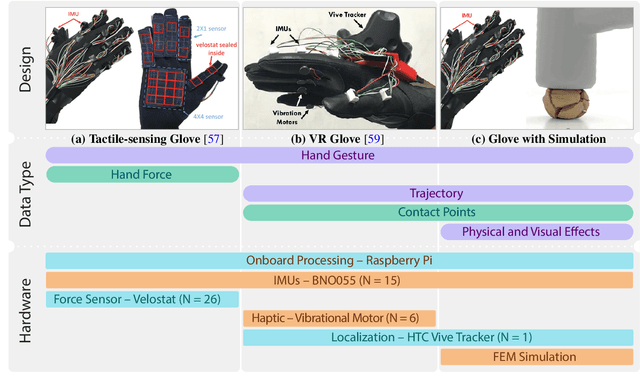


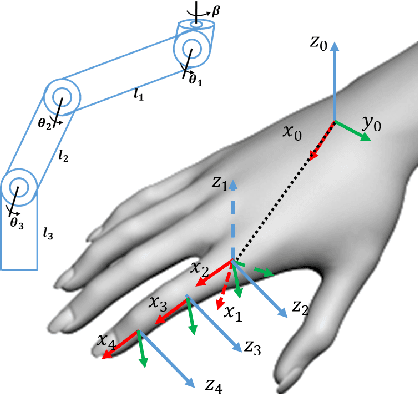
We present a reconfigurable data glove design to capture different modes of human hand-object interactions, critical for training embodied AI agents for fine manipulation tasks. Sharing a unified backbone design that reconstructs hand gestures in real-time, our reconfigurable data glove operates in three modes for various downstream tasks with distinct features. In the tactile-sensing mode, the glove system aggregates manipulation force via customized force sensors made from a soft and thin piezoresistive material; this design is to minimize interference during complex hand movements. The Virtual Reality (VR) mode enables real-time interaction in a physically plausible fashion; a caging-based approach is devised to determine stable grasps by detecting collision events. Leveraging a state-of-the-art Finite Element Method (FEM) simulator, the simulation mode collects a fine-grained 4D manipulation event: hand and object motions in 3D space and how the object's physical properties (e.g., stress, energy) change in accord with the manipulation in time. Of note, this glove system is the first to look into, through high-fidelity simulation, the unobservable physical and causal factors behind manipulation actions. In a series of experiments, we characterize our data glove in terms of individual sensors and the overall system. Specifically, we evaluate the system's three modes by (i) recording hand gestures and associated forces, (ii) improving manipulation fluency in VR, and (iii) producing realistic simulation effects of various tool uses, respectively. Together, our reconfigurable data glove collects and reconstructs fine-grained human grasp data in both the physical and virtual environments, opening up new avenues to learning manipulation skills for embodied AI agents.
Near Lossless Time Series Data Compression Methods using Statistics and Deviation
Sep 28, 2022
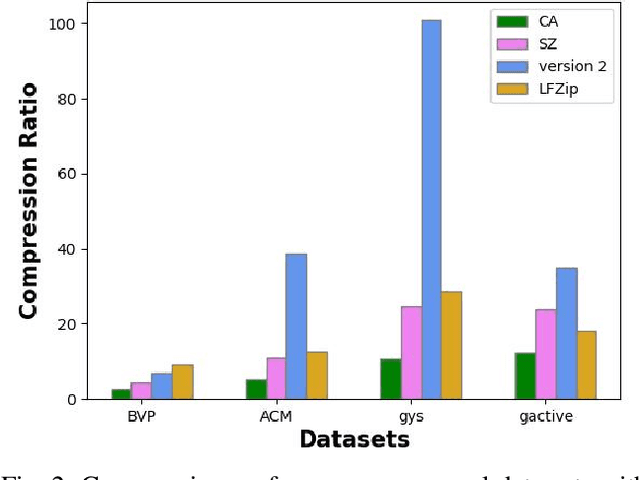

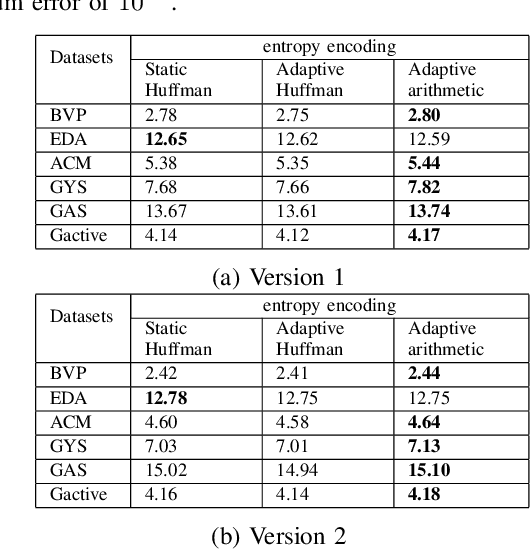
The last two decades have seen tremendous growth in data collections because of the realization of recent technologies, including the internet of things (IoT), E-Health, industrial IoT 4.0, autonomous vehicles, etc. The challenge of data transmission and storage can be handled by utilizing state-of-the-art data compression methods. Recent data compression methods are proposed using deep learning methods, which perform better than conventional methods. However, these methods require a lot of data and resources for training. Furthermore, it is difficult to materialize these deep learning-based solutions on IoT devices due to the resource-constrained nature of IoT devices. In this paper, we propose lightweight data compression methods based on data statistics and deviation. The proposed method performs better than the deep learning method in terms of compression ratio (CR). We simulate and compare the proposed data compression methods for various time series signals, e.g., accelerometer, gas sensor, gyroscope, electrical power consumption, etc. In particular, it is observed that the proposed method achieves 250.8\%, 94.3\%, and 205\% higher CR than the deep learning method for the GYS, Gactive, and ACM datasets, respectively. The code and data are available at https://github.com/vidhi0206/data-compression .
Estimating Latent Population Flows from Aggregated Data via Inversing Multi-Marginal Optimal Transport
Dec 30, 2022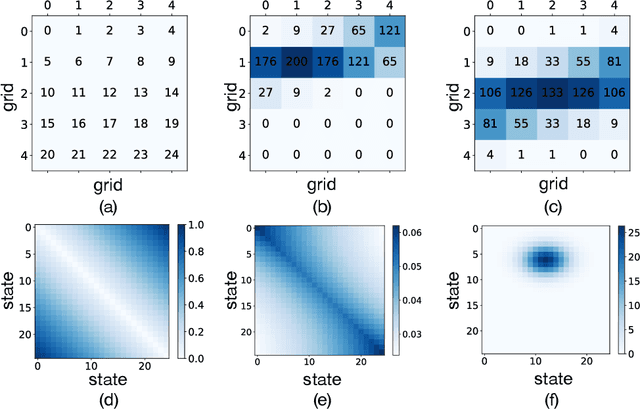
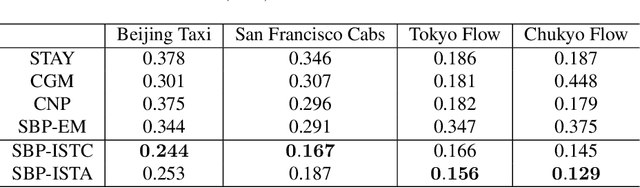
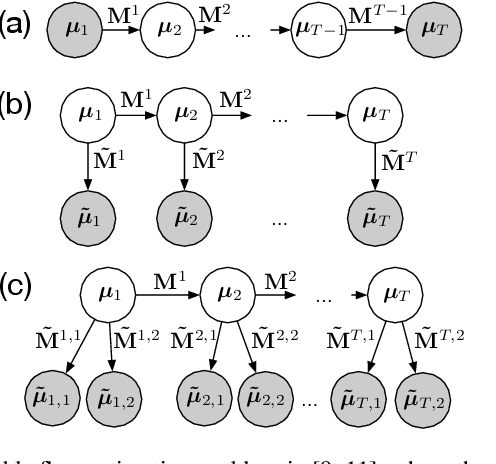
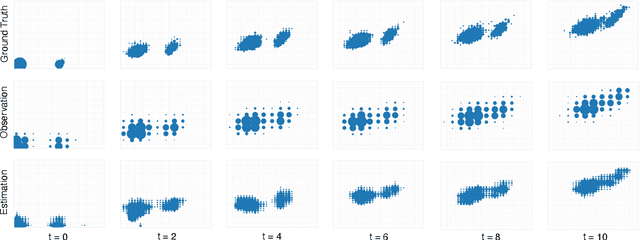
We study the problem of estimating latent population flows from aggregated count data. This problem arises when individual trajectories are not available due to privacy issues or measurement fidelity. Instead, the aggregated observations are measured over discrete-time points, for estimating the population flows among states. Most related studies tackle the problems by learning the transition parameters of a time-homogeneous Markov process. Nonetheless, most real-world population flows can be influenced by various uncertainties such as traffic jam and weather conditions. Thus, in many cases, a time-homogeneous Markov model is a poor approximation of the much more complex population flows. To circumvent this difficulty, we resort to a multi-marginal optimal transport (MOT) formulation that can naturally represent aggregated observations with constrained marginals, and encode time-dependent transition matrices by the cost functions. In particular, we propose to estimate the transition flows from aggregated data by learning the cost functions of the MOT framework, which enables us to capture time-varying dynamic patterns. The experiments demonstrate the improved accuracy of the proposed algorithms than the related methods in estimating several real-world transition flows.
An Efficient Convex Hull-Based Vehicle Pose Estimation Method for 3D LiDAR
Feb 02, 2023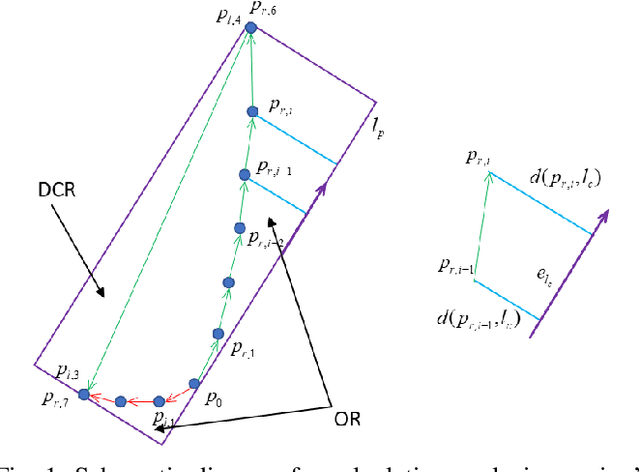
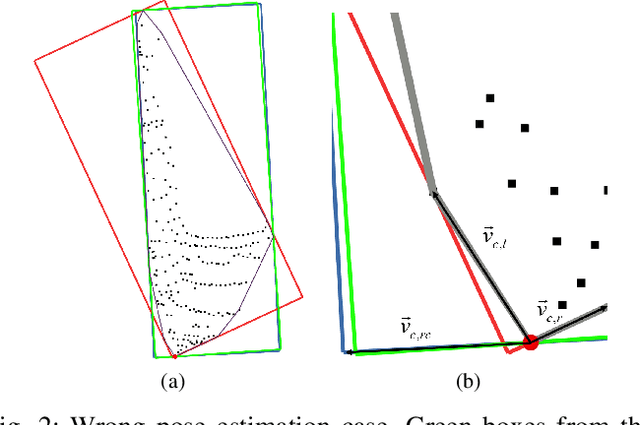
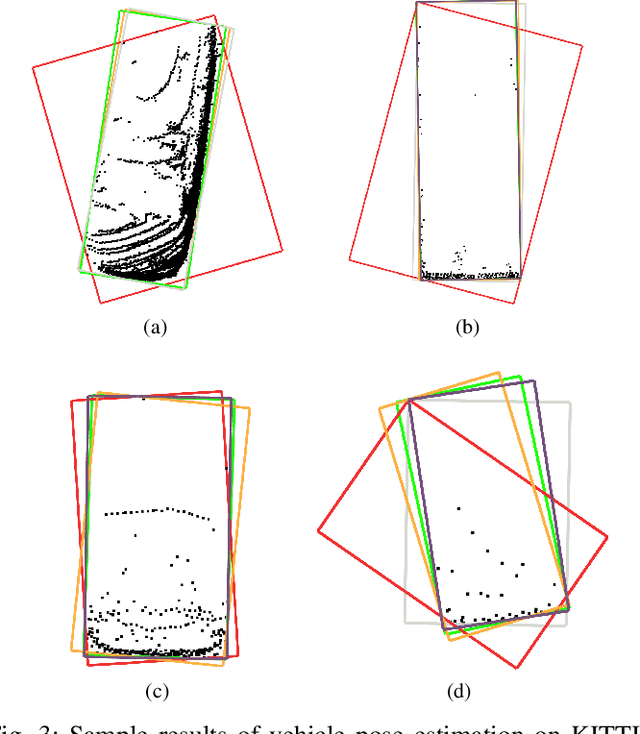
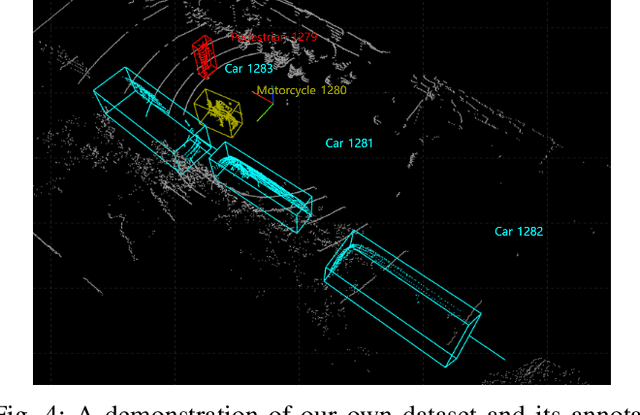
Vehicle pose estimation is essential in the perception technology of autonomous driving. However, due to the different density distributions of the LiDAR point cloud, it is challenging to achieve accurate direction extraction based on 3D LiDAR by using the existing pose estimation methods. In this paper, we proposed a novel convex hull-based vehicle pose estimation method. The extracted 3D cluster is reduced to the convex hull, reducing the computation burden. Then a novel criterion based on the minimum occlusion area is developed for the search-based algorithm, which can achieve accurate pose estimation. The proposed algorithm is validated on the KITTI dataset and a manually labeled dataset acquired at an industrial park. The results show that our proposed method can achieve better accuracy than the three mainstream algorithms while maintaining real-time speed.