 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Async-HFL: Efficient and Robust Asynchronous Federated Learning in Hierarchical IoT Networks
Jan 17, 2023
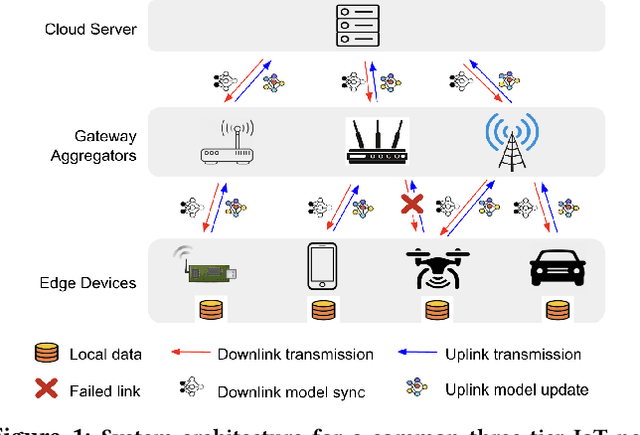
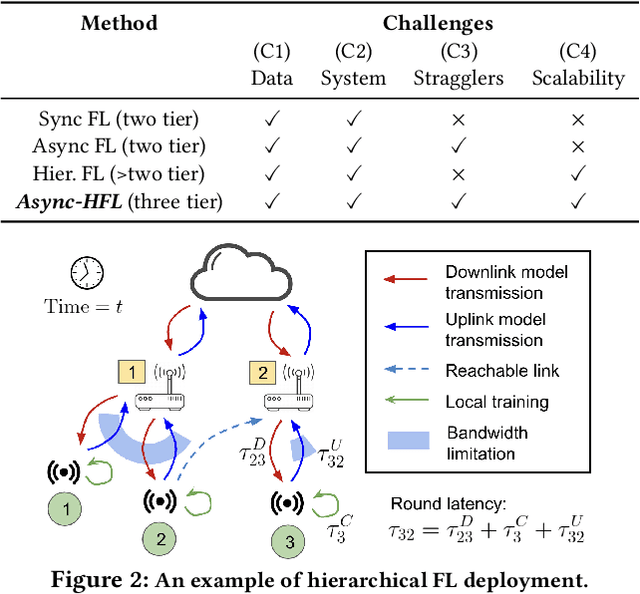
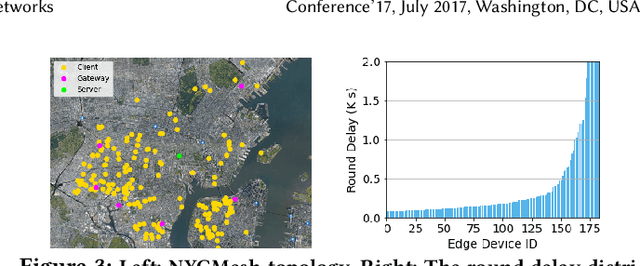

Federated Learning (FL) has gained increasing interest in recent years as a distributed on-device learning paradigm. However, multiple challenges remain to be addressed for deploying FL in real-world Internet-of-Things (IoT) networks with hierarchies. Although existing works have proposed various approaches to account data heterogeneity, system heterogeneity, unexpected stragglers and scalibility, none of them provides a systematic solution to address all of the challenges in a hierarchical and unreliable IoT network. In this paper, we propose an asynchronous and hierarchical framework (Async-HFL) for performing FL in a common three-tier IoT network architecture. In response to the largely varied delays, Async-HFL employs asynchronous aggregations at both the gateway and the cloud levels thus avoids long waiting time. To fully unleash the potential of Async-HFL in converging speed under system heterogeneities and stragglers, we design device selection at the gateway level and device-gateway association at the cloud level. Device selection chooses edge devices to trigger local training in real-time while device-gateway association determines the network topology periodically after several cloud epochs, both satisfying bandwidth limitation. We evaluate Async-HFL's convergence speedup using large-scale simulations based on ns-3 and a network topology from NYCMesh. Our results show that Async-HFL converges 1.08-1.31x faster in wall-clock time and saves up to 21.6% total communication cost compared to state-of-the-art asynchronous FL algorithms (with client selection). We further validate Async-HFL on a physical deployment and observe robust convergence under unexpected stragglers.
Downlink TDMA Scheduling for IRS-aided Communications with Block-Static Constraints
Jan 25, 2023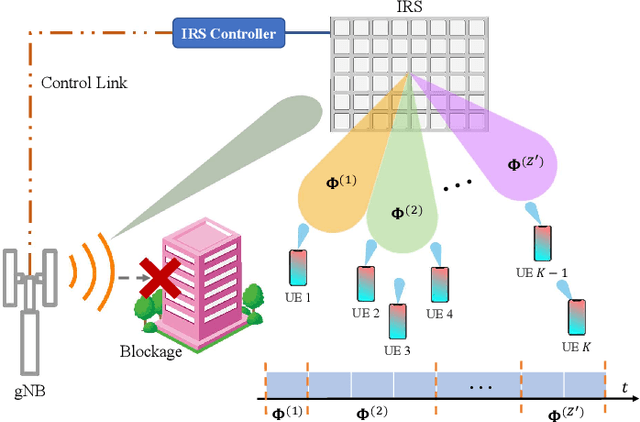
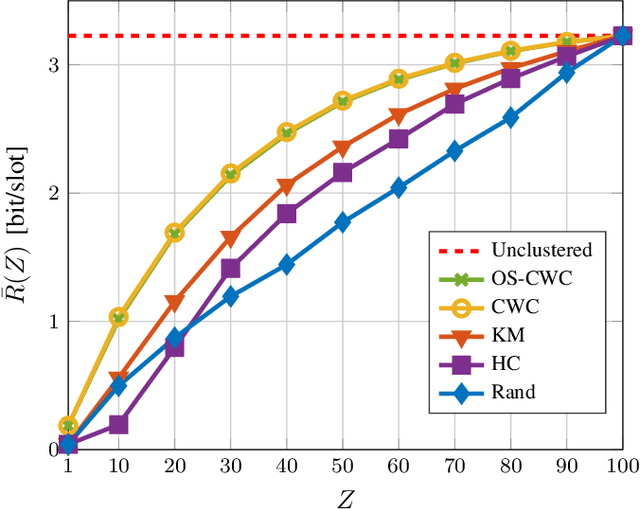
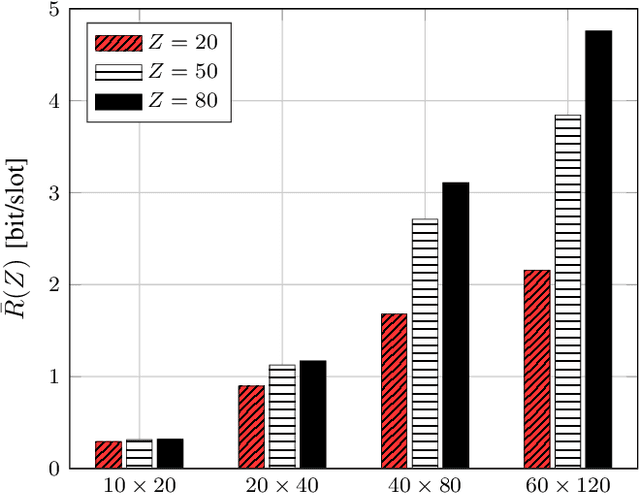
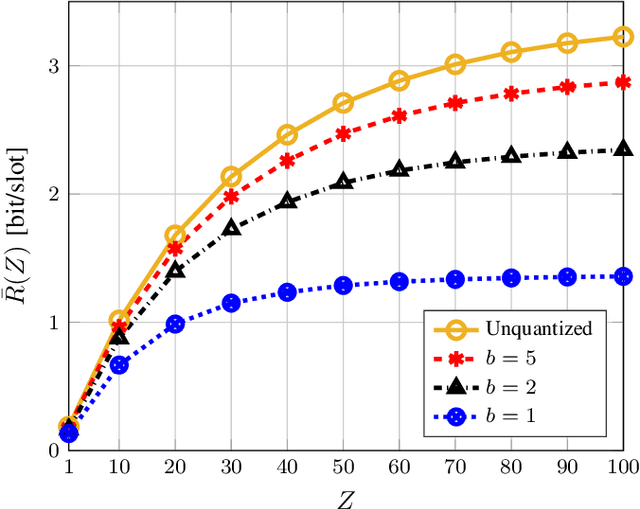
Intelligent reflecting surfaces (IRSs) are being studied as possible low-cost energy-efficient alternatives to active relays, with the goal of solving the coverage issues of millimeter wave (mmWave) and terahertz (THz) network deployments. In the literature, these surfaces are often studied by idealizing their characteristics. Notably, it is often assumed that IRSs can tune with arbitrary frequency the phase-shifts induced by their elements, thanks to a wire-like control channel to the next generation node base (gNB). Instead, in this work we investigate an IRS-aided time division multiple access (TDMA) cellular network, where the reconfiguration of the IRS may entail an energy or communication cost, and we aim at limiting the number of reconfigurations over time. We develop a clustering-based heuristic scheduling, which optimizes the system sum-rate subject to a given number of reconfigurations within the TDMA frame. To such end, we first cluster user equipments (UEs) with a similar optimal IRS configuration. Then, we compute an overall IRS cluster configuration, which can be thus kept constant while scheduling the whole UEs cluster. Numerical results show that our approach is effective in supporting IRSs-aided systems with practical constraints, achieving up to 85% of the throughput obtained by an ideal deployment, while providing a 50% reduction in the number of IRS reconfigurations.
Self-Compressing Neural Networks
Jan 31, 2023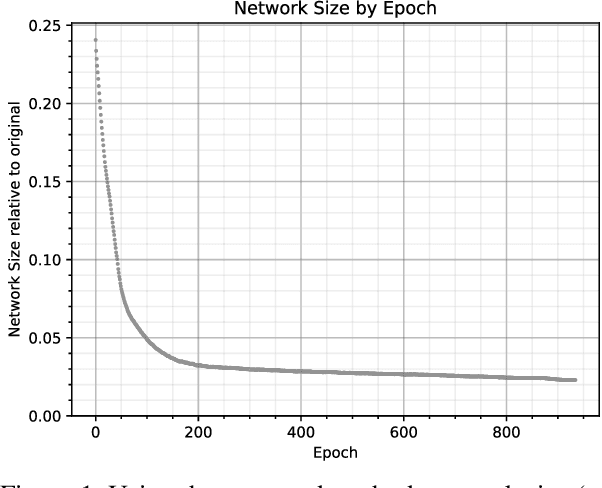
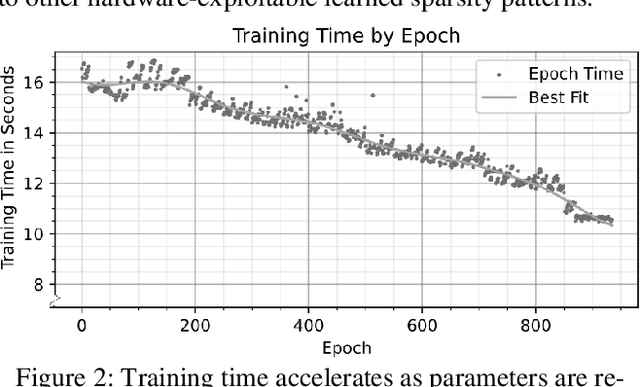
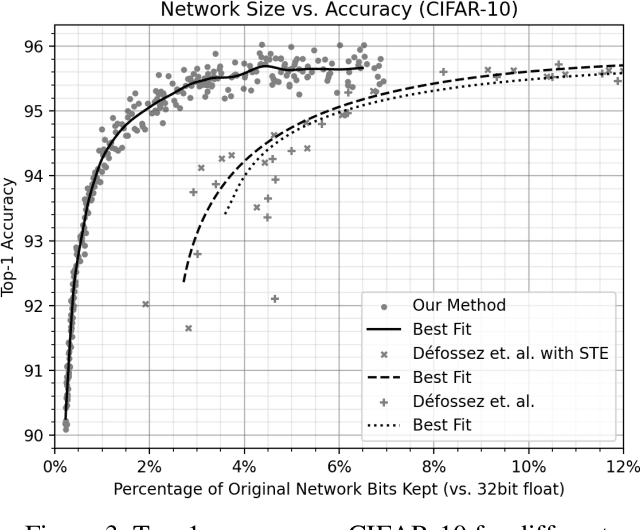
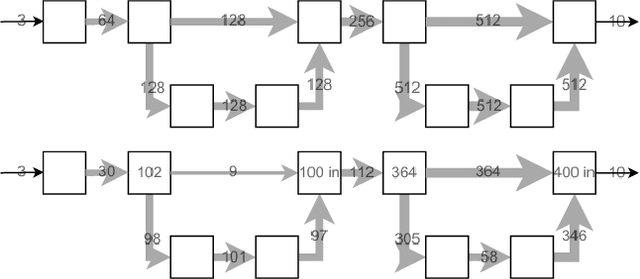
This work focuses on reducing neural network size, which is a major driver of neural network execution time, power consumption, bandwidth, and memory footprint. A key challenge is to reduce size in a manner that can be exploited readily for efficient training and inference without the need for specialized hardware. We propose Self-Compression: a simple, general method that simultaneously achieves two goals: (1) removing redundant weights, and (2) reducing the number of bits required to represent the remaining weights. This is achieved using a generalized loss function to minimize overall network size. In our experiments we demonstrate floating point accuracy with as few as 3% of the bits and 18% of the weights remaining in the network.
Salient Conditional Diffusion for Defending Against Backdoor Attacks
Jan 31, 2023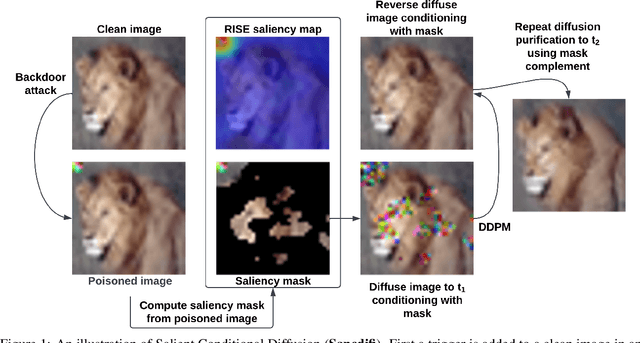
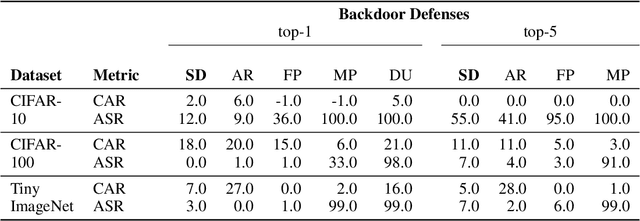
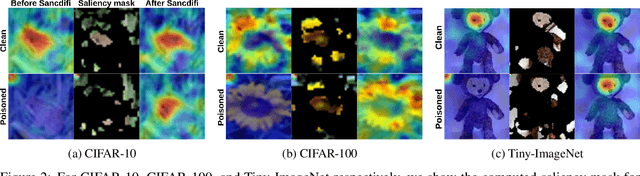
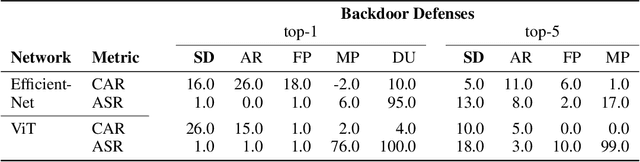
We propose a novel algorithm, Salient Conditional Diffusion (Sancdifi), a state-of-the-art defense against backdoor attacks. Sancdifi uses a denoising diffusion probabilistic model (DDPM) to degrade an image with noise and then recover said image using the learned reverse diffusion. Critically, we compute saliency map-based masks to condition our diffusion, allowing for stronger diffusion on the most salient pixels by the DDPM. As a result, Sancdifi is highly effective at diffusing out triggers in data poisoned by backdoor attacks. At the same time, it reliably recovers salient features when applied to clean data. This performance is achieved without requiring access to the model parameters of the Trojan network, meaning Sancdifi operates as a black-box defense.
Languages are Rewards: Chain of Hindsight Finetuning using Human Feedback
Feb 13, 2023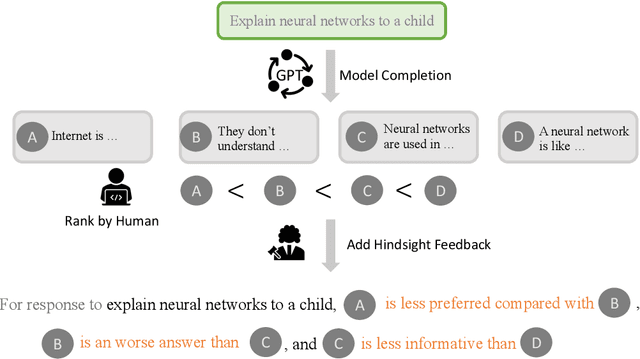
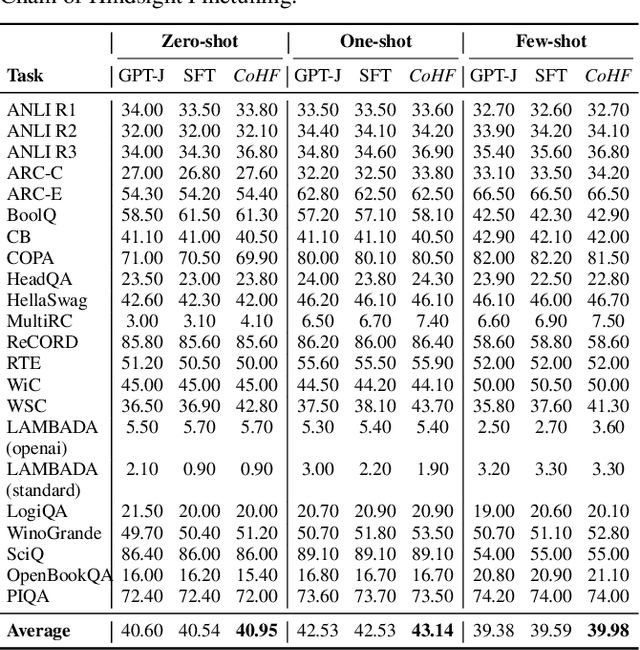
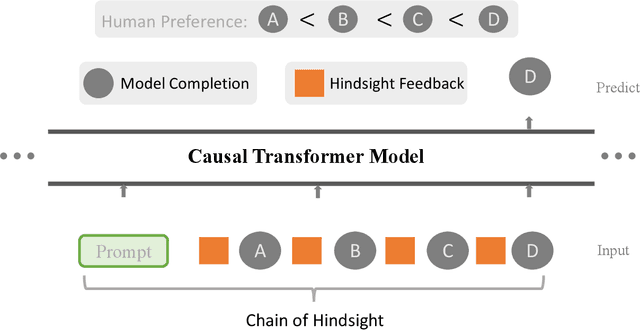
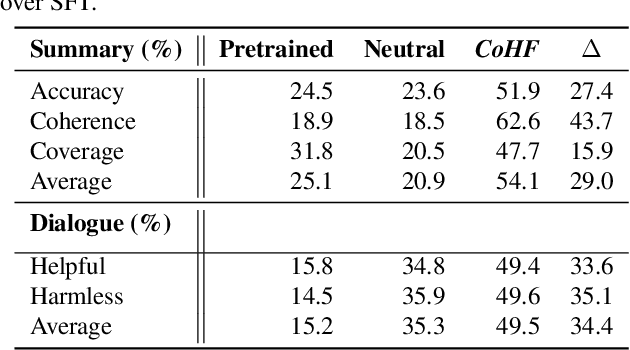
Learning from human preferences is important for language models to be helpful and useful for humans, and to align with human and social values. Existing works focus on supervised finetuning of pretrained models, based on curated model generations that are preferred by human labelers. Such works have achieved remarkable successes in understanding and following instructions (e.g., InstructGPT, ChatGPT, etc). However, to date, a key limitation of supervised finetuning is that it cannot learn from negative ratings; models are only trained on positive-rated data, which makes it data inefficient. Because collecting human feedback data is both time consuming and expensive, it is vital for the model to learn from all feedback, akin to the remarkable ability of humans to learn from diverse feedback. In this work, we propose a novel technique called Hindsight Finetuning for making language models learn from diverse human feedback. In fact, our idea is motivated by how humans learn from hindsight experience. We condition the model on a sequence of model generations paired with hindsight feedback, and finetune the model to predict the most preferred output. By doing so, models can learn to identify and correct negative attributes or errors. Applying the method to GPT-J, we observe that it significantly improves results on summarization and dialogue tasks using the same amount of human feedback.
Improving robot navigation in crowded environments using intrinsic rewards
Feb 13, 2023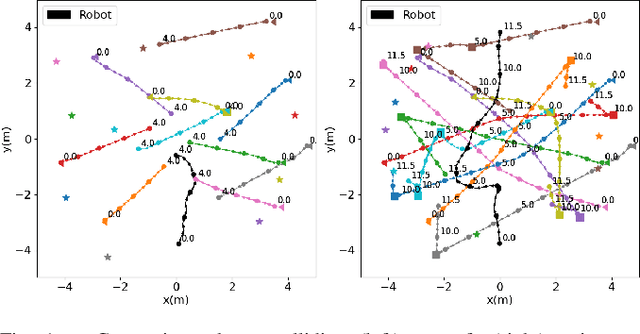
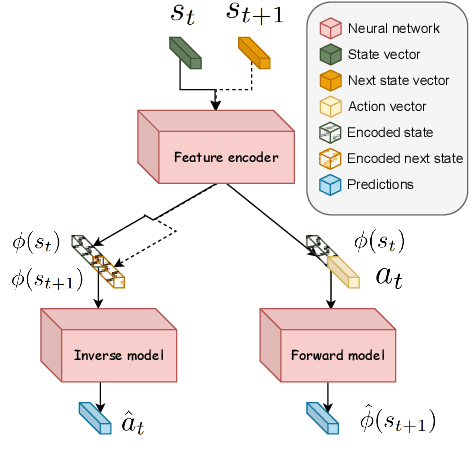
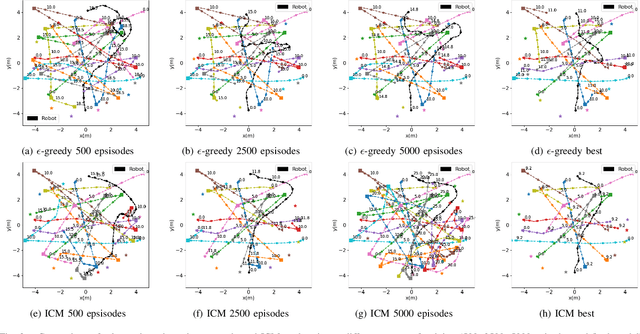
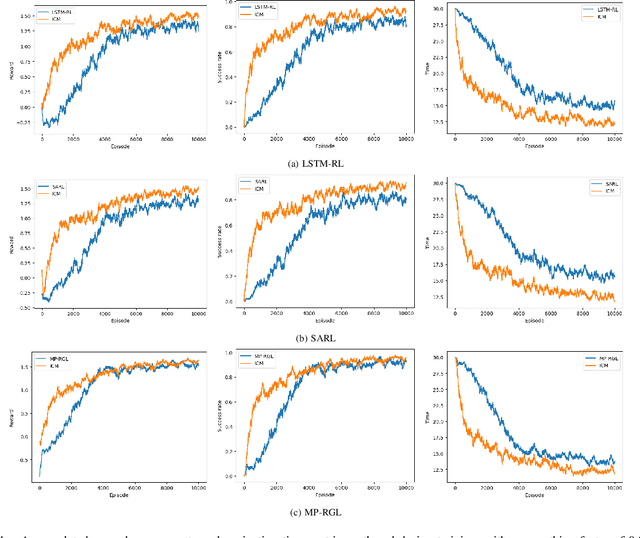
Autonomous navigation in crowded environments is an open problem with many applications, essential for the coexistence of robots and humans in the smart cities of the future. In recent years, deep reinforcement learning approaches have proven to outperform model-based algorithms. Nevertheless, even though the results provided are promising, the works are not able to take advantage of the capabilities that their models offer. They usually get trapped in local optima in the training process, that prevent them from learning the optimal policy. They are not able to visit and interact with every possible state appropriately, such as with the states near the goal or near the dynamic obstacles. In this work, we propose using intrinsic rewards to balance between exploration and exploitation and explore depending on the uncertainty of the states instead of on the time the agent has been trained, encouraging the agent to get more curious about unknown states. We explain the benefits of the approach and compare it with other exploration algorithms that may be used for crowd navigation. Many simulation experiments are performed modifying several algorithms of the state-of-the-art, showing that the use of intrinsic rewards makes the robot learn faster and reach higher rewards and success rates (fewer collisions) in shorter navigation times, outperforming the state-of-the-art.
Sensing-Throughput Tradeoffs with Generative Adversarial Networks for NextG Spectrum Sharing
Dec 27, 2022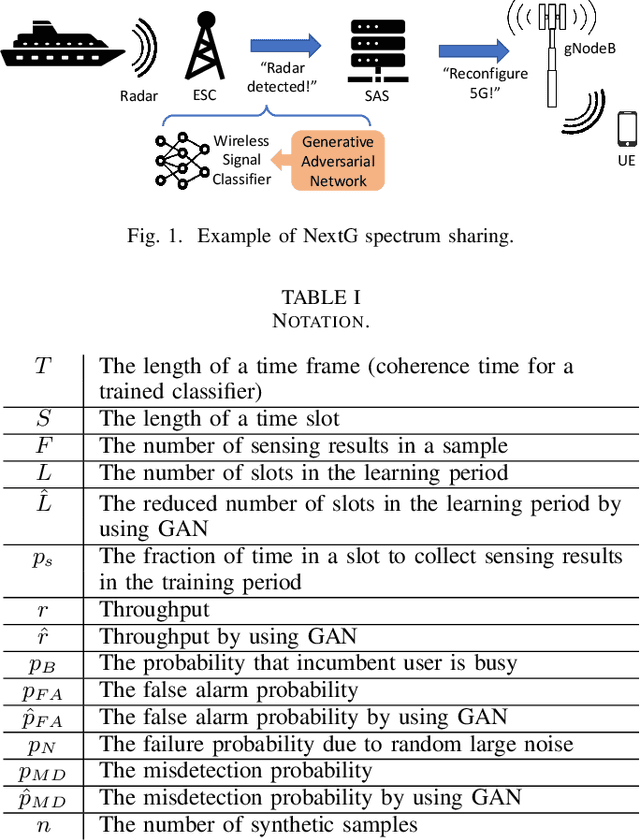

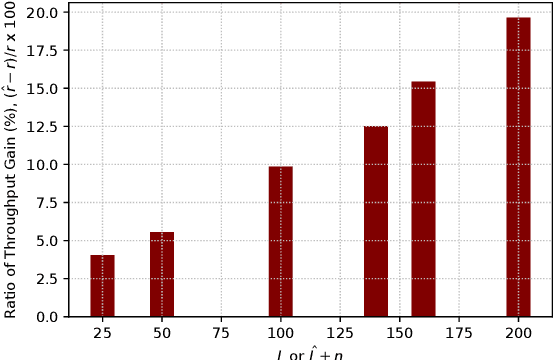
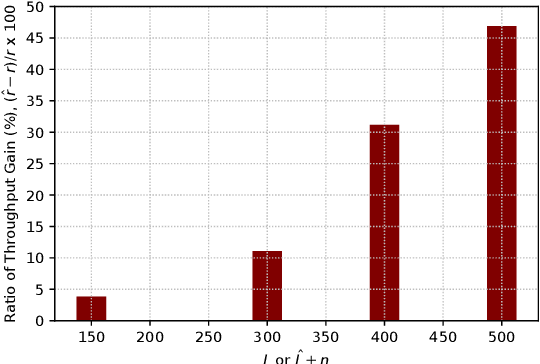
Spectrum coexistence is essential for next generation (NextG) systems to share the spectrum with incumbent (primary) users and meet the growing demand for bandwidth. One example is the 3.5 GHz Citizens Broadband Radio Service (CBRS) band, where the 5G and beyond communication systems need to sense the spectrum and then access the channel in an opportunistic manner when the incumbent user (e.g., radar) is not transmitting. To that end, a high-fidelity classifier based on a deep neural network is needed for low misdetection (to protect incumbent users) and low false alarm (to achieve high throughput for NextG). In a dynamic wireless environment, the classifier can only be used for a limited period of time, i.e., coherence time. A portion of this period is used for learning to collect sensing results and train a classifier, and the rest is used for transmissions. In spectrum sharing systems, there is a well-known tradeoff between the sensing time and the transmission time. While increasing the sensing time can increase the spectrum sensing accuracy, there is less time left for data transmissions. In this paper, we present a generative adversarial network (GAN) approach to generate synthetic sensing results to augment the training data for the deep learning classifier so that the sensing time can be reduced (and thus the transmission time can be increased) while keeping high accuracy of the classifier. We consider both additive white Gaussian noise (AWGN) and Rayleigh channels, and show that this GAN-based approach can significantly improve both the protection of the high-priority user and the throughput of the NextG user (more in Rayleigh channels than AWGN channels).
Disentangling Random and Cyclic Effects in Time-Lapse Sequences
Jul 04, 2022



Time-lapse image sequences offer visually compelling insights into dynamic processes that are too slow to observe in real time. However, playing a long time-lapse sequence back as a video often results in distracting flicker due to random effects, such as weather, as well as cyclic effects, such as the day-night cycle. We introduce the problem of disentangling time-lapse sequences in a way that allows separate, after-the-fact control of overall trends, cyclic effects, and random effects in the images, and describe a technique based on data-driven generative models that achieves this goal. This enables us to "re-render" the sequences in ways that would not be possible with the input images alone. For example, we can stabilize a long sequence to focus on plant growth over many months, under selectable, consistent weather. Our approach is based on Generative Adversarial Networks (GAN) that are conditioned with the time coordinate of the time-lapse sequence. Our architecture and training procedure are designed so that the networks learn to model random variations, such as weather, using the GAN's latent space, and to disentangle overall trends and cyclic variations by feeding the conditioning time label to the model using Fourier features with specific frequencies. We show that our models are robust to defects in the training data, enabling us to amend some of the practical difficulties in capturing long time-lapse sequences, such as temporary occlusions, uneven frame spacing, and missing frames.
Cross-domain Neural Pitch and Periodicity Estimation
Jan 28, 2023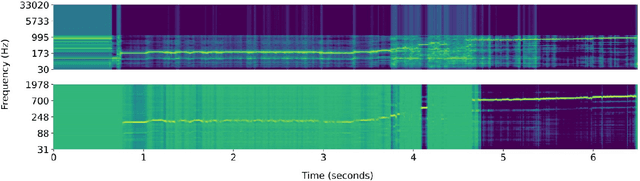
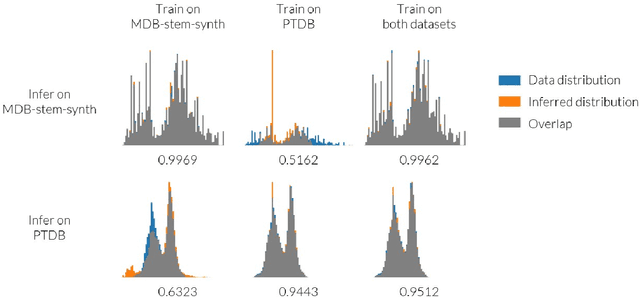
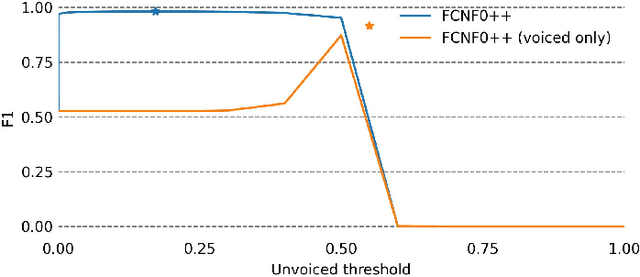
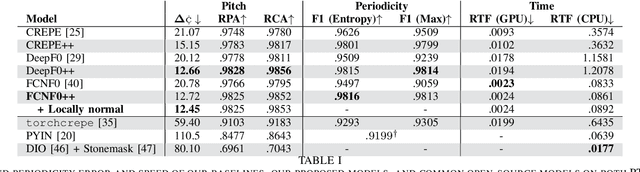
Pitch is a foundational aspect of our perception of audio signals. Pitch contours are commonly used to analyze speech and music signals and as input features for many audio tasks, including music transcription, singing voice synthesis, and prosody editing. In this paper, we describe a set of techniques for improving the accuracy of state-of-the-art neural pitch and periodicity estimators. We also introduce a novel entropy-based method for extracting periodicity and per-frame voiced-unvoiced classifications from statistical inference-based pitch estimators (e.g., neural networks), and show how to train a neural pitch estimator to simultaneously handle speech and music without performance degradation. While neural pitch trackers have historically been significantly slower than signal processing based pitch trackers, our estimator implementations approach the speed of state-of-the-art DSP-based pitch estimators on a standard CPU, but with significantly more accurate pitch and periodicity estimation. Our experiments show that an accurate, cross-domain pitch and periodicity estimator written in PyTorch with a hopsize of ten milliseconds can run 11.2x faster than real-time on a Intel i9-9820X 10-core 3.30 GHz CPU or 408x faster than real-time on a NVIDIA GeForce RTX 3090 GPU without hardware optimization. We release all of our code and models as Pitch-Estimating Neural Networks (penn), an open-source, pip-installable Python module for training, evaluating, and performing inference with pitch- and periodicity-estimating neural networks. The code for penn is available at https://github.com/interactiveaudiolab/penn.
A survey on online active learning
Feb 17, 2023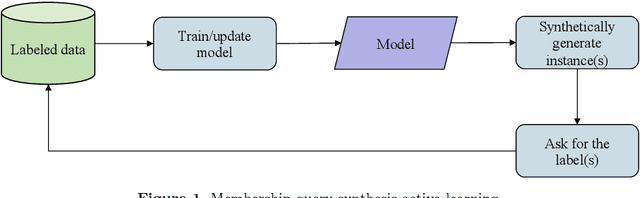
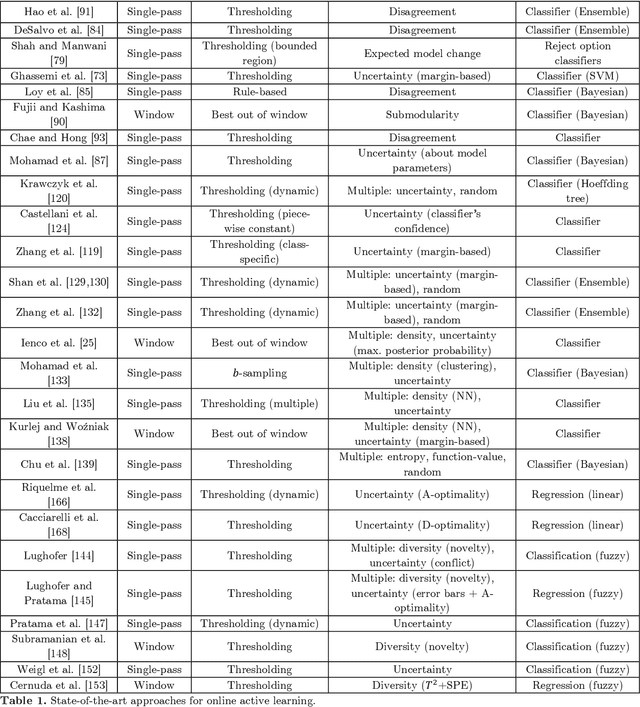
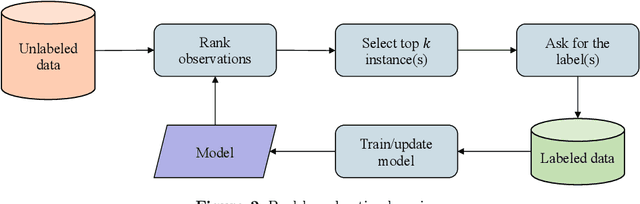
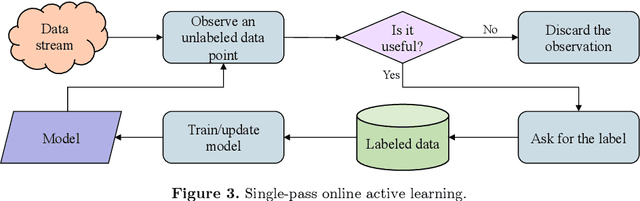
Online active learning is a paradigm in machine learning that aims to select the most informative data points to label from a data stream. The problem of minimizing the cost associated with collecting labeled observations has gained a lot of attention in recent years, particularly in real-world applications where data is only available in an unlabeled form. Annotating each observation can be time-consuming and costly, making it difficult to obtain large amounts of labeled data. To overcome this issue, many active learning strategies have been proposed in the last decades, aiming to select the most informative observations for labeling in order to improve the performance of machine learning models. These approaches can be broadly divided into two categories: static pool-based and stream-based active learning. Pool-based active learning involves selecting a subset of observations from a closed pool of unlabeled data, and it has been the focus of many surveys and literature reviews. However, the growing availability of data streams has led to an increase in the number of approaches that focus on online active learning, which involves continuously selecting and labeling observations as they arrive in a stream. This work aims to provide an overview of the most recently proposed approaches for selecting the most informative observations from data streams in the context of online active learning. We review the various techniques that have been proposed and discuss their strengths and limitations, as well as the challenges and opportunities that exist in this area of research. Our review aims to provide a comprehensive and up-to-date overview of the field and to highlight directions for future work.