 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning for Event-based Vision: A Comprehensive Survey and Benchmarks
Feb 17, 2023
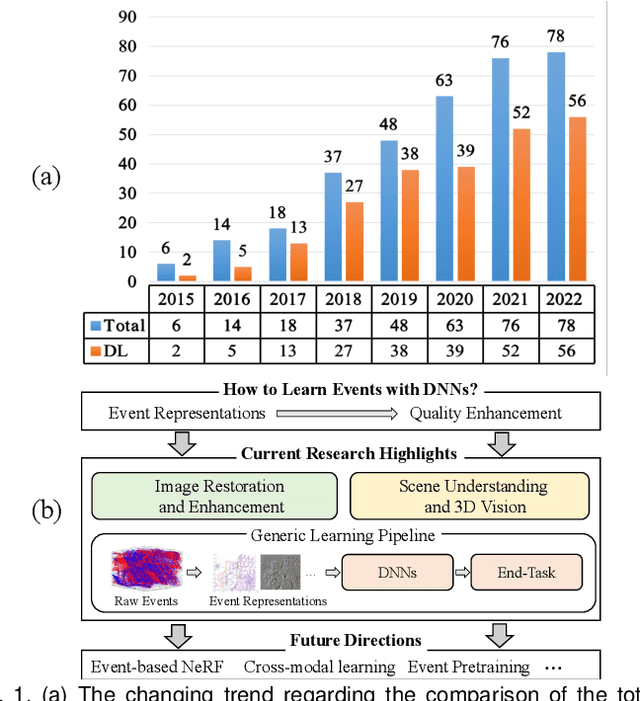
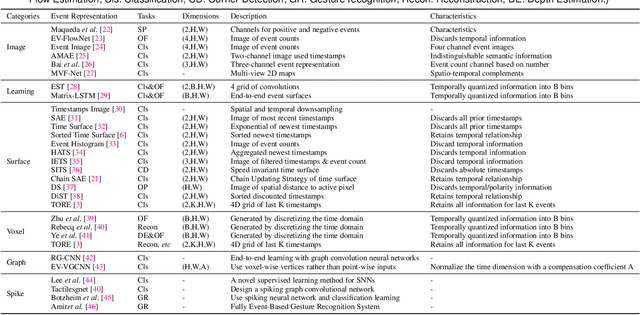

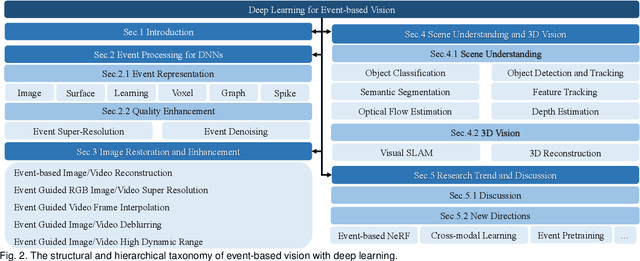
Event cameras are bio-inspired sensors that capture the per-pixel intensity changes asynchronously and produce event streams encoding the time, pixel position, and polarity (sign) of the intensity changes. Event cameras possess a myriad of advantages over canonical frame-based cameras, such as high temporal resolution, high dynamic range, low latency, etc. Being capable of capturing information in challenging visual conditions, event cameras have the potential to overcome the limitations of frame-based cameras in the computer vision and robotics community. In very recent years, deep learning (DL) has been brought to this emerging field and inspired active research endeavors in mining its potential. However, the technical advances still remain unknown, thus making it urgent and necessary to conduct a systematic overview. To this end, we conduct the first yet comprehensive and in-depth survey, with a focus on the latest developments of DL techniques for event-based vision. We first scrutinize the typical event representations with quality enhancement methods as they play a pivotal role as inputs to the DL models. We then provide a comprehensive taxonomy for existing DL-based methods by structurally grouping them into two major categories: 1) image reconstruction and restoration; 2) event-based scene understanding 3D vision. Importantly, we conduct benchmark experiments for the existing methods in some representative research directions (eg, object recognition and optical flow estimation) to identify some critical insights and problems. Finally, we make important discussions regarding the challenges and provide new perspectives for motivating future research studies.
From ORAN to Cell-Free RAN: Architecture, Performance Analysis, Testbeds and Trials
Feb 07, 2023
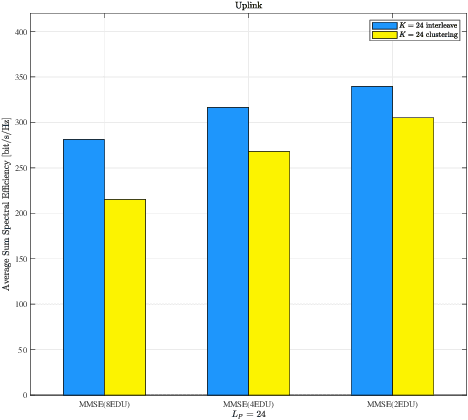
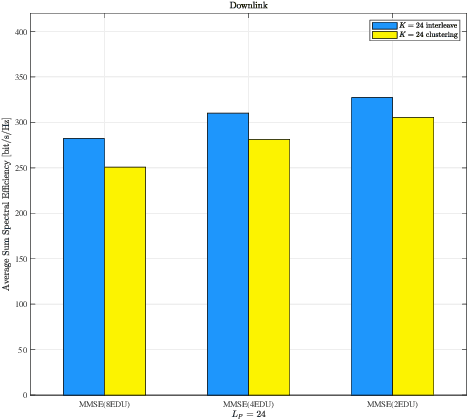

Open radio access network (ORAN) provides an open architecture to implement radio access network (RAN) of the fifth generation (5G) and beyond mobile communications. As a key technology for the evolution to the sixth generation (6G) systems, cell-free massive multiple-input multiple-output (CF-mMIMO) can effectively improve the spectrum efficiency, peak rate and reliability of wireless communication systems. Starting from scalable implementation of CF-mMIMO, we study a cell-free RAN (CF-RAN) under the ORAN architecture. Through theoretical analysis and numerical simulation, we investigate the uplink and downlink spectral efficiencies of CF-mMIMO with the new architecture. We then discuss the implementation issues of CF-RAN under ORAN architecture, including time-frequency synchronization and over-the-air reciprocity calibration, low layer splitting, deployment of ORAN radio units (O-RU), artificial intelligent based user associations. Finally, we present some representative experimental results for the uplink distributed reception and downlink coherent joint transmission of CF-RAN with commercial off-the-shelf O-RUs.
Riemannian Flow Matching on General Geometries
Feb 07, 2023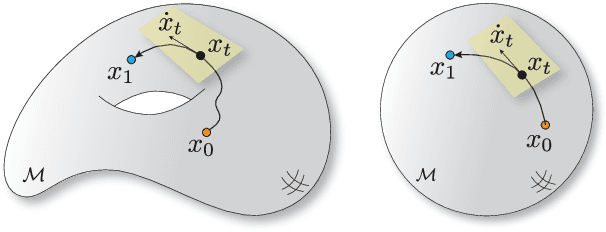
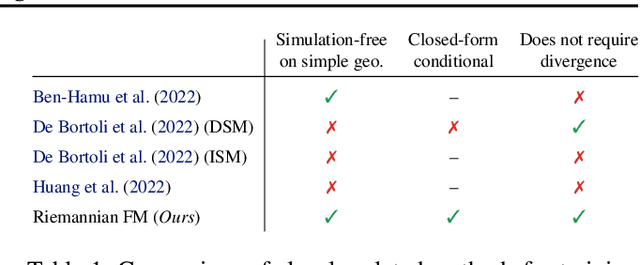
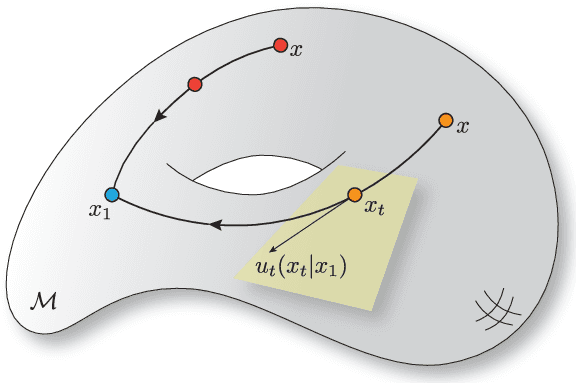
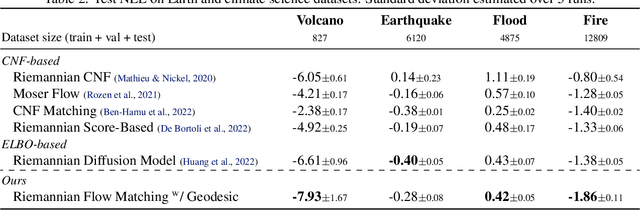
We propose Riemannian Flow Matching (RFM), a simple yet powerful framework for training continuous normalizing flows on manifolds. Existing methods for generative modeling on manifolds either require expensive simulation, inherently cannot scale to high dimensions, or use approximations to limiting quantities that result in biased objectives. Riemannian Flow Matching bypasses these inconveniences and exhibits multiple benefits over prior approaches: It is completely simulation-free on simple geometries, it does not require divergence computation, and its target vector field is computed in closed form even on general geometries. The key ingredient behind RFM is the construction of a simple kernel function for defining per-sample vector fields, which subsumes existing Euclidean cases. Extending to general geometries, we rely on the use of spectral decompositions to efficiently compute kernel functions. Our method achieves state-of-the-art performance on real-world non-Euclidean datasets, and we showcase, for the first time, tractable training on general geometries, including on triangular meshes and maze-like manifolds with boundaries.
Sketchy: Memory-efficient Adaptive Regularization with Frequent Directions
Feb 07, 2023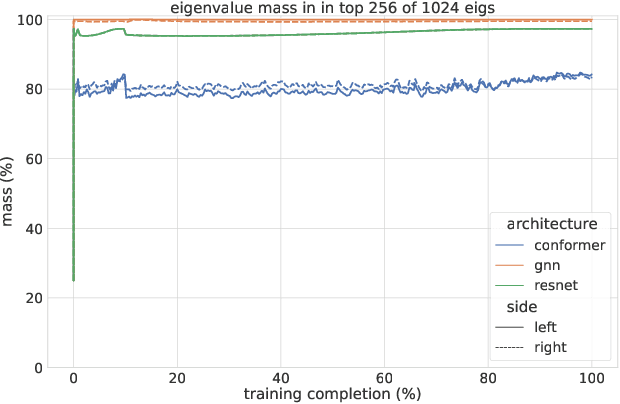


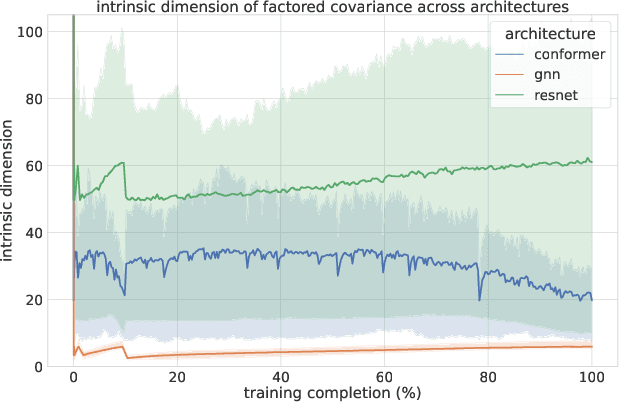
Adaptive regularization methods that exploit more than the diagonal entries exhibit state of the art performance for many tasks, but can be prohibitive in terms of memory and running time. We find the spectra of the Kronecker-factored gradient covariance matrix in deep learning (DL) training tasks are concentrated on a small leading eigenspace that changes throughout training, motivating a low-rank sketching approach. We describe a generic method for reducing memory and compute requirements of maintaining a matrix preconditioner using the Frequent Directions (FD) sketch. Our technique allows interpolation between resource requirements and the degradation in regret guarantees with rank $k$: in the online convex optimization (OCO) setting over dimension $d$, we match full-matrix $d^2$ memory regret using only $dk$ memory up to additive error in the bottom $d-k$ eigenvalues of the gradient covariance. Further, we show extensions of our work to Shampoo, placing the method on the memory-quality Pareto frontier of several large scale benchmarks.
On the Ideal Number of Groups for Isometric Gradient Propagation
Feb 07, 2023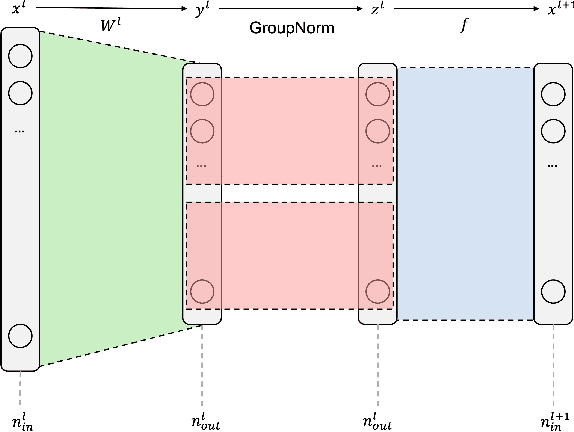

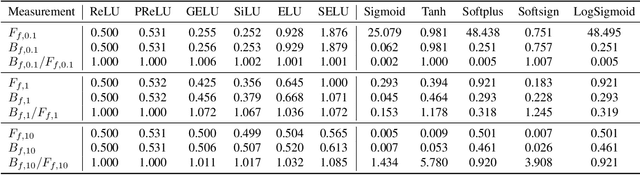
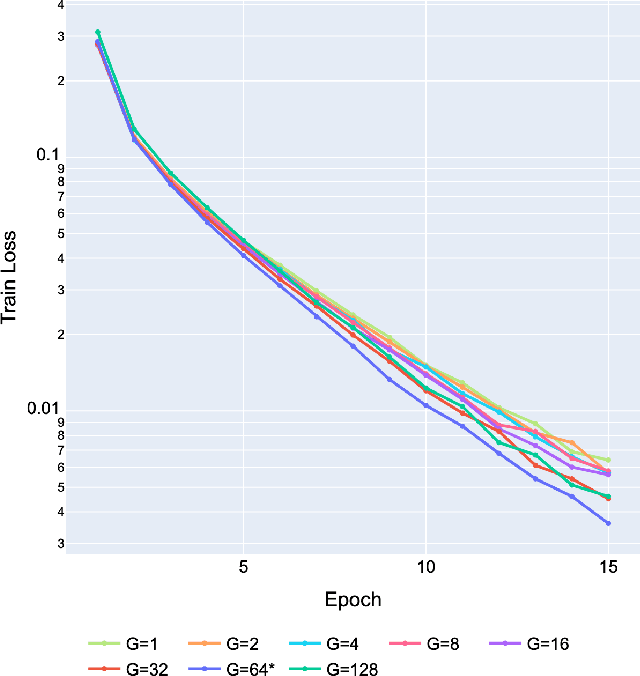
Recently, various normalization layers have been proposed to stabilize the training of deep neural networks. Among them, group normalization is a generalization of layer normalization and instance normalization by allowing a degree of freedom in the number of groups it uses. However, to determine the optimal number of groups, trial-and-error-based hyperparameter tuning is required, and such experiments are time-consuming. In this study, we discuss a reasonable method for setting the number of groups. First, we find that the number of groups influences the gradient behavior of the group normalization layer. Based on this observation, we derive the ideal number of groups, which calibrates the gradient scale to facilitate gradient descent optimization. Our proposed number of groups is theoretically grounded, architecture-aware, and can provide a proper value in a layer-wise manner for all layers. The proposed method exhibited improved performance over existing methods in numerous neural network architectures, tasks, and datasets.
Weakly Supervised Human Skin Segmentation using Guidance Attention Mechanisms
Feb 09, 2023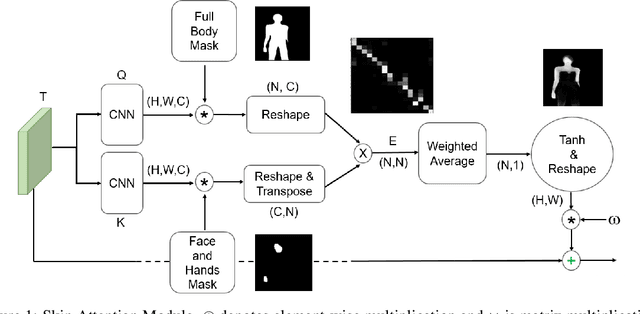
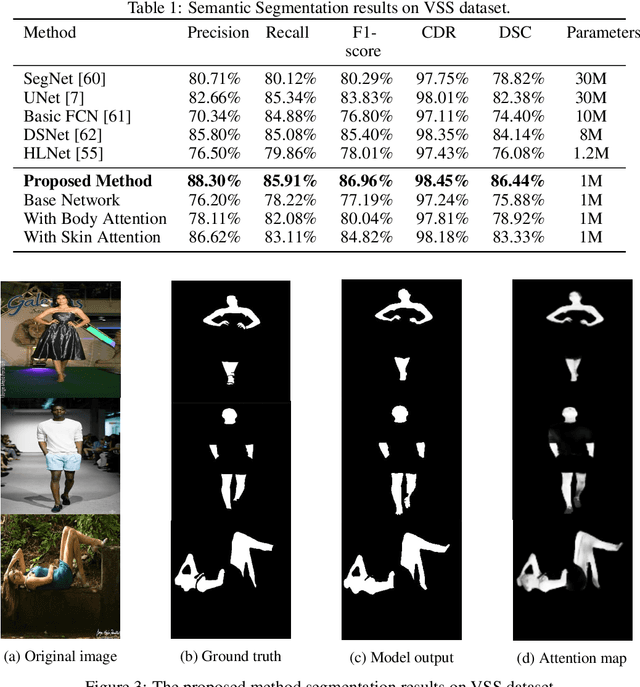
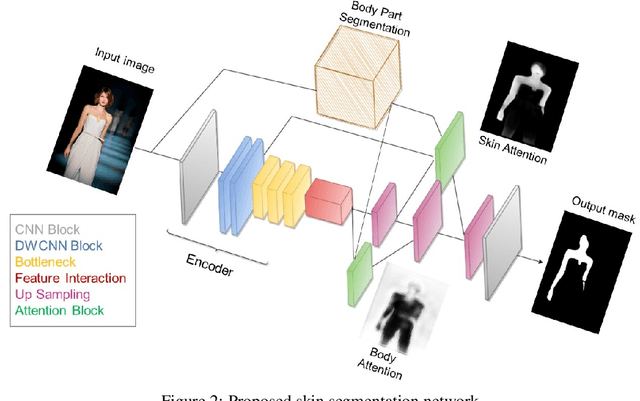
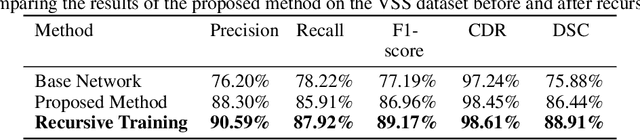
Human skin segmentation is a crucial task in computer vision and biometric systems, yet it poses several challenges such as variability in skin color, pose, and illumination. This paper presents a robust data-driven skin segmentation method for a single image that addresses these challenges through the integration of contextual information and efficient network design. In addition to robustness and accuracy, the integration into real-time systems requires a careful balance between computational power, speed, and performance. The proposed method incorporates two attention modules, Body Attention and Skin Attention, that utilize contextual information to improve segmentation results. These modules draw attention to the desired areas, focusing on the body boundaries and skin pixels, respectively. Additionally, an efficient network architecture is employed in the encoder part to minimize computational power while retaining high performance. To handle the issue of noisy labels in skin datasets, the proposed method uses a weakly supervised training strategy, relying on the Skin Attention module. The results of this study demonstrate that the proposed method is comparable to, or outperforms, state-of-the-art methods on benchmark datasets.
Geometry of Score Based Generative Models
Feb 09, 2023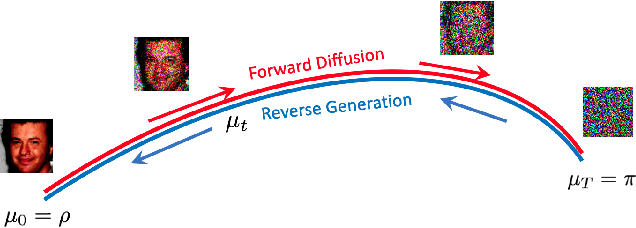
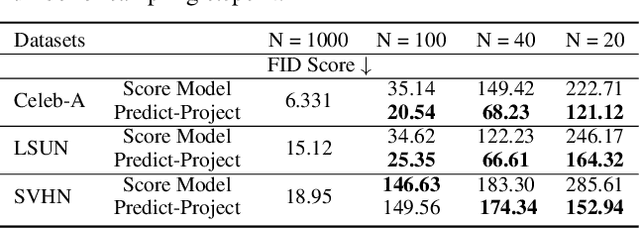


In this work, we look at Score-based generative models (also called diffusion generative models) from a geometric perspective. From a new view point, we prove that both the forward and backward process of adding noise and generating from noise are Wasserstein gradient flow in the space of probability measures. We are the first to prove this connection. Our understanding of Score-based (and Diffusion) generative models have matured and become more complete by drawing ideas from different fields like Bayesian inference, control theory, stochastic differential equation and Schrodinger bridge. However, many open questions and challenges remain. One problem, for example, is how to decrease the sampling time? We demonstrate that looking from geometric perspective enables us to answer many of these questions and provide new interpretations to some known results. Furthermore, geometric perspective enables us to devise an intuitive geometric solution to the problem of faster sampling. By augmenting traditional score-based generative models with a projection step, we show that we can generate high quality images with significantly fewer sampling-steps.
Fast Kinodynamic Planning on the Constraint Manifold with Deep Neural Networks
Jan 12, 2023
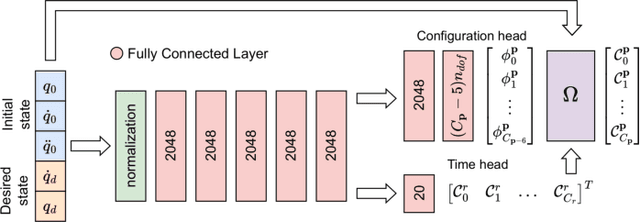
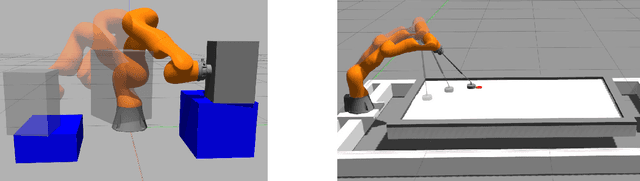
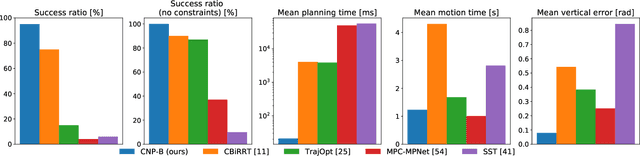
Motion planning is a mature area of research in robotics with many well-established methods based on optimization or sampling the state space, suitable for solving kinematic motion planning. However, when dynamic motions under constraints are needed and computation time is limited, fast kinodynamic planning on the constraint manifold is indispensable. In recent years, learning-based solutions have become alternatives to classical approaches, but they still lack comprehensive handling of complex constraints, such as planning on a lower-dimensional manifold of the task space while considering the robot's dynamics. This paper introduces a novel learning-to-plan framework that exploits the concept of constraint manifold, including dynamics, and neural planning methods. Our approach generates plans satisfying an arbitrary set of constraints and computes them in a short constant time, namely the inference time of a neural network. This allows the robot to plan and replan reactively, making our approach suitable for dynamic environments. We validate our approach on two simulated tasks and in a demanding real-world scenario, where we use a Kuka LBR Iiwa 14 robotic arm to perform the hitting movement in robotic Air Hockey.
Breaking the accuracy and resolution limitation of filter- and frequency-to-time mapping-based time and frequency acquisition methods by broadening the filter bandwidth
Aug 09, 2022In this paper, the filter- and frequency-to-time mapping (FTTM)-based photonics-assisted time and frequency acquisition methods are comprehensively analyzed and the accuracy and resolution limitation in the fast sweep scenario is broken by broadening the filter bandwidth. It is found that when the sweep speed is very fast, the width of the generated pulse via FTTM is mainly determined by the impulse response of the filter. In this case, appropriately increasing the filter bandwidth can significantly reduce the pulse width, so as to improve the measurement accuracy and resolution. FTTM-based short-time Fourier transform (STFT) and microwave frequency measurement using the stimulated Brillouin scattering (SBS) effect is demonstrated by comparing the results with and without SBS gain spectrum broadening and the improvement of measurement accuracy and frequency resolution is well confirmed. The frequency measurement accuracy of the system is improved by around 25 times compared with the former work using a similar sweep speed, while the frequency resolution of the STFT is also much improved compared with our former results.
Deepfake CAPTCHA: A Method for Preventing Fake Calls
Jan 08, 2023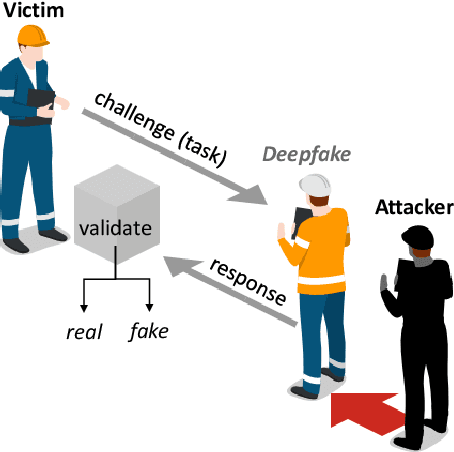
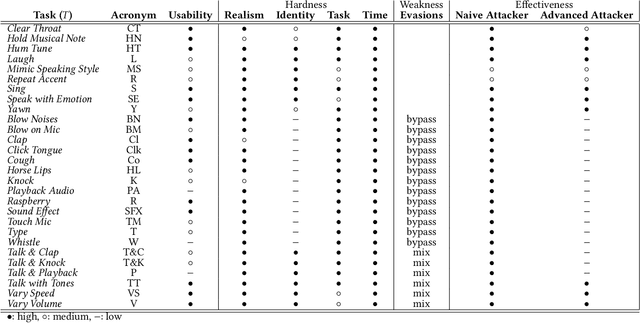
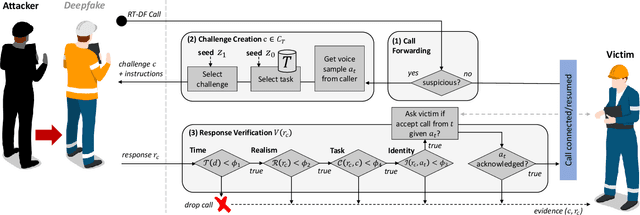
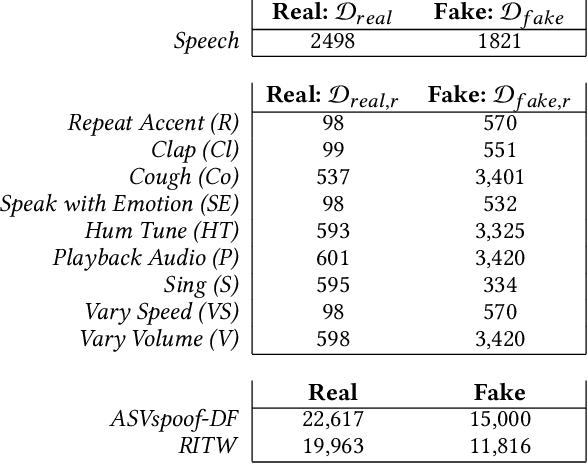
Deep learning technology has made it possible to generate realistic content of specific individuals. These `deepfakes' can now be generated in real-time which enables attackers to impersonate people over audio and video calls. Moreover, some methods only need a few images or seconds of audio to steal an identity. Existing defenses perform passive analysis to detect fake content. However, with the rapid progress of deepfake quality, this may be a losing game. In this paper, we propose D-CAPTCHA: an active defense against real-time deepfakes. The approach is to force the adversary into the spotlight by challenging the deepfake model to generate content which exceeds its capabilities. By doing so, passive detection becomes easier since the content will be distorted. In contrast to existing CAPTCHAs, we challenge the AI's ability to create content as opposed to its ability to classify content. In this work we focus on real-time audio deepfakes and present preliminary results on video. In our evaluation we found that D-CAPTCHA outperforms state-of-the-art audio deepfake detectors with an accuracy of 91-100% depending on the challenge (compared to 71% without challenges). We also performed a study on 41 volunteers to understand how threatening current real-time deepfake attacks are. We found that the majority of the volunteers could not tell the difference between real and fake audio.