 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automated Testing of Spatially-Dependent Environmental Hypotheses through Active Transfer Learning
Mar 07, 2024
The efficient collection of samples is an important factor in outdoor information gathering applications on account of high sampling costs such as time, energy, and potential destruction to the environment. Utilization of available a-priori data can be a powerful tool for increasing efficiency. However, the relationships of this data with the quantity of interest are often not known ahead of time, limiting the ability to leverage this knowledge for improved planning efficiency. To this end, this work combines transfer learning and active learning through a Multi-Task Gaussian Process and an information-based objective function. Through this combination it can explore the space of hypothetical inter-quantity relationships and evaluate these hypotheses in real-time, allowing this new knowledge to be immediately exploited for future plans. The performance of the proposed method is evaluated against synthetic data and is shown to evaluate multiple hypotheses correctly. Its effectiveness is also demonstrated on real datasets. The technique is able to identify and leverage hypotheses which show a medium or strong correlation to reduce prediction error by a factor of 1.4--3.4 within the first 7 samples, and poor hypotheses are quickly identified and rejected eventually having no adverse effect.
Non-asymptotic Convergence of Discrete-time Diffusion Models: New Approach and Improved Rate
Feb 21, 2024The denoising diffusion model emerges recently as a powerful generative technique that converts noise into data. Theoretical convergence guarantee has been mainly studied for continuous-time diffusion models, and has been obtained for discrete-time diffusion models only for distributions with bounded support in the literature. In this paper, we establish the convergence guarantee for substantially larger classes of distributions under discrete-time diffusion models and further improve the convergence rate for distributions with bounded support. In particular, we first establish the convergence rates for both smooth and general (possibly non-smooth) distributions having finite second moment. We then specialize our results to a number of interesting classes of distributions with explicit parameter dependencies, including distributions with Lipschitz scores, Gaussian mixture distributions, and distributions with bounded support. We further propose a novel accelerated sampler and show that it improves the convergence rates of the corresponding regular sampler by orders of magnitude with respect to all system parameters. For distributions with bounded support, our result improves the dimensional dependence of the previous convergence rate by orders of magnitude. Our study features a novel analysis technique that constructs tilting factor representation of the convergence error and exploits Tweedie's formula for handling Taylor expansion power terms.
LSTPrompt: Large Language Models as Zero-Shot Time Series Forecasters by Long-Short-Term Prompting
Feb 25, 2024Time-series forecasting (TSF) finds broad applications in real-world scenarios. Prompting off-the-shelf Large Language Models (LLMs) demonstrates strong zero-shot TSF capabilities while preserving computational efficiency. However, existing prompting methods oversimplify TSF as language next-token predictions, overlooking its dynamic nature and lack of integration with state-of-the-art prompt strategies such as Chain-of-Thought. Thus, we propose LSTPrompt, a novel approach for prompting LLMs in zero-shot TSF tasks. LSTPrompt decomposes TSF into short-term and long-term forecasting sub-tasks, tailoring prompts to each. LSTPrompt guides LLMs to regularly reassess forecasting mechanisms to enhance adaptability. Extensive evaluations demonstrate consistently better performance of LSTPrompt than existing prompting methods, and competitive results compared to foundation TSF models.
A Framework for Controlling Multiple Industrial Robots using Mobile Applications
Mar 12, 2024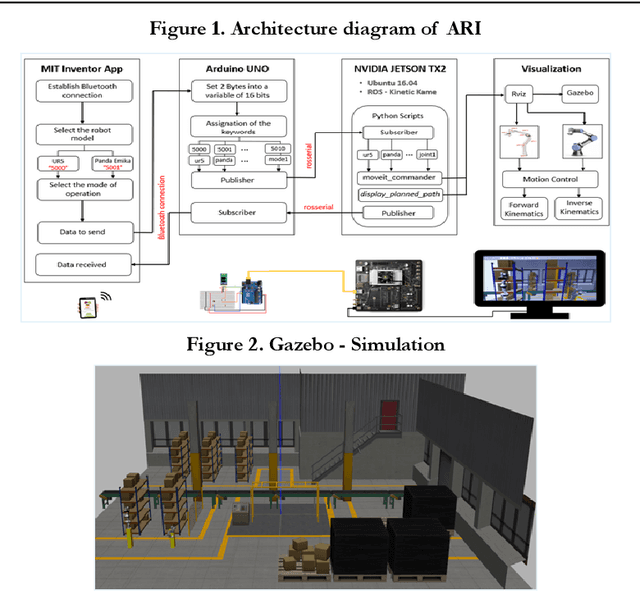
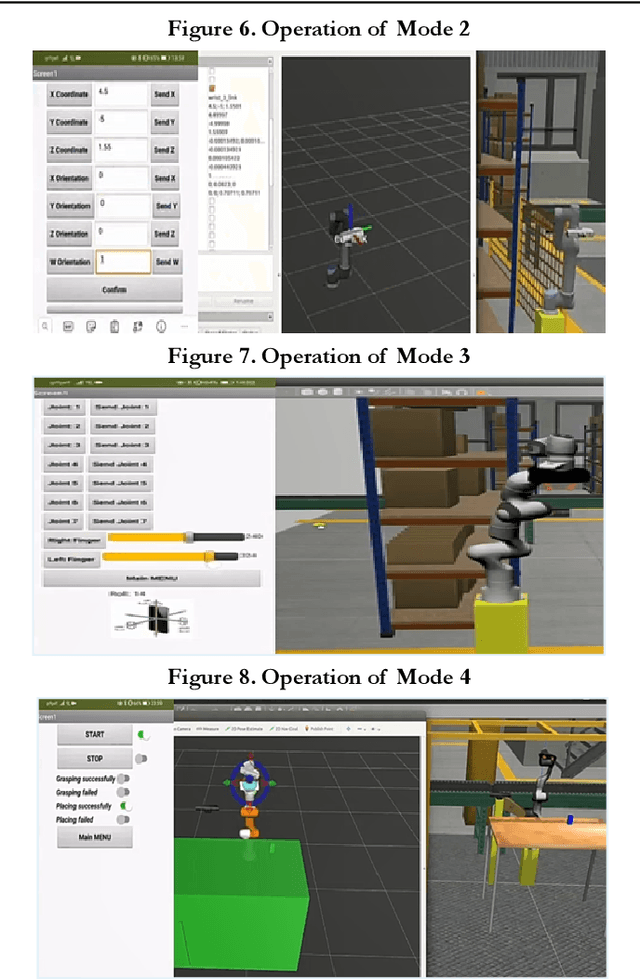
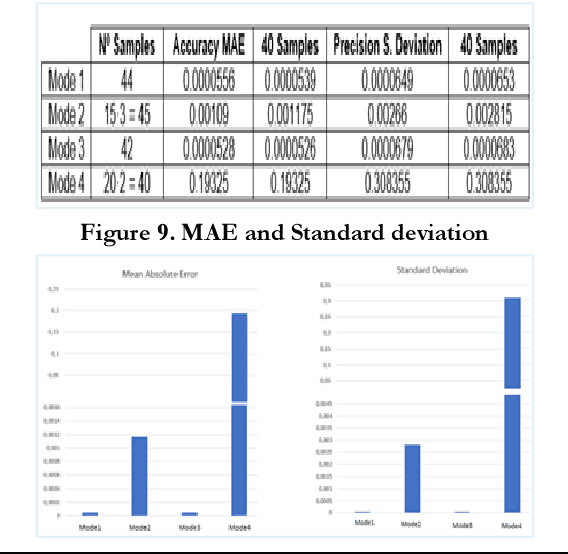
Purpose: Over the last few decades, the development of the hardware and software has enabled the application of advanced systems. In the robotics field, the UI design is an intriguing area to be explored due to the creation of devices with a wide range of functionalities in a reduced size. Moreover, the idea of using the same UI to control several systems arouses a great interest considering that this involves less learning effort and time for the users. Therefore, this paper will present a mobile application to control two industrial robots with four modes of operation. Design/methodology/approach: The smartphone was selected to be the interface due to its wide range of capabilities and the MIT Inventor App was used to create the application, whose environment is supported by Android smartphones. For the validation, ROS was used since it is a fundamental framework utilised in industrial robotics and the Arduino Uno was used to establish the data transmission between the smartphone and the board NVIDIA Jetson TX2. In MIT Inventor App, the graphical interface was created to visualize the options available in the app whereas two scripts in python were programmed to perform the simulations in ROS and carry out the tests. Findings: The results indicated that the use of the sliders to control the robots is more favourable than the Orientation Sensor due to the sensibility of the sensor and human limitations to hold the smartphone perfectly still. Another important finding was the limitations of the autonomous mode, in which the robot grabs an object. In this case, the configuration of the Kinect camera and the controllers has a significant impact on the success of the simulation. Finally, it was observed that the delay was appropriate despite the use of the Arduino UNO to transfer the data between the Smartphone and the Nvidia Jetson TX2.
Vision-based Vehicle Re-identification in Bridge Scenario using Flock Similarity
Mar 12, 2024


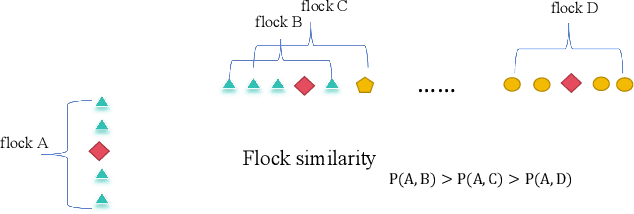
Due to the needs of road traffic flow monitoring and public safety management, video surveillance cameras are widely distributed in urban roads. However, the information captured directly by each camera is siloed, making it difficult to use it effectively. Vehicle re-identification refers to finding a vehicle that appears under one camera in another camera, which can correlate the information captured by multiple cameras. While license plate recognition plays an important role in some applications, there are some scenarios where re-identification method based on vehicle appearance are more suitable. The main challenge is that the data of vehicle appearance has the characteristics of high inter-class similarity and large intra-class differences. Therefore, it is difficult to accurately distinguish between different vehicles by relying only on vehicle appearance information. At this time, it is often necessary to introduce some extra information, such as spatio-temporal information. Nevertheless, the relative position of the vehicles rarely changes when passing through two adjacent cameras in the bridge scenario. In this paper, we present a vehicle re-identification method based on flock similarity, which improves the accuracy of vehicle re-identification by utilizing vehicle information adjacent to the target vehicle. When the relative position of the vehicles remains unchanged and flock size is appropriate, we obtain an average relative improvement of 204% on VeRi dataset in our experiments. Then, the effect of the magnitude of the relative position change of the vehicles as they pass through two cameras is discussed. We present two metrics that can be used to quantify the difference and establish a connection between them. Although this assumption is based on the bridge scenario, it is often true in other scenarios due to driving safety and camera location.
Safe Execution of Learned Orientation Skills with Conic Control Barrier Functions
Mar 08, 2024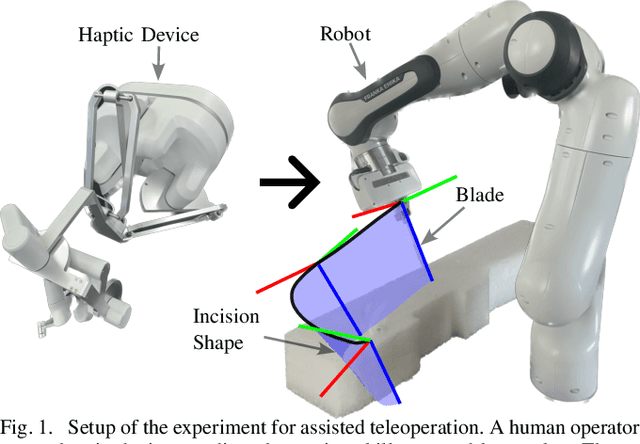
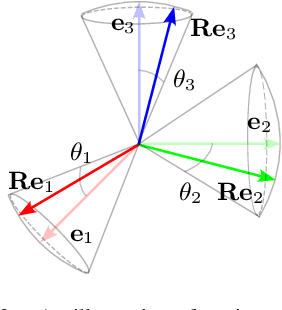
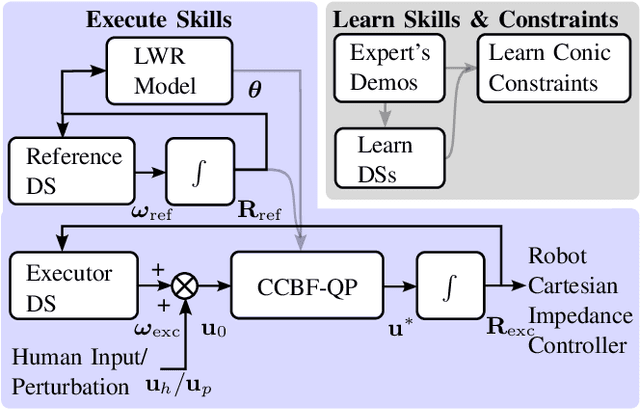
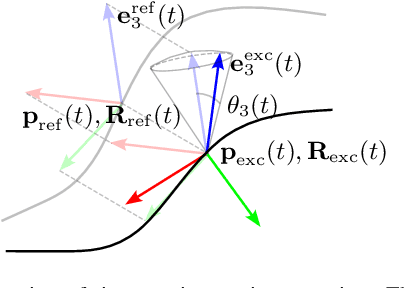
In the field of Learning from Demonstration (LfD), Dynamical Systems (DSs) have gained significant attention due to their ability to generate real-time motions and reach predefined targets. However, the conventional convergence-centric behavior exhibited by DSs may fall short in safety-critical tasks, specifically, those requiring precise replication of demonstrated trajectories or strict adherence to constrained regions even in the presence of perturbations or human intervention. Moreover, existing DS research often assumes demonstrations solely in Euclidean space, overlooking the crucial aspect of orientation in various applications. To alleviate these shortcomings, we present an innovative approach geared toward ensuring the safe execution of learned orientation skills within constrained regions surrounding a reference trajectory. This involves learning a stable DS on SO(3), extracting time-varying conic constraints from the variability observed in expert demonstrations, and bounding the evolution of the DS with Conic Control Barrier Function (CCBF) to fulfill the constraints. We validated our approach through extensive evaluation in simulation and showcased its effectiveness for a cutting skill in the context of assisted teleoperation.
Sparse Wearable Sonomyography Sensor-based Proprioceptive Proportional Control Across Multiple Gestures
Mar 08, 2024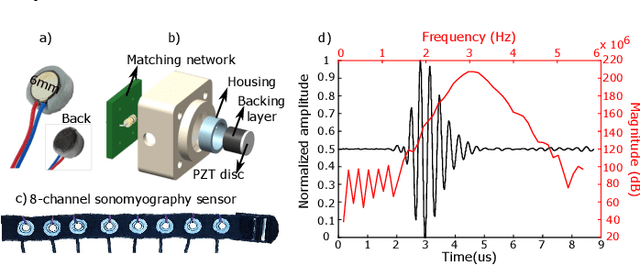
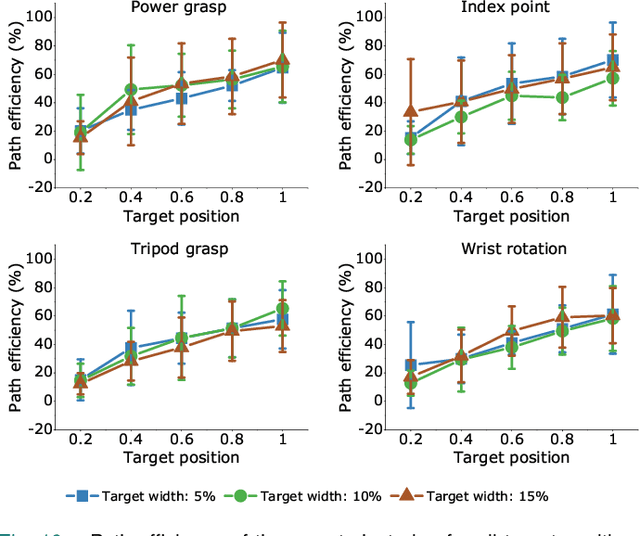
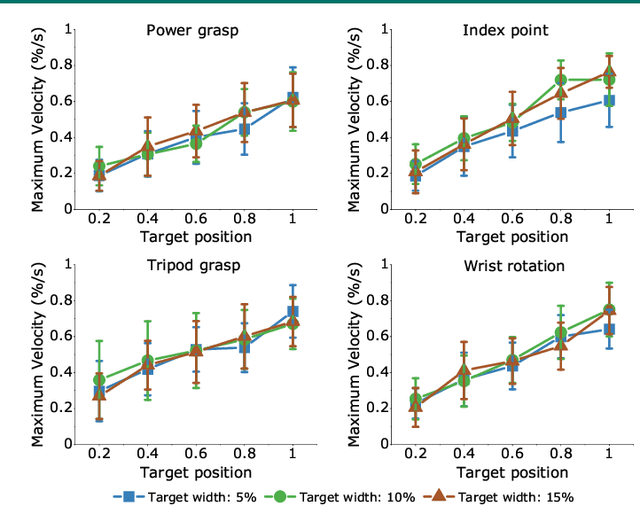
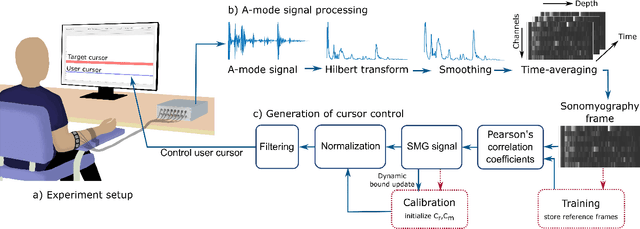
Sonomyography (SMG) is a non-invasive technique that uses ultrasound imaging to detect the dynamic activity of muscles. Wearable SMG systems have recently gained popularity due to their potential as human-computer interfaces for their superior performance compared to conventional methods. This paper demonstrates real-time positional proportional control of multiple gestures using a multiplexed 8-channel wearable SMG system. The amplitude-mode ultrasound signals from the SMG system were utilized to detect muscle activity from the forearm of 8 healthy individuals. The derived signals were used to control the on-screen movement of the cursor. A target achievement task was performed to analyze the performance of our SMG-based human-machine interface. Our wearable SMG system provided accurate, stable, and intuitive control in real-time by achieving an average success rate greater than 80% with all gestures. Furthermore, the wearable SMG system's abilities to detect volitional movement and decode movement kinematic information from SMG trajectories using standard performance metrics were evaluated. Our results provide insights to validate SMG as an intuitive human-machine interface.
Looking Ahead to Avoid Being Late: Solving Hard-Constrained Traveling Salesman Problem
Mar 08, 2024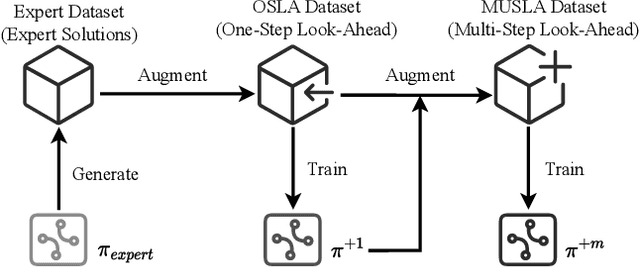
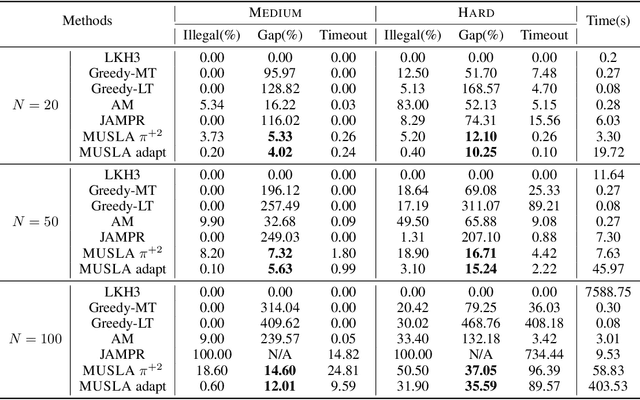
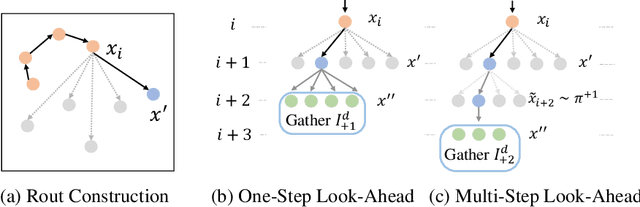
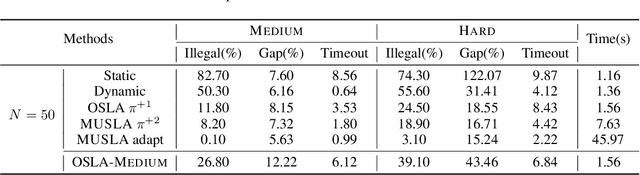
Many real-world problems can be formulated as a constrained Traveling Salesman Problem (TSP). However, the constraints are always complex and numerous, making the TSPs challenging to solve. When the number of complicated constraints grows, it is time-consuming for traditional heuristic algorithms to avoid illegitimate outcomes. Learning-based methods provide an alternative to solve TSPs in a soft manner, which also supports GPU acceleration to generate solutions quickly. Nevertheless, the soft manner inevitably results in difficulty solving hard-constrained problems with learning algorithms, and the conflicts between legality and optimality may substantially affect the optimality of the solution. To overcome this problem and to have an effective solution against hard constraints, we proposed a novel learning-based method that uses looking-ahead information as the feature to improve the legality of TSP with Time Windows (TSPTW) solutions. Besides, we constructed TSPTW datasets with hard constraints in order to accurately evaluate and benchmark the statistical performance of various approaches, which can serve the community for future research. With comprehensive experiments on diverse datasets, MUSLA outperforms existing baselines and shows generalizability potential.
Consecutive Model Editing with Batch alongside HooK Layers
Mar 08, 2024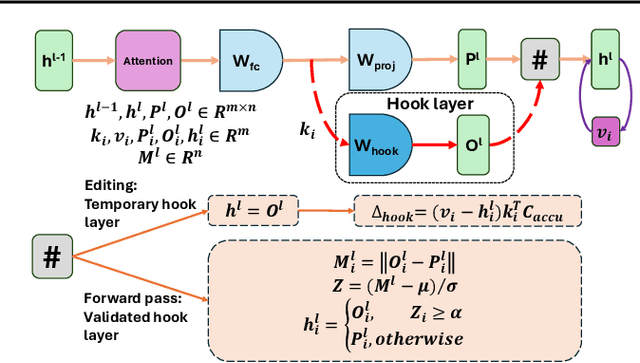
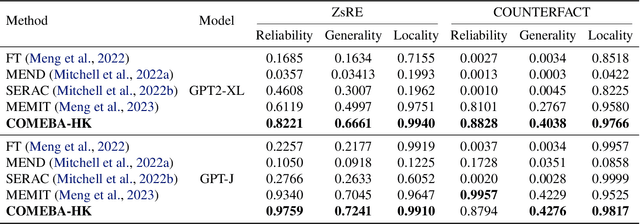
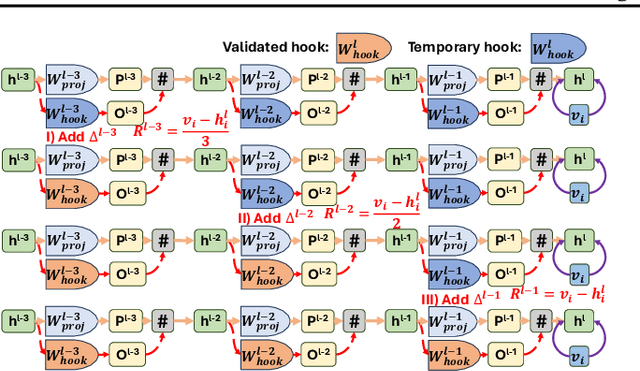
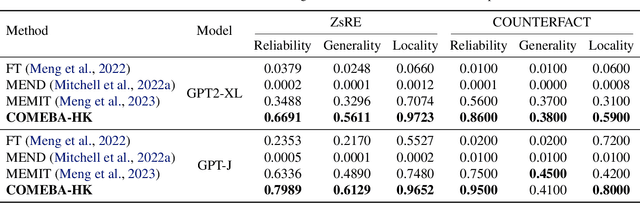
As the typical retraining paradigm is unacceptably time- and resource-consuming, researchers are turning to model editing in order to seek an effective, consecutive, and batch-supportive way to edit the model behavior directly. Despite all these practical expectations, existing model editing methods fail to realize all of them. Furthermore, the memory demands for such succession-supportive model editing approaches tend to be prohibitive, frequently necessitating an external memory that grows incrementally over time. To cope with these challenges, we propose COMEBA-HK, a model editing method that is both consecutive and batch-supportive. COMEBA-HK is memory-friendly as it only needs a small amount of it to store several hook layers with updated weights. Experimental results demonstrate the superiority of our method over other batch-supportive model editing methods under both single-round and consecutive batch editing scenarios. Extensive analyses of COMEBA-HK have been conducted to verify the stability of our method over 1) the number of consecutive steps and 2) the number of editing instance.
OmniJet-$α$: The first cross-task foundation model for particle physics
Mar 08, 2024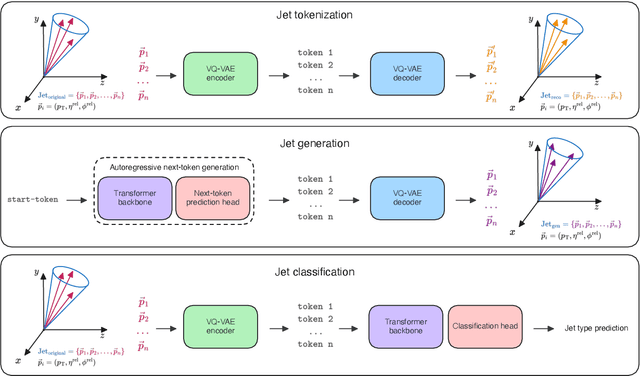
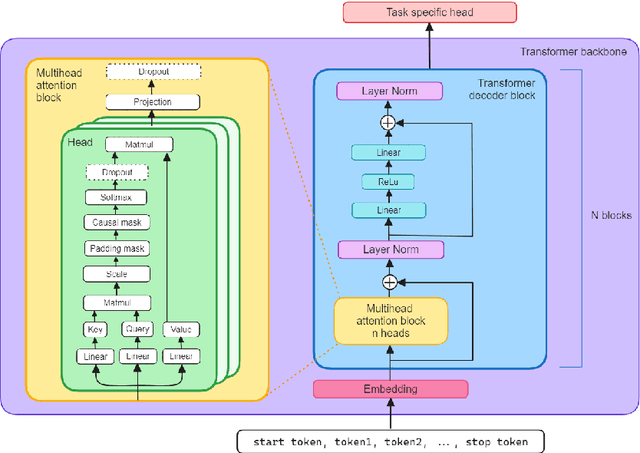
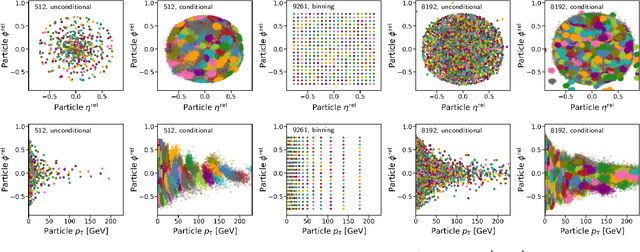
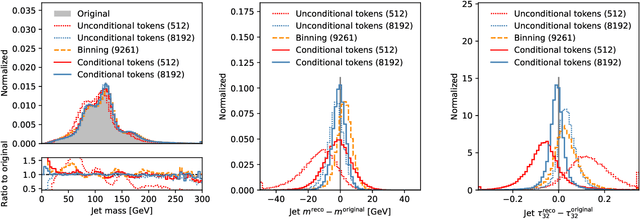
Foundation models are multi-dataset and multi-task machine learning methods that once pre-trained can be fine-tuned for a large variety of downstream applications. The successful development of such general-purpose models for physics data would be a major breakthrough as they could improve the achievable physics performance while at the same time drastically reduce the required amount of training time and data. We report significant progress on this challenge on several fronts. First, a comprehensive set of evaluation methods is introduced to judge the quality of an encoding from physics data into a representation suitable for the autoregressive generation of particle jets with transformer architectures (the common backbone of foundation models). These measures motivate the choice of a higher-fidelity tokenization compared to previous works. Finally, we demonstrate transfer learning between an unsupervised problem (jet generation) and a classic supervised task (jet tagging) with our new OmniJet-$\alpha$ model. This is the first successful transfer between two different and actively studied classes of tasks and constitutes a major step in the building of foundation models for particle physics.