 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
From paintbrush to pixel: A review of deep neural networks in AI-generated art
Feb 14, 2023

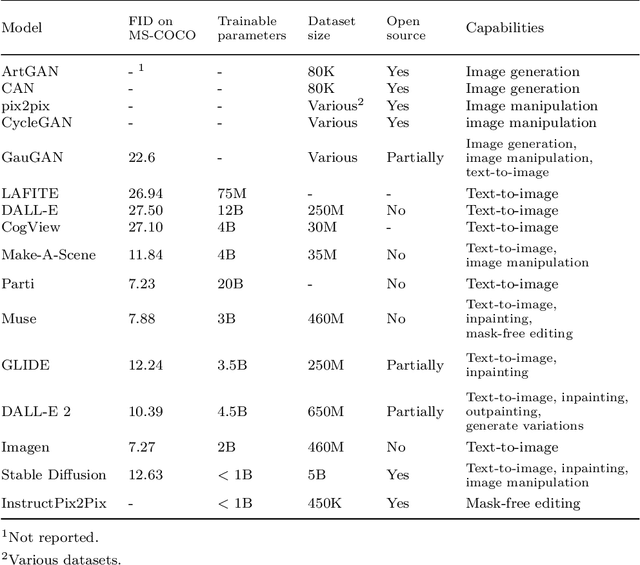
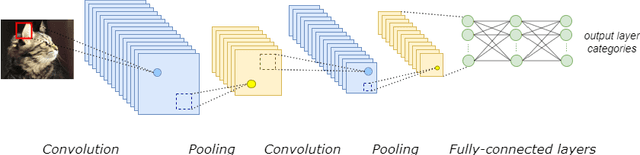
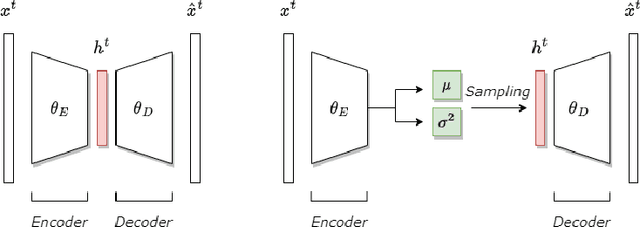
This paper delves into the fascinating field of AI-generated art and explores the various deep neural network architectures and models that have been utilized to create it. From the classic convolutional networks to the cutting-edge diffusion models, we examine the key players in the field. We explain the general structures and working principles of these neural networks. Then, we showcase examples of milestones, starting with the dreamy landscapes of DeepDream and moving on to the most recent developments, including Stable Diffusion and DALL-E 2, which produce mesmerizing images. A detailed comparison of these models is provided, highlighting their strengths and limitations. Thus, we examine the remarkable progress that deep neural networks have made so far in a short period of time. With a unique blend of technical explanations and insights into the current state of AI-generated art, this paper exemplifies how art and computer science interact.
Data-Centric Governance
Feb 14, 2023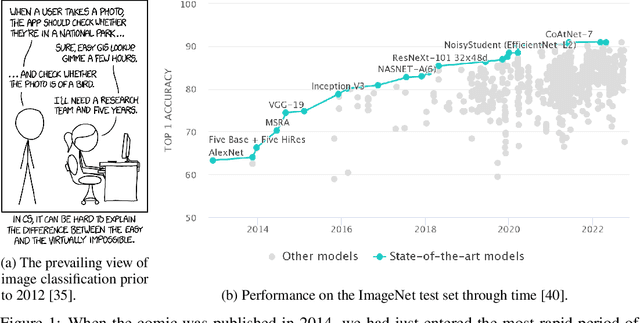


Artificial intelligence (AI) governance is the body of standards and practices used to ensure that AI systems are deployed responsibly. Current AI governance approaches consist mainly of manual review and documentation processes. While such reviews are necessary for many systems, they are not sufficient to systematically address all potential harms, as they do not operationalize governance requirements for system engineering, behavior, and outcomes in a way that facilitates rigorous and reproducible evaluation. Modern AI systems are data-centric: they act on data, produce data, and are built through data engineering. The assurance of governance requirements must also be carried out in terms of data. This work explores the systematization of governance requirements via datasets and algorithmic evaluations. When applied throughout the product lifecycle, data-centric governance decreases time to deployment, increases solution quality, decreases deployment risks, and places the system in a continuous state of assured compliance with governance requirements.
Nonparametric Density Estimation under Distribution Drift
Feb 05, 2023
We study nonparametric density estimation in non-stationary drift settings. Given a sequence of independent samples taken from a distribution that gradually changes in time, the goal is to compute the best estimate for the current distribution. We prove tight minimax risk bounds for both discrete and continuous smooth densities, where the minimum is over all possible estimates and the maximum is over all possible distributions that satisfy the drift constraints. Our technique handles a broad class of drift models, and generalizes previous results on agnostic learning under drift.
Smooth Non-Stationary Bandits
Jan 29, 2023
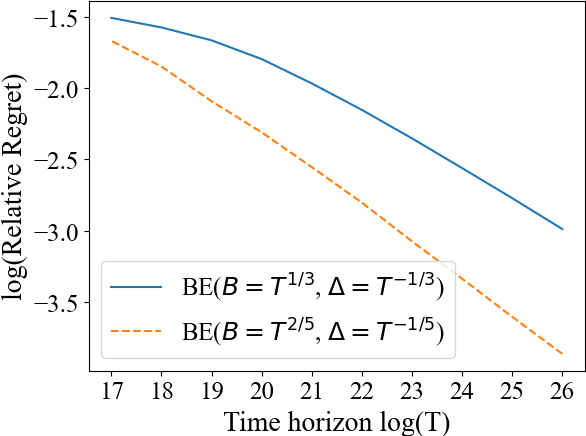
In many applications of online decision making, the environment is non-stationary and it is therefore crucial to use bandit algorithms that handle changes. Most existing approaches are designed to protect against non-smooth changes, constrained only by total variation or Lipschitzness over time, where they guarantee $T^{2/3}$ regret. However, in practice environments are often changing {\it smoothly}, so such algorithms may incur higher-than-necessary regret in these settings and do not leverage information on the {\it rate of change}. In this paper, we study a non-stationary two-arm bandit problem where we assume an arm's mean reward is a $\beta$-H\"older function over (normalized) time, meaning it is $(\beta-1)$-times Lipschitz-continuously differentiable. We show the first {\it separation} between the smooth and non-smooth regimes by presenting a policy with $T^{3/5}$ regret for $\beta=2$. We complement this result by a $T^{\frac{\beta+1}{2\beta+1}}$ lower bound for any integer $\beta\ge 1$, which matches our upper bound for $\beta=2$.
A Simplistic Model of Neural Scaling Laws: Multiperiodic Santa Fe Processes
Feb 17, 2023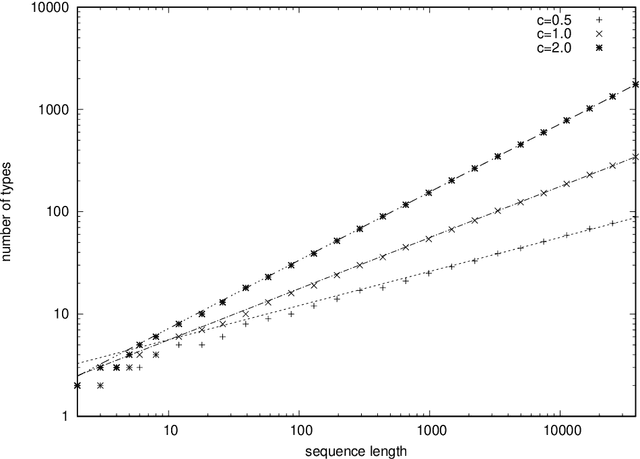
It was observed that large language models exhibit a power-law decay of cross entropy with respect to the number of parameters and training tokens. When extrapolated literally, this decay implies that the entropy rate of natural language is zero. To understand this phenomenon -- or an artifact -- better, we construct a simple stationary stochastic process and its memory-based predictor that exhibit a power-law decay of cross entropy with the vanishing entropy rate. Our example is based on previously discussed Santa Fe processes, which decompose a random text into a process of narration and time-independent knowledge. Previous discussions assumed that narration is a memoryless source with Zipf's distribution. In this paper, we propose a model of narration that has the vanishing entropy rate and applies a randomly chosen deterministic sequence called a multiperiodic sequence. Under a suitable parameterization, multiperiodic sequences exhibit asymptotic relative frequencies given by Zipf's law. Remaining agnostic about the value of the entropy rate of natural language, we discuss relevance of similar constructions for language modeling.
Analysis of the Effect of Time Delay for Unmanned Aerial Vehicles with Applications to Vision Based Navigation
Sep 05, 2022
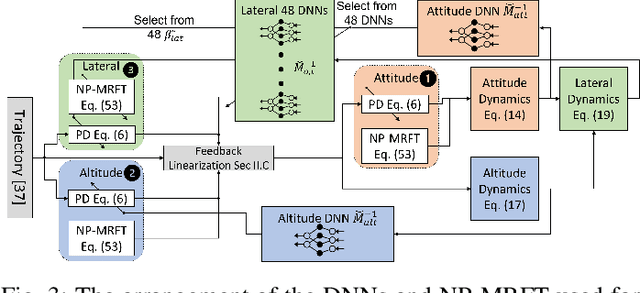
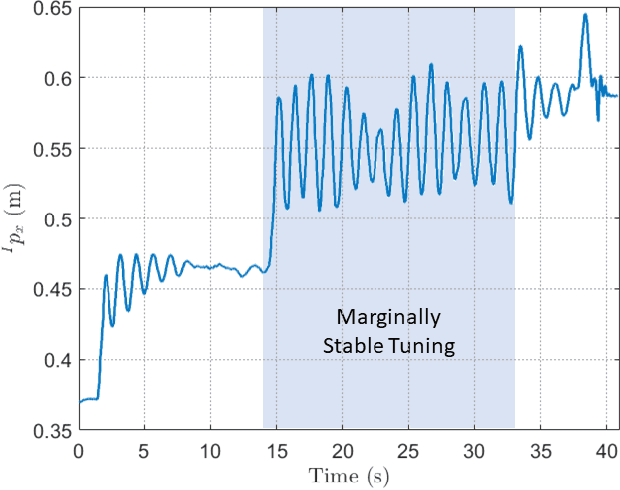
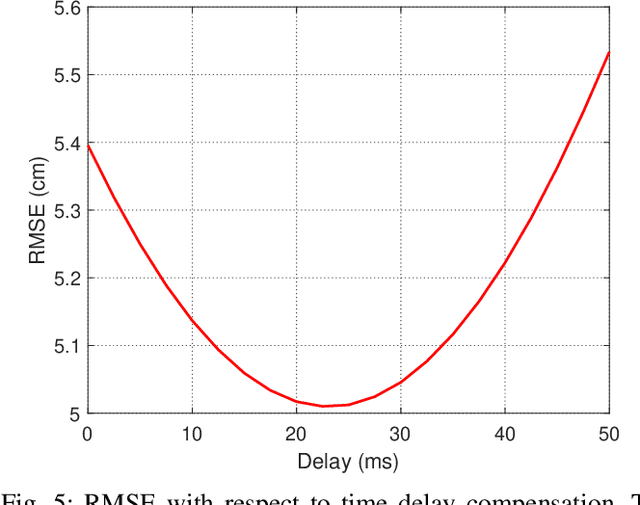
In this paper, we analyze the effect of time delay dynamics on controller design for Unmanned Aerial Vehicles (UAVs) with vision based navigation. Time delay is an inevitable phenomenon in cyber-physical systems, and has important implications on controller design and trajectory generation for UAVs. The impact of time delay on UAV dynamics increases with the use of the slower vision based navigation stack. We show that the existing models in the literature, which exclude time delay, are unsuitable for controller tuning since a trivial solution for minimizing an error cost functional always exists. The trivial solution that we identify suggests use of infinite controller gains to achieve optimal performance, which contradicts practical findings. We avoid such shortcomings by introducing a novel nonlinear time delay model for UAVs, and then obtain a set of linear decoupled models corresponding to each of the UAV control loops. The cost functional of the linearized time delay model of angular and altitude dynamics is analyzed, and in contrast to the delay-free models, we show the existence of finite optimal controller parameters. Due to the use of time delay models, we experimentally show that the proposed model accurately represents system stability limits. Due to time delay consideration, we achieved a tracking results of RMSE 5.01 cm when tracking a lemniscate trajectory with a peak velocity of 2.09 m/s using visual odometry (VO) based UAV navigation, which is on par with the state-of-the-art.
Input Perturbation Reduces Exposure Bias in Diffusion Models
Jan 27, 2023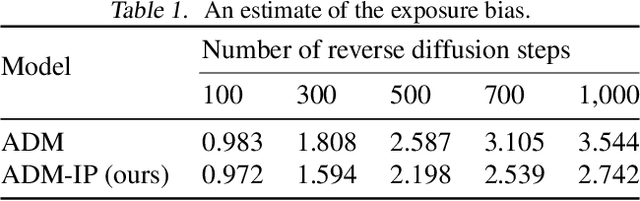
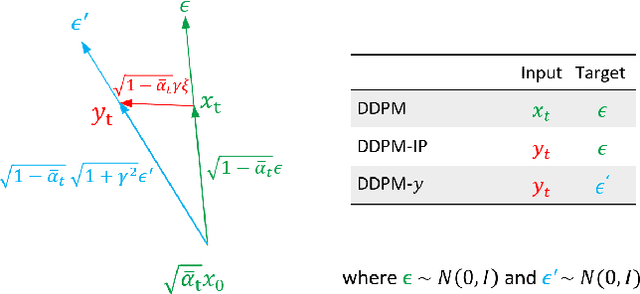
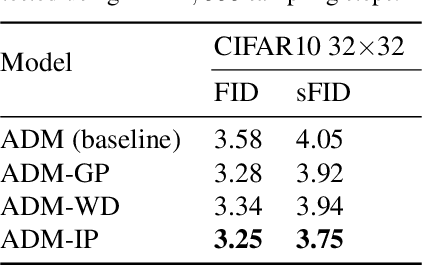
Denoising Diffusion Probabilistic Models have shown an impressive generation quality, although their long sampling chain leads to high computational costs. In this paper, we observe that a long sampling chain also leads to an error accumulation phenomenon, which is similar to the \textbf{exposure bias} problem in autoregressive text generation. Specifically, we note that there is a discrepancy between training and testing, since the former is conditioned on the ground truth samples, while the latter is conditioned on the previously generated results. To alleviate this problem, we propose a very simple but effective training regularization, consisting in perturbing the ground truth samples to simulate the inference time prediction errors. We empirically show that the proposed input perturbation leads to a significant improvement of the sample quality while reducing both the training and the inference times. For instance, on CelebA 64$\times$64, we achieve a new state-of-the-art FID score of 1.27, while saving 37.5% of the training time.
A Comparison of Tiny-nerf versus Spatial Representations for 3d Reconstruction
Jan 27, 2023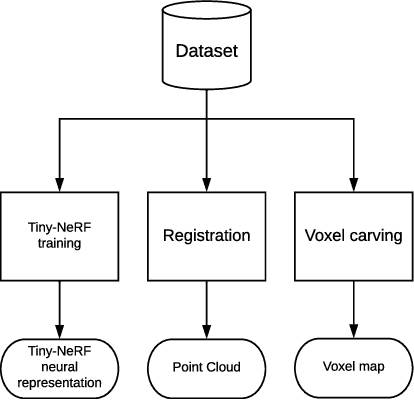
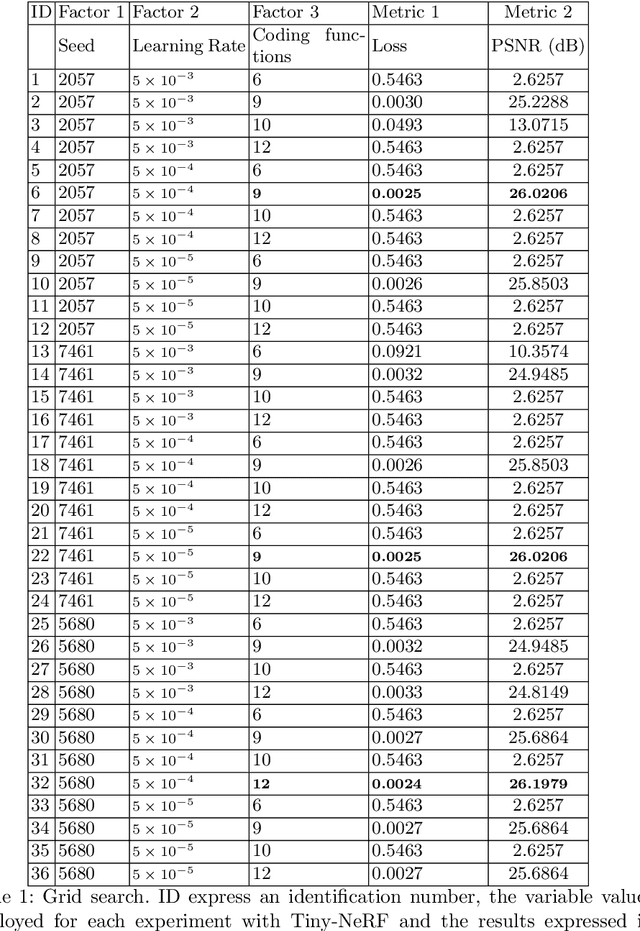

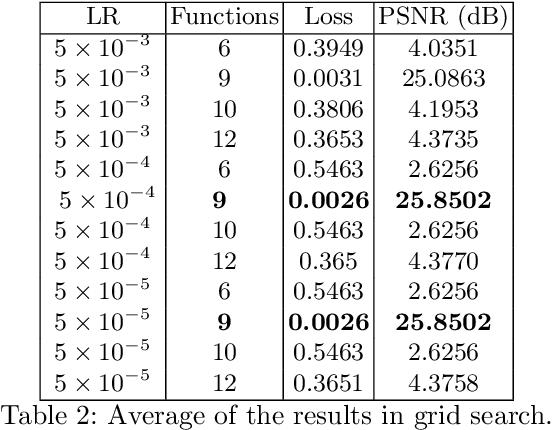
Neural rendering has emerged as a powerful paradigm for synthesizing images, offering many benefits over classical rendering by using neural networks to reconstruct surfaces, represent shapes, and synthesize novel views, either for objects or scenes. In this neural rendering, the environment is encoded into a neural network. We believe that these new representations can be used to codify the scene for a mobile robot. Therefore, in this work, we perform a comparison between a trending neural rendering, called tiny-NeRF, and other volume representations that are commonly used as maps in robotics, such as voxel maps, point clouds, and triangular meshes. The target is to know the advantages and disadvantages of neural representations in the robotics context. The comparison is made in terms of spatial complexity and processing time to obtain a model. Experiments show that tiny-NeRF requires three times less memory space compared to other representations. In terms of processing time, tiny-NeRF takes about six times more to compute the model.
A Memory Efficient Deep Reinforcement Learning Approach For Snake Game Autonomous Agents
Jan 27, 2023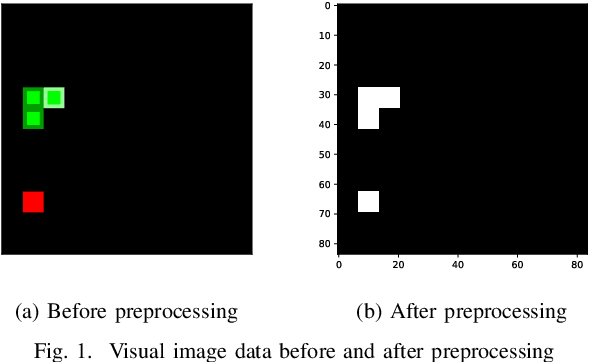

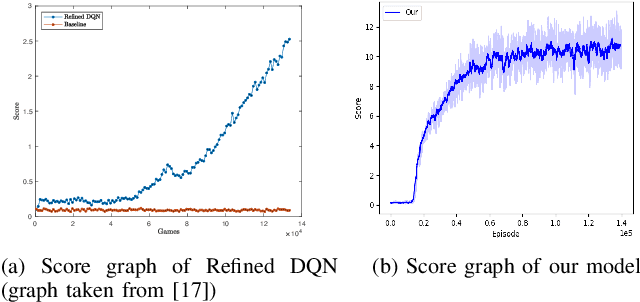
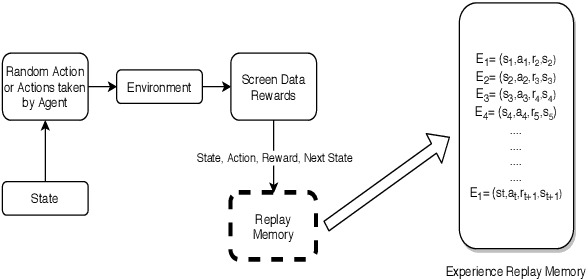
To perform well, Deep Reinforcement Learning (DRL) methods require significant memory resources and computational time. Also, sometimes these systems need additional environment information to achieve a good reward. However, it is more important for many applications and devices to reduce memory usage and computational times than to achieve the maximum reward. This paper presents a modified DRL method that performs reasonably well with compressed imagery data without requiring additional environment information and also uses less memory and time. We have designed a lightweight Convolutional Neural Network (CNN) with a variant of the Q-network that efficiently takes preprocessed image data as input and uses less memory. Furthermore, we use a simple reward mechanism and small experience replay memory so as to provide only the minimum necessary information. Our modified DRL method enables our autonomous agent to play Snake, a classical control game. The results show our model can achieve similar performance as other DRL methods.
* AICT 2022
Embodied Footprints: A Safety-guaranteed Collision Avoidance Model for Numerical Optimization-based Trajectory Planning
Feb 15, 2023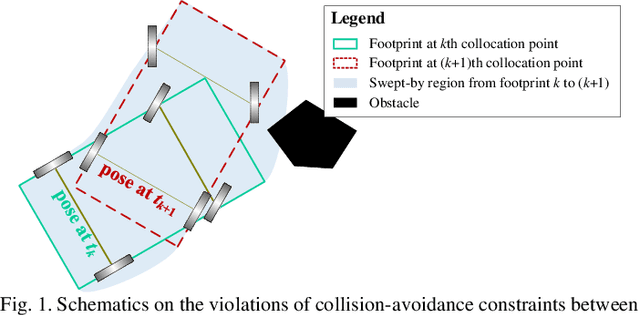
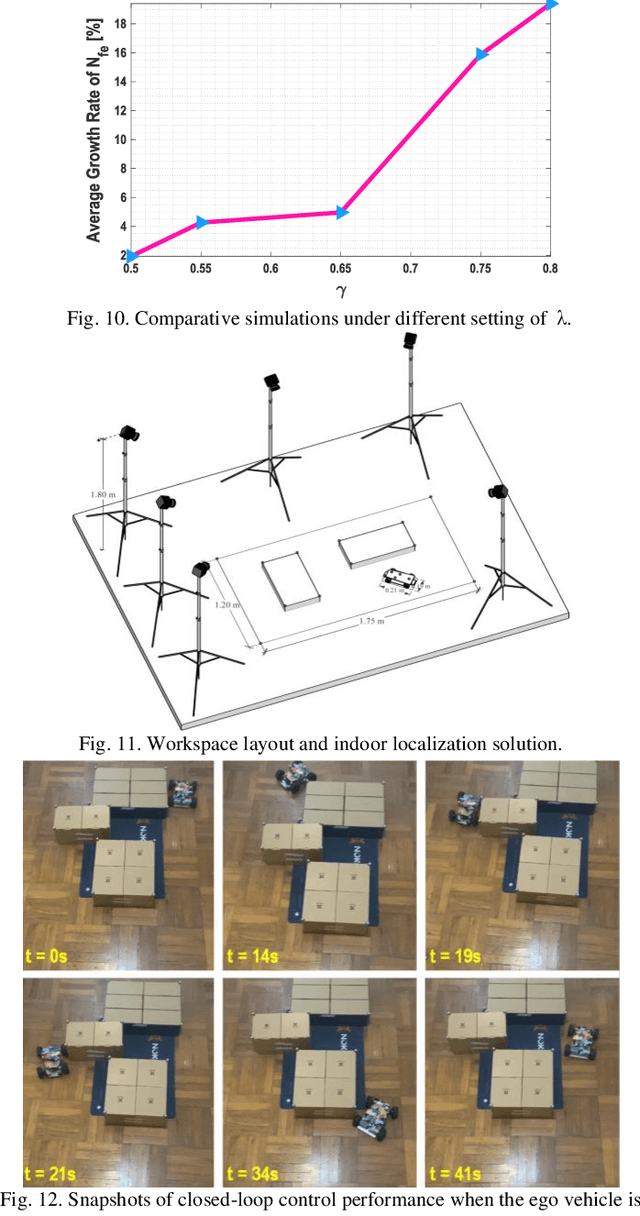
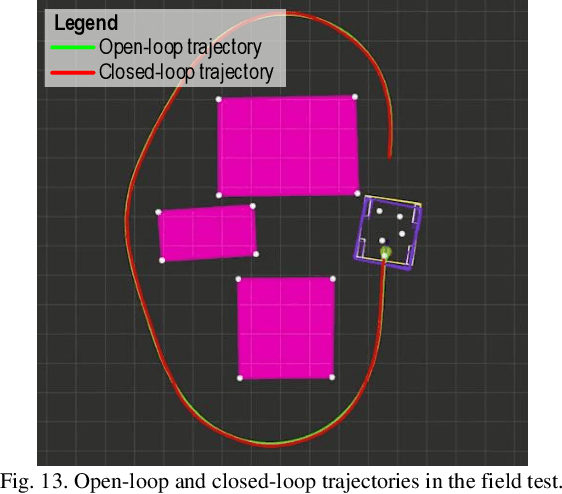
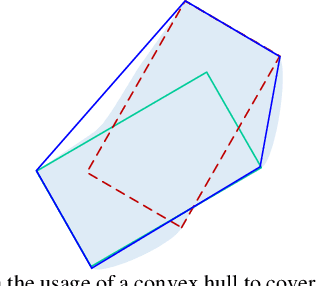
Numerical optimization-based methods are among the prevalent trajectory planners for autonomous driving. In a numerical optimization-based planner, the nominal continuous-time trajectory planning problem is discretized into a nonlinear program (NLP) problem with finite constraints imposed on finite collocation points. However, constraint violations between adjacent collocation points may still occur. This study proposes a safety-guaranteed collision-avoidance modeling method to eliminate the collision risks between adjacent collocation points in using numerical optimization-based trajectory planners. A new concept called embodied box is proposed, which is formed by enlarging the rectangular footprint of the ego vehicle. If one can ensure that the embodied boxes at finite collocation points are collide-free, then the ego vehicle's footprint is collide-free at any a moment between adjacent collocation points. We find that the geometric size of an embodied box is a simple function of vehicle velocity and curvature. The proposed theory lays a foundation for numerical optimization-based trajectory planners in autonomous driving.