 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stop Wasting My Time! Saving Days of ImageNet and BERT Training with Latest Weight Averaging
Oct 06, 2022
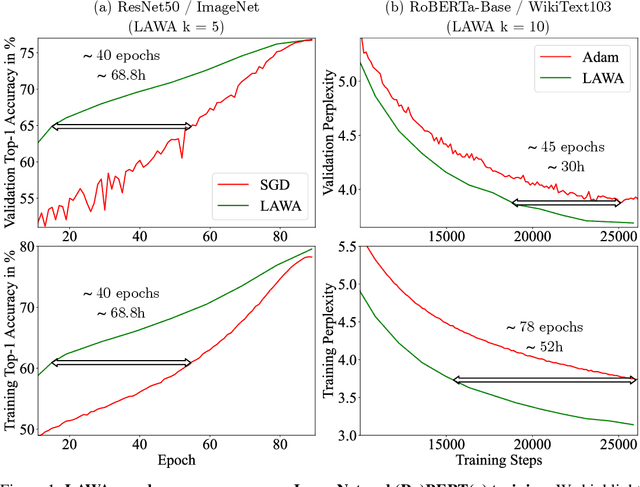
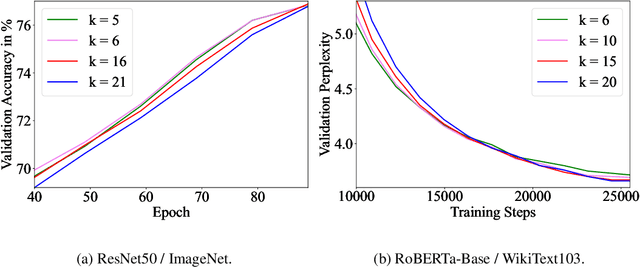
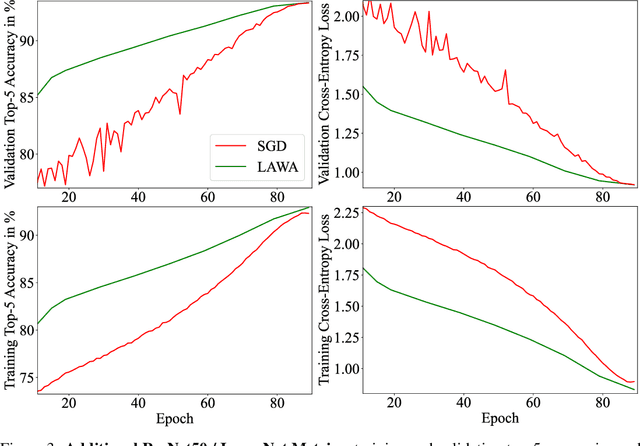
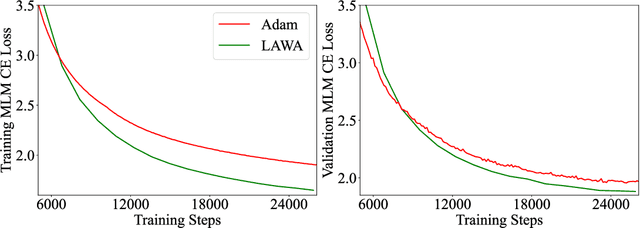
Training vision or language models on large datasets can take days, if not weeks. We show that averaging the weights of the k latest checkpoints, each collected at the end of an epoch, can speed up the training progression in terms of loss and accuracy by dozens of epochs, corresponding to time savings up to ~68 and ~30 GPU hours when training a ResNet50 on ImageNet and RoBERTa-Base model on WikiText-103, respectively. We also provide the code and model checkpoint trajectory to reproduce the results and facilitate research on reusing historical weights for faster convergence.
Conformal Prediction Bands for Two-Dimensional Functional Time Series
Jul 27, 2022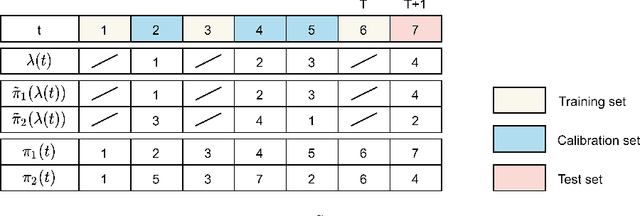
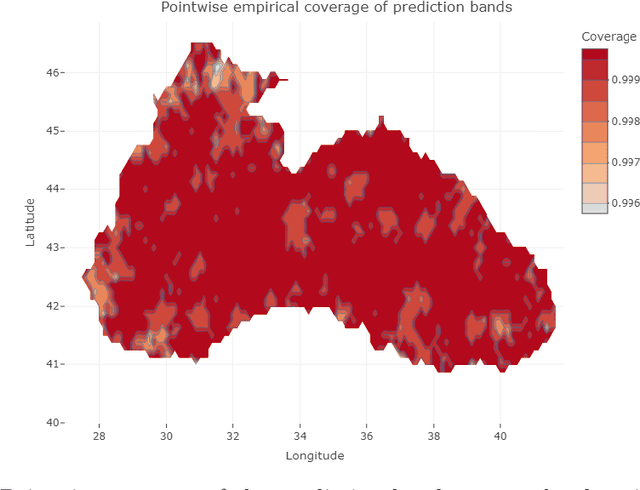
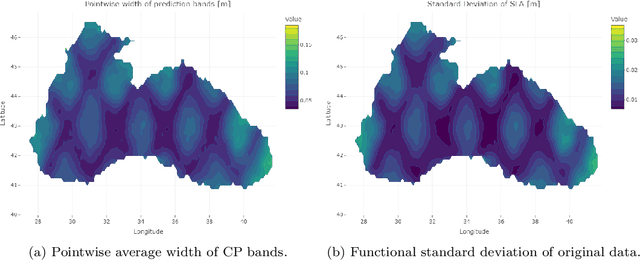
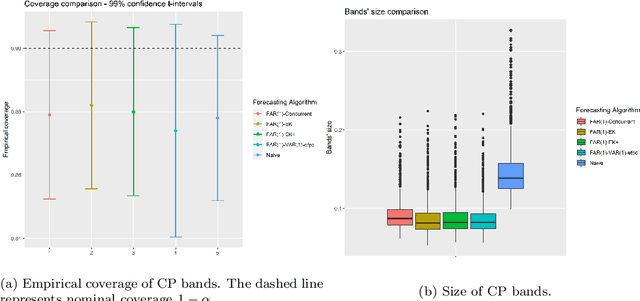
Conformal Prediction (CP) is a versatile nonparametric framework used to quantify uncertainty in prediction problems. In this work, we provide an extension of such method to the case of time series of functions defined on a bivariate domain, by proposing for the first time a distribution-free technique which can be applied to time-evolving surfaces. In order to obtain meaningful and efficient prediction regions, CP must be coupled with an accurate forecasting algorithm, for this reason, we extend the theory of autoregressive processes in Hilbert space in order to allow for functions with a bivariate domain. Given the novelty of the subject, we present estimation techniques for the Functional Autoregressive model (FAR). A simulation study is implemented, in order to investigate how different point predictors affect the resulting prediction bands. Finally, we explore benefits and limits of the proposed approach on a real dataset, collecting daily observations of Sea Level Anomalies of the Black Sea in the last twenty years.
Resource Allocation with Stability Constraints of an Edge-cloud controlled AGV
Jan 23, 2023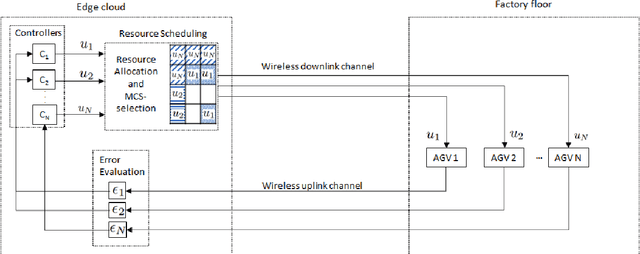
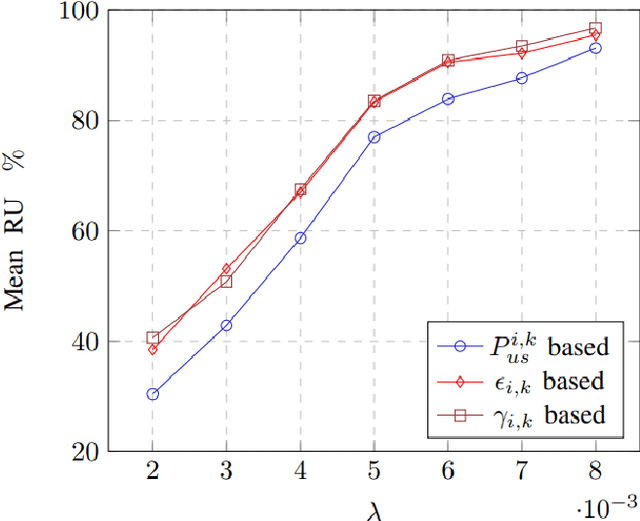
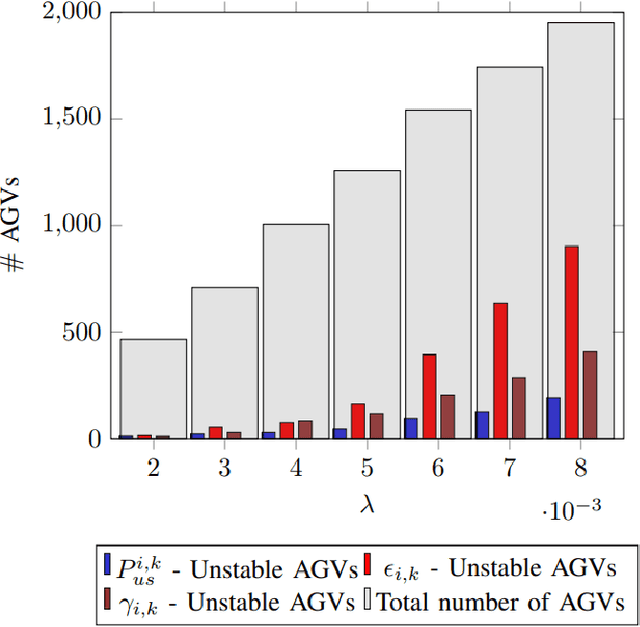
The paper proposes Resource Allocation (RA) schemes for a closed loop feedback control system by analysing the control-communication dependencies. We consider an Automated Guided Vehicle (AGV) that communicates with a controller located in an edge-cloud over a wireless fading channel. The control commands are transmitted to an AGV and the position state is feedback to the controller at every time-instant. A control stability based scheduling metric 'Probability of Instability' is evaluated for the resource allocation. The performance of stability based RA scheme is compared with the maximum SNR based RA scheme and control error first approach in an overloaded and non-overloaded scenario. The RA scheme with the stability constraints significantly reduces the resource utilization and is able to schedule more number of AGVs while maintaining its stability. Moreover, the proposed RA scheme is independent of control state and depends upon consecutive packet errors, the control parameters like sampling time and AGV velocity. Furthermore, we also analyse the impact of RA schemes on the AGV's stability and error performance, and evaluated the number of unstable AGVs.
Feature construction using explanations of individual predictions
Jan 23, 2023
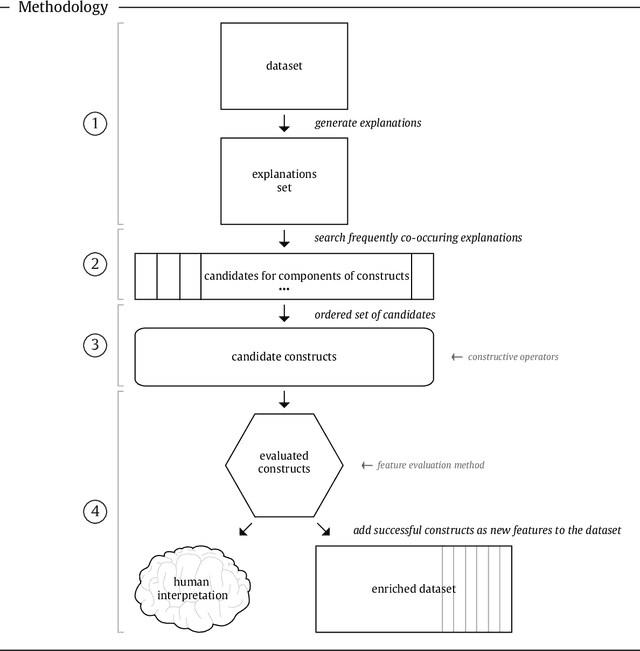
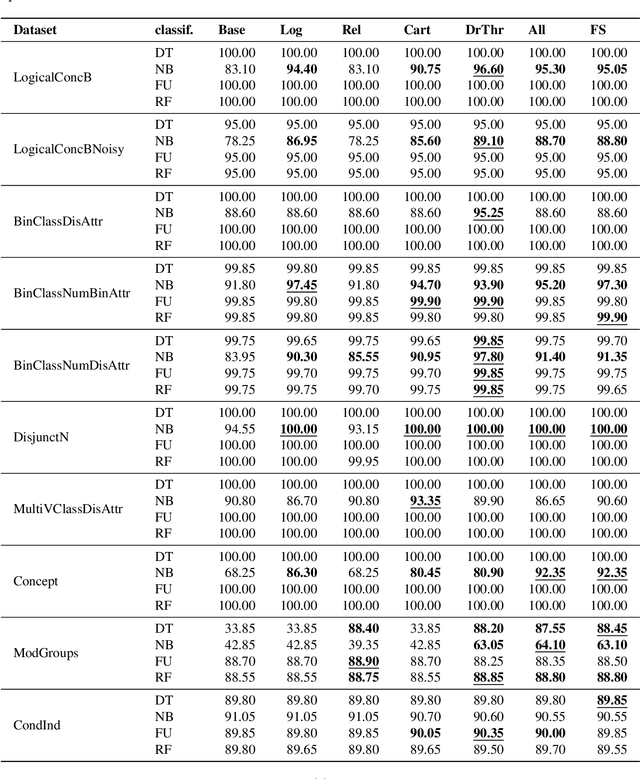
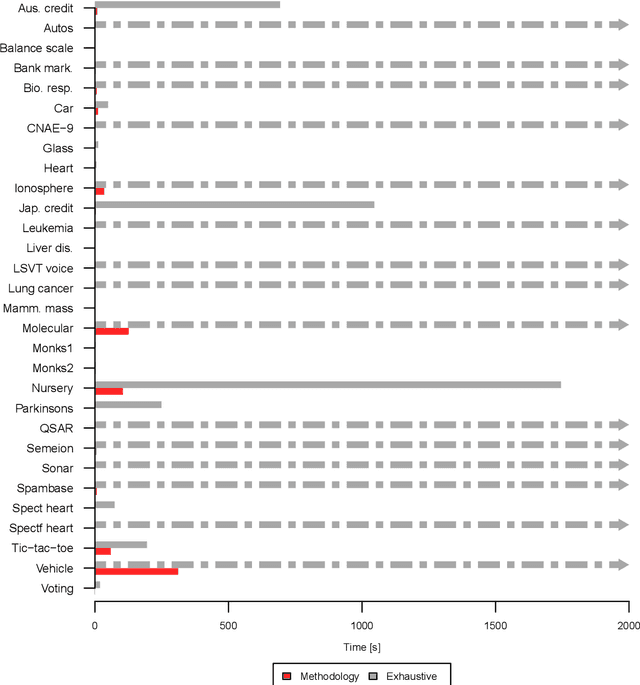
Feature construction can contribute to comprehensibility and performance of machine learning models. Unfortunately, it usually requires exhaustive search in the attribute space or time-consuming human involvement to generate meaningful features. We propose a novel heuristic approach for reducing the search space based on aggregation of instance-based explanations of predictive models. The proposed Explainable Feature Construction (EFC) methodology identifies groups of co-occurring attributes exposed by popular explanation methods, such as IME and SHAP. We empirically show that reducing the search to these groups significantly reduces the time of feature construction using logical, relational, Cartesian, numerical, and threshold num-of-N and X-of-N constructive operators. An analysis on 10 transparent synthetic datasets shows that EFC effectively identifies informative groups of attributes and constructs relevant features. Using 30 real-world classification datasets, we show significant improvements in classification accuracy for several classifiers and demonstrate the feasibility of the proposed feature construction even for large datasets. Finally, EFC generated interpretable features on a real-world problem from the financial industry, which were confirmed by a domain expert.
* 54 pages, 10 figures, 22 tables
Are Labels Needed for Incremental Instance Learning?
Feb 02, 2023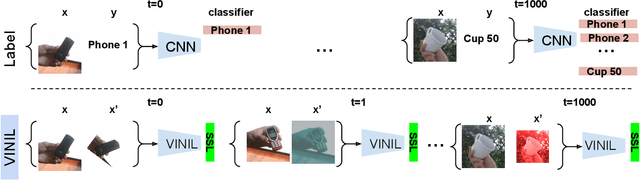
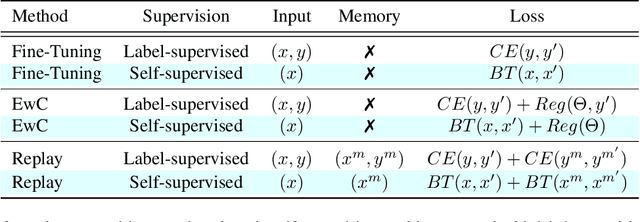
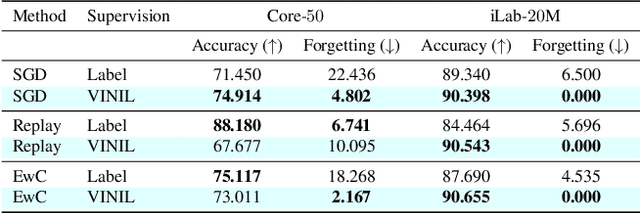
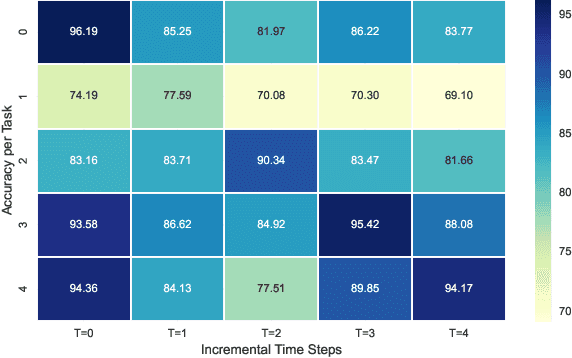
In this paper, we learn to classify visual object instances, incrementally and via self-supervision (self-incremental). Our learner observes a single instance at a time, which is then discarded from the dataset. Incremental instance learning is challenging, since longer learning sessions exacerbate forgetfulness, and labeling instances is cumbersome. We overcome these challenges via three contributions: i. We propose VINIL, a self-incremental learner that can learn object instances sequentially, ii. We equip VINIL with self-supervision to by-pass the need for instance labelling, iii. We compare VINIL to label-supervised variants on two large-scale benchmarks and show that VINIL significantly improves accuracy while reducing forgetfulness.
Who wants what and how: a Mapping Function for Explainable Artificial Intelligence
Feb 07, 2023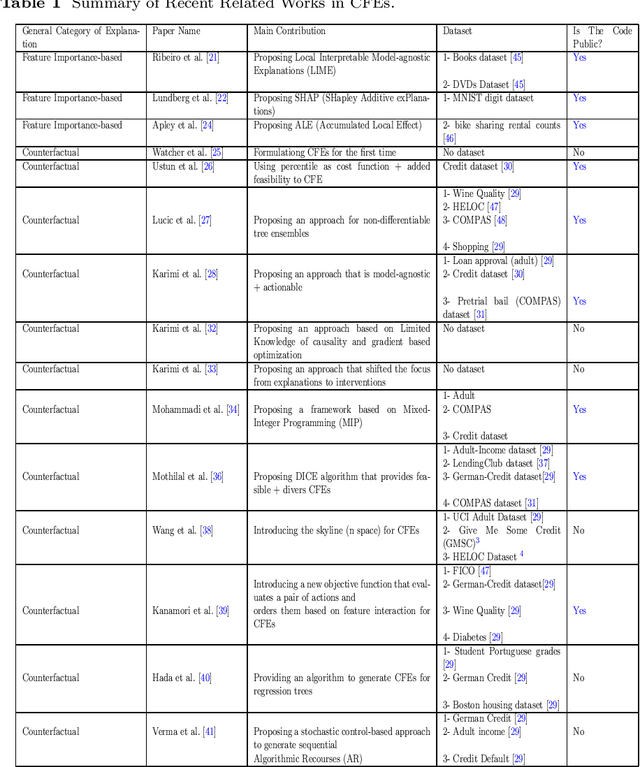
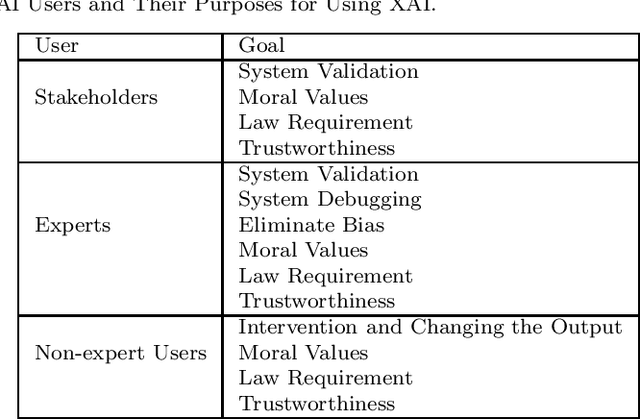
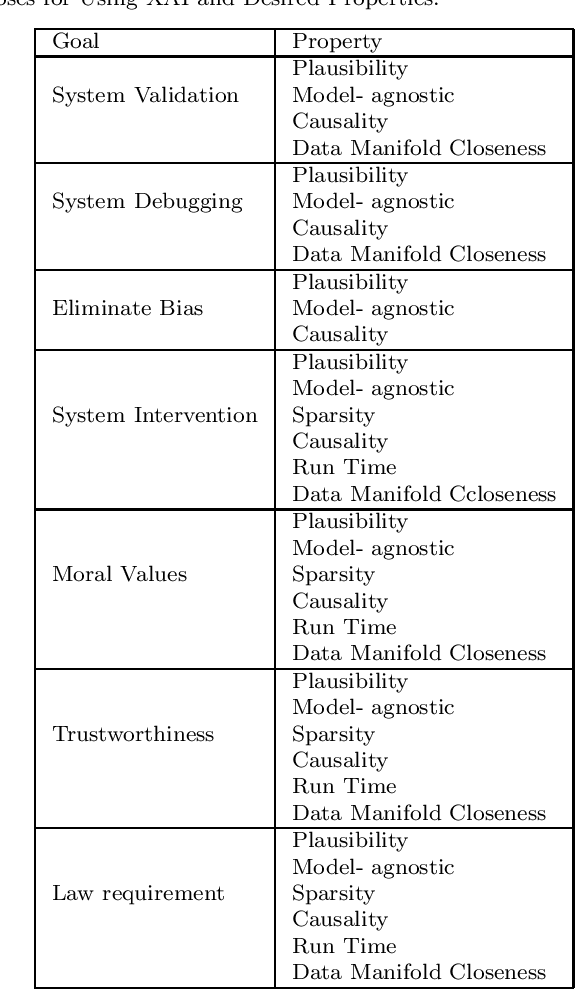
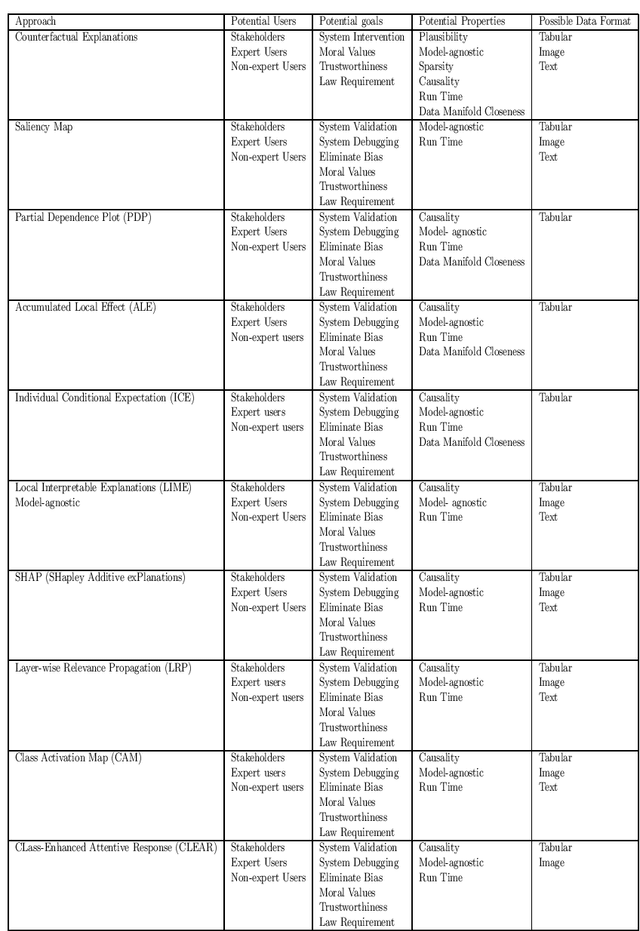
The increasing complexity of AI systems has led to the growth of the field of explainable AI (XAI), which aims to provide explanations and justifications for the outputs of AI algorithms. These methods mainly focus on feature importance and identifying changes that can be made to achieve a desired outcome. Researchers have identified desired properties for XAI methods, such as plausibility, sparsity, causality, low run-time, etc. The objective of this study is to conduct a review of existing XAI research and present a classification of XAI methods. The study also aims to connect XAI users with the appropriate method and relate desired properties to current XAI approaches. The outcome of this study will be a clear strategy that outlines how to choose the right XAI method for a particular goal and user and provide a personalized explanation for users.
SLIM: Sparsified Late Interaction for Multi-Vector Retrieval with Inverted Indexes
Feb 13, 2023
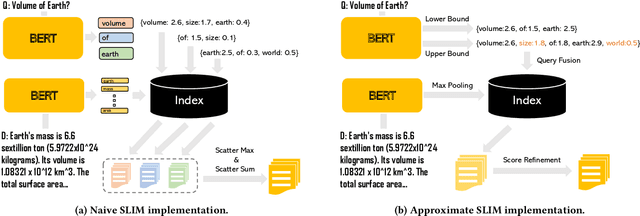
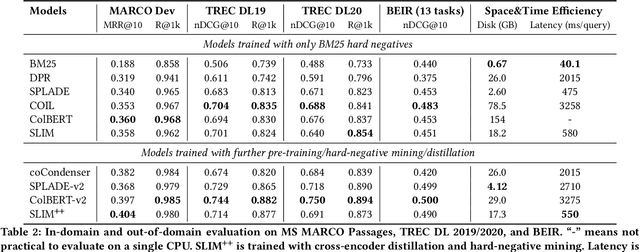
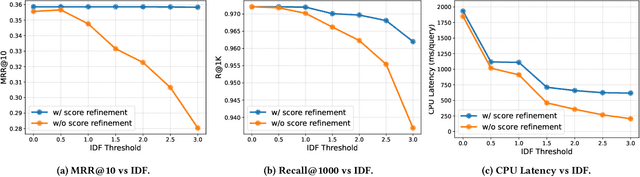
This paper introduces a method called Sparsified Late Interaction for Multi-vector retrieval with inverted indexes (SLIM). Although multi-vector models have demonstrated their effectiveness in various information retrieval tasks, most of their pipelines require custom optimization to be efficient in both time and space. Among them, ColBERT is probably the most established method which is based on the late interaction of contextualized token embeddings of pre-trained language models. Unlike ColBERT where all its token embeddings are low-dimensional and dense, SLIM projects each token embedding into a high-dimensional, sparse lexical space before performing late interaction. In practice, we further propose to approximate SLIM using the lower- and upper-bound of the late interaction to reduce latency and storage. In this way, the sparse outputs can be easily incorporated into an inverted search index and are fully compatible with off-the-shelf search tools such as Pyserini and Elasticsearch. SLIM has competitive accuracy on information retrieval benchmarks such as MS MARCO Passages and BEIR compared to ColBERT while being much smaller and faster on CPUs. Source code and data will be available at https://github.com/castorini/pyserini/blob/master/docs/experiments-slim.md.
A Lifetime Extended Energy Management Strategy for Fuel Cell Hybrid Electric Vehicles via Self-Learning Fuzzy Reinforcement Learning
Feb 13, 2023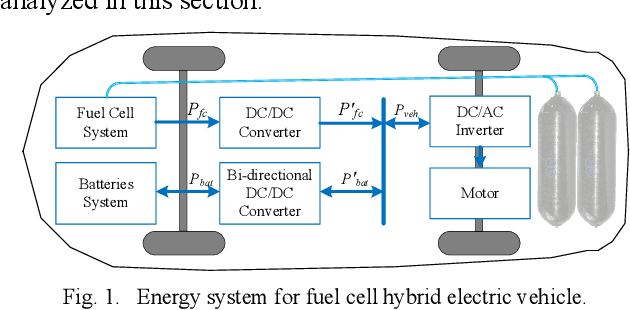
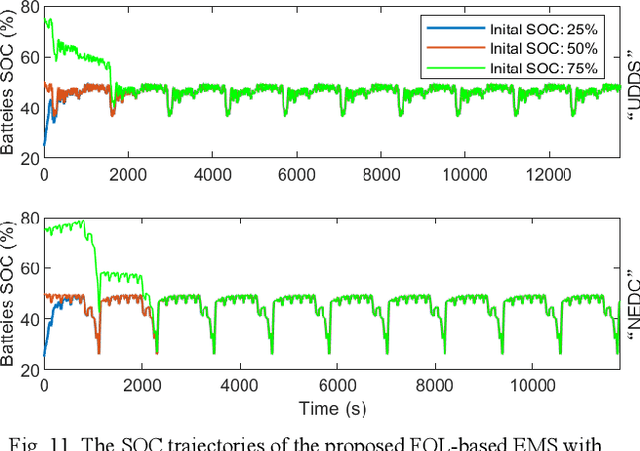

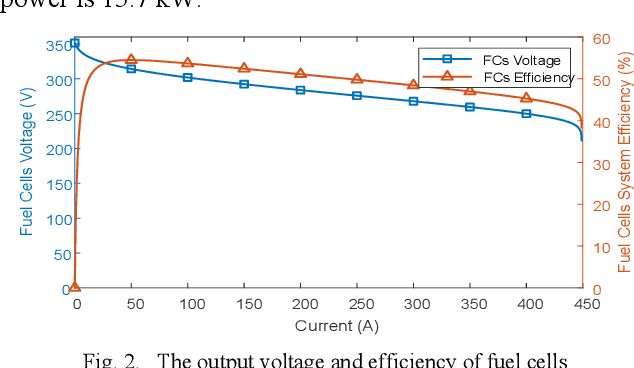
Modeling difficulty, time-varying model, and uncertain external inputs are the main challenges for energy management of fuel cell hybrid electric vehicles. In the paper, a fuzzy reinforcement learning-based energy management strategy for fuel cell hybrid electric vehicles is proposed to reduce fuel consumption, maintain the batteries' long-term operation, and extend the lifetime of the fuel cells system. Fuzzy Q-learning is a model-free reinforcement learning that can learn itself by interacting with the environment, so there is no need for modeling the fuel cells system. In addition, frequent startup of the fuel cells will reduce the remaining useful life of the fuel cells system. The proposed method suppresses frequent fuel cells startup by considering the penalty for the times of fuel cell startups in the reward of reinforcement learning. Moreover, applying fuzzy logic to approximate the value function in Q-Learning can solve continuous state and action space problems. Finally, a python-based training and testing platform verify the effectiveness and self-learning improvement of the proposed method under conditions of initial state change, model change and driving condition change.
TIGER: Temporal Interaction Graph Embedding with Restarts
Feb 13, 2023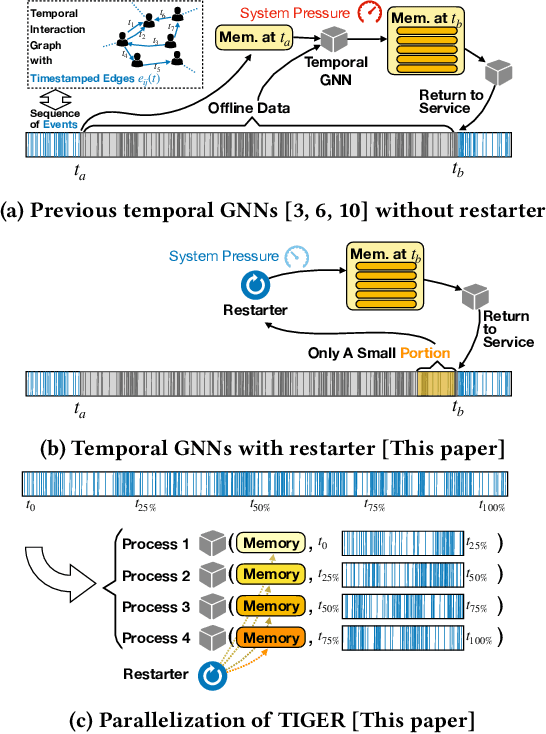
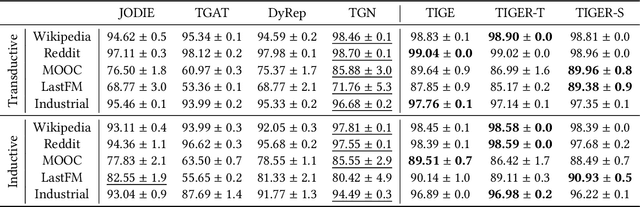
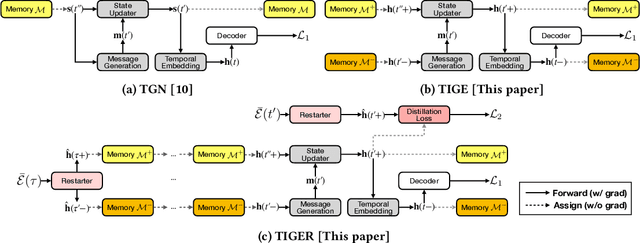

Temporal interaction graphs (TIGs), consisting of sequences of timestamped interaction events, are prevalent in fields like e-commerce and social networks. To better learn dynamic node embeddings that vary over time, researchers have proposed a series of temporal graph neural networks for TIGs. However, due to the entangled temporal and structural dependencies, existing methods have to process the sequence of events chronologically and consecutively to ensure node representations are up-to-date. This prevents existing models from parallelization and reduces their flexibility in industrial applications. To tackle the above challenge, in this paper, we propose TIGER, a TIG embedding model that can restart at any timestamp. We introduce a restarter module that generates surrogate representations acting as the warm initialization of node representations. By restarting from multiple timestamps simultaneously, we divide the sequence into multiple chunks and naturally enable the parallelization of the model. Moreover, in contrast to previous models that utilize a single memory unit, we introduce a dual memory module to better exploit neighborhood information and alleviate the staleness problem. Extensive experiments on four public datasets and one industrial dataset are conducted, and the results verify both the effectiveness and the efficiency of our work.
When Can We Track Significant Preference Shifts in Dueling Bandits?
Feb 13, 2023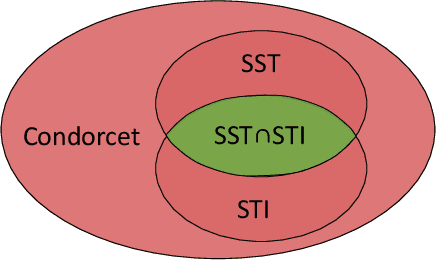
The $K$-armed dueling bandits problem, where the feedback is in the form of noisy pairwise preferences, has been widely studied due its applications in information retrieval, recommendation systems, etc. Motivated by concerns that user preferences/tastes can evolve over time, we consider the problem of dueling bandits with distribution shifts. Specifically, we study the recent notion of significant shifts (Suk and Kpotufe, 2022), and ask whether one can design an adaptive algorithm for the dueling problem with $O(\sqrt{K\tilde{L}T})$ dynamic regret, where $\tilde{L}$ is the (unknown) number of significant shifts in preferences. We show that the answer to this question depends on the properties of underlying preference distributions. Firstly, we give an impossibility result that rules out any algorithm with $O(\sqrt{K\tilde{L}T})$ dynamic regret under the well-studied Condorcet and SST classes of preference distributions. Secondly, we show that $\text{SST} \cap \text{STI}$ is the largest amongst popular classes of preference distributions where it is possible to design such an algorithm. Overall, our results provides an almost complete resolution of the above question for the hierarchy of distribution classes.