 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Are Labels Needed for Incremental Instance Learning?
Feb 02, 2023
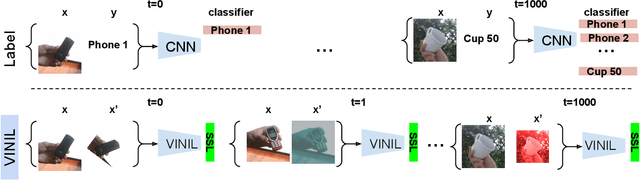
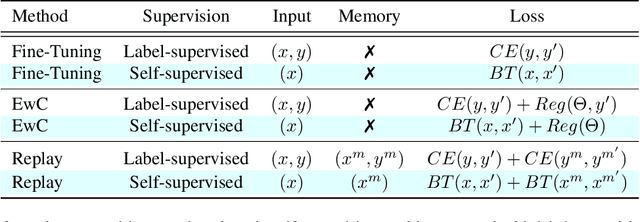
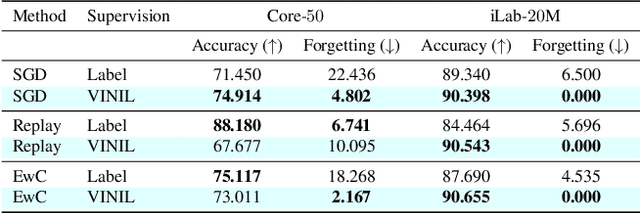
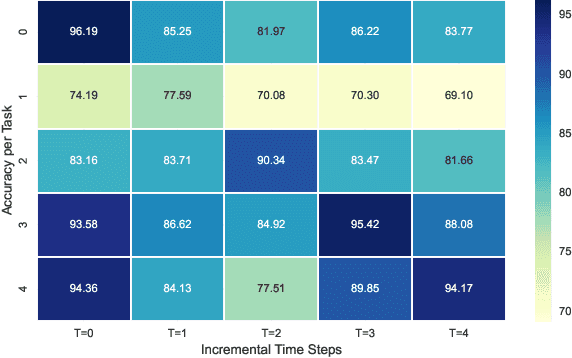
In this paper, we learn to classify visual object instances, incrementally and via self-supervision (self-incremental). Our learner observes a single instance at a time, which is then discarded from the dataset. Incremental instance learning is challenging, since longer learning sessions exacerbate forgetfulness, and labeling instances is cumbersome. We overcome these challenges via three contributions: i. We propose VINIL, a self-incremental learner that can learn object instances sequentially, ii. We equip VINIL with self-supervision to by-pass the need for instance labelling, iii. We compare VINIL to label-supervised variants on two large-scale benchmarks and show that VINIL significantly improves accuracy while reducing forgetfulness.
Connecting the Universe: Challenges, Mitigation, Advances, and Link Engineering
Feb 19, 2023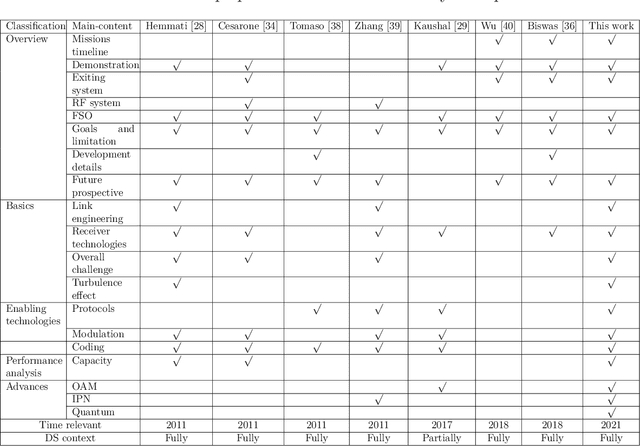
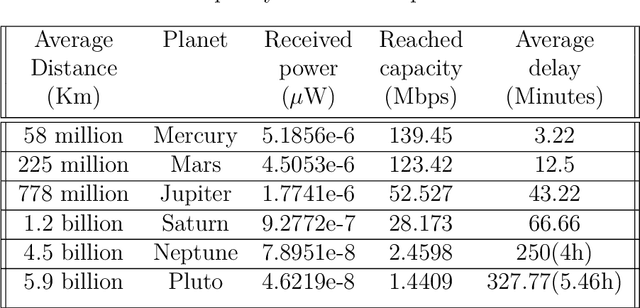
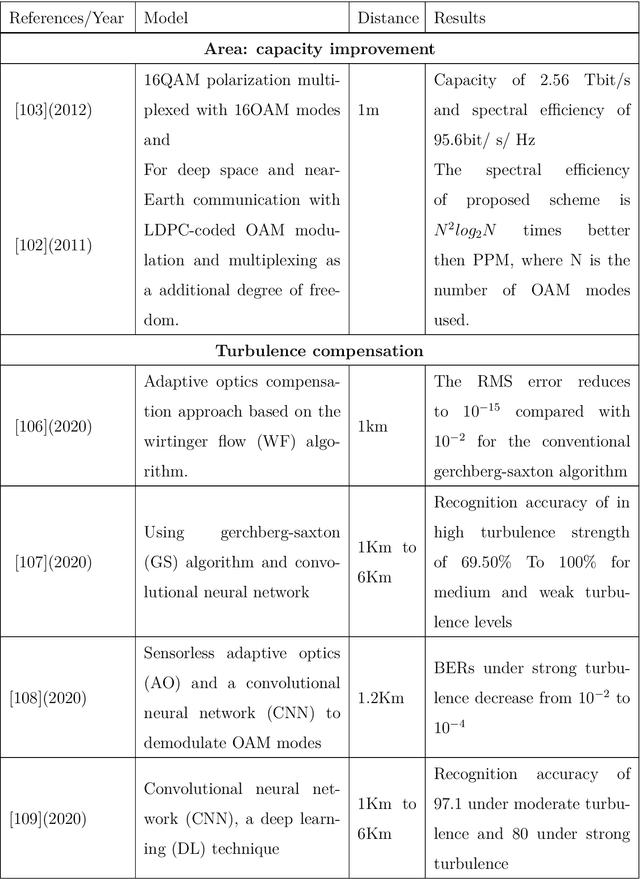
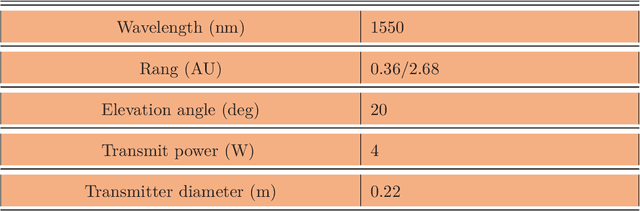
With the large number of deep space (DS) missions anticipated by the end of this decade, reliable-high capacity DS communication systems are needed more than ever. Nevertheless, existing DS communication technologies are far from meeting such a goal. Improving current systems does not only demand a system engineering leadership, but more crucially a well investigation in the potentials of emerging technologies in overcoming the challenges of the unique-ultra long DS communication channel. This project starts with a survey that highlights current technologies, trends, and advancements, investigates potentials, and identify challenges, and in essence, provide perspectives and propose solutions. It focuses on free-space optical (FSO) communication as a potential technology that can overcome the shortcomings of current radio frequency (RF)-based communication systems. To the best of our knowledge, in addition, it provides for the very first time a thoughtful discussion about implementing orbital angular momentum (OAM) for DS, identifies major related challenges, and proposes some novel solutions. Furthermore, we discuss DS modulations and coding schemes, as well as emerging receiver technologies and communication protocols. We also elaborate on how all of these technologies guarantee reliability, improve efficiency, offer capacity boosts, and enhance security in the unique DS environment. In addition to that, an extended study on the design and performance analysis of deep space optical communication (DSOC) is included, with the most suggested modulation for such a link being pulse position modulation (PPM) and a focus on the communication between Earth and the planet Mars, which is an important destination for space exploration.
Evaluating the Effectiveness of Pre-trained Language Models in Predicting the Helpfulness of Online Product Reviews
Feb 19, 2023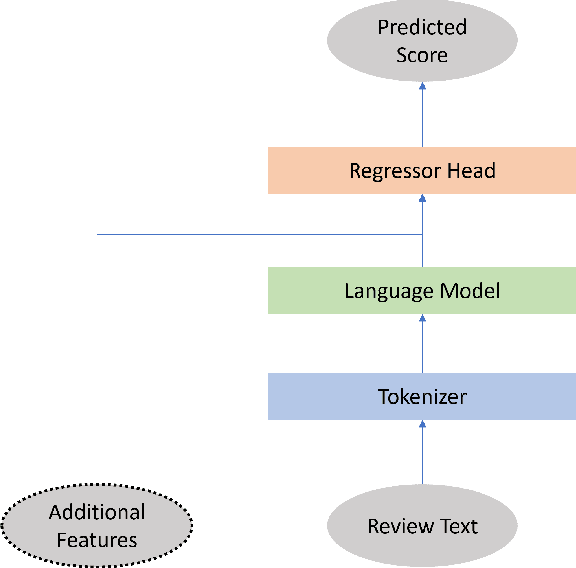
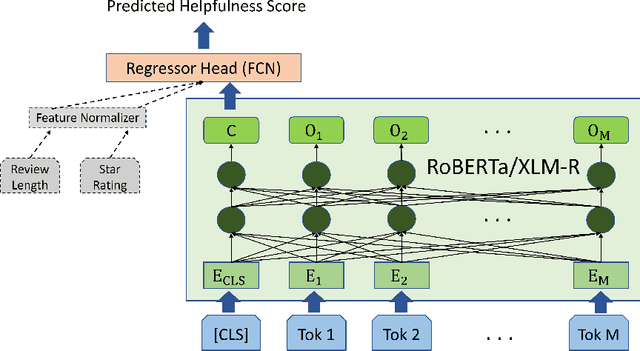

Businesses and customers can gain valuable information from product reviews. The sheer number of reviews often necessitates ranking them based on their potential helpfulness. However, only a few reviews ever receive any helpfulness votes on online marketplaces. Sorting all reviews based on the few existing votes can cause helpful reviews to go unnoticed because of the limited attention span of readers. The problem of review helpfulness prediction is even more important for higher review volumes, and newly written reviews or launched products. In this work we compare the use of RoBERTa and XLM-R language models to predict the helpfulness of online product reviews. The contributions of our work in relation to literature include extensively investigating the efficacy of state-of-the-art language models -- both monolingual and multilingual -- against a robust baseline, taking ranking metrics into account when assessing these approaches, and assessing multilingual models for the first time. We employ the Amazon review dataset for our experiments. According to our study on several product categories, multilingual and monolingual pre-trained language models outperform the baseline that utilizes random forest with handcrafted features as much as 23% in RMSE. Pre-trained language models reduce the need for complex text feature engineering. However, our results suggest that pre-trained multilingual models may not be used for fine-tuning only one language. We assess the performance of language models with and without additional features. Our results show that including additional features like product rating by the reviewer can further help the predictive methods.
CitySpec with Shield: A Secure Intelligent Assistant for Requirement Formalization
Feb 19, 2023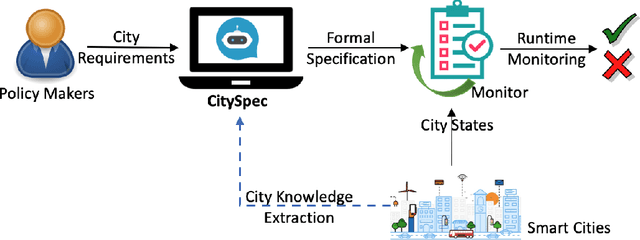

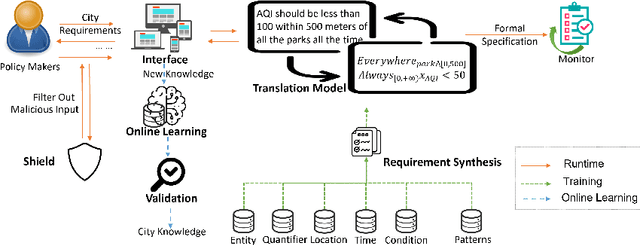
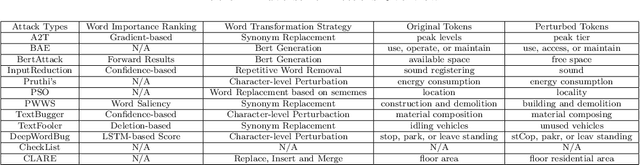
An increasing number of monitoring systems have been developed in smart cities to ensure that the real-time operations of a city satisfy safety and performance requirements. However, many existing city requirements are written in English with missing, inaccurate, or ambiguous information. There is a high demand for assisting city policymakers in converting human-specified requirements to machine-understandable formal specifications for monitoring systems. To tackle this limitation, we build CitySpec, the first intelligent assistant system for requirement specification in smart cities. To create CitySpec, we first collect over 1,500 real-world city requirements across different domains (e.g., transportation and energy) from over 100 cities and extract city-specific knowledge to generate a dataset of city vocabulary with 3,061 words. We also build a translation model and enhance it through requirement synthesis and develop a novel online learning framework with shielded validation. The evaluation results on real-world city requirements show that CitySpec increases the sentence-level accuracy of requirement specification from 59.02% to 86.64%, and has strong adaptability to a new city and a new domain (e.g., the F1 score for requirements in Seattle increases from 77.6% to 93.75% with online learning). After the enhancement from the shield function, CitySpec is now immune to most known textual adversarial inputs (e.g., the attack success rate of DeepWordBug after the shield function is reduced to 0% from 82.73%). We test the CitySpec with 18 participants from different domains. CitySpec shows its strong usability and adaptability to different domains, and also its robustness to malicious inputs.
EHRSQL: A Practical Text-to-SQL Benchmark for Electronic Health Records
Jan 16, 2023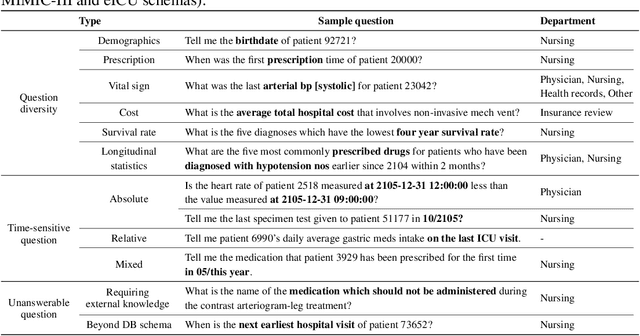
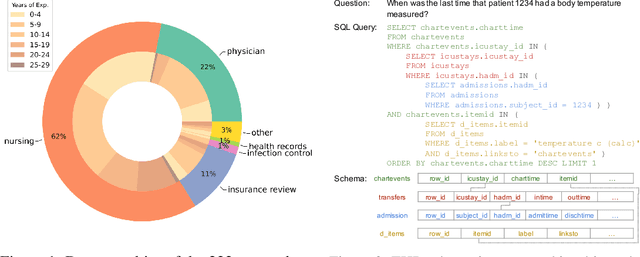

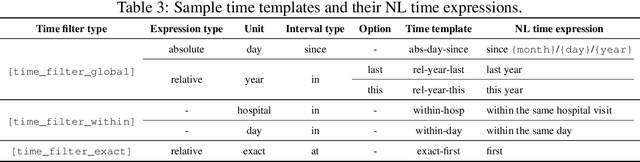
We present a new text-to-SQL dataset for electronic health records (EHRs). The utterances were collected from 222 hospital staff, including physicians, nurses, insurance review and health records teams, and more. To construct the QA dataset on structured EHR data, we conducted a poll at a university hospital and templatized the responses to create seed questions. Then, we manually linked them to two open-source EHR databases, MIMIC-III and eICU, and included them with various time expressions and held-out unanswerable questions in the dataset, which were all collected from the poll. Our dataset poses a unique set of challenges: the model needs to 1) generate SQL queries that reflect a wide range of needs in the hospital, including simple retrieval and complex operations such as calculating survival rate, 2) understand various time expressions to answer time-sensitive questions in healthcare, and 3) distinguish whether a given question is answerable or unanswerable based on the prediction confidence. We believe our dataset, EHRSQL, could serve as a practical benchmark to develop and assess QA models on structured EHR data and take one step further towards bridging the gap between text-to-SQL research and its real-life deployment in healthcare. EHRSQL is available at https://github.com/glee4810/EHRSQL.
Learnable Path in Neural Controlled Differential Equations
Jan 11, 2023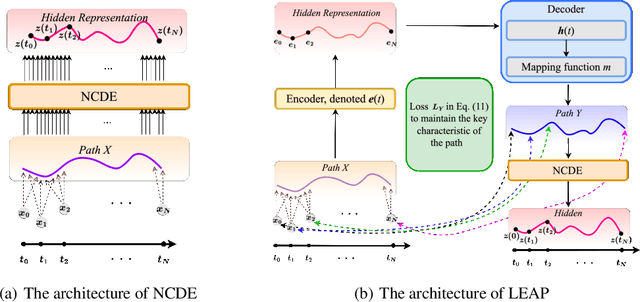

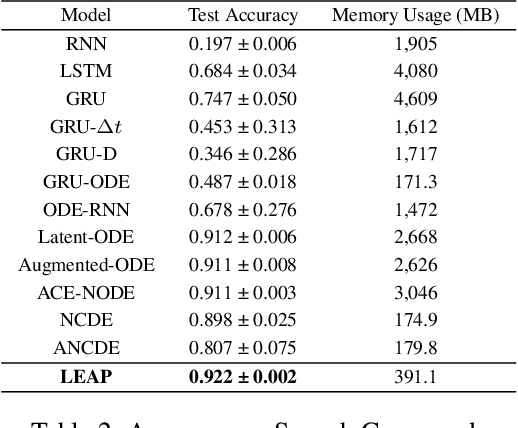
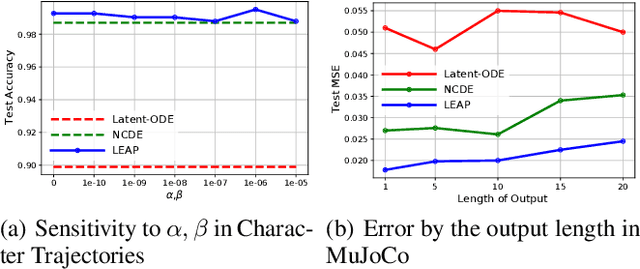
Neural controlled differential equations (NCDEs), which are continuous analogues to recurrent neural networks (RNNs), are a specialized model in (irregular) time-series processing. In comparison with similar models, e.g., neural ordinary differential equations (NODEs), the key distinctive characteristics of NCDEs are i) the adoption of the continuous path created by an interpolation algorithm from each raw discrete time-series sample and ii) the adoption of the Riemann--Stieltjes integral. It is the continuous path which makes NCDEs be analogues to continuous RNNs. However, NCDEs use existing interpolation algorithms to create the path, which is unclear whether they can create an optimal path. To this end, we present a method to generate another latent path (rather than relying on existing interpolation algorithms), which is identical to learning an appropriate interpolation method. We design an encoder-decoder module based on NCDEs and NODEs, and a special training method for it. Our method shows the best performance in both time-series classification and forecasting.
Network Adaptive Federated Learning: Congestion and Lossy Compression
Jan 11, 2023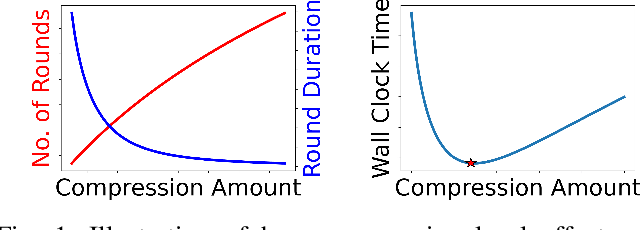
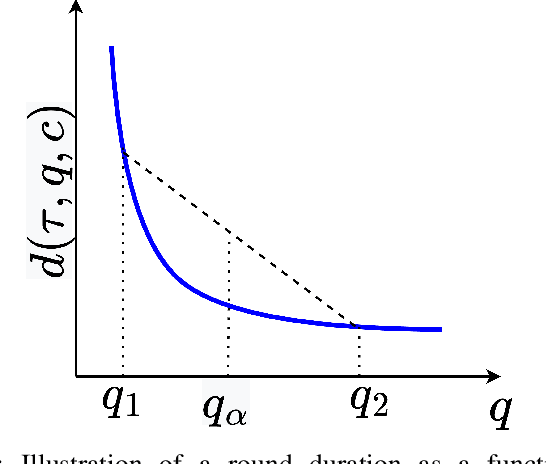
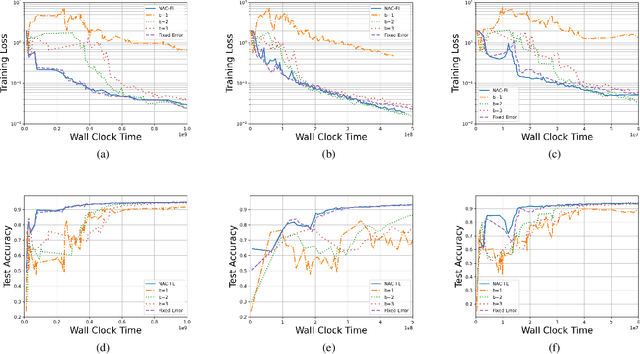
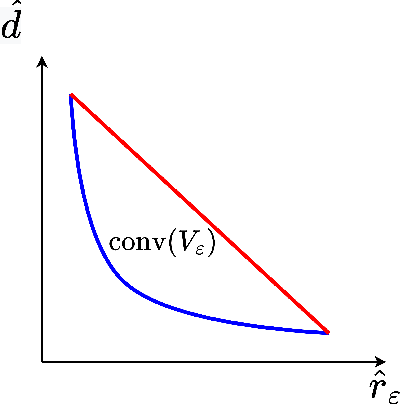
In order to achieve the dual goals of privacy and learning across distributed data, Federated Learning (FL) systems rely on frequent exchanges of large files (model updates) between a set of clients and the server. As such FL systems are exposed to, or indeed the cause of, congestion across a wide set of network resources. Lossy compression can be used to reduce the size of exchanged files and associated delays, at the cost of adding noise to model updates. By judiciously adapting clients' compression to varying network congestion, an FL application can reduce wall clock training time. To that end, we propose a Network Adaptive Compression (NAC-FL) policy, which dynamically varies the client's lossy compression choices to network congestion variations. We prove, under appropriate assumptions, that NAC-FL is asymptotically optimal in terms of directly minimizing the expected wall clock training time. Further, we show via simulation that NAC-FL achieves robust performance improvements with higher gains in settings with positively correlated delays across time.
Nerfstudio: A Modular Framework for Neural Radiance Field Development
Feb 08, 2023
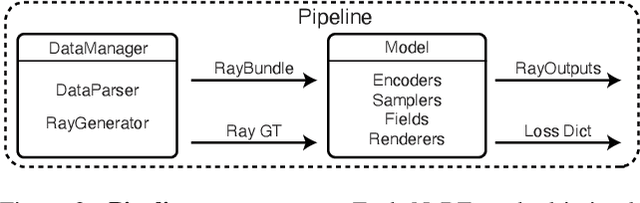
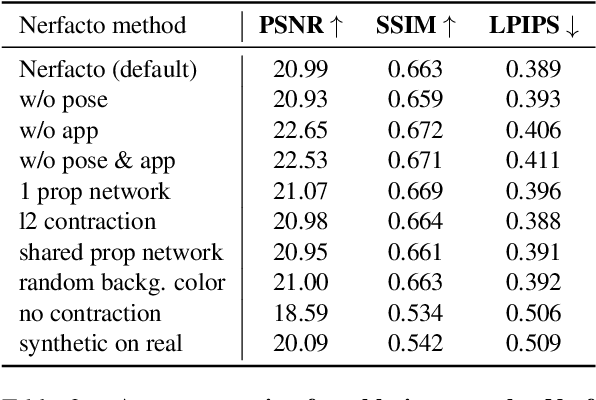

Neural Radiance Fields (NeRF) are a rapidly growing area of research with wide-ranging applications in computer vision, graphics, robotics, and more. In order to streamline the development and deployment of NeRF research, we propose a modular PyTorch framework, Nerfstudio. Our framework includes plug-and-play components for implementing NeRF-based methods, which make it easy for researchers and practitioners to incorporate NeRF into their projects. Additionally, the modular design enables support for extensive real-time visualization tools, streamlined pipelines for importing captured in-the-wild data, and tools for exporting to video, point cloud and mesh representations. The modularity of Nerfstudio enables the development of Nerfacto, our method that combines components from recent papers to achieve a balance between speed and quality, while also remaining flexible to future modifications. To promote community-driven development, all associated code and data are made publicly available with open-source licensing at https://nerf.studio.
An SDE for Modeling SAM: Theory and Insights
Jan 19, 2023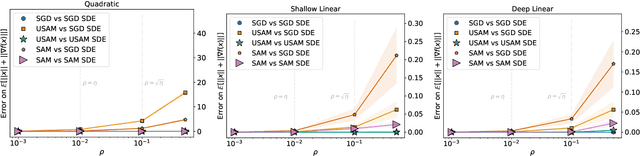
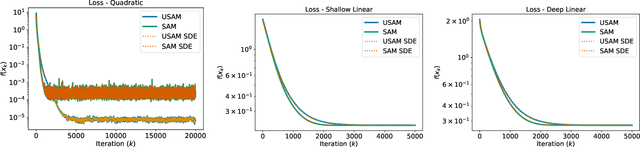

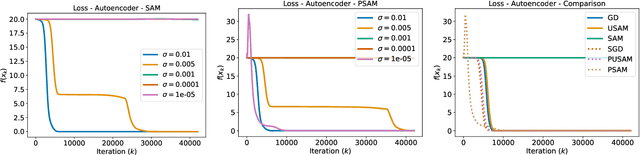
We study the SAM (Sharpness-Aware Minimization) optimizer which has recently attracted a lot of interest due to its increased performance over more classical variants of stochastic gradient descent. Our main contribution is the derivation of continuous-time models (in the form of SDEs) for SAM and its unnormalized variant USAM, both for the full-batch and mini-batch settings. We demonstrate that these SDEs are rigorous approximations of the real discrete-time algorithms (in a weak sense, scaling linearly with the step size). Using these models, we then offer an explanation of why SAM prefers flat minima over sharp ones - by showing that it minimizes an implicitly regularized loss with a Hessian-dependent noise structure. Finally, we prove that perhaps unexpectedly SAM is attracted to saddle points under some realistic conditions. Our theoretical results are supported by detailed experiments.
Sketch Less Face Image Retrieval: A New Challenge
Feb 11, 2023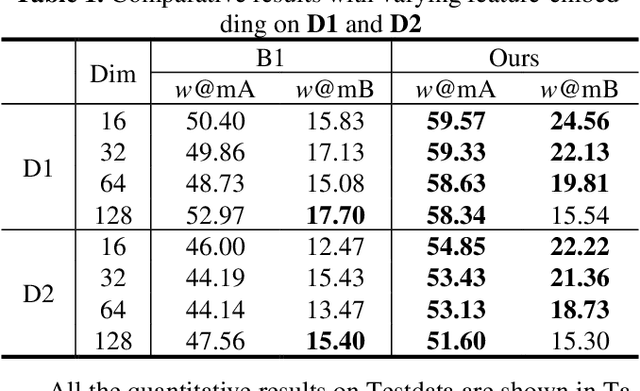
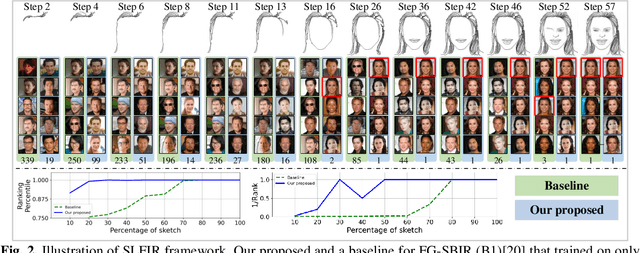
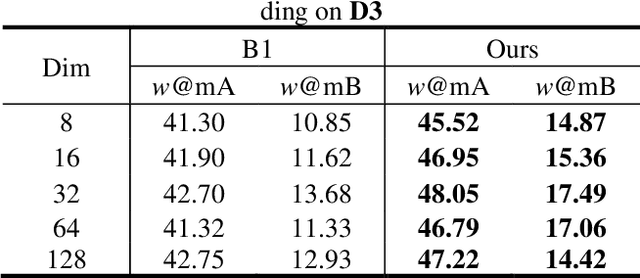
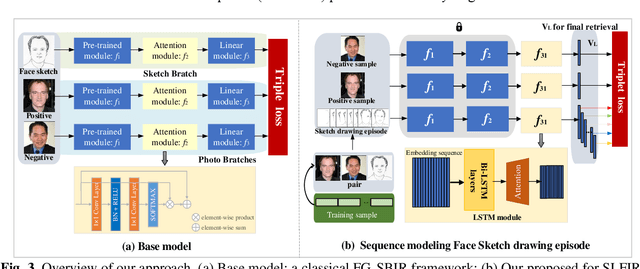
In some specific scenarios, face sketch was used to identify a person. However, drawing a complete face sketch often needs skills and takes time, which hinder its widespread applicability in the practice. In this study, we proposed a new task named sketch less face image retrieval (SLFIR), in which the retrieval was carried out at each stroke and aim to retrieve the target face photo using a partial sketch with as few strokes as possible (see Fig.1). Firstly, we developed a method to generate the data of sketch with drawing process, and opened such dataset; Secondly, we proposed a two-stage method as the baseline for SLFIR that (1) A triplet network, was first adopt to learn the joint embedding space shared between the complete sketch and its target face photo; (2) Regarding the sketch drawing episode as a sequence, we designed a LSTM module to optimize the representation of the incomplete face sketch. Experiments indicate that the new framework can finish the retrieval using a partial or pool drawing sketch.