 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the balance between the training time and interpretability of neural ODE for time series modelling
Jun 07, 2022
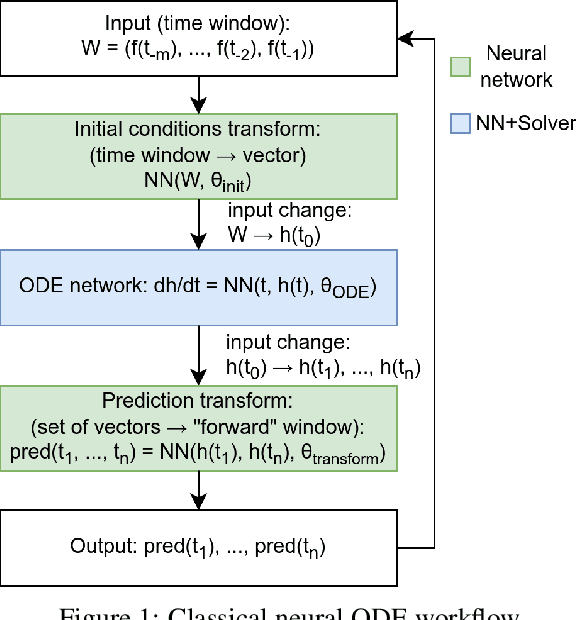
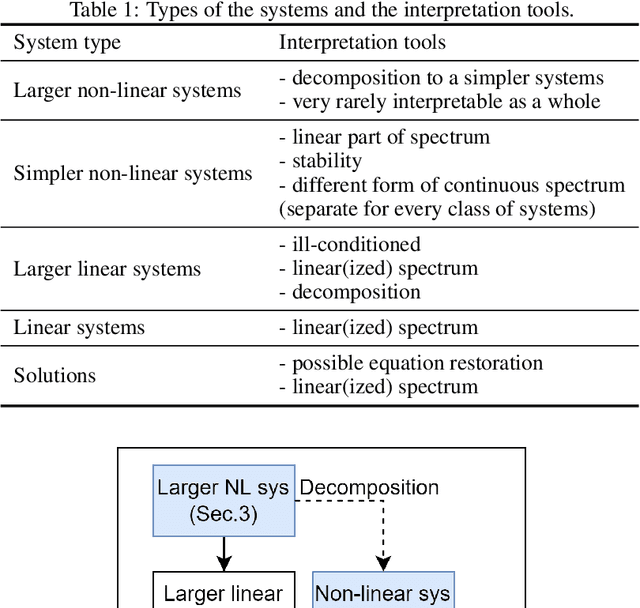
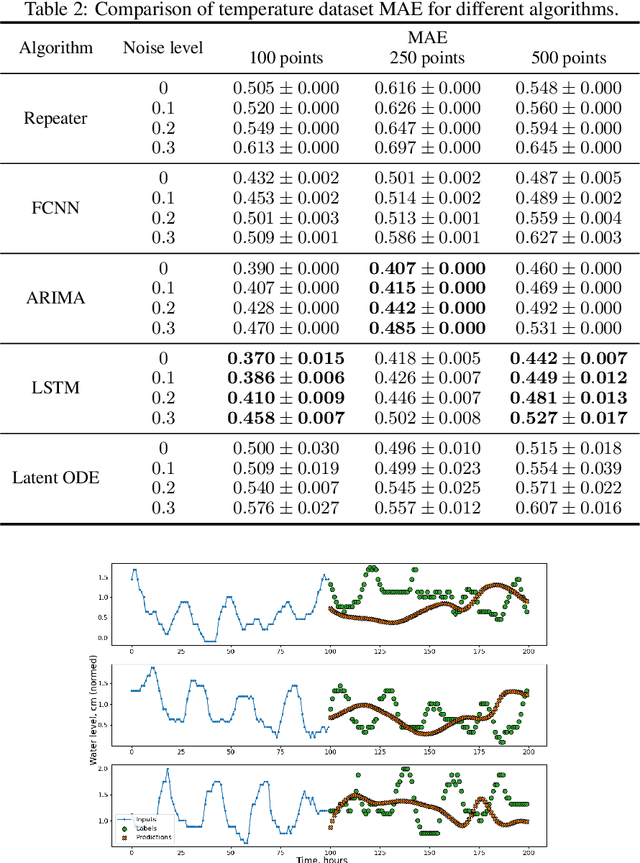
Most machine learning methods are used as a black box for modelling. We may try to extract some knowledge from physics-based training methods, such as neural ODE (ordinary differential equation). Neural ODE has advantages like a possibly higher class of represented functions, the extended interpretability compared to black-box machine learning models, ability to describe both trend and local behaviour. Such advantages are especially critical for time series with complicated trends. However, the known drawback is the high training time compared to the autoregressive models and long-short term memory (LSTM) networks widely used for data-driven time series modelling. Therefore, we should be able to balance interpretability and training time to apply neural ODE in practice. The paper shows that modern neural ODE cannot be reduced to simpler models for time-series modelling applications. The complexity of neural ODE is compared to or exceeds the conventional time-series modelling tools. The only interpretation that could be extracted is the eigenspace of the operator, which is an ill-posed problem for a large system. Spectra could be extracted using different classical analysis methods that do not have the drawback of extended time. Consequently, we reduce the neural ODE to a simpler linear form and propose a new view on time-series modelling using combined neural networks and an ODE system approach.
DAMS-LIO: A Degeneration-Aware and Modular Sensor-Fusion LiDAR-inertial Odometry
Feb 08, 2023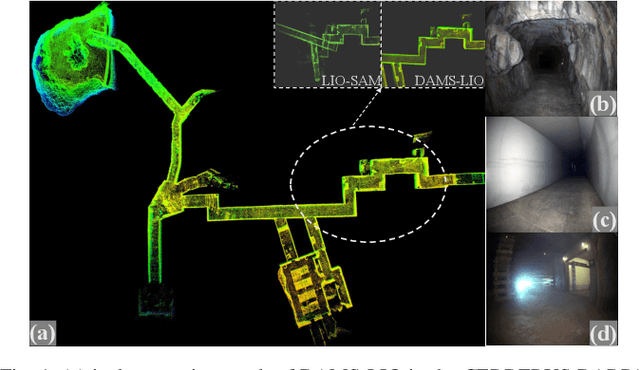
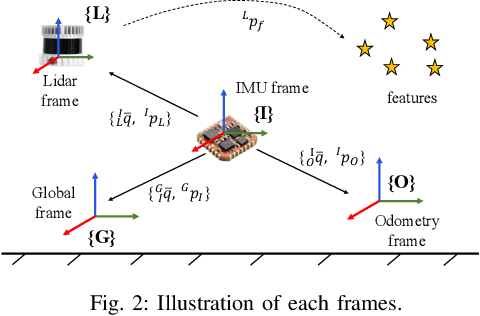
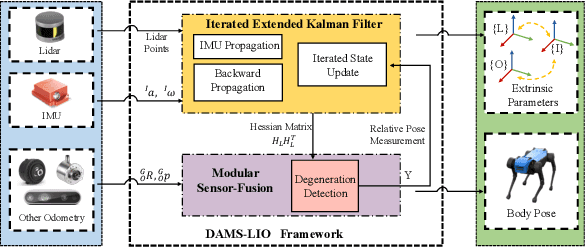
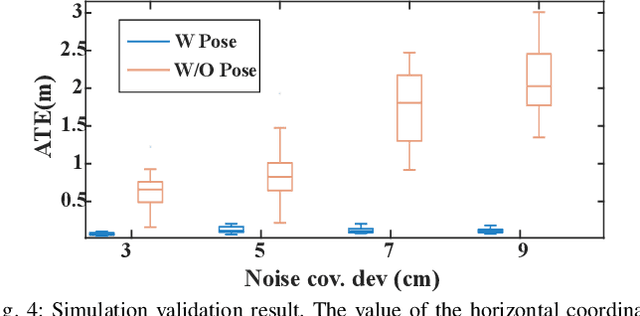
The fusion scheme is crucial to the multi-sensor fusion method that is the promising solution to the state estimation in complex and extreme environments like underground mines and planetary surfaces. In this work, a light-weight iEKF-based LiDAR-inertial odometry system is presented, which utilizes a degeneration-aware and modular sensor-fusion pipeline that takes both LiDAR points and relative pose from another odometry as the measurement in the update process only when degeneration is detected. Both the CRLB theory and simulation test are used to demonstrate the higher accuracy of our method compared to methods using a single observation. Furthermore, the proposed system is evaluated in perceptually challenging datasets against various state-of-the-art sensor-fusion methods. The results show that the proposed system achieves real-time and high estimation accuracy performance despite the challenging environment and poor observations.
Study of Optical Networks, 5G, Artificial Intelligence and Their Applications
Jan 31, 2023This paper discusses the application of artificial intelligence (AI) technology in optical communication networks and 5G. It primarily introduces representative applications of AI technology and potential risks of AI technology failure caused by the openness of optical communication networks, and proposes some coping strategies, mainly including modeling AI systems through modularization and miniaturization, combining with traditional classical network modeling and planning methods, and improving the effectiveness and interpretability of AI technology. At the same time, it proposes response strategies based on network protection for the possible failure and attack of AI technology.
Weakly Supervised Anomaly Detection: A Survey
Feb 09, 2023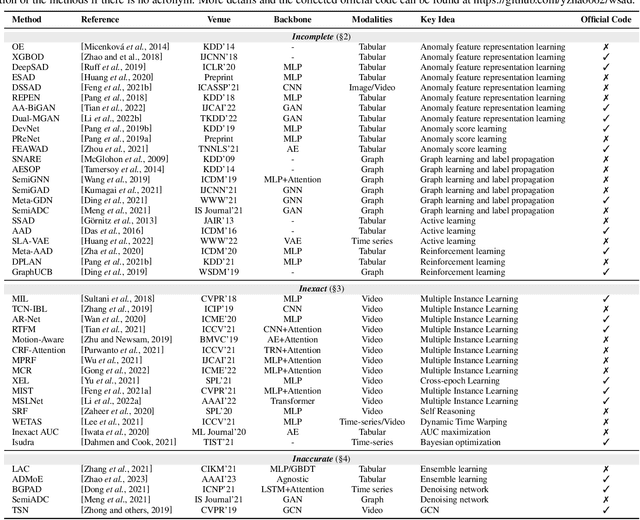
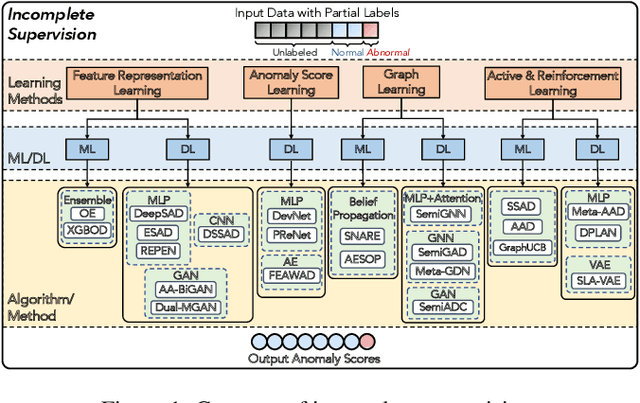
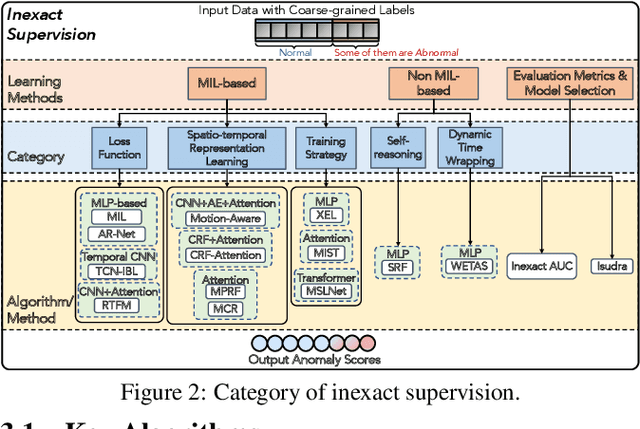
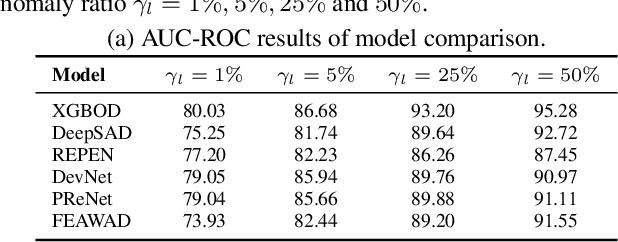
Anomaly detection (AD) is a crucial task in machine learning with various applications, such as detecting emerging diseases, identifying financial frauds, and detecting fake news. However, obtaining complete, accurate, and precise labels for AD tasks can be expensive and challenging due to the cost and difficulties in data annotation. To address this issue, researchers have developed AD methods that can work with incomplete, inexact, and inaccurate supervision, collectively summarized as weakly supervised anomaly detection (WSAD) methods. In this study, we present the first comprehensive survey of WSAD methods by categorizing them into the above three weak supervision settings across four data modalities (i.e., tabular, graph, time-series, and image/video data). For each setting, we provide formal definitions, key algorithms, and potential future directions. To support future research, we conduct experiments on a selected setting and release the source code, along with a collection of WSAD methods and data.
DeepGen: Diverse Search Ad Generation and Real-Time Customization
Aug 06, 2022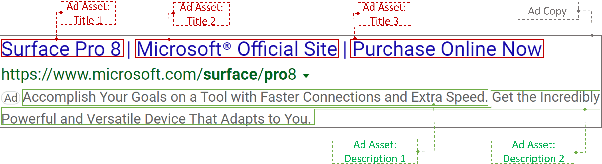

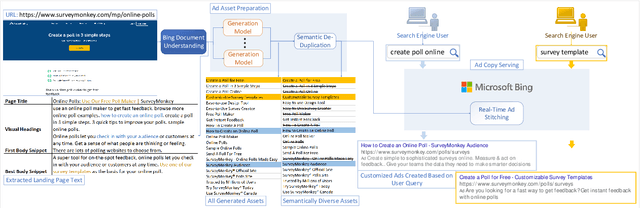
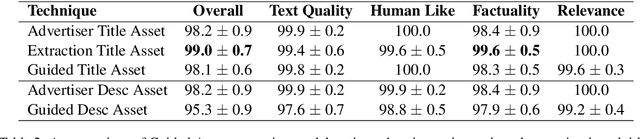
We present DeepGen, a system deployed at web scale for automatically creating sponsored search advertisements (ads) for BingAds customers. We leverage state-of-the-art natural language generation (NLG) models to generate fluent ads from advertiser's web pages in an abstractive fashion and solve practical issues such as factuality and inference speed. In addition, our system creates a customized ad in real-time in response to the user's search query, therefore highlighting different aspects of the same product based on what the user is looking for. To achieve this, our system generates a diverse choice of smaller pieces of the ad ahead of time and, at query time, selects the most relevant ones to be stitched into a complete ad. We improve generation diversity by training a controllable NLG model to generate multiple ads for the same web page highlighting different selling points. Our system design further improves diversity horizontally by first running an ensemble of generation models trained with different objectives and then using a diversity sampling algorithm to pick a diverse subset of generation results for online selection. Experimental results show the effectiveness of our proposed system design. Our system is currently deployed in production, serving ${\sim}4\%$ of global ads served in Bing.
Self-supervised Contrastive Representation Learning for Semi-supervised Time-Series Classification
Aug 13, 2022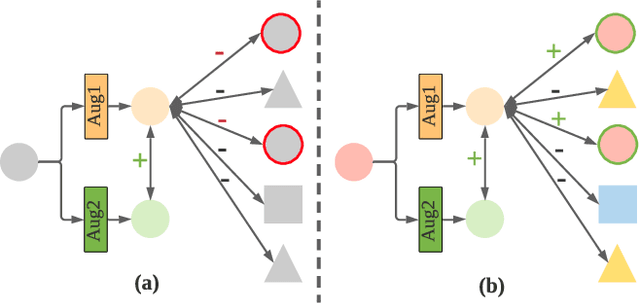
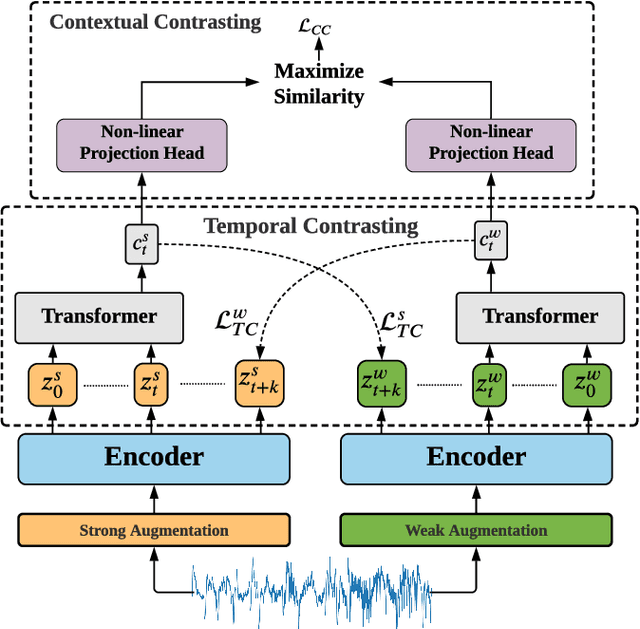
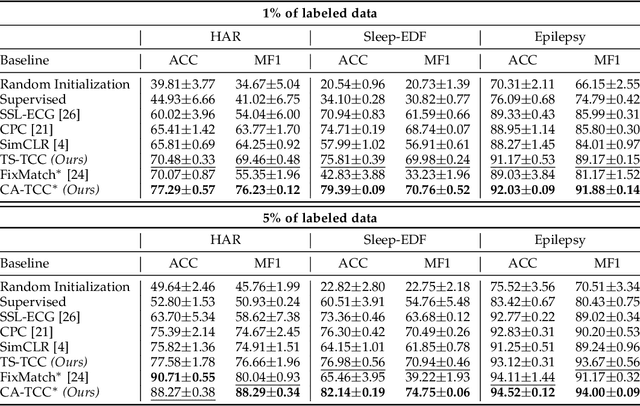
Learning time-series representations when only unlabeled data or few labeled samples are available can be a challenging task. Recently, contrastive self-supervised learning has shown great improvement in extracting useful representations from unlabeled data via contrasting different augmented views of data. In this work, we propose a novel Time-Series representation learning framework via Temporal and Contextual Contrasting (TS-TCC) that learns representations from unlabeled data with contrastive learning. Specifically, we propose time-series specific weak and strong augmentations and use their views to learn robust temporal relations in the proposed temporal contrasting module, besides learning discriminative representations by our proposed contextual contrasting module. Additionally, we conduct a systematic study of time-series data augmentation selection, which is a key part of contrastive learning. We also extend TS-TCC to the semi-supervised learning settings and propose a Class-Aware TS-TCC (CA-TCC) that benefits from the available few labeled data to further improve representations learned by TS-TCC. Specifically, we leverage robust pseudo labels produced by TS-TCC to realize class-aware contrastive loss. Extensive experiments show that the linear evaluation of the features learned by our proposed framework performs comparably with the fully supervised training. Additionally, our framework shows high efficiency in few labeled data and transfer learning scenarios. The code is publicly available at \url{https://github.com/emadeldeen24/TS-TCC}.
Is multi-modal vision supervision beneficial to language?
Feb 10, 2023
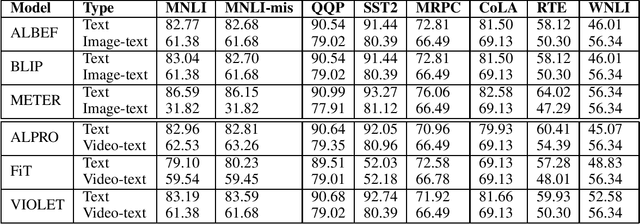
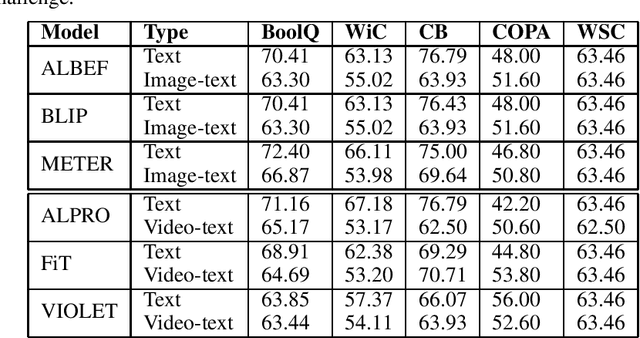
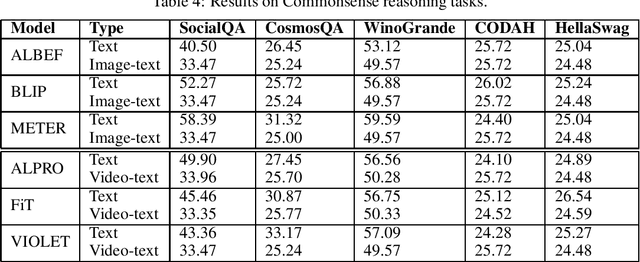
Vision (image and video) - Language (VL) pre-training is the recent popular paradigm that achieved state-of-the-art results on multi-modal tasks like image-retrieval, video-retrieval, visual question answering etc. These models are trained in an unsupervised way and greatly benefit from the complementary modality supervision. In this paper, we explore if the language representations trained using vision supervision perform better than vanilla language representations on Natural Language Understanding and commonsense reasoning benchmarks. We experiment with a diverse set of image-text models such as ALBEF, BLIP, METER and video-text models like ALPRO, Frozen-in-Time (FiT), VIOLET. We compare the performance of language representations of stand-alone text encoders of these models to the language representations of text encoders learnt through vision supervision. Our experiments suggest that vanilla language representations show superior performance on most of the tasks. These results shed light on the current drawbacks of the vision-language models.
Exploiting Graph Structured Cross-Domain Representation for Multi-Domain Recommendation
Feb 12, 2023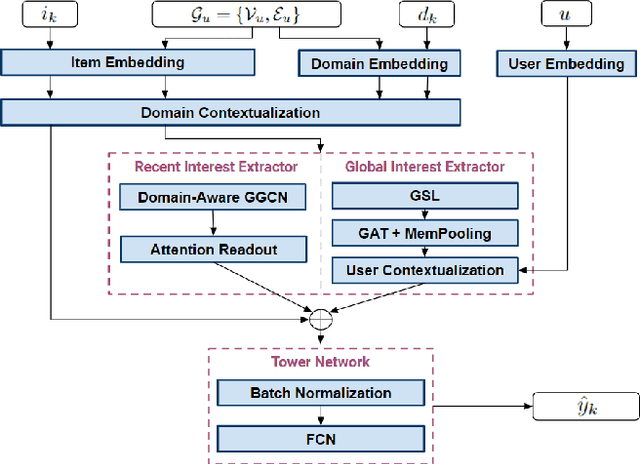
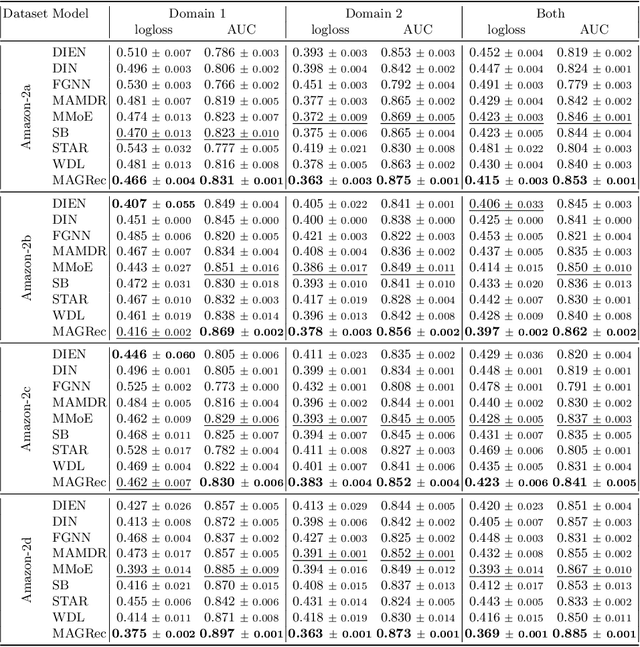
Multi-domain recommender systems benefit from cross-domain representation learning and positive knowledge transfer. Both can be achieved by introducing a specific modeling of input data (i.e. disjoint history) or trying dedicated training regimes. At the same time, treating domains as separate input sources becomes a limitation as it does not capture the interplay that naturally exists between domains. In this work, we efficiently learn multi-domain representation of sequential users' interactions using graph neural networks. We use temporal intra- and inter-domain interactions as contextual information for our method called MAGRec (short for Multi-domAin Graph-based Recommender). To better capture all relations in a multi-domain setting, we learn two graph-based sequential representations simultaneously: domain-guided for recent user interest, and general for long-term interest. This approach helps to mitigate the negative knowledge transfer problem from multiple domains and improve overall representation. We perform experiments on publicly available datasets in different scenarios where MAGRec consistently outperforms state-of-the-art methods. Furthermore, we provide an ablation study and discuss further extensions of our method.
Interpretable Diversity Analysis: Visualizing Feature Representations In Low-Cost Ensembles
Feb 12, 2023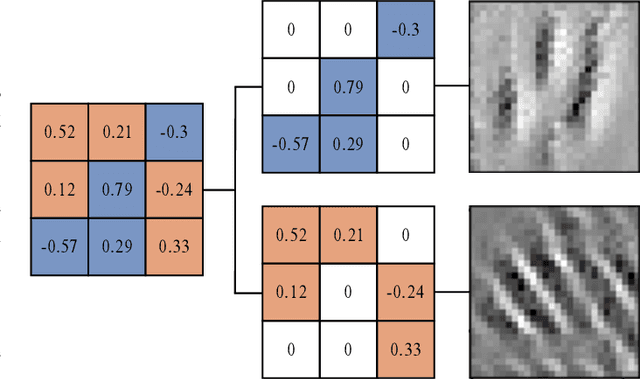
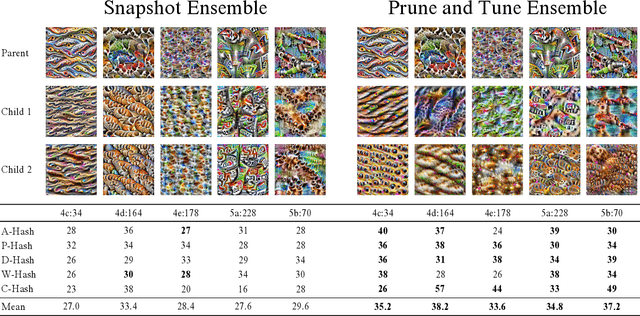


Diversity is an important consideration in the construction of robust neural network ensembles. A collection of well trained models will generalize better if they are diverse in the patterns they respond to and the predictions they make. Diversity is especially important for low-cost ensemble methods because members often share network structure in order to avoid training several independent models from scratch. Diversity is traditionally analyzed by measuring differences between the outputs of models. However, this gives little insight into how knowledge representations differ between ensemble members. This paper introduces several interpretability methods that can be used to qualitatively analyze diversity. We demonstrate these techniques by comparing the diversity of feature representations between child networks using two low-cost ensemble algorithms, Snapshot Ensembles and Prune and Tune Ensembles. We use the same pre-trained parent network as a starting point for both methods which allows us to explore how feature representations evolve over time. This approach to diversity analysis can lead to valuable insights and new perspectives for how we measure and promote diversity in ensemble methods.
FLAC: Practical Failure-Aware Atomic Commit Protocol for Distributed Transactions
Feb 20, 2023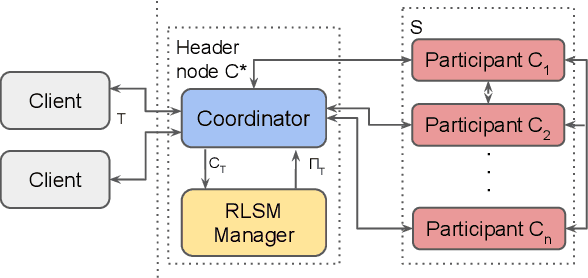

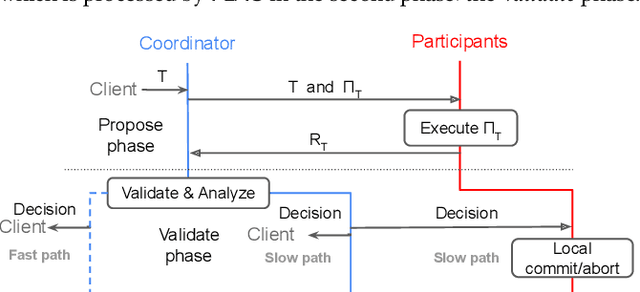

In distributed transaction processing, atomic commit protocol (ACP) is used to ensure database consistency. With the use of commodity compute nodes and networks, failures such as system crashes and network partitioning are common. It is therefore important for ACP to dynamically adapt to the operating condition for efficiency while ensuring the consistency of the database. Existing ACPs often assume stable operating conditions, hence, they are either non-generalizable to different environments or slow in practice. In this paper, we propose a novel and practical ACP, called Failure-Aware Atomic Commit (FLAC). In essence, FLAC includes three sub-protocols, which are specifically designed for three different environments: (i) no failure occurs, (ii) participant nodes might crash but there is no delayed connection, or (iii) both crashed nodes and delayed connection can occur. It models these environments as the failure-free, crash-failure, and network-failure robustness levels. During its operation, FLAC can monitor if any failure occurs and dynamically switch to operate the most suitable sub-protocol, using a robustness level state machine, whose parameters are fine-tuned by reinforcement learning. Consequently, it improves both the response time and throughput, and effectively handles nodes distributed across the Internet where crash and network failures might occur. We implement FLAC in a distributed transactional key-value storage system based on Google Percolator and evaluate its performance with both a micro benchmark and a macro benchmark of real workload. The results show that FLAC achieves up to 2.22x throughput improvement and 2.82x latency speedup, compared to existing ACPs for high-contention workloads.