 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FLAC: Practical Failure-Aware Atomic Commit Protocol for Distributed Transactions
Feb 20, 2023
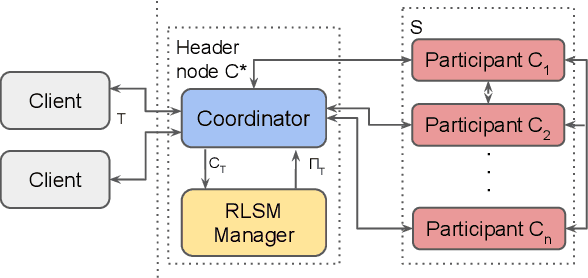

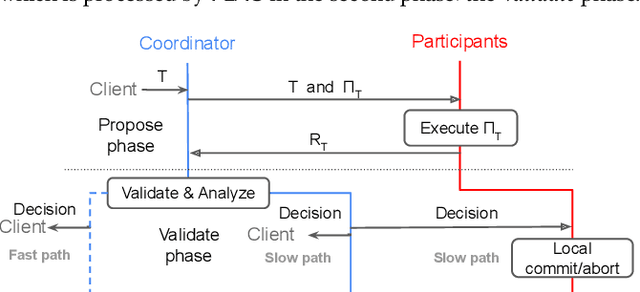

In distributed transaction processing, atomic commit protocol (ACP) is used to ensure database consistency. With the use of commodity compute nodes and networks, failures such as system crashes and network partitioning are common. It is therefore important for ACP to dynamically adapt to the operating condition for efficiency while ensuring the consistency of the database. Existing ACPs often assume stable operating conditions, hence, they are either non-generalizable to different environments or slow in practice. In this paper, we propose a novel and practical ACP, called Failure-Aware Atomic Commit (FLAC). In essence, FLAC includes three sub-protocols, which are specifically designed for three different environments: (i) no failure occurs, (ii) participant nodes might crash but there is no delayed connection, or (iii) both crashed nodes and delayed connection can occur. It models these environments as the failure-free, crash-failure, and network-failure robustness levels. During its operation, FLAC can monitor if any failure occurs and dynamically switch to operate the most suitable sub-protocol, using a robustness level state machine, whose parameters are fine-tuned by reinforcement learning. Consequently, it improves both the response time and throughput, and effectively handles nodes distributed across the Internet where crash and network failures might occur. We implement FLAC in a distributed transactional key-value storage system based on Google Percolator and evaluate its performance with both a micro benchmark and a macro benchmark of real workload. The results show that FLAC achieves up to 2.22x throughput improvement and 2.82x latency speedup, compared to existing ACPs for high-contention workloads.
Lero: A Learning-to-Rank Query Optimizer
Feb 20, 2023
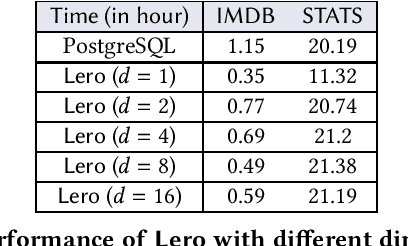
A recent line of works apply machine learning techniques to assist or rebuild cost-based query optimizers in DBMS. While exhibiting superiority in some benchmarks, their deficiencies, e.g., unstable performance, high training cost, and slow model updating, stem from the inherent hardness of predicting the cost or latency of execution plans using machine learning models. In this paper, we introduce a learning-to-rank query optimizer, called Lero, which builds on top of a native query optimizer and continuously learns to improve the optimization performance. The key observation is that the relative order or rank of plans, rather than the exact cost or latency, is sufficient for query optimization. Lero employs a pairwise approach to train a classifier to compare any two plans and tell which one is better. Such a binary classification task is much easier than the regression task to predict the cost or latency, in terms of model efficiency and accuracy. Rather than building a learned optimizer from scratch, Lero is designed to leverage decades of wisdom of databases and improve the native query optimizer. With its non-intrusive design, Lero can be implemented on top of any existing DBMS with minimal integration efforts. We implement Lero and demonstrate its outstanding performance using PostgreSQL. In our experiments, Lero achieves near optimal performance on several benchmarks. It reduces the plan execution time of the native optimizer in PostgreSQL by up to 70% and other learned query optimizers by up to 37%. Meanwhile, Lero continuously learns and automatically adapts to query workloads and changes in data.
Lightweight Neural Architecture Search for Temporal Convolutional Networks at the Edge
Jan 24, 2023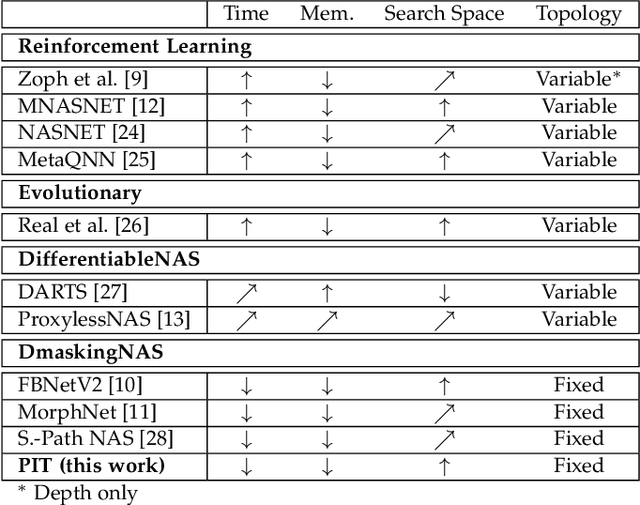
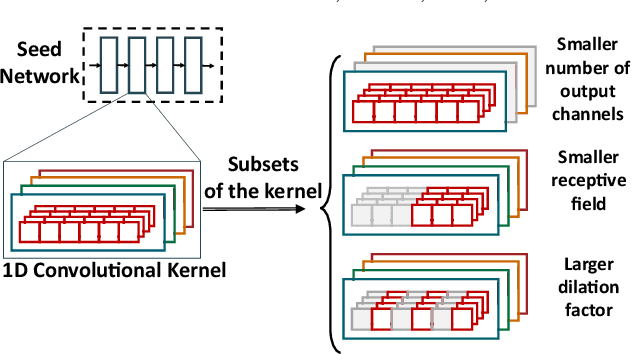
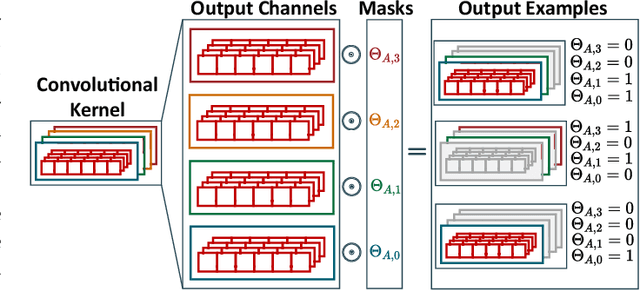
Neural Architecture Search (NAS) is quickly becoming the go-to approach to optimize the structure of Deep Learning (DL) models for complex tasks such as Image Classification or Object Detection. However, many other relevant applications of DL, especially at the edge, are based on time-series processing and require models with unique features, for which NAS is less explored. This work focuses in particular on Temporal Convolutional Networks (TCNs), a convolutional model for time-series processing that has recently emerged as a promising alternative to more complex recurrent architectures. We propose the first NAS tool that explicitly targets the optimization of the most peculiar architectural parameters of TCNs, namely dilation, receptive-field and number of features in each layer. The proposed approach searches for networks that offer good trade-offs between accuracy and number of parameters/operations, enabling an efficient deployment on embedded platforms. We test the proposed NAS on four real-world, edge-relevant tasks, involving audio and bio-signals. Results show that, starting from a single seed network, our method is capable of obtaining a rich collection of Pareto optimal architectures, among which we obtain models with the same accuracy as the seed, and 15.9-152x fewer parameters. Compared to three state-of-the-art NAS tools, ProxylessNAS, MorphNet and FBNetV2, our method explores a larger search space for TCNs (up to 10^12x) and obtains superior solutions, while requiring low GPU memory and search time. We deploy our NAS outputs on two distinct edge devices, the multicore GreenWaves Technology GAP8 IoT processor and the single-core STMicroelectronics STM32H7 microcontroller. With respect to the state-of-the-art hand-tuned models, we reduce latency and energy of up to 5.5x and 3.8x on the two targets respectively, without any accuracy loss.
Dynamic Calibration of Nonlinear Sensors with Time-Drifts and Delays by Bayesian Inference
Aug 29, 2022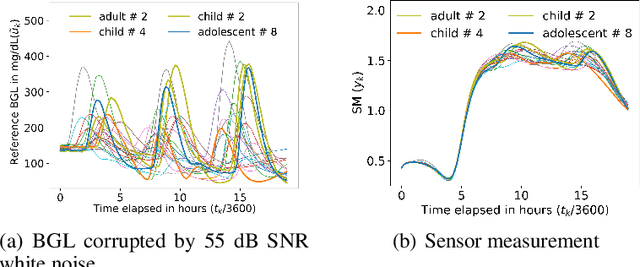
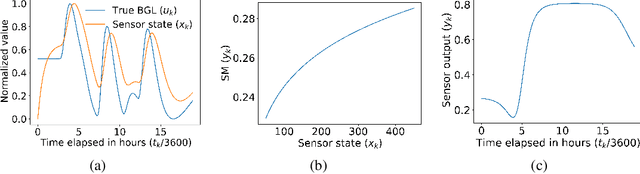
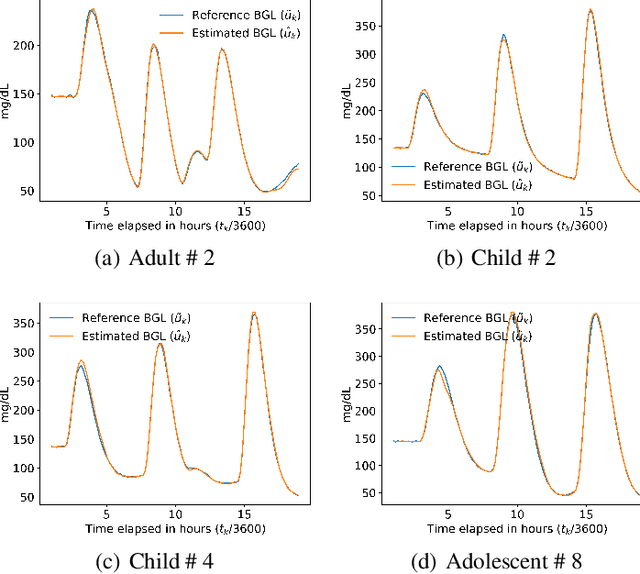
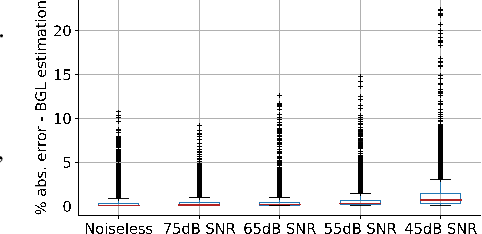
Most sensor calibrations rely on the linearity and steadiness of their response characteristics, but practical sensors are nonlinear, and their response drifts with time, restricting their choices for adoption. To broaden the realm of sensors to allow nonlinearity and time-drift in the underlying dynamics, a Bayesian inference-based nonlinear, non-causal dynamic calibration method is introduced, where the sensed value is estimated as a posterior conditional mean given a finite-length sequence of the sensor measurements and the elapsed time. Additionally, an algorithm is proposed to adjust an already learned calibration map online whenever new data arrives. The effectiveness of the proposed method is validated on continuous-glucose-monitoring (CGM) data from an alive rat equipped with an in-house optical glucose sensor. To allow flexibility in choice, the validation is also performed on a synthetic blood glucose level (BGL) dataset generated using FDA-approved virtual diabetic patient models together with an illustrative CGM sensor model.
Learning and Blending Robot Hugging Behaviors in Time and Space
Dec 03, 2022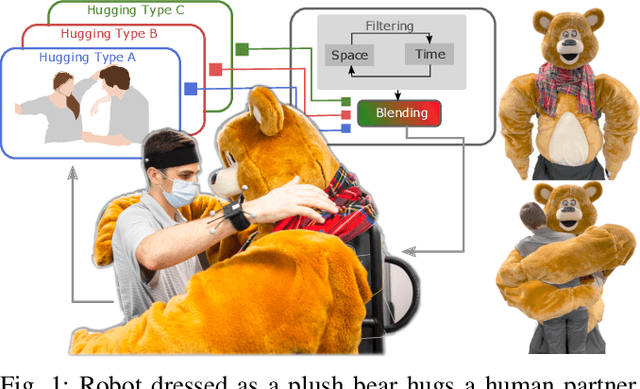
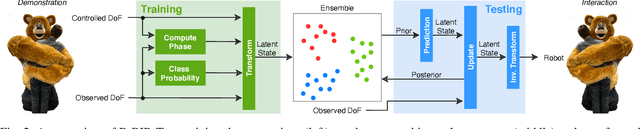

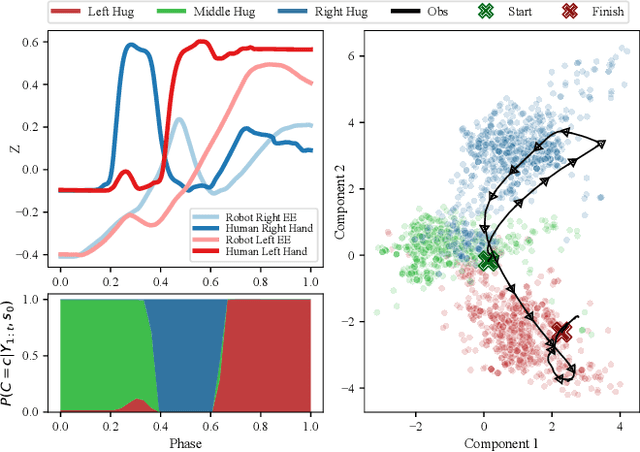
We introduce an imitation learning-based physical human-robot interaction algorithm capable of predicting appropriate robot responses in complex interactions involving a superposition of multiple interactions. Our proposed algorithm, Blending Bayesian Interaction Primitives (B-BIP) allows us to achieve responsive interactions in complex hugging scenarios, capable of reciprocating and adapting to a hugs motion and timing. We show that this algorithm is a generalization of prior work, for which the original formulation reduces to the particular case of a single interaction, and evaluate our method through both an extensive user study and empirical experiments. Our algorithm yields significantly better quantitative prediction error and more-favorable participant responses with respect to accuracy, responsiveness, and timing, when compared to existing state-of-the-art methods.
Weakly Supervised Anomaly Detection: A Survey
Feb 09, 2023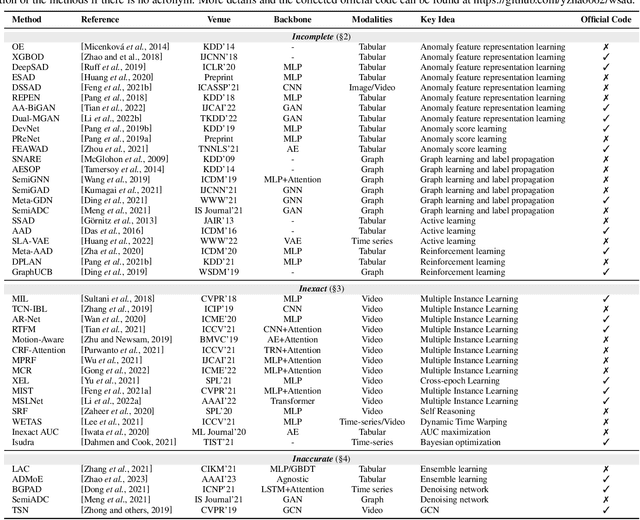
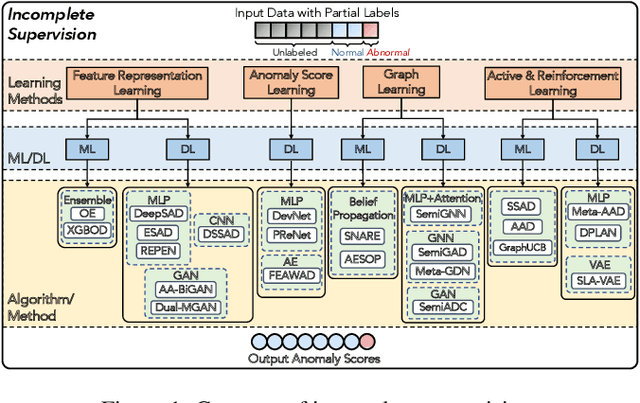
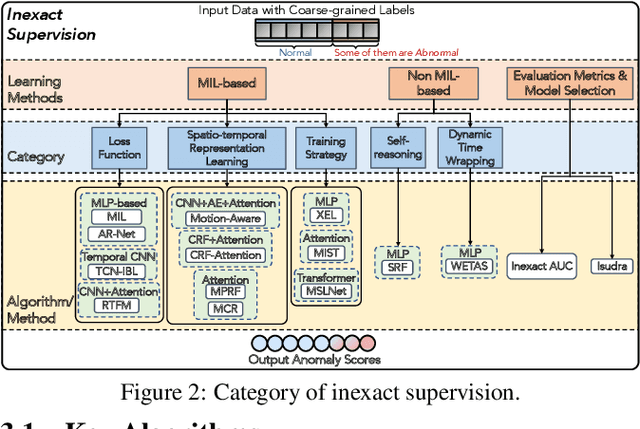
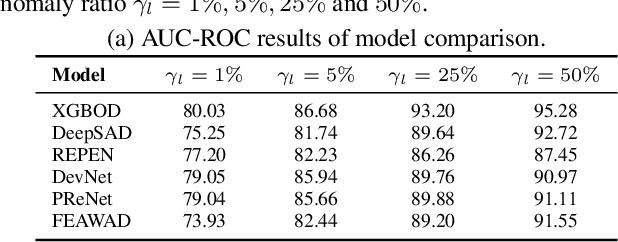
Anomaly detection (AD) is a crucial task in machine learning with various applications, such as detecting emerging diseases, identifying financial frauds, and detecting fake news. However, obtaining complete, accurate, and precise labels for AD tasks can be expensive and challenging due to the cost and difficulties in data annotation. To address this issue, researchers have developed AD methods that can work with incomplete, inexact, and inaccurate supervision, collectively summarized as weakly supervised anomaly detection (WSAD) methods. In this study, we present the first comprehensive survey of WSAD methods by categorizing them into the above three weak supervision settings across four data modalities (i.e., tabular, graph, time-series, and image/video data). For each setting, we provide formal definitions, key algorithms, and potential future directions. To support future research, we conduct experiments on a selected setting and release the source code, along with a collection of WSAD methods and data.
Perceptual evaluation of listener envelopment using spatial granular synthesis
Jan 24, 2023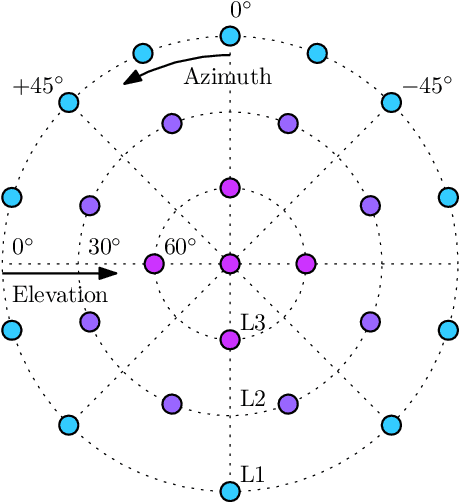
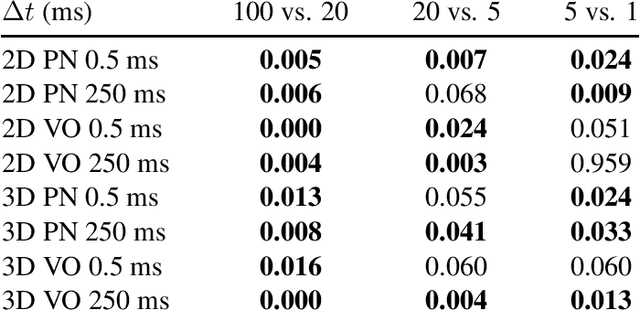
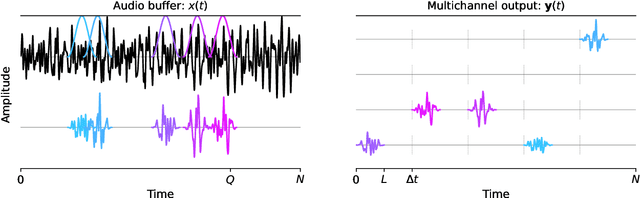
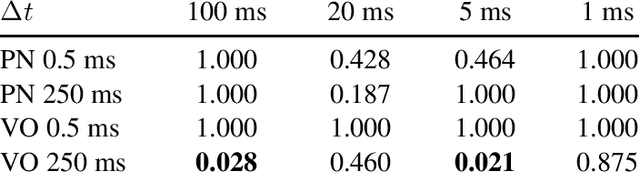
Listener envelopment refers to the sensation of being surrounded by sound, either by multiple direct sound events or by a diffuse reverberant sound field. More recently, a specific attribute for the sensation of being covered by sound from elevated directions has been proposed by Sazdov et al. and was termed listener engulfment. This contribution investigates the effect of the temporal and directional density of sound events on listener envelopment and engulfment. A spatial granular synthesis technique is used to precisely control the temporal and directional density of sound events. Experimental results indicate that a directionally uniform distribution of sound events at time intervals $\Delta t < 20$ milliseconds is required to elicit a sensation of diffuse envelopment, whereas longer time intervals lead to localized auditory events. It shows that elevated loudspeaker layers do not increase envelopment, but contribute specifically to listener engulfment. Lowpass-filtered stimuli increase envelopment, but lead to a decreased control over engulfment. The results can be exploited in the technical design and creative application of spatial sound synthesis and reverberation algorithms.
Exploiting Graph Structured Cross-Domain Representation for Multi-Domain Recommendation
Feb 12, 2023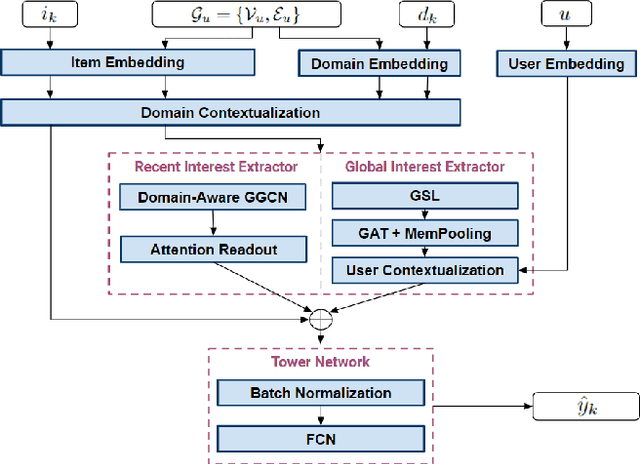
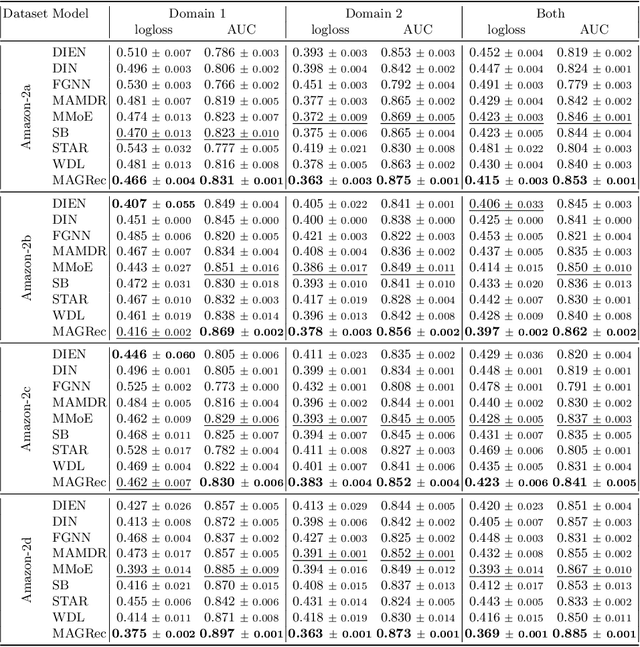
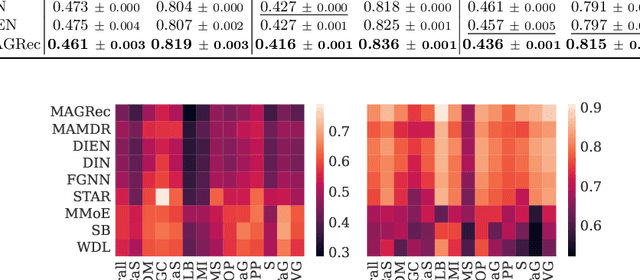
Multi-domain recommender systems benefit from cross-domain representation learning and positive knowledge transfer. Both can be achieved by introducing a specific modeling of input data (i.e. disjoint history) or trying dedicated training regimes. At the same time, treating domains as separate input sources becomes a limitation as it does not capture the interplay that naturally exists between domains. In this work, we efficiently learn multi-domain representation of sequential users' interactions using graph neural networks. We use temporal intra- and inter-domain interactions as contextual information for our method called MAGRec (short for Multi-domAin Graph-based Recommender). To better capture all relations in a multi-domain setting, we learn two graph-based sequential representations simultaneously: domain-guided for recent user interest, and general for long-term interest. This approach helps to mitigate the negative knowledge transfer problem from multiple domains and improve overall representation. We perform experiments on publicly available datasets in different scenarios where MAGRec consistently outperforms state-of-the-art methods. Furthermore, we provide an ablation study and discuss further extensions of our method.
Interpretable Diversity Analysis: Visualizing Feature Representations In Low-Cost Ensembles
Feb 12, 2023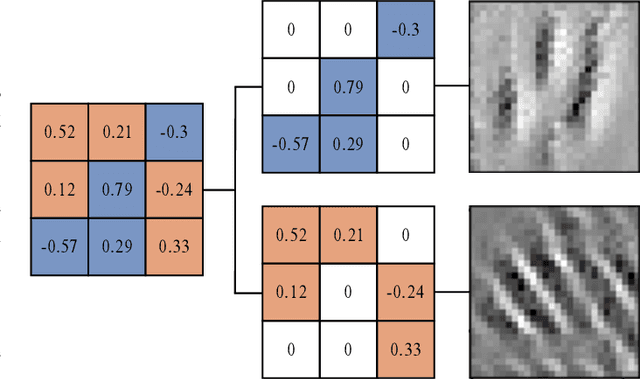
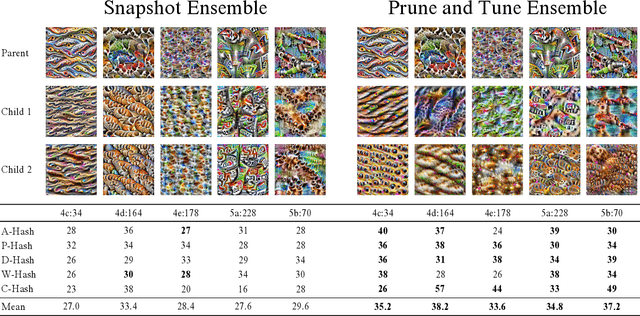


Diversity is an important consideration in the construction of robust neural network ensembles. A collection of well trained models will generalize better if they are diverse in the patterns they respond to and the predictions they make. Diversity is especially important for low-cost ensemble methods because members often share network structure in order to avoid training several independent models from scratch. Diversity is traditionally analyzed by measuring differences between the outputs of models. However, this gives little insight into how knowledge representations differ between ensemble members. This paper introduces several interpretability methods that can be used to qualitatively analyze diversity. We demonstrate these techniques by comparing the diversity of feature representations between child networks using two low-cost ensemble algorithms, Snapshot Ensembles and Prune and Tune Ensembles. We use the same pre-trained parent network as a starting point for both methods which allows us to explore how feature representations evolve over time. This approach to diversity analysis can lead to valuable insights and new perspectives for how we measure and promote diversity in ensemble methods.
Study of Optical Networks, 5G, Artificial Intelligence and Their Applications
Jan 31, 2023This paper discusses the application of artificial intelligence (AI) technology in optical communication networks and 5G. It primarily introduces representative applications of AI technology and potential risks of AI technology failure caused by the openness of optical communication networks, and proposes some coping strategies, mainly including modeling AI systems through modularization and miniaturization, combining with traditional classical network modeling and planning methods, and improving the effectiveness and interpretability of AI technology. At the same time, it proposes response strategies based on network protection for the possible failure and attack of AI technology.