 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Dynamic Model for Bus Arrival Time Estimation based on Spatial Patterns using Machine Learning
Oct 03, 2022
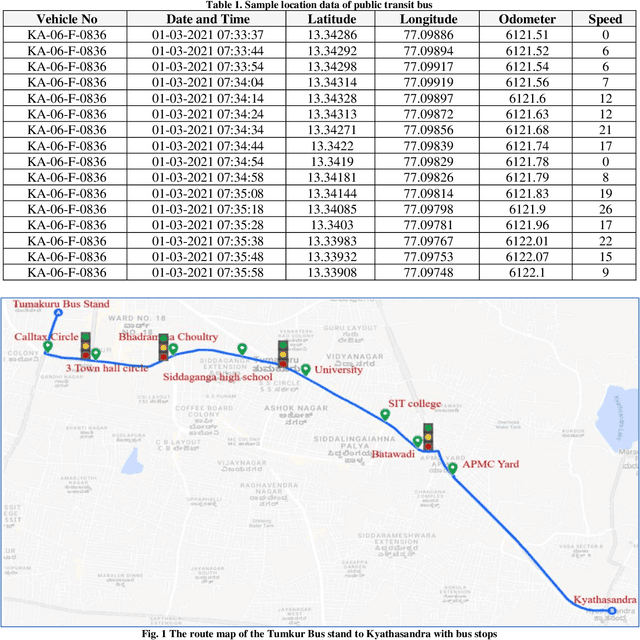
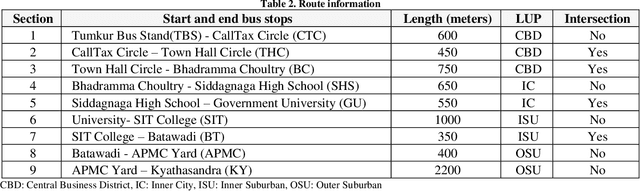
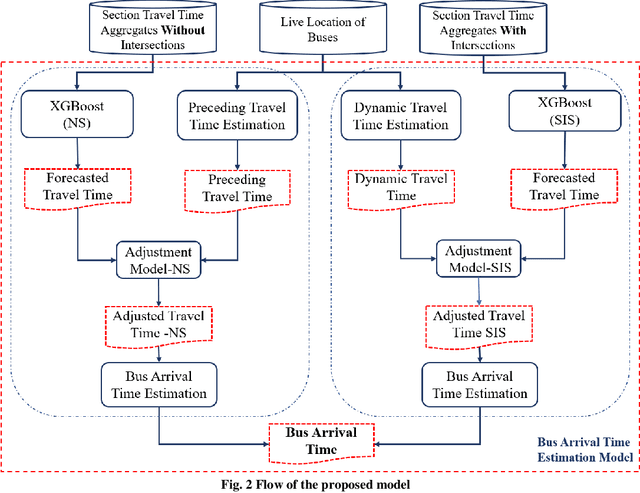

The notion of smart cities is being adapted globally to provide a better quality of living. A smart city's smart mobility component focuses on providing smooth and safe commuting for its residents and promotes eco-friendly and sustainable alternatives such as public transit (bus). Among several smart applications, a system that provides up-to-the-minute information like bus arrival, travel duration, schedule, etc., improves the reliability of public transit services. Still, this application needs live information on traffic flow, accidents, events, and the location of the buses. Most cities lack the infrastructure to provide these data. In this context, a bus arrival prediction model is proposed for forecasting the arrival time using limited data sets. The location data of public transit buses and spatial characteristics are used for the study. One of the routes of Tumakuru city service, Tumakuru, India, is selected and divided into two spatial patterns: sections with intersections and sections without intersections. The machine learning model XGBoost is modeled for both spatial patterns individually. A model to dynamically predict bus arrival time is developed using the preceding trip information and the machine learning model to estimate the arrival time at a downstream bus stop. The performance of models is compared based on the R-squared values of the predictions made, and the proposed model established superior results. It is suggested to predict bus arrival in the study area. The proposed model can also be extended to other similar cities with limited traffic-related infrastructure.
Agglomerative Hierarchical Clustering with Dynamic Time Warping for Household Load Curve Clustering
Oct 18, 2022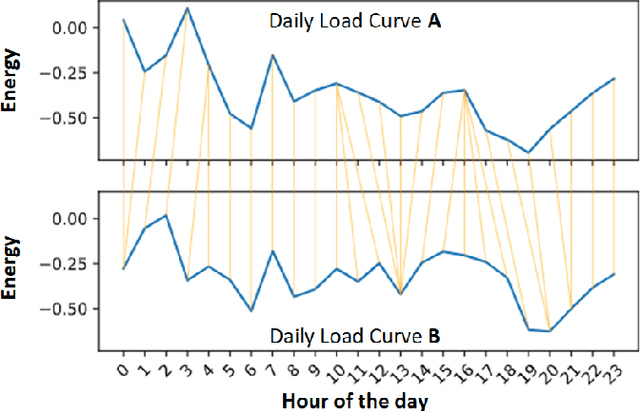
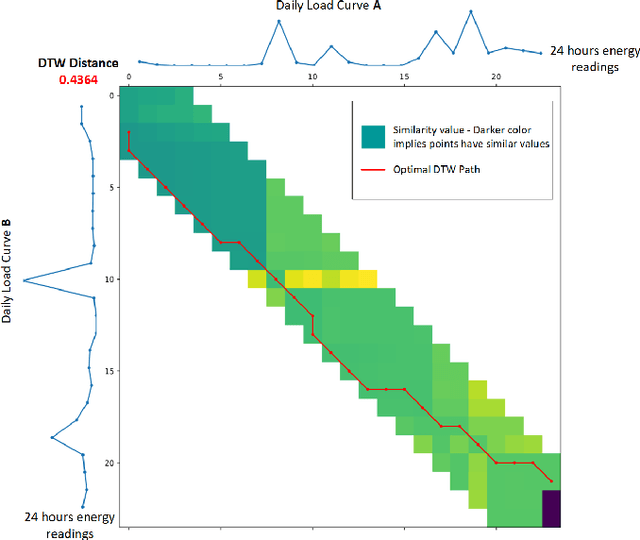
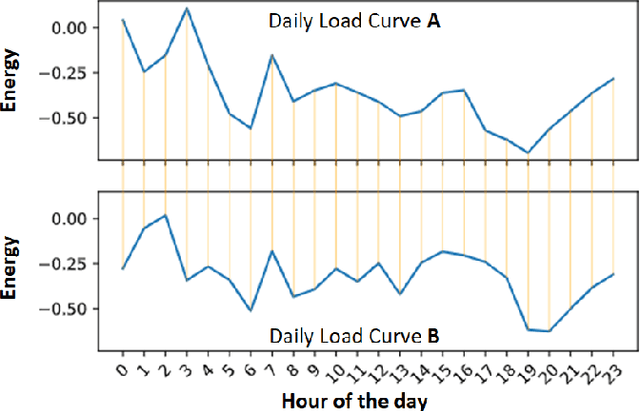
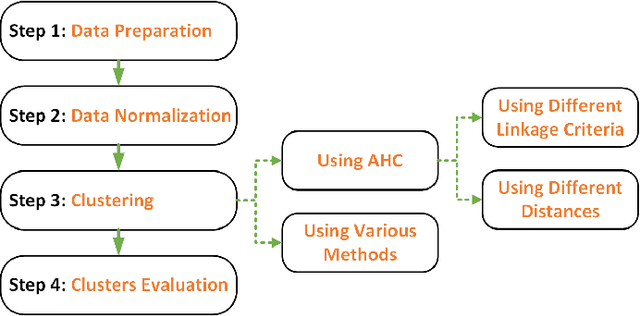
Energy companies often implement various demand response (DR) programs to better match electricity demand and supply by offering the consumers incentives to reduce their demand during critical periods. Classifying clients according to their consumption patterns enables targeting specific groups of consumers for DR. Traditional clustering algorithms use standard distance measurement to find the distance between two points. The results produced by clustering algorithms such as K-means, K-medoids, and Gaussian Mixture Models depend on the clustering parameters or initial clusters. In contrast, our methodology uses a shape-based approach that combines Agglomerative Hierarchical Clustering (AHC) with Dynamic Time Warping (DTW) to classify residential households' daily load curves based on their consumption patterns. While DTW seeks the optimal alignment between two load curves, AHC provides a realistic initial clusters center. In this paper, we compare the results with other clustering algorithms such as K-means, K-medoids, and GMM using different distance measures, and we show that AHC using DTW outperformed other clustering algorithms and needed fewer clusters.
RealityTalk: Real-Time Speech-Driven Augmented Presentation for AR Live Storytelling
Aug 12, 2022
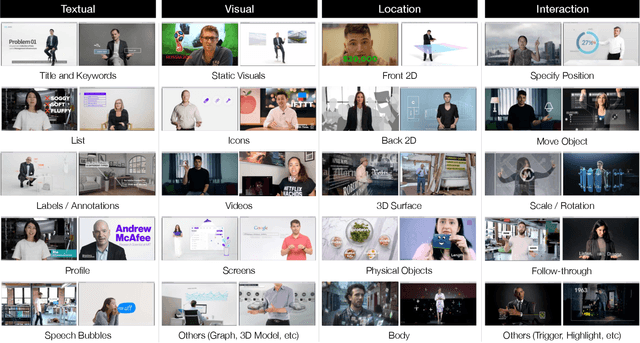
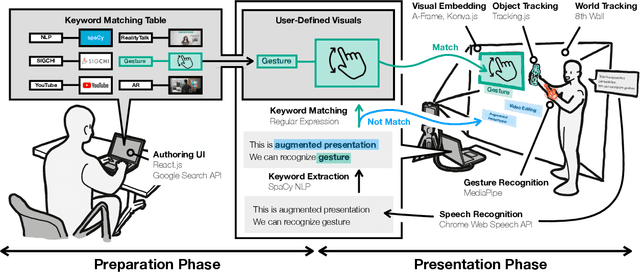

We present RealityTalk, a system that augments real-time live presentations with speech-driven interactive virtual elements. Augmented presentations leverage embedded visuals and animation for engaging and expressive storytelling. However, existing tools for live presentations often lack interactivity and improvisation, while creating such effects in video editing tools require significant time and expertise. RealityTalk enables users to create live augmented presentations with real-time speech-driven interactions. The user can interactively prompt, move, and manipulate graphical elements through real-time speech and supporting modalities. Based on our analysis of 177 existing video-edited augmented presentations, we propose a novel set of interaction techniques and then incorporated them into RealityTalk. We evaluate our tool from a presenter's perspective to demonstrate the effectiveness of our system.
One-Time Model Adaptation to Heterogeneous Clients: An Intra-Client and Inter-Image Attention Design
Nov 11, 2022
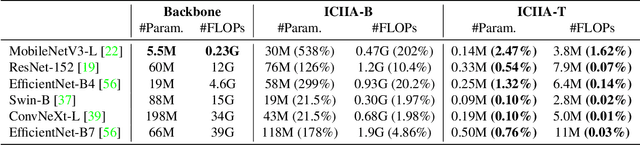
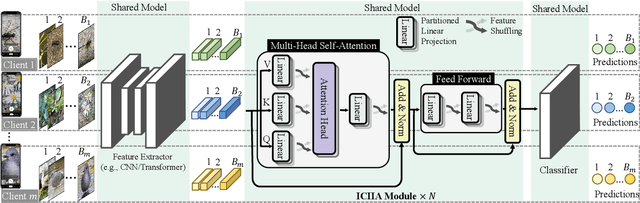
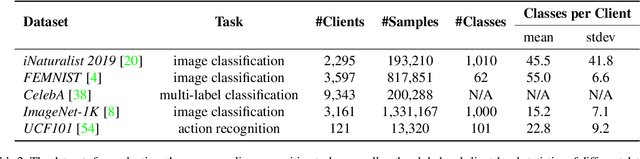
The mainstream workflow of image recognition applications is first training one global model on the cloud for a wide range of classes and then serving numerous clients, each with heterogeneous images from a small subset of classes to be recognized. From the cloud-client discrepancies on the range of image classes, the recognition model is desired to have strong adaptiveness, intuitively by concentrating the focus on each individual client's local dynamic class subset, while incurring negligible overhead. In this work, we propose to plug a new intra-client and inter-image attention (ICIIA) module into existing backbone recognition models, requiring only one-time cloud-based training to be client-adaptive. In particular, given a target image from a certain client, ICIIA introduces multi-head self-attention to retrieve relevant images from the client's historical unlabeled images, thereby calibrating the focus and the recognition result. Further considering that ICIIA's overhead is dominated by linear projection, we propose partitioned linear projection with feature shuffling for replacement and allow increasing the number of partitions to dramatically improve efficiency without scarifying too much accuracy. We finally evaluate ICIIA using 3 different recognition tasks with 9 backbone models over 5 representative datasets. Extensive evaluation results demonstrate the effectiveness and efficiency of ICIIA. Specifically, for ImageNet-1K with the backbone models of MobileNetV3-L and Swin-B, ICIIA can improve the testing accuracy to 83.37% (+8.11%) and 88.86% (+5.28%), while adding only 1.62% and 0.02% of FLOPs, respectively.
Understanding how the use of AI decision support tools affect critical thinking and over-reliance on technology by drug dispensers in Tanzania
Feb 22, 2023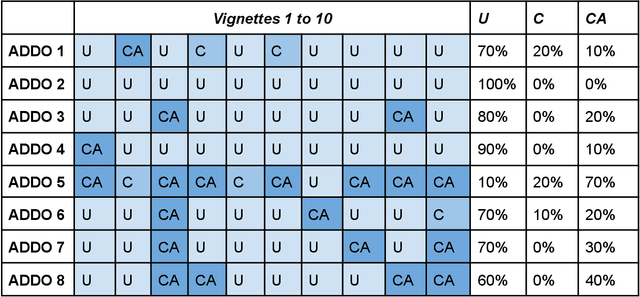
The use of AI in healthcare is designed to improve care delivery and augment the decisions of providers to enhance patient outcomes. When deployed in clinical settings, the interaction between providers and AI is a critical component for measuring and understanding the effectiveness of these digital tools on broader health outcomes. Even in cases where AI algorithms have high diagnostic accuracy, healthcare providers often still rely on their experience and sometimes gut feeling to make a final decision. Other times, providers rely unquestioningly on the outputs of the AI models, which leads to a concern about over-reliance on the technology. The purpose of this research was to understand how reliant drug shop dispensers were on AI-powered technologies when determining a differential diagnosis for a presented clinical case vignette. We explored how the drug dispensers responded to technology that is framed as always correct in an attempt to measure whether they begin to rely on it without any critical thought of their own. We found that dispensers relied on the decision made by the AI 25 percent of the time, even when the AI provided no explanation for its decision.
Reduce, Reuse, Recycle: Compositional Generation with Energy-Based Diffusion Models and MCMC
Feb 22, 2023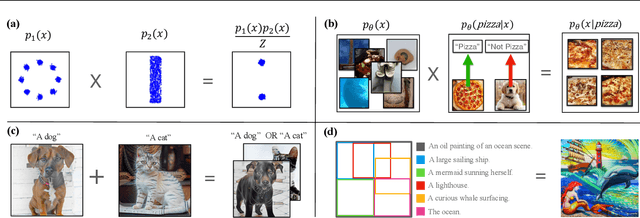
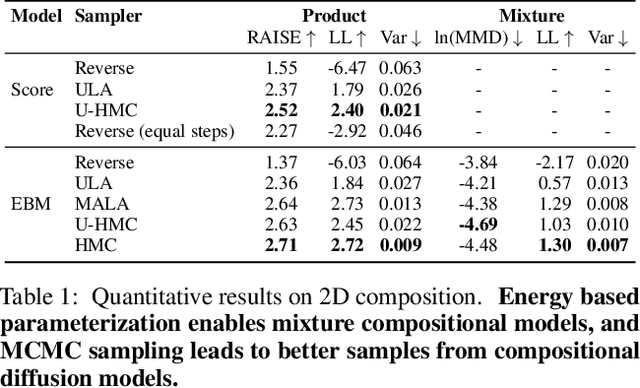
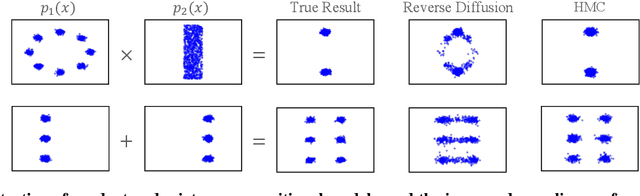
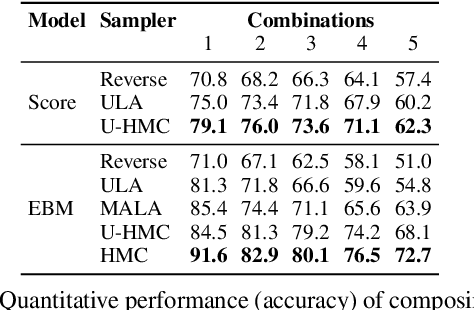
Since their introduction, diffusion models have quickly become the prevailing approach to generative modeling in many domains. They can be interpreted as learning the gradients of a time-varying sequence of log-probability density functions. This interpretation has motivated classifier-based and classifier-free guidance as methods for post-hoc control of diffusion models. In this work, we build upon these ideas using the score-based interpretation of diffusion models, and explore alternative ways to condition, modify, and reuse diffusion models for tasks involving compositional generation and guidance. In particular, we investigate why certain types of composition fail using current techniques and present a number of solutions. We conclude that the sampler (not the model) is responsible for this failure and propose new samplers, inspired by MCMC, which enable successful compositional generation. Further, we propose an energy-based parameterization of diffusion models which enables the use of new compositional operators and more sophisticated, Metropolis-corrected samplers. Intriguingly we find these samplers lead to notable improvements in compositional generation across a wide set of problems such as classifier-guided ImageNet modeling and compositional text-to-image generation.
Steerable Equivariant Representation Learning
Feb 22, 2023



Pre-trained deep image representations are useful for post-training tasks such as classification through transfer learning, image retrieval, and object detection. Data augmentations are a crucial aspect of pre-training robust representations in both supervised and self-supervised settings. Data augmentations explicitly or implicitly promote invariance in the embedding space to the input image transformations. This invariance reduces generalization to those downstream tasks which rely on sensitivity to these particular data augmentations. In this paper, we propose a method of learning representations that are instead equivariant to data augmentations. We achieve this equivariance through the use of steerable representations. Our representations can be manipulated directly in embedding space via learned linear maps. We demonstrate that our resulting steerable and equivariant representations lead to better performance on transfer learning and robustness: e.g. we improve linear probe top-1 accuracy by between 1% to 3% for transfer; and ImageNet-C accuracy by upto 3.4%. We further show that the steerability of our representations provides significant speedup (nearly 50x) for test-time augmentations; by applying a large number of augmentations for out-of-distribution detection, we significantly improve OOD AUC on the ImageNet-C dataset over an invariant representation.
Distributionally Robust Recourse Action
Feb 22, 2023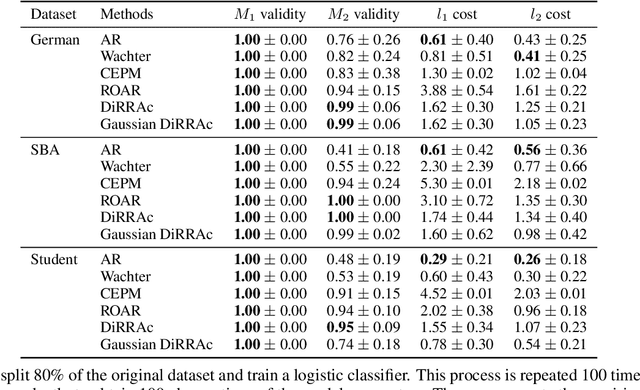
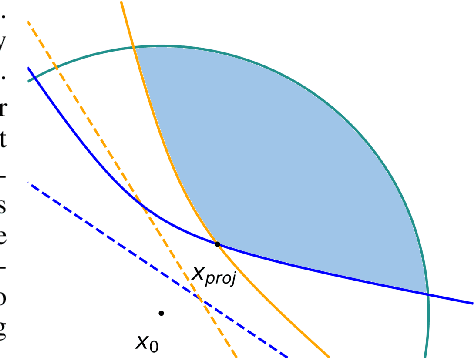
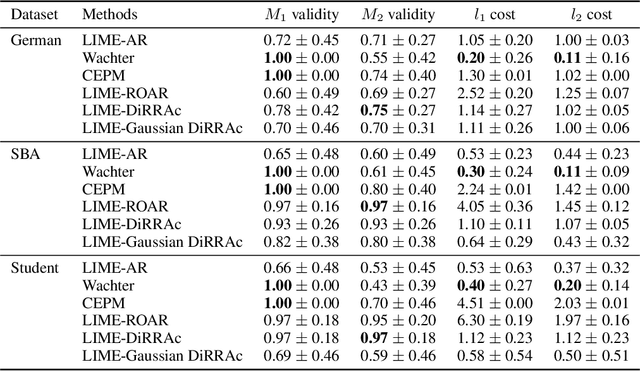
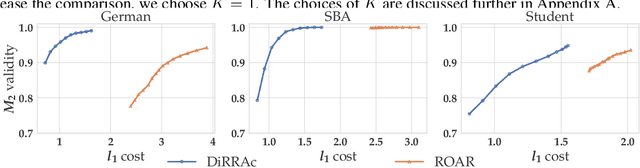
A recourse action aims to explain a particular algorithmic decision by showing one specific way in which the instance could be modified to receive an alternate outcome. Existing recourse generation methods often assume that the machine learning model does not change over time. However, this assumption does not always hold in practice because of data distribution shifts, and in this case, the recourse action may become invalid. To redress this shortcoming, we propose the Distributionally Robust Recourse Action (DiRRAc) framework, which generates a recourse action that has a high probability of being valid under a mixture of model shifts. We formulate the robustified recourse setup as a min-max optimization problem, where the max problem is specified by Gelbrich distance over an ambiguity set around the distribution of model parameters. Then we suggest a projected gradient descent algorithm to find a robust recourse according to the min-max objective. We show that our DiRRAc framework can be extended to hedge against the misspecification of the mixture weights. Numerical experiments with both synthetic and three real-world datasets demonstrate the benefits of our proposed framework over state-of-the-art recourse methods.
Neural Graph Revealers
Feb 28, 2023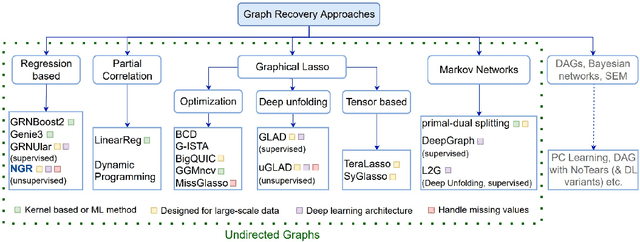
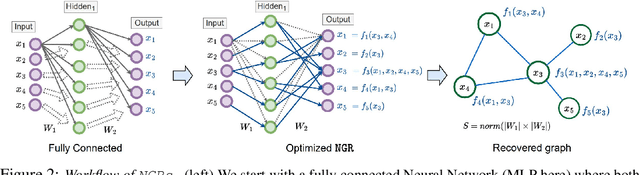
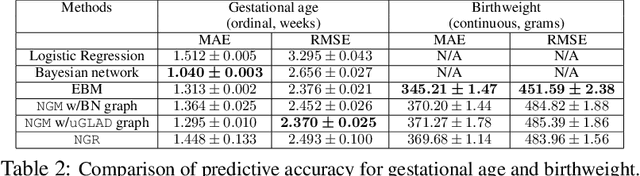
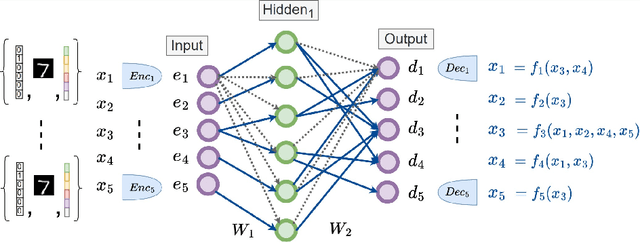
Sparse graph recovery methods work well where the data follows their assumptions but often they are not designed for doing downstream probabilistic queries. This limits their adoption to only identifying connections among the input variables. On the other hand, the Probabilistic Graphical Models (PGMs) assume an underlying base graph between variables and learns a distribution over them. PGM design choices are carefully made such that the inference \& sampling algorithms are efficient. This brings in certain restrictions and often simplifying assumptions. In this work, we propose Neural Graph Revealers (NGRs), that are an attempt to efficiently merge the sparse graph recovery methods with PGMs into a single flow. The problem setting consists of an input data X with D features and M samples and the task is to recover a sparse graph showing connection between the features and learn a probability distribution over the D at the same time. NGRs view the neural networks as a `glass box' or more specifically as a multitask learning framework. We introduce `Graph-constrained path norm' that NGRs leverage to learn a graphical model that captures complex non-linear functional dependencies between the features in the form of an undirected sparse graph. Furthermore, NGRs can handle multimodal inputs like images, text, categorical data, embeddings etc. which is not straightforward to incorporate in the existing methods. We show experimental results of doing sparse graph recovery and probabilistic inference on data from Gaussian graphical models and a multimodal infant mortality dataset by Centers for Disease Control and Prevention.
CHGNet: Pretrained universal neural network potential for charge-informed atomistic modeling
Feb 28, 2023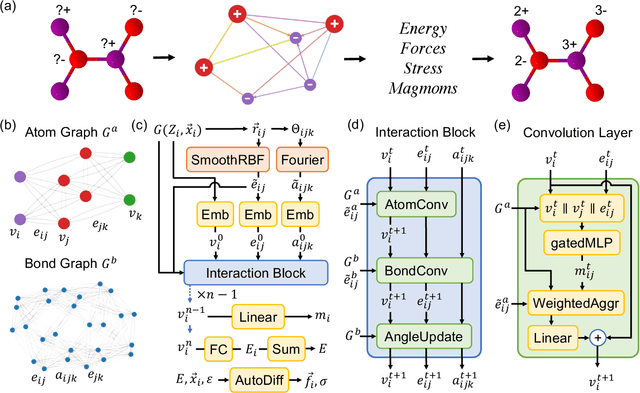
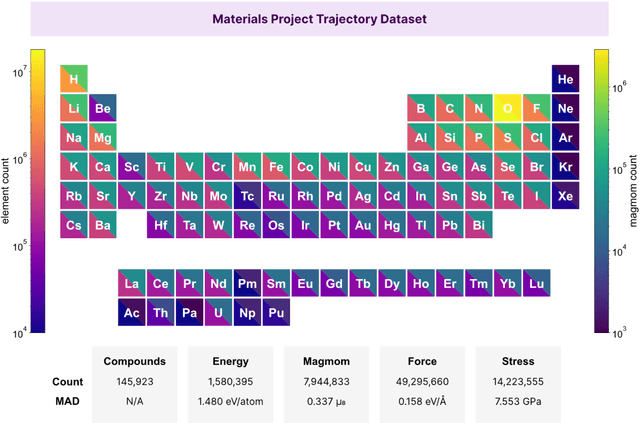
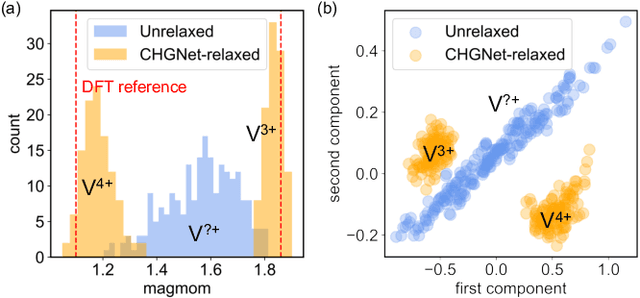
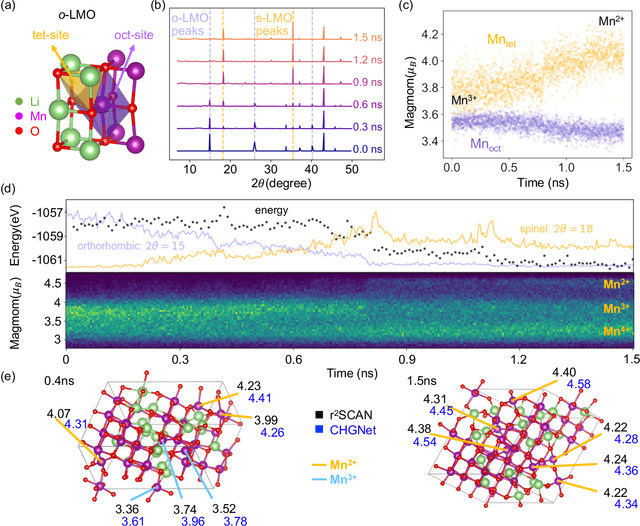
The simulation of large-scale systems with complex electron interactions remains one of the greatest challenges for the atomistic modeling of materials. Although classical force-fields often fail to describe the coupling between electronic states and ionic rearrangements, the more accurate \textit{ab-initio} molecular dynamics suffers from computational complexity that prevents long-time and large-scale simulations, which are essential to study many technologically relevant phenomena, such as reactions, ion migrations, phase transformations, and degradation. In this work, we present the Crystal Hamiltonian Graph neural Network (CHGNet) as a novel machine-learning interatomic potential (MLIP), using a graph-neural-network-based force-field to model a universal potential energy surface. CHGNet is pretrained on the energies, forces, stresses, and magnetic moments from the Materials Project Trajectory Dataset, which consists of over 10 years of density functional theory static and relaxation trajectories of $\sim 1.5$ million inorganic structures. The explicit inclusion of magnetic moments enables CHGNet to learn and accurately represent the orbital occupancy of electrons, enhancing its capability to describe both atomic and electronic degrees of freedom. We demonstrate several applications of CHGNet in solid-state materials, including charge-informed molecular dynamics in Li$_x$MnO$_2$, the finite temperature phase diagram for Li$_x$FePO$_4$ and Li diffusion in garnet conductors. We critically analyze the significance of including charge information for capturing appropriate chemistry, and we provide new insights into ionic systems with additional electronic degrees of freedom that can not be observed by previous MLIPs.