 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Pricing and Hedging of High Dimensional American Options Using Recurrent Networks
Jan 19, 2023
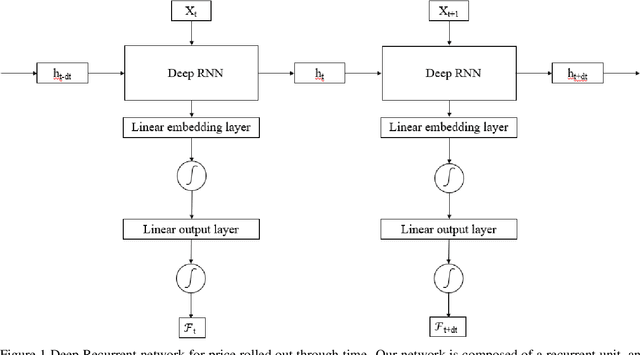
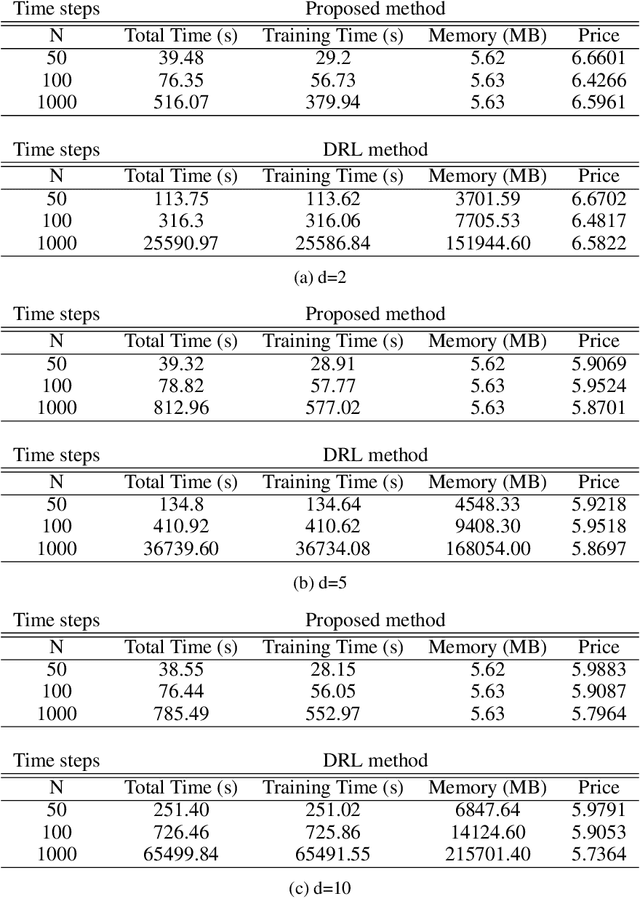
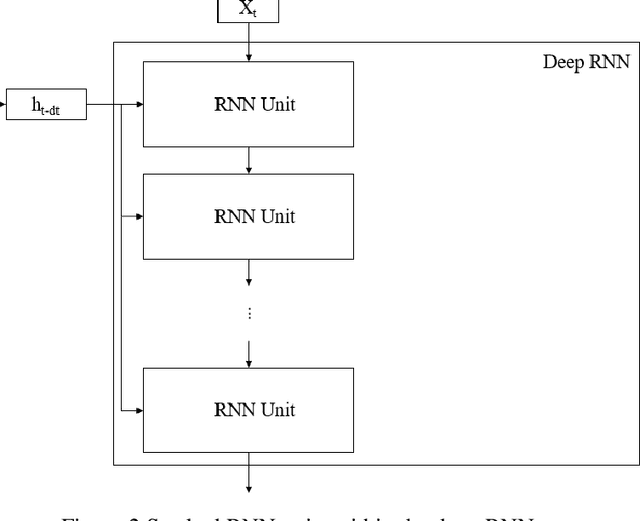
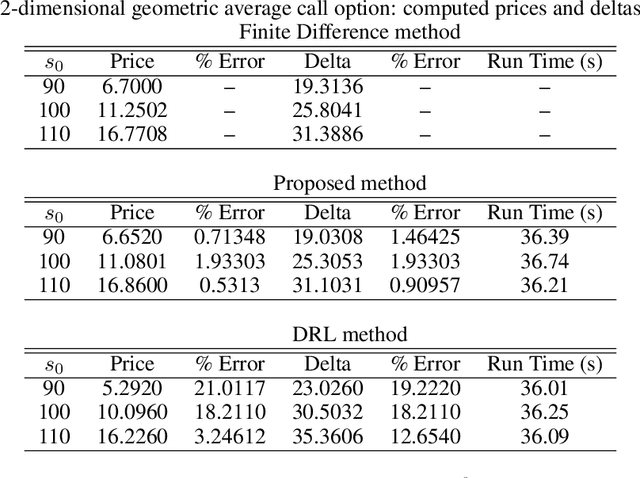
We propose a deep Recurrent neural network (RNN) framework for computing prices and deltas of American options in high dimensions. Our proposed framework uses two deep RNNs, where one network learns the price and the other learns the delta of the option for each timestep. Our proposed framework yields prices and deltas for the entire spacetime, not only at a given point (e.g. t = 0). The computational cost of the proposed approach is linear in time, which improves on the quadratic time seen for feedforward networks that price American options. The computational memory cost of our method is constant in memory, which is an improvement over the linear memory costs seen in feedforward networks. Our numerical simulations demonstrate these contributions, and show that the proposed deep RNN framework is computationally more efficient than traditional feedforward neural network frameworks in time and memory.
Bi-Phase Enhanced IVFPQ for Time-Efficient Ad-hoc Retrieval
Oct 11, 2022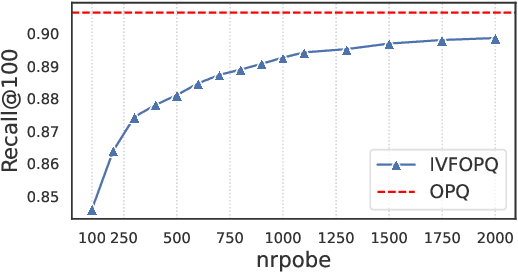
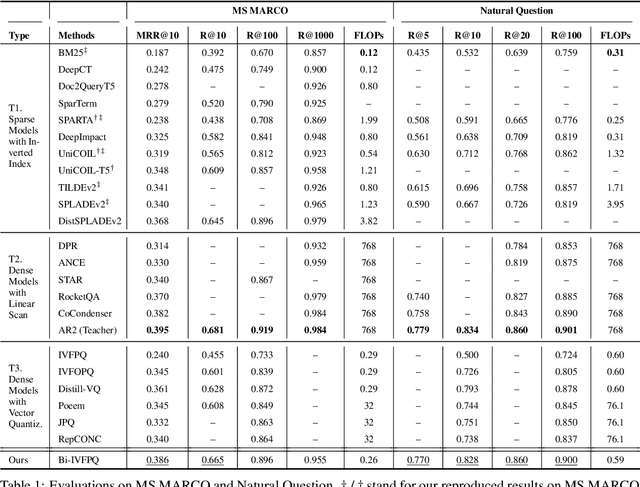
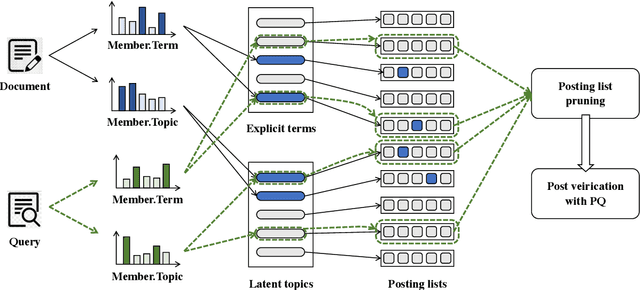
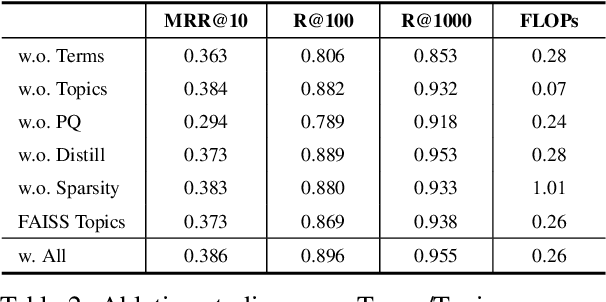
IVFPQ is a popular index paradigm for time-efficient ad-hoc retrieval. Instead of traversing the entire database for relevant documents, it accelerates the retrieval operation by 1) accessing a fraction of the database guided the activation of latent topics in IVF (inverted file system), and 2) approximating the exact relevance measurement based on PQ (product quantization). However, the conventional IVFPQ is limited in retrieval performance due to the coarse granularity of its latent topics. On the one hand, it may result in severe loss of retrieval quality when visiting a small number of topics; on the other hand, it will lead to a huge retrieval cost when visiting a large number of topics. To mitigate the above problem, we propose a novel framework named Bi-Phase IVFPQ. It jointly uses two types of features: the latent topics and the explicit terms, to build the inverted file system. Both types of features are complementary to each other, which helps to achieve better coverage of the relevant documents. Besides, the documents' memberships to different IVF entries are learned by distilling knowledge from deep semantic models, which substantially improves the index quality and retrieval accuracy. We perform comprehensive empirical studies on popular ad-hoc retrieval benchmarks, whose results verify the effectiveness and efficiency of our proposed framework.
Elementwise Language Representation
Feb 27, 2023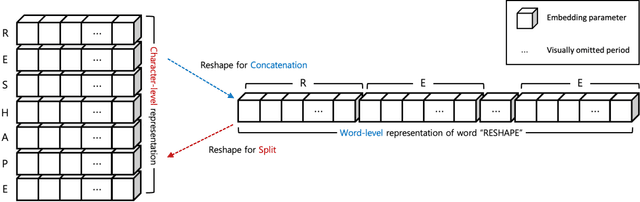
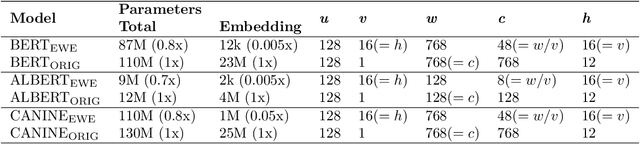
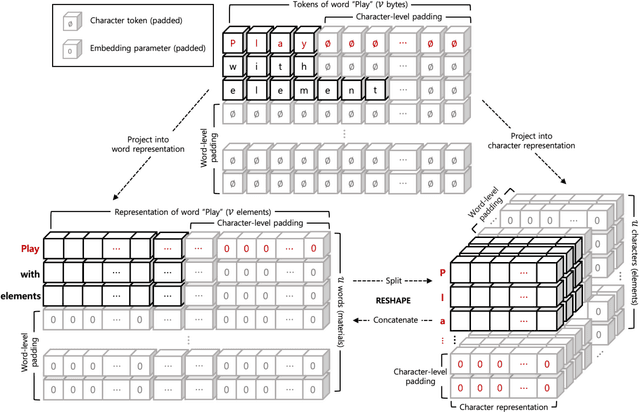
We propose a new technique for computational language representation called elementwise embedding, in which a material (semantic unit) is abstracted into a horizontal concatenation of lower-dimensional element (character) embeddings. While elements are always characters, materials are arbitrary levels of semantic units so it generalizes to any type of tokenization. To focus only on the important letters, the $n^{th}$ spellings of each semantic unit are aligned in $n^{th}$ attention heads, then concatenated back into original forms creating unique embedding representations; they are jointly projected thereby determining own contextual importance. Technically, this framework is achieved by passing a sequence of materials, each consists of $v$ elements, to a transformer having $h=v$ attention heads. As a pure embedding technique, elementwise embedding replaces the $w$-dimensional embedding table of a transformer model with $256$ $c$-dimensional elements (each corresponding to one of UTF-8 bytes) where $c=w/v$. Using this novel approach, we show that the standard transformer architecture can be reused for all levels of language representations and be able to process much longer sequences at the same time-complexity without "any" architectural modification and additional overhead. BERT trained with elementwise embedding outperforms its subword equivalence (original implementation) in multilabel patent document classification exhibiting superior robustness to domain-specificity and data imbalance, despite using $0.005\%$ of embedding parameters. Experiments demonstrate the generalizability of the proposed method by successfully transferring these enhancements to differently architected transformers CANINE and ALBERT.
Hybrid machine-learned homogenization: Bayesian data mining and convolutional neural networks
Feb 24, 2023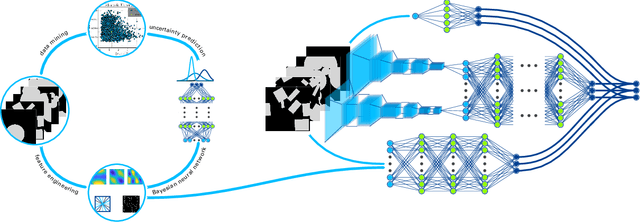


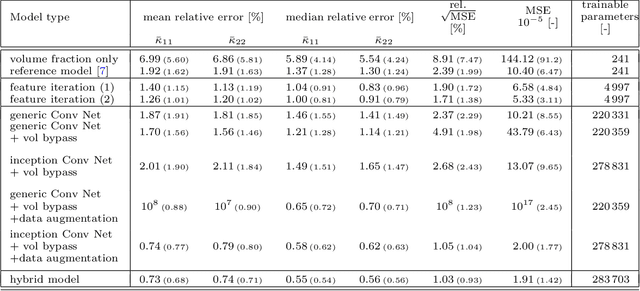
Beyond the generally deployed features for microstructure property prediction this study aims to improve the machine learned prediction by developing novel feature descriptors. Therefore, Bayesian infused data mining is conducted to acquire samples containing characteristics inexplicable to the current feature set, and suitable feature descriptors to describe these characteristics are proposed. The iterative development of feature descriptors resulted in 37 novel features, being able to reduce the prediction error by roughly one third. To further improve the predictive model, convolutional neural networks (Conv Nets) are deployed to generate auxiliary features in a supervised machine learning manner. The Conv Nets were able to outperform the feature based approach. A key ingredient for that is a newly proposed data augmentation scheme and the development of so-called deep inception modules. A combination of the feature based approach and the convolutional neural network leads to a hybrid neural network: A parallel deployment of the both neural network archetypes in a single model achieved a relative rooted mean squared error below 1%, more than halving the error compared to prior models operating on the same data. The hybrid neural network was found powerful enough to be extended to predict variable material parameters, from a low to high phase contrast, while allowing for arbitrary microstructure geometry at the same time.
A Convolutional Vision Transformer for Semantic Segmentation of Side-Scan Sonar Data
Feb 24, 2023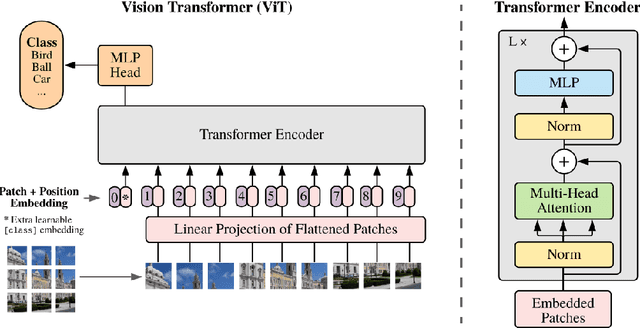
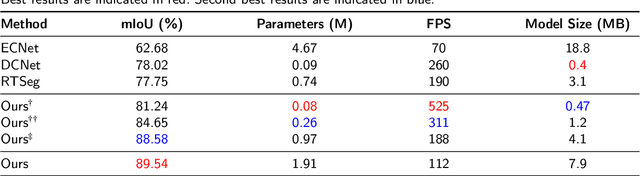
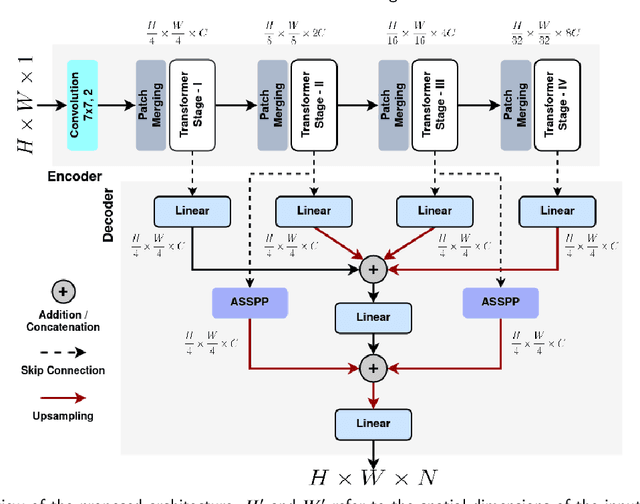
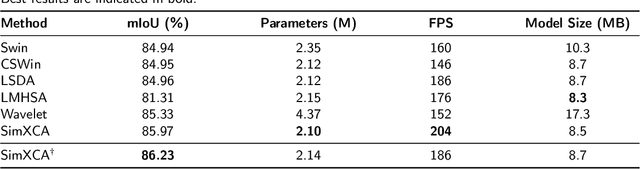
Distinguishing among different marine benthic habitat characteristics is of key importance in a wide set of seabed operations ranging from installations of oil rigs to laying networks of cables and monitoring the impact of humans on marine ecosystems. The Side-Scan Sonar (SSS) is a widely used imaging sensor in this regard. It produces high-resolution seafloor maps by logging the intensities of sound waves reflected back from the seafloor. In this work, we leverage these acoustic intensity maps to produce pixel-wise categorization of different seafloor types. We propose a novel architecture adapted from the Vision Transformer (ViT) in an encoder-decoder framework. Further, in doing so, the applicability of ViTs is evaluated on smaller datasets. To overcome the lack of CNN-like inductive biases, thereby making ViTs more conducive to applications in low data regimes, we propose a novel feature extraction module to replace the Multi-layer Perceptron (MLP) block within transformer layers and a novel module to extract multiscale patch embeddings. A lightweight decoder is also proposed to complement this design in order to further boost multiscale feature extraction. With the modified architecture, we achieve state-of-the-art results and also meet real-time computational requirements. We make our code available at ~\url{https://github.com/hayatrajani/s3seg-vit
3D Trajectory Planning for UAV-based Search Missions: An Integrated Assessment and Search Planning Approach
Feb 24, 2023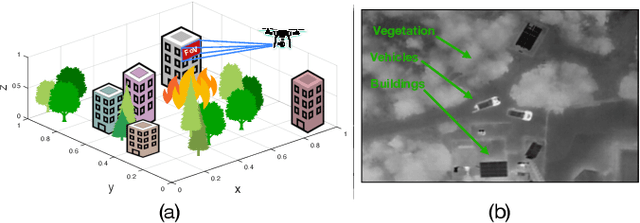
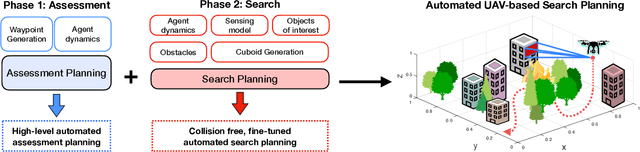
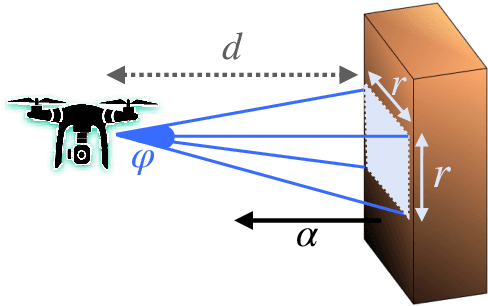
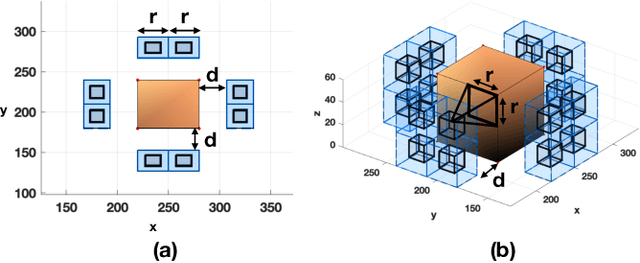
The ability to efficiently plan and execute search missions in challenging and complex environments during natural and man-made disasters is imperative. In many emergency situations, precise navigation between obstacles and time-efficient searching around 3D structures is essential for finding survivors. In this work we propose an integrated assessment and search planning approach which allows an autonomous UAV (unmanned aerial vehicle) agent to plan and execute collision-free search trajectories in 3D environments. More specifically, the proposed search-planning framework aims to integrate and automate the first two phases (i.e., the assessment phase and the search phase) of a traditional search-and-rescue (SAR) mission. In the first stage, termed assessment-planning we aim to find a high-level assessment plan which the UAV agent can execute in order to visit a set of points of interest. The generated plan of this stage guides the UAV to fly over the objects of interest thus providing a first assessment of the situation at hand. In the second stage, termed search-planning, the UAV trajectory is further fine-tuned to allow the UAV to search in 3D (i.e., across all faces) the objects of interest for survivors. The performance of the proposed approach is demonstrated through extensive simulation analysis.
* 2021 International Conference on Unmanned Aircraft Systems (ICUAS)
Robot Behavior-Tree-Based Task Generation with Large Language Models
Feb 24, 2023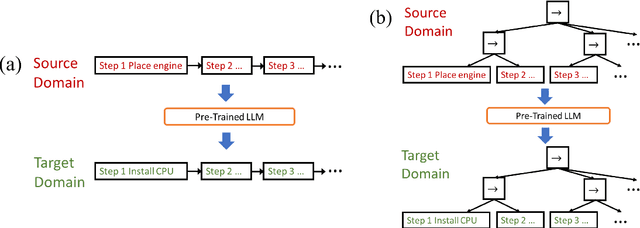
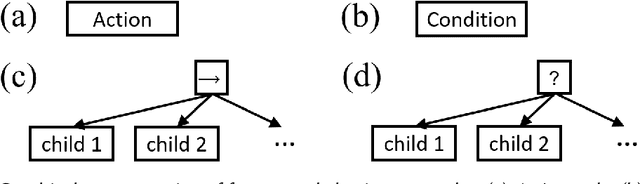
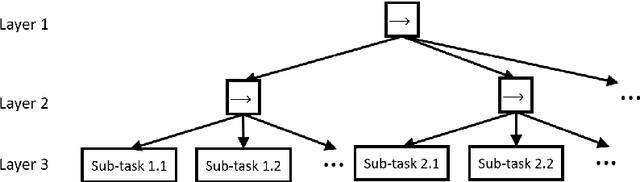
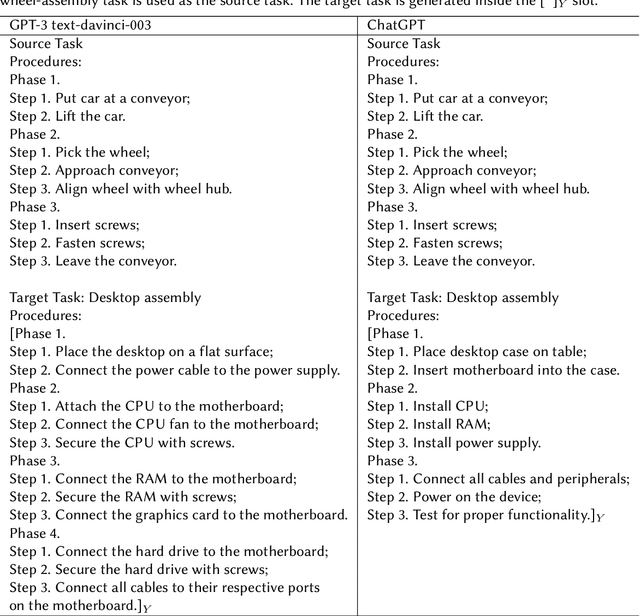
Nowadays, the behavior tree is gaining popularity as a representation for robot tasks due to its modularity and reusability. Designing behavior-tree tasks manually is time-consuming for robot end-users, thus there is a need for investigating automatic behavior-tree-based task generation. Prior behavior-tree-based task generation approaches focus on fixed primitive tasks and lack generalizability to new task domains. To cope with this issue, we propose a novel behavior-tree-based task generation approach that utilizes state-of-the-art large language models. We propose a Phase-Step prompt design that enables a hierarchical-structured robot task generation and further integrate it with behavior-tree-embedding-based search to set up the appropriate prompt. In this way, we enable an automatic and cross-domain behavior-tree task generation. Our behavior-tree-based task generation approach does not require a set of pre-defined primitive tasks. End-users only need to describe an abstract desired task and our proposed approach can swiftly generate the corresponding behavior tree. A full-process case study is provided to demonstrate our proposed approach. An ablation study is conducted to evaluate the effectiveness of our Phase-Step prompts. Assessment on Phase-Step prompts and the limitation of large language models are presented and discussed.
Learning Neural Volumetric Representations of Dynamic Humans in Minutes
Feb 24, 2023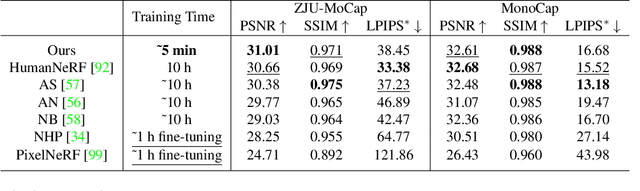
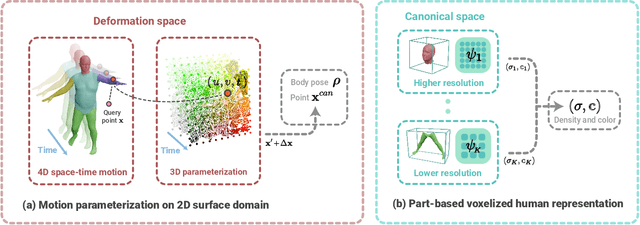

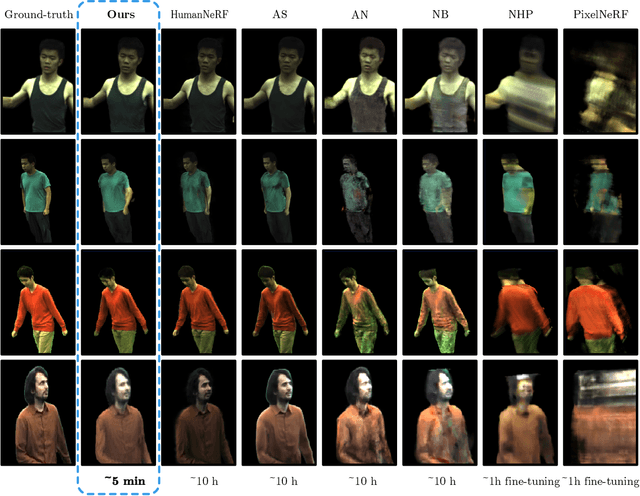
This paper addresses the challenge of quickly reconstructing free-viewpoint videos of dynamic humans from sparse multi-view videos. Some recent works represent the dynamic human as a canonical neural radiance field (NeRF) and a motion field, which are learned from videos through differentiable rendering. But the per-scene optimization generally requires hours. Other generalizable NeRF models leverage learned prior from datasets and reduce the optimization time by only finetuning on new scenes at the cost of visual fidelity. In this paper, we propose a novel method for learning neural volumetric videos of dynamic humans from sparse view videos in minutes with competitive visual quality. Specifically, we define a novel part-based voxelized human representation to better distribute the representational power of the network to different human parts. Furthermore, we propose a novel 2D motion parameterization scheme to increase the convergence rate of deformation field learning. Experiments demonstrate that our model can be learned 100 times faster than prior per-scene optimization methods while being competitive in the rendering quality. Training our model on a $512 \times 512$ video with 100 frames typically takes about 5 minutes on a single RTX 3090 GPU. The code will be released on our project page: https://zju3dv.github.io/instant_nvr
From Occlusion to Insight: Object Search in Semantic Shelves using Large Language Models
Feb 24, 2023
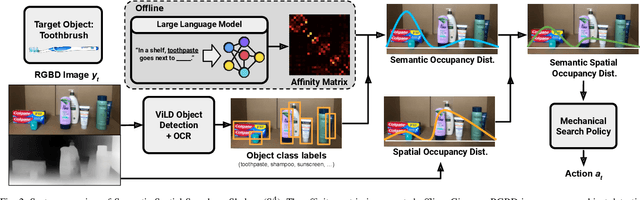
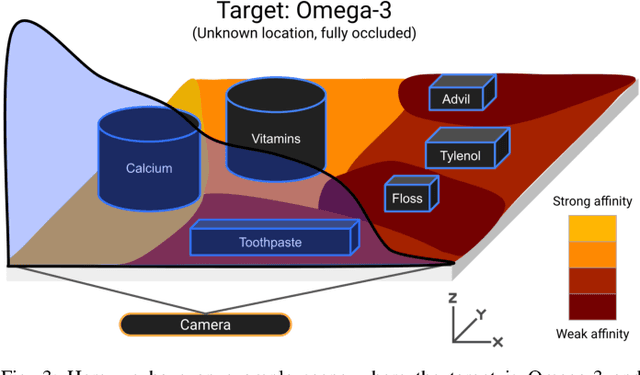

How can a robot efficiently extract a desired object from a shelf when it is fully occluded by other objects? Prior works propose geometric approaches for this problem but do not consider object semantics. Shelves in pharmacies, restaurant kitchens, and grocery stores are often organized such that semantically similar objects are placed close to one another. Can large language models (LLMs) serve as semantic knowledge sources to accelerate robotic mechanical search in semantically arranged environments? With Semantic Spatial Search on Shelves (S^4), we use LLMs to generate affinity matrices, where entries correspond to semantic likelihood of physical proximity between objects. We derive semantic spatial distributions by synthesizing semantics with learned geometric constraints. S^4 incorporates Optical Character Recognition (OCR) and semantic refinement with predictions from ViLD, an open-vocabulary object detection model. Simulation experiments suggest that semantic spatial search reduces the search time relative to pure spatial search by an average of 24% across three domains: pharmacy, kitchen, and office shelves. A manually collected dataset of 100 semantic scenes suggests that OCR and semantic refinement improve object detection accuracy by 35%. Lastly, physical experiments in a pharmacy shelf suggest 47.1% improvement over pure spatial search. Supplementary material can be found at https://sites.google.com/view/s4-rss/home.
$\mathcal{L}_1$Quad: $\mathcal{L}_1$ Adaptive Augmentation of Geometric Control for Agile Quadrotors with Performance Guarantees
Feb 14, 2023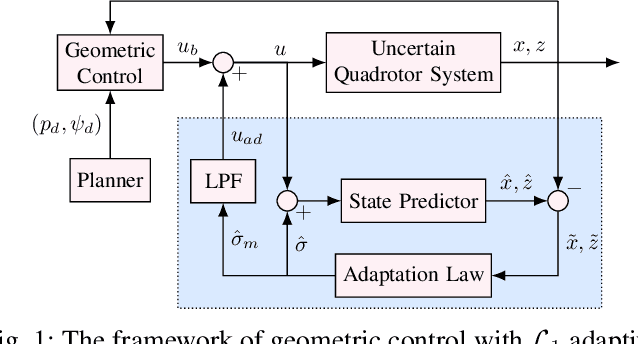
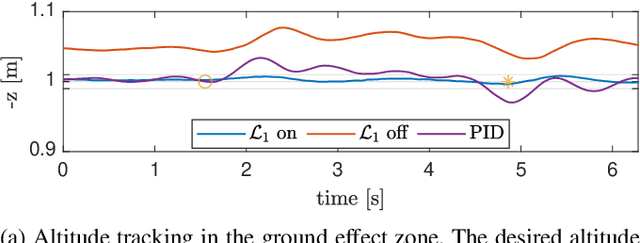
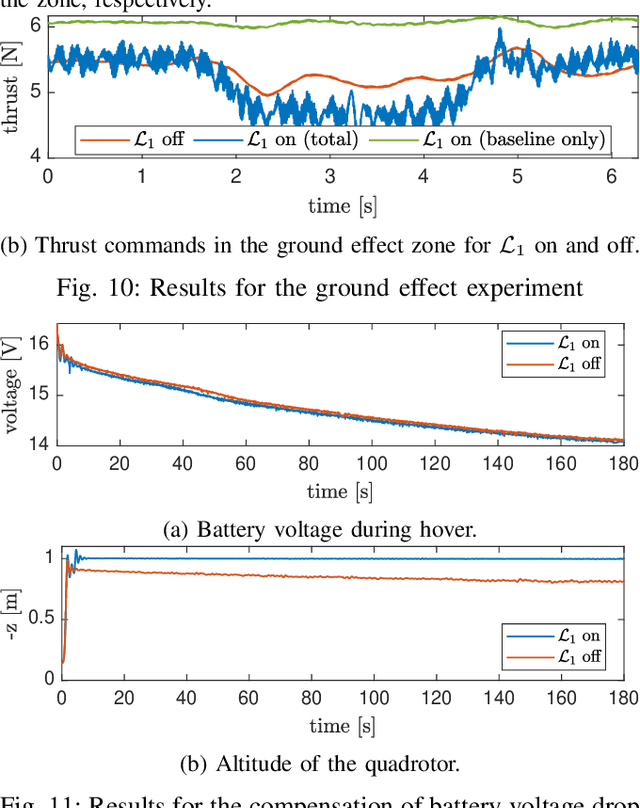

Quadrotors that can operate safely in the presence of imperfect model knowledge and external disturbances are crucial in safety-critical applications. We present L1Quad, a control architecture for quadrotors based on the L1 adaptive control. L1Quad enables safe tubes centered around a desired trajectory that the quadrotor is always guaranteed to remain inside. Our design applies to both the rotational and the translational dynamics of the quadrotor. We lump various types of uncertainties and disturbances as unknown nonlinear (time- and state-dependent) forces and moments. Without assuming or enforcing parametric structures, L1Quad can accurately estimate and compensate for these unknown forces and moments. Extensive experimental results demonstrate that L1Quad is able to significantly outperform baseline controllers under a variety of uncertainties with consistently small tracking errors.