 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fixflow: A Framework to Evaluate Fixed-point Arithmetic in Light-Weight CNN Inference
Feb 19, 2023
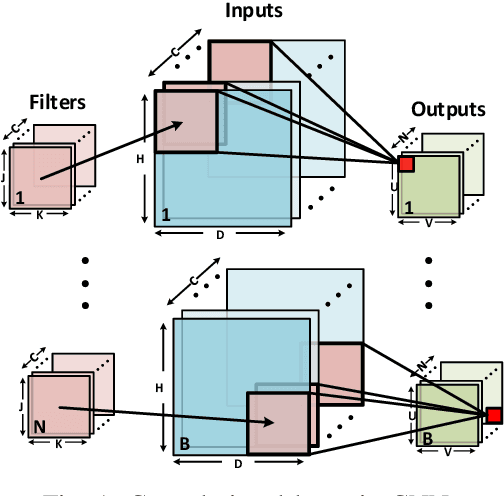
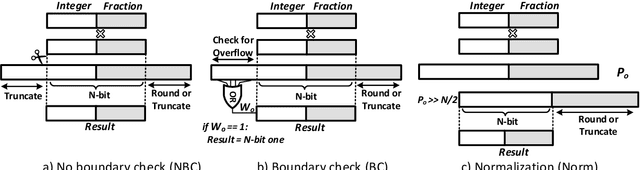
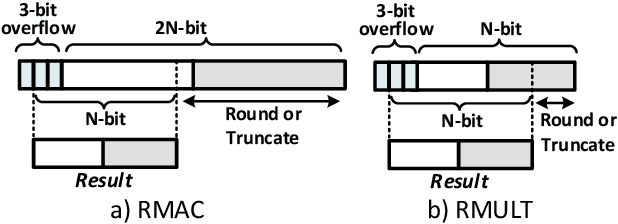
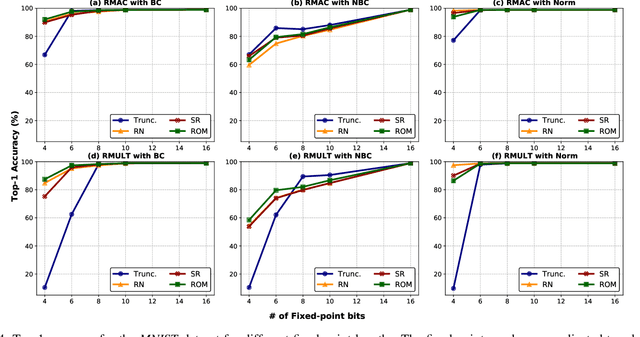
Convolutional neural networks (CNN) are widely used in resource-constrained devices in IoT applications. In order to reduce the computational complexity and memory footprint, the resource-constrained devices use fixed-point representation. This representation consumes less area and energy in hardware with similar classification accuracy compared to the floating-point ones. However, to employ the low-precision fixed-point representation, various considerations to gain high accuracy are required. Although many quantization and re-training techniques are proposed to improve the inference accuracy, these approaches are time-consuming and require access to the entire dataset. This paper investigates the effect of different fixed-point hardware units on CNN inference accuracy. To this end, we provide a framework called Fixflow to evaluate the effect of fixed-point computations performed at hardware level on CNN classification accuracy. We can employ different fixed-point considerations at the hardware accelerators.This includes rounding methods and adjusting the precision of the fixed-point operation's result. Fixflow can determine the impact of employing different arithmetic units (such as truncated multipliers) on CNN classification accuracy. Moreover, we evaluate the energy and area consumption of these units in hardware accelerators. We perform experiments on two common MNIST and CIFAR-10 datasets. Our results show that employing different methods at the hardware level specially with low-precision, can significantly change the classification accuracy.
Audio Representation Learning by Distilling Video as Privileged Information
Feb 06, 2023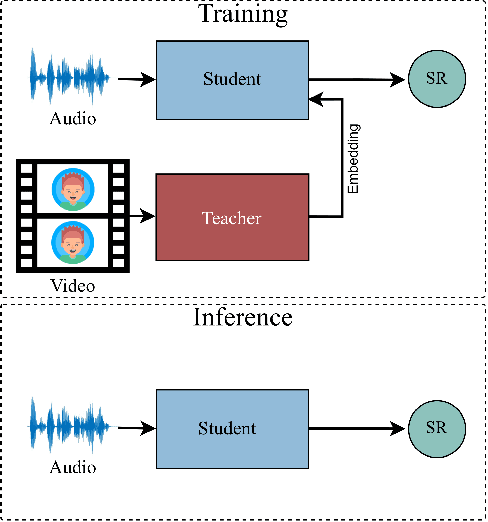
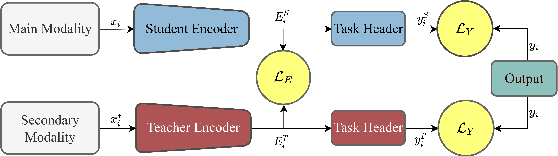
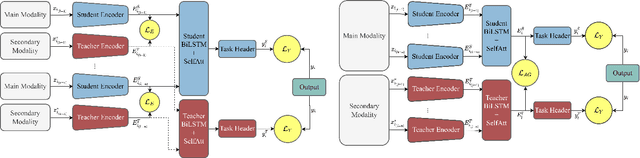
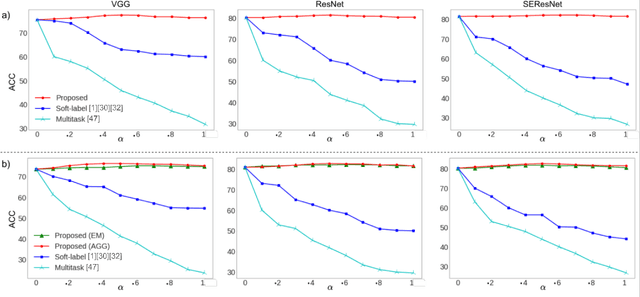
Deep audio representation learning using multi-modal audio-visual data often leads to a better performance compared to uni-modal approaches. However, in real-world scenarios both modalities are not always available at the time of inference, leading to performance degradation by models trained for multi-modal inference. In this work, we propose a novel approach for deep audio representation learning using audio-visual data when the video modality is absent at inference. For this purpose, we adopt teacher-student knowledge distillation under the framework of learning using privileged information (LUPI). While the previous methods proposed for LUPI use soft-labels generated by the teacher, in our proposed method we use embeddings learned by the teacher to train the student network. We integrate our method in two different settings: sequential data where the features are divided into multiple segments throughout time, and non-sequential data where the entire features are treated as one whole segment. In the non-sequential setting both the teacher and student networks are comprised of an encoder component and a task header. We use the embeddings produced by the encoder component of the teacher to train the encoder of the student, while the task header of the student is trained using ground-truth labels. In the sequential setting, the networks have an additional aggregation component that is placed between the encoder and task header. We use two sets of embeddings produced by the encoder and aggregation component of the teacher to train the student. Similar to the non-sequential setting, the task header of the student network is trained using ground-truth labels. We test our framework on two different audio-visual tasks, namely speaker recognition and speech emotion recognition and show considerable improvements over sole audio-based recognition as well as prior works that use LUPI.
Deterministic Online Classification: Non-iteratively Reweighted Recursive Least-Squares for Binary Class Rebalancing
Jan 22, 2023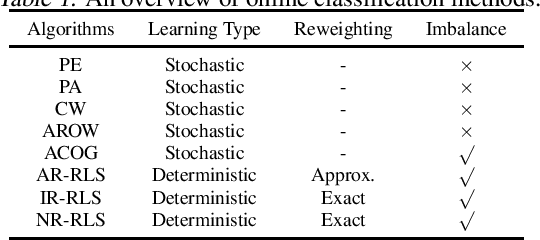

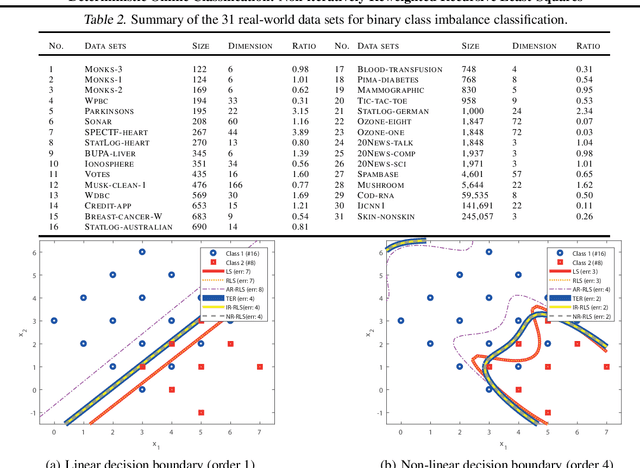
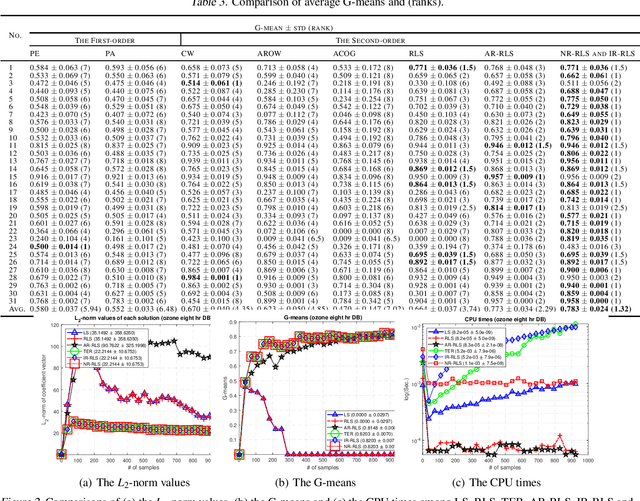
Deterministic solutions are becoming more critical for interpretability. Weighted Least-Squares (WLS) has been widely used as a deterministic batch solution with a specific weight design. In the online settings of WLS, exact reweighting is necessary to converge to its batch settings. In order to comply with its necessity, the iteratively reweighted least-squares algorithm is mainly utilized with a linearly growing time complexity which is not attractive for online learning. Due to the high and growing computational costs, an efficient online formulation of reweighted least-squares is desired. We introduce a new deterministic online classification algorithm of WLS with a constant time complexity for binary class rebalancing. We demonstrate that our proposed online formulation exactly converges to its batch formulation and outperforms existing state-of-the-art stochastic online binary classification algorithms in real-world data sets empirically.
Evolution of Filter Bubbles and Polarization in News Recommendation
Jan 26, 2023
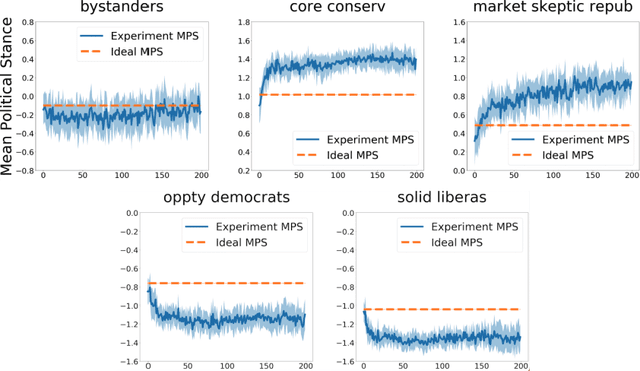
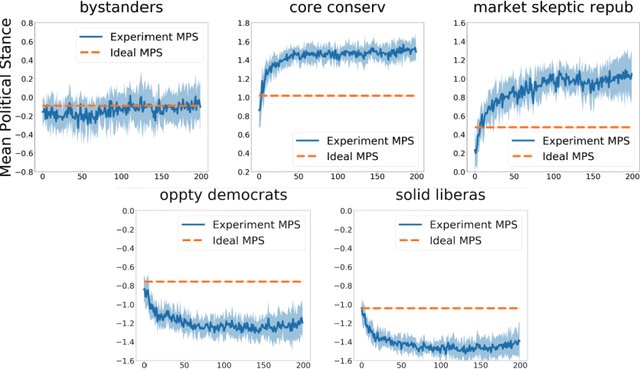
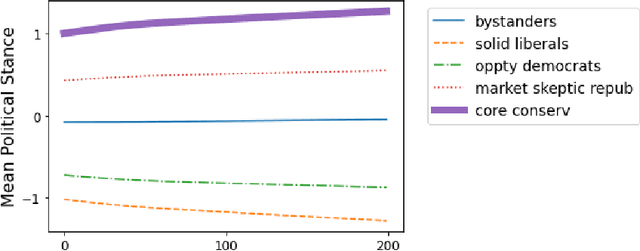
Recent work in news recommendation has demonstrated that recommenders can over-expose users to articles that support their pre-existing opinions. However, most existing work focuses on a static setting or over a short-time window, leaving open questions about the long-term and dynamic impacts of news recommendations. In this paper, we explore these dynamic impacts through a systematic study of three research questions: 1) How do the news reading behaviors of users change after repeated long-term interactions with recommenders? 2) How do the inherent preferences of users change over time in such a dynamic recommender system? 3) Can the existing SOTA static method alleviate the problem in the dynamic environment? Concretely, we conduct a comprehensive data-driven study through simulation experiments of political polarization in news recommendations based on 40,000 annotated news articles. We find that users are rapidly exposed to more extreme content as the recommender evolves. We also find that a calibration-based intervention can slow down this polarization, but leaves open significant opportunities for future improvements
Relative-Interior Solution for (Incomplete) Linear Assignment Problem with Applications to Quadratic Assignment Problem
Jan 26, 2023
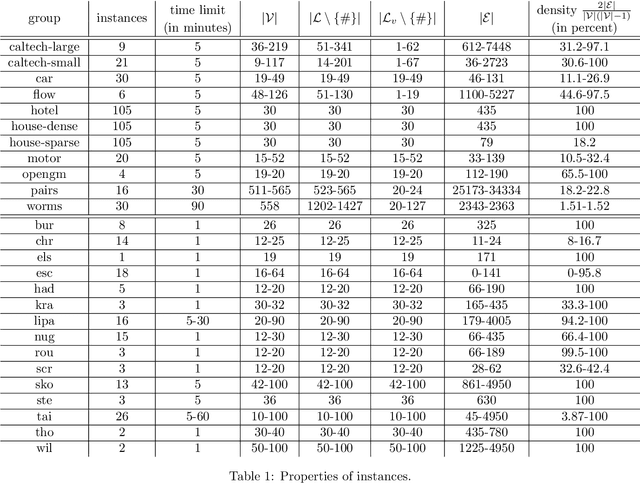
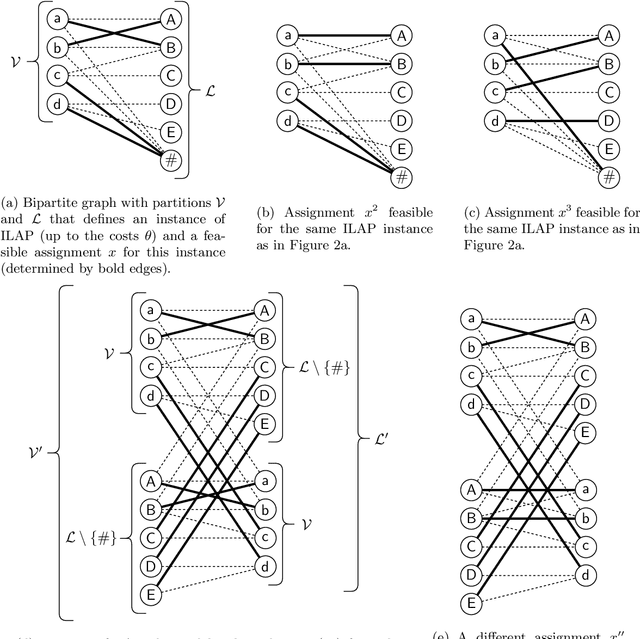
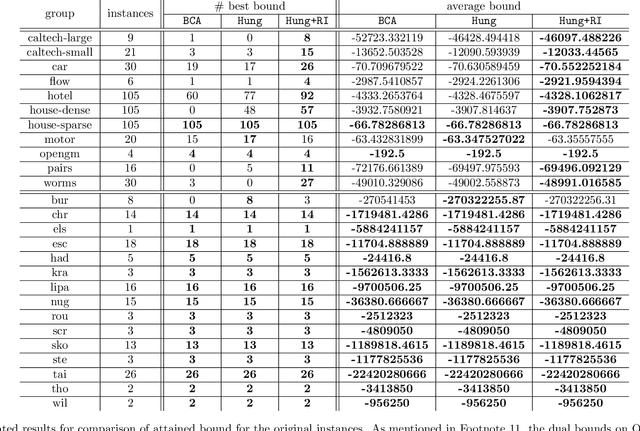
We study the set of optimal solutions of the dual linear programming formulation of the linear assignment problem (LAP) to propose a method for computing a solution from the relative interior of this set. Assuming that an arbitrary dual-optimal solution and an optimal assignment are available (for which many efficient algorithms already exist), our method computes a relative-interior solution in linear time. Since LAP occurs as a subproblem in the linear programming relaxation of quadratic assignment problem (QAP), we employ our method as a new component in the family of dual-ascent algorithms that provide bounds on the optimal value of QAP. To make our results applicable to incomplete QAP, which is of interest in practical use-cases, we also provide a linear-time reduction from incomplete LAP to complete LAP along with a mapping that preserves optimality and membership in the relative interior. Our experiments on publicly available benchmarks indicate that our approach with relative-interior solution is frequently capable of providing superior bounds and otherwise is at least comparable.
An Aligned Multi-Temporal Multi-Resolution Satellite Image Dataset for Change Detection Research
Feb 23, 2023
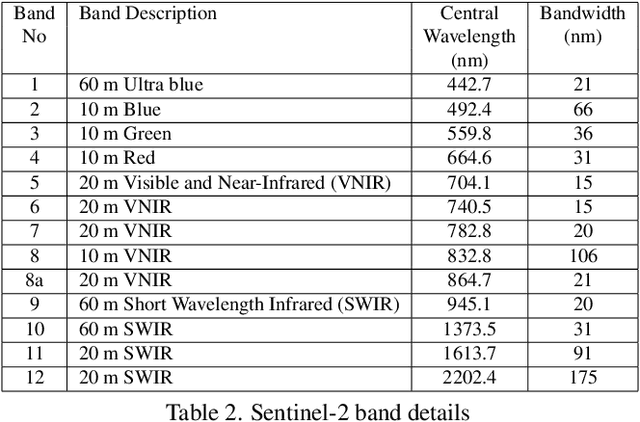
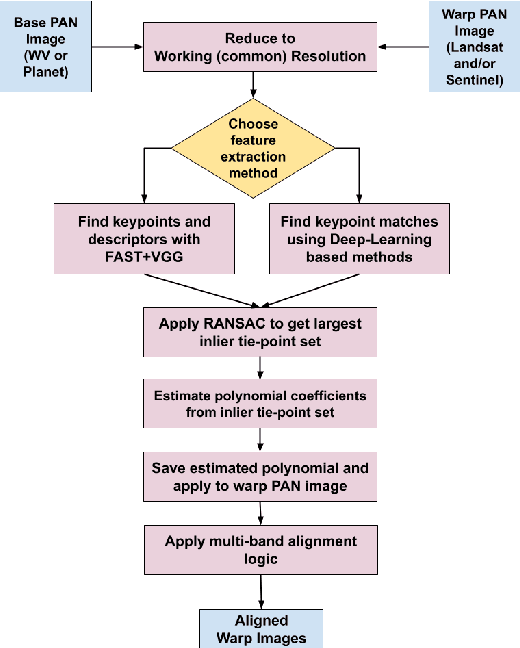
This paper presents an aligned multi-temporal and multi-resolution satellite image dataset for research in change detection. We expect our dataset to be useful to researchers who want to fuse information from multiple satellites for detecting changes on the surface of the earth that may not be fully visible in any single satellite. The dataset we present was created by augmenting the SpaceNet-7 dataset with temporally parallel stacks of Landsat and Sentinel images. The SpaceNet-7 dataset consists of time-sequenced Planet images recorded over 101 AOIs (Areas-of-Interest). In our dataset, for each of the 60 AOIs that are meant for training, we augment the Planet datacube with temporally parallel datacubes of Landsat and Sentinel images. The temporal alignments between the high-res Planet images, on the one hand, and the Landsat and Sentinel images, on the other, are approximate since the temporal resolution for the Planet images is one month -- each image being a mosaic of the best data collected over a month. Whenever we have a choice regarding which Landsat and Sentinel images to pair up with the Planet images, we have chosen those that had the least cloud cover. A particularly important feature of our dataset is that the high-res and the low-res images are spatially aligned together with our MuRA framework presented in this paper. Foundational to the alignment calculation is the modeling of inter-satellite misalignment errors with polynomials as in NASA's AROP algorithm. We have named our dataset MuRA-T for the MuRA framework that is used for aligning the cross-satellite images and "T" for the temporal dimension in the dataset.
Deep Unfolding Hybrid Beamforming Designs for THz Massive MIMO Systems
Feb 23, 2023
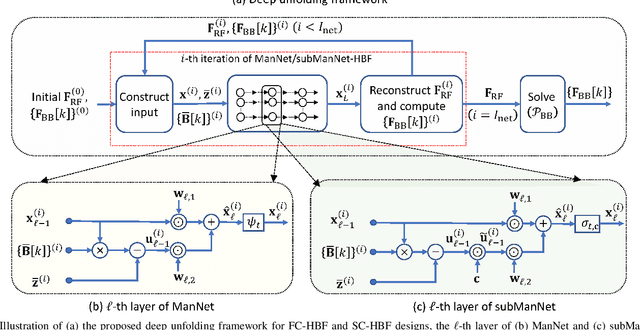
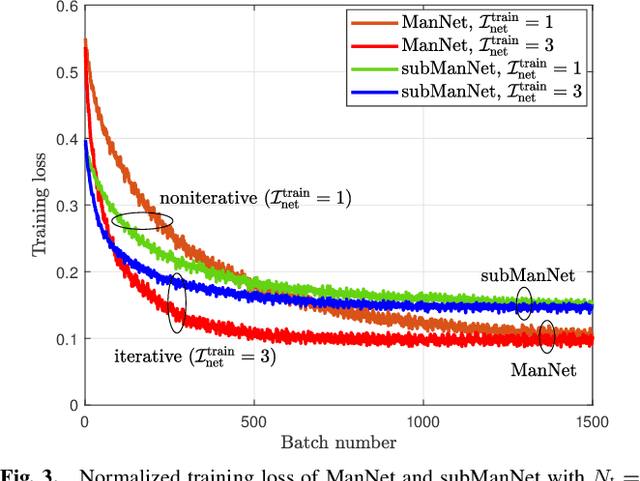
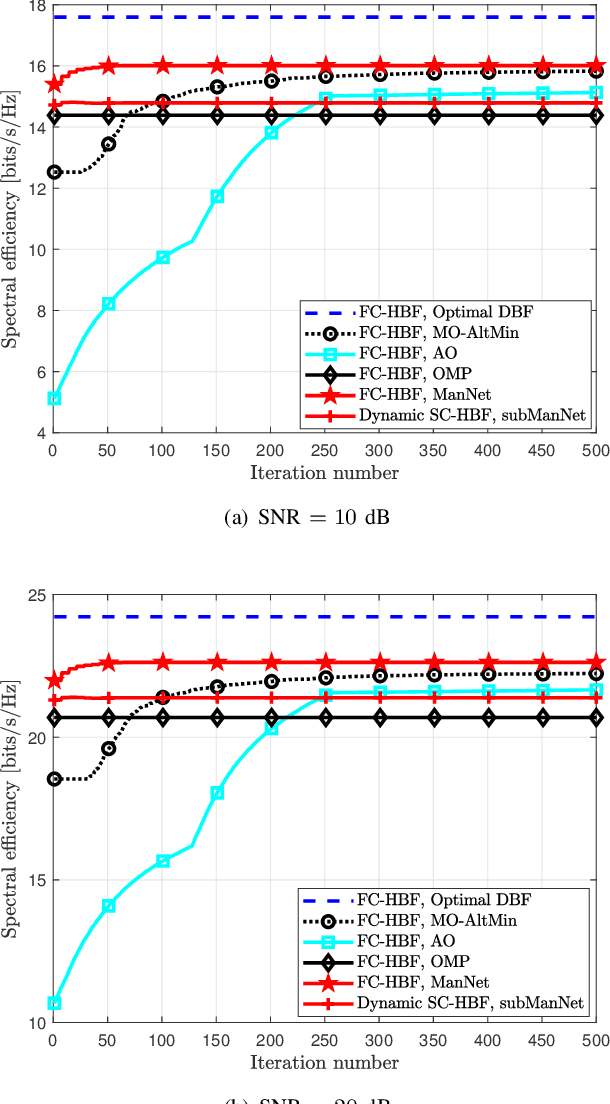
Hybrid beamforming (HBF) is a key enabler for wideband terahertz (THz) massive multiple-input multiple-output (mMIMO) communications systems. A core challenge with designing HBF systems stems from the fact their application often involves a non-convex, highly complex optimization of large dimensions. In this paper, we propose HBF schemes that leverage data to enable efficient designs for both the fully-connected HBF (FC-HBF) and dynamic sub-connected HBF (SC-HBF) architectures. We develop a deep unfolding framework based on factorizing the optimal fully digital beamformer into analog and digital terms and formulating two corresponding equivalent least squares (LS) problems. Then, the digital beamformer is obtained via a closed-form LS solution, while the analog beamformer is obtained via ManNet, a lightweight sparsely-connected deep neural network based on unfolding projected gradient descent. Incorporating ManNet into the developed deep unfolding framework leads to the ManNet-based FC-HBF scheme. We show that the proposed ManNet can also be applied to SC-HBF designs after determining the connections between the radio frequency chain and antennas. We further develop a simplified version of ManNet, referred to as subManNet, that directly produces the sparse analog precoder for SC-HBF architectures. Both networks are trained with an unsupervised training procedure. Numerical results verify that the proposed ManNet/subManNet-based HBF approaches outperform the conventional model-based and deep unfolded counterparts with very low complexity and a fast run time. For example, in a simulation with 128 transmit antennas, it attains a slightly higher spectral efficiency than the Riemannian manifold scheme, but over 1000 times faster and with a complexity reduction of more than by a factor of six (6).
Time Encoding via Unlimited Sampling: Theory, Algorithms and Hardware Validation
Aug 22, 2022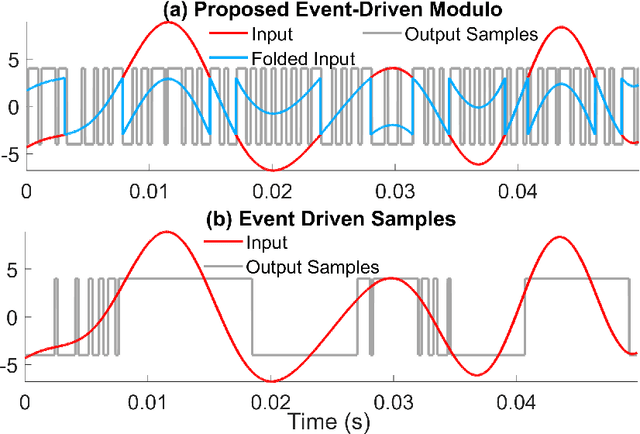
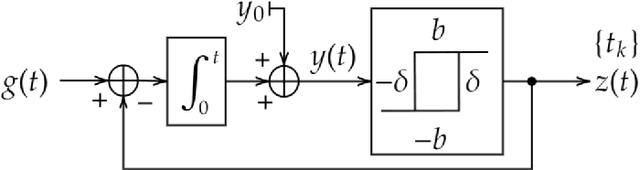
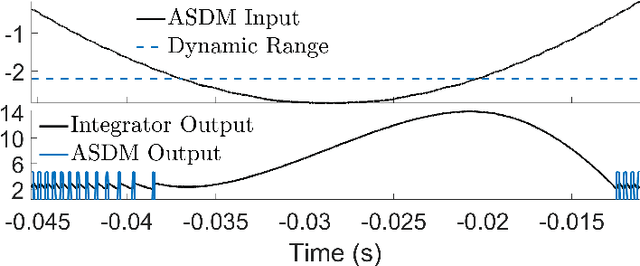
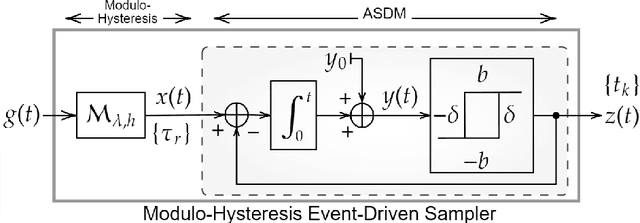
An alternative to conventional uniform sampling is that of time encoding, which converts continuous-time signals into streams of trigger times. This gives rise to Event-Driven Sampling (EDS) models. The data-driven nature of EDS acquisition is advantageous in terms of power consumption and time resolution and is inspired by the information representation in biological nervous systems. If an analog signal is outside a predefined dynamic range, then EDS generates a low density of trigger times, which in turn leads to recovery distortion due to aliasing. In this paper, inspired by the Unlimited Sensing Framework (USF), we propose a new EDS architecture that incorporates a modulo nonlinearity prior to acquisition that we refer to as the modulo EDS or MEDS. In MEDS, the modulo nonlinearity folds high dynamic range inputs into low dynamic range amplitudes, thus avoiding recovery distortion. In particular, we consider the asynchronous sigma-delta modulator (ASDM), previously used for low power analog-to-digital conversion. This novel MEDS based acquisition is enabled by a recent generalization of the modulo nonlinearity called modulo-hysteresis. We design a mathematically guaranteed recovery algorithm for bandlimited inputs based on a sampling rate criterion and provide reconstruction error bounds. We go beyond numerical experiments and also provide a first hardware validation of our approach, thus bridging the gap between theory and practice, while corroborating the conceptual underpinnings of our work.
An Out-of-Domain Synapse Detection Challenge for Microwasp Brain Connectomes
Feb 01, 2023

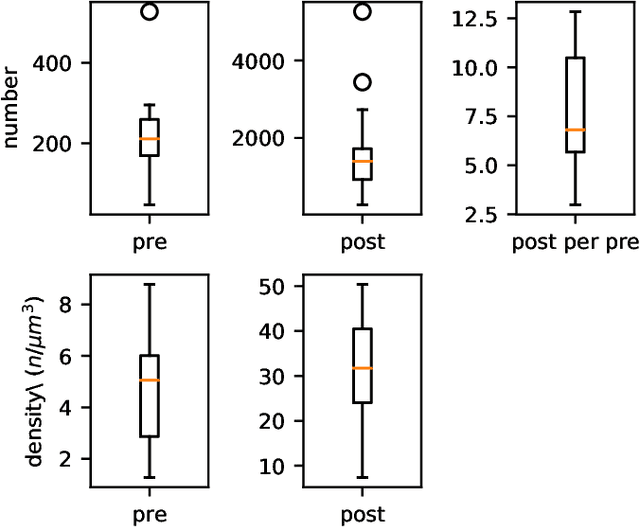

The size of image stacks in connectomics studies now reaches the terabyte and often petabyte scales with a great diversity of appearance across brain regions and samples. However, manual annotation of neural structures, e.g., synapses, is time-consuming, which leads to limited training data often smaller than 0.001\% of the test data in size. Domain adaptation and generalization approaches were proposed to address similar issues for natural images, which were less evaluated on connectomics data due to a lack of out-of-domain benchmarks.
Deep active learning for nonlinear system identification
Feb 24, 2023



The exploding research interest for neural networks in modeling nonlinear dynamical systems is largely explained by the networks' capacity to model complex input-output relations directly from data. However, they typically need vast training data before they can be put to any good use. The data generation process for dynamical systems can be an expensive endeavor both in terms of time and resources. Active learning addresses this shortcoming by acquiring the most informative data, thereby reducing the need to collect enormous datasets. What makes the current work unique is integrating the deep active learning framework into nonlinear system identification. We formulate a general static deep active learning acquisition problem for nonlinear system identification. This is enabled by exploring system dynamics locally in different regions of the input space to obtain a simulated dataset covering the broader input space. This simulated dataset can be used in a static deep active learning acquisition scheme referred to as global explorations. The global exploration acquires a batch of initial states corresponding to the most informative state-action trajectories according to a batch acquisition function. The local exploration solves an optimal control problem, finding the control trajectory that maximizes some measure of information. After a batch of informative initial states is acquired, a new round of local explorations from the initial states in the batch is conducted to obtain a set of corresponding control trajectories that are to be applied on the system dynamics to get data from the system. Information measures used in the acquisition scheme are derived from the predictive variance of an ensemble of neural networks. The novel method outperforms standard data acquisition methods used for system identification of nonlinear dynamical systems in the case study performed on simulated data.