 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time to Cite: Modeling Citation Networks using the Dynamic Impact Single-Event Embedding Model
Feb 28, 2024
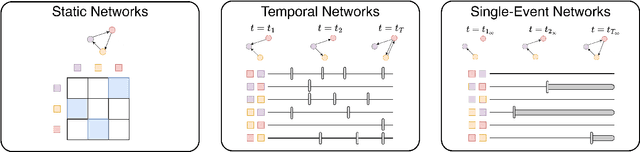

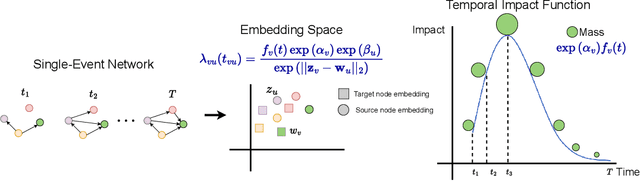
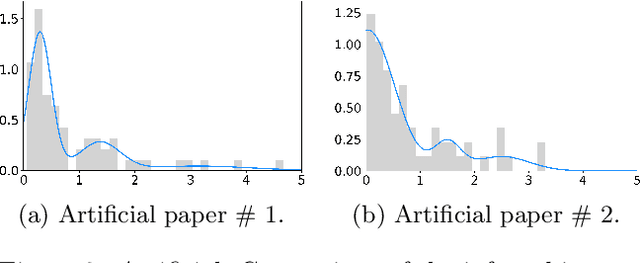
Understanding the structure and dynamics of scientific research, i.e., the science of science (SciSci), has become an important area of research in order to address imminent questions including how scholars interact to advance science, how disciplines are related and evolve, and how research impact can be quantified and predicted. Central to the study of SciSci has been the analysis of citation networks. Here, two prominent modeling methodologies have been employed: one is to assess the citation impact dynamics of papers using parametric distributions, and the other is to embed the citation networks in a latent space optimal for characterizing the static relations between papers in terms of their citations. Interestingly, citation networks are a prominent example of single-event dynamic networks, i.e., networks for which each dyad only has a single event (i.e., the point in time of citation). We presently propose a novel likelihood function for the characterization of such single-event networks. Using this likelihood, we propose the Dynamic Impact Single-Event Embedding model (DISEE). The \textsc{\modelabbrev} model characterizes the scientific interactions in terms of a latent distance model in which random effects account for citation heterogeneity while the time-varying impact is characterized using existing parametric representations for assessment of dynamic impact. We highlight the proposed approach on several real citation networks finding that the DISEE well reconciles static latent distance network embedding approaches with classical dynamic impact assessments.
FastVideoEdit: Leveraging Consistency Models for Efficient Text-to-Video Editing
Mar 10, 2024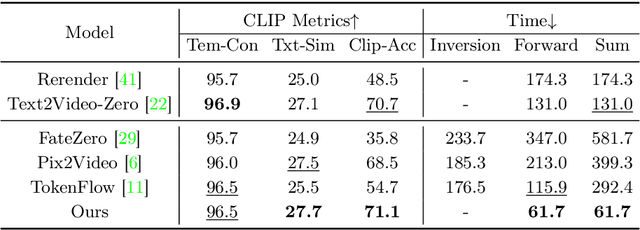
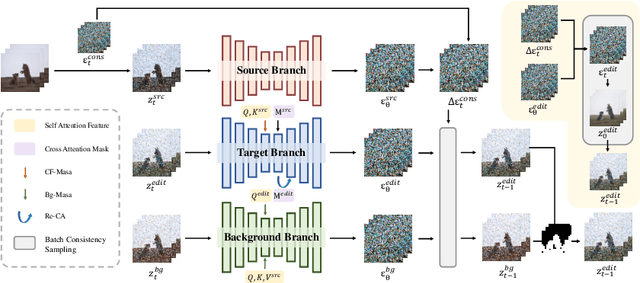

Diffusion models have demonstrated remarkable capabilities in text-to-image and text-to-video generation, opening up possibilities for video editing based on textual input. However, the computational cost associated with sequential sampling in diffusion models poses challenges for efficient video editing. Existing approaches relying on image generation models for video editing suffer from time-consuming one-shot fine-tuning, additional condition extraction, or DDIM inversion, making real-time applications impractical. In this work, we propose FastVideoEdit, an efficient zero-shot video editing approach inspired by Consistency Models (CMs). By leveraging the self-consistency property of CMs, we eliminate the need for time-consuming inversion or additional condition extraction, reducing editing time. Our method enables direct mapping from source video to target video with strong preservation ability utilizing a special variance schedule. This results in improved speed advantages, as fewer sampling steps can be used while maintaining comparable generation quality. Experimental results validate the state-of-the-art performance and speed advantages of FastVideoEdit across evaluation metrics encompassing editing speed, temporal consistency, and text-video alignment.
CoroNetGAN: Controlled Pruning of GANs via Hypernetworks
Mar 13, 2024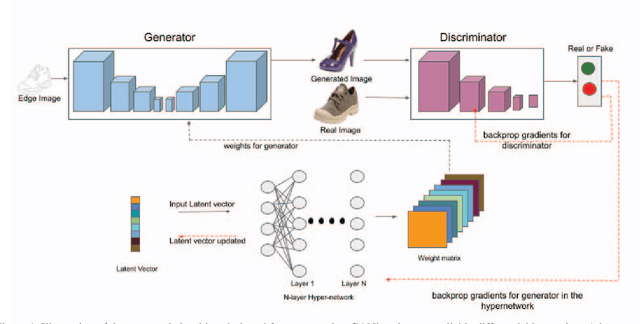
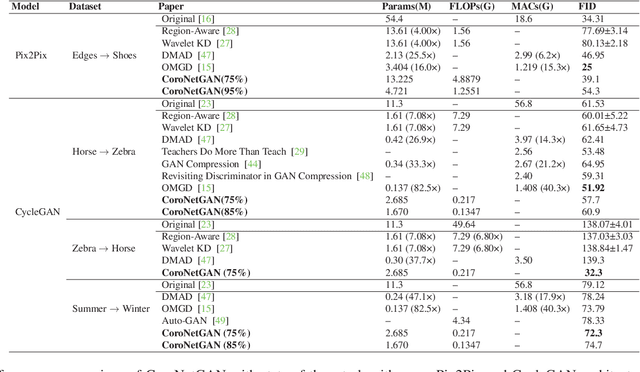
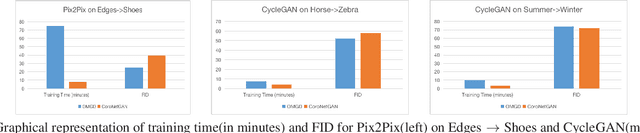

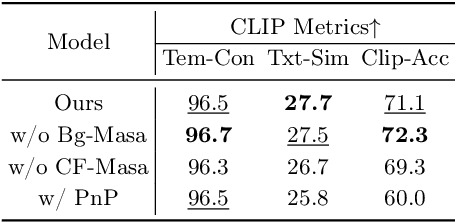
Generative Adversarial Networks (GANs) have proven to exhibit remarkable performance and are widely used across many generative computer vision applications. However, the unprecedented demand for the deployment of GANs on resource-constrained edge devices still poses a challenge due to huge number of parameters involved in the generation process. This has led to focused attention on the area of compressing GANs. Most of the existing works use knowledge distillation with the overhead of teacher dependency. Moreover, there is no ability to control the degree of compression in these methods. Hence, we propose CoroNet-GAN for compressing GAN using the combined strength of differentiable pruning method via hypernetworks. The proposed method provides the advantage of performing controllable compression while training along with reducing training time by a substantial factor. Experiments have been done on various conditional GAN architectures (Pix2Pix and CycleGAN) to signify the effectiveness of our approach on multiple benchmark datasets such as Edges-to-Shoes, Horse-to-Zebra and Summer-to-Winter. The results obtained illustrate that our approach succeeds to outperform the baselines on Zebra-to-Horse and Summer-to-Winter achieving the best FID score of 32.3 and 72.3 respectively, yielding high-fidelity images across all the datasets. Additionally, our approach also outperforms the state-of-the-art methods in achieving better inference time on various smart-phone chipsets and data-types making it a feasible solution for deployment on edge devices.
MGIC: A Multi-Label Gradient Inversion Attack based on Canny Edge Detection on Federated Learning
Mar 13, 2024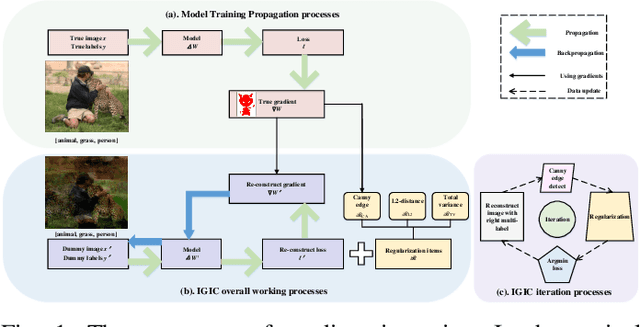
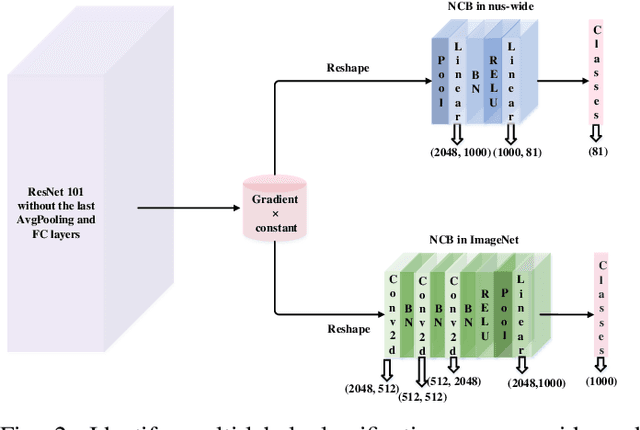


As a new distributed computing framework that can protect data privacy, federated learning (FL) has attracted more and more attention in recent years. It receives gradients from users to train the global model and releases the trained global model to working users. Nonetheless, the gradient inversion (GI) attack reflects the risk of privacy leakage in federated learning. Attackers only need to use gradients through hundreds of thousands of simple iterations to obtain relatively accurate private data stored on users' local devices. For this, some works propose simple but effective strategies to obtain user data under a single-label dataset. However, these strategies induce a satisfactory visual effect of the inversion image at the expense of higher time costs. Due to the semantic limitation of a single label, the image obtained by gradient inversion may have semantic errors. We present a novel gradient inversion strategy based on canny edge detection (MGIC) in both the multi-label and single-label datasets. To reduce semantic errors caused by a single label, we add new convolution layers' blocks in the trained model to obtain the image's multi-label. Through multi-label representation, serious semantic errors in inversion images are reduced. Then, we analyze the impact of parameters on the difficulty of input image reconstruction and discuss how image multi-subjects affect the inversion performance. Our proposed strategy has better visual inversion image results than the most widely used ones, saving more than 78% of time costs in the ImageNet dataset.
The Impact Of Bug Localization Based on Crash Report Mining: A Developers' Perspective
Mar 16, 2024
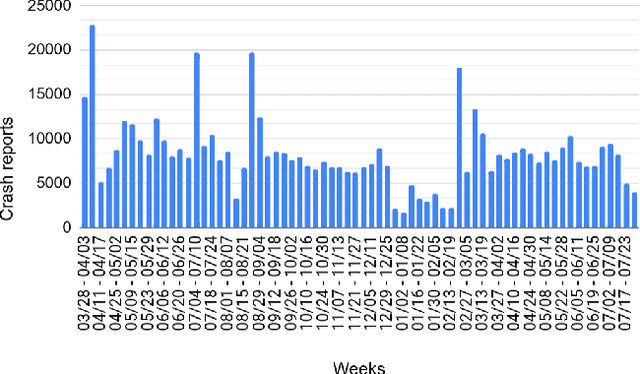
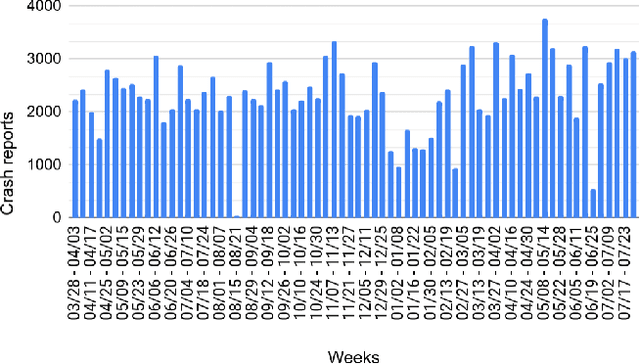
Developers often use crash reports to understand the root cause of bugs. However, locating the buggy source code snippet from such information is a challenging task, mainly when the log database contains many crash reports. To mitigate this issue, recent research has proposed and evaluated approaches for grouping crash report data and using stack trace information to locate bugs. The effectiveness of such approaches has been evaluated by mainly comparing the candidate buggy code snippets with the actual changed code in bug-fix commits -- which happens in the context of retrospective repository mining studies. Therefore, the existing literature still lacks discussing the use of such approaches in the daily life of a software company, which could explain the developers' perceptions on the use of these approaches. In this paper, we report our experience of using an approach for grouping crash reports and finding buggy code on a weekly basis for 18 months, within three development teams in a software company. We grouped over 750,000 crash reports, opened over 130 issues, and collected feedback from 18 developers and team leaders. Among other results, we observe that the amount of system logs related to a crash report group is not the only criteria developers use to choose a candidate bug to be analyzed. Instead, other factors were considered, such as the need to deliver customer-prioritized features and the difficulty of solving complex crash reports (e.g., architectural debts), to cite some. The approach investigated in this study correctly suggested the buggy file most of the time -- the approach's precision was around 80%. In this study, the developers also shared their perspectives on the usefulness of the suspicious files and methods extracted from crash reports to fix related bugs.
Better Understandings and Configurations in MaxSAT Local Search Solvers via Anytime Performance Analysis
Mar 11, 2024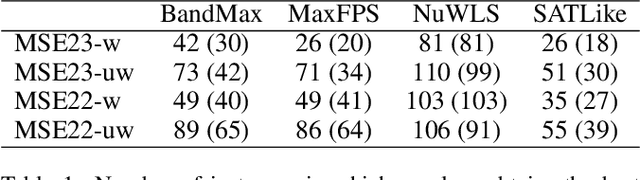
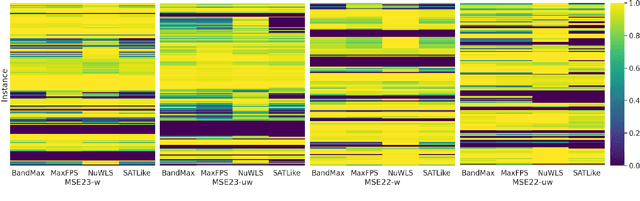
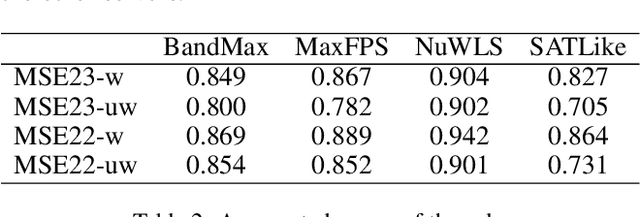
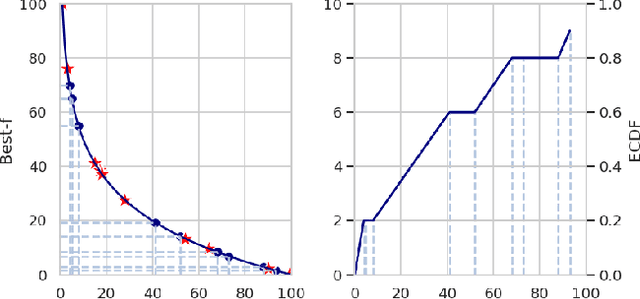
Though numerous solvers have been proposed for the MaxSAT problem, and the benchmark environment such as MaxSAT Evaluations provides a platform for the comparison of the state-of-the-art solvers, existing assessments were usually evaluated based on the quality, e.g., fitness, of the best-found solutions obtained within a given running time budget. However, concerning solely the final obtained solutions regarding specific time budgets may restrict us from comprehending the behavior of the solvers along the convergence process. This paper demonstrates that Empirical Cumulative Distribution Functions can be used to compare MaxSAT local search solvers' anytime performance across multiple problem instances and various time budgets. The assessment reveals distinctions in solvers' performance and displays that the (dis)advantages of solvers adjust along different running times. This work also exhibits that the quantitative and high variance assessment of anytime performance can guide machines, i.e., automatic configurators, to search for better parameter settings. Our experimental results show that the hyperparameter optimization tool, i.e., SMAC, generally achieves better parameter settings of local search when using the anytime performance as the cost function, compared to using the fitness of the best-found solutions.
Towards the Reusability and Compositionality of Causal Representations
Mar 14, 2024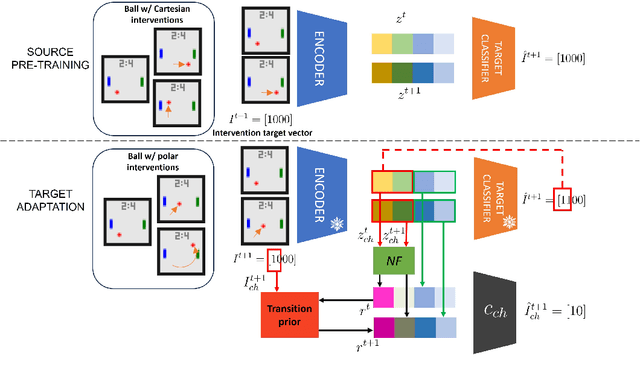
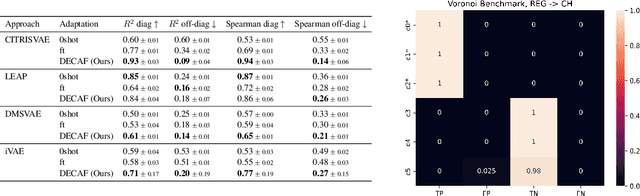
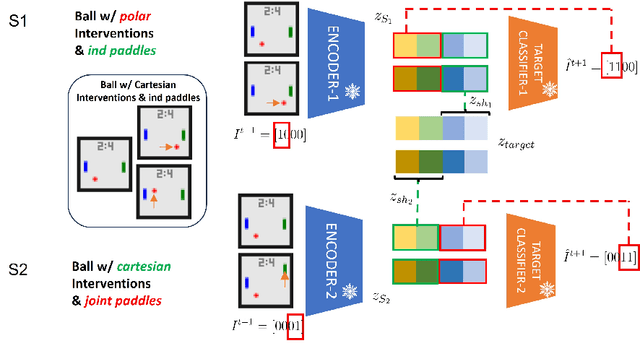

Causal Representation Learning (CRL) aims at identifying high-level causal factors and their relationships from high-dimensional observations, e.g., images. While most CRL works focus on learning causal representations in a single environment, in this work we instead propose a first step towards learning causal representations from temporal sequences of images that can be adapted in a new environment, or composed across multiple related environments. In particular, we introduce DECAF, a framework that detects which causal factors can be reused and which need to be adapted from previously learned causal representations. Our approach is based on the availability of intervention targets, that indicate which variables are perturbed at each time step. Experiments on three benchmark datasets show that integrating our framework with four state-of-the-art CRL approaches leads to accurate representations in a new environment with only a few samples.
PDETime: Rethinking Long-Term Multivariate Time Series Forecasting from the perspective of partial differential equations
Feb 25, 2024Recent advancements in deep learning have led to the development of various models for long-term multivariate time-series forecasting (LMTF), many of which have shown promising results. Generally, the focus has been on historical-value-based models, which rely on past observations to predict future series. Notably, a new trend has emerged with time-index-based models, offering a more nuanced understanding of the continuous dynamics underlying time series. Unlike these two types of models that aggregate the information of spatial domains or temporal domains, in this paper, we consider multivariate time series as spatiotemporal data regularly sampled from a continuous dynamical system, which can be represented by partial differential equations (PDEs), with the spatial domain being fixed. Building on this perspective, we present PDETime, a novel LMTF model inspired by the principles of Neural PDE solvers, following the encoding-integration-decoding operations. Our extensive experimentation across seven diverse real-world LMTF datasets reveals that PDETime not only adapts effectively to the intrinsic spatiotemporal nature of the data but also sets new benchmarks, achieving state-of-the-art results
RAFT: Adapting Language Model to Domain Specific RAG
Mar 15, 2024
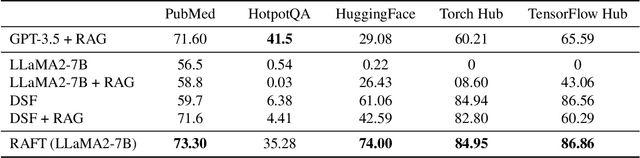
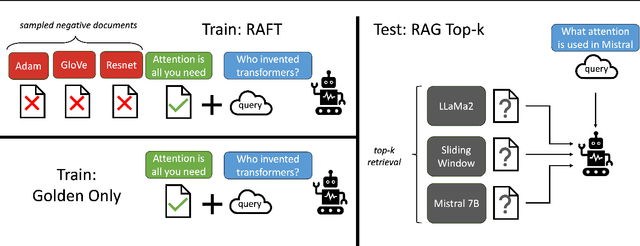
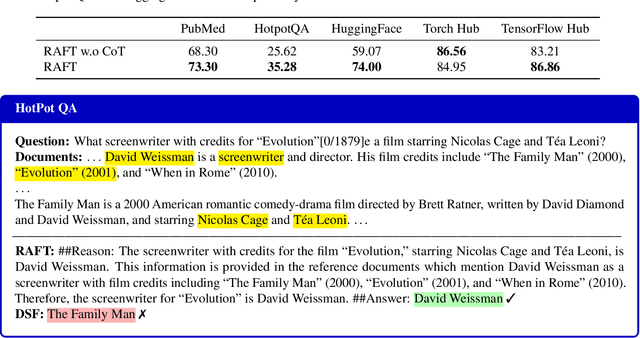
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a "open-book" in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
Lifelong Person Re-Identification with Backward-Compatibility
Mar 15, 2024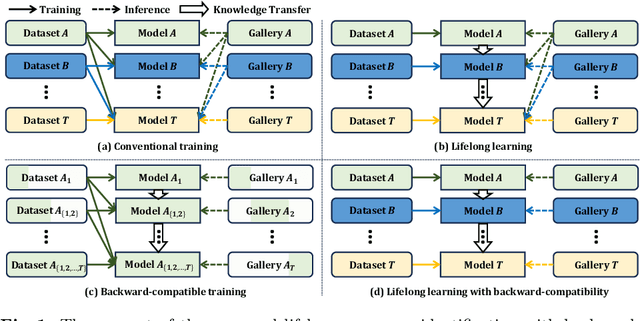
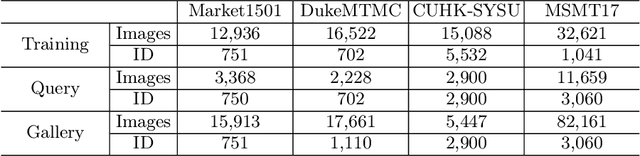
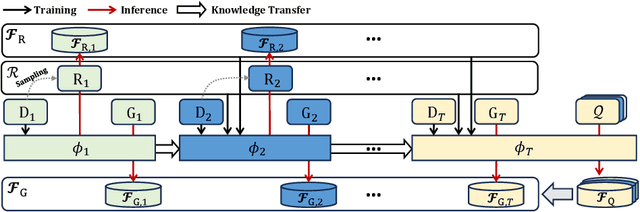
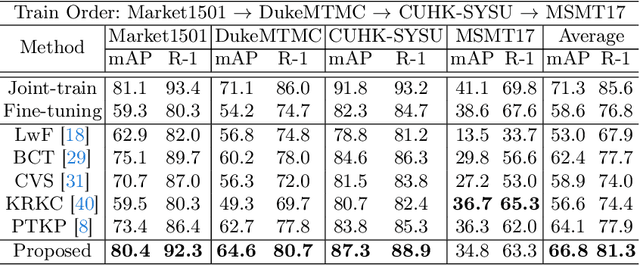
Lifelong person re-identification (LReID) assumes a practical scenario where the model is sequentially trained on continuously incoming datasets while alleviating the catastrophic forgetting in the old datasets. However, not only the training datasets but also the gallery images are incrementally accumulated, that requires a huge amount of computational complexity and storage space to extract the features at the inference phase. In this paper, we address the above mentioned problem by incorporating the backward-compatibility to LReID for the first time. We train the model using the continuously incoming datasets while maintaining the model's compatibility toward the previously trained old models without re-computing the features of the old gallery images. To this end, we devise the cross-model compatibility loss based on the contrastive learning with respect to the replay features across all the old datasets. Moreover, we also develop the knowledge consolidation method based on the part classification to learn the shared representation across different datasets for the backward-compatibility. We suggest a more practical methodology for performance evaluation as well where all the gallery and query images are considered together. Experimental results demonstrate that the proposed method achieves a significantly higher performance of the backward-compatibility compared with the existing methods. It is a promising tool for more practical scenarios of LReID.