 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Neuromorphic Dataset for Object Segmentation in Indoor Cluttered Environment
Feb 13, 2023
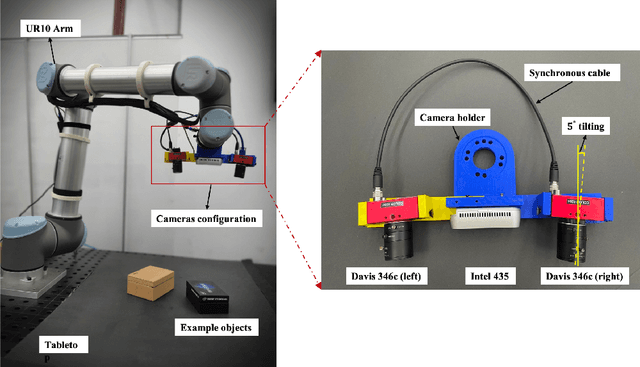
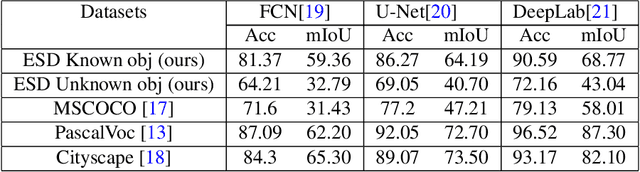
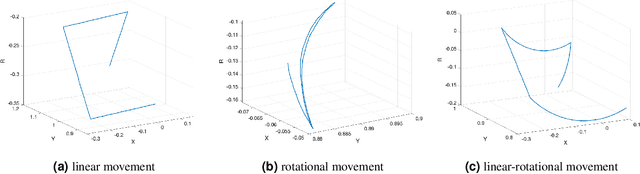

Taking advantage of an event-based camera, the issues of motion blur, low dynamic range and low time sampling of standard cameras can all be addressed. However, there is a lack of event-based datasets dedicated to the benchmarking of segmentation algorithms, especially those that provide depth information which is critical for segmentation in occluded scenes. This paper proposes a new Event-based Segmentation Dataset (ESD), a high-quality 3D spatial and temporal dataset for object segmentation in an indoor cluttered environment. Our proposed dataset ESD comprises 145 sequences with 14,166 RGB frames that are manually annotated with instance masks. Overall 21.88 million and 20.80 million events from two event-based cameras in a stereo-graphic configuration are collected, respectively. To the best of our knowledge, this densely annotated and 3D spatial-temporal event-based segmentation benchmark of tabletop objects is the first of its kind. By releasing ESD, we expect to provide the community with a challenging segmentation benchmark with high quality.
Multi-Agent Path Integral Control for Interaction-Aware Motion Planning in Urban Canals
Feb 13, 2023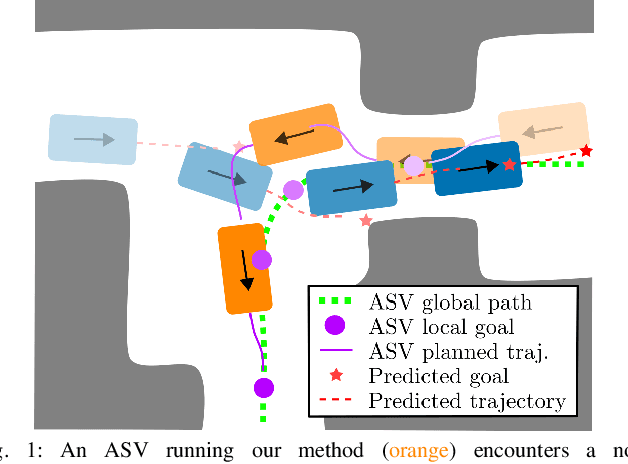
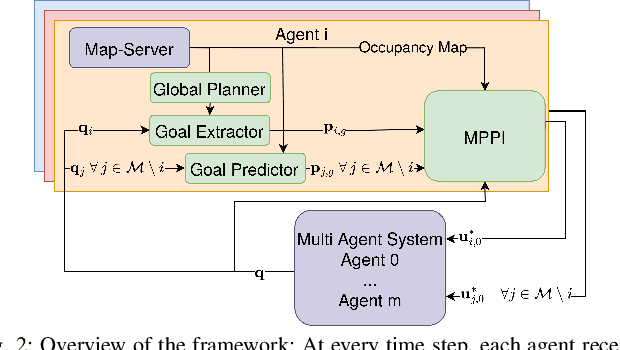
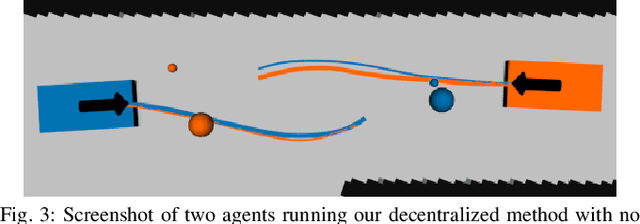
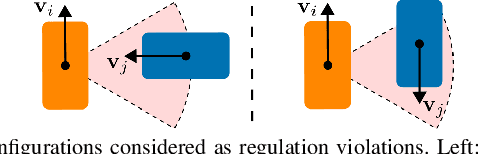
Autonomous vehicles that operate in urban environments shall comply with existing rules and reason about the interactions with other decision-making agents. In this paper, we introduce a decentralized and communication-free interaction-aware motion planner and apply it to Autonomous Surface Vessels (ASVs) in urban canals. We build upon a sampling-based method, namely Model Predictive Path Integral control (MPPI), and employ it to, in each time instance, compute both a collision-free trajectory for the vehicle and a prediction of other agents' trajectories, thus modeling interactions. To improve the method's efficiency in multi-agent scenarios, we introduce a two-stage sample evaluation strategy and define an appropriate cost function to achieve rule compliance. We evaluate this decentralized approach in simulations with multiple vessels in real scenarios extracted from Amsterdam's canals, showing superior performance than a state-of-the-art trajectory optimization framework and robustness when encountering different types of agents.
The Framework Tax: Disparities Between Inference Efficiency in Research and Deployment
Feb 13, 2023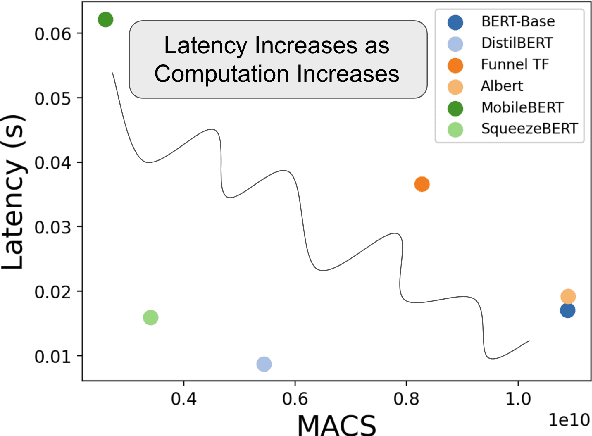
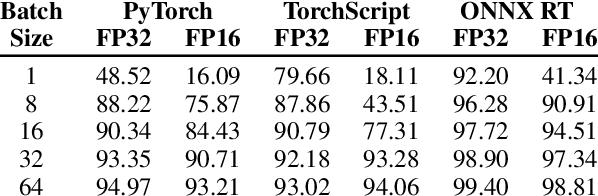

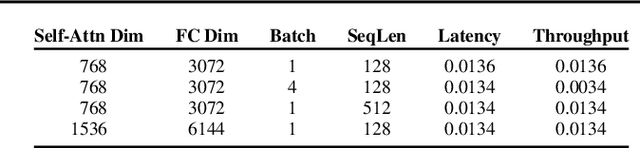
Increased focus on the deployment of machine learning systems has led to rapid improvements in hardware accelerator performance and neural network model efficiency. However, the resulting reductions in floating point operations and increases in computational throughput of accelerators have not directly translated to improvements in real-world inference latency. We demonstrate that these discrepancies can be largely attributed to mis-alignments between model architectures and the capabilities of underlying hardware due to bottlenecks introduced by deep learning frameworks. We denote this phenomena as the \textit{framework tax}, and observe that the disparity is growing as hardware speed increases over time. In this work, we examine this phenomena through a series of case studies analyzing the effects of model design decisions, framework paradigms, and hardware platforms on total model latency. Based on our findings, we provide actionable recommendations to ML researchers and practitioners aimed at narrowing the gap between efficient ML model research and practice.
Deep Learning Predicts Prevalent and Incident Parkinson's Disease From UK Biobank Fundus Imaging
Feb 13, 2023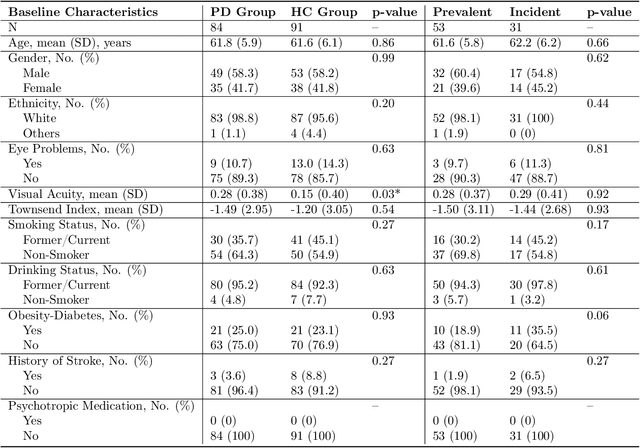

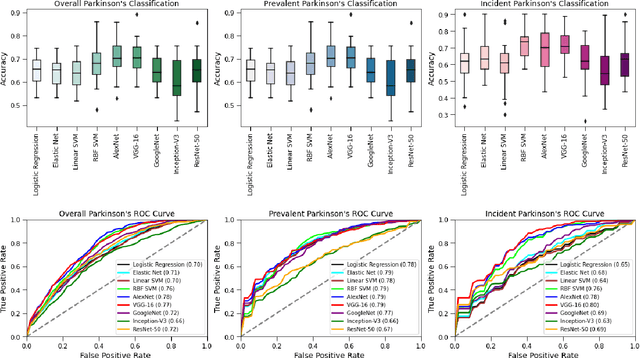

Parkinson's disease is the world's fastest growing neurological disorder. Research to elucidate the mechanisms of Parkinson's disease and automate diagnostics would greatly improve the treatment of patients with Parkinson's disease. Current diagnostic methods are expensive with limited availability. Considering the long progression time of Parkinson's disease, a desirable screening should be diagnostically accurate even before the onset of symptoms to allow medical intervention. We promote attention for retinal fundus imaging, often termed a window to the brain, as a diagnostic screening modality for Parkinson's disease. We conduct a systematic evaluation of conventional machine learning and deep learning techniques to classify Parkinson's disease from UK Biobank fundus imaging. Our results suggest Parkinson's disease individuals can be differentiated from age and gender matched healthy subjects with 71% accuracy. This accuracy is maintained when predicting either prevalent or incident Parkinson's disease. Explainability and trustworthiness is enhanced by visual attribution maps of localized biomarkers and quantified metrics of model robustness to data perturbations.
Privacy Performance of MIMO Dual-Functional Radar-Communications with Internal Adversary
Feb 13, 2023
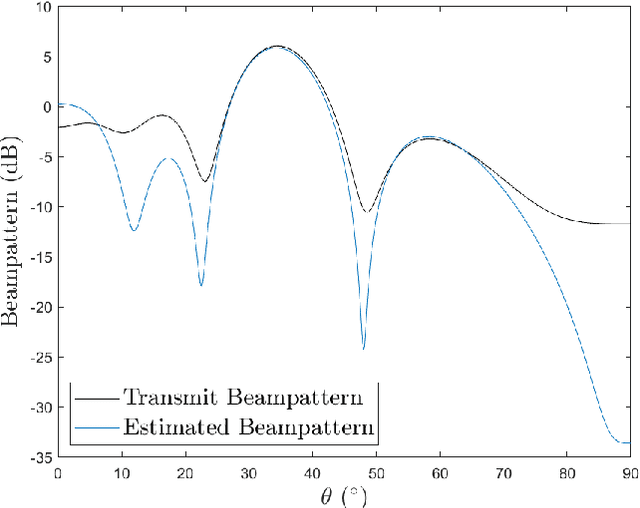
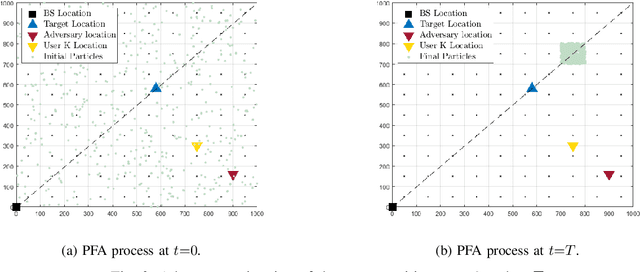
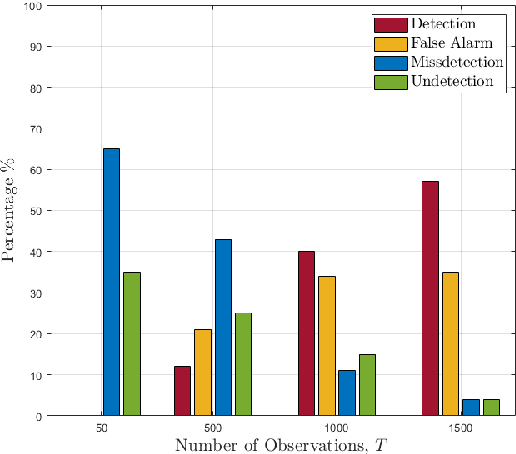
The co-design of radar sensing and communications in dual-functional radar communication systems brings promising advantages for next generation wireless networks by providing gains in terms of the efficient and flexible use of spectrum, reduced costs, and lower energy consumption than in two separate systems. Besides the challenges associated with the conciliation of the conflicting requirements to perform wireless communication and radar sensing in a real-time cooperation, privacy issues represent a cause of concern as the co-design can let the network prone to active attacks. This paper tackles this issue by evaluating the associated privacy risks with the design of transmit precoders that simultaneously optimise both the radar transmit beampattern and the signal-to-interference-plus-noise at the communication users. Our results show that if a malicious user can infer the transmitted precoder matrix with a certain accuracy, there is a reasonable risk of exposure of the location of the target and privacy breaches.
Prompt Stealing Attacks Against Text-to-Image Generation Models
Feb 20, 2023
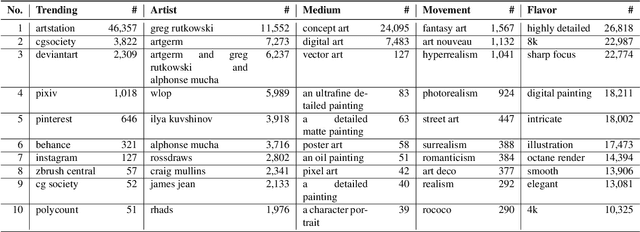


Text-to-Image generation models have revolutionized the artwork design process and enabled anyone to create high-quality images by entering text descriptions called prompts. Creating a high-quality prompt that consists of a subject and several modifiers can be time-consuming and costly. In consequence, a trend of trading high-quality prompts on specialized marketplaces has emerged. In this paper, we propose a novel attack, namely prompt stealing attack, which aims to steal prompts from generated images by text-to-image generation models. Successful prompt stealing attacks direct violate the intellectual property and privacy of prompt engineers and also jeopardize the business model of prompt trading marketplaces. We first perform a large-scale analysis on a dataset collected by ourselves and show that a successful prompt stealing attack should consider a prompt's subject as well as its modifiers. We then propose the first learning-based prompt stealing attack, PromptStealer, and demonstrate its superiority over two baseline methods quantitatively and qualitatively. We also make some initial attempts to defend PromptStealer. In general, our study uncovers a new attack surface in the ecosystem created by the popular text-to-image generation models. We hope our results can help to mitigate the threat. To facilitate research in this field, we will share our dataset and code with the community.
Learning Deep Semantics for Test Completion
Feb 20, 2023
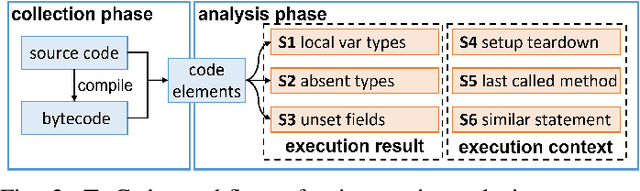
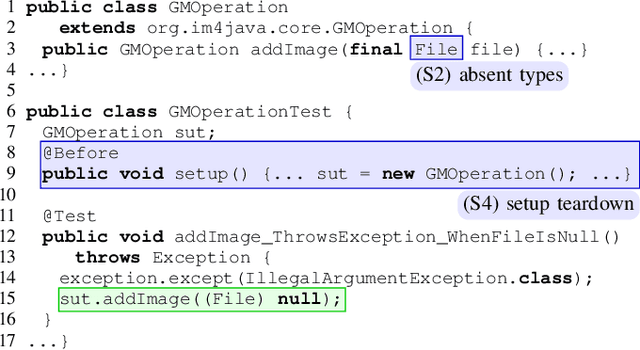
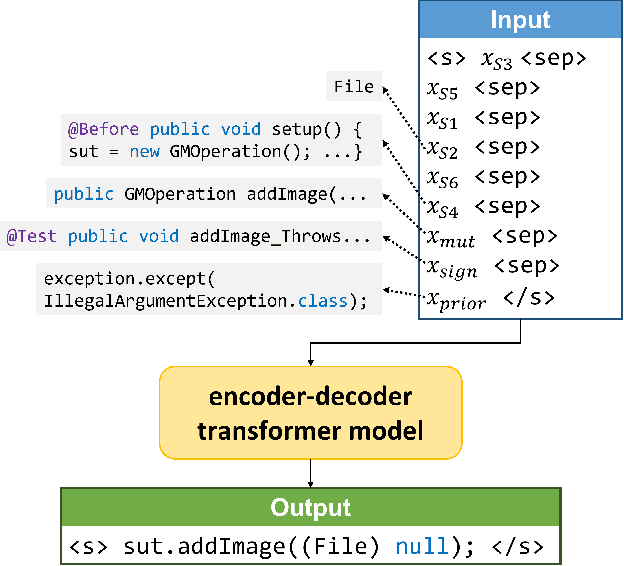
Writing tests is a time-consuming yet essential task during software development. We propose to leverage recent advances in deep learning for text and code generation to assist developers in writing tests. We formalize the novel task of test completion to automatically complete the next statement in a test method based on the context of prior statements and the code under test. We develop TeCo -- a deep learning model using code semantics for test completion. The key insight underlying TeCo is that predicting the next statement in a test method requires reasoning about code execution, which is hard to do with only syntax-level data that existing code completion models use. TeCo extracts and uses six kinds of code semantics data, including the execution result of prior statements and the execution context of the test method. To provide a testbed for this new task, as well as to evaluate TeCo, we collect a corpus of 130,934 test methods from 1,270 open-source Java projects. Our results show that TeCo achieves an exact-match accuracy of 18, which is 29% higher than the best baseline using syntax-level data only. When measuring functional correctness of generated next statement, TeCo can generate runnable code in 29% of the cases compared to 18% obtained by the best baseline. Moreover, TeCo is significantly better than prior work on test oracle generation.
Boosting classification reliability of NLP transformer models in the long run
Feb 20, 2023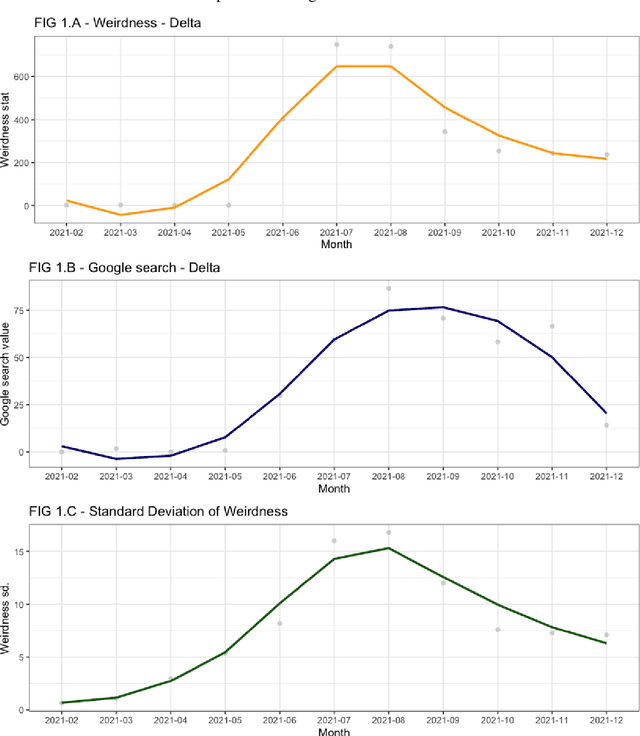
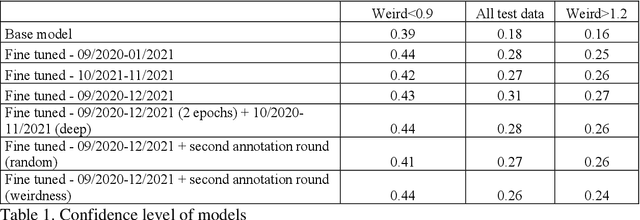
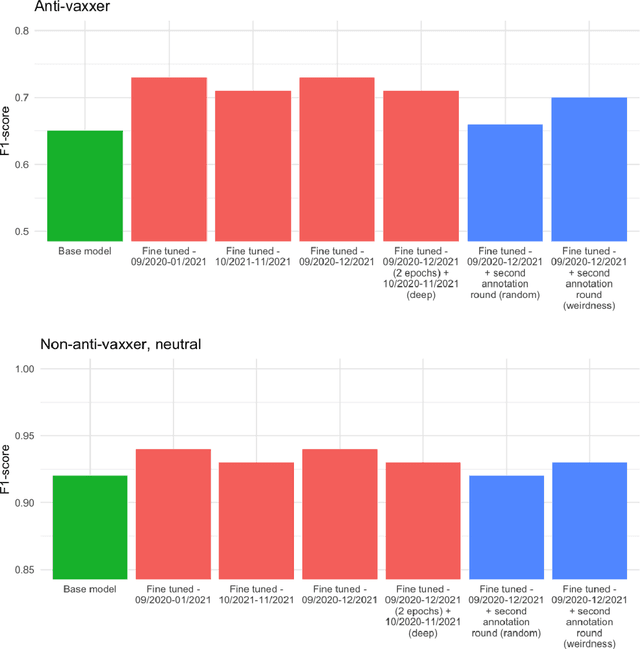
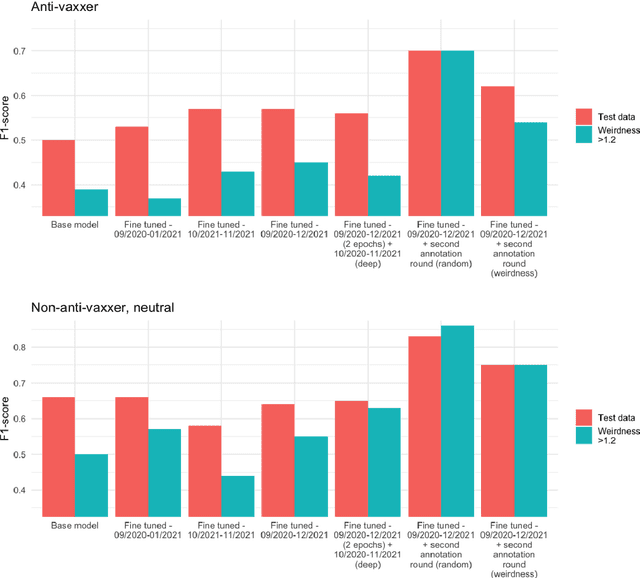
Transformer-based machine learning models have become an essential tool for many natural language processing (NLP) tasks since the introduction of the method. A common objective of these projects is to classify text data. Classification models are often extended to a different topic and/or time period. In these situations, deciding how long a classification is suitable for and when it is worth re-training our model is difficult. This paper compares different approaches to fine-tune a BERT model for a long-running classification task. We use data from different periods to fine-tune our original BERT model, and we also measure how a second round of annotation could boost the classification quality. Our corpus contains over 8 million comments on COVID-19 vaccination in Hungary posted between September 2020 and December 2021. Our results show that the best solution is using all available unlabeled comments to fine-tune a model. It is not advisable to focus only on comments containing words that our model has not encountered before; a more efficient solution is randomly sample comments from the new period. Fine-tuning does not prevent the model from losing performance but merely slows it down. In a rapidly changing linguistic environment, it is not possible to maintain model performance without regularly annotating new text.
Deep Reinforcement Learning for Cost-Effective Medical Diagnosis
Feb 20, 2023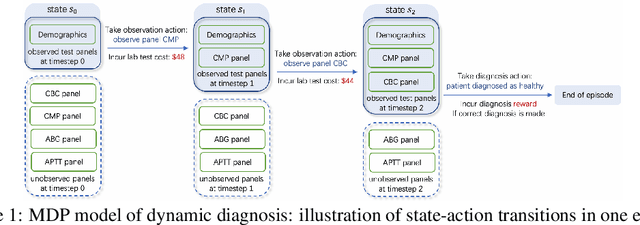

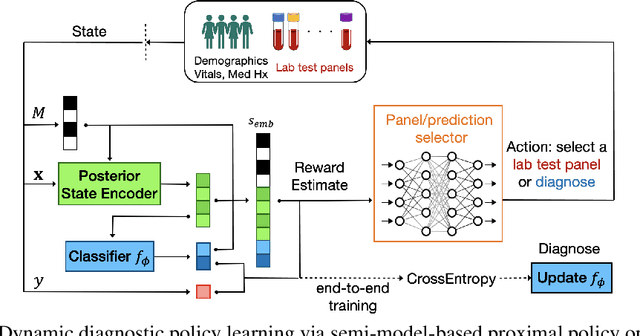
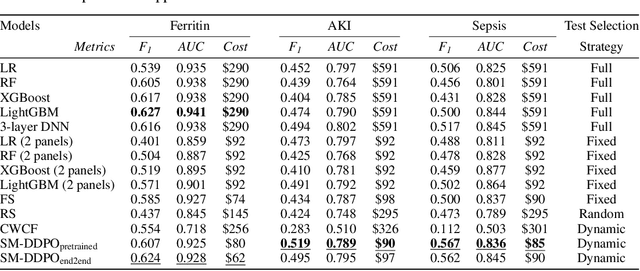
Dynamic diagnosis is desirable when medical tests are costly or time-consuming. In this work, we use reinforcement learning (RL) to find a dynamic policy that selects lab test panels sequentially based on previous observations, ensuring accurate testing at a low cost. Clinical diagnostic data are often highly imbalanced; therefore, we aim to maximize the $F_1$ score instead of the error rate. However, optimizing the non-concave $F_1$ score is not a classic RL problem, thus invalidates standard RL methods. To remedy this issue, we develop a reward shaping approach, leveraging properties of the $F_1$ score and duality of policy optimization, to provably find the set of all Pareto-optimal policies for budget-constrained $F_1$ score maximization. To handle the combinatorially complex state space, we propose a Semi-Model-based Deep Diagnosis Policy Optimization (SM-DDPO) framework that is compatible with end-to-end training and online learning. SM-DDPO is tested on diverse clinical tasks: ferritin abnormality detection, sepsis mortality prediction, and acute kidney injury diagnosis. Experiments with real-world data validate that SM-DDPO trains efficiently and identifies all Pareto-front solutions. Across all tasks, SM-DDPO is able to achieve state-of-the-art diagnosis accuracy (in some cases higher than conventional methods) with up to $85\%$ reduction in testing cost. The code is available at [https://github.com/Zheng321/Blood_Panel].
Multiagent Inverse Reinforcement Learning via Theory of Mind Reasoning
Feb 20, 2023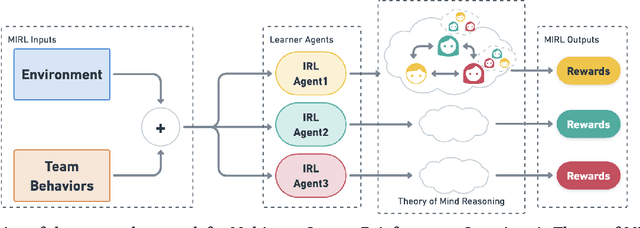
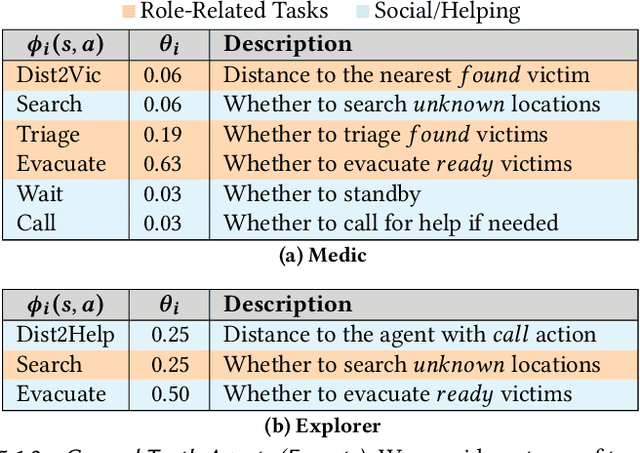


To understand how people interact with each other in collaborative settings, especially in situations where individuals know little about their teammates, Multiagent Inverse Reinforcement Learning (MIRL) aims to infer the reward functions guiding the behavior of each individual given trajectories of a team's behavior during task performance. Unlike current MIRL approaches, team members \emph{are not} assumed to know each other's goals a priori, rather they collaborate by adapting to the goals of others perceived by observing their behavior, all while jointly performing a task. To address this problem, we propose a novel approach to MIRL via Theory of Mind (MIRL-ToM). For each agent, we first use ToM reasoning to estimate a posterior distribution over baseline reward profiles given their demonstrated behavior. We then perform MIRL via decentralized equilibrium by employing single-agent Maximum Entropy IRL to infer a reward function for each agent, where we simulate the behavior of other teammates according to the time-varying distribution over profiles. We evaluate our approach in a simulated 2-player search-and-rescue operation where the goal of the agents, playing different roles, is to search for and evacuate victims in the environment. Results show that the choice of baseline profiles is paramount to the recovery of ground-truth rewards, and MIRL-ToM is able to recover the rewards used by agents interacting with either known and unknown teammates.