 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Urine Dataset having eigth particles classes
Feb 18, 2023
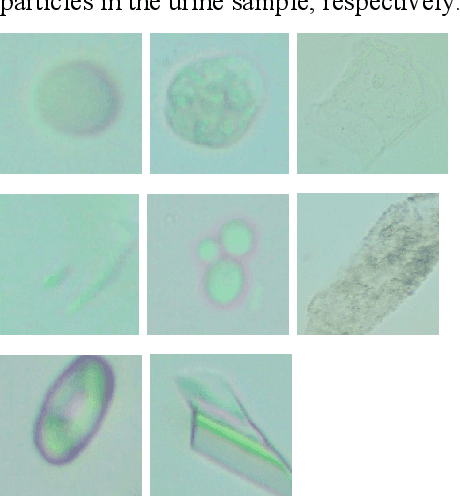

Urine sediment examination (USE) is one of the main tests used in the evaluation of diseases such as kidney, urinary, metabolic, and diabetes and to determine the density and number of various cells in the urine. USE's manual microscopy is a labor-intensive and time-consuming, imprecise, subjective process. Recently, automatic analysis of urine sediment has become inevitable in the medical field. In this study, we propose a dataset that can be used by artificial intelligence techniques to automatically identify particles in urine sediment images. The data set consists of 8509 particle images obtained by examining the particles in the urine sediment obtained from 409 patients from the Biochemistry Clinics of Elazig Fethi Sekin Central Hospital. Particle images are collected in 8 classes in total and these are Erythrocyte, Leukocyte, Epithelial, Bacteria, Yeast, Cylinders, Crystals, and others (sperm, etc.).
Feasibility and Transferability of Transfer Learning: A Mathematical Framework
Jan 27, 2023
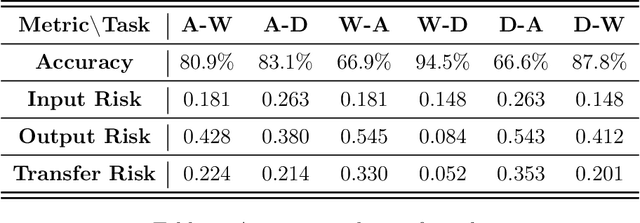
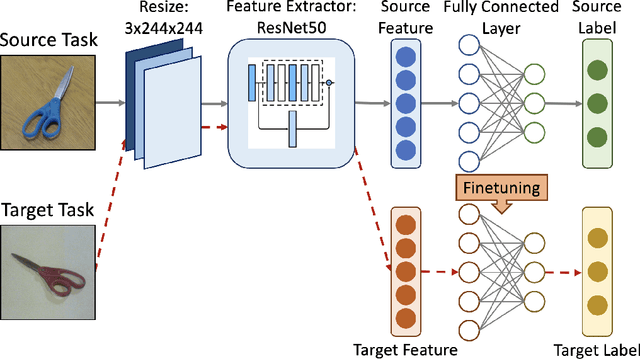
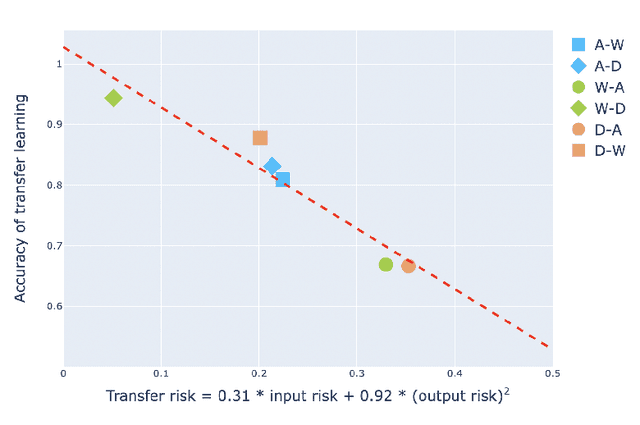
Transfer learning is an emerging and popular paradigm for utilizing existing knowledge from previous learning tasks to improve the performance of new ones. Despite its numerous empirical successes, theoretical analysis for transfer learning is limited. In this paper we build for the first time, to the best of our knowledge, a mathematical framework for the general procedure of transfer learning. Our unique reformulation of transfer learning as an optimization problem allows for the first time, analysis of its feasibility. Additionally, we propose a novel concept of transfer risk to evaluate transferability of transfer learning. Our numerical studies using the Office-31 dataset demonstrate the potential and benefits of incorporating transfer risk in the evaluation of transfer learning performance.
AbLit: A Resource for Analyzing and Generating Abridged Versions of English Literature
Feb 13, 2023
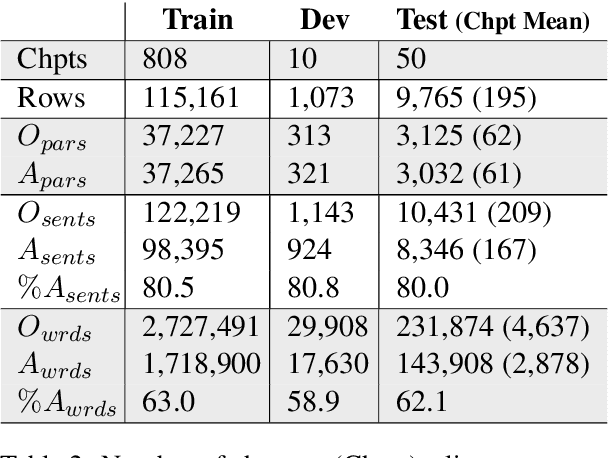
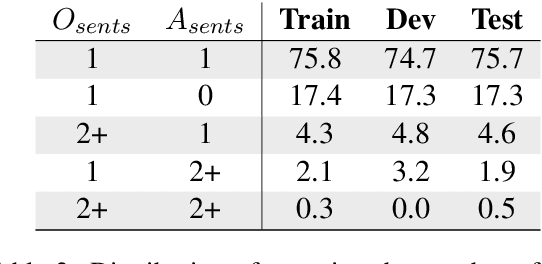
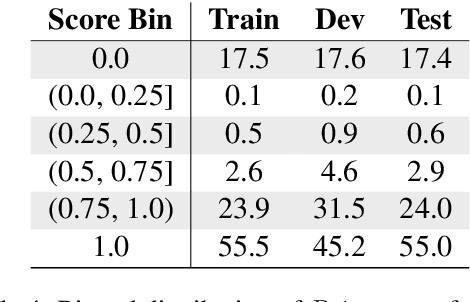
Creating an abridged version of a text involves shortening it while maintaining its linguistic qualities. In this paper, we examine this task from an NLP perspective for the first time. We present a new resource, AbLit, which is derived from abridged versions of English literature books. The dataset captures passage-level alignments between the original and abridged texts. We characterize the linguistic relations of these alignments, and create automated models to predict these relations as well as to generate abridgements for new texts. Our findings establish abridgement as a challenging task, motivating future resources and research. The dataset is available at github.com/roemmele/AbLit.
Algorithmic Aspects of the Log-Laplace Transform and a Non-Euclidean Proximal Sampler
Feb 22, 2023The development of efficient sampling algorithms catering to non-Euclidean geometries has been a challenging endeavor, as discretization techniques which succeed in the Euclidean setting do not readily carry over to more general settings. We develop a non-Euclidean analog of the recent proximal sampler of [LST21], which naturally induces regularization by an object known as the log-Laplace transform (LLT) of a density. We prove new mathematical properties (with an algorithmic flavor) of the LLT, such as strong convexity-smoothness duality and an isoperimetric inequality, which are used to prove a mixing time on our proximal sampler matching [LST21] under a warm start. As our main application, we show our warm-started sampler improves the value oracle complexity of differentially private convex optimization in $\ell_p$ and Schatten-$p$ norms for $p \in [1, 2]$ to match the Euclidean setting [GLL22], while retaining state-of-the-art excess risk bounds [GLLST23]. We find our investigation of the LLT to be a promising proof-of-concept of its utility as a tool for designing samplers, and outline directions for future exploration.
Exploiting Graph Structured Cross-Domain Representation for Multi-Domain Recommendation
Feb 22, 2023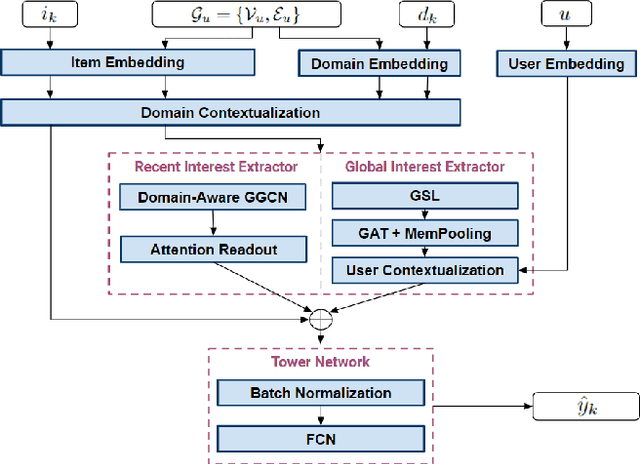
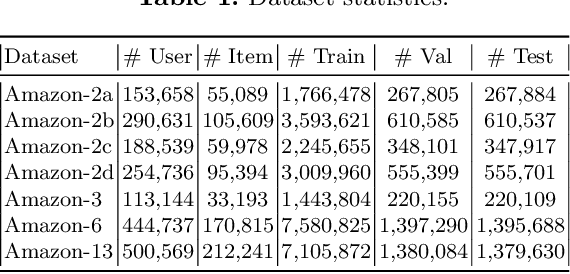
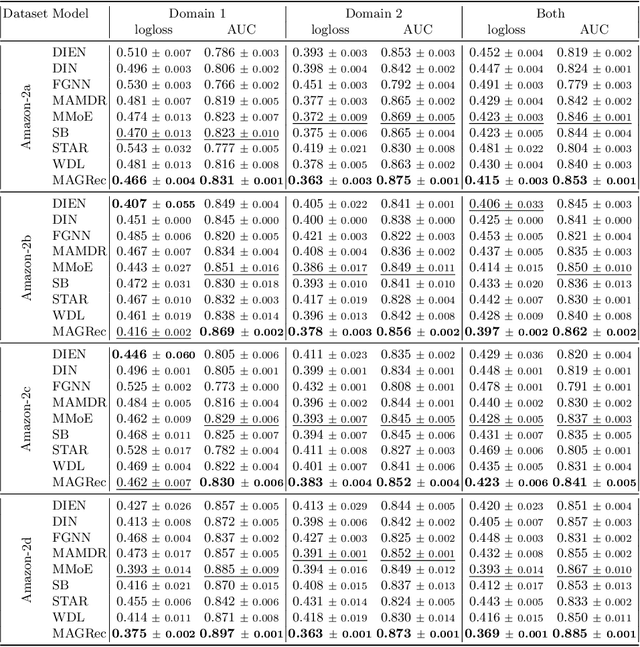
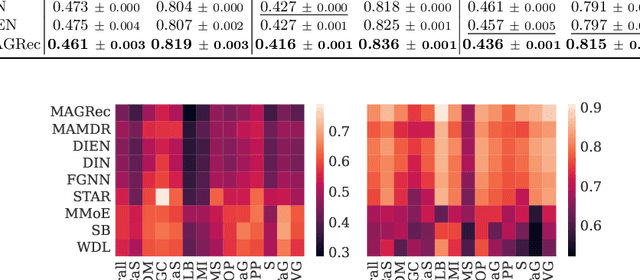
Multi-domain recommender systems benefit from cross-domain representation learning and positive knowledge transfer. Both can be achieved by introducing a specific modeling of input data (i.e. disjoint history) or trying dedicated training regimes. At the same time, treating domains as separate input sources becomes a limitation as it does not capture the interplay that naturally exists between domains. In this work, we efficiently learn multi-domain representation of sequential users' interactions using graph neural networks. We use temporal intra- and inter-domain interactions as contextual information for our method called MAGRec (short for Multi-domAin Graph-based Recommender). To better capture all relations in a multi-domain setting, we learn two graph-based sequential representations simultaneously: domain-guided for recent user interest, and general for long-term interest. This approach helps to mitigate the negative knowledge transfer problem from multiple domains and improve overall representation. We perform experiments on publicly available datasets in different scenarios where MAGRec consistently outperforms state-of-the-art methods. Furthermore, we provide an ablation study and discuss further extensions of our method.
mmAlert: mmWave Link Blockage Prediction via Passive Sensing
Feb 22, 2023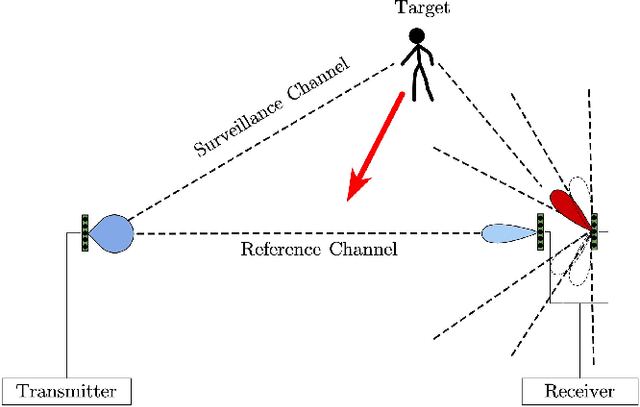
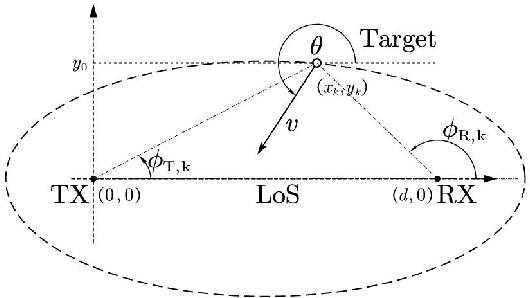
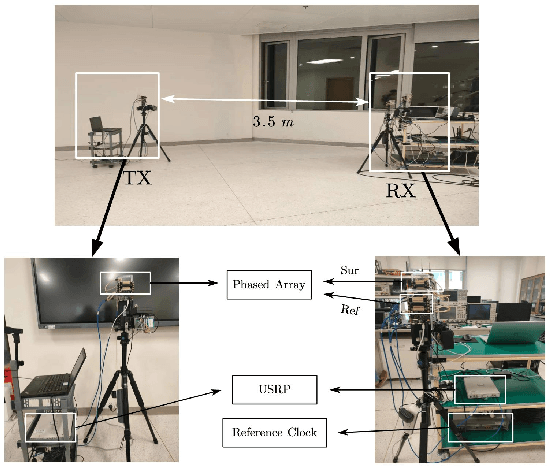
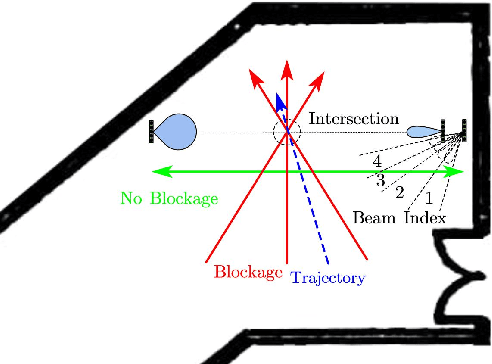
In this letter, the mmAlert system, predicting millimeter wave (mmWave) link blockage during data communication, is elaborated and demonstrated. The passive sensing method is adopted for mobile blocker detection, where two receive beams with separated radio frequency (RF) chains are equipped at the data communication receiver. One receive beam is aligned to the direction of line-of-sight (LoS) path, and the other one periodically sweeps the region close to the LoS path. By comparing the signals received by the above two beams, the Doppler frequencies of the signal scattered from the mobile blocker can be detected. Furthermore, by tracking the Doppler frequencies and the angle-of-arrivals (AoAs) of the scattered signals, the trajectory of the mobile blocker can be estimated, such that the potential link blockage can be predicted by assuming consistent mobile velocity. It is demonstrated via experiments that the mmAlert system can always detect the motions of the walking person close to the LoS path, and predict 90\% of the LoS blockage with sensing time of 1.4 seconds.
Fusing Visual Appearance and Geometry for Multi-modality 6DoF Object Tracking
Feb 22, 2023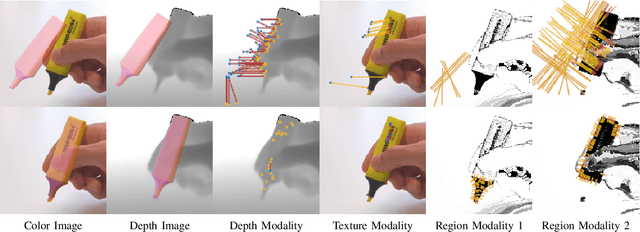
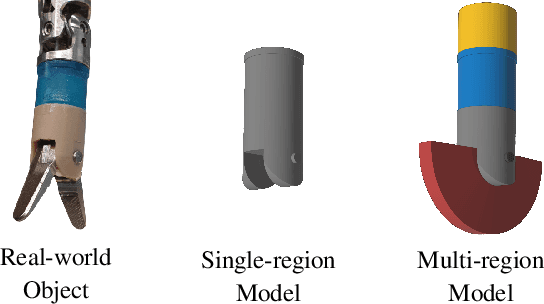
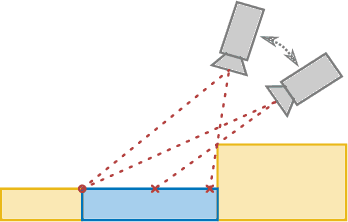
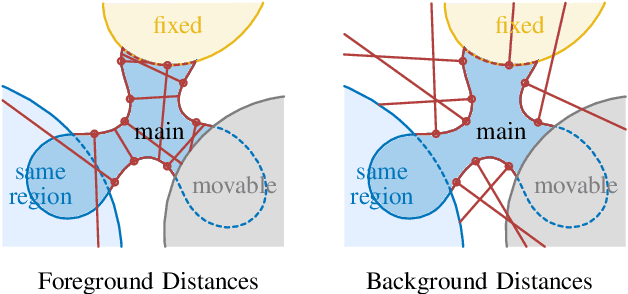
In many applications of advanced robotic manipulation, six degrees of freedom (6DoF) object pose estimates are continuously required. In this work, we develop a multi-modality tracker that fuses information from visual appearance and geometry to estimate object poses. The algorithm extends our previous method ICG, which uses geometry, to additionally consider surface appearance. In general, object surfaces contain local characteristics from text, graphics, and patterns, as well as global differences from distinct materials and colors. To incorporate this visual information, two modalities are developed. For local characteristics, keypoint features are used to minimize distances between points from keyframes and the current image. For global differences, a novel region approach is developed that considers multiple regions on the object surface. In addition, it allows the modeling of external geometries. Experiments on the YCB-Video and OPT datasets demonstrate that our approach ICG+ performs best on both datasets, outperforming both conventional and deep learning-based methods. At the same time, the algorithm is highly efficient and runs at more than 300 Hz. The source code of our tracker is publicly available.
Exploration by self-supervised exploitation
Feb 22, 2023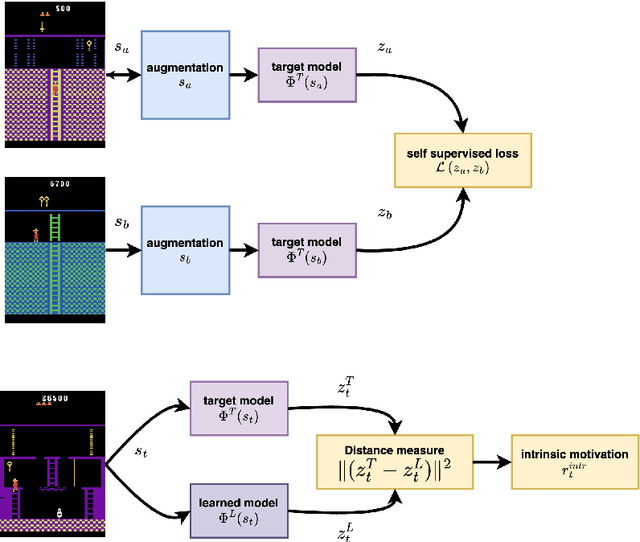

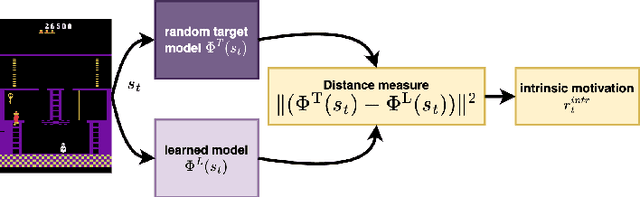
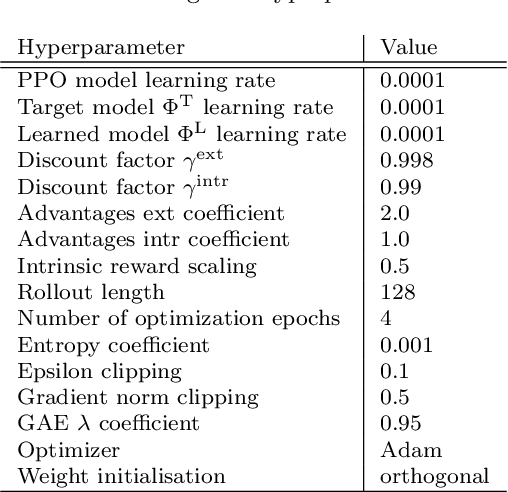
Reinforcement learning can solve decision-making problems and train an agent to behave in an environment according to a predesigned reward function. However, such an approach becomes very problematic if the reward is too sparse and the agent does not come across the reward during the environmental exploration. The solution to such a problem may be in equipping the agent with an intrinsic motivation, which will provide informed exploration, during which the agent is likely to also encounter external reward. Novelty detection is one of the promising branches of intrinsic motivation research. We present Self-supervised Network Distillation (SND), a class of internal motivation algorithms based on the distillation error as a novelty indicator, where the target model is trained using self-supervised learning. We adapted three existing self-supervised methods for this purpose and experimentally tested them on a set of ten environments that are considered difficult to explore. The results show that our approach achieves faster growth and higher external reward for the same training time compared to the baseline models, which implies improved exploration in a very sparse reward environment.
Non-Uniform Interpolation in Integrated Gradients for Low-Latency Explainable-AI
Feb 22, 2023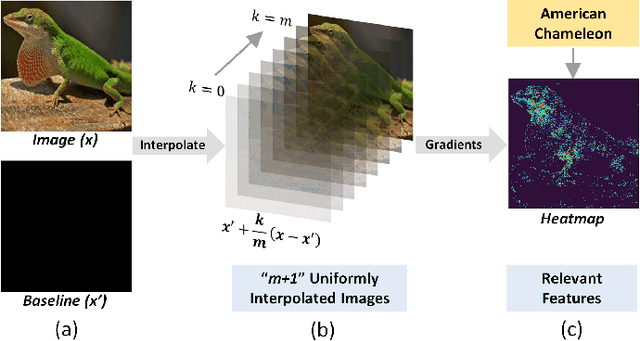
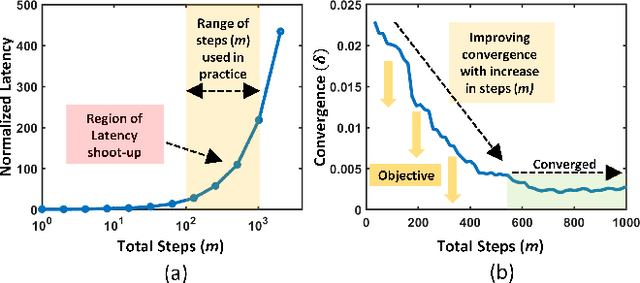
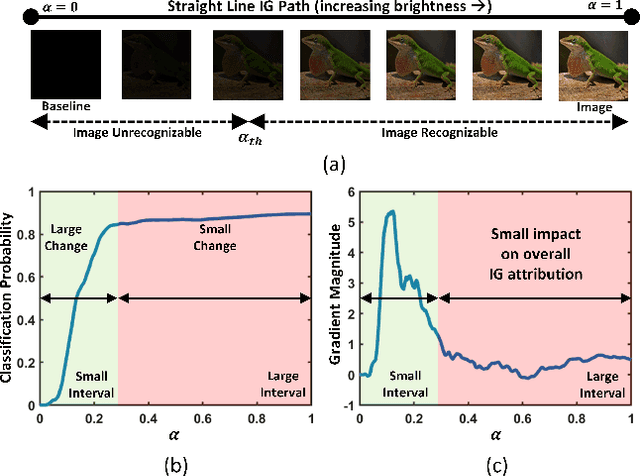
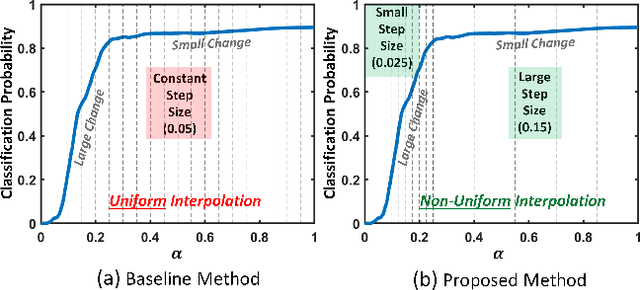
There has been a surge in Explainable-AI (XAI) methods that provide insights into the workings of Deep Neural Network (DNN) models. Integrated Gradients (IG) is a popular XAI algorithm that attributes relevance scores to input features commensurate with their contribution to the model's output. However, it requires multiple forward \& backward passes through the model. Thus, compared to a single forward-pass inference, there is a significant computational overhead to generate the explanation which hinders real-time XAI. This work addresses the aforementioned issue by accelerating IG with a hardware-aware algorithm optimization. We propose a novel non-uniform interpolation scheme to compute the IG attribution scores which replaces the baseline uniform interpolation. Our algorithm significantly reduces the total interpolation steps required without adversely impacting convergence. Experiments on the ImageNet dataset using a pre-trained InceptionV3 model demonstrate \textit{2.6-3.6}$\times$ performance speedup on GPU systems for iso-convergence. This includes the minimal \textit{0.2-3.2}\% latency overhead introduced by the pre-processing stage of computing the non-uniform interpolation step-sizes.
Effectiveness and Efficiency Trade-off in Selective Query Processing
Feb 22, 2023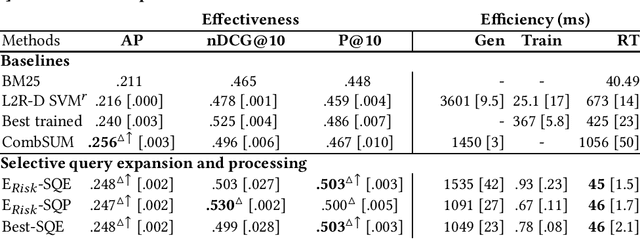
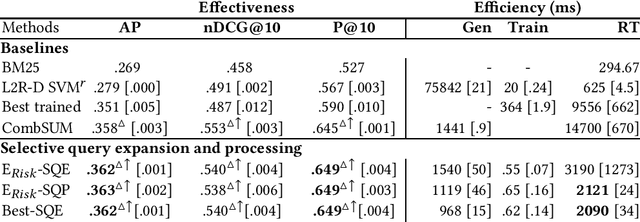
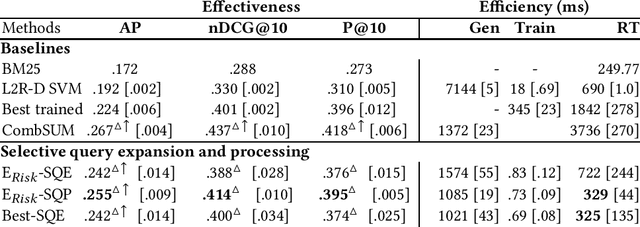
Query processing in search engines can be optimized for use for all queries. For this, system component parameters such as the weighting function or the automatic query expansion model can be optimized or learned from past queries. However, it may be more interesting to optimize the processing thread on a query-by-query basis by adjusting the component parameters; this is what selective query processing does. Selective query processing uses one of the candidate processing threads chosen at query time. The choice is based on query features. In this paper, we examine selective query processing in different settings, both in terms of effectiveness and efficiency; this includes selective query expansion and other forms of selective query processing (e.g., when the term weighting function varies or when the expansion model varies). We found that the best trade-off between effectiveness and efficiency is obtained when using the best trained processing thread and its query expansion counter part. This seems to be also the most natural for a real-word engine since the two threads use the same core engine (e.g., same term weighting function).