 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Simplistic Model of Neural Scaling Laws: Multiperiodic Santa Fe Processes
Feb 17, 2023
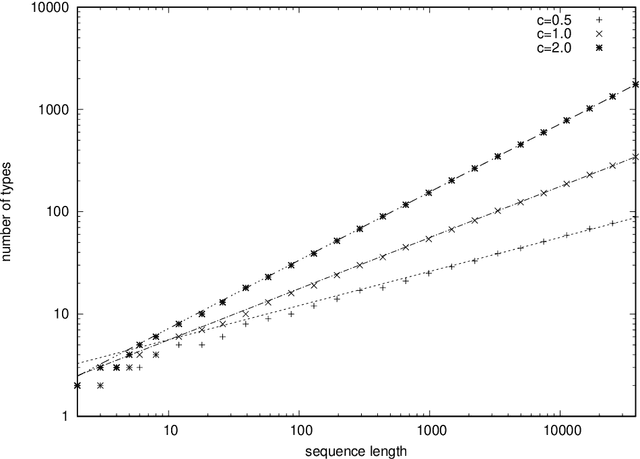
It was observed that large language models exhibit a power-law decay of cross entropy with respect to the number of parameters and training tokens. When extrapolated literally, this decay implies that the entropy rate of natural language is zero. To understand this phenomenon -- or an artifact -- better, we construct a simple stationary stochastic process and its memory-based predictor that exhibit a power-law decay of cross entropy with the vanishing entropy rate. Our example is based on previously discussed Santa Fe processes, which decompose a random text into a process of narration and time-independent knowledge. Previous discussions assumed that narration is a memoryless source with Zipf's distribution. In this paper, we propose a model of narration that has the vanishing entropy rate and applies a randomly chosen deterministic sequence called a multiperiodic sequence. Under a suitable parameterization, multiperiodic sequences exhibit asymptotic relative frequencies given by Zipf's law. Remaining agnostic about the value of the entropy rate of natural language, we discuss relevance of similar constructions for language modeling.
Boosted ab initio Cryo-EM 3D Reconstruction with ACE-EM
Feb 14, 2023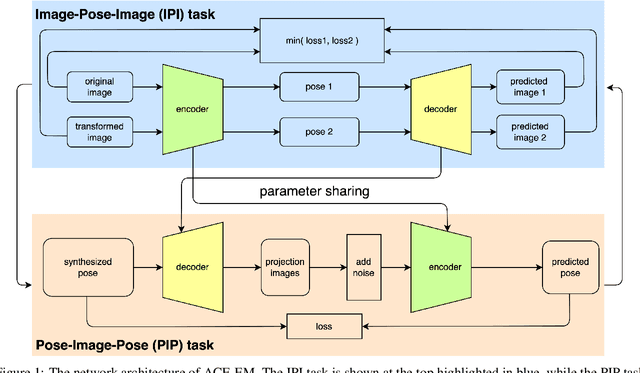
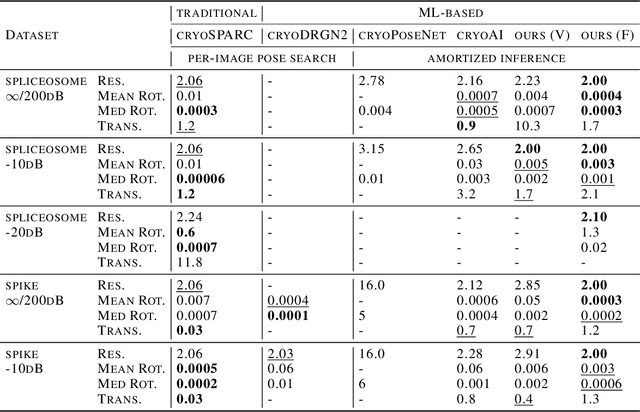
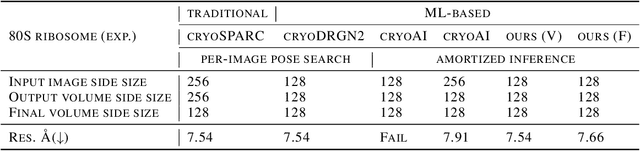
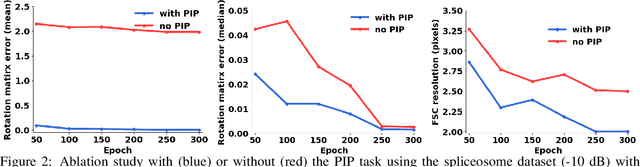
The central problem in cryo-electron microscopy (cryo-EM) is to recover the 3D structure from noisy 2D projection images which requires estimating the missing projection angles (poses). Recent methods attempted to solve the 3D reconstruction problem with the autoencoder architecture, which suffers from the latent vector space sampling problem and frequently produces suboptimal pose inferences and inferior 3D reconstructions. Here we present an improved autoencoder architecture called ACE (Asymmetric Complementary autoEncoder), based on which we designed the ACE-EM method for cryo-EM 3D reconstructions. Compared to previous methods, ACE-EM reached higher pose space coverage within the same training time and boosted the reconstruction performance regardless of the choice of decoders. With this method, the Nyquist resolution (highest possible resolution) was reached for 3D reconstructions of both simulated and experimental cryo-EM datasets. Furthermore, ACE-EM is the only amortized inference method that reached the Nyquist resolution.
From paintbrush to pixel: A review of deep neural networks in AI-generated art
Feb 14, 2023
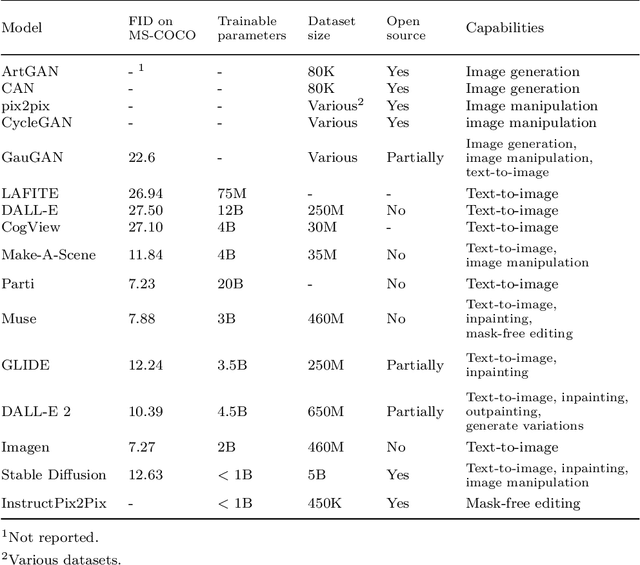
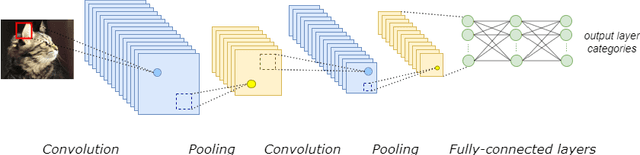
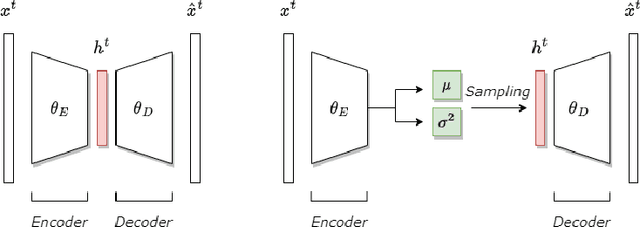
This paper delves into the fascinating field of AI-generated art and explores the various deep neural network architectures and models that have been utilized to create it. From the classic convolutional networks to the cutting-edge diffusion models, we examine the key players in the field. We explain the general structures and working principles of these neural networks. Then, we showcase examples of milestones, starting with the dreamy landscapes of DeepDream and moving on to the most recent developments, including Stable Diffusion and DALL-E 2, which produce mesmerizing images. A detailed comparison of these models is provided, highlighting their strengths and limitations. Thus, we examine the remarkable progress that deep neural networks have made so far in a short period of time. With a unique blend of technical explanations and insights into the current state of AI-generated art, this paper exemplifies how art and computer science interact.
Data-Centric Governance
Feb 14, 2023
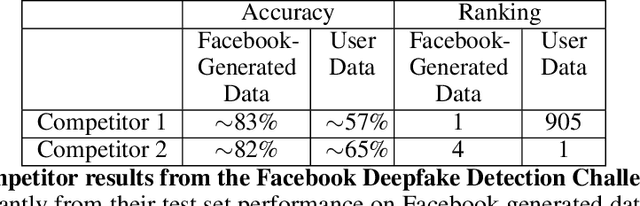


Artificial intelligence (AI) governance is the body of standards and practices used to ensure that AI systems are deployed responsibly. Current AI governance approaches consist mainly of manual review and documentation processes. While such reviews are necessary for many systems, they are not sufficient to systematically address all potential harms, as they do not operationalize governance requirements for system engineering, behavior, and outcomes in a way that facilitates rigorous and reproducible evaluation. Modern AI systems are data-centric: they act on data, produce data, and are built through data engineering. The assurance of governance requirements must also be carried out in terms of data. This work explores the systematization of governance requirements via datasets and algorithmic evaluations. When applied throughout the product lifecycle, data-centric governance decreases time to deployment, increases solution quality, decreases deployment risks, and places the system in a continuous state of assured compliance with governance requirements.
Embodied Footprints: A Safety-guaranteed Collision Avoidance Model for Numerical Optimization-based Trajectory Planning
Feb 15, 2023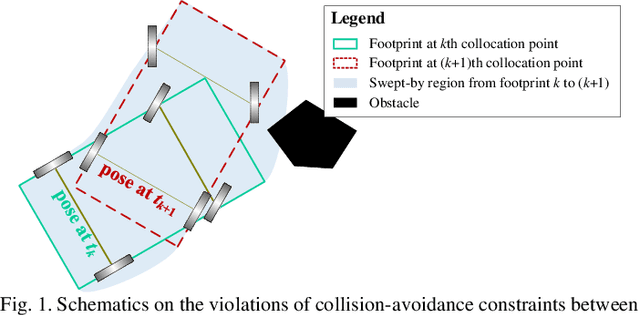
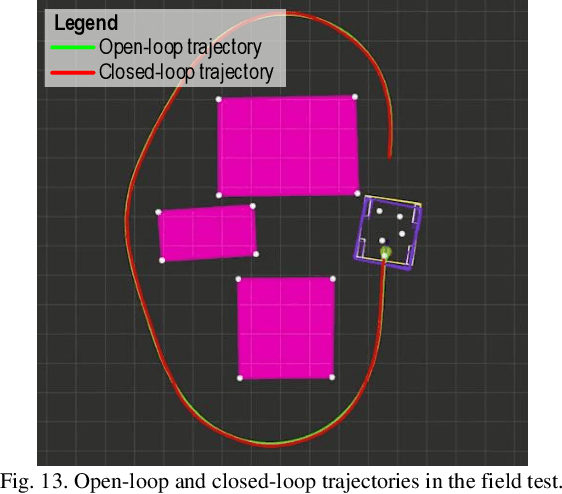
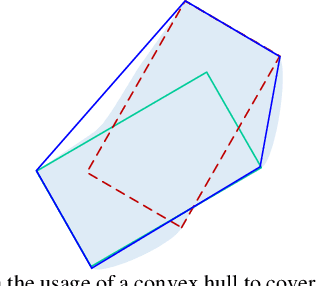
Numerical optimization-based methods are among the prevalent trajectory planners for autonomous driving. In a numerical optimization-based planner, the nominal continuous-time trajectory planning problem is discretized into a nonlinear program (NLP) problem with finite constraints imposed on finite collocation points. However, constraint violations between adjacent collocation points may still occur. This study proposes a safety-guaranteed collision-avoidance modeling method to eliminate the collision risks between adjacent collocation points in using numerical optimization-based trajectory planners. A new concept called embodied box is proposed, which is formed by enlarging the rectangular footprint of the ego vehicle. If one can ensure that the embodied boxes at finite collocation points are collide-free, then the ego vehicle's footprint is collide-free at any a moment between adjacent collocation points. We find that the geometric size of an embodied box is a simple function of vehicle velocity and curvature. The proposed theory lays a foundation for numerical optimization-based trajectory planners in autonomous driving.
Ultrafast single-channel machine vision based on neuro-inspired photonic computing
Feb 15, 2023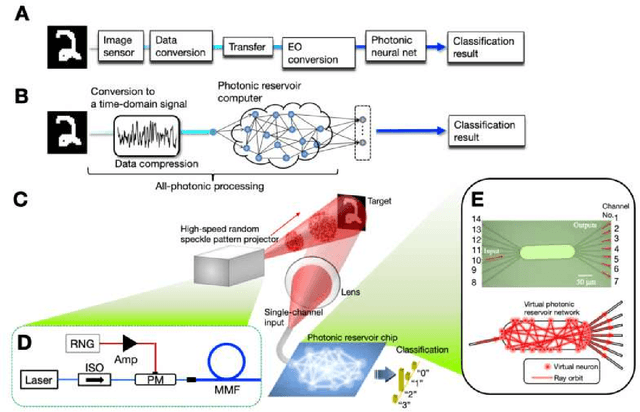
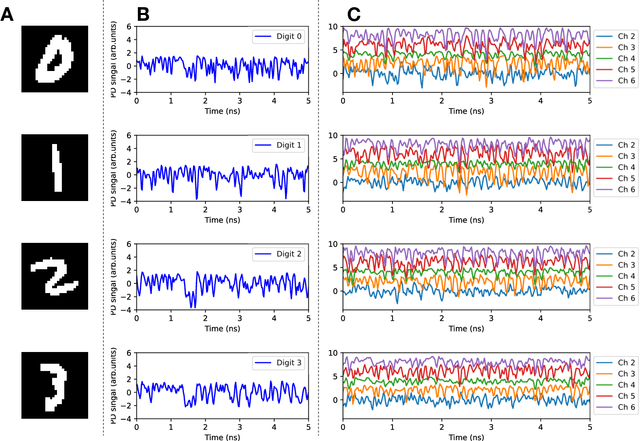
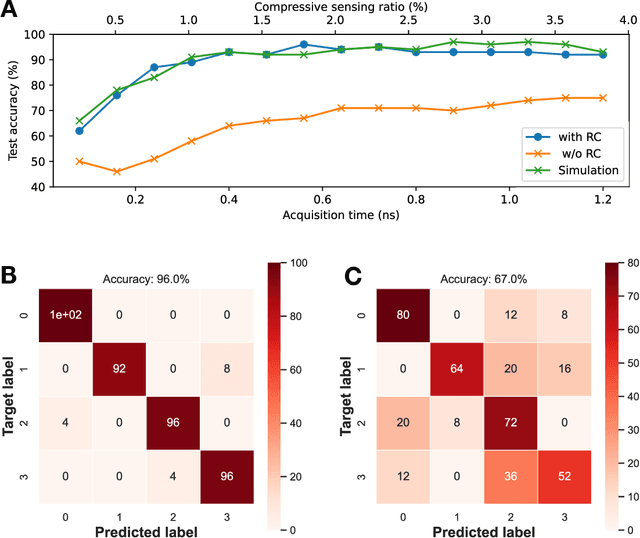
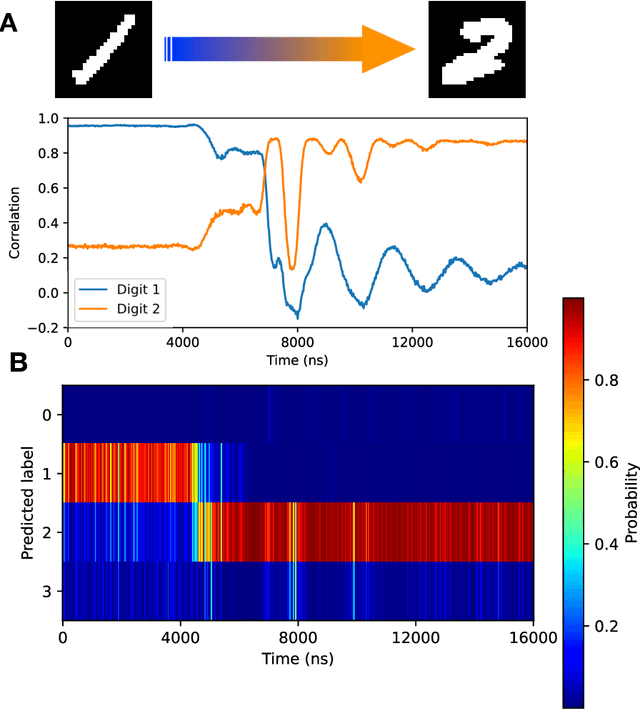
High-speed machine vision is increasing its importance in both scientific and technological applications. Neuro-inspired photonic computing is a promising approach to speed-up machine vision processing with ultralow latency. However, the processing rate is fundamentally limited by the low frame rate of image sensors, typically operating at tens of hertz. Here, we propose an image-sensor-free machine vision framework, which optically processes real-world visual information with only a single input channel, based on a random temporal encoding technique. This approach allows for compressive acquisitions of visual information with a single channel at gigahertz rates, outperforming conventional approaches, and enables its direct photonic processing using a photonic reservoir computer in a time domain. We experimentally demonstrate that the proposed approach is capable of high-speed image recognition and anomaly detection, and furthermore, it can be used for high-speed imaging. The proposed approach is multipurpose and can be extended for a wide range of applications, including tracking, controlling, and capturing sub-nanosecond phenomena.
Self-supervised Registration and Segmentation of the Ossicles with A Single Ground Truth Label
Feb 15, 2023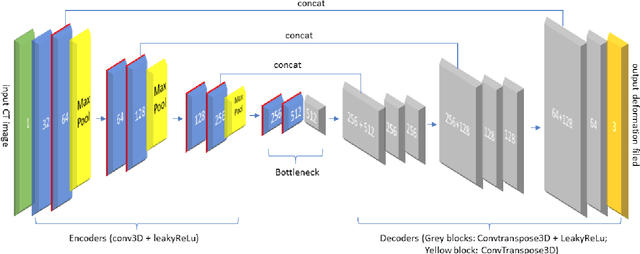

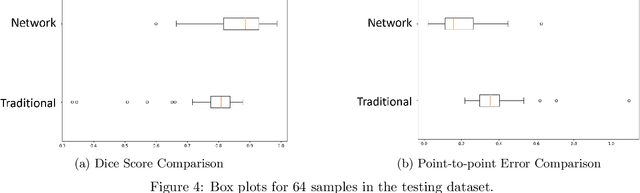
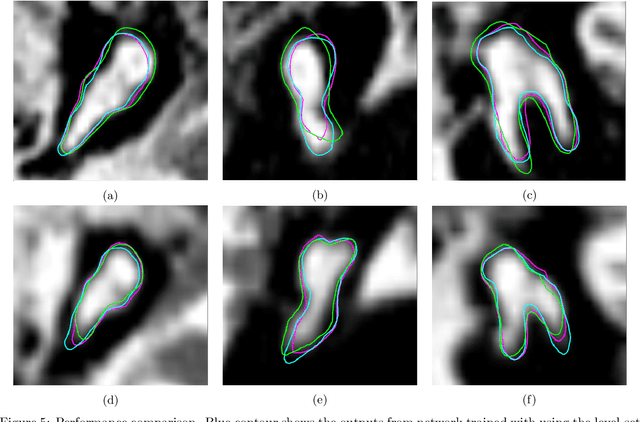
AI-assisted surgeries have drawn the attention of the medical image research community due to their real-world impact on improving surgery success rates. For image-guided surgeries, such as Cochlear Implants (CIs), accurate object segmentation can provide useful information for surgeons before an operation. Recently published image segmentation methods that leverage machine learning usually rely on a large number of manually predefined ground truth labels. However, it is a laborious and time-consuming task to prepare the dataset. This paper presents a novel technique using a self-supervised 3D-UNet that produces a dense deformation field between an atlas and a target image that can be used for atlas-based segmentation of the ossicles. Our results show that our method outperforms traditional image segmentation methods and generates a more accurate boundary around the ossicles based on Dice similarity coefficient and point-to-point error comparison. The mean Dice coefficient is improved by 8.51% with our proposed method.
Whats New? Identifying the Unfolding of New Events in Narratives
Feb 15, 2023
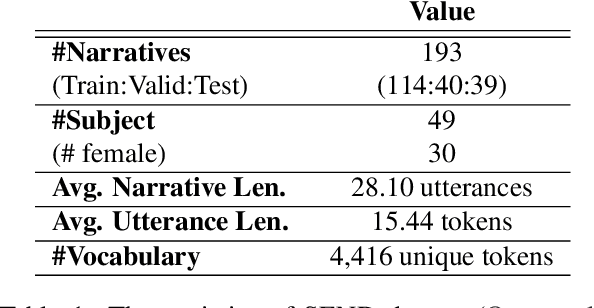

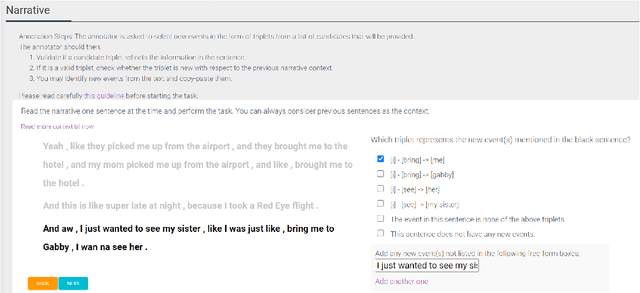
Narratives include a rich source of events unfolding over time and context. Automatic understanding of these events may provide a summarised comprehension of the narrative for further computation (such as reasoning). In this paper, we study the Information Status (IS) of the events and propose a novel challenging task: the automatic identification of new events in a narrative. We define an event as a triplet of subject, predicate, and object. The event is categorized as new with respect to the discourse context and whether it can be inferred through commonsense reasoning. We annotated a publicly available corpus of narratives with the new events at sentence level using human annotators. We present the annotation protocol and a study aiming at validating the quality of the annotation and the difficulty of the task. We publish the annotated dataset, annotation materials, and machine learning baseline models for the task of new event extraction for narrative understanding.
Cooperative Simultaneous Tracking and Jamming for Disabling a Rogue Drone
Feb 15, 2023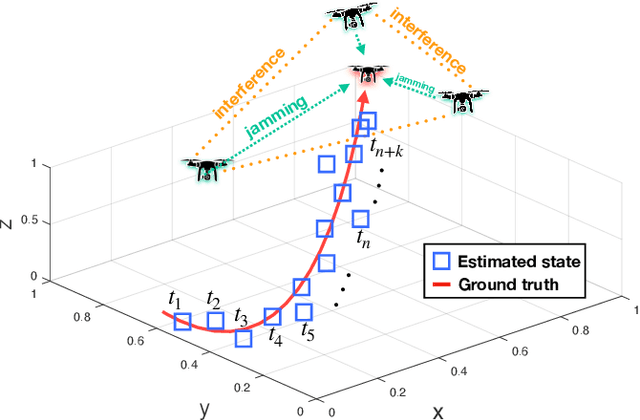
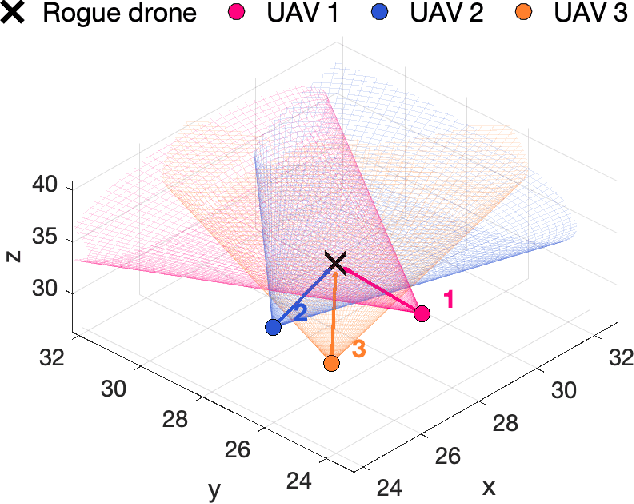
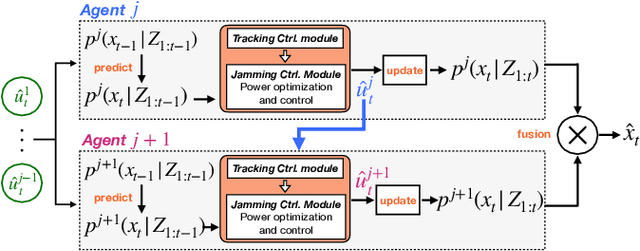
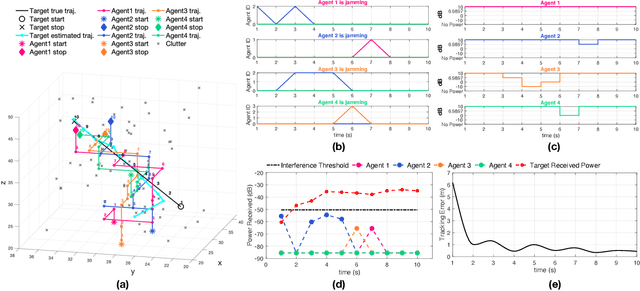
This work investigates the problem of simultaneous tracking and jamming of a rogue drone in 3D space with a team of cooperative unmanned aerial vehicles (UAVs). We propose a decentralized estimation, decision and control framework in which a team of UAVs cooperate in order to a) optimally choose their mobility control actions that result in accurate target tracking and b) select the desired transmit power levels which cause uninterrupted radio jamming and thus ultimately disrupt the operation of the rogue drone. The proposed decision and control framework allows the UAVs to reconfigure themselves in 3D space such that the cooperative simultaneous tracking and jamming (CSTJ) objective is achieved; while at the same time ensures that the unwanted inter-UAV jamming interference caused during CSTJ is kept below a specified critical threshold. Finally, we formulate this problem under challenging conditions i.e., uncertain dynamics, noisy measurements and false alarms. Extensive simulation experiments illustrate the performance of the proposed approach.
* 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Resilient Binary Neural Network
Feb 05, 2023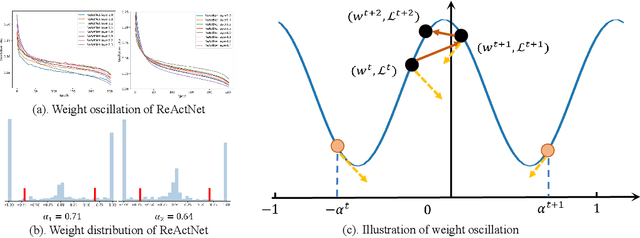
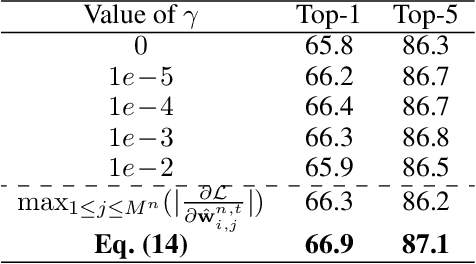
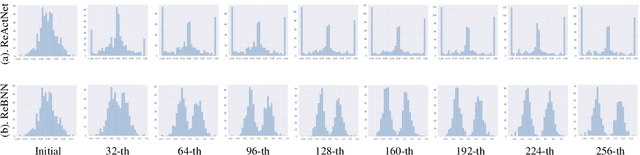
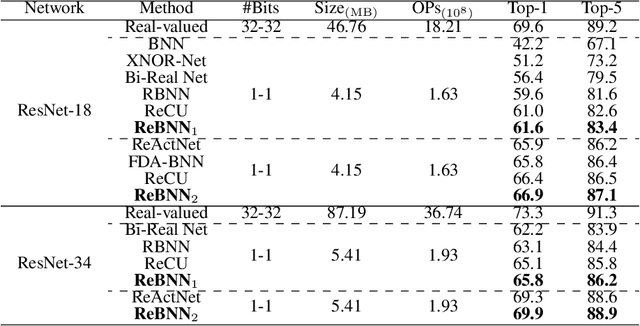
Binary neural networks (BNNs) have received ever-increasing popularity for their great capability of reducing storage burden as well as quickening inference time. However, there is a severe performance drop compared with real-valued networks, due to its intrinsic frequent weight oscillation during training. In this paper, we introduce a Resilient Binary Neural Network (ReBNN) to mitigate the frequent oscillation for better BNNs' training. We identify that the weight oscillation mainly stems from the non-parametric scaling factor. To address this issue, we propose to parameterize the scaling factor and introduce a weighted reconstruction loss to build an adaptive training objective. For the first time, we show that the weight oscillation is controlled by the balanced parameter attached to the reconstruction loss, which provides a theoretical foundation to parameterize it in back propagation. Based on this, we learn our ReBNN by calculating the balanced parameter based on its maximum magnitude, which can effectively mitigate the weight oscillation with a resilient training process. Extensive experiments are conducted upon various network models, such as ResNet and Faster-RCNN for computer vision, as well as BERT for natural language processing. The results demonstrate the overwhelming performance of our ReBNN over prior arts. For example, our ReBNN achieves 66.9% Top-1 accuracy with ResNet-18 backbone on the ImageNet dataset, surpassing existing state-of-the-arts by a significant margin. Our code is open-sourced at https://github.com/SteveTsui/ReBNN.