 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adapter Incremental Continual Learning of Efficient Audio Spectrogram Transformers
Feb 28, 2023
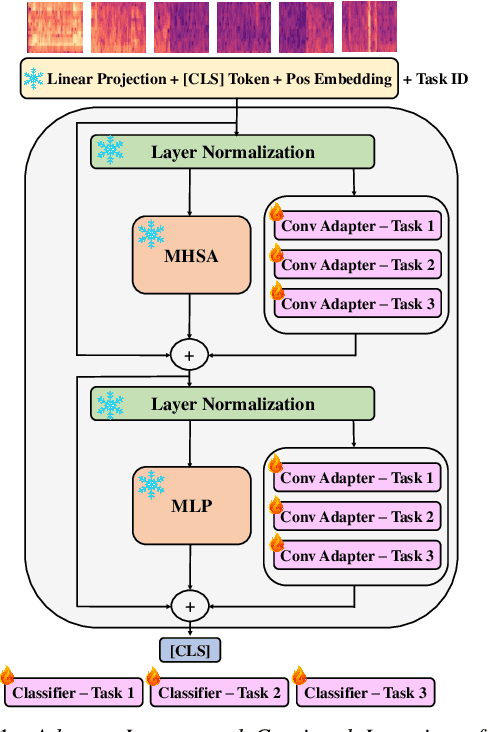

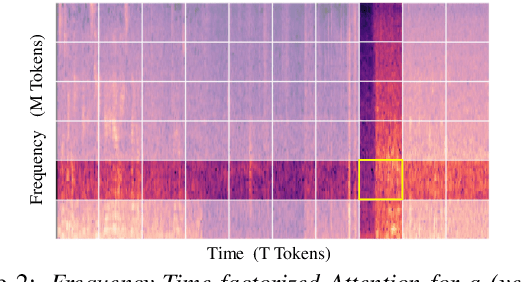
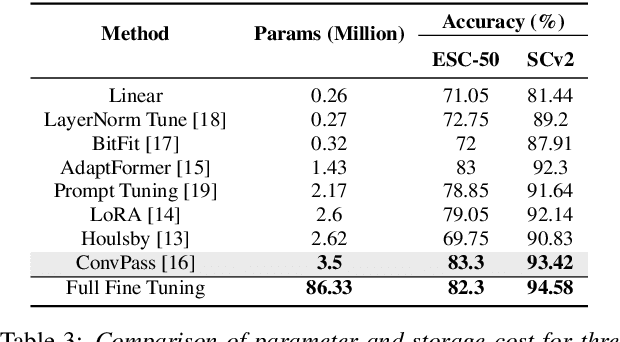
Continual learning involves training neural networks incrementally for new tasks while retaining the knowledge of previous tasks. However, efficiently fine-tuning the model for sequential tasks with minimal computational resources remains a challenge. In this paper, we propose Task Incremental Continual Learning (TI-CL) of audio classifiers with both parameter-efficient and compute-efficient Audio Spectrogram Transformers (AST). To reduce the trainable parameters without performance degradation for TI-CL, we compare several Parameter Efficient Transfer (PET) methods and propose AST with Convolutional Adapters for TI-CL, which has less than 5% of trainable parameters of the fully fine-tuned counterparts. To reduce the computational complexity, we introduce a novel Frequency-Time factorized Attention (FTA) method that replaces the traditional self-attention in transformers for audio spectrograms. FTA achieves competitive performance with only a factor of the computations required by Global Self-Attention (GSA). Finally, we formulate our method for TI-CL, called Adapter Incremental Continual Learning (AI-CL), as a combination of the "parameter-efficient" Convolutional Adapter and the "compute-efficient" FTA. Experiments on ESC-50, SpeechCommandsV2 (SCv2), and Audio-Visual Event (AVE) benchmarks show that our proposed method prevents catastrophic forgetting in TI-CL while maintaining a lower computational budget.
On the Road to 6G: Visions, Requirements, Key Technologies and Testbeds
Feb 28, 2023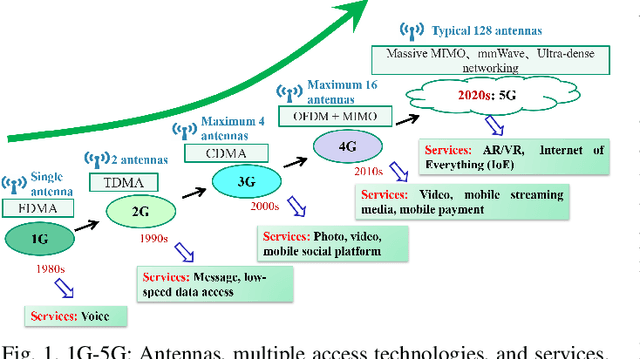

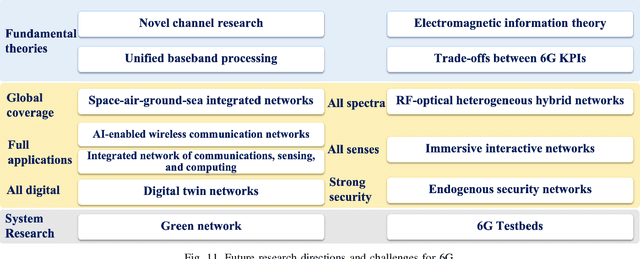
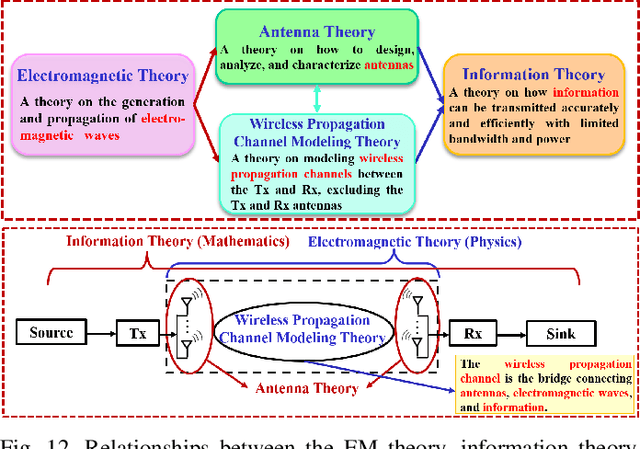
Fifth generation (5G) mobile communication systems have entered the stage of commercial development, providing users with new services and improved user experiences as well as offering a host of novel opportunities to various industries. However, 5G still faces many challenges. To address these challenges, international industrial, academic, and standards organizations have commenced research on sixth generation (6G) wireless communication systems. A series of white papers and survey papers have been published, which aim to define 6G in terms of requirements, application scenarios, key technologies, etc. Although ITU-R has been working on the 6G vision and it is expected to reach a consensus on what 6G will be by mid-2023, the related global discussions are still wide open and the existing literature has identified numerous open issues. This paper first provides a comprehensive portrayal of the 6G vision, technical requirements, and application scenarios, covering the current common understanding of 6G. Then, a critical appraisal of the 6G network architecture and key technologies is presented. Furthermore, existing testbeds and advanced 6G verification platforms are detailed for the first time. In addition, future research directions and open challenges are identified for stimulating the on-going global debate. Finally, lessons learned to date concerning 6G networks are discussed.
Onboard dynamic-object detection and tracking for autonomous robot navigation with RGB-D camera
Feb 28, 2023

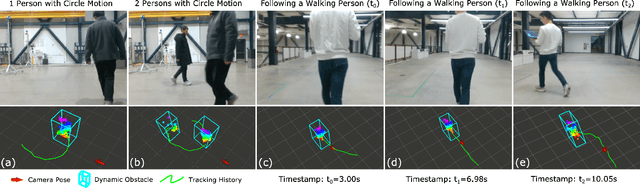
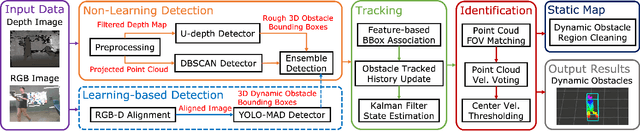
Deploying autonomous robots in crowded indoor environments usually requires them to have accurate dynamic obstacle perception. Although plenty of previous works in the autonomous driving field have investigated the 3D object detection problem, the usage of dense point clouds from a heavy LiDAR and their high computation cost for learning-based data processing make those methods not applicable to lightweight robots, such as vision-based UAVs with small onboard computers. To address this issue, we propose a lightweight 3D dynamic obstacle detection and tracking (DODT) method based on an RGB-D camera. Our method adopts a novel ensemble detection strategy, combining multiple computationally efficient but low-accuracy detectors to achieve real-time high-accuracy obstacle detection. Besides, we introduce a new feature-based data association method to prevent mismatches and use the Kalman filter with the constant acceleration model to track detected obstacles. In addition, our system includes an optional and auxiliary learning-based module to enhance the obstacle detection range and dynamic obstacle identification. The users can determine whether or not to run this module based on the available computation resources. The proposed method is implemented in a lightweight quadcopter, and the experiments prove that the algorithm can make the robot detect dynamic obstacles and navigate dynamic environments safely.
Automatic Scoring of Dream Reports' Emotional Content with Large Language Models
Feb 28, 2023
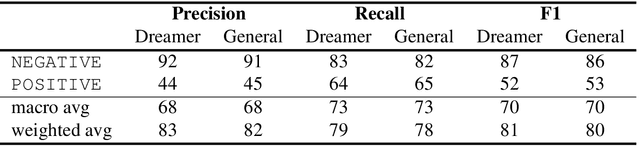
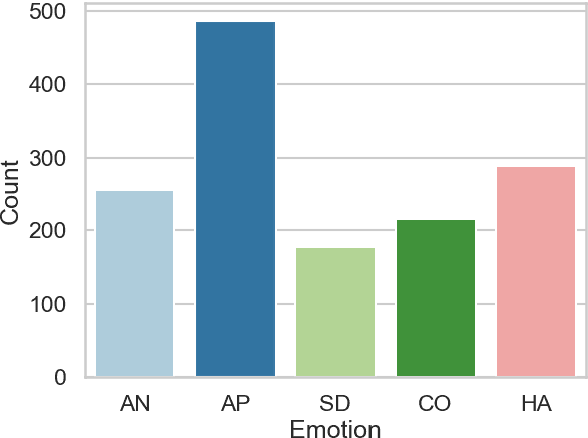
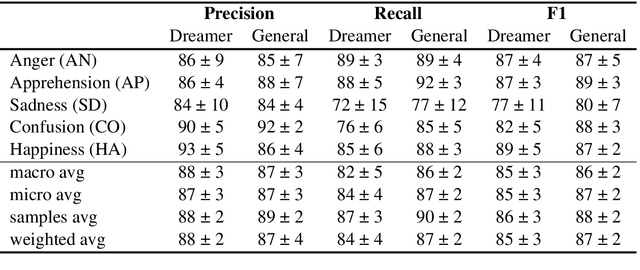
In the field of dream research, the study of dream content typically relies on the analysis of verbal reports provided by dreamers upon awakening from their sleep. This task is classically performed through manual scoring provided by trained annotators, at a great time expense. While a consistent body of work suggests that natural language processing (NLP) tools can support the automatic analysis of dream reports, proposed methods lacked the ability to reason over a report's full context and required extensive data pre-processing. Furthermore, in most cases, these methods were not validated against standard manual scoring approaches. In this work, we address these limitations by adopting large language models (LLMs) to study and replicate the manual annotation of dream reports, using a mixture of off-the-shelf and bespoke approaches, with a focus on references to reports' emotions. Our results show that the off-the-shelf method achieves a low performance probably in light of inherent linguistic differences between reports collected in different (groups of) individuals. On the other hand, the proposed bespoke text classification method achieves a high performance, which is robust against potential biases. Overall, these observations indicate that our approach could find application in the analysis of large dream datasets and may favour reproducibility and comparability of results across studies.
Multirate Spectral Domain Optical Coherence Tomography
Feb 28, 2023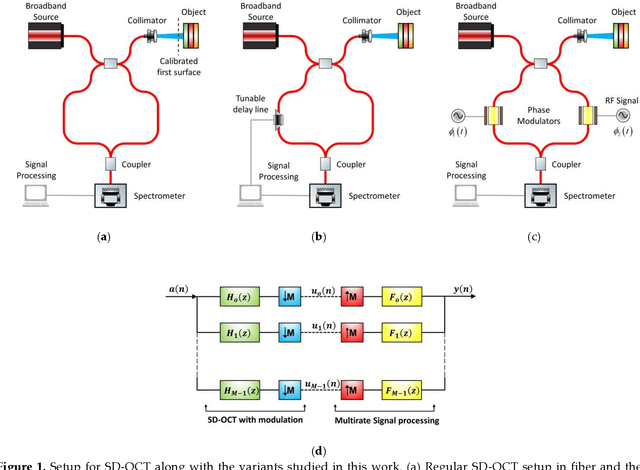
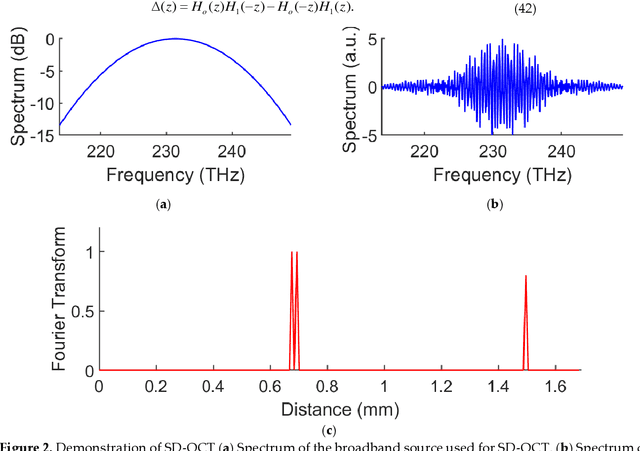
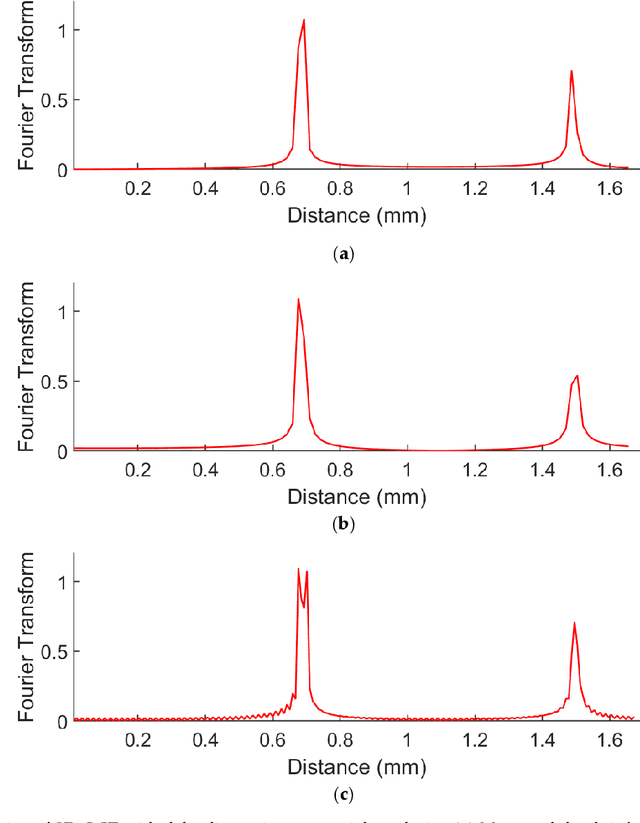
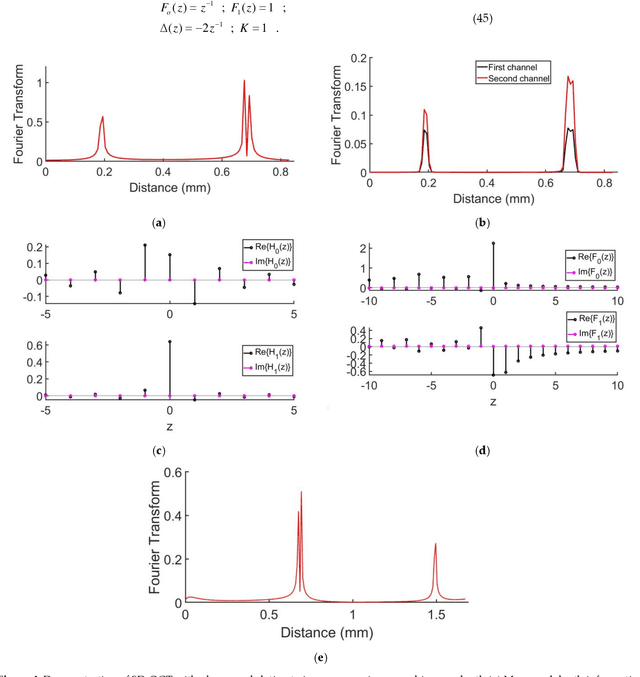
Optical coherence tomography is state-of-the-art in non-invasive imaging of biological structures. Spectral Domain Optical Co-herence Tomography is the popularly used variation of this technique, but its performance is limited by the bandwidth and res-olution of the system. In this work, we theoretically formulate the use of phase modulators and delay lines to act as filters on the tomography system and scan multiple channels. Various channels are then combined in a digital computer using filter bank theory to improve the sampling rate . The combination of multiple channels allows for increasing the axial resolution and maximum unambiguous range beyond the Nyquist limit. We then simulate the multirate spectral domain optical coherence tomography with 2 channels. We show that a single delay line can improve the axial resolution while a pair of phase modulators can improve the maximum unambiguous range of the system. We also show the use of multirate filter banks to carry out this process. Thus, by using a few extra components in the spectral domain optical coherence tomography, its performance can be increased manifold de-pending on the number of channels used. The extra cost is the time taken to perform the extra scans that is trivial for stationary objects like biological tissues.
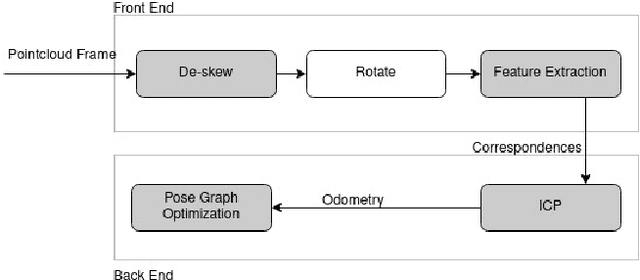
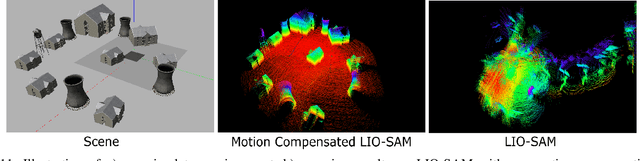
ROG-Map: An Efficient Robocentric Occupancy Grid Map for Large-scene and High-resolution LiDAR-based Motion Planning
Feb 28, 2023
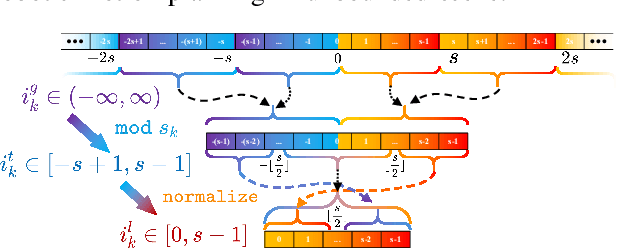
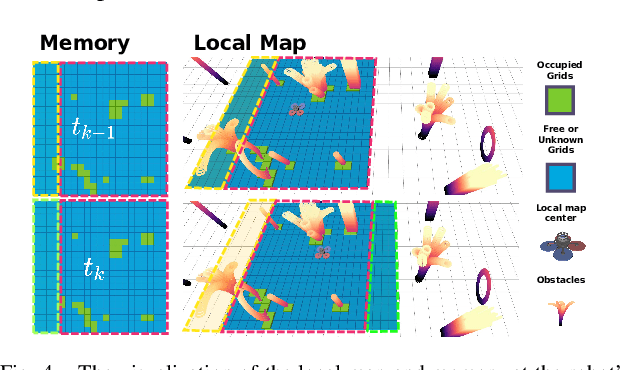
Recent advances in LiDAR technology have opened up new possibilities for robotic navigation. Given the widespread use of occupancy grid maps (OGMs) in robotic motion planning, this paper aims to address the challenges of integrating LiDAR with OGMs. To this end, we propose ROG-Map, a uniform grid-based OGM that maintains a local map moving along with the robot to enable efficient map operation and reduce memory costs for large-scene autonomous flight. Moreover, we present a novel incremental obstacle inflation method that significantly reduces the computational cost of inflation. The proposed method outperforms state-of-the-art (SOTA) methods on various public datasets. To demonstrate the effectiveness and efficiency of ROG-Map, we integrate it into a complete quadrotor system and perform autonomous flights against both small obstacles and large-scale scenes. During real-world flight tests with a 0.05 m resolution local map and 30mx30mx12m local map size, ROG-Map takes only 29.8% of frame time on average to update the map at a frame rate of 50 Hz (\ie, 5.96 ms in 20 ms), including 0.33% (i.e., 0.66 ms) to perform obstacle inflation, demonstrating outstanding real-world performance. We release ROG-Map as an open-source ROS package to promote the development of LiDAR-based motion planning.
A Closer Look at the Intervention Procedure of Concept Bottleneck Models
Feb 28, 2023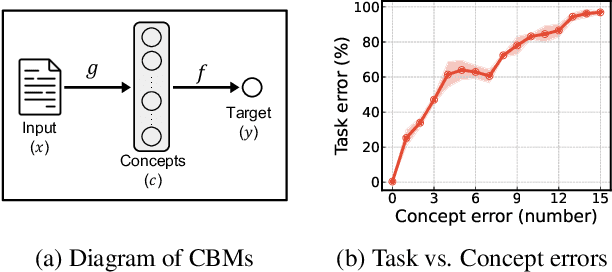

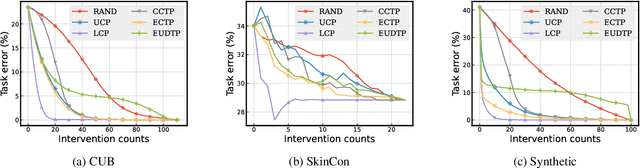
Concept bottleneck models (CBMs) are a class of interpretable neural network models that predict the target response of a given input based on its high-level concepts. Unlike the standard end-to-end models, CBMs enable domain experts to intervene on the predicted concepts and rectify any mistakes at test time, so that more accurate task predictions can be made at the end. While such intervenability provides a powerful avenue of control, many aspects of the intervention procedure remain rather unexplored. In this work, we develop various ways of selecting intervening concepts to improve the intervention effectiveness and conduct an array of in-depth analyses as to how they evolve under different circumstances. Specifically, we find that an informed intervention strategy can reduce the task error more than ten times compared to the current baseline under the same amount of intervention counts in realistic settings, and yet, this can vary quite significantly when taking into account different intervention granularity. We verify our findings through comprehensive evaluations, not only on the standard real datasets, but also on synthetic datasets that we generate based on a set of different causal graphs. We further discover some major pitfalls of the current practices which, without a proper addressing, raise concerns on reliability and fairness of the intervention procedure.
Design of an Adaptive Lightweight LiDAR to Decouple Robot-Camera Geometry
Feb 28, 2023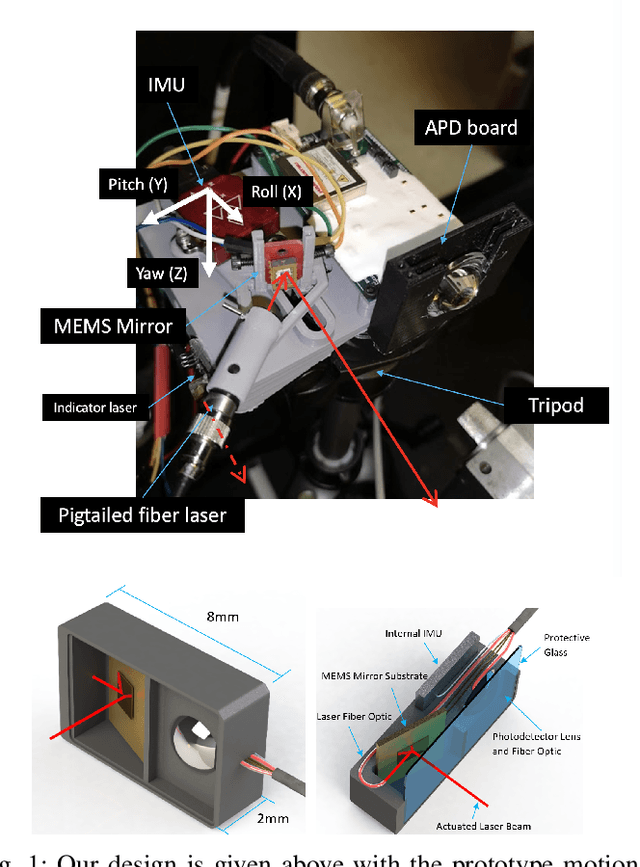
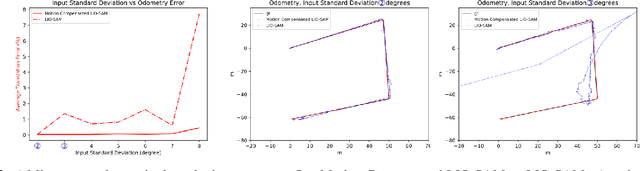
A fundamental challenge in robot perception is the coupling of the sensor pose and robot pose. This has led to research in active vision where robot pose is changed to reorient the sensor to areas of interest for perception. Further, egomotion such as jitter, and external effects such as wind and others affect perception requiring additional effort in software such as image stabilization. This effect is particularly pronounced in micro-air vehicles and micro-robots who typically are lighter and subject to larger jitter but do not have the computational capability to perform stabilization in real-time. We present a novel microelectromechanical (MEMS) mirror LiDAR system to change the field of view of the LiDAR independent of the robot motion. Our design has the potential for use on small, low-power systems where the expensive components of the LiDAR can be placed external to the small robot. We show the utility of our approach in simulation and on prototype hardware mounted on a UAV. We believe that this LiDAR and its compact movable scanning design provide mechanisms to decouple robot and sensor geometry allowing us to simplify robot perception. We also demonstrate examples of motion compensation using IMU and external odometry feedback in hardware.
Memory-aided Contrastive Consensus Learning for Co-salient Object Detection
Feb 28, 2023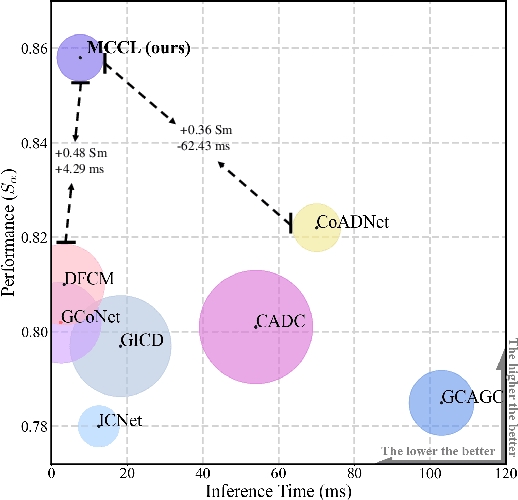
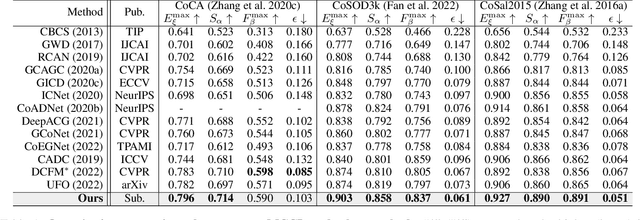
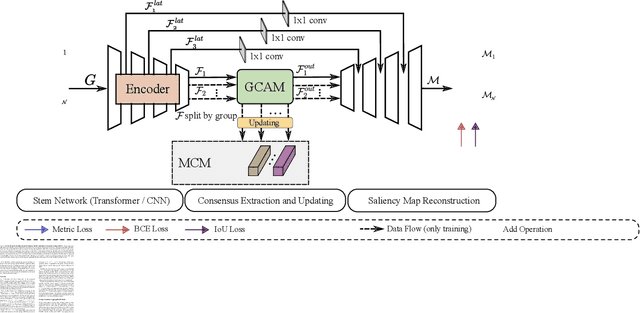

Co-Salient Object Detection (CoSOD) aims at detecting common salient objects within a group of relevant source images. Most of the latest works employ the attention mechanism for finding common objects. To achieve accurate CoSOD results with high-quality maps and high efficiency, we propose a novel Memory-aided Contrastive Consensus Learning (MCCL) framework, which is capable of effectively detecting co-salient objects in real time (~110 fps). To learn better group consensus, we propose the Group Consensus Aggregation Module (GCAM) to abstract the common features of each image group; meanwhile, to make the consensus representation more discriminative, we introduce the Memory-based Contrastive Module (MCM), which saves and updates the consensus of images from different groups in a queue of memories. Finally, to improve the quality and integrity of the predicted maps, we develop an Adversarial Integrity Learning (AIL) strategy to make the segmented regions more likely composed of complete objects with less surrounding noise. Extensive experiments on all the latest CoSOD benchmarks demonstrate that our lite MCCL outperforms 13 cutting-edge models, achieving the new state of the art (~5.9% and ~6.2% improvement in S-measure on CoSOD3k and CoSal2015, respectively). Our source codes, saliency maps, and online demos are publicly available at https://github.com/ZhengPeng7/MCCL.
PULL: Reactive Log Anomaly Detection Based On Iterative PU Learning
Jan 25, 2023Due to the complexity of modern IT services, failures can be manifold, occur at any stage, and are hard to detect. For this reason, anomaly detection applied to monitoring data such as logs allows gaining relevant insights to improve IT services steadily and eradicate failures. However, existing anomaly detection methods that provide high accuracy often rely on labeled training data, which are time-consuming to obtain in practice. Therefore, we propose PULL, an iterative log analysis method for reactive anomaly detection based on estimated failure time windows provided by monitoring systems instead of labeled data. Our attention-based model uses a novel objective function for weak supervision deep learning that accounts for imbalanced data and applies an iterative learning strategy for positive and unknown samples (PU learning) to identify anomalous logs. Our evaluation shows that PULL consistently outperforms ten benchmark baselines across three different datasets and detects anomalous log messages with an F1-score of more than 0.99 even within imprecise failure time windows.