 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WESPER: Zero-shot and Realtime Whisper to Normal Voice Conversion for Whisper-based Speech Interactions
Mar 03, 2023
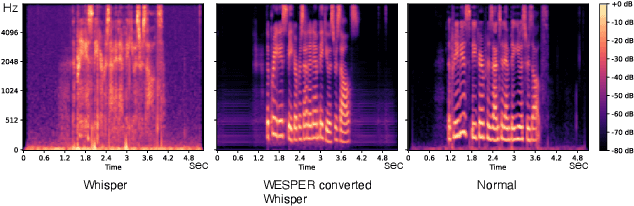

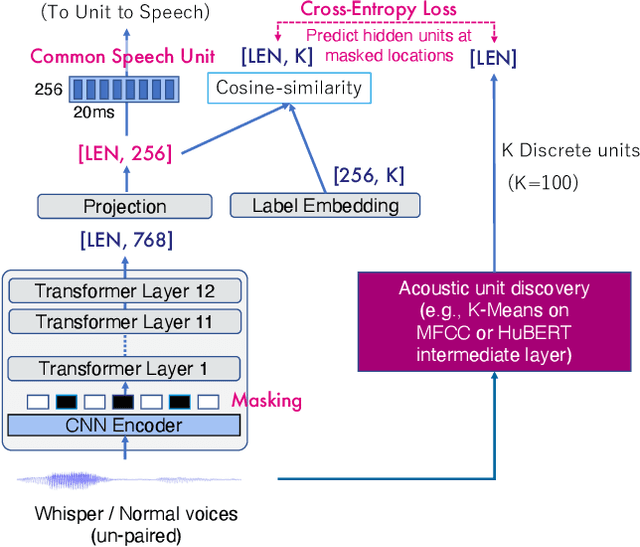
Recognizing whispered speech and converting it to normal speech creates many possibilities for speech interaction. Because the sound pressure of whispered speech is significantly lower than that of normal speech, it can be used as a semi-silent speech interaction in public places without being audible to others. Converting whispers to normal speech also improves the speech quality for people with speech or hearing impairments. However, conventional speech conversion techniques do not provide sufficient conversion quality or require speaker-dependent datasets consisting of pairs of whispered and normal speech utterances. To address these problems, we propose WESPER, a zero-shot, real-time whisper-to-normal speech conversion mechanism based on self-supervised learning. WESPER consists of a speech-to-unit (STU) encoder, which generates hidden speech units common to both whispered and normal speech, and a unit-to-speech (UTS) decoder, which reconstructs speech from the encoded speech units. Unlike the existing methods, this conversion is user-independent and does not require a paired dataset for whispered and normal speech. The UTS decoder can reconstruct speech in any target speaker's voice from speech units, and it requires only an unlabeled target speaker's speech data. We confirmed that the quality of the speech converted from a whisper was improved while preserving its natural prosody. Additionally, we confirmed the effectiveness of the proposed approach to perform speech reconstruction for people with speech or hearing disabilities. (project page: http://lab.rekimoto.org/projects/wesper )
* ACM CHI 2023 paper
Bi-parametric prostate MR image synthesis using pathology and sequence-conditioned stable diffusion
Mar 03, 2023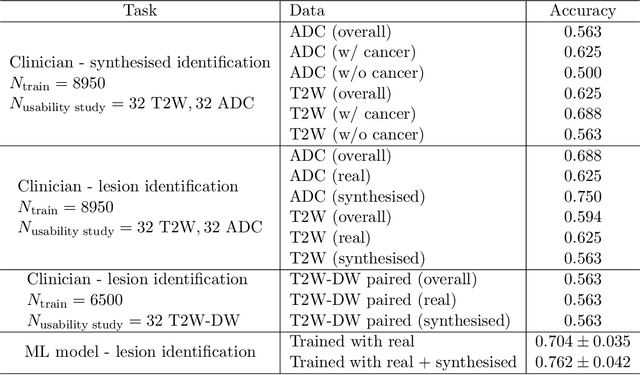

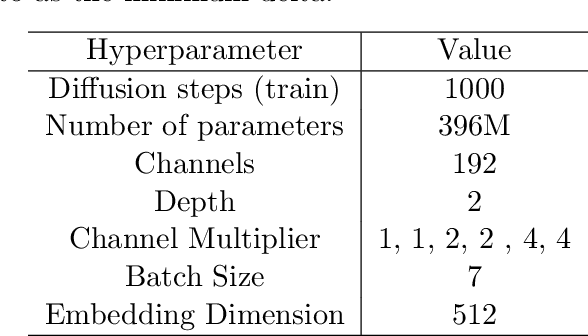
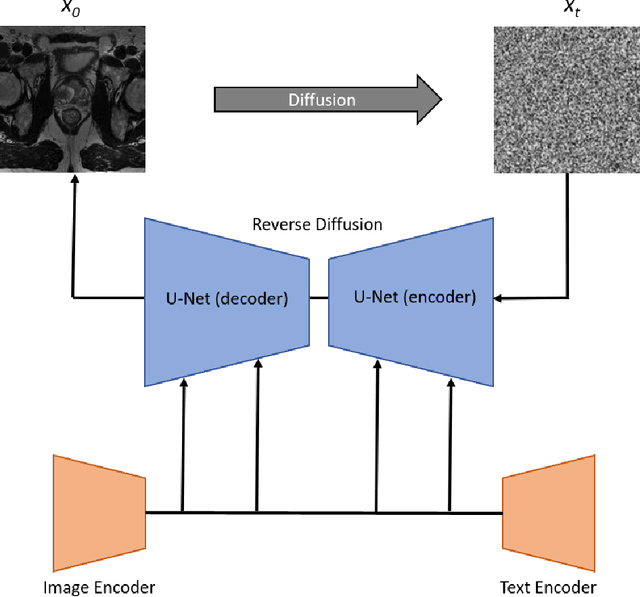
We propose an image synthesis mechanism for multi-sequence prostate MR images conditioned on text, to control lesion presence and sequence, as well as to generate paired bi-parametric images conditioned on images e.g. for generating diffusion-weighted MR from T2-weighted MR for paired data, which are two challenging tasks in pathological image synthesis. Our proposed mechanism utilises and builds upon the recent stable diffusion model by proposing image-based conditioning for paired data generation. We validate our method using 2D image slices from real suspected prostate cancer patients. The realism of the synthesised images is validated by means of a blind expert evaluation for identifying real versus fake images, where a radiologist with 4 years experience reading urological MR only achieves 59.4% accuracy across all tested sequences (where chance is 50%). For the first time, we evaluate the realism of the generated pathology by blind expert identification of the presence of suspected lesions, where we find that the clinician performs similarly for both real and synthesised images, with a 2.9 percentage point difference in lesion identification accuracy between real and synthesised images, demonstrating the potentials in radiological training purposes. Furthermore, we also show that a machine learning model, trained for lesion identification, shows better performance (76.2% vs 70.4%, statistically significant improvement) when trained with real data augmented by synthesised data as opposed to training with only real images, demonstrating usefulness for model training.
BSH-Det3D: Improving 3D Object Detection with BEV Shape Heatmap
Mar 03, 2023
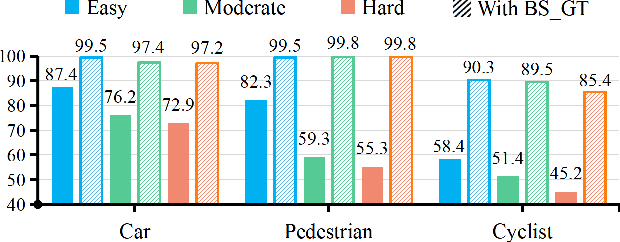
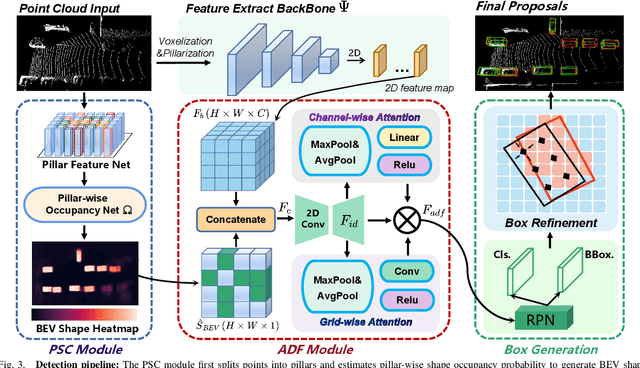
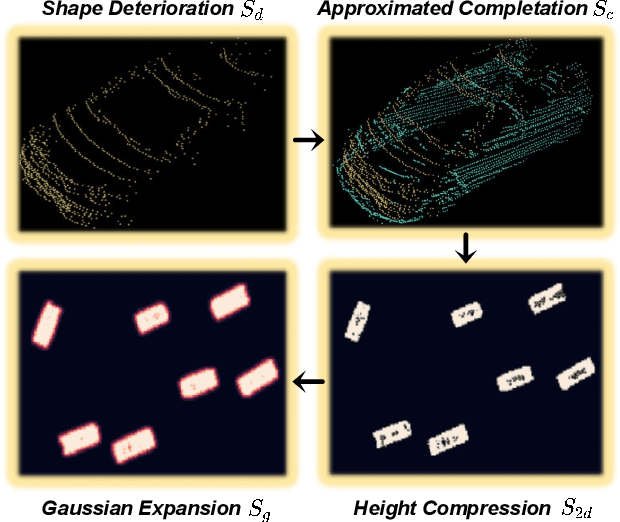
The progress of LiDAR-based 3D object detection has significantly enhanced developments in autonomous driving and robotics. However, due to the limitations of LiDAR sensors, object shapes suffer from deterioration in occluded and distant areas, which creates a fundamental challenge to 3D perception. Existing methods estimate specific 3D shapes and achieve remarkable performance. However, these methods rely on extensive computation and memory, causing imbalances between accuracy and real-time performance. To tackle this challenge, we propose a novel LiDAR-based 3D object detection model named BSH-Det3D, which applies an effective way to enhance spatial features by estimating complete shapes from a bird's eye view (BEV). Specifically, we design the Pillar-based Shape Completion (PSC) module to predict the probability of occupancy whether a pillar contains object shapes. The PSC module generates a BEV shape heatmap for each scene. After integrating with heatmaps, BSH-Det3D can provide additional information in shape deterioration areas and generate high-quality 3D proposals. We also design an attention-based densification fusion module (ADF) to adaptively associate the sparse features with heatmaps and raw points. The ADF module integrates the advantages of points and shapes knowledge with negligible overheads. Extensive experiments on the KITTI benchmark achieve state-of-the-art (SOTA) performance in terms of accuracy and speed, demonstrating the efficiency and flexibility of BSH-Det3D. The source code is available on https://github.com/mystorm16/BSH-Det3D.
Collaborative Learning with a Drone Orchestrator
Mar 03, 2023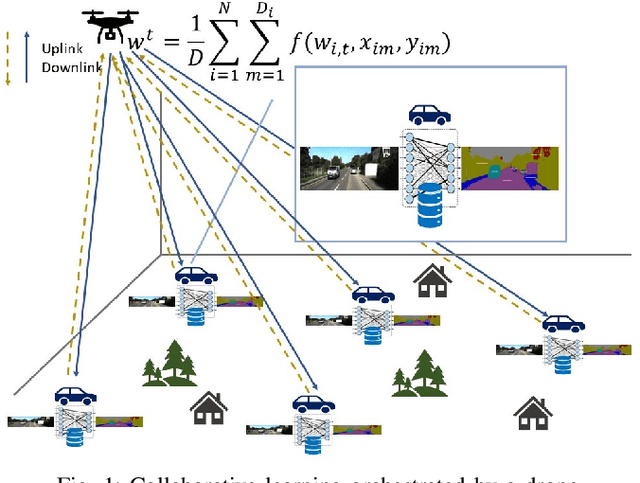
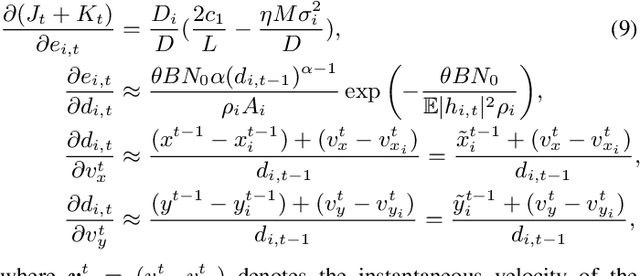
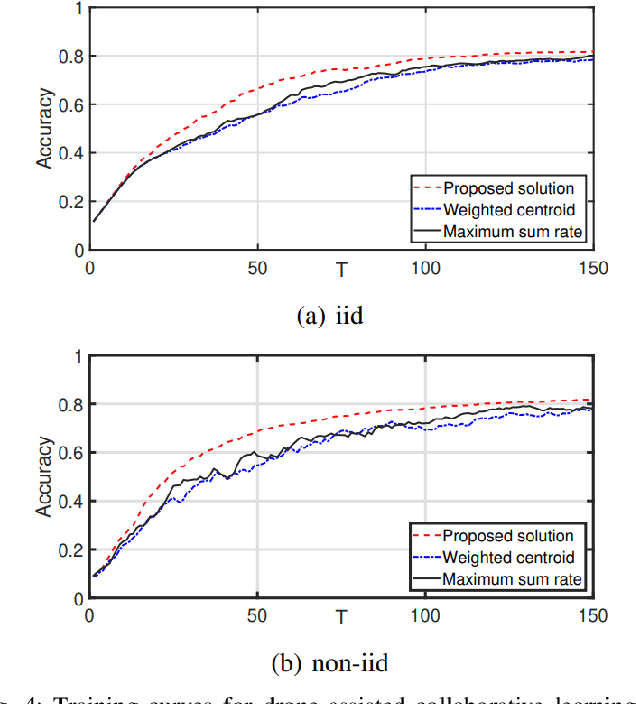
In this paper, the problem of drone-assisted collaborative learning is considered. In this scenario, swarm of intelligent wireless devices train a shared neural network (NN) model with the help of a drone. Using its sensors, each device records samples from its environment to gather a local dataset for training. The training data is severely heterogeneous as various devices have different amount of data and sensor noise level. The intelligent devices iteratively train the NN on their local datasets and exchange the model parameters with the drone for aggregation. For this system, the convergence rate of collaborative learning is derived while considering data heterogeneity, sensor noise levels, and communication errors, then, the drone trajectory that maximizes the final accuracy of the trained NN is obtained. The proposed trajectory optimization approach is aware of both the devices data characteristics (i.e., local dataset size and noise level) and their wireless channel conditions, and significantly improves the convergence rate and final accuracy in comparison with baselines that only consider data characteristics or channel conditions. Compared to state-of-the-art baselines, the proposed approach achieves an average 3.85% and 3.54% improvement in the final accuracy of the trained NN on benchmark datasets for image recognition and semantic segmentation tasks, respectively. Moreover, the proposed framework achieves a significant speedup in training, leading to an average 24% and 87% saving in the drone hovering time, communication overhead, and battery usage, respectively for these tasks.
Simple yet Effective Gradient-Free Graph Convolutional Networks
Feb 01, 2023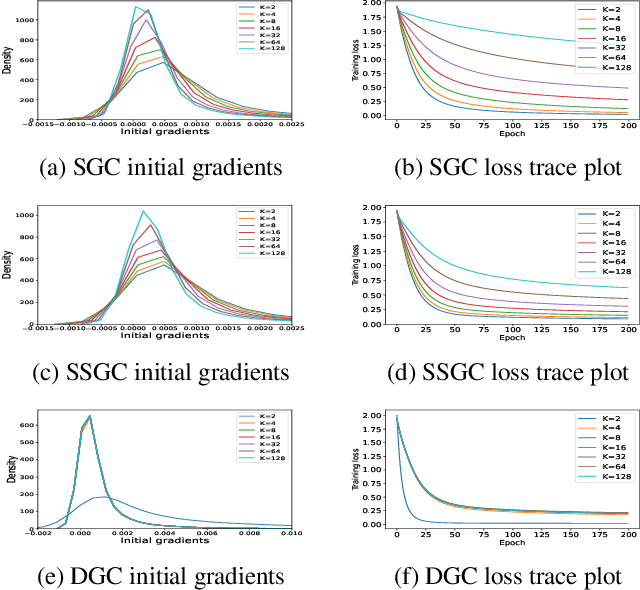
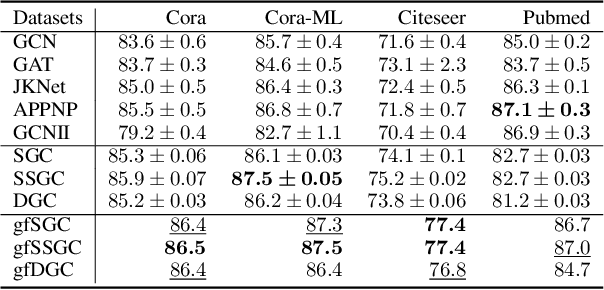
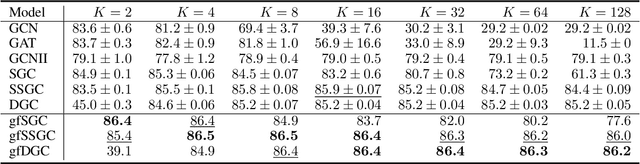
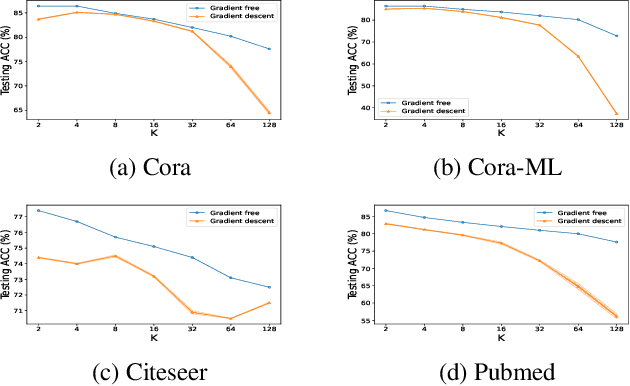
Linearized Graph Neural Networks (GNNs) have attracted great attention in recent years for graph representation learning. Compared with nonlinear Graph Neural Network (GNN) models, linearized GNNs are much more time-efficient and can achieve comparable performances on typical downstream tasks such as node classification. Although some linearized GNN variants are purposely crafted to mitigate ``over-smoothing", empirical studies demonstrate that they still somehow suffer from this issue. In this paper, we instead relate over-smoothing with the vanishing gradient phenomenon and craft a gradient-free training framework to achieve more efficient and effective linearized GNNs which can significantly overcome over-smoothing and enhance the generalization of the model. The experimental results demonstrate that our methods achieve better and more stable performances on node classification tasks with varying depths and cost much less training time.
Goal Driven Discovery of Distributional Differences via Language Descriptions
Feb 28, 2023

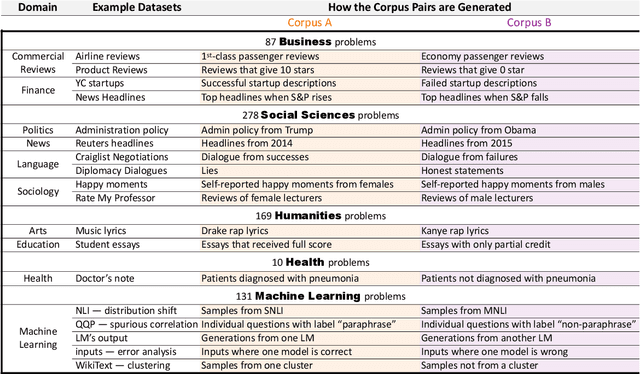
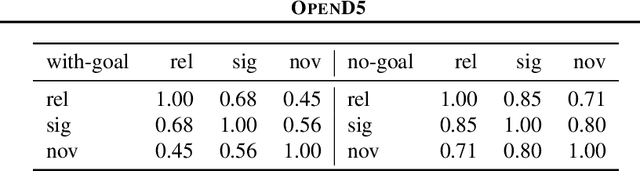
Mining large corpora can generate useful discoveries but is time-consuming for humans. We formulate a new task, D5, that automatically discovers differences between two large corpora in a goal-driven way. The task input is a problem comprising a research goal "$\textit{comparing the side effects of drug A and drug B}$" and a corpus pair (two large collections of patients' self-reported reactions after taking each drug). The output is a language description (discovery) of how these corpora differ (patients taking drug A "$\textit{mention feelings of paranoia}$" more often). We build a D5 system, and to quantitatively measure its performance, we 1) contribute a meta-dataset, OpenD5, aggregating 675 open-ended problems ranging across business, social sciences, humanities, machine learning, and health, and 2) propose a set of unified evaluation metrics: validity, relevance, novelty, and significance. With the dataset and the unified metrics, we confirm that language models can use the goals to propose more relevant, novel, and significant candidate discoveries. Finally, our system produces discoveries previously unknown to the authors on a wide range of applications in OpenD5, including temporal and demographic differences in discussion topics, political stances and stereotypes in speech, insights in commercial reviews, and error patterns in NLP models.
Adapter Incremental Continual Learning of Efficient Audio Spectrogram Transformers
Feb 28, 2023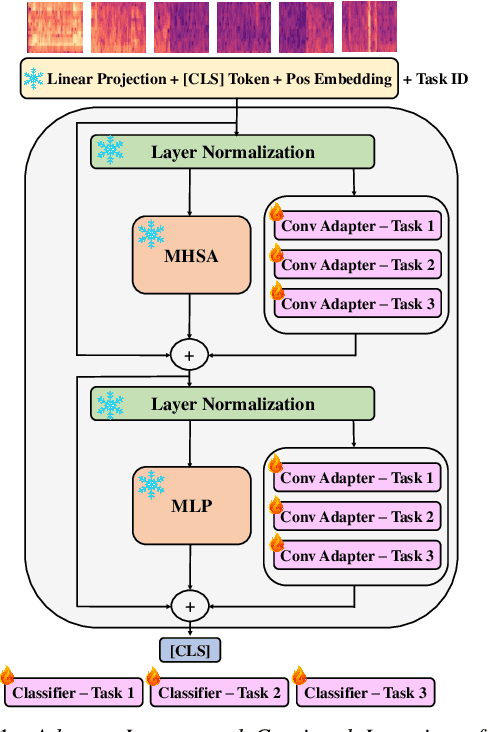

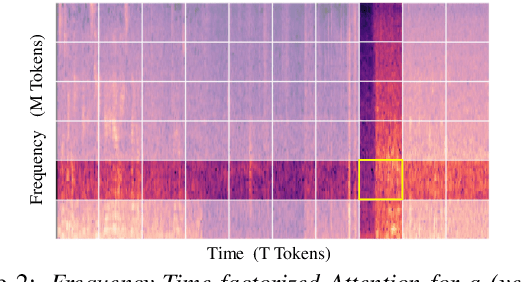
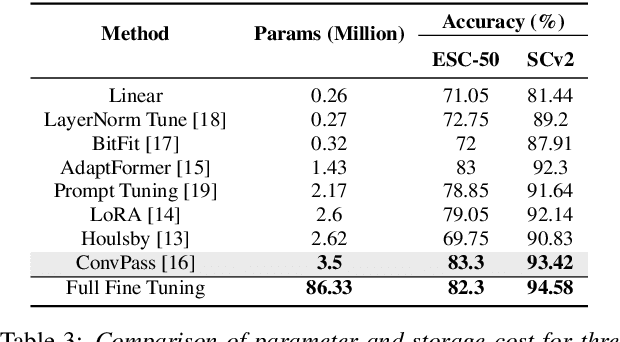
Continual learning involves training neural networks incrementally for new tasks while retaining the knowledge of previous tasks. However, efficiently fine-tuning the model for sequential tasks with minimal computational resources remains a challenge. In this paper, we propose Task Incremental Continual Learning (TI-CL) of audio classifiers with both parameter-efficient and compute-efficient Audio Spectrogram Transformers (AST). To reduce the trainable parameters without performance degradation for TI-CL, we compare several Parameter Efficient Transfer (PET) methods and propose AST with Convolutional Adapters for TI-CL, which has less than 5% of trainable parameters of the fully fine-tuned counterparts. To reduce the computational complexity, we introduce a novel Frequency-Time factorized Attention (FTA) method that replaces the traditional self-attention in transformers for audio spectrograms. FTA achieves competitive performance with only a factor of the computations required by Global Self-Attention (GSA). Finally, we formulate our method for TI-CL, called Adapter Incremental Continual Learning (AI-CL), as a combination of the "parameter-efficient" Convolutional Adapter and the "compute-efficient" FTA. Experiments on ESC-50, SpeechCommandsV2 (SCv2), and Audio-Visual Event (AVE) benchmarks show that our proposed method prevents catastrophic forgetting in TI-CL while maintaining a lower computational budget.
On the Road to 6G: Visions, Requirements, Key Technologies and Testbeds
Feb 28, 2023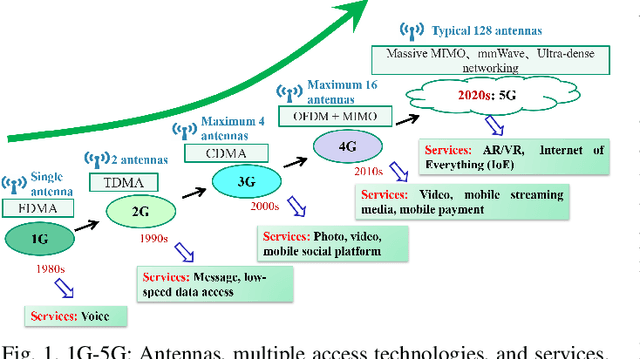

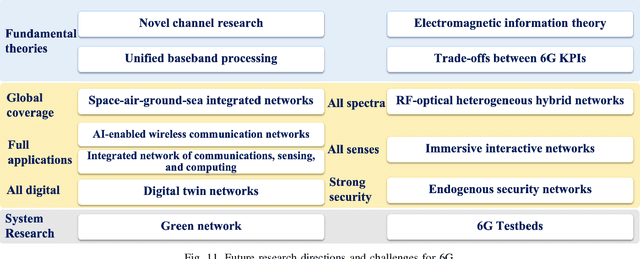
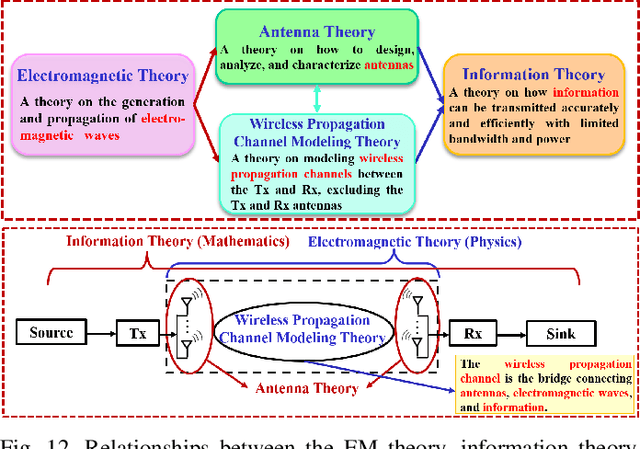
Fifth generation (5G) mobile communication systems have entered the stage of commercial development, providing users with new services and improved user experiences as well as offering a host of novel opportunities to various industries. However, 5G still faces many challenges. To address these challenges, international industrial, academic, and standards organizations have commenced research on sixth generation (6G) wireless communication systems. A series of white papers and survey papers have been published, which aim to define 6G in terms of requirements, application scenarios, key technologies, etc. Although ITU-R has been working on the 6G vision and it is expected to reach a consensus on what 6G will be by mid-2023, the related global discussions are still wide open and the existing literature has identified numerous open issues. This paper first provides a comprehensive portrayal of the 6G vision, technical requirements, and application scenarios, covering the current common understanding of 6G. Then, a critical appraisal of the 6G network architecture and key technologies is presented. Furthermore, existing testbeds and advanced 6G verification platforms are detailed for the first time. In addition, future research directions and open challenges are identified for stimulating the on-going global debate. Finally, lessons learned to date concerning 6G networks are discussed.
Onboard dynamic-object detection and tracking for autonomous robot navigation with RGB-D camera
Feb 28, 2023

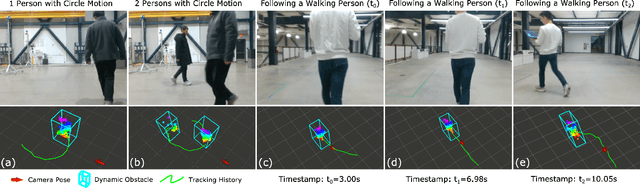
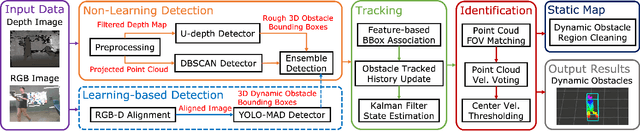
Deploying autonomous robots in crowded indoor environments usually requires them to have accurate dynamic obstacle perception. Although plenty of previous works in the autonomous driving field have investigated the 3D object detection problem, the usage of dense point clouds from a heavy LiDAR and their high computation cost for learning-based data processing make those methods not applicable to lightweight robots, such as vision-based UAVs with small onboard computers. To address this issue, we propose a lightweight 3D dynamic obstacle detection and tracking (DODT) method based on an RGB-D camera. Our method adopts a novel ensemble detection strategy, combining multiple computationally efficient but low-accuracy detectors to achieve real-time high-accuracy obstacle detection. Besides, we introduce a new feature-based data association method to prevent mismatches and use the Kalman filter with the constant acceleration model to track detected obstacles. In addition, our system includes an optional and auxiliary learning-based module to enhance the obstacle detection range and dynamic obstacle identification. The users can determine whether or not to run this module based on the available computation resources. The proposed method is implemented in a lightweight quadcopter, and the experiments prove that the algorithm can make the robot detect dynamic obstacles and navigate dynamic environments safely.
Automatic Scoring of Dream Reports' Emotional Content with Large Language Models
Feb 28, 2023
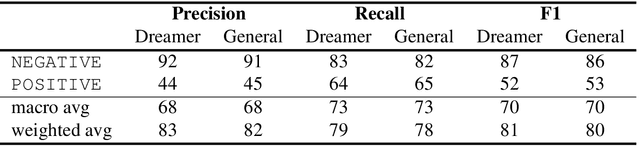
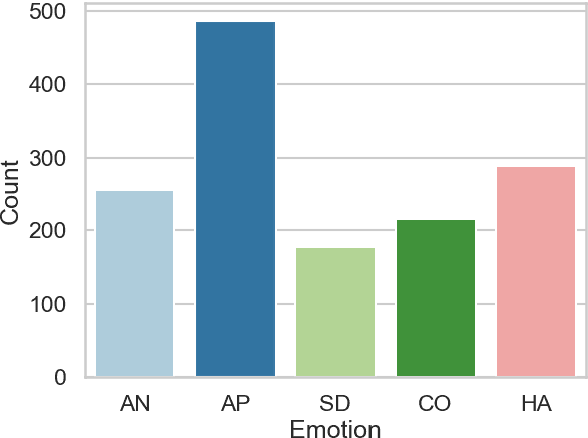
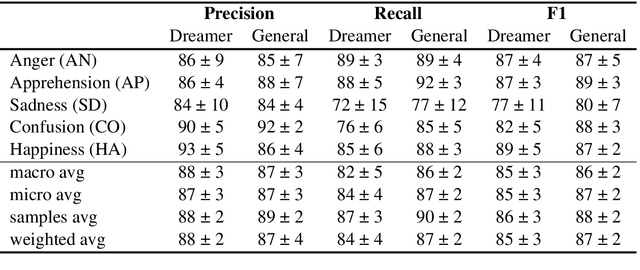
In the field of dream research, the study of dream content typically relies on the analysis of verbal reports provided by dreamers upon awakening from their sleep. This task is classically performed through manual scoring provided by trained annotators, at a great time expense. While a consistent body of work suggests that natural language processing (NLP) tools can support the automatic analysis of dream reports, proposed methods lacked the ability to reason over a report's full context and required extensive data pre-processing. Furthermore, in most cases, these methods were not validated against standard manual scoring approaches. In this work, we address these limitations by adopting large language models (LLMs) to study and replicate the manual annotation of dream reports, using a mixture of off-the-shelf and bespoke approaches, with a focus on references to reports' emotions. Our results show that the off-the-shelf method achieves a low performance probably in light of inherent linguistic differences between reports collected in different (groups of) individuals. On the other hand, the proposed bespoke text classification method achieves a high performance, which is robust against potential biases. Overall, these observations indicate that our approach could find application in the analysis of large dream datasets and may favour reproducibility and comparability of results across studies.