 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
adaPARL: Adaptive Privacy-Aware Reinforcement Learning for Sequential-Decision Making Human-in-the-Loop Systems
Mar 07, 2023
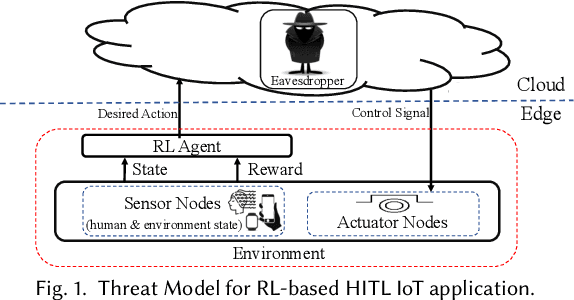
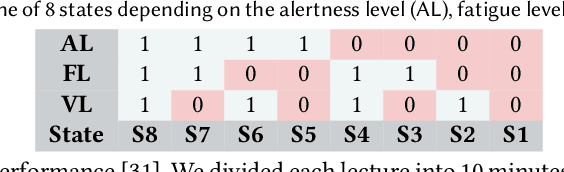
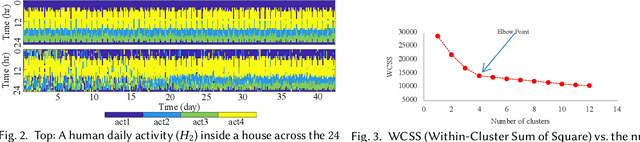
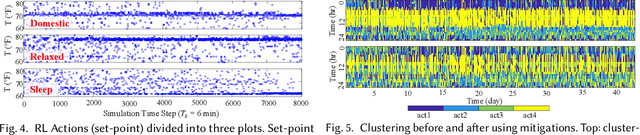
Reinforcement learning (RL) presents numerous benefits compared to rule-based approaches in various applications. Privacy concerns have grown with the widespread use of RL trained with privacy-sensitive data in IoT devices, especially for human-in-the-loop systems. On the one hand, RL methods enhance the user experience by trying to adapt to the highly dynamic nature of humans. On the other hand, trained policies can leak the user's private information. Recent attention has been drawn to designing privacy-aware RL algorithms while maintaining an acceptable system utility. A central challenge in designing privacy-aware RL, especially for human-in-the-loop systems, is that humans have intrinsic variability and their preferences and behavior evolve. The effect of one privacy leak mitigation can be different for the same human or across different humans over time. Hence, we can not design one fixed model for privacy-aware RL that fits all. To that end, we propose adaPARL, an adaptive approach for privacy-aware RL, especially for human-in-the-loop IoT systems. adaPARL provides a personalized privacy-utility trade-off depending on human behavior and preference. We validate the proposed adaPARL on two IoT applications, namely (i) Human-in-the-Loop Smart Home and (ii) Human-in-the-Loop Virtual Reality (VR) Smart Classroom. Results obtained on these two applications validate the generality of adaPARL and its ability to provide a personalized privacy-utility trade-off. On average, for the first application, adaPARL improves the utility by $57\%$ over the baseline and by $43\%$ over randomization. adaPARL also reduces the privacy leak by $23\%$ on average. For the second application, adaPARL decreases the privacy leak to $44\%$ before the utility drops by $15\%$.
VA-DepthNet: A Variational Approach to Single Image Depth Prediction
Feb 13, 2023
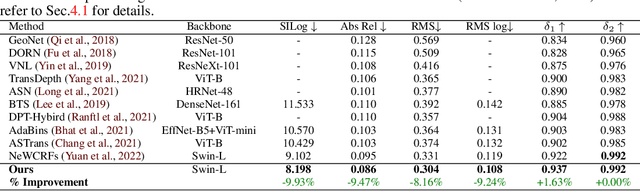
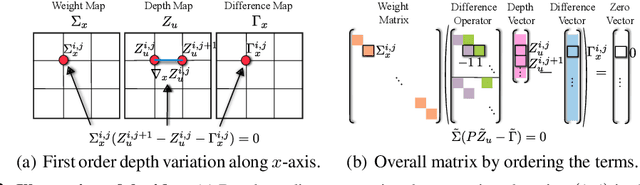

We introduce VA-DepthNet, a simple, effective, and accurate deep neural network approach for the single-image depth prediction (SIDP) problem. The proposed approach advocates using classical first-order variational constraints for this problem. While state-of-the-art deep neural network methods for SIDP learn the scene depth from images in a supervised setting, they often overlook the invaluable invariances and priors in the rigid scene space, such as the regularity of the scene. The paper's main contribution is to reveal the benefit of classical and well-founded variational constraints in the neural network design for the SIDP task. It is shown that imposing first-order variational constraints in the scene space together with popular encoder-decoder-based network architecture design provides excellent results for the supervised SIDP task. The imposed first-order variational constraint makes the network aware of the depth gradient in the scene space, i.e., regularity. The paper demonstrates the usefulness of the proposed approach via extensive evaluation and ablation analysis over several benchmark datasets, such as KITTI, NYU Depth V2, and SUN RGB-D. The VA-DepthNet at test time shows considerable improvements in depth prediction accuracy compared to the prior art and is accurate also at high-frequency regions in the scene space. At the time of writing this paper, our method -- labeled as VA-DepthNet, when tested on the KITTI depth-prediction evaluation set benchmarks, shows state-of-the-art results, and is the top-performing published approach.
Transient Hemodynamics Prediction Using an Efficient Octree-Based Deep Learning Model
Feb 13, 2023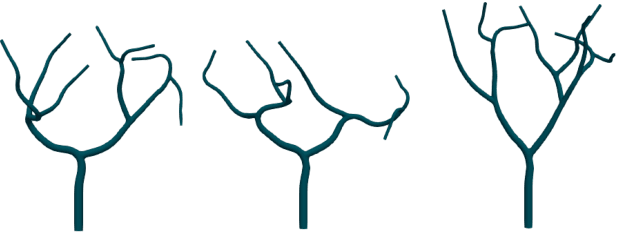
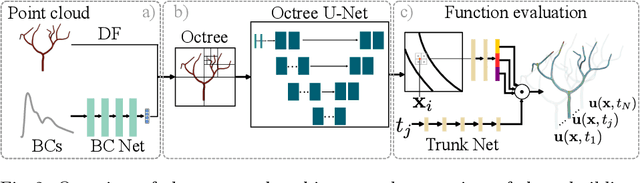
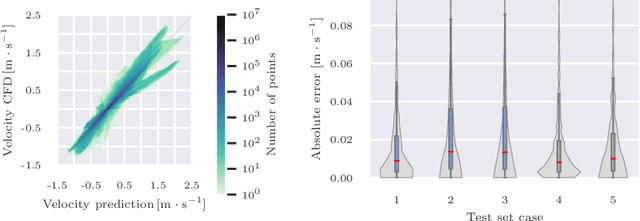
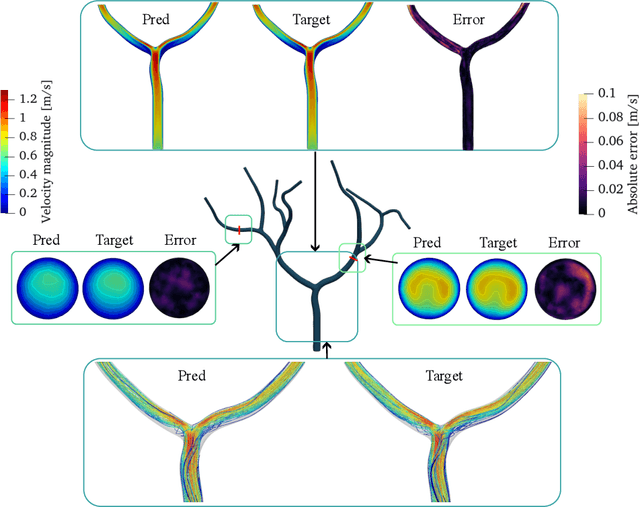
Patient-specific hemodynamics assessment could support diagnosis and treatment of neurovascular diseases. Currently, conventional medical imaging modalities are not able to accurately acquire high-resolution hemodynamic information that would be required to assess complex neurovascular pathologies. Therefore, computational fluid dynamics (CFD) simulations can be applied to tomographic reconstructions to obtain clinically relevant information. However, three-dimensional (3D) CFD simulations require enormous computational resources and simulation-related expert knowledge that are usually not available in clinical environments. Recently, deep-learning-based methods have been proposed as CFD surrogates to improve computational efficiency. Nevertheless, the prediction of high-resolution transient CFD simulations for complex vascular geometries poses a challenge to conventional deep learning models. In this work, we present an architecture that is tailored to predict high-resolution (spatial and temporal) velocity fields for complex synthetic vascular geometries. For this, an octree-based spatial discretization is combined with an implicit neural function representation to efficiently handle the prediction of the 3D velocity field for each time step. The presented method is evaluated for the task of cerebral hemodynamics prediction before and during the injection of contrast agent in the internal carotid artery (ICA). Compared to CFD simulations, the velocity field can be estimated with a mean absolute error of 0.024 m/s, whereas the run time reduces from several hours on a high-performance cluster to a few seconds on a consumer graphical processing unit.
Optimal Allocation of Many Robot Guards for Sweep-Line Coverage
Feb 08, 2023


We study the problem of allocating many mobile robots for the execution of a pre-defined sweep schedule in a known two-dimensional environment, with applications toward search and rescue, coverage, surveillance, monitoring, pursuit-evasion, and so on. The mobile robots (or agents) are assumed to have one-dimensional sensing capability with probabilistic guarantees that deteriorate as the sensing distance increases. In solving such tasks, a time-parameterized distribution of robots along the sweep frontier must be computed, with the objective to minimize the number of robots used to achieve some desired coverage quality guarantee or to maximize the probabilistic guarantee for a given number of robots. We propose a max-flow based algorithm for solving the allocation task, which builds on a decomposition technique of the workspace as a generalization of the well-known boustrophedon decomposition. Our proposed algorithm has a very low polynomial running time and completes in under two seconds for polygonal environments with over $10^5$ vertices. Simulation experiments are carried out on three realistic use cases with randomly generated obstacles of varying shapes, sizes, and spatial distributions, which demonstrate the applicability and scalability our proposed method.
The Hypervolume Indicator Hessian Matrix: Analytical Expression, Computational Time Complexity, and Sparsity
Nov 08, 2022

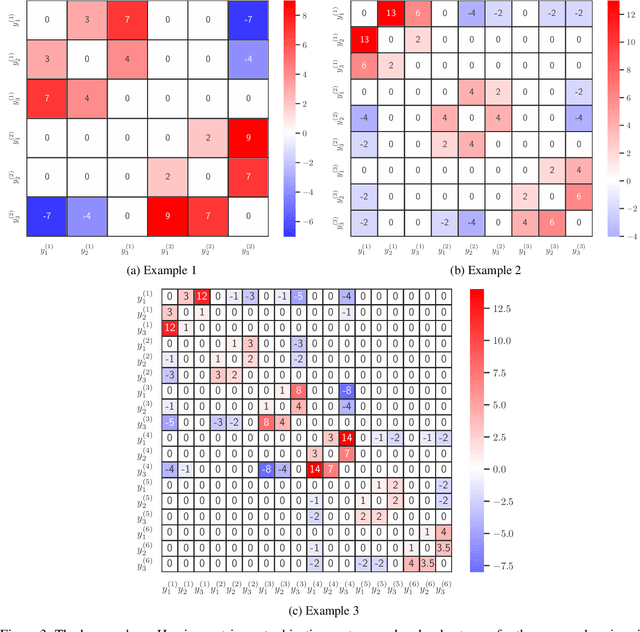
The problem of approximating the Pareto front of a multiobjective optimization problem can be reformulated as the problem of finding a set that maximizes the hypervolume indicator. This paper establishes the analytical expression of the Hessian matrix of the mapping from a (fixed size) collection of $n$ points in the $d$-dimensional decision space (or $m$ dimensional objective space) to the scalar hypervolume indicator value. To define the Hessian matrix, the input set is vectorized, and the matrix is derived by analytical differentiation of the mapping from a vectorized set to the hypervolume indicator. The Hessian matrix plays a crucial role in second-order methods, such as the Newton-Raphson optimization method, and it can be used for the verification of local optimal sets. So far, the full analytical expression was only established and analyzed for the relatively simple bi-objective case. This paper will derive the full expression for arbitrary dimensions ($m\geq2$ objective functions). For the practically important three-dimensional case, we also provide an asymptotically efficient algorithm with time complexity in $O(n\log n)$ for the exact computation of the Hessian Matrix' non-zero entries. We establish a sharp bound of $12m-6$ for the number of non-zero entries. Also, for the general $m$-dimensional case, a compact recursive analytical expression is established, and its algorithmic implementation is discussed. Also, for the general case, some sparsity results can be established; these results are implied by the recursive expression. To validate and illustrate the analytically derived algorithms and results, we provide a few numerical examples using Python and Mathematica implementations. Open-source implementations of the algorithms and testing data are made available as a supplement to this paper.
Finding Things in the Unknown: Semantic Object-Centric Exploration with an MAV
Mar 03, 2023
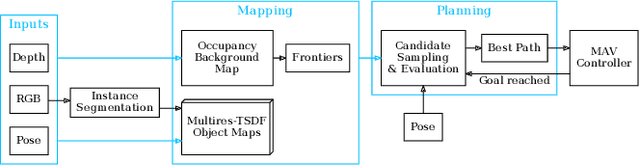
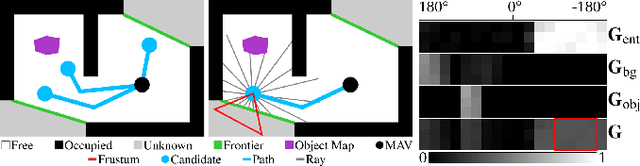

Exploration of unknown space with an autonomous mobile robot is a well-studied problem. In this work we broaden the scope of exploration, moving beyond the pure geometric goal of uncovering as much free space as possible. We believe that for many practical applications, exploration should be contextualised with semantic and object-level understanding of the environment for task-specific exploration. Here, we study the task of both finding specific objects in unknown space as well as reconstructing them to a target level of detail. We therefore extend our environment reconstruction to not only consist of a background map, but also object-level and semantically fused submaps. Importantly, we adapt our previous objective function of uncovering as much free space as possible in as little time as possible with two additional elements: first, we require a maximum observation distance of background surfaces to ensure target objects are not missed by image-based detectors because they are too small to be detected. Second, we require an even smaller maximum distance to the found objects in order to reconstruct them with the desired accuracy. We further created a Micro Aerial Vehicle (MAV) semantic exploration simulator based on Habitat in order to quantitatively demonstrate how our framework can be used to efficiently find specific objects as part of exploration. Finally, we showcase this capability can be deployed in real-world scenes involving our drone equipped with an Intel RealSense D455 RGB-D camera.
Visual Exemplar Driven Task-Prompting for Unified Perception in Autonomous Driving
Mar 03, 2023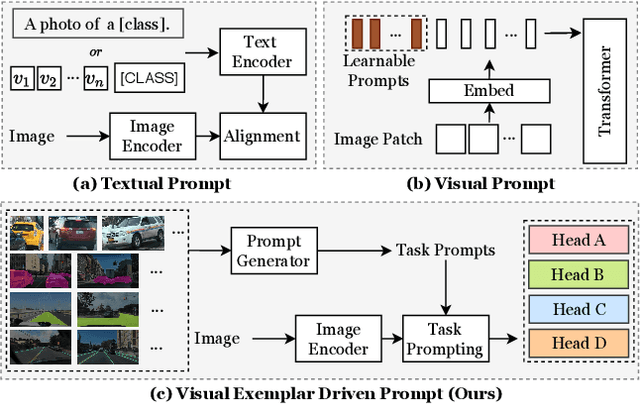
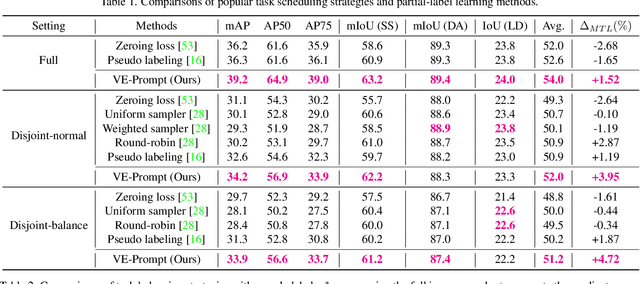
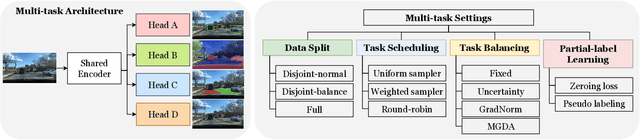
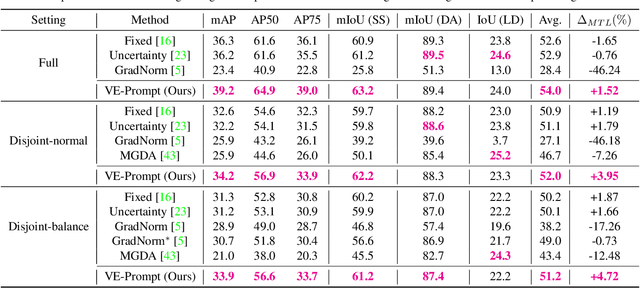
Multi-task learning has emerged as a powerful paradigm to solve a range of tasks simultaneously with good efficiency in both computation resources and inference time. However, these algorithms are designed for different tasks mostly not within the scope of autonomous driving, thus making it hard to compare multi-task methods in autonomous driving. Aiming to enable the comprehensive evaluation of present multi-task learning methods in autonomous driving, we extensively investigate the performance of popular multi-task methods on the large-scale driving dataset, which covers four common perception tasks, i.e., object detection, semantic segmentation, drivable area segmentation, and lane detection. We provide an in-depth analysis of current multi-task learning methods under different common settings and find out that the existing methods make progress but there is still a large performance gap compared with single-task baselines. To alleviate this dilemma in autonomous driving, we present an effective multi-task framework, VE-Prompt, which introduces visual exemplars via task-specific prompting to guide the model toward learning high-quality task-specific representations. Specifically, we generate visual exemplars based on bounding boxes and color-based markers, which provide accurate visual appearances of target categories and further mitigate the performance gap. Furthermore, we bridge transformer-based encoders and convolutional layers for efficient and accurate unified perception in autonomous driving. Comprehensive experimental results on the diverse self-driving dataset BDD100K show that the VE-Prompt improves the multi-task baseline and further surpasses single-task models.
WESPER: Zero-shot and Realtime Whisper to Normal Voice Conversion for Whisper-based Speech Interactions
Mar 03, 2023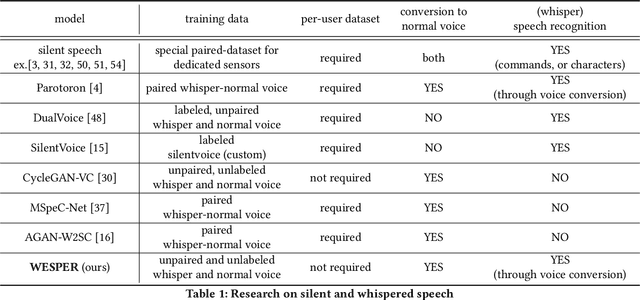
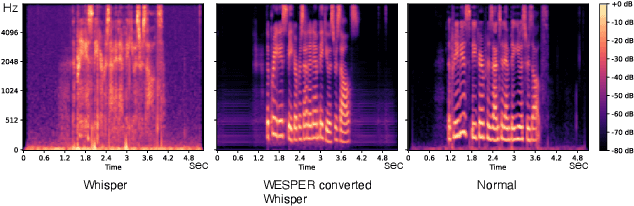

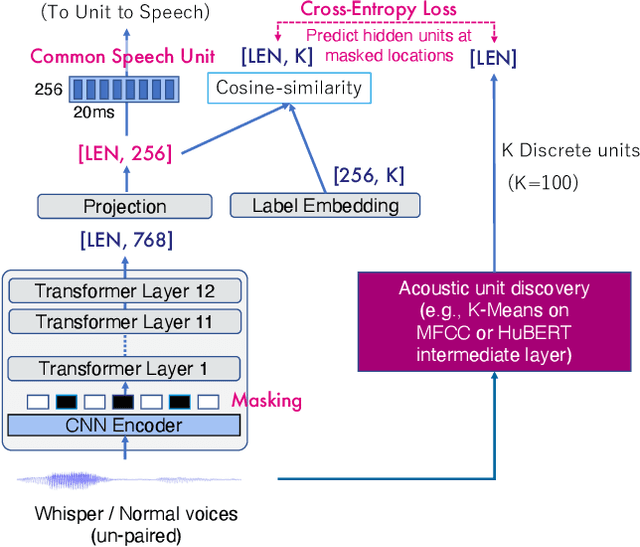
Recognizing whispered speech and converting it to normal speech creates many possibilities for speech interaction. Because the sound pressure of whispered speech is significantly lower than that of normal speech, it can be used as a semi-silent speech interaction in public places without being audible to others. Converting whispers to normal speech also improves the speech quality for people with speech or hearing impairments. However, conventional speech conversion techniques do not provide sufficient conversion quality or require speaker-dependent datasets consisting of pairs of whispered and normal speech utterances. To address these problems, we propose WESPER, a zero-shot, real-time whisper-to-normal speech conversion mechanism based on self-supervised learning. WESPER consists of a speech-to-unit (STU) encoder, which generates hidden speech units common to both whispered and normal speech, and a unit-to-speech (UTS) decoder, which reconstructs speech from the encoded speech units. Unlike the existing methods, this conversion is user-independent and does not require a paired dataset for whispered and normal speech. The UTS decoder can reconstruct speech in any target speaker's voice from speech units, and it requires only an unlabeled target speaker's speech data. We confirmed that the quality of the speech converted from a whisper was improved while preserving its natural prosody. Additionally, we confirmed the effectiveness of the proposed approach to perform speech reconstruction for people with speech or hearing disabilities. (project page: http://lab.rekimoto.org/projects/wesper )
* ACM CHI 2023 paper
Bi-parametric prostate MR image synthesis using pathology and sequence-conditioned stable diffusion
Mar 03, 2023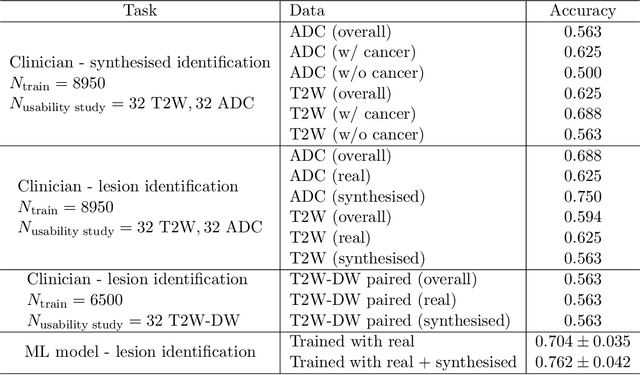

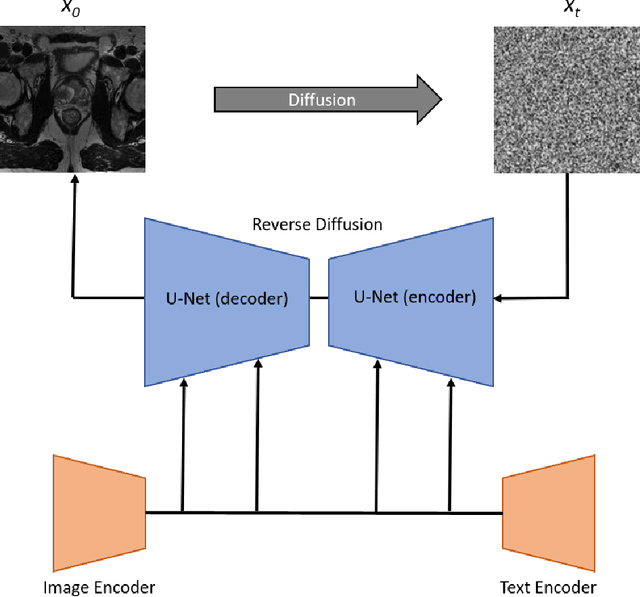
We propose an image synthesis mechanism for multi-sequence prostate MR images conditioned on text, to control lesion presence and sequence, as well as to generate paired bi-parametric images conditioned on images e.g. for generating diffusion-weighted MR from T2-weighted MR for paired data, which are two challenging tasks in pathological image synthesis. Our proposed mechanism utilises and builds upon the recent stable diffusion model by proposing image-based conditioning for paired data generation. We validate our method using 2D image slices from real suspected prostate cancer patients. The realism of the synthesised images is validated by means of a blind expert evaluation for identifying real versus fake images, where a radiologist with 4 years experience reading urological MR only achieves 59.4% accuracy across all tested sequences (where chance is 50%). For the first time, we evaluate the realism of the generated pathology by blind expert identification of the presence of suspected lesions, where we find that the clinician performs similarly for both real and synthesised images, with a 2.9 percentage point difference in lesion identification accuracy between real and synthesised images, demonstrating the potentials in radiological training purposes. Furthermore, we also show that a machine learning model, trained for lesion identification, shows better performance (76.2% vs 70.4%, statistically significant improvement) when trained with real data augmented by synthesised data as opposed to training with only real images, demonstrating usefulness for model training.
BSH-Det3D: Improving 3D Object Detection with BEV Shape Heatmap
Mar 03, 2023
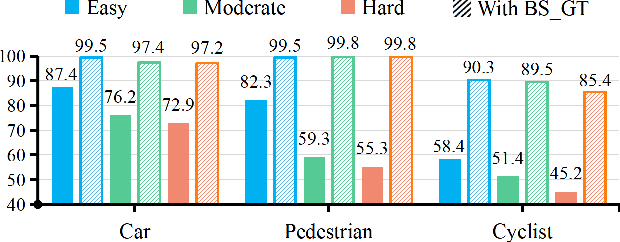
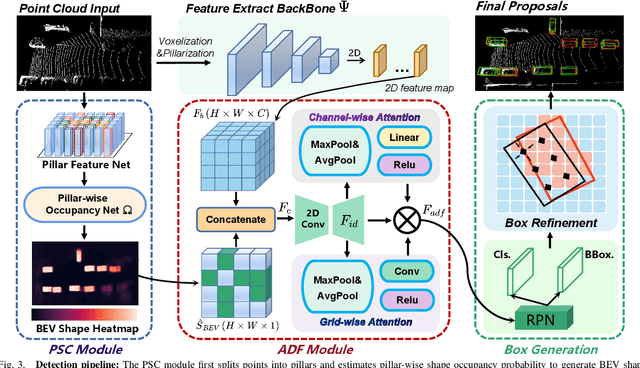
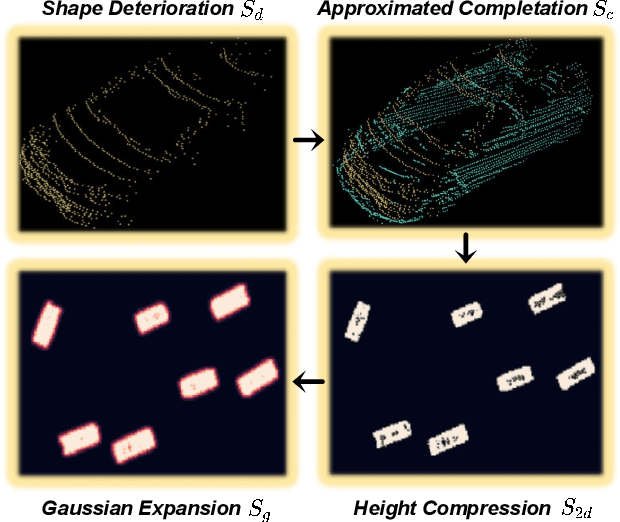
The progress of LiDAR-based 3D object detection has significantly enhanced developments in autonomous driving and robotics. However, due to the limitations of LiDAR sensors, object shapes suffer from deterioration in occluded and distant areas, which creates a fundamental challenge to 3D perception. Existing methods estimate specific 3D shapes and achieve remarkable performance. However, these methods rely on extensive computation and memory, causing imbalances between accuracy and real-time performance. To tackle this challenge, we propose a novel LiDAR-based 3D object detection model named BSH-Det3D, which applies an effective way to enhance spatial features by estimating complete shapes from a bird's eye view (BEV). Specifically, we design the Pillar-based Shape Completion (PSC) module to predict the probability of occupancy whether a pillar contains object shapes. The PSC module generates a BEV shape heatmap for each scene. After integrating with heatmaps, BSH-Det3D can provide additional information in shape deterioration areas and generate high-quality 3D proposals. We also design an attention-based densification fusion module (ADF) to adaptively associate the sparse features with heatmaps and raw points. The ADF module integrates the advantages of points and shapes knowledge with negligible overheads. Extensive experiments on the KITTI benchmark achieve state-of-the-art (SOTA) performance in terms of accuracy and speed, demonstrating the efficiency and flexibility of BSH-Det3D. The source code is available on https://github.com/mystorm16/BSH-Det3D.