 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CVTNet: A Cross-View Transformer Network for Place Recognition Using LiDAR Data
Feb 03, 2023

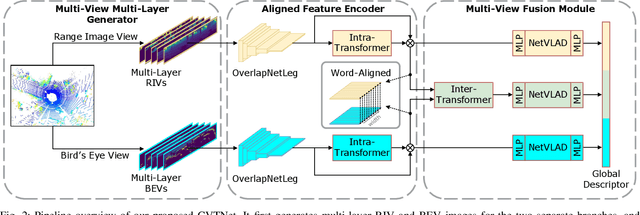
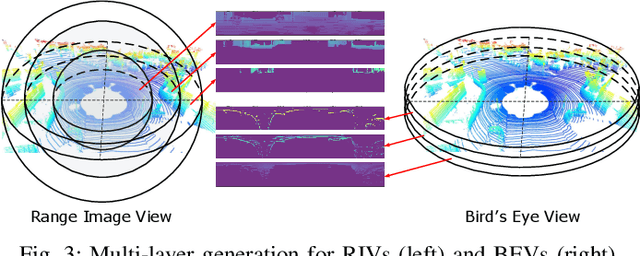
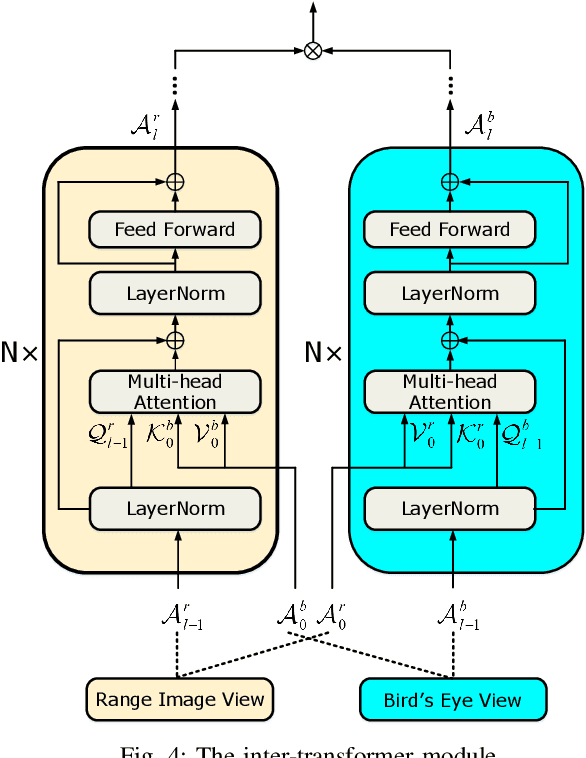
LiDAR-based place recognition (LPR) is one of the most crucial components of autonomous vehicles to identify previously visited places in GPS-denied environments. Most existing LPR methods use mundane representations of the input point cloud without considering different views, which may not fully exploit the information from LiDAR sensors. In this paper, we propose a cross-view transformer-based network, dubbed CVTNet, to fuse the range image views (RIVs) and bird's eye views (BEVs) generated from the LiDAR data. It extracts correlations within the views themselves using intra-transformers and between the two different views using inter-transformers. Based on that, our proposed CVTNet generates a yaw-angle-invariant global descriptor for each laser scan end-to-end online and retrieves previously seen places by descriptor matching between the current query scan and the pre-built database. We evaluate our approach on three datasets collected with different sensor setups and environmental conditions. The experimental results show that our method outperforms the state-of-the-art LPR methods with strong robustness to viewpoint changes and long-time spans. Furthermore, our approach has a good real-time performance that can run faster than the typical LiDAR frame rate. The implementation of our method is released as open source at: https://github.com/BIT-MJY/CVTNet.
ANTM: An Aligned Neural Topic Model for Exploring Evolving Topics
Feb 03, 2023

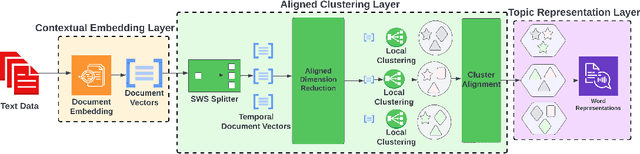
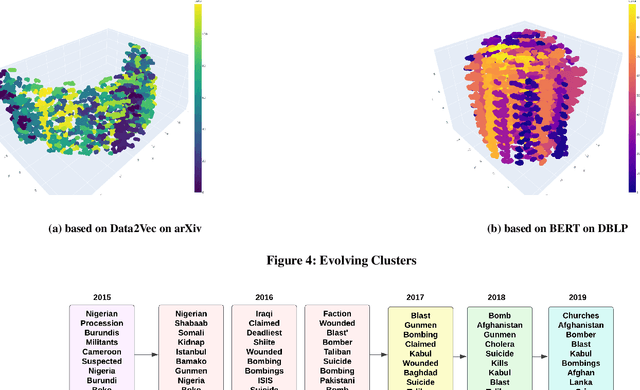
As the amount of text data generated by humans and machines increases, the necessity of understanding large corpora and finding a way to extract insights from them is becoming more crucial than ever. Dynamic topic models are effective methods that primarily focus on studying the evolution of topics present in a collection of documents. These models are widely used for understanding trends, exploring public opinion in social networks, or tracking research progress and discoveries in scientific archives. Since topics are defined as clusters of semantically similar documents, it is necessary to observe the changes in the content or themes of these clusters in order to understand how topics evolve as new knowledge is discovered over time. In this paper, we introduce the Aligned Neural Topic Model (ANTM), a dynamic neural topic model that uses document embeddings to compute clusters of semantically similar documents at different periods and to align document clusters to represent their evolution. This alignment procedure preserves the temporal similarity of document clusters over time and captures the semantic change of words characterized by their context within different periods. Experiments on four different datasets show that ANTM outperforms probabilistic dynamic topic models (e.g. DTM, DETM) and significantly improves topic coherence and diversity over other existing dynamic neural topic models (e.g. BERTopic).
Zero3D: Semantic-Driven Multi-Category 3D Shape Generation
Feb 13, 2023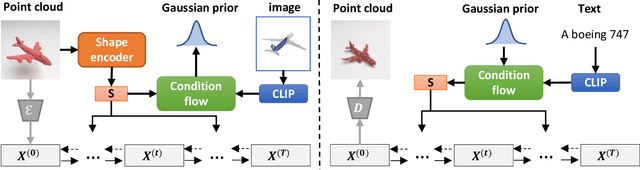
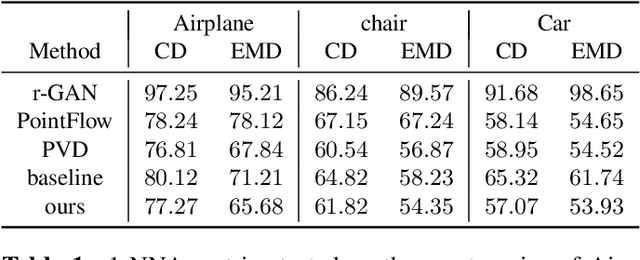
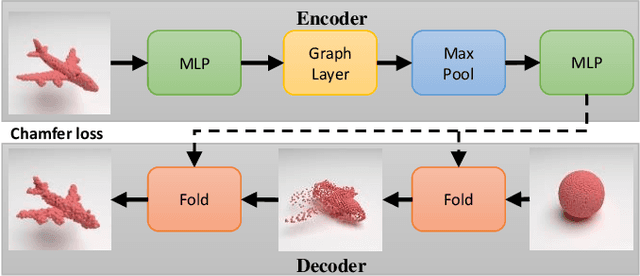
Semantic-driven 3D shape generation aims to generate 3D objects conditioned on text. Previous works face problems with single-category generation, low-frequency 3D details, and requiring a large number of paired datasets for training. To tackle these challenges, we propose a multi-category conditional diffusion model. Specifically, 1) to alleviate the problem of lack of large-scale paired data, we bridge the text, 2D image and 3D shape based on the pre-trained CLIP model, and 2) to obtain the multi-category 3D shape feature, we apply the conditional flow model to generate 3D shape vector conditioned on CLIP embedding. 3) to generate multi-category 3D shape, we employ the hidden-layer diffusion model conditioned on the multi-category shape vector, which greatly reduces the training time and memory consumption.
Content-Adaptive Motion Rate Adaption for Learned Video Compression
Feb 13, 2023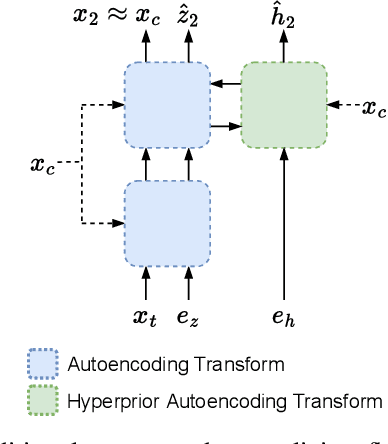
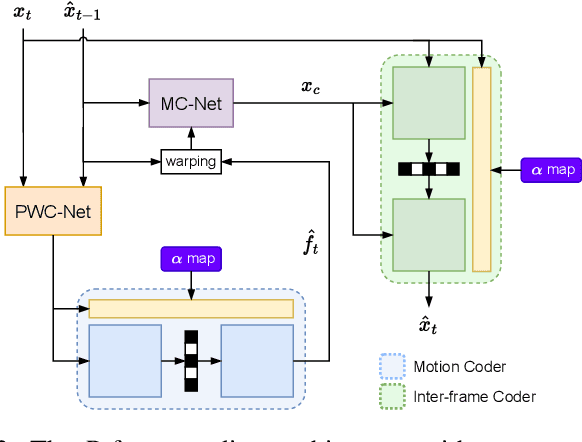
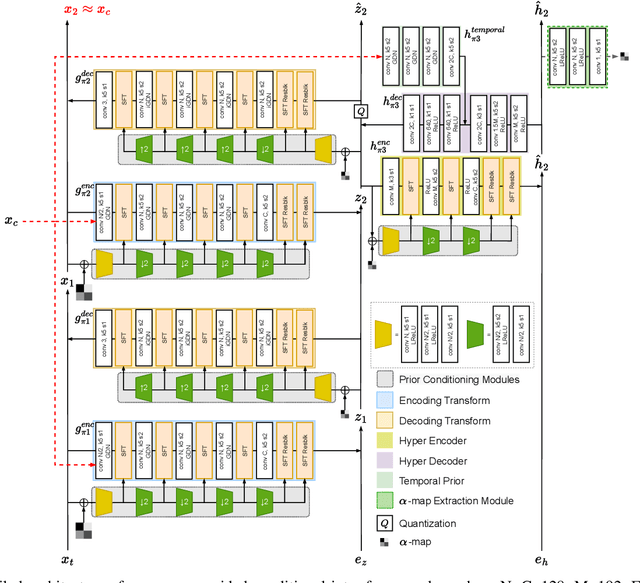
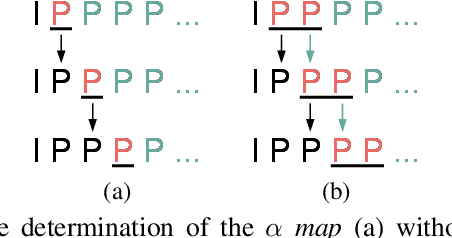
This paper introduces an online motion rate adaptation scheme for learned video compression, with the aim of achieving content-adaptive coding on individual test sequences to mitigate the domain gap between training and test data. It features a patch-level bit allocation map, termed the $\alpha$-map, to trade off between the bit rates for motion and inter-frame coding in a spatially-adaptive manner. We optimize the $\alpha$-map through an online back-propagation scheme at inference time. Moreover, we incorporate a look-ahead mechanism to consider its impact on future frames. Extensive experimental results confirm that the proposed scheme, when integrated into a conditional learned video codec, is able to adapt motion bit rate effectively, showing much improved rate-distortion performance particularly on test sequences with complicated motion characteristics.
Deep Neural Networks for Encrypted Inference with TFHE
Feb 13, 2023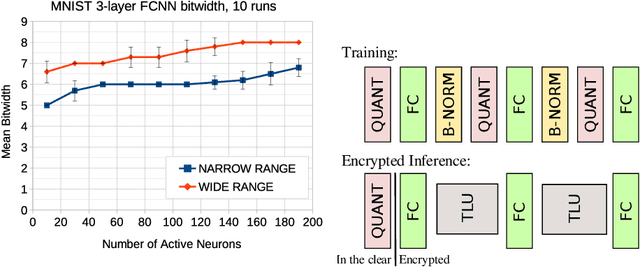
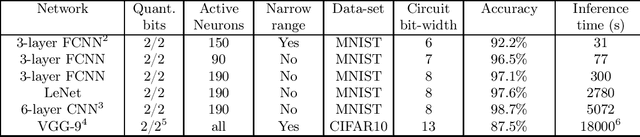
Fully homomorphic encryption (FHE) is an encryption method that allows to perform computation on encrypted data, without decryption. FHE preserves the privacy of the users of online services that handle sensitive data, such as health data, biometrics, credit scores and other personal information. A common way to provide a valuable service on such data is through machine learning and, at this time, Neural Networks are the dominant machine learning model for unstructured data. In this work we show how to construct Deep Neural Networks (DNN) that are compatible with the constraints of TFHE, an FHE scheme that allows arbitrary depth computation circuits. We discuss the constraints and show the architecture of DNNs for two computer vision tasks. We benchmark the architectures using the Concrete stack, an open-source implementation of TFHE.
Near-Optimal Cryptographic Hardness of Agnostically Learning Halfspaces and ReLU Regression under Gaussian Marginals
Feb 13, 2023We study the task of agnostically learning halfspaces under the Gaussian distribution. Specifically, given labeled examples $(\mathbf{x},y)$ from an unknown distribution on $\mathbb{R}^n \times \{ \pm 1\}$, whose marginal distribution on $\mathbf{x}$ is the standard Gaussian and the labels $y$ can be arbitrary, the goal is to output a hypothesis with 0-1 loss $\mathrm{OPT}+\epsilon$, where $\mathrm{OPT}$ is the 0-1 loss of the best-fitting halfspace. We prove a near-optimal computational hardness result for this task, under the widely believed sub-exponential time hardness of the Learning with Errors (LWE) problem. Prior hardness results are either qualitatively suboptimal or apply to restricted families of algorithms. Our techniques extend to yield near-optimal lower bounds for related problems, including ReLU regression.
GraphTTA: Test Time Adaptation on Graph Neural Networks
Aug 19, 2022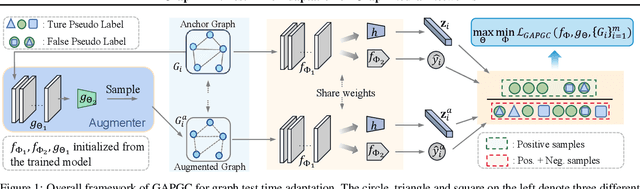
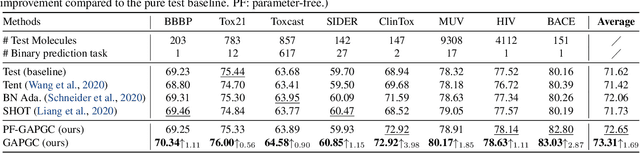
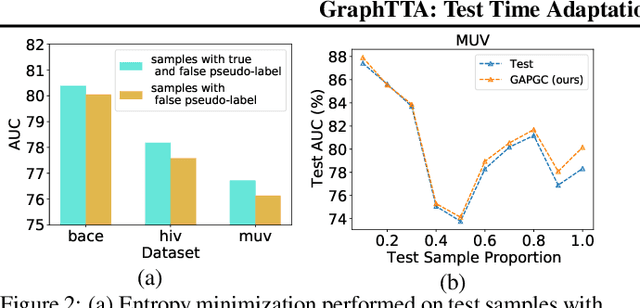

Recently, test time adaptation (TTA) has attracted increasing attention due to its power of handling the distribution shift issue in the real world. Unlike what has been developed for convolutional neural networks (CNNs) for image data, TTA is less explored for Graph Neural Networks (GNNs). There is still a lack of efficient algorithms tailored for graphs with irregular structures. In this paper, we present a novel test time adaptation strategy named Graph Adversarial Pseudo Group Contrast (GAPGC), for graph neural networks TTA, to better adapt to the Out Of Distribution (OOD) test data. Specifically, GAPGC employs a contrastive learning variant as a self-supervised task during TTA, equipped with Adversarial Learnable Augmenter and Group Pseudo-Positive Samples to enhance the relevance between the self-supervised task and the main task, boosting the performance of the main task. Furthermore, we provide theoretical evidence that GAPGC can extract minimal sufficient information for the main task from information theory perspective. Extensive experiments on molecular scaffold OOD dataset demonstrated that the proposed approach achieves state-of-the-art performance on GNNs.
Can ChatGPT Write a Good Boolean Query for Systematic Review Literature Search?
Feb 09, 2023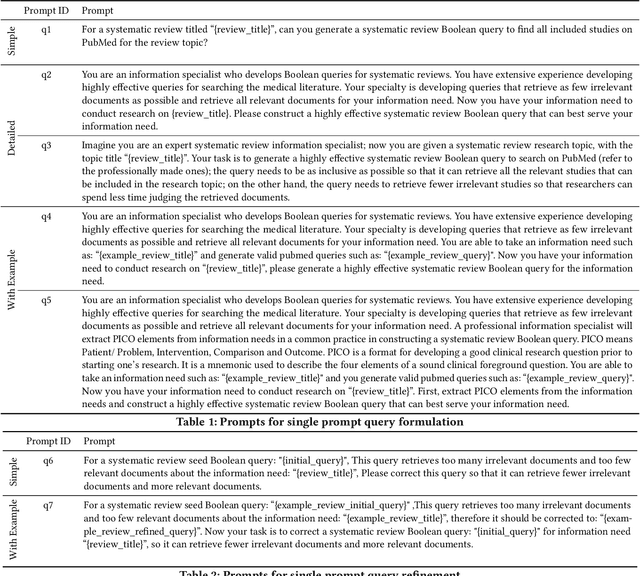

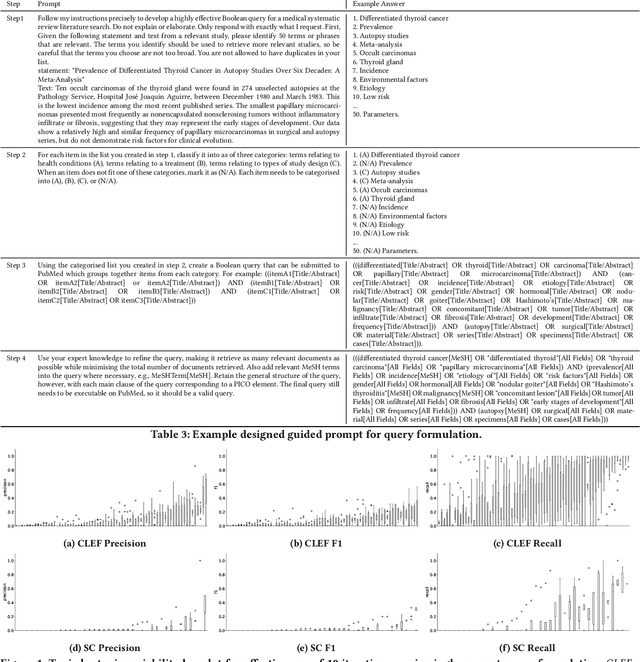

Systematic reviews are comprehensive reviews of the literature for a highly focused research question. These reviews are often treated as the highest form of evidence in evidence-based medicine, and are the key strategy to answer research questions in the medical field. To create a high-quality systematic review, complex Boolean queries are often constructed to retrieve studies for the review topic. However, it often takes a long time for systematic review researchers to construct a high quality systematic review Boolean query, and often the resulting queries are far from effective. Poor queries may lead to biased or invalid reviews, because they missed to retrieve key evidence, or to extensive increase in review costs, because they retrieved too many irrelevant studies. Recent advances in Transformer-based generative models have shown great potential to effectively follow instructions from users and generate answers based on the instructions being made. In this paper, we investigate the effectiveness of the latest of such models, ChatGPT, in generating effective Boolean queries for systematic review literature search. Through a number of extensive experiments on standard test collections for the task, we find that ChatGPT is capable of generating queries that lead to high search precision, although trading-off this for recall. Overall, our study demonstrates the potential of ChatGPT in generating effective Boolean queries for systematic review literature search. The ability of ChatGPT to follow complex instructions and generate queries with high precision makes it a valuable tool for researchers conducting systematic reviews, particularly for rapid reviews where time is a constraint and often trading-off higher precision for lower recall is acceptable.
LyricJam Sonic: A Generative System for Real-Time Composition and Musical Improvisation
Oct 27, 2022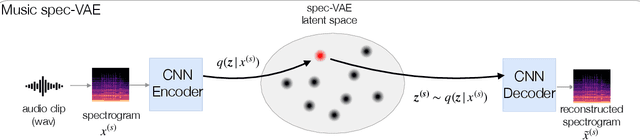

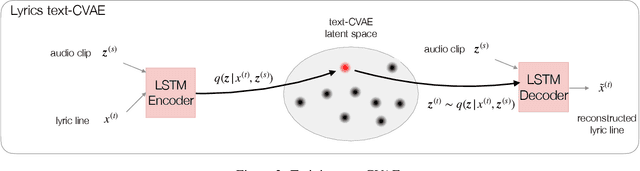
Electronic music artists and sound designers have unique workflow practices that necessitate specialized approaches for developing music information retrieval and creativity support tools. Furthermore, electronic music instruments, such as modular synthesizers, have near-infinite possibilities for sound creation and can be combined to create unique and complex audio paths. The process of discovering interesting sounds is often serendipitous and impossible to replicate. For this reason, many musicians in electronic genres record audio output at all times while they work in the studio. Subsequently, it is difficult for artists to rediscover audio segments that might be suitable for use in their compositions from thousands of hours of recordings. In this paper, we describe LyricJam Sonic -- a novel creative tool for musicians to rediscover their previous recordings, re-contextualize them with other recordings, and create original live music compositions in real-time. A bi-modal AI-driven approach uses generated lyric lines to find matching audio clips from the artist's past studio recordings, and uses them to generate new lyric lines, which in turn are used to find other clips, thus creating a continuous and evolving stream of music and lyrics. The intent is to keep the artists in a state of creative flow conducive to music creation rather than taking them into an analytical/critical state of deliberately searching for past audio segments. The system can run in either a fully autonomous mode without user input, or in a live performance mode, where the artist plays live music, while the system "listens" and creates a continuous stream of music and lyrics in response.
Learning Goal-based Movement via Motivational-based Models in Cognitive Mobile Robots
Feb 20, 2023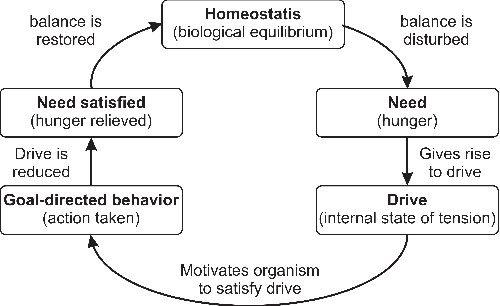
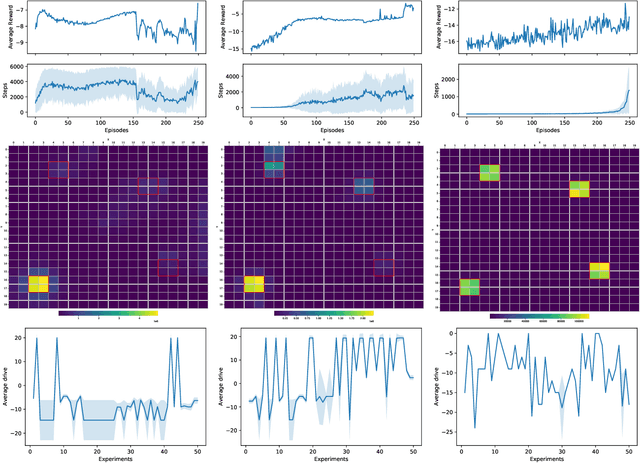
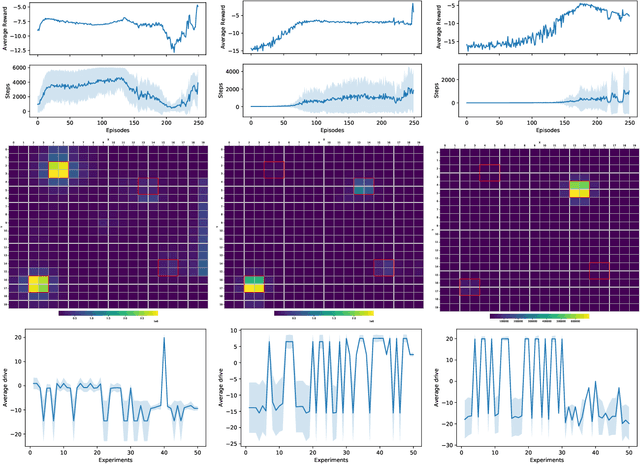
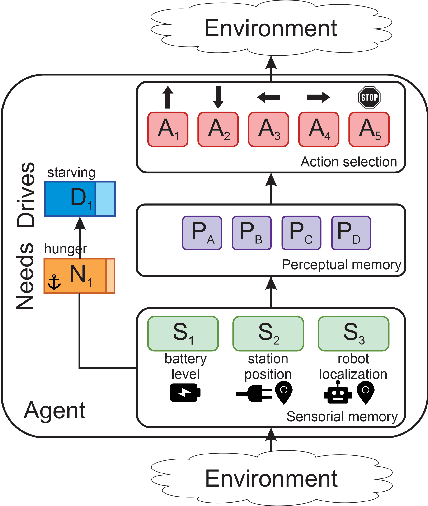
Humans have needs motivating their behavior according to intensity and context. However, we also create preferences associated with each action's perceived pleasure, which is susceptible to changes over time. This makes decision-making more complex, requiring learning to balance needs and preferences according to the context. To understand how this process works and enable the development of robots with a motivational-based learning model, we computationally model a motivation theory proposed by Hull. In this model, the agent (an abstraction of a mobile robot) is motivated to keep itself in a state of homeostasis. We added hedonic dimensions to see how preferences affect decision-making, and we employed reinforcement learning to train our motivated-based agents. We run three agents with energy decay rates representing different metabolisms in two different environments to see the impact on their strategy, movement, and behavior. The results show that the agent learned better strategies in the environment that enables choices more adequate according to its metabolism. The use of pleasure in the motivational mechanism significantly impacted behavior learning, mainly for slow metabolism agents. When survival is at risk, the agent ignores pleasure and equilibrium, hinting at how to behave in harsh scenarios.