 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast, Sample-Efficient, Affine-Invariant Private Mean and Covariance Estimation for Subgaussian Distributions
Jan 28, 2023

We present a fast, differentially private algorithm for high-dimensional covariance-aware mean estimation with nearly optimal sample complexity. Only exponential-time estimators were previously known to achieve this guarantee. Given $n$ samples from a (sub-)Gaussian distribution with unknown mean $\mu$ and covariance $\Sigma$, our $(\varepsilon,\delta)$-differentially private estimator produces $\tilde{\mu}$ such that $\|\mu - \tilde{\mu}\|_{\Sigma} \leq \alpha$ as long as $n \gtrsim \tfrac d {\alpha^2} + \tfrac{d \sqrt{\log 1/\delta}}{\alpha \varepsilon}+\frac{d\log 1/\delta}{\varepsilon}$. The Mahalanobis error metric $\|\mu - \hat{\mu}\|_{\Sigma}$ measures the distance between $\hat \mu$ and $\mu$ relative to $\Sigma$; it characterizes the error of the sample mean. Our algorithm runs in time $\tilde{O}(nd^{\omega - 1} + nd/\varepsilon)$, where $\omega < 2.38$ is the matrix multiplication exponent. We adapt an exponential-time approach of Brown, Gaboardi, Smith, Ullman, and Zakynthinou (2021), giving efficient variants of stable mean and covariance estimation subroutines that also improve the sample complexity to the nearly optimal bound above. Our stable covariance estimator can be turned to private covariance estimation for unrestricted subgaussian distributions. With $n\gtrsim d^{3/2}$ samples, our estimate is accurate in spectral norm. This is the first such algorithm using $n= o(d^2)$ samples, answering an open question posed by Alabi et al. (2022). With $n\gtrsim d^2$ samples, our estimate is accurate in Frobenius norm. This leads to a fast, nearly optimal algorithm for private learning of unrestricted Gaussian distributions in TV distance. Duchi, Haque, and Kuditipudi (2023) obtained similar results independently and concurrently.
Spectral Cross-Domain Neural Network with Soft-adaptive Threshold Spectral Enhancement
Jan 10, 2023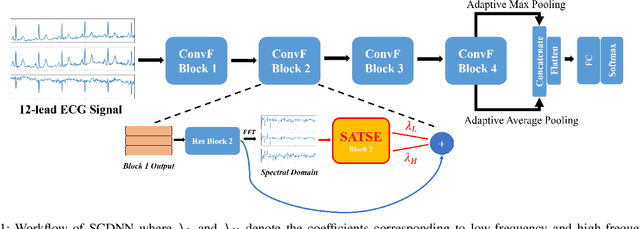
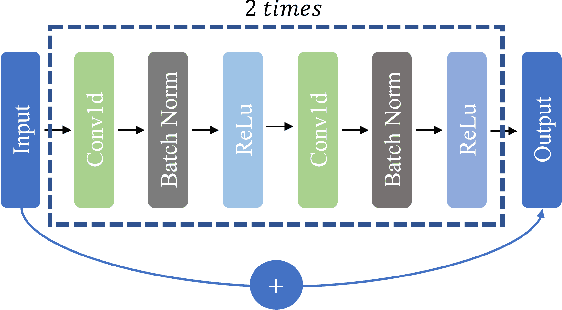
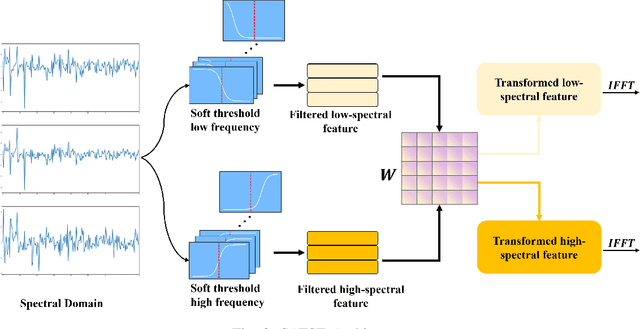
Electrocardiography (ECG) signals can be considered as multi-variable time-series. The state-of-the-art ECG data classification approaches, based on either feature engineering or deep learning techniques, treat separately spectral and time domains in machine learning systems. No spectral-time domain communication mechanism inside the classifier model can be found in current approaches, leading to difficulties in identifying complex ECG forms. In this paper, we proposed a novel deep learning model named Spectral Cross-domain neural network (SCDNN) with a new block called Soft-adaptive threshold spectral enhancement (SATSE), to simultaneously reveal the key information embedded in spectral and time domains inside the neural network. More precisely, the domain-cross information is captured by a general Convolutional neural network (CNN) backbone, and different information sources are merged by a self-adaptive mechanism to mine the connection between time and spectral domains. In SATSE, the knowledge from time and spectral domains is extracted via the Fast Fourier Transformation (FFT) with soft trainable thresholds in modified Sigmoid functions. The proposed SCDNN is tested with several classification tasks implemented on the public ECG databases \textit{PTB-XL} and \textit{MIT-BIH}. SCDNN outperforms the state-of-the-art approaches with a low computational cost regarding a variety of metrics in all classification tasks on both databases, by finding appropriate domains from the infinite spectral mapping. The convergence of the trainable thresholds in the spectral domain is also numerically investigated in this paper. The robust performance of SCDNN provides a new perspective to exploit knowledge across deep learning models from time and spectral domains. The repository can be found: https://github.com/DL-WG/SCDNN-TS
RealityTalk: Real-Time Speech-Driven Augmented Presentation for AR Live Storytelling
Aug 12, 2022
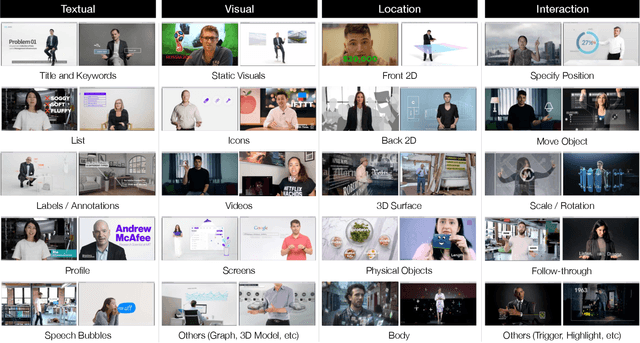
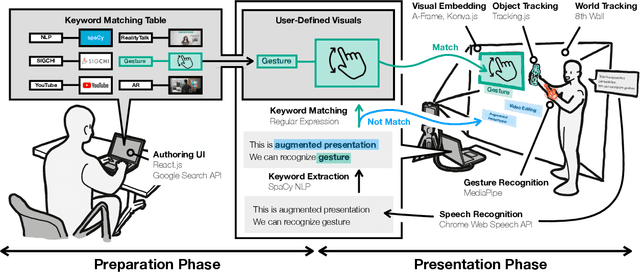

We present RealityTalk, a system that augments real-time live presentations with speech-driven interactive virtual elements. Augmented presentations leverage embedded visuals and animation for engaging and expressive storytelling. However, existing tools for live presentations often lack interactivity and improvisation, while creating such effects in video editing tools require significant time and expertise. RealityTalk enables users to create live augmented presentations with real-time speech-driven interactions. The user can interactively prompt, move, and manipulate graphical elements through real-time speech and supporting modalities. Based on our analysis of 177 existing video-edited augmented presentations, we propose a novel set of interaction techniques and then incorporated them into RealityTalk. We evaluate our tool from a presenter's perspective to demonstrate the effectiveness of our system.
Space-time design for deep joint source channel coding of images Over MIMO channels
Oct 30, 2022
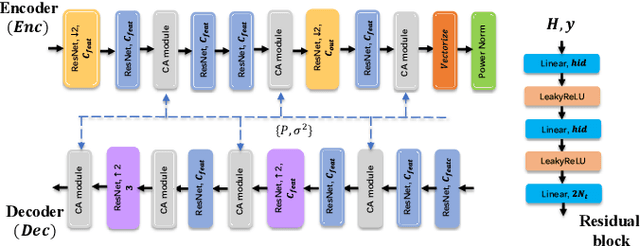
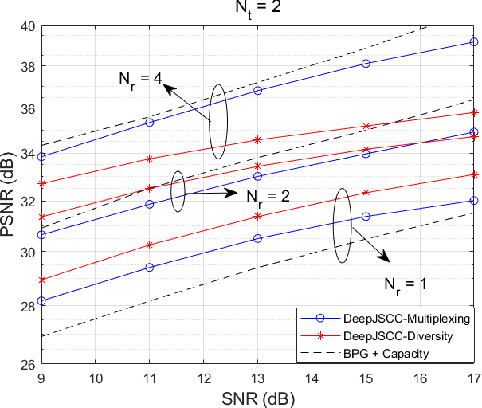
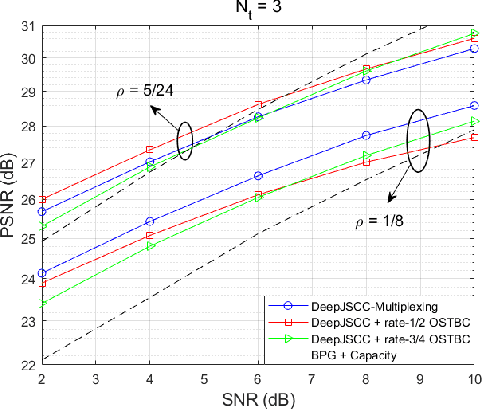
We propose novel deep joint source-channel coding (DeepJSCC) algorithms for wireless image transmission over multi-input multi-output (MIMO) Rayleigh fading channels, when channel state information (CSI) is available only at the receiver. We consider two different transmission schemes; one exploiting spatial diversity and the other one exploiting spatial multiplexing of the MIMO channel. In the diversity scheme, we utilize an orthogonal space-time block code (OSTBC) to achieve full diversity which increases the robustness of transmission against channel variations. The multiplexing scheme, on the other hand, allows the user to directly map the codeword to the antennas, where the additional degree-of-freedom is used to send more information about the source signal. Simulation results show that the diversity scheme outperforms the multiplexing scheme at lower signal-to-noise ratio (SNR) values and smaller number of receive antennas at the AP. When the number of transmit antennas is greater than two, however, the full-diversity scheme becomes less beneficial. We also show that both the diversity and multiplexing scheme can achieve comparable performance with the state-of-the-art BPG algorithm delivered at the MIMO capacity in the considered scenarios.
Stereo X-ray Tomography
Feb 26, 2023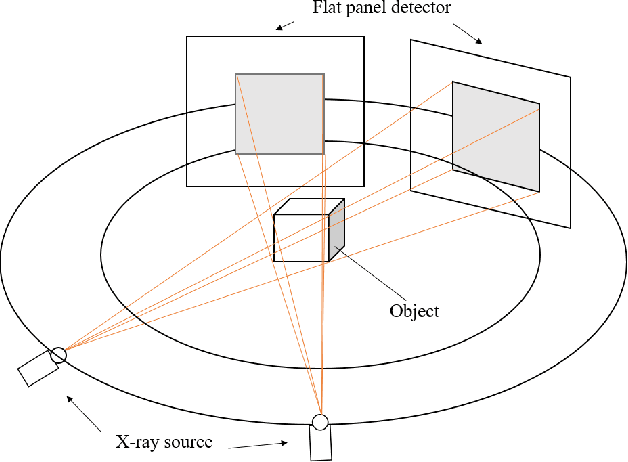

X-ray tomography is a powerful volumetric imaging technique, but detailed three dimensional (3D) imaging requires the acquisition of a large number of individual X-ray images, which is time consuming. For applications where spatial information needs to be collected quickly, for example, when studying dynamic processes, standard X-ray tomography is therefore not applicable. Inspired by stereo vision, in this paper, we develop X-ray imaging methods that work with two X-ray projection images. In this setting, without the use of additional strong prior information, we no longer have enough information to fully recover the 3D tomographic images. However, up to a point, we are nevertheless able to extract spatial locations of point and line features. From stereo vision, it is well known that, for a known imaging geometry, once the same point is identified in two images taken from different directions, then the point's location in 3D space is exactly specified. The challenge is the matching of points between images. As X-ray transmission images are fundamentally different from the surface reflection images used in standard computer vision, we here develop a different feature identification and matching approach. In fact, once point like features are identified, if there are limited points in the image, then they can often be matched exactly. In fact, by utilising a third observation from an appropriate direction, matching becomes unique. Once matched, point locations in 3D space are easily computed using geometric considerations. Linear features, with clear end points, can be located using a similar approach.
Multi-objective Generative Design of Three-Dimensional Composite Materials
Feb 26, 2023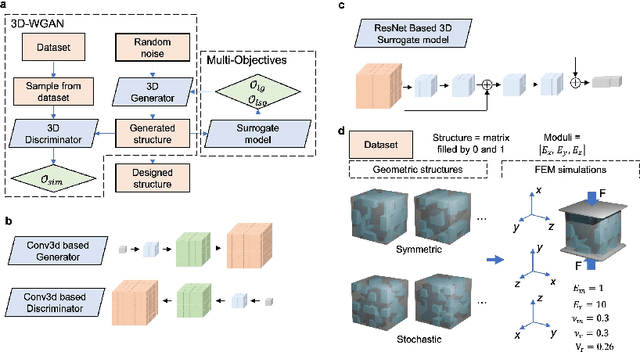
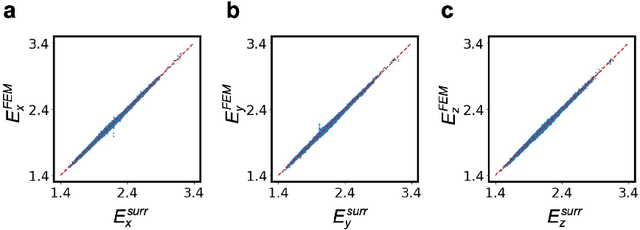
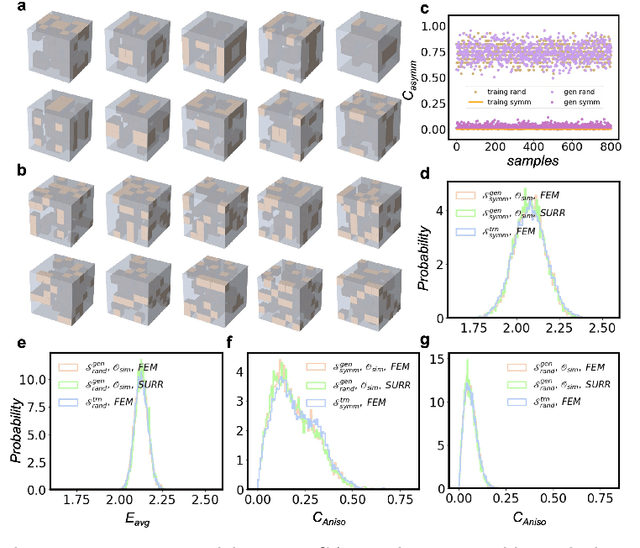
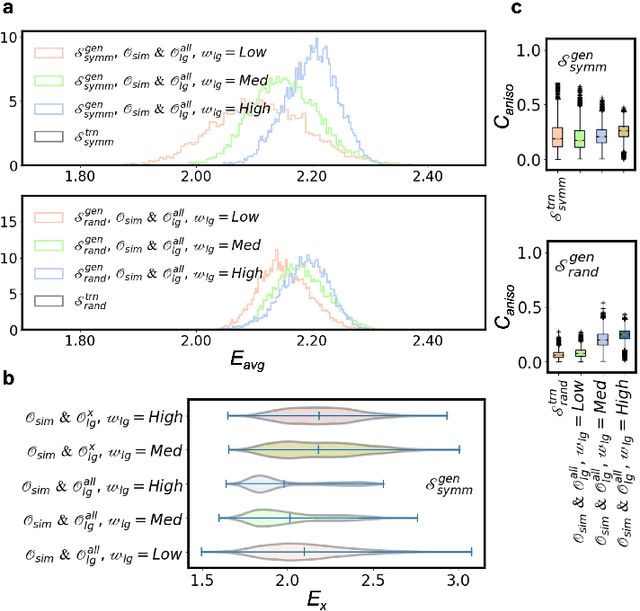
Composite materials with 3D architectures are desirable in a variety of applications for the capability of tailoring their properties to meet multiple functional requirements. By the arrangement of materials' internal components, structure design is of great significance in tuning the properties of the composites. However, most of the composite structures are proposed by empirical designs following existing patterns. Hindered by the complexity of 3D structures, it is hard to extract customized structures with multiple desired properties from large design space. Here we report a multi-objective driven Wasserstein generative adversarial network (MDWGAN) to implement inverse designs of 3D composite structures according to given geometrical, structural and mechanical requirements. Our framework consists a GAN based network which generates 3D composite structures possessing with similar geometrical and structural features to the target dataset. Besides, multiple objectives are introduced to our framework for the control of mechanical property and isotropy of the composites. Real time calculation of the properties in training iterations is achieved by an accurate surrogate model. We constructed a small and concise dataset to illustrate our framework. With multiple objectives combined by their weight, and the 3D-GAN act as a soft constraint, our framework is proved to be capable of tuning the properties of the generated composites in multiple aspects, while keeping the selected features of different kinds of structures. The feasibility on small dataset and potential scalability on objectives of other properties make our work a novel, effective approach to provide fast, experience free composite structure designs for various functional materials.
Zero3D: Semantic-Driven Multi-Category 3D Shape Generation
Feb 13, 2023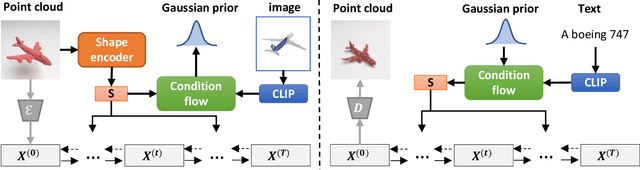
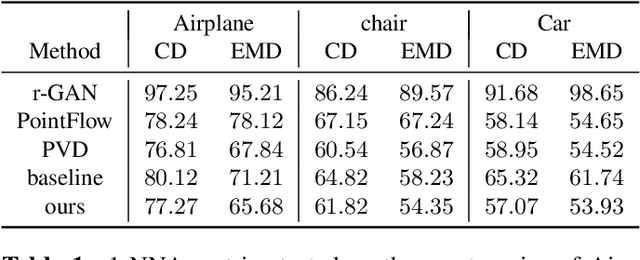
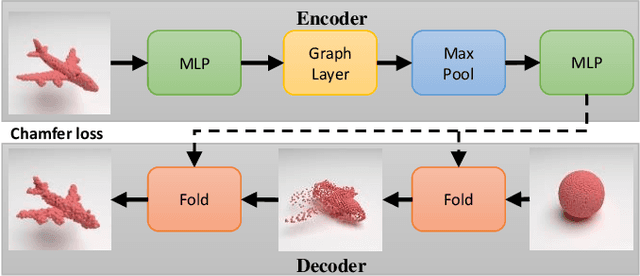
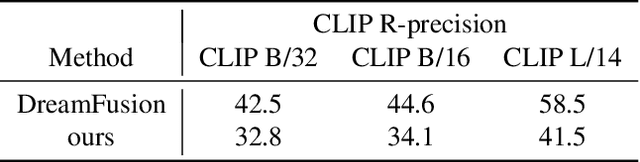
Semantic-driven 3D shape generation aims to generate 3D objects conditioned on text. Previous works face problems with single-category generation, low-frequency 3D details, and requiring a large number of paired datasets for training. To tackle these challenges, we propose a multi-category conditional diffusion model. Specifically, 1) to alleviate the problem of lack of large-scale paired data, we bridge the text, 2D image and 3D shape based on the pre-trained CLIP model, and 2) to obtain the multi-category 3D shape feature, we apply the conditional flow model to generate 3D shape vector conditioned on CLIP embedding. 3) to generate multi-category 3D shape, we employ the hidden-layer diffusion model conditioned on the multi-category shape vector, which greatly reduces the training time and memory consumption.
Content-Adaptive Motion Rate Adaption for Learned Video Compression
Feb 13, 2023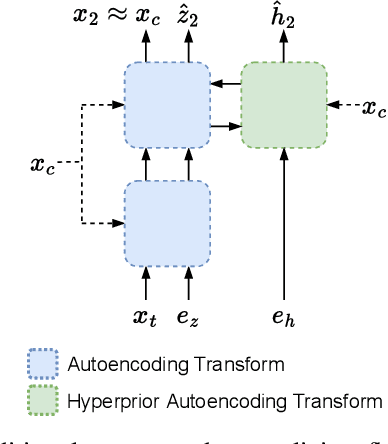
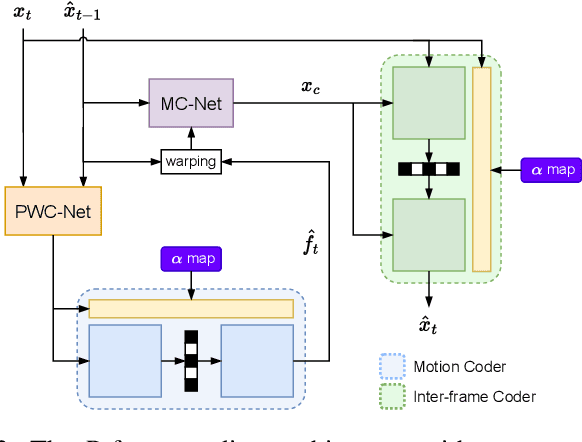
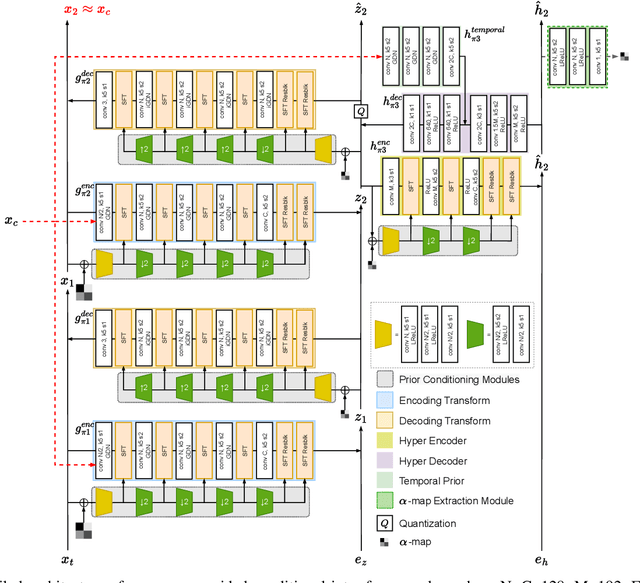
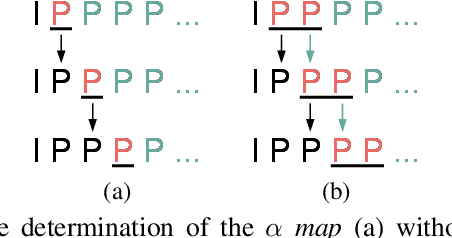
This paper introduces an online motion rate adaptation scheme for learned video compression, with the aim of achieving content-adaptive coding on individual test sequences to mitigate the domain gap between training and test data. It features a patch-level bit allocation map, termed the $\alpha$-map, to trade off between the bit rates for motion and inter-frame coding in a spatially-adaptive manner. We optimize the $\alpha$-map through an online back-propagation scheme at inference time. Moreover, we incorporate a look-ahead mechanism to consider its impact on future frames. Extensive experimental results confirm that the proposed scheme, when integrated into a conditional learned video codec, is able to adapt motion bit rate effectively, showing much improved rate-distortion performance particularly on test sequences with complicated motion characteristics.
Deep Neural Networks for Encrypted Inference with TFHE
Feb 13, 2023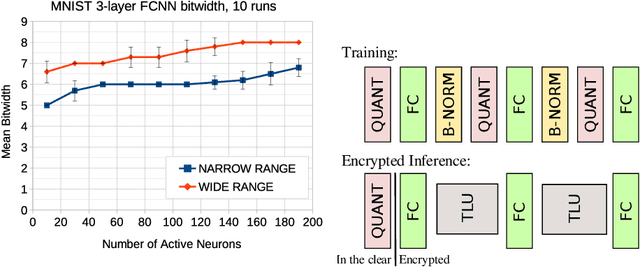
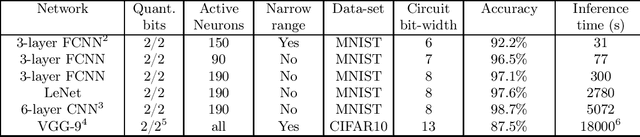
Fully homomorphic encryption (FHE) is an encryption method that allows to perform computation on encrypted data, without decryption. FHE preserves the privacy of the users of online services that handle sensitive data, such as health data, biometrics, credit scores and other personal information. A common way to provide a valuable service on such data is through machine learning and, at this time, Neural Networks are the dominant machine learning model for unstructured data. In this work we show how to construct Deep Neural Networks (DNN) that are compatible with the constraints of TFHE, an FHE scheme that allows arbitrary depth computation circuits. We discuss the constraints and show the architecture of DNNs for two computer vision tasks. We benchmark the architectures using the Concrete stack, an open-source implementation of TFHE.
Near-Optimal Cryptographic Hardness of Agnostically Learning Halfspaces and ReLU Regression under Gaussian Marginals
Feb 13, 2023We study the task of agnostically learning halfspaces under the Gaussian distribution. Specifically, given labeled examples $(\mathbf{x},y)$ from an unknown distribution on $\mathbb{R}^n \times \{ \pm 1\}$, whose marginal distribution on $\mathbf{x}$ is the standard Gaussian and the labels $y$ can be arbitrary, the goal is to output a hypothesis with 0-1 loss $\mathrm{OPT}+\epsilon$, where $\mathrm{OPT}$ is the 0-1 loss of the best-fitting halfspace. We prove a near-optimal computational hardness result for this task, under the widely believed sub-exponential time hardness of the Learning with Errors (LWE) problem. Prior hardness results are either qualitatively suboptimal or apply to restricted families of algorithms. Our techniques extend to yield near-optimal lower bounds for related problems, including ReLU regression.