 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adversarial Detection: Attacking Object Detection in Real Time
Sep 16, 2022
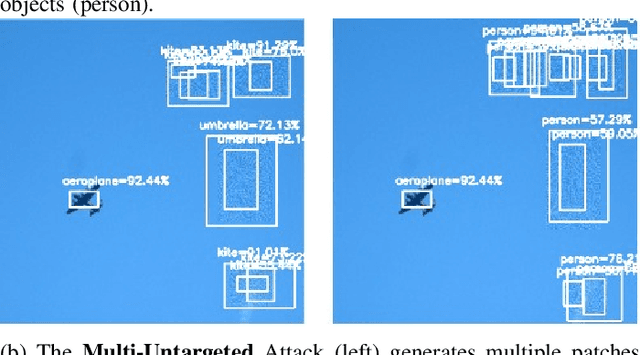

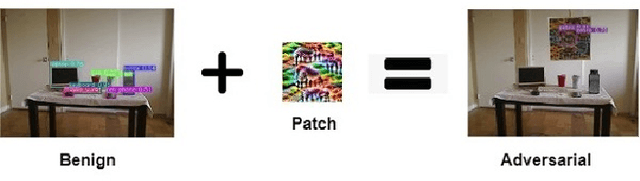
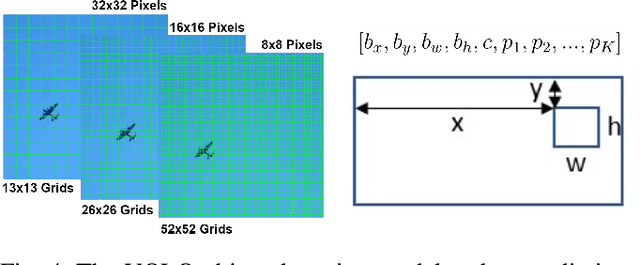
Intelligent robots rely on object detection models to perceive the environment. Following advances in deep learning security it has been revealed that object detection models are vulnerable to adversarial attacks. However, prior research primarily focuses on attacking static images or offline videos. Therefore, it is still unclear if such attacks could jeopardize real-world robotic applications in dynamic environments. This paper bridges this gap by presenting the first real-time online attack against object detection models. We devise three attacks that fabricate bounding boxes for nonexistent objects at desired locations. The attacks achieve a success rate of about 90% within about 20 iterations. The demo video is available at: https://youtu.be/zJZ1aNlXsMU.
Revisiting Weighted Strategy for Non-stationary Parametric Bandits
Mar 05, 2023
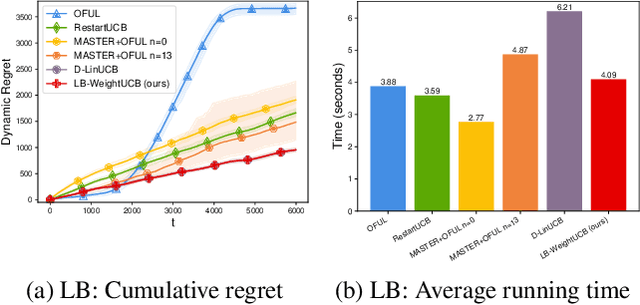
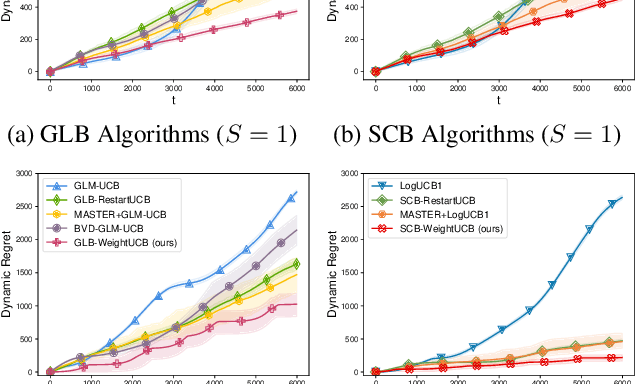
Non-stationary parametric bandits have attracted much attention recently. There are three principled ways to deal with non-stationarity, including sliding-window, weighted, and restart strategies. As many non-stationary environments exhibit gradual drifting patterns, the weighted strategy is commonly adopted in real-world applications. However, previous theoretical studies show that its analysis is more involved and the algorithms are either computationally less efficient or statistically suboptimal. This paper revisits the weighted strategy for non-stationary parametric bandits. In linear bandits (LB), we discover that this undesirable feature is due to an inadequate regret analysis, which results in an overly complex algorithm design. We propose a refined analysis framework, which simplifies the derivation and importantly produces a simpler weight-based algorithm that is as efficient as window/restart-based algorithms while retaining the same regret as previous studies. Furthermore, our new framework can be used to improve regret bounds of other parametric bandits, including Generalized Linear Bandits (GLB) and Self-Concordant Bandits (SCB). For example, we develop a simple weighted GLB algorithm with an $\widetilde{O}(k_\mu^{\frac{5}{4}} c_\mu^{-\frac{3}{4}} d^{\frac{3}{4}} P_T^{\frac{1}{4}}T^{\frac{3}{4}})$ regret, improving the $\widetilde{O}(k_\mu^{2} c_\mu^{-1}d^{\frac{9}{10}} P_T^{\frac{1}{5}}T^{\frac{4}{5}})$ bound in prior work, where $k_\mu$ and $c_\mu$ characterize the reward model's nonlinearity, $P_T$ measures the non-stationarity, $d$ and $T$ denote the dimension and time horizon.
Frequency-domain Blind Quality Assessment of Blurred and Blocking-artefact Images using Gaussian Process Regression model
Mar 05, 2023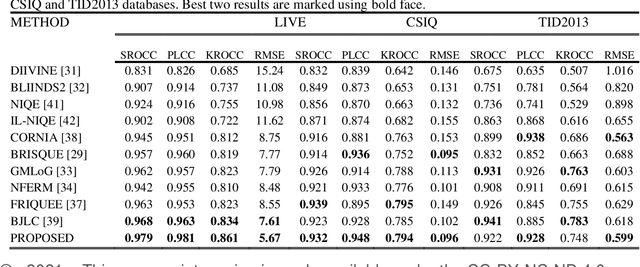
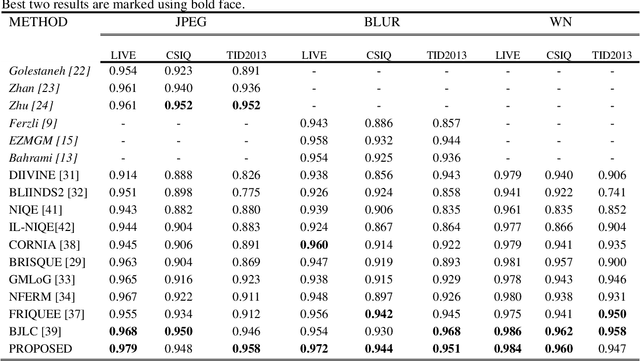

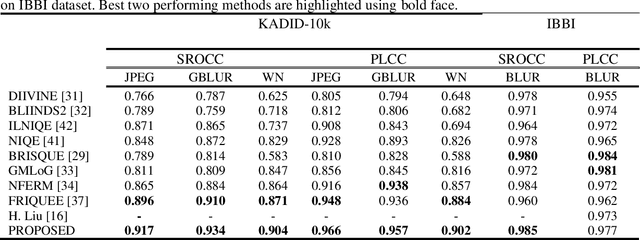
Most of the standard image and video codecs are block-based and depending upon the compression ratio the compressed images/videos suffer from different distortions. At low ratios, blurriness is observed and as compression increases blocking artifacts occur. Generally, in order to reduce blockiness, images are low-pass filtered which leads to more blurriness. Also, in bokeh mode images they are commonly seen: blurriness as a result of intentional blurred background while blocking artifact and global blurriness arising due to compression. Therefore, such visual media suffer from both blockiness and blurriness distortions. Along with this, noise is also commonly encountered distortion. Most of the existing works on quality assessment quantify these distortions individually. This paper proposes a methodology to blindly measure overall quality of an image suffering from these distortions, individually as well as jointly. This is achieved by considering the sum of absolute values of low and high-frequency Discrete Frequency Transform (DFT) coefficients defined as sum magnitudes. The number of blocks lying in specific ranges of sum magnitudes including zero-valued AC coefficients and mean of 100 maximum and 100 minimum values of these sum magnitudes are used as feature vectors. These features are then fed to the Machine Learning (ML) based Gaussian Process Regression (GPR) model, which quantifies the image quality. The simulation results show that the proposed method can estimate the quality of images distorted with the blockiness, blurriness, noise and their combinations. It is relatively fast compared to many state-of-art methods, and therefore is suitable for real-time quality monitoring applications.
Understanding Bugs in Multi-Language Deep Learning Frameworks
Mar 05, 2023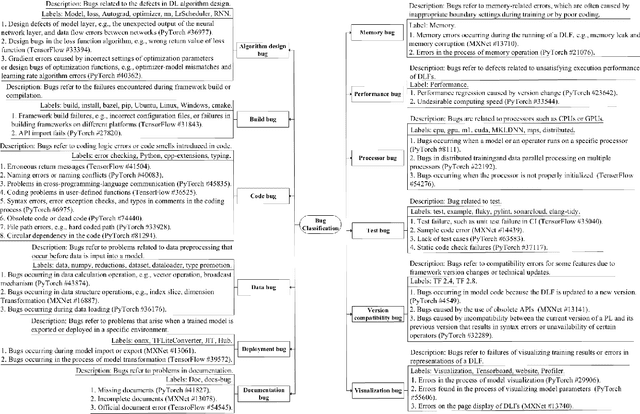
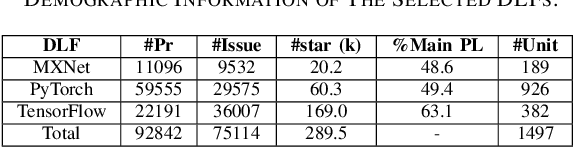
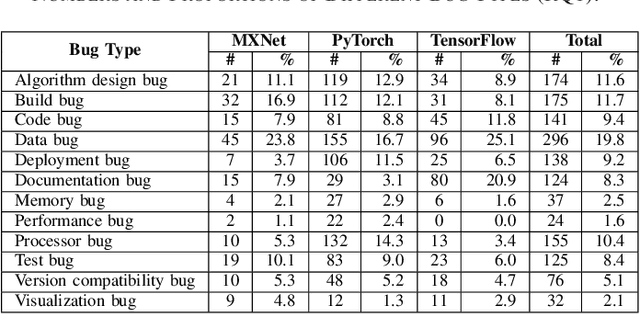
Deep learning frameworks (DLFs) have been playing an increasingly important role in this intelligence age since they act as a basic infrastructure for an increasingly wide range of AIbased applications. Meanwhile, as multi-programming-language (MPL) software systems, DLFs are inevitably suffering from bugs caused by the use of multiple programming languages (PLs). Hence, it is of paramount significance to understand the bugs (especially the bugs involving multiple PLs, i.e., MPL bugs) of DLFs, which can provide a foundation for preventing, detecting, and resolving bugs in the development of DLFs. To this end, we manually analyzed 1497 bugs in three MPL DLFs, namely MXNet, PyTorch, and TensorFlow. First, we classified bugs in these DLFs into 12 types (e.g., algorithm design bugs and memory bugs) according to their bug labels and characteristics. Second, we further explored the impacts of different bug types on the development of DLFs, and found that deployment bugs and memory bugs negatively impact the development of DLFs in different aspects the most. Third, we found that 28.6%, 31.4%, and 16.0% of bugs in MXNet, PyTorch, and TensorFlow are MPL bugs, respectively; the PL combination of Python and C/C++ is most used in fixing more than 92% MPL bugs in all DLFs. Finally, the code change complexity of MPL bug fixes is significantly greater than that of single-programming-language (SPL) bug fixes in all the three DLFs, while in PyTorch MPL bug fixes have longer open time and greater communication complexity than SPL bug fixes. These results provide insights for bug management in DLFs.
Task-oriented Explainable Semantic Communications
Feb 27, 2023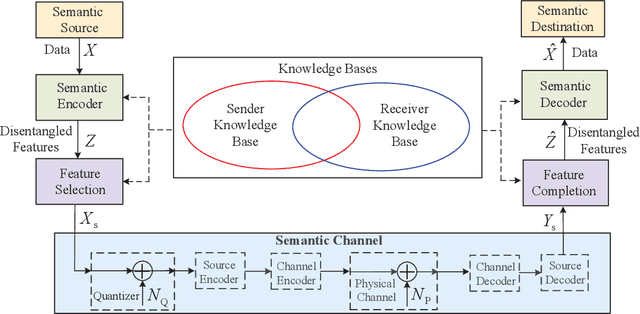
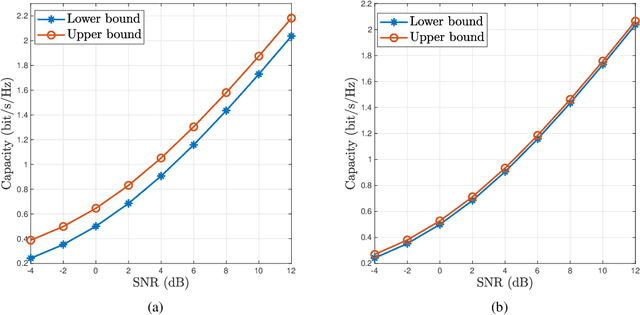
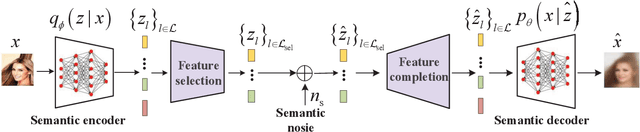
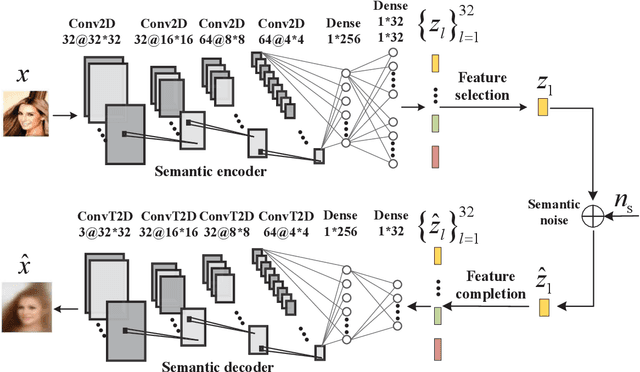
Semantic communications utilize the transceiver computing resources to alleviate scarce transmission resources, such as bandwidth and energy. Although the conventional deep learning (DL) based designs may achieve certain transmission efficiency, the uninterpretability issue of extracted features is the major challenge in the development of semantic communications. In this paper, we propose an explainable and robust semantic communication framework by incorporating the well-established bit-level communication system, which not only extracts and disentangles features into independent and semantically interpretable features, but also only selects task-relevant features for transmission, instead of all extracted features. Based on this framework, we derive the optimal input for rate-distortion-perception theory, and derive both lower and upper bounds on the semantic channel capacity. Furthermore, based on the $\beta $-variational autoencoder ($\beta $-VAE), we propose a practical explainable semantic communication system design, which simultaneously achieves semantic features selection and is robust against semantic channel noise. We further design a real-time wireless mobile semantic communication proof-of-concept prototype. Our simulations and experiments demonstrate that our proposed explainable semantic communications system can significantly improve transmission efficiency, and also verify the effectiveness of our proposed robust semantic transmission scheme.
Knowledge-enhanced Pre-training for Auto-diagnosis of Chest Radiology Images
Feb 27, 2023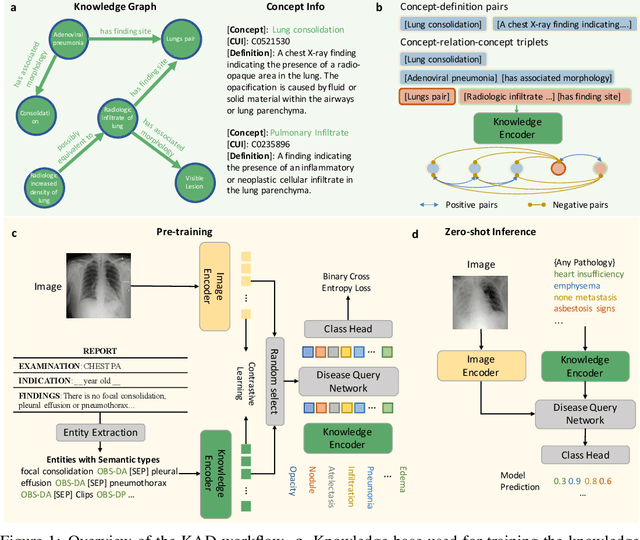
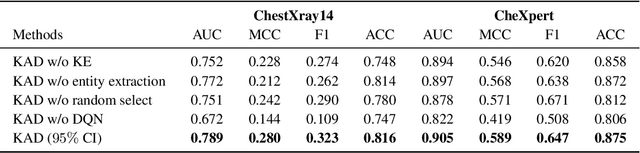
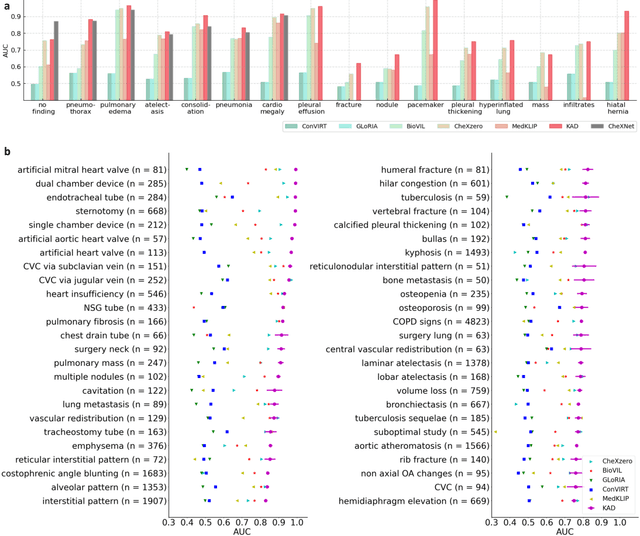
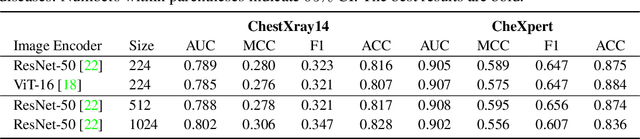
Despite of the success of multi-modal foundation models pre-trained on large-scale data in natural language understanding and vision recognition, its counterpart in medical and clinical domains remains preliminary, due to the fine-grained recognition nature of the medical tasks with high demands on domain knowledge. Here, we propose a knowledge-enhanced vision-language pre-training approach for auto-diagnosis on chest X-ray images. The algorithm, named Knowledge-enhanced Auto Diagnosis~(KAD), first trains a knowledge encoder based on an existing medical knowledge graph, i.e., learning neural embeddings of the definitions and relationships between medical concepts and then leverages the pre-trained knowledge encoder to guide the visual representation learning with paired chest X-rays and radiology reports. We experimentally validate KAD's effectiveness on three external X-ray datasets. The zero-shot performance of KAD is not only comparable to that of the fully-supervised models but also, for the first time, superior to the average of three expert radiologists for three (out of five) pathologies with statistical significance. When the few-shot annotation is available, KAD also surpasses all existing approaches in finetuning settings, demonstrating the potential for application in different clinical scenarios.
Acquisition Conditioned Oracle for Nongreedy Active Feature Acquisition
Feb 27, 2023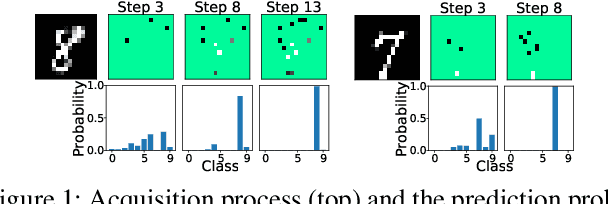
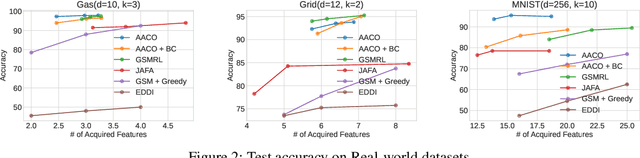
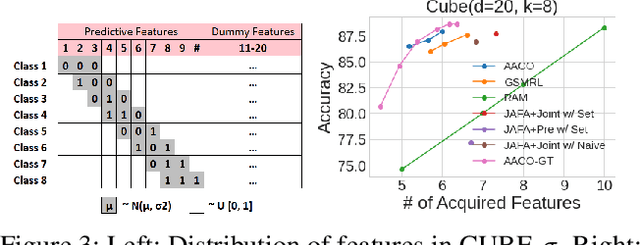
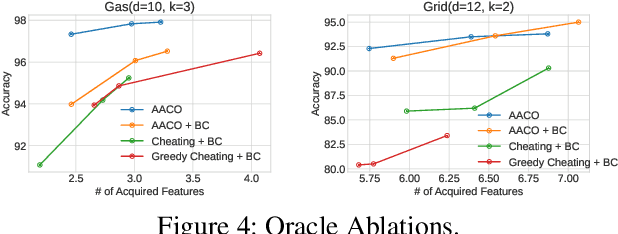
We develop novel methodology for active feature acquisition (AFA), the study of how to sequentially acquire a dynamic (on a per instance basis) subset of features that minimizes acquisition costs whilst still yielding accurate predictions. The AFA framework can be useful in a myriad of domains, including health care applications where the cost of acquiring additional features for a patient (in terms of time, money, risk, etc.) can be weighed against the expected improvement to diagnostic performance. Previous approaches for AFA have employed either: deep learning RL techniques, which have difficulty training policies in the AFA MDP due to sparse rewards and a complicated action space; deep learning surrogate generative models, which require modeling complicated multidimensional conditional distributions; or greedy policies, which fail to account for how joint feature acquisitions can be informative together for better predictions. In this work we show that we can bypass many of these challenges with a novel, nonparametric oracle based approach, which we coin the acquisition conditioned oracle (ACO). Extensive experiments show the superiority of the ACO to state-of-the-art AFA methods when acquiring features for both predictions and general decision-making.
Fast Trajectory End-Point Prediction with Event Cameras for Reactive Robot Control
Feb 27, 2023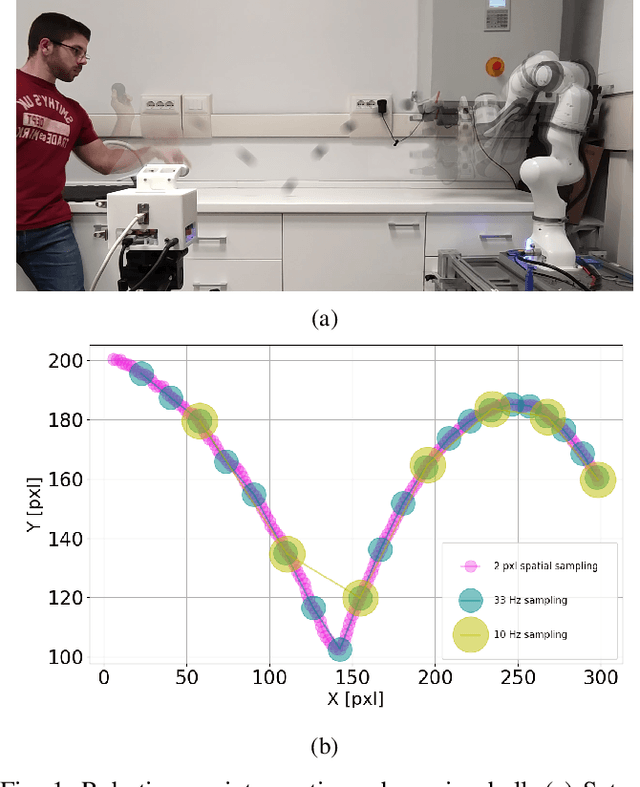
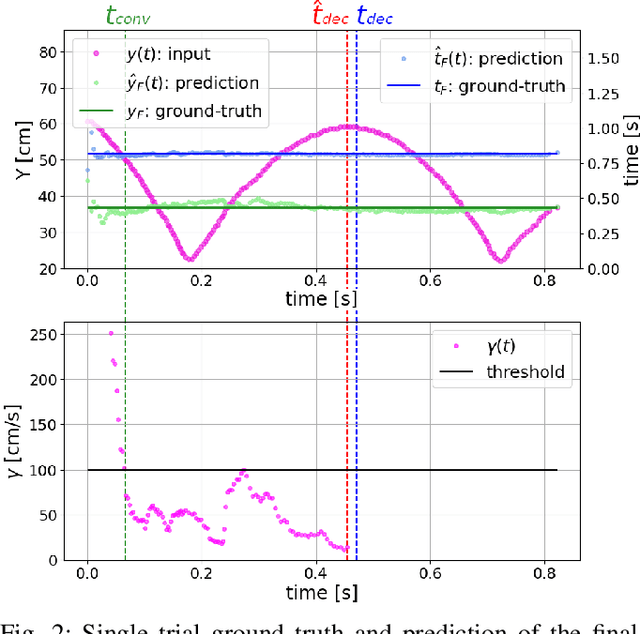
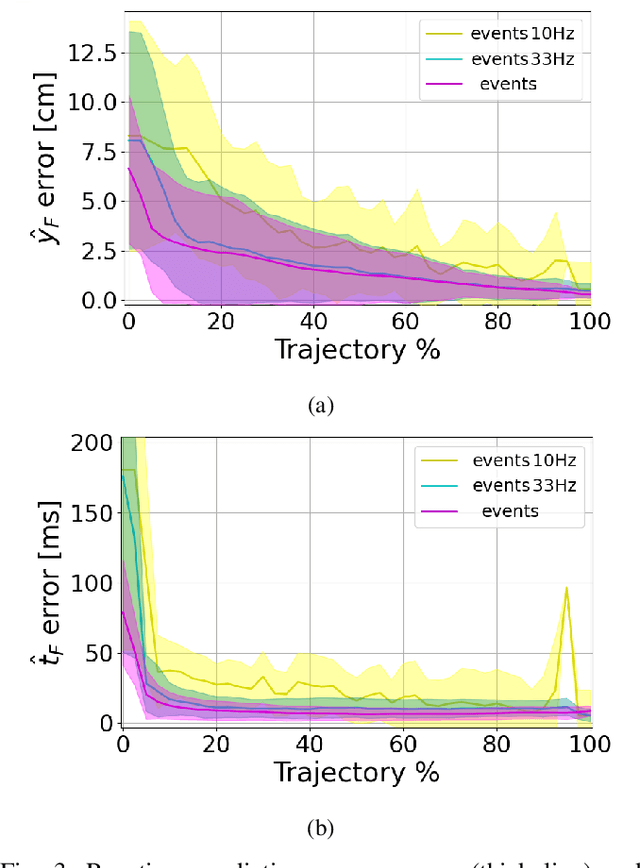
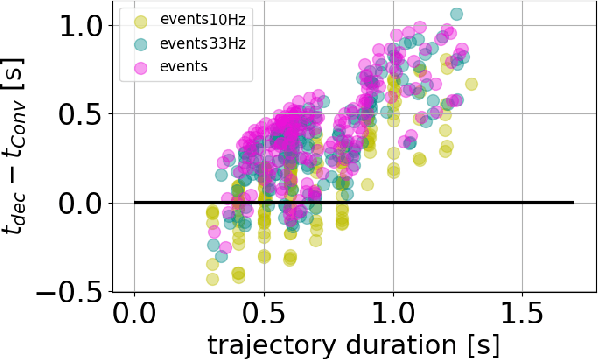
Prediction skills can be crucial for the success of tasks where robots have limited time to act or joints actuation power. In such a scenario, a vision system with a fixed, possibly too low, sampling rate could lead to the loss of informative points, slowing down prediction convergence and reducing the accuracy. In this paper, we propose to exploit the low latency, motion-driven sampling, and data compression properties of event cameras to overcome these issues. As a use-case, we use a Panda robotic arm to intercept a ball bouncing on a table. To predict the interception point, we adopt a Stateful LSTM network, a specific LSTM variant without fixed input length, which perfectly suits the event-driven paradigm and the problem at hand, where the length of the trajectory is not defined. We train the network in simulation to speed up the dataset acquisition and then fine-tune the models on real trajectories. Experimental results demonstrate how using a dense spatial sampling (i.e. event cameras) significantly increases the number of intercepted trajectories as compared to a fixed temporal sampling (i.e. frame-based cameras).
Hulk: Graph Neural Networks for Optimizing Regionally Distributed Computing Systems
Feb 27, 2023
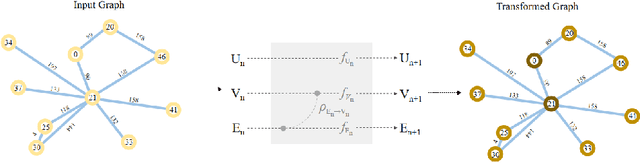

Large deep learning models have shown great potential for delivering exceptional results in various applications. However, the training process can be incredibly challenging due to the models' vast parameter sizes, often consisting of hundreds of billions of parameters. Common distributed training methods, such as data parallelism, tensor parallelism, and pipeline parallelism, demand significant data communication throughout the process, leading to prolonged wait times for some machines in physically distant distributed systems. To address this issue, we propose a novel solution called Hulk, which utilizes a modified graph neural network to optimize distributed computing systems. Hulk not only optimizes data communication efficiency between different countries or even different regions within the same city, but also provides optimal distributed deployment of models in parallel. For example, it can place certain layers on a machine in a specific region or pass specific parameters of a model to a machine in a particular location. By using Hulk in experiments, we were able to improve the time efficiency of training large deep learning models on distributed systems by more than 20\%. Our open source collection of unlabeled data:https://github.com/DLYuanGod/Hulk.
Imaginary Voice: Face-styled Diffusion Model for Text-to-Speech
Feb 27, 2023

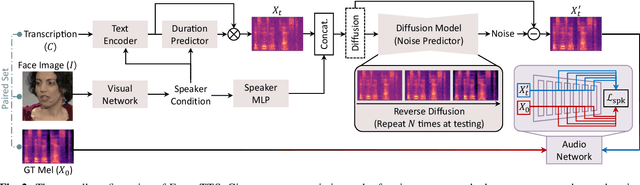
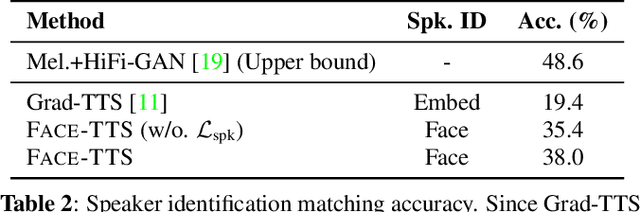
The goal of this work is zero-shot text-to-speech synthesis, with speaking styles and voices learnt from facial characteristics. Inspired by the natural fact that people can imagine the voice of someone when they look at his or her face, we introduce a face-styled diffusion text-to-speech (TTS) model within a unified framework learnt from visible attributes, called Face-TTS. This is the first time that face images are used as a condition to train a TTS model. We jointly train cross-model biometrics and TTS models to preserve speaker identity between face images and generated speech segments. We also propose a speaker feature binding loss to enforce the similarity of the generated and the ground truth speech segments in speaker embedding space. Since the biometric information is extracted directly from the face image, our method does not require extra fine-tuning steps to generate speech from unseen and unheard speakers. We train and evaluate the model on the LRS3 dataset, an in-the-wild audio-visual corpus containing background noise and diverse speaking styles. The project page is https://facetts.github.io.