 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Dynamic Model for Bus Arrival Time Estimation based on Spatial Patterns using Machine Learning
Oct 03, 2022
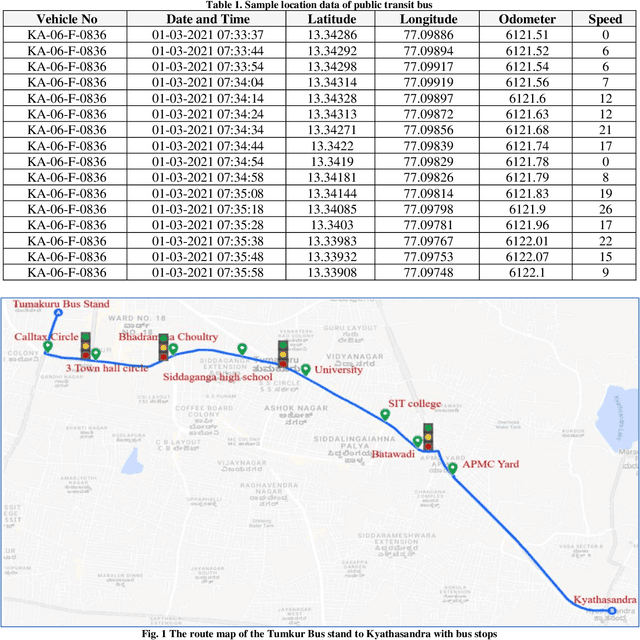
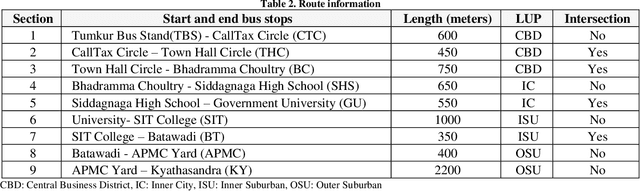
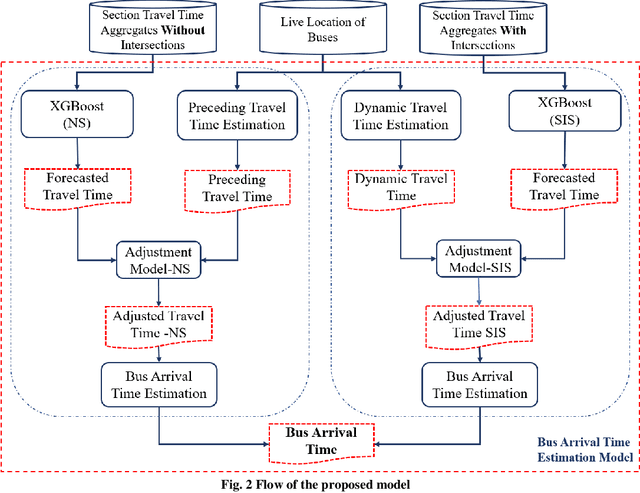

The notion of smart cities is being adapted globally to provide a better quality of living. A smart city's smart mobility component focuses on providing smooth and safe commuting for its residents and promotes eco-friendly and sustainable alternatives such as public transit (bus). Among several smart applications, a system that provides up-to-the-minute information like bus arrival, travel duration, schedule, etc., improves the reliability of public transit services. Still, this application needs live information on traffic flow, accidents, events, and the location of the buses. Most cities lack the infrastructure to provide these data. In this context, a bus arrival prediction model is proposed for forecasting the arrival time using limited data sets. The location data of public transit buses and spatial characteristics are used for the study. One of the routes of Tumakuru city service, Tumakuru, India, is selected and divided into two spatial patterns: sections with intersections and sections without intersections. The machine learning model XGBoost is modeled for both spatial patterns individually. A model to dynamically predict bus arrival time is developed using the preceding trip information and the machine learning model to estimate the arrival time at a downstream bus stop. The performance of models is compared based on the R-squared values of the predictions made, and the proposed model established superior results. It is suggested to predict bus arrival in the study area. The proposed model can also be extended to other similar cities with limited traffic-related infrastructure.
AMFPMC -- An improved method of detecting multiple types of drug-drug interactions using only known drug-drug interactions
Feb 07, 2023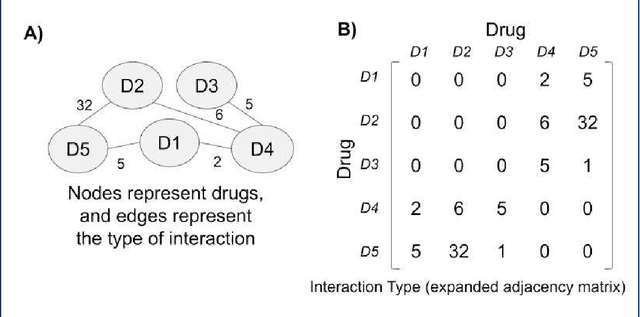

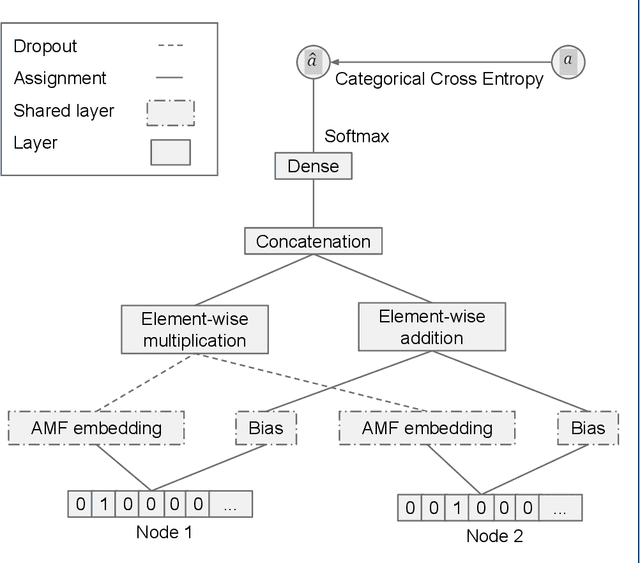
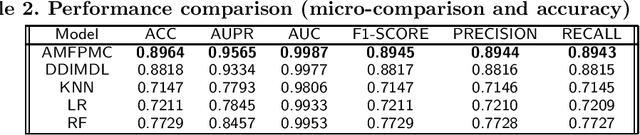
Adverse drug interactions are largely preventable causes of medical accidents, which frequently result in physician and emergency room encounters. The detection of drug interactions in a lab, prior to a drug's use in medical practice, is essential, however it is costly and time-consuming. Machine learning techniques can provide an efficient and accurate means of predicting possible drug-drug interactions and combat the growing problem of adverse drug interactions. Most existing models for predicting interactions rely on the chemical properties of drugs. While such models can be accurate, the required properties are not always available.
A Self-supervised Riemannian GNN with Time Varying Curvature for Temporal Graph Learning
Aug 30, 2022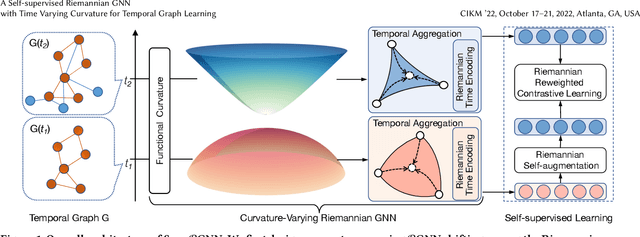

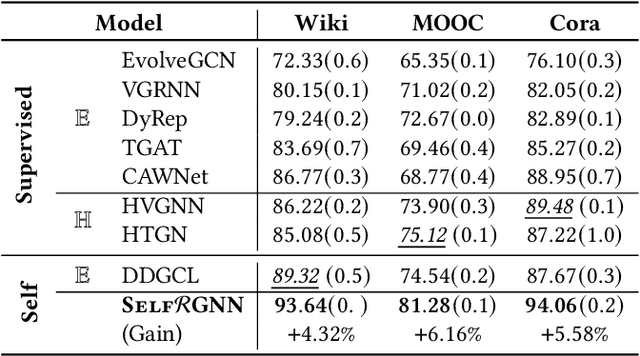
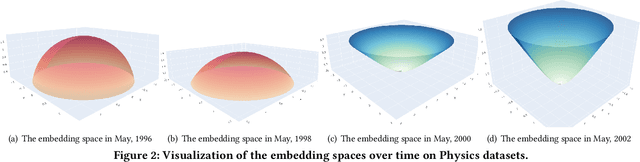
Representation learning on temporal graphs has drawn considerable research attention owing to its fundamental importance in a wide spectrum of real-world applications. Though a number of studies succeed in obtaining time-dependent representations, it still faces significant challenges. On the one hand, most of the existing methods restrict the embedding space with a certain curvature. However, the underlying geometry in fact shifts among the positive curvature hyperspherical, zero curvature Euclidean and negative curvature hyperbolic spaces in the evolvement over time. On the other hand, these methods usually require abundant labels to learn temporal representations, and thereby notably limit their wide use in the unlabeled graphs of the real applications. To bridge this gap, we make the first attempt to study the problem of self-supervised temporal graph representation learning in the general Riemannian space, supporting the time-varying curvature to shift among hyperspherical, Euclidean and hyperbolic spaces. In this paper, we present a novel self-supervised Riemannian graph neural network (SelfRGNN). Specifically, we design a curvature-varying Riemannian GNN with a theoretically grounded time encoding, and formulate a functional curvature over time to model the evolvement shifting among the positive, zero and negative curvature spaces. To enable the self-supervised learning, we propose a novel reweighting self-contrastive approach, exploring the Riemannian space itself without augmentation, and propose an edge-based self-supervised curvature learning with the Ricci curvature. Extensive experiments show the superiority of SelfRGNN, and moreover, the case study shows the time-varying curvature of temporal graph in reality.
Enabling surrogate-assisted evolutionary reinforcement learning via policy embedding
Jan 31, 2023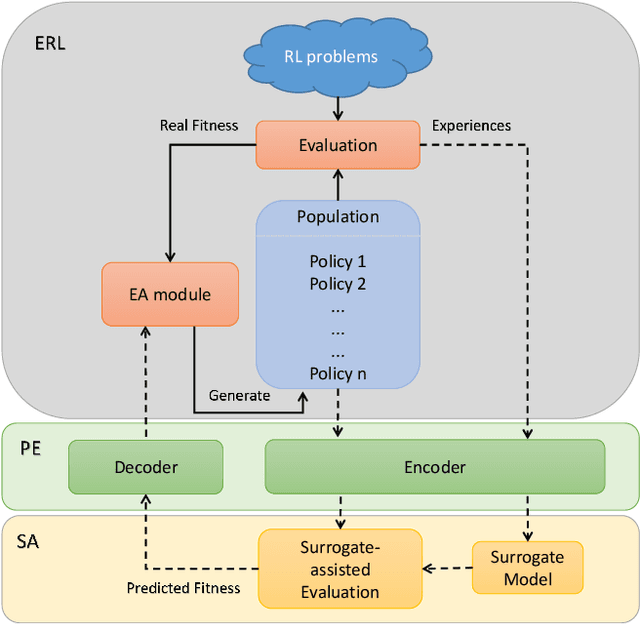

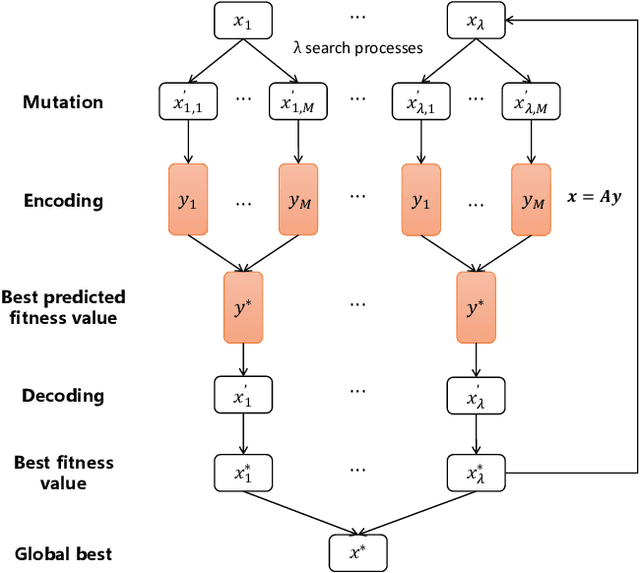

Evolutionary Reinforcement Learning (ERL) that applying Evolutionary Algorithms (EAs) to optimize the weight parameters of Deep Neural Network (DNN) based policies has been widely regarded as an alternative to traditional reinforcement learning methods. However, the evaluation of the iteratively generated population usually requires a large amount of computational time and can be prohibitively expensive, which may potentially restrict the applicability of ERL. Surrogate is often used to reduce the computational burden of evaluation in EAs. Unfortunately, in ERL, each individual of policy usually represents millions of weights parameters of DNN. This high-dimensional representation of policy has introduced a great challenge to the application of surrogates into ERL to speed up training. This paper proposes a PE-SAERL Framework to at the first time enable surrogate-assisted evolutionary reinforcement learning via policy embedding (PE). Empirical results on 5 Atari games show that the proposed method can perform more efficiently than the four state-of-the-art algorithms. The training process is accelerated up to 7x on tested games, comparing to its counterpart without the surrogate and PE.
ITstyler: Image-optimized Text-based Style Transfer
Jan 26, 2023
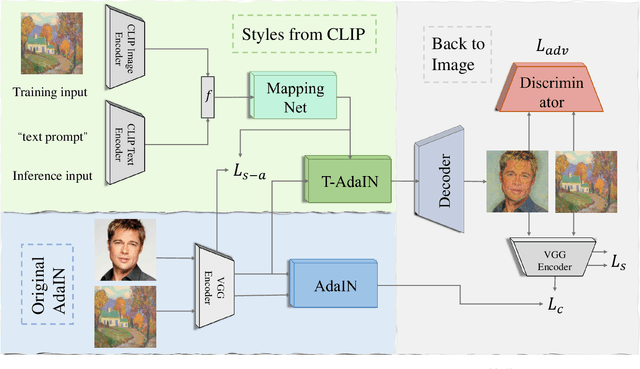
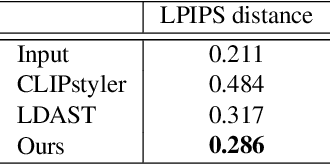

Text-based style transfer is a newly-emerging research topic that uses text information instead of style image to guide the transfer process, significantly extending the application scenario of style transfer. However, previous methods require extra time for optimization or text-image paired data, leading to limited effectiveness. In this work, we achieve a data-efficient text-based style transfer method that does not require optimization at the inference stage. Specifically, we convert text input to the style space of the pre-trained VGG network to realize a more effective style swap. We also leverage CLIP's multi-modal embedding space to learn the text-to-style mapping with the image dataset only. Our method can transfer arbitrary new styles of text input in real-time and synthesize high-quality artistic images.
BOP Challenge 2022 on Detection, Segmentation and Pose Estimation of Specific Rigid Objects
Feb 25, 2023
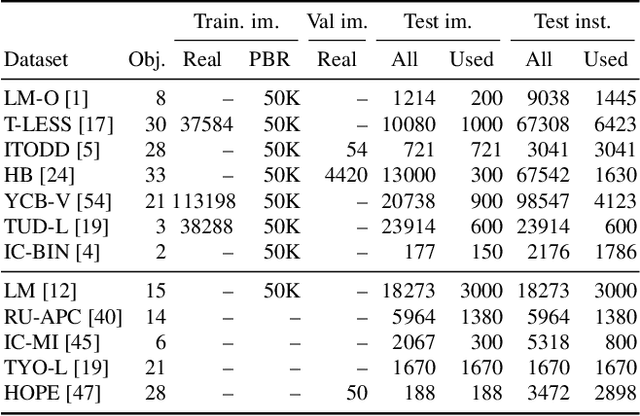

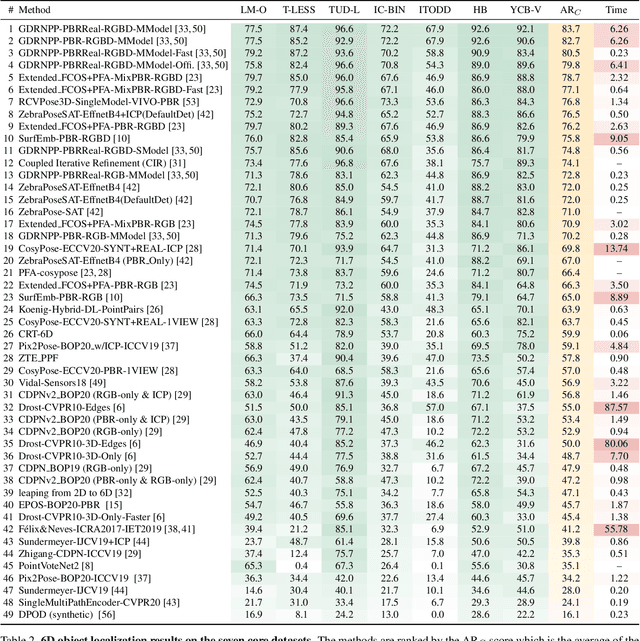
We present the evaluation methodology, datasets and results of the BOP Challenge 2022, the fourth in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB/RGB-D image. In 2022, we witnessed another significant improvement in the pose estimation accuracy -- the state of the art, which was 56.9 AR$_C$ in 2019 (Vidal et al.) and 69.8 AR$_C$ in 2020 (CosyPose), moved to new heights of 83.7 AR$_C$ (GDRNPP). Out of 49 pose estimation methods evaluated since 2019, the top 18 are from 2022. Methods based on point pair features, which were introduced in 2010 and achieved competitive results even in 2020, are now clearly outperformed by deep learning methods. The synthetic-to-real domain gap was again significantly reduced, with 82.7 AR$_C$ achieved by GDRNPP trained only on synthetic images from BlenderProc. The fastest variant of GDRNPP reached 80.5 AR$_C$ with an average time per image of 0.23s. Since most of the recent methods for 6D object pose estimation begin by detecting/segmenting objects, we also started evaluating 2D object detection and segmentation performance based on the COCO metrics. Compared to the Mask R-CNN results from CosyPose in 2020, detection improved from 60.3 to 77.3 AP$_C$ and segmentation from 40.5 to 58.7 AP$_C$. The online evaluation system stays open and is available at: \href{http://bop.felk.cvut.cz/}{bop.felk.cvut.cz}.
Chaotic Variational Auto encoder-based Adversarial Machine Learning
Feb 25, 2023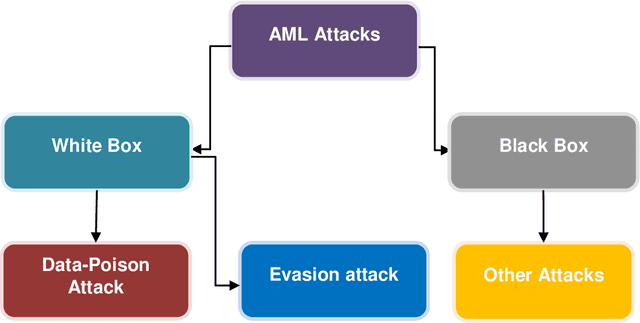
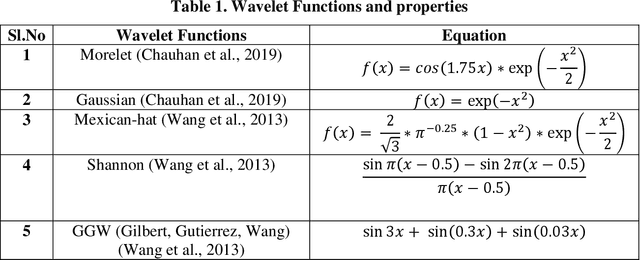
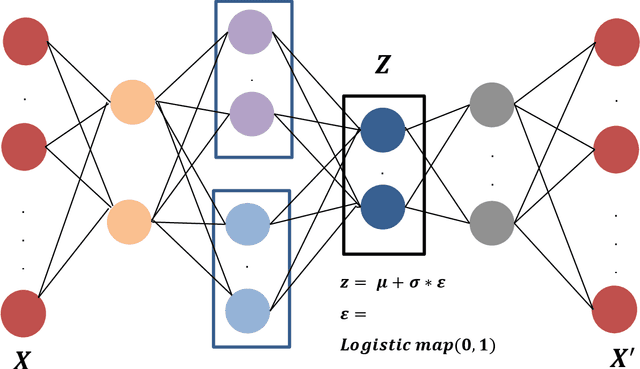
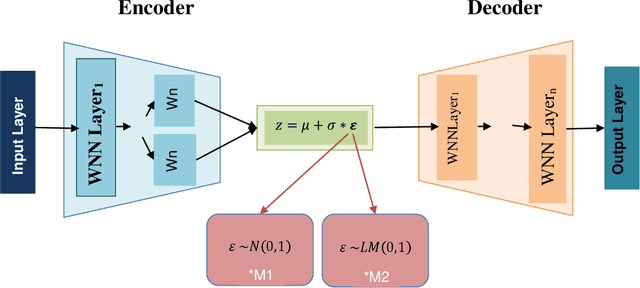
Machine Learning (ML) has become the new contrivance in almost every field. This makes them a target of fraudsters by various adversary attacks, thereby hindering the performance of ML models. Evasion and Data-Poison-based attacks are well acclaimed, especially in finance, healthcare, etc. This motivated us to propose a novel computationally less expensive attack mechanism based on the adversarial sample generation by Variational Auto Encoder (VAE). It is well known that Wavelet Neural Network (WNN) is considered computationally efficient in solving image and audio processing, speech recognition, and time-series forecasting. This paper proposed VAE-Deep-Wavelet Neural Network (VAE-Deep-WNN), where Encoder and Decoder employ WNN networks. Further, we proposed chaotic variants of both VAE with Multi-layer perceptron (MLP) and Deep-WNN and named them C-VAE-MLP and C-VAE-Deep-WNN, respectively. Here, we employed a Logistic map to generate random noise in the latent space. In this paper, we performed VAE-based adversary sample generation and applied it to various problems related to finance and cybersecurity domain-related problems such as loan default, credit card fraud, and churn modelling, etc., We performed both Evasion and Data-Poison attacks on Logistic Regression (LR) and Decision Tree (DT) models. The results indicated that VAE-Deep-WNN outperformed the rest in the majority of the datasets and models. However, its chaotic variant C-VAE-Deep-WNN performed almost similarly to VAE-Deep-WNN in the majority of the datasets.
Myocardial Infarction Detection from ECG: A Gramian Angular Field-based 2D-CNN Approach
Feb 25, 2023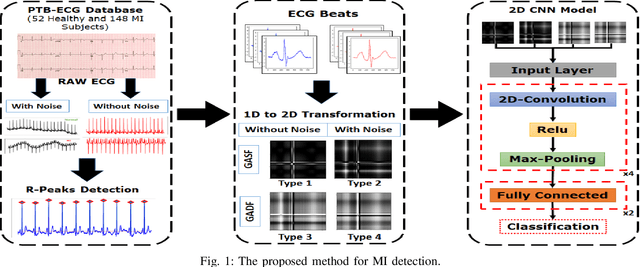
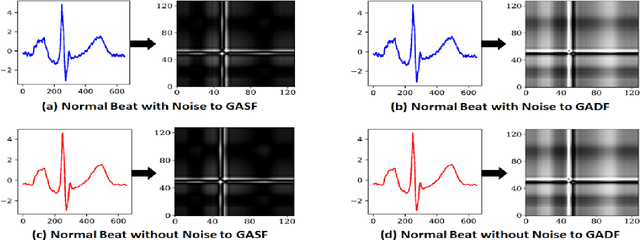
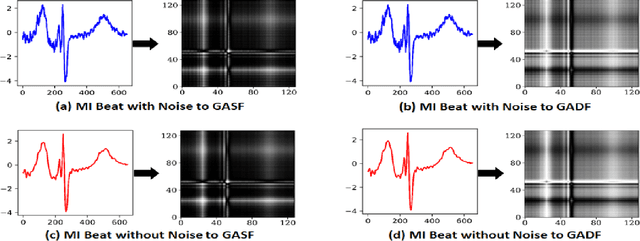
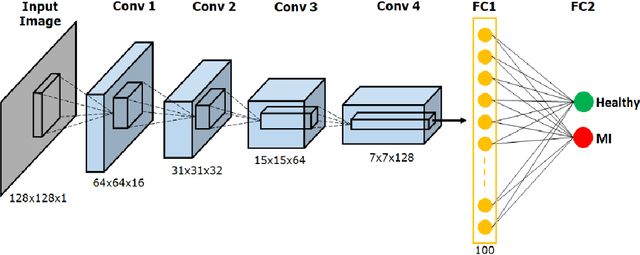
This paper presents a novel method for myocardial infarction (MI) detection using lead II of electrocardiogram (ECG). Under our proposed method, we first clean the noisy ECG signals using db4 wavelet, followed by an R-peak detection algorithm to segment the ECG signals into beats. We then translate the ECG timeseries dataset to an equivalent dataset of gray-scale images using Gramian Angular Summation Field (GASF) and Gramian Angular Difference Field (GADF) operations. Subsequently, the gray-scale images are fed into a custom two-dimensional convolutional neural network (2D-CNN) which efficiently differentiates the ECG beats of the healthy subjects from the ECG beats of the subjects with MI. We train and test the performance of our proposed method on a public dataset, namely, Physikalisch Technische Bundesanstalt (PTB) ECG dataset from Physionet. Our proposed approach achieves an average classification accuracy of 99.68\%, 99.80\%, 99.82\%, and 99.84\% under GASF dataset with noise and baseline wander, GADF dataset with noise and baseline wander, GASF dataset with noise and baseline wander removed, and GADF dataset with noise and baseline wander removed, respectively. Our proposed method is able to cope with additive noise and baseline wander, and does not require handcrafted features by a domain expert. Most importantly, this work opens the floor for innovation in wearable devices (e.g., smart watches, wrist bands etc.) to do accurate, real-time and early MI detection using a single-lead (lead II) ECG.
Over-the-Air Computation with Multiple Receivers: A Space-Time Approach
Aug 24, 2022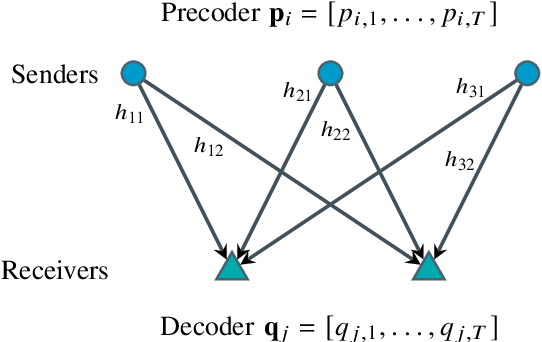
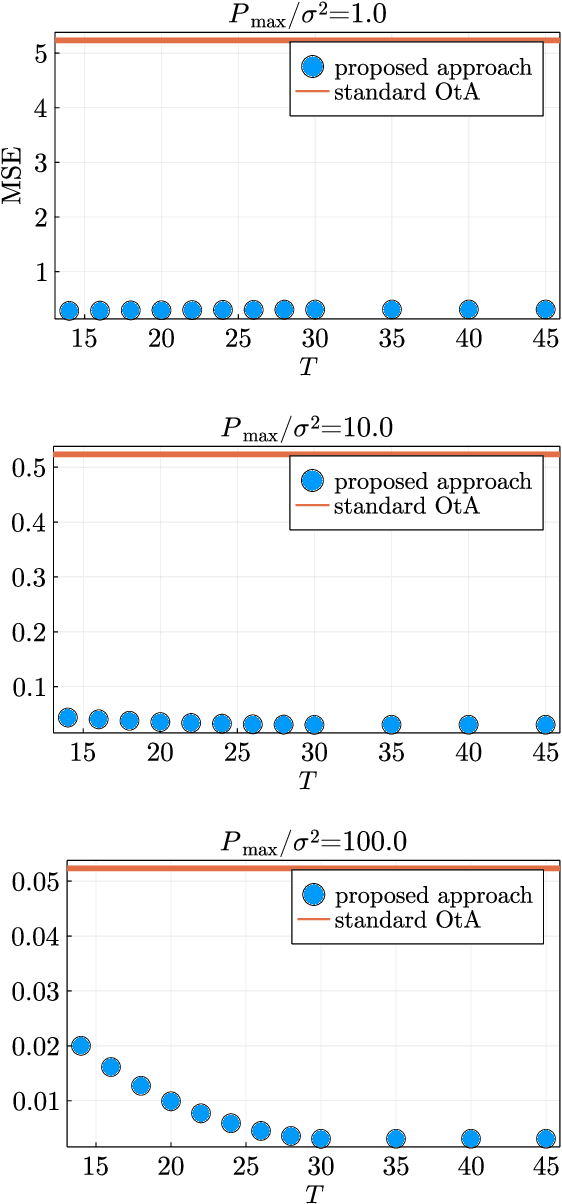
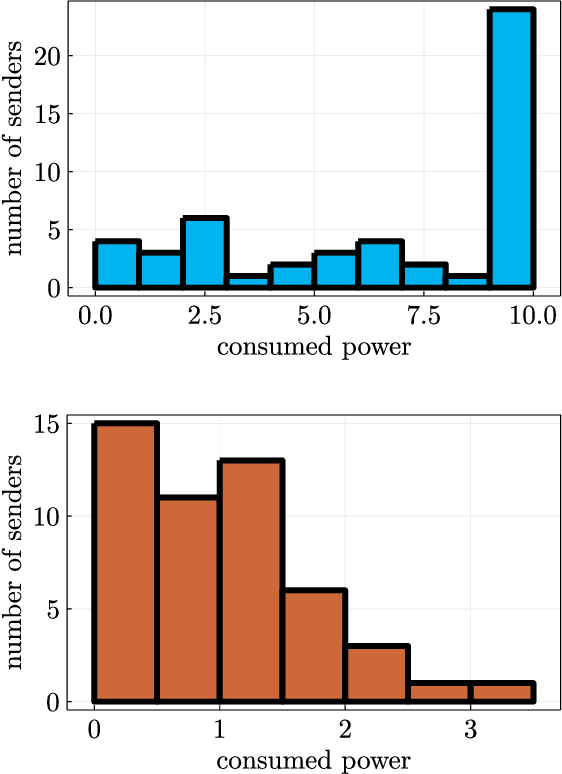
Over-the-air (OtA) computation is a newly emerged concept for achieving resource-efficient data aggregation over a large number of wireless nodes. Current research on this topic only considers the standard star topology with multiple senders transmitting information to one receiver. In this work, we investigate how to achieve OtA computation with multiple receivers, and we propose a novel communication design by exploiting joint precoding and decoding over multiple time slots. The optimal precoding and decoding vectors are determined by solving an optimization problem that aims at minimizing the mean squared error of aggregated data under the unbiasedness condition and the power constraints. We show that with our proposed multi-slot design, we can save communication resources (e.g., time slots) and achieve smaller estimation error as compared to the baseline approach of separating different receivers over time.
USR: Unsupervised Separated 3D Garment and Human Reconstruction via Geometry and Semantic Consistency
Feb 22, 2023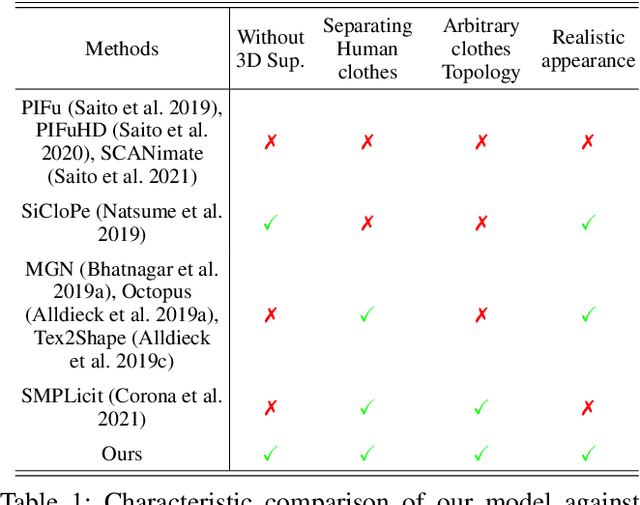
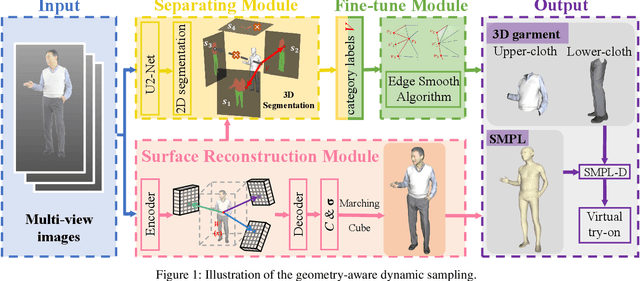
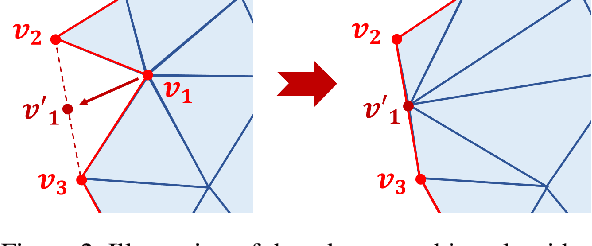
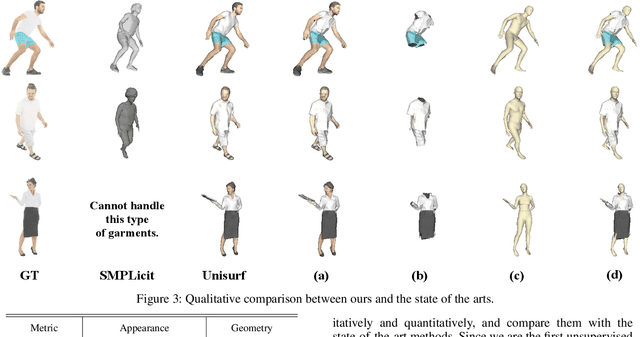
Dressed people reconstruction from images is a popular task with promising applications in the creative media and game industry. However, most existing methods reconstruct the human body and garments as a whole with the supervision of 3D models, which hinders the downstream interaction tasks and requires hard-to-obtain data. To address these issues, we propose an unsupervised separated 3D garments and human reconstruction model (USR), which reconstructs the human body and authentic textured clothes in layers without 3D models. More specifically, our method proposes a generalized surface-aware neural radiance field to learn the mapping between sparse multi-view images and geometries of the dressed people. Based on the full geometry, we introduce a Semantic and Confidence Guided Separation strategy (SCGS) to detect, segment, and reconstruct the clothes layer, leveraging the consistency between 2D semantic and 3D geometry. Moreover, we propose a Geometry Fine-tune Module to smooth edges. Extensive experiments on our dataset show that comparing with state-of-the-art methods, USR achieves improvements on both geometry and appearance reconstruction while supporting generalizing to unseen people in real time. Besides, we also introduce SMPL-D model to show the benefit of the separated modeling of clothes and the human body that allows swapping clothes and virtual try-on.