 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Practical Synchronization for OTFS
Jan 24, 2023
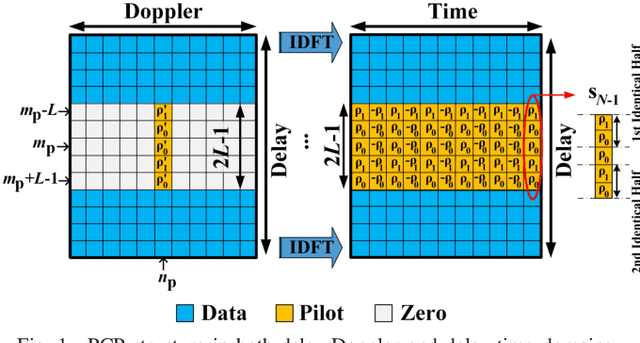
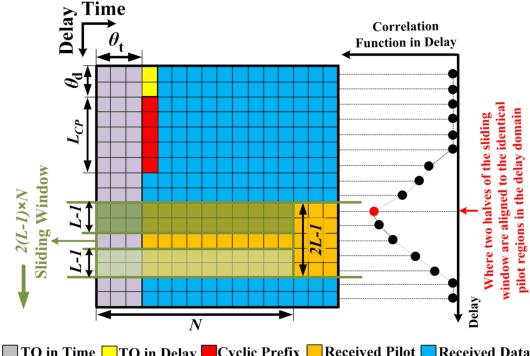
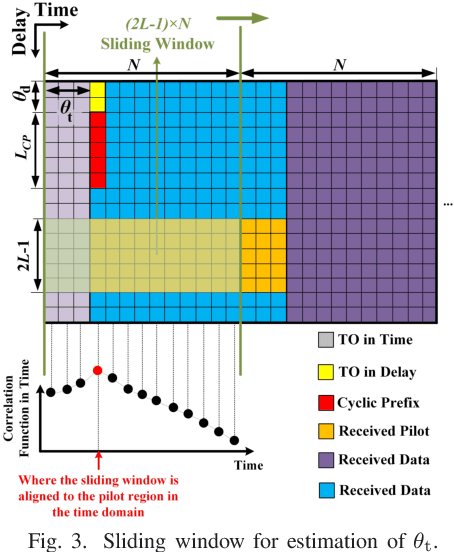
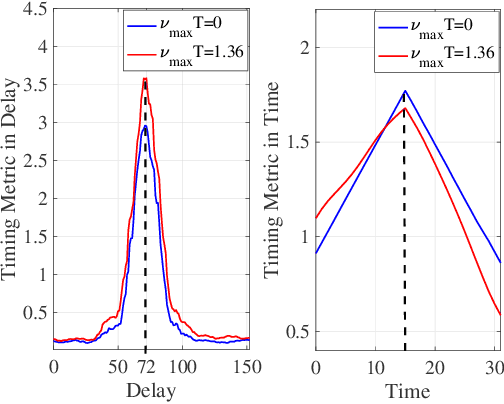
In the existing literature on joint timing and frequency synchronization of orthogonal time frequency space modulation (OTFS), practically infeasible impulse pilot with large peak-to-average power ratio (PAPR) is deployed. Hence, in this paper, we propose a timing offset (TO) and carrier frequency offset (CFO) estimation for OTFS over a linear time-varying (LTV) channel, using a low PAPR pilot structure. The proposed technique utilizes the recently proposed practically feasible pilot structure with a cyclic prefix (PCP). We exploit the periodic properties of PCP in both delay and time domains to find the starting point of each OTFS block. Furthermore, we propose a two-stage CFO estimation technique with over an order of magnitude higher estimation accuracy than the existing estimator using the impulse pilot. In the first stage, a coarse CFO estimate is obtained which is refined in the second stage, through our proposed maximum likelihood (ML) based approach. The proposed ML-based approach deploys the generalized complex exponential basis expansion model (GCE-BEM) to capture the time variations of the channel, absorb them into the pilot and provide an accurate CFO estimate. Since our proposed synchronization technique utilizes the same pilot deployed for channel estimation, it does not require any additional overhead. Finally, we evaluate the performance of our proposed synchronization technique through simulations. We also compare and show the superior performance of our proposed technique to the only other existing joint TO and CFO estimation method in OTFS literature.
Learning Vision-based Robotic Manipulation Tasks Sequentially in Offline Reinforcement Learning Settings
Jan 31, 2023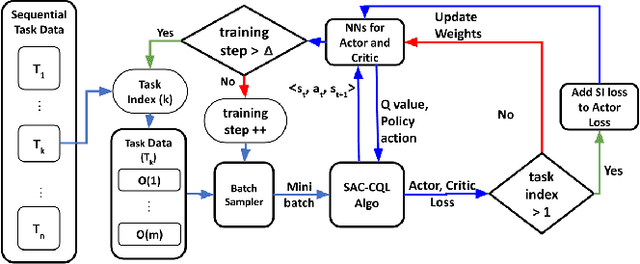
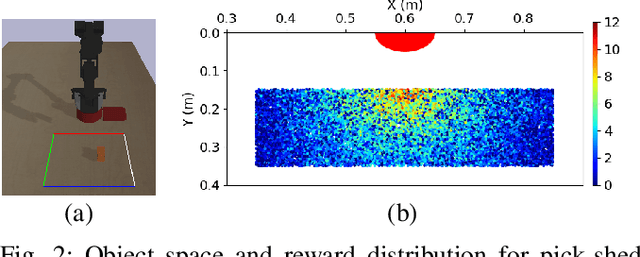
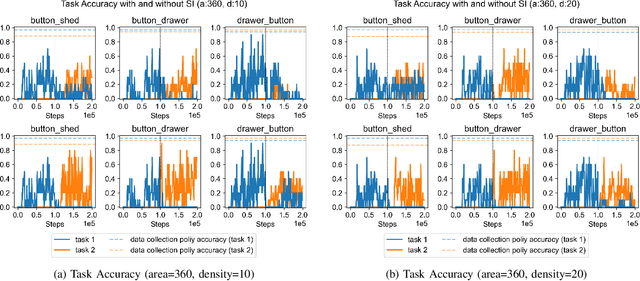
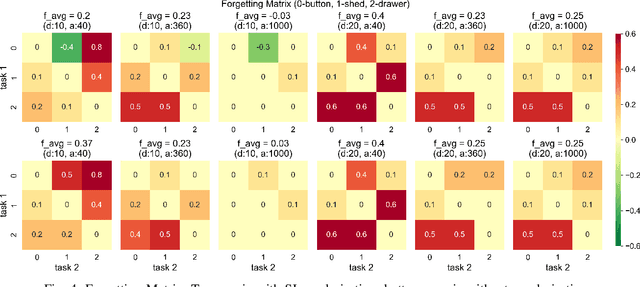
With the rise of deep reinforcement learning (RL) methods, many complex robotic manipulation tasks are being solved. However, harnessing the full power of deep learning requires large datasets. Online-RL does not suit itself readily into this paradigm due to costly and time-taking agent environment interaction. Therefore recently, many offline-RL algorithms have been proposed to learn robotic tasks. But mainly, all such methods focus on a single task or multi-task learning, which requires retraining every time we need to learn a new task. Continuously learning tasks without forgetting previous knowledge combined with the power of offline deep-RL would allow us to scale the number of tasks by keep adding them one-after-another. In this paper, we investigate the effectiveness of regularisation-based methods like synaptic intelligence for sequentially learning image-based robotic manipulation tasks in an offline-RL setup. We evaluate the performance of this combined framework against common challenges of sequential learning: catastrophic forgetting and forward knowledge transfer. We performed experiments with different task combinations to analyze the effect of task ordering. We also investigated the effect of the number of object configurations and density of robot trajectories. We found that learning tasks sequentially helps in the propagation of knowledge from previous tasks, thereby reducing the time required to learn a new task. Regularisation based approaches for continuous learning like the synaptic intelligence method although helps in mitigating catastrophic forgetting but has shown only limited transfer of knowledge from previous tasks.
Multi-Content Time-Series Popularity Prediction with Multiple-Model Transformers in MEC Networks
Oct 12, 2022
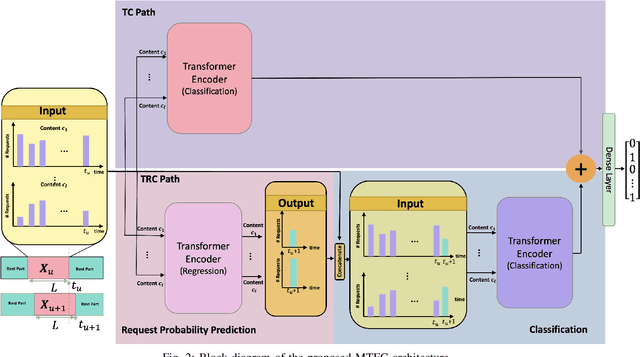
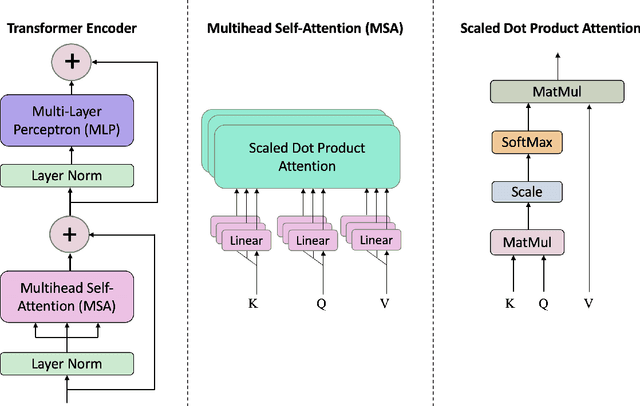
Coded/uncoded content placement in Mobile Edge Caching (MEC) has evolved as an efficient solution to meet the significant growth of global mobile data traffic by boosting the content diversity in the storage of caching nodes. To meet the dynamic nature of the historical request pattern of multimedia contents, the main focus of recent researches has been shifted to develop data-driven and real-time caching schemes. In this regard and with the assumption that users' preferences remain unchanged over a short horizon, the Top-K popular contents are identified as the output of the learning model. Most existing datadriven popularity prediction models, however, are not suitable for the coded/uncoded content placement frameworks. On the one hand, in coded/uncoded content placement, in addition to classifying contents into two groups, i.e., popular and nonpopular, the probability of content request is required to identify which content should be stored partially/completely, where this information is not provided by existing data-driven popularity prediction models. On the other hand, the assumption that users' preferences remain unchanged over a short horizon only works for content with a smooth request pattern. To tackle these challenges, we develop a Multiple-model (hybrid) Transformer-based Edge Caching (MTEC) framework with higher generalization ability, suitable for various types of content with different time-varying behavior, that can be adapted with coded/uncoded content placement frameworks. Simulation results corroborate the effectiveness of the proposed MTEC caching framework in comparison to its counterparts in terms of the cache-hit ratio, classification accuracy, and the transferred byte volume.
A Proof that Using Crossover Can Guarantee Exponential Speed-Ups in Evolutionary Multi-Objective Optimisation
Jan 31, 2023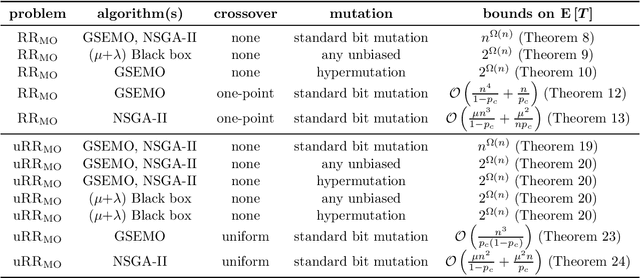
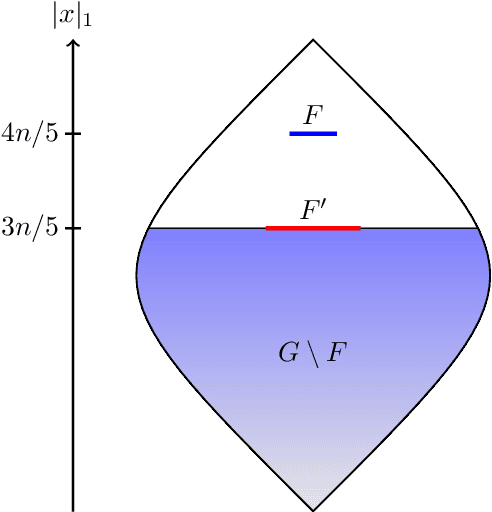
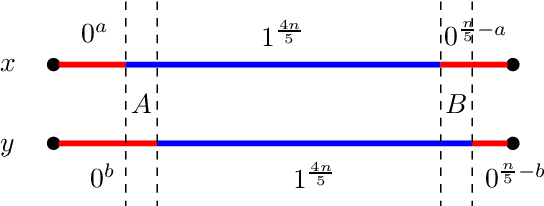
Evolutionary algorithms are popular algorithms for multiobjective optimisation (also called Pareto optimisation) as they use a population to store trade-offs between different objectives. Despite their popularity, the theoretical foundation of multiobjective evolutionary optimisation (EMO) is still in its early development. Fundamental questions such as the benefits of the crossover operator are still not fully understood. We provide a theoretical analysis of well-known EMO algorithms GSEMO and NSGA-II to showcase the possible advantages of crossover. We propose a class of problems on which these EMO algorithms using crossover find the Pareto set in expected polynomial time. In sharp contrast, they and many other EMO algorithms without crossover require exponential time to even find a single Pareto-optimal point. This is the first example of an exponential performance gap through the use of crossover for the widely used NSGA-II algorithm.
Differentially-Private Hierarchical Clustering with Provable Approximation Guarantees
Jan 31, 2023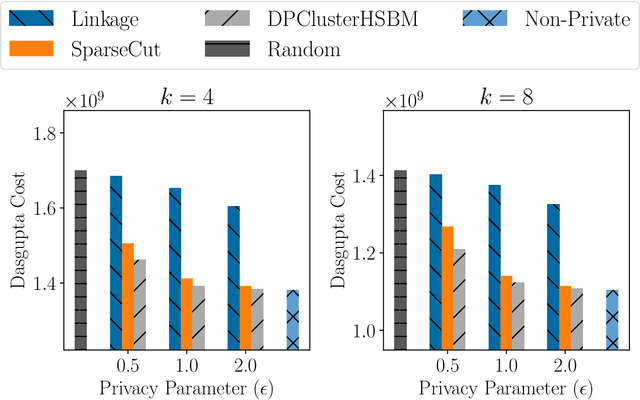
Hierarchical Clustering is a popular unsupervised machine learning method with decades of history and numerous applications. We initiate the study of differentially private approximation algorithms for hierarchical clustering under the rigorous framework introduced by (Dasgupta, 2016). We show strong lower bounds for the problem: that any $\epsilon$-DP algorithm must exhibit $O(|V|^2/ \epsilon)$-additive error for an input dataset $V$. Then, we exhibit a polynomial-time approximation algorithm with $O(|V|^{2.5}/ \epsilon)$-additive error, and an exponential-time algorithm that meets the lower bound. To overcome the lower bound, we focus on the stochastic block model, a popular model of graphs, and, with a separation assumption on the blocks, propose a private $1+o(1)$ approximation algorithm which also recovers the blocks exactly. Finally, we perform an empirical study of our algorithms and validate their performance.
Combining Tree-Search, Generative Models, and Nash Bargaining Concepts in Game-Theoretic Reinforcement Learning
Feb 01, 2023
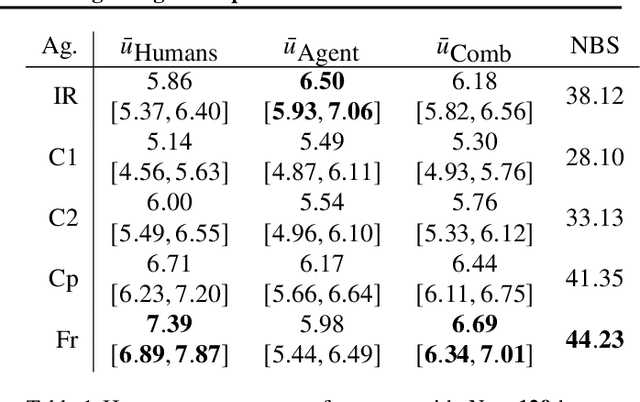
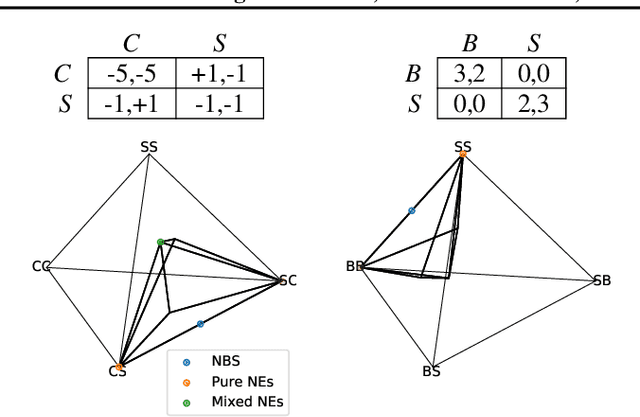
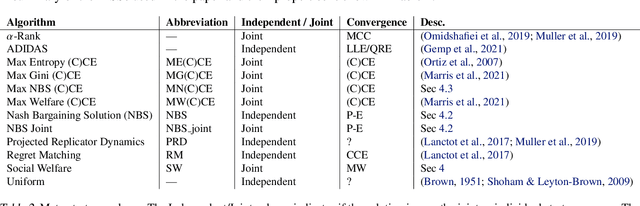
Multiagent reinforcement learning (MARL) has benefited significantly from population-based and game-theoretic training regimes. One approach, Policy-Space Response Oracles (PSRO), employs standard reinforcement learning to compute response policies via approximate best responses and combines them via meta-strategy selection. We augment PSRO by adding a novel search procedure with generative sampling of world states, and introduce two new meta-strategy solvers based on the Nash bargaining solution. We evaluate PSRO's ability to compute approximate Nash equilibrium, and its performance in two negotiation games: Colored Trails, and Deal or No Deal. We conduct behavioral studies where human participants negotiate with our agents ($N = 346$). We find that search with generative modeling finds stronger policies during both training time and test time, enables online Bayesian co-player prediction, and can produce agents that achieve comparable social welfare negotiating with humans as humans trading among themselves.
Multiagent Inverse Reinforcement Learning via Theory of Mind Reasoning
Mar 01, 2023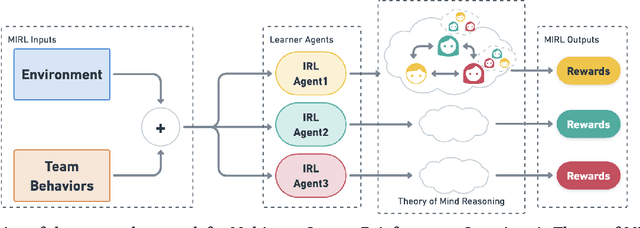
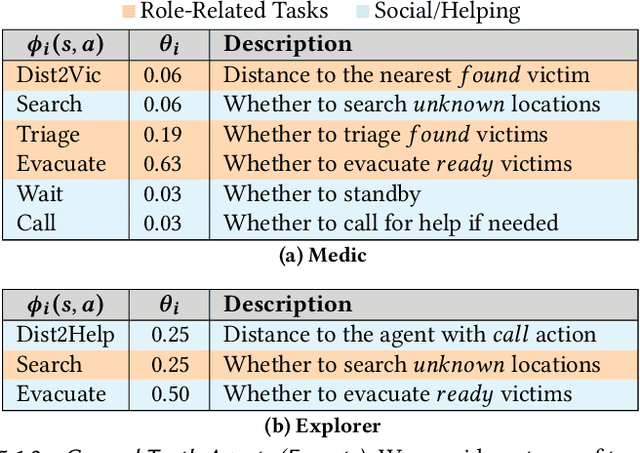


We approach the problem of understanding how people interact with each other in collaborative settings, especially when individuals know little about their teammates, via Multiagent Inverse Reinforcement Learning (MIRL), where the goal is to infer the reward functions guiding the behavior of each individual given trajectories of a team's behavior during some task. Unlike current MIRL approaches, we do not assume that team members know each other's goals a priori; rather, that they collaborate by adapting to the goals of others perceived by observing their behavior, all while jointly performing a task. To address this problem, we propose a novel approach to MIRL via Theory of Mind (MIRL-ToM). For each agent, we first use ToM reasoning to estimate a posterior distribution over baseline reward profiles given their demonstrated behavior. We then perform MIRL via decentralized equilibrium by employing single-agent Maximum Entropy IRL to infer a reward function for each agent, where we simulate the behavior of other teammates according to the time-varying distribution over profiles. We evaluate our approach in a simulated 2-player search-and-rescue operation where the goal of the agents, playing different roles, is to search for and evacuate victims in the environment. Our results show that the choice of baseline profiles is paramount to the recovery of the ground-truth rewards, and that MIRL-ToM is able to recover the rewards used by agents interacting both with known and unknown teammates.
Online Video Streaming Super-Resolution with Adaptive Look-Up Table Fusion
Mar 01, 2023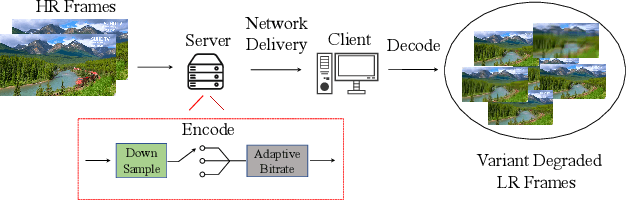
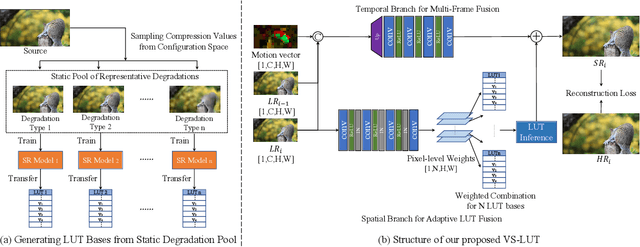
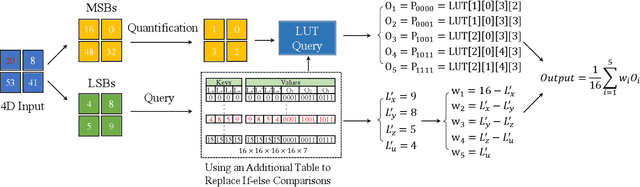
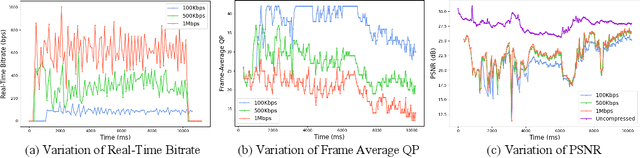
This paper focuses on Super-resolution for online video streaming data. Applying existing super-resolution methods to video streaming data is non-trivial for two reasons. First, to support application with constant interactions, video streaming has a high requirement for latency that most existing methods are less applicable, especially on low-end devices. Second, existing video streaming protocols (e.g., WebRTC) dynamically adapt the video quality to the network condition, thus video streaming in the wild varies greatly under different network bandwidths, which leads to diverse and dynamic degradations. To tackle the above two challenges, we proposed a novel video super-resolution method for online video streaming. First, we incorporate Look-Up Table (LUT) to lightweight convolution modules to achieve real-time latency. Second, for variant degradations, we propose a pixel-level LUT fusion strategy, where a set of LUT bases are built upon state-of-the-art SR networks pre-trained on different degraded data, and those LUT bases are combined with extracted weights from lightweight convolution modules to adaptively handle dynamic degradations. Extensive experiments are conducted on a newly proposed online video streaming dataset named LDV-WebRTC. All the results show that our method significantly outperforms existing LUT-based methods and offers competitive SR performance with faster speed compared to efficient CNN-based methods. Accelerated with our parallel LUT inference, our proposed method can even support online 720P video SR around 100 FPS.
DAMO-YOLO : A Report on Real-Time Object Detection Design
Dec 15, 2022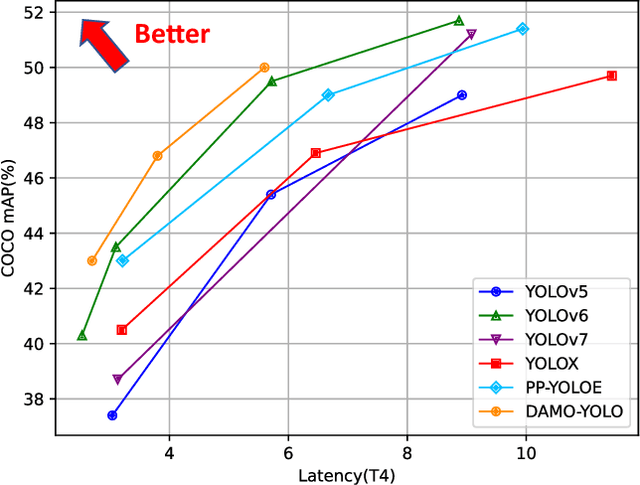
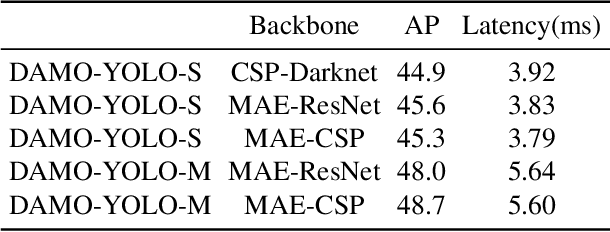
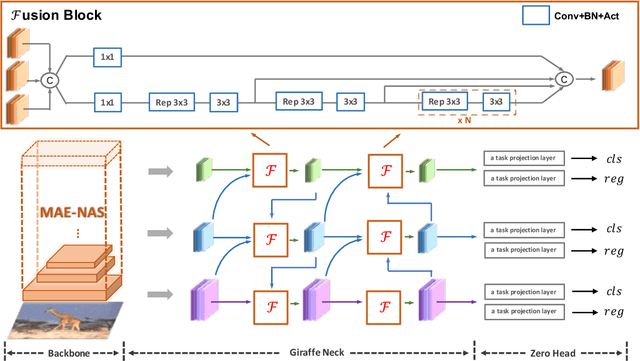
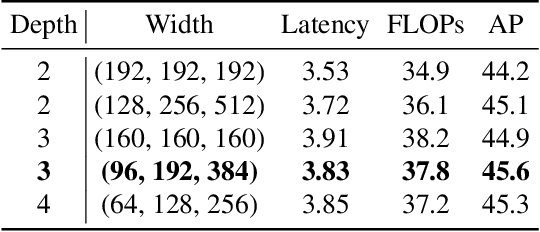
In this report, we present a fast and accurate object detection method dubbed DAMO-YOLO, which achieves higher performance than the state-of-the-art YOLO series. DAMO-YOLO is extended from YOLO with some new technologies, including Neural Architecture Search (NAS), efficient Reparameterized Generalized-FPN (RepGFPN), a lightweight head with AlignedOTA label assignment, and distillation enhancement. In particular, we use MAE-NAS, a method guided by the principle of maximum entropy, to search our detection backbone under the constraints of low latency and high performance, producing ResNet-like / CSP-like structures with spatial pyramid pooling and focus modules. In the design of necks and heads, we follow the rule of "large neck, small head". We import Generalized-FPN with accelerated queen-fusion to build the detector neck and upgrade its CSPNet with efficient layer aggregation networks (ELAN) and reparameterization. Then we investigate how detector head size affects detection performance and find that a heavy neck with only one task projection layer would yield better results. In addition, AlignedOTA is proposed to solve the misalignment problem in label assignment. And a distillation schema is introduced to improve performance to a higher level. Based on these new techs, we build a suite of models at various scales to meet the needs of different scenarios, i.e., DAMO-YOLO-Tiny/Small/Medium. They can achieve 43.0/46.8/50.0 mAPs on COCO with the latency of 2.78/3.83/5.62 ms on T4 GPUs respectively. The code is available at https://github.com/tinyvision/damo-yolo.
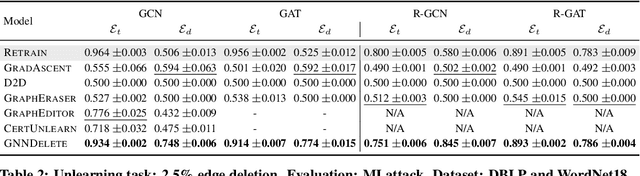
GNNDelete: A General Strategy for Unlearning in Graph Neural Networks
Feb 26, 2023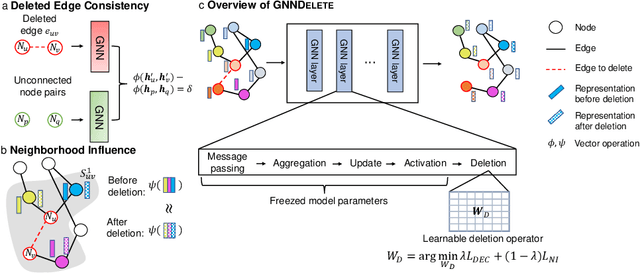
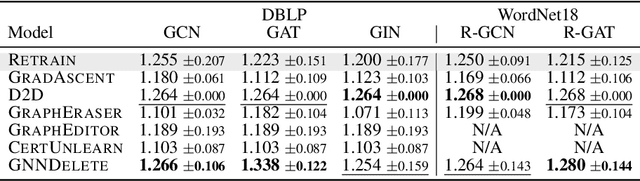
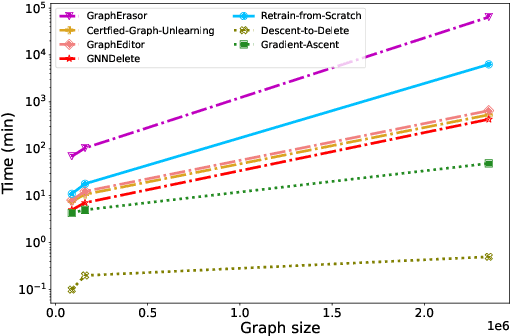
Graph unlearning, which involves deleting graph elements such as nodes, node labels, and relationships from a trained graph neural network (GNN) model, is crucial for real-world applications where data elements may become irrelevant, inaccurate, or privacy-sensitive. However, existing methods for graph unlearning either deteriorate model weights shared across all nodes or fail to effectively delete edges due to their strong dependence on local graph neighborhoods. To address these limitations, we introduce GNNDelete, a novel model-agnostic layer-wise operator that optimizes two critical properties, namely, Deleted Edge Consistency and Neighborhood Influence, for graph unlearning. Deleted Edge Consistency ensures that the influence of deleted elements is removed from both model weights and neighboring representations, while Neighborhood Influence guarantees that the remaining model knowledge is preserved after deletion. GNNDelete updates representations to delete nodes and edges from the model while retaining the rest of the learned knowledge. We conduct experiments on seven real-world graphs, showing that GNNDelete outperforms existing approaches by up to 38.8% (AUC) on edge, node, and node feature deletion tasks, and 32.2% on distinguishing deleted edges from non-deleted ones. Additionally, GNNDelete is efficient, taking 12.3x less time and 9.3x less space than retraining GNN from scratch on WordNet18.