 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ProbPNN: Enhancing Deep Probabilistic Forecasting with Statistical Information
Feb 06, 2023
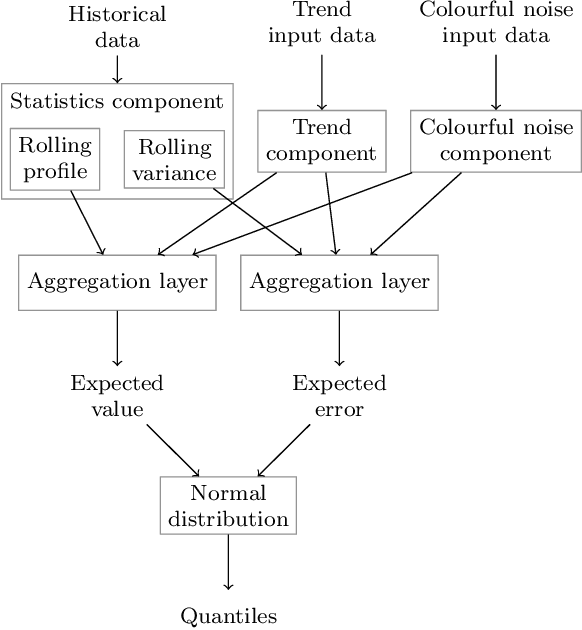
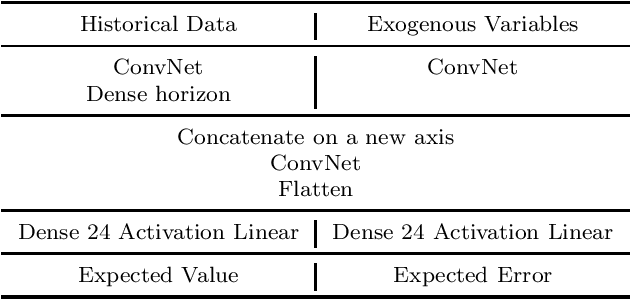

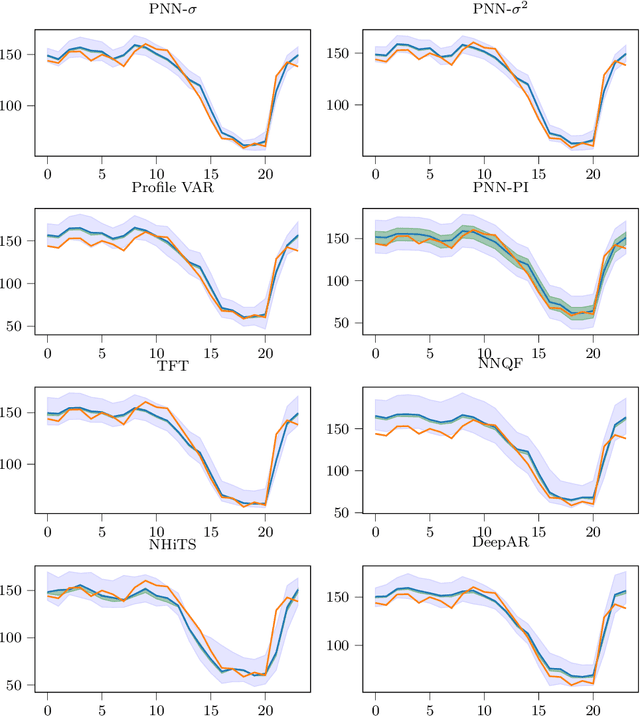
Probabilistic forecasts are essential for various downstream applications such as business development, traffic planning, and electrical grid balancing. Many of these probabilistic forecasts are performed on time series data that contain calendar-driven periodicities. However, existing probabilistic forecasting methods do not explicitly take these periodicities into account. Therefore, in the present paper, we introduce a deep learning-based method that considers these calendar-driven periodicities explicitly. The present paper, thus, has a twofold contribution: First, we apply statistical methods that use calendar-driven prior knowledge to create rolling statistics and combine them with neural networks to provide better probabilistic forecasts. Second, we benchmark ProbPNN with state-of-the-art benchmarks by comparing the achieved normalised continuous ranked probability score (nCRPS) and normalised Pinball Loss (nPL) on two data sets containing in total more than 1000 time series. The results of the benchmarks show that using statistical forecasting components improves the probabilistic forecast performance and that ProbPNN outperforms other deep learning forecasting methods whilst requiring less computation costs.
Exploring the Advantages of Transformers for High-Frequency Trading
Feb 20, 2023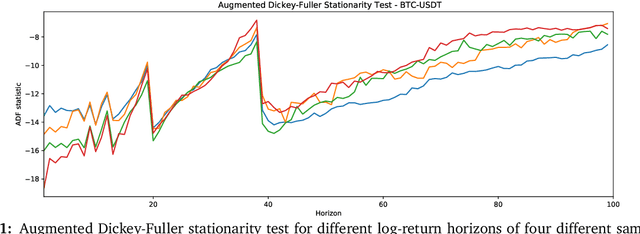
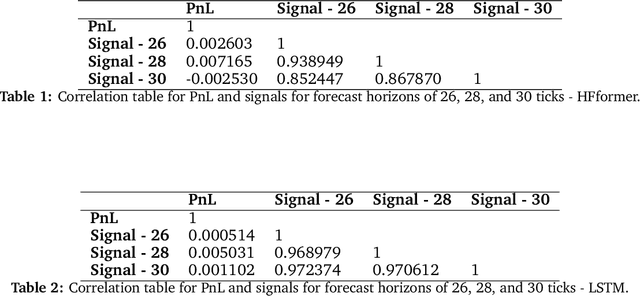
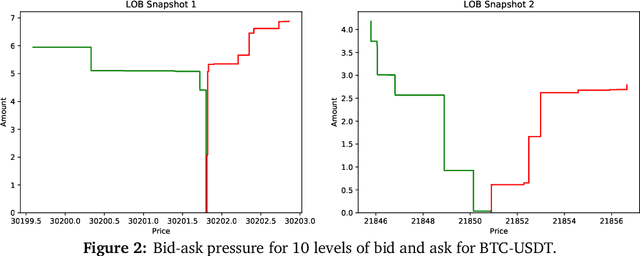
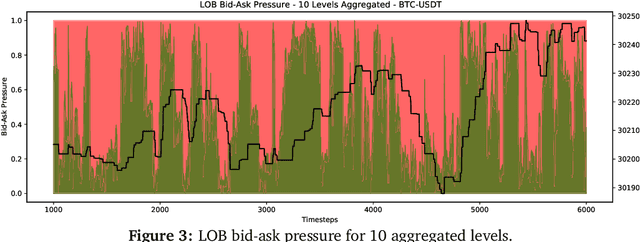
This paper explores the novel deep learning Transformers architectures for high-frequency Bitcoin-USDT log-return forecasting and compares them to the traditional Long Short-Term Memory models. A hybrid Transformer model, called \textbf{HFformer}, is then introduced for time series forecasting which incorporates a Transformer encoder, linear decoder, spiking activations, and quantile loss function, and does not use position encoding. Furthermore, possible high-frequency trading strategies for use with the HFformer model are discussed, including trade sizing, trading signal aggregation, and minimal trading threshold. Ultimately, the performance of the HFformer and Long Short-Term Memory models are assessed and results indicate that the HFformer achieves a higher cumulative PnL than the LSTM when trading with multiple signals during backtesting.
On the Expressivity of Persistent Homology in Graph Learning
Feb 20, 2023
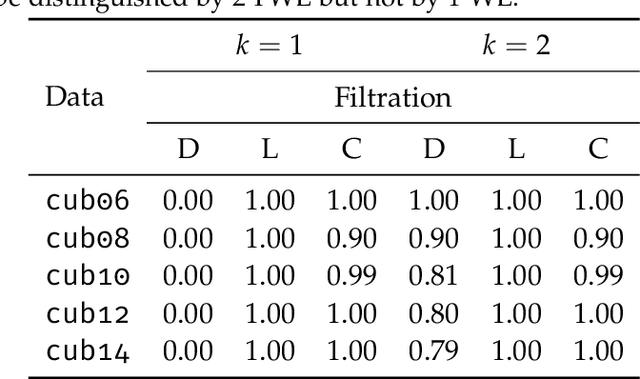
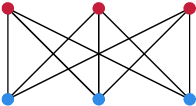
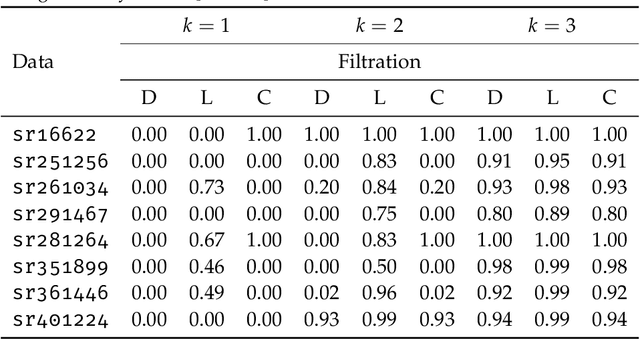
Persistent homology, a technique from computational topology, has recently shown strong empirical performance in the context of graph classification. Being able to capture long range graph properties via higher-order topological features, such as cycles of arbitrary length, in combination with multi-scale topological descriptors, has improved predictive performance for data sets with prominent topological structures, such as molecules. At the same time, the theoretical properties of persistent homology have not been formally assessed in this context. This paper intends to bridge the gap between computational topology and graph machine learning by providing a brief introduction to persistent homology in the context of graphs, as well as a theoretical discussion and empirical analysis of its expressivity for graph learning tasks.
Two-stream Decoder Feature Normality Estimating Network for Industrial Anomaly Detection
Feb 20, 2023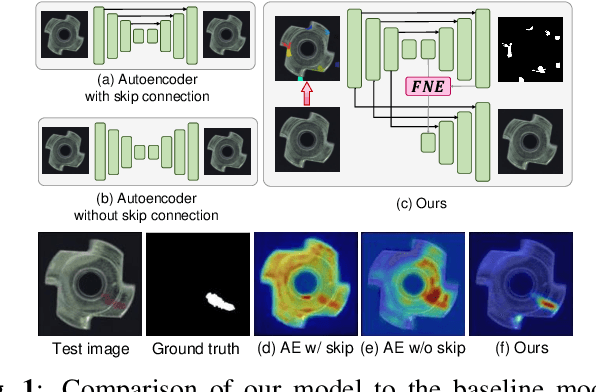

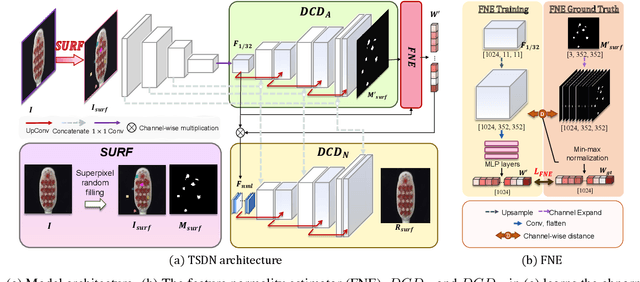
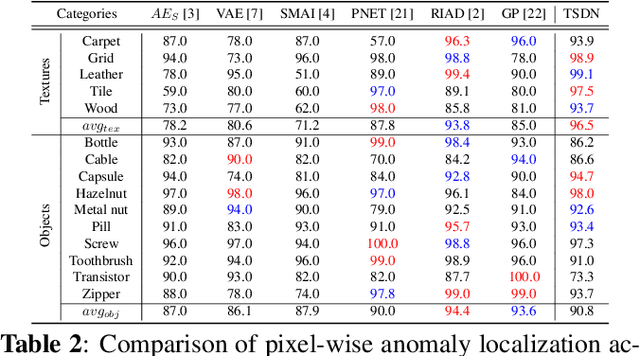
Image reconstruction-based anomaly detection has recently been in the spotlight because of the difficulty of constructing anomaly datasets. These approaches work by learning to model normal features without seeing abnormal samples during training and then discriminating anomalies at test time based on the reconstructive errors. However, these models have limitations in reconstructing the abnormal samples due to their indiscriminate conveyance of features. Moreover, these approaches are not explicitly optimized for distinguishable anomalies. To address these problems, we propose a two-stream decoder network (TSDN), designed to learn both normal and abnormal features. Additionally, we propose a feature normality estimator (FNE) to eliminate abnormal features and prevent high-quality reconstruction of abnormal regions. Evaluation on a standard benchmark demonstrated performance better than state-of-the-art models.
A Differentiable Signed Distance Representation for Continuous Collision Avoidance in Optimization-Based Motion Planning
Feb 20, 2023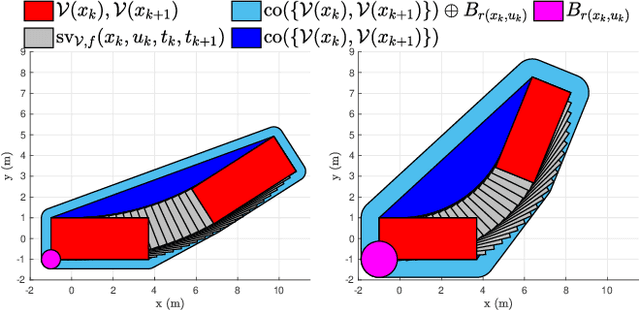
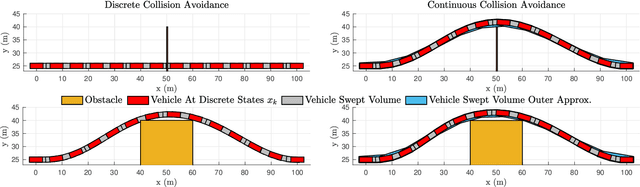
This paper proposes a new set of conditions for exactly representing collision avoidance constraints within optimization-based motion planning algorithms. The conditions are continuously differentiable and therefore suitable for use with standard nonlinear optimization solvers. The method represents convex shapes using a support function representation and is therefore quite general. For collision avoidance involving polyhedral or ellipsoidal shapes, the proposed method introduces fewer variables and constraints than existing approaches. Additionally the proposed method can be used to rigorously ensure continuous collision avoidance as the vehicle transitions between the discrete poses determined by the motion planning algorithm. Numerical examples demonstrate how this can be used to prevent problems of corner cutting and passing through obstacles which can occur when collision avoidance is only enforced at discrete time steps.
* 8 pages, 2 figures, accepted for publication at IEEE Conference on Decision and Control, 2022
Real-Time Reinforcement Learning for Vision-Based Robotics Utilizing Local and Remote Computers
Oct 05, 2022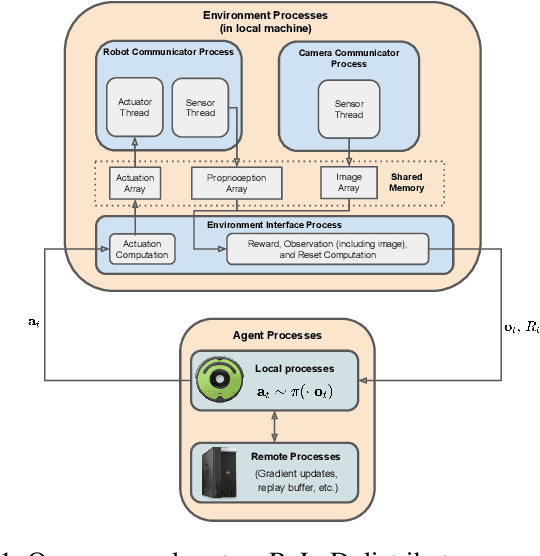
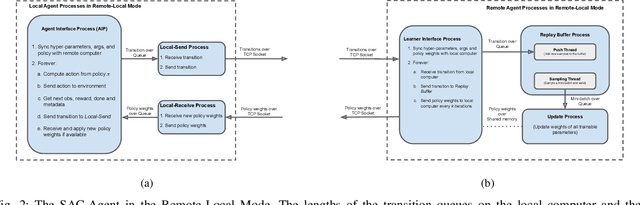
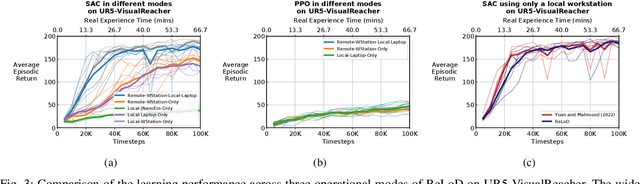
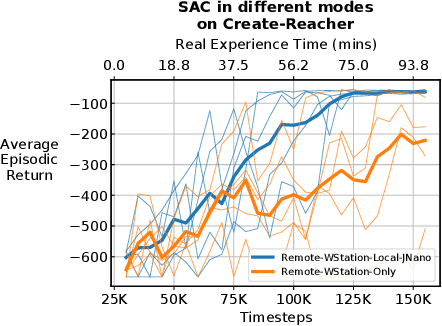
Real-time learning is crucial for robotic agents adapting to ever-changing, non-stationary environments. A common setup for a robotic agent is to have two different computers simultaneously: a resource-limited local computer tethered to the robot and a powerful remote computer connected wirelessly. Given such a setup, it is unclear to what extent the performance of a learning system can be affected by resource limitations and how to efficiently use the wirelessly connected powerful computer to compensate for any performance loss. In this paper, we implement a real-time learning system called the Remote-Local Distributed (ReLoD) system to distribute computations of two deep reinforcement learning (RL) algorithms, Soft Actor-Critic (SAC) and Proximal Policy Optimization (PPO), between a local and a remote computer. The performance of the system is evaluated on two vision-based control tasks developed using a robotic arm and a mobile robot. Our results show that SAC's performance degrades heavily on a resource-limited local computer. Strikingly, when all computations of the learning system are deployed on a remote workstation, SAC fails to compensate for the performance loss, indicating that, without careful consideration, using a powerful remote computer may not result in performance improvement. However, a carefully chosen distribution of computations of SAC consistently and substantially improves its performance on both tasks. On the other hand, the performance of PPO remains largely unaffected by the distribution of computations. In addition, when all computations happen solely on a powerful tethered computer, the performance of our system remains on par with an existing system that is well-tuned for using a single machine. ReLoD is the only publicly available system for real-time RL that applies to multiple robots for vision-based tasks.
ONE PIECE: One Patchwork In Effectively Combined Extraction for grasp
Mar 06, 2023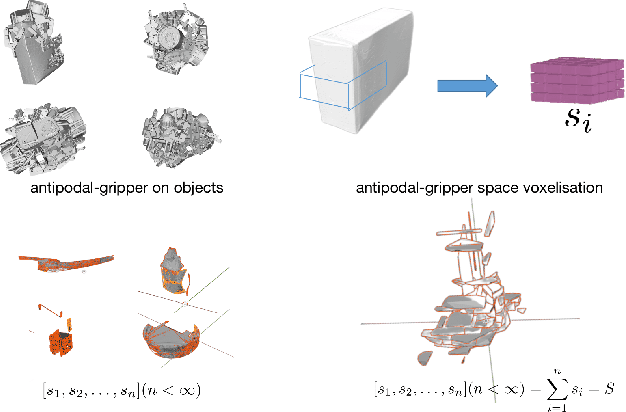

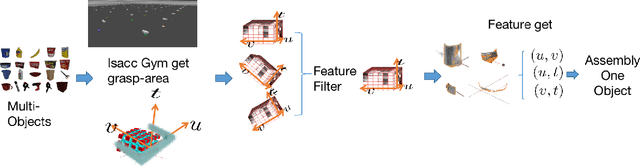
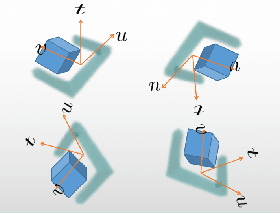
For grasp network algorithms, generating grasp datasets for a large number of 3D objects is a crucial task. However, generating grasp datasets for hundreds of objects can be very slow and consume a lot of storage resources, which hinders algorithm iteration and promotion. For point cloud grasp network algorithms, the network input is essentially the internal point cloud of the grasp area that intersects with the object in the gripper coordinate system. Due to the existence of a large number of completely consistent gripper area point clouds based on the gripper coordinate system in the grasp dataset generated for hundreds of objects, it is possible to remove the consistent gripper area point clouds from many objects and assemble them into a single object to generate the grasp dataset, thus replacing the enormous workload of generating grasp datasets for hundreds of objects. We propose a new approach to map the repetitive features of a large number of objects onto a finite set.To this end, we propose a method for extracting the gripper area point cloud that intersects with the object from the simulator and design a gripper feature filter to remove the shape-repeated gripper space area point clouds, and then assemble them into a single object. The experimental results show that the time required to generate the new object grasp dataset is greatly reduced compared to generating the grasp dataset for hundreds of objects, and it performs well in real machine grasping experiments. We will release the data and tools after the paper is accepted.
Self-Supervised Contrastive Pre-Training For Time Series via Time-Frequency Consistency
Jun 17, 2022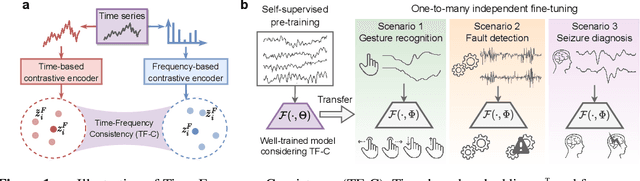
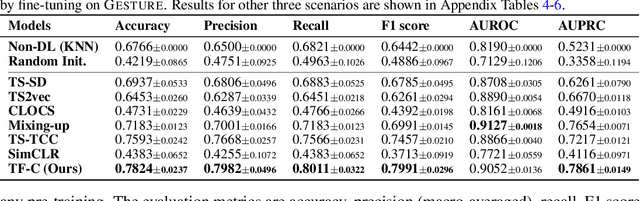
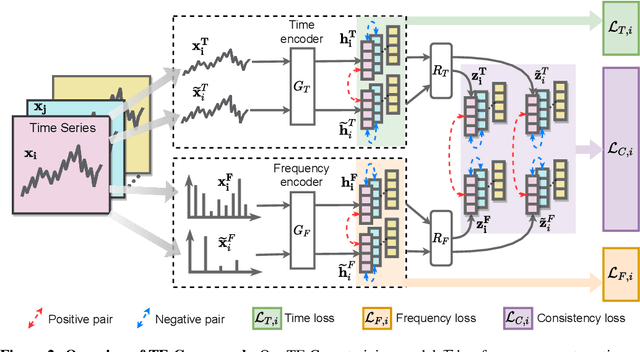
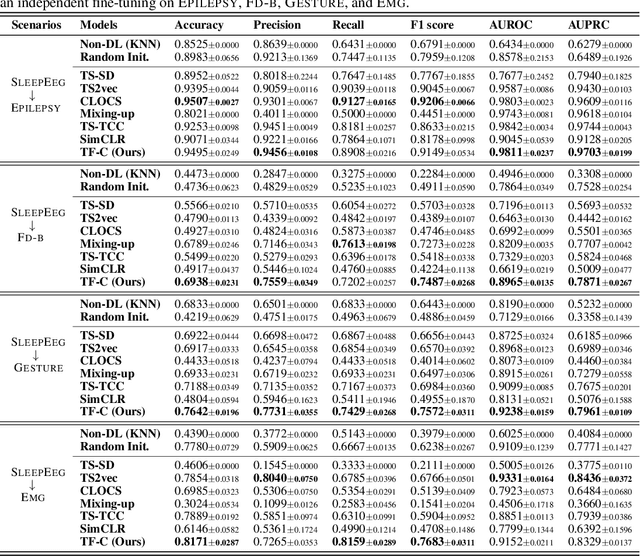
Pre-training on time series poses a unique challenge due to the potential mismatch between pre-training and target domains, such as shifts in temporal dynamics, fast-evolving trends, and long-range and short cyclic effects, which can lead to poor downstream performance. While domain adaptation methods can mitigate these shifts, most methods need examples directly from the target domain, making them suboptimal for pre-training. To address this challenge, methods need to accommodate target domains with different temporal dynamics and be capable of doing so without seeing any target examples during pre-training. Relative to other modalities, in time series, we expect that time-based and frequency-based representations of the same example are located close together in the time-frequency space. To this end, we posit that time-frequency consistency (TF-C) -- embedding a time-based neighborhood of a particular example close to its frequency-based neighborhood and back -- is desirable for pre-training. Motivated by TF-C, we define a decomposable pre-training model, where the self-supervised signal is provided by the distance between time and frequency components, each individually trained by contrastive estimation. We evaluate the new method on eight datasets, including electrodiagnostic testing, human activity recognition, mechanical fault detection, and physical status monitoring. Experiments against eight state-of-the-art methods show that TF-C outperforms baselines by 15.4% (F1 score) on average in one-to-one settings (e.g., fine-tuning an EEG-pretrained model on EMG data) and by up to 8.4% (F1 score) in challenging one-to-many settings, reflecting the breadth of scenarios that arise in real-world applications. The source code and datasets are available at https: //anonymous.4open.science/r/TFC-pretraining-6B07.
Extreme-Long-short Term Memory for Time-series Prediction
Oct 15, 2022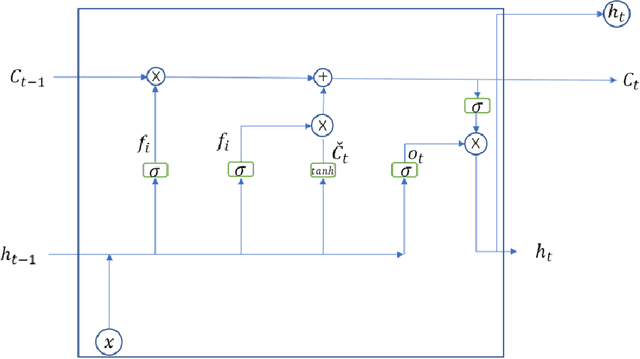
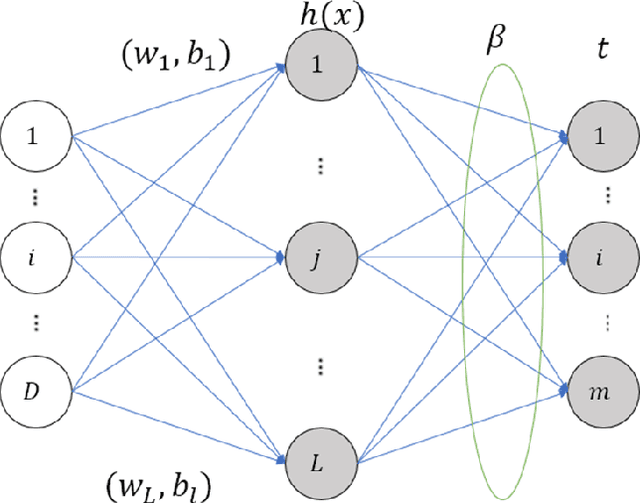
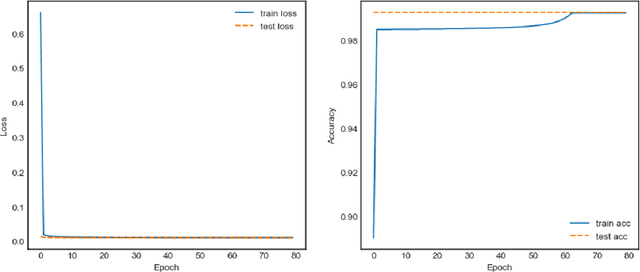
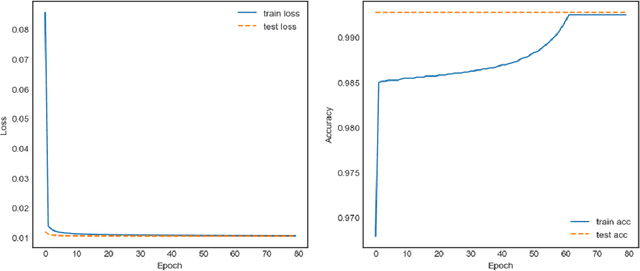
The emergence of Long Short-Term Memory (LSTM) solves the problems of vanishing gradient and exploding gradient in traditional Recurrent Neural Networks (RNN). LSTM, as a new type of RNN, has been widely used in various fields, such as text prediction, Wind Speed Forecast, depression prediction by EEG signals, etc. The results show that improving the efficiency of LSTM can help to improve the efficiency in other application areas. In this paper, we proposed an advanced LSTM algorithm, the Extreme Long Short-Term Memory (E-LSTM), which adds the inverse matrix part of Extreme Learning Machine (ELM) as a new "gate" into the structure of LSTM. This "gate" preprocess a portion of the data and involves the processed data in the cell update of the LSTM to obtain more accurate data with fewer training rounds, thus reducing the overall training time. In this research, the E-LSTM model is used for the text prediction task. Experimental results showed that the E-LSTM sometimes takes longer to perform a single training round, but when tested on a small data set, the new E-LSTM requires only 2 epochs to obtain the results of the 7th epoch traditional LSTM. Therefore, the E-LSTM retains the high accuracy of the traditional LSTM, whilst also improving the training speed and the overall efficiency of the LSTM.
TTT-UCDR: Test-time Training for Universal Cross-Domain Retrieval
Aug 19, 2022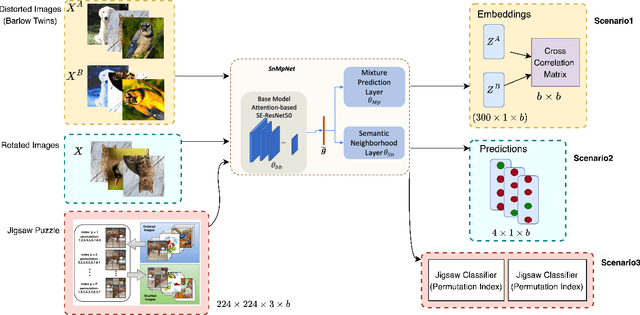
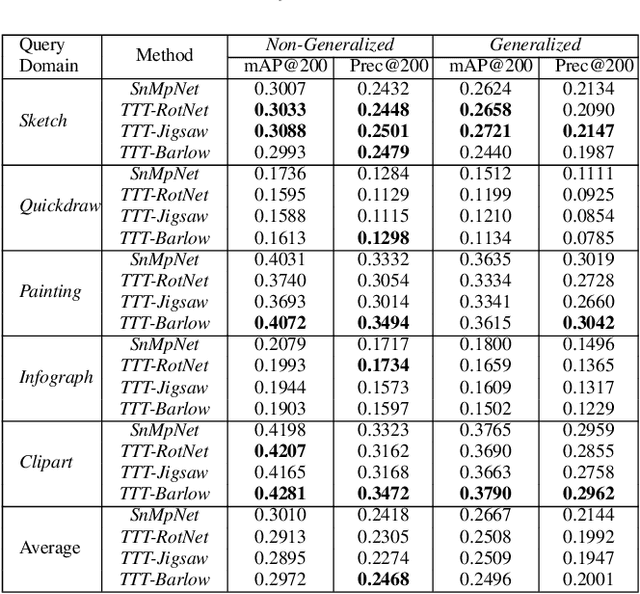
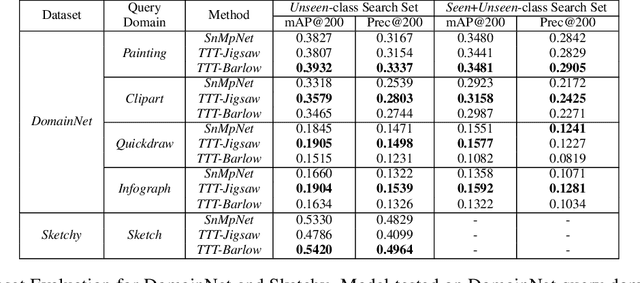
Image retrieval is a niche problem in computer vision curated towards finding similar images in a database using a query. In this work, for the first time in literature, we employ test-time training techniques for adapting to distribution shifts under Universal Cross-Domain Retrieval (UCDR). Test-time training has previously been shown to reduce generalization error for image classification, domain adaptation, semantic segmentation, and zero-shot sketch-based image retrieval (ZS-SBIR). In UCDR, in addition to the semantic shift of unknown categories present in ZS-SBIR, the presence of unknown domains leads to even higher distribution shifts. To bridge this domain gap, we use self-supervision through 3 different losses - Barlow Twins, Jigsaw Puzzle and RotNet on a pretrained network at test-time. This simple approach leads to improvements on UCDR benchmarks and also improves model robustness under a challenging cross-dataset generalization setting.