 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Communication and Control in Collaborative UAVs: Recent Advances and Future Trends
Feb 23, 2023
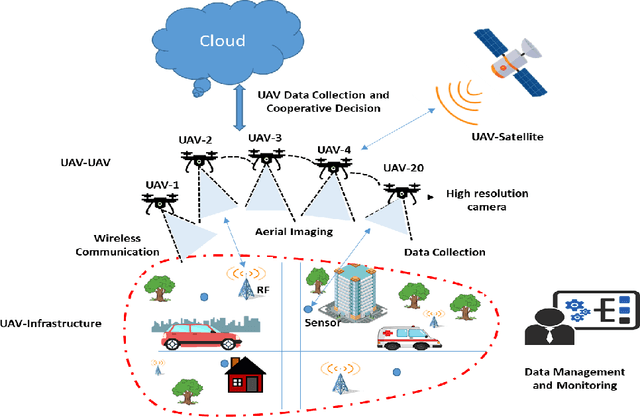
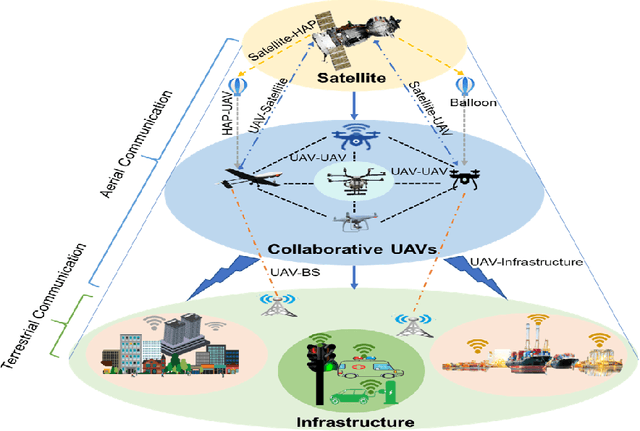
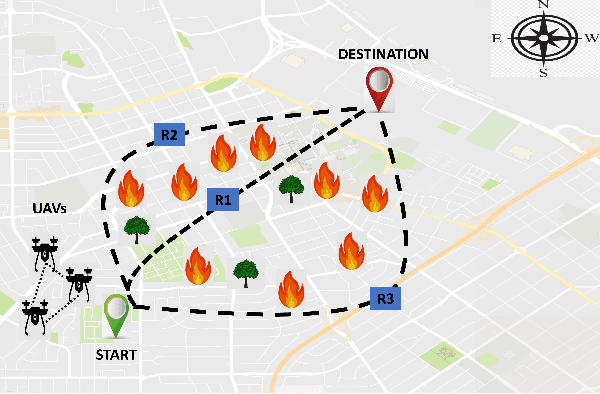
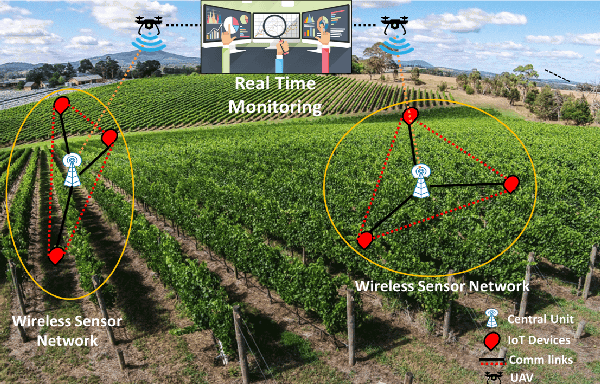
The recent progress in unmanned aerial vehicles (UAV) technology has significantly advanced UAV-based applications for military, civil, and commercial domains. Nevertheless, the challenges of establishing high-speed communication links, flexible control strategies, and developing efficient collaborative decision-making algorithms for a swarm of UAVs limit their autonomy, robustness, and reliability. Thus, a growing focus has been witnessed on collaborative communication to allow a swarm of UAVs to coordinate and communicate autonomously for the cooperative completion of tasks in a short time with improved efficiency and reliability. This work presents a comprehensive review of collaborative communication in a multi-UAV system. We thoroughly discuss the characteristics of intelligent UAVs and their communication and control requirements for autonomous collaboration and coordination. Moreover, we review various UAV collaboration tasks, summarize the applications of UAV swarm networks for dense urban environments and present the use case scenarios to highlight the current developments of UAV-based applications in various domains. Finally, we identify several exciting future research direction that needs attention for advancing the research in collaborative UAVs.
Tight Runtime Bounds for Static Unary Unbiased Evolutionary Algorithms on Linear Functions
Feb 23, 2023In a seminal paper in 2013, Witt showed that the (1+1) Evolutionary Algorithm with standard bit mutation needs time $(1+o(1))n \ln n/p_1$ to find the optimum of any linear function, as long as the probability $p_1$ to flip exactly one bit is $\Theta(1)$. In this paper we investigate how this result generalizes if standard bit mutation is replaced by an arbitrary unbiased mutation operator. This situation is notably different, since the stochastic domination argument used for the lower bound by Witt no longer holds. In particular, starting closer to the optimum is not necessarily an advantage, and OneMax is no longer the easiest function for arbitrary starting position. Nevertheless, we show that Witt's result carries over if $p_1$ is not too small and if the number of flipped bits has bounded expectation~$\mu$. Notably, this includes some of the heavy-tail mutation operators used in fast genetic algorithms, but not all of them. We also give examples showing that algorithms with unbounded $\mu$ have qualitatively different trajectories close to the optimum.
Investigating Catastrophic Overfitting in Fast Adversarial Training: A Self-fitting Perspective
Feb 23, 2023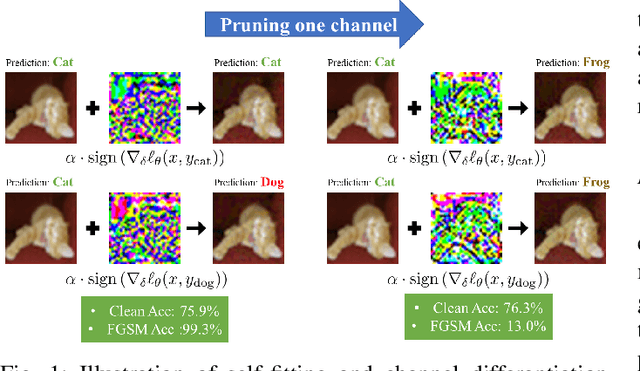
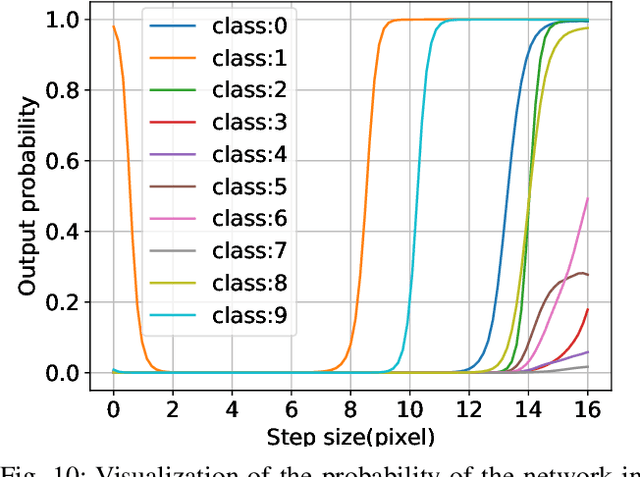
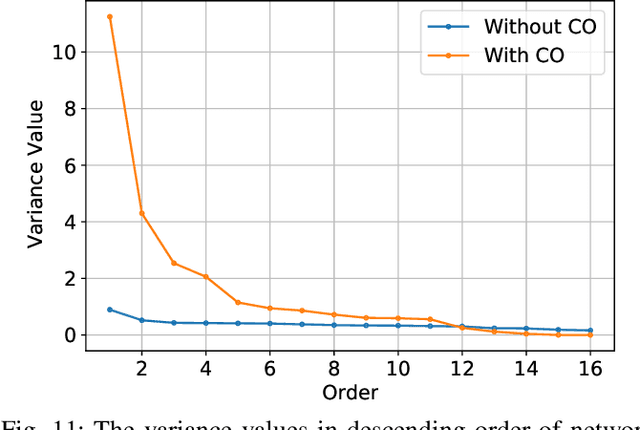
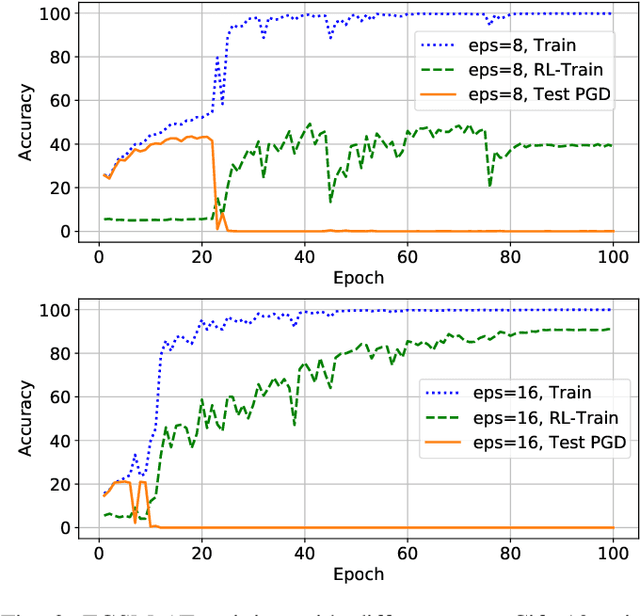
Although fast adversarial training provides an efficient approach for building robust networks, it may suffer from a serious problem known as catastrophic overfitting (CO), where the multi-step robust accuracy suddenly collapses to zero. In this paper, we for the first time decouple the FGSM examples into data-information and self-information, which reveals an interesting phenomenon called "self-fitting". Self-fitting, i.e., DNNs learn the self-information embedded in single-step perturbations, naturally leads to the occurrence of CO. When self-fitting occurs, the network experiences an obvious "channel differentiation" phenomenon that some convolution channels accounting for recognizing self-information become dominant, while others for data-information are suppressed. In this way, the network learns to only recognize images with sufficient self-information and loses generalization ability to other types of data. Based on self-fitting, we provide new insight into the existing methods to mitigate CO and extend CO to multi-step adversarial training. Our findings reveal a self-learning mechanism in adversarial training and open up new perspectives for suppressing different kinds of information to mitigate CO.
Fairguard: Harness Logic-based Fairness Rules in Smart Cities
Feb 23, 2023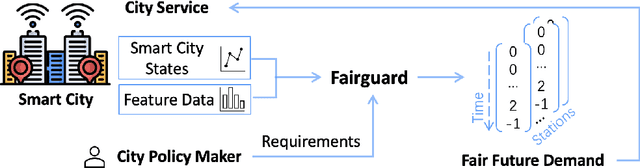

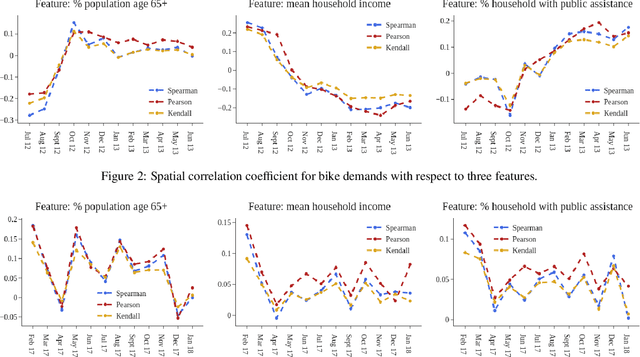
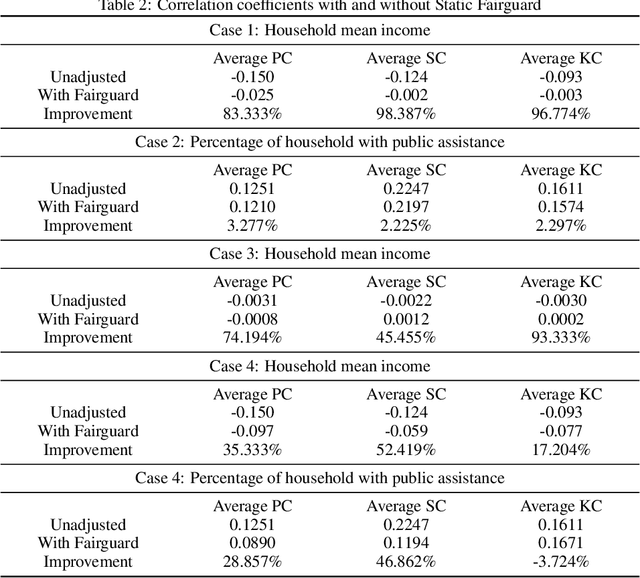
Smart cities operate on computational predictive frameworks that collect, aggregate, and utilize data from large-scale sensor networks. However, these frameworks are prone to multiple sources of data and algorithmic bias, which often lead to unfair prediction results. In this work, we first demonstrate that bias persists at a micro-level both temporally and spatially by studying real city data from Chattanooga, TN. To alleviate the issue of such bias, we introduce Fairguard, a micro-level temporal logic-based approach for fair smart city policy adjustment and generation in complex temporal-spatial domains. The Fairguard framework consists of two phases: first, we develop a static generator that is able to reduce data bias based on temporal logic conditions by minimizing correlations between selected attributes. Then, to ensure fairness in predictive algorithms, we design a dynamic component to regulate prediction results and generate future fair predictions by harnessing logic rules. Evaluations show that logic-enabled static Fairguard can effectively reduce the biased correlations while dynamic Fairguard can guarantee fairness on protected groups at run-time with minimal impact on overall performance.
A Definition of Non-Stationary Bandits
Feb 23, 2023The subject of non-stationary bandit learning has attracted much recent attention. However, non-stationary bandits lack a formal definition. Loosely speaking, non-stationary bandits have typically been characterized in the literature as those for which the reward distribution changes over time. We demonstrate that this informal definition is ambiguous. Further, a widely-used notion of regret -- the dynamic regret -- is motivated by this ambiguous definition and thus problematic. In particular, even for an optimal agent, dynamic regret can suggest poor performance. The ambiguous definition also motivates a measure of the degree of non-stationarity experienced by a bandit, which often overestimates and can give rise to extremely loose regret bounds. The primary contribution of this paper is a formal definition that resolves ambiguity. This definition motivates a new notion of regret, an alternative measure of the degree of non-stationarity, and a regret analysis that leads to tighter bounds for non-stationary bandit learning. The regret analysis applies to any bandit, stationary or non-stationary, and any agent.
pykanto: a python library to accelerate research on wild bird song
Feb 20, 2023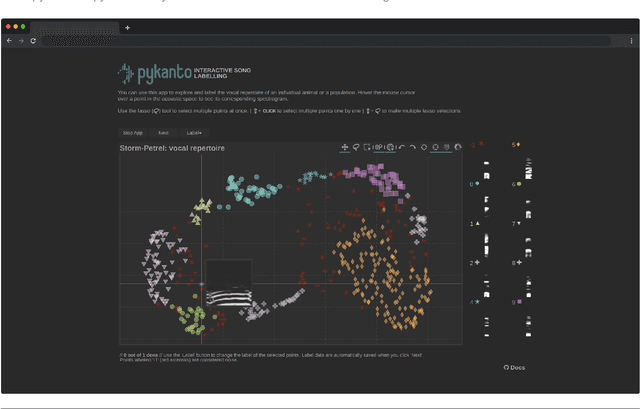

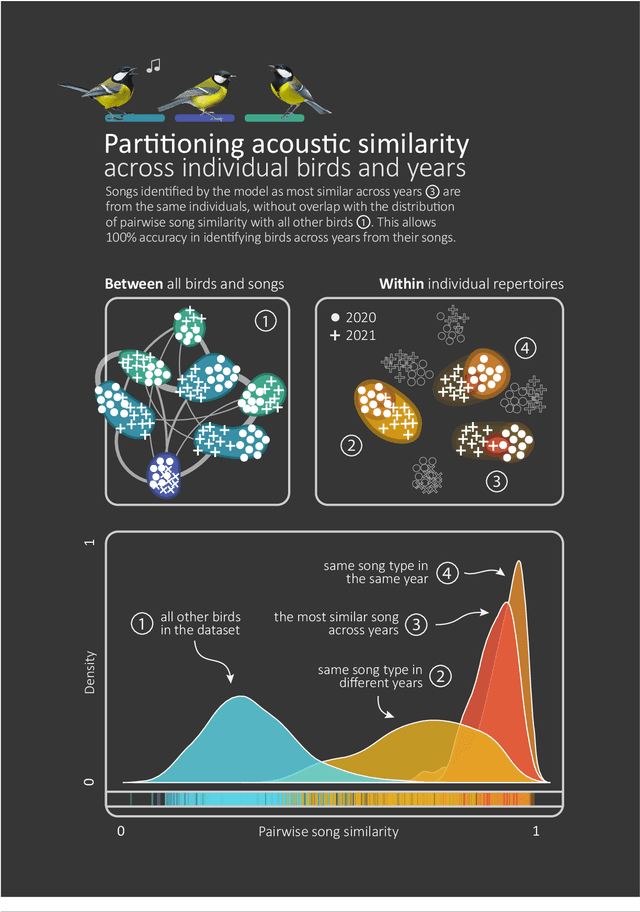
Studying the vocalisations of wild animals can be a challenge due to the limitations of traditional computational methods, which often are time-consuming and lack reproducibility. Here, I present pykanto, a new software package that provides a set of tools to build, manage, and explore large sound databases. It can automatically find discrete units in animal vocalisations, perform semi-supervised labelling of individual repertoires with a new interactive web app, and feed data to deep learning models to study things like individual signatures and acoustic similarity between individuals and populations. To demonstrate its capabilities, I put the library to the test on the vocalisations of male great tits in Wytham Woods, near Oxford, UK. The results show that the identities of individual birds can be accurately determined from their songs and that the use of pykanto improves the efficiency and reproducibility of the process.
SurvLIMEpy: A Python package implementing SurvLIME
Feb 21, 2023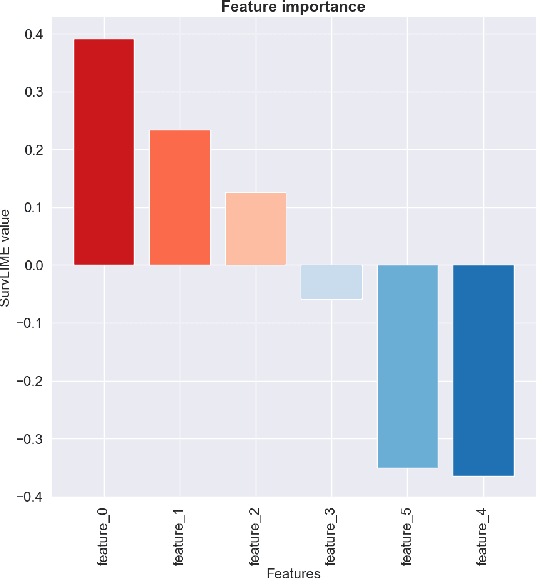
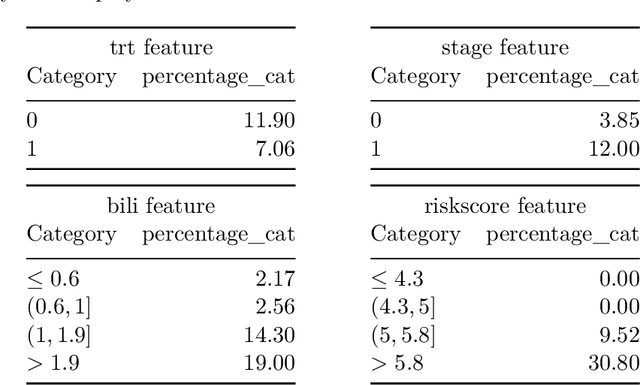
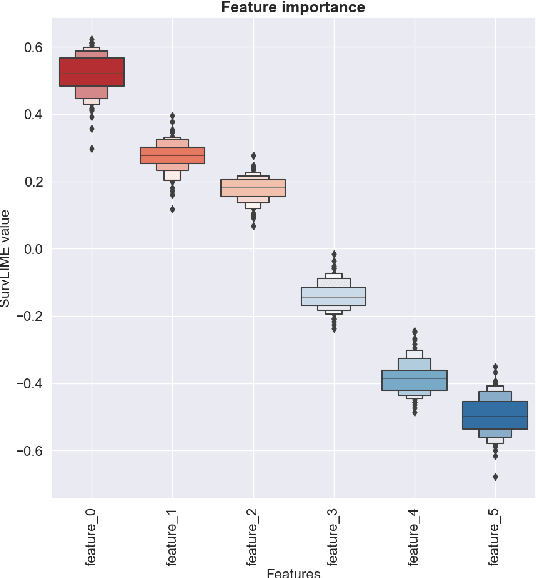
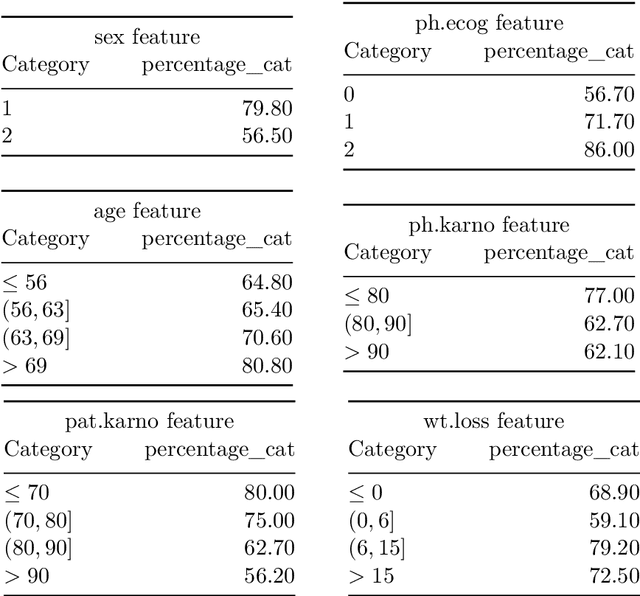
In this paper we present SurvLIMEpy, an open-source Python package that implements the SurvLIME algorithm. This method allows to compute local feature importance for machine learning algorithms designed for modelling Survival Analysis data. Our implementation takes advantage of the parallelisation paradigm as all computations are performed in a matrix-wise fashion which speeds up execution time. Additionally, SurvLIMEpy assists the user with visualization tools to better understand the result of the algorithm. The package supports a wide variety of survival models, from the Cox Proportional Hazards Model to deep learning models such as DeepHit or DeepSurv. Two types of experiments are presented in this paper. First, by means of simulated data, we study the ability of the algorithm to capture the importance of the features. Second, we use three open source survival datasets together with a set of survival algorithms in order to demonstrate how SurvLIMEpy behaves when applied to different models.
Nonparallel Emotional Voice Conversion For Unseen Speaker-Emotion Pairs Using Dual Domain Adversarial Network & Virtual Domain Pairing
Feb 21, 2023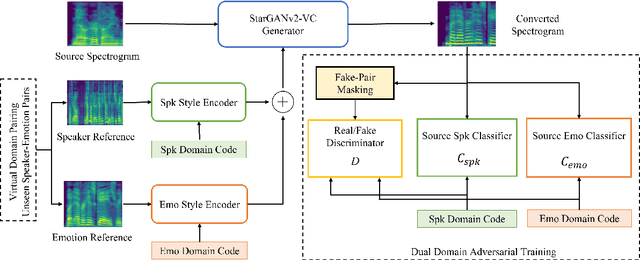
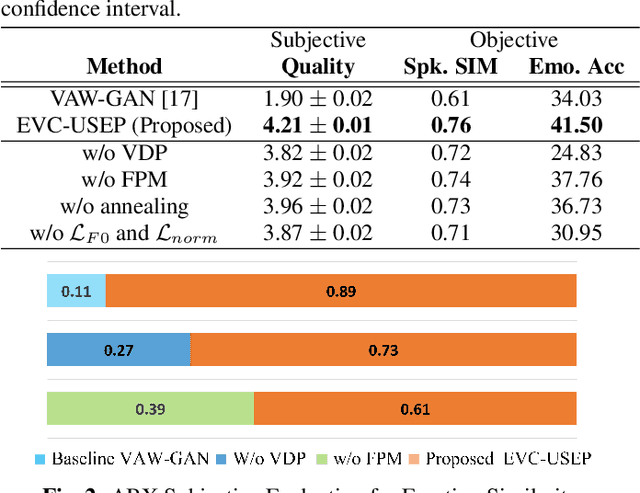
Primary goal of an emotional voice conversion (EVC) system is to convert the emotion of a given speech signal from one style to another style without modifying the linguistic content of the signal. Most of the state-of-the-art approaches convert emotions for seen speaker-emotion combinations only. In this paper, we tackle the problem of converting the emotion of speakers whose only neutral data are present during the time of training and testing (i.e., unseen speaker-emotion combinations). To this end, we extend a recently proposed StartGANv2-VC architecture by utilizing dual encoders for learning the speaker and emotion style embeddings separately along with dual domain source classifiers. For achieving the conversion to unseen speaker-emotion combinations, we propose a Virtual Domain Pairing (VDP) training strategy, which virtually incorporates the speaker-emotion pairs that are not present in the real data without compromising the min-max game of a discriminator and generator in adversarial training. We evaluate the proposed method using a Hindi emotional database.
Scalable Infomin Learning
Feb 21, 2023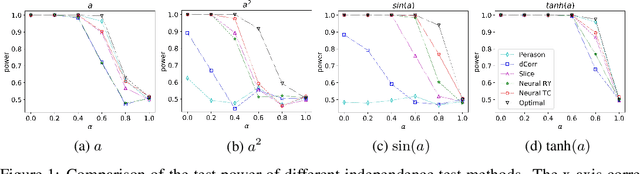


The task of infomin learning aims to learn a representation with high utility while being uninformative about a specified target, with the latter achieved by minimising the mutual information between the representation and the target. It has broad applications, ranging from training fair prediction models against protected attributes, to unsupervised learning with disentangled representations. Recent works on infomin learning mainly use adversarial training, which involves training a neural network to estimate mutual information or its proxy and thus is slow and difficult to optimise. Drawing on recent advances in slicing techniques, we propose a new infomin learning approach, which uses a novel proxy metric to mutual information. We further derive an accurate and analytically computable approximation to this proxy metric, thereby removing the need of constructing neural network-based mutual information estimators. Experiments on algorithmic fairness, disentangled representation learning and domain adaptation verify that our method can effectively remove unwanted information with limited time budget.
Assessing Domain Gap for Continual Domain Adaptation in Object Detection
Feb 21, 2023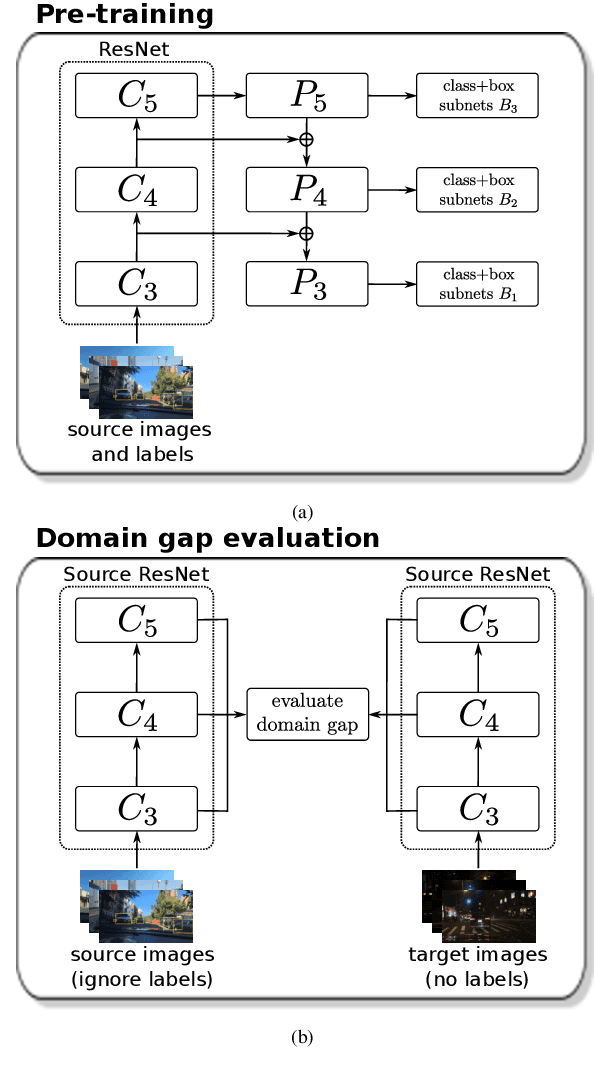

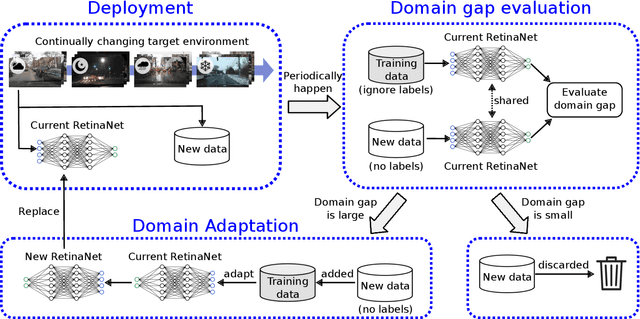
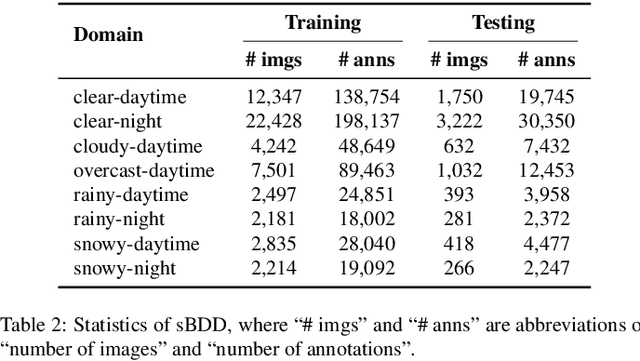
To ensure reliable object detection in autonomous systems, the detector must be able to adapt to changes in appearance caused by environmental factors such as time of day, weather, and seasons. Continually adapting the detector to incorporate these changes is a promising solution, but it can be computationally costly. Our proposed approach is to selectively adapt the detector only when necessary, using new data that does not have the same distribution as the current training data. To this end, we investigate three popular metrics for domain gap evaluation and find that there is a correlation between the domain gap and detection accuracy. Therefore, we apply the domain gap as a criterion to decide when to adapt the detector. Our experiments show that our approach has the potential to improve the efficiency of the detector's operation in real-world scenarios, where environmental conditions change in a cyclical manner, without sacrificing the overall performance of the detector. Our code is publicly available at https://github.com/dadung/DGE-CDA.