 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stable Neural Stochastic Differential Equations in Analyzing Irregular Time Series Data
Feb 22, 2024
Irregular sampling intervals and missing values in real-world time series data present challenges for conventional methods that assume consistent intervals and complete data. Neural Ordinary Differential Equations (Neural ODEs) offer an alternative approach, utilizing neural networks combined with ODE solvers to learn continuous latent representations through parameterized vector fields. Neural Stochastic Differential Equations (Neural SDEs) extend Neural ODEs by incorporating a diffusion term, although this addition is not trivial, particularly when addressing irregular intervals and missing values. Consequently, careful design of drift and diffusion functions is crucial for maintaining stability and enhancing performance, while incautious choices can result in adverse properties such as the absence of strong solutions, stochastic destabilization, or unstable Euler discretizations, significantly affecting Neural SDEs' performance. In this study, we propose three stable classes of Neural SDEs: Langevin-type SDE, Linear Noise SDE, and Geometric SDE. Then, we rigorously demonstrate their robustness in maintaining excellent performance under distribution shift, while effectively preventing overfitting. To assess the effectiveness of our approach, we conduct extensive experiments on four benchmark datasets for interpolation, forecasting, and classification tasks, and analyze the robustness of our methods with 30 public datasets under different missing rates. Our results demonstrate the efficacy of the proposed method in handling real-world irregular time series data.
A Framework for Controlling Multiple Industrial Robots using Mobile Applications
Mar 12, 2024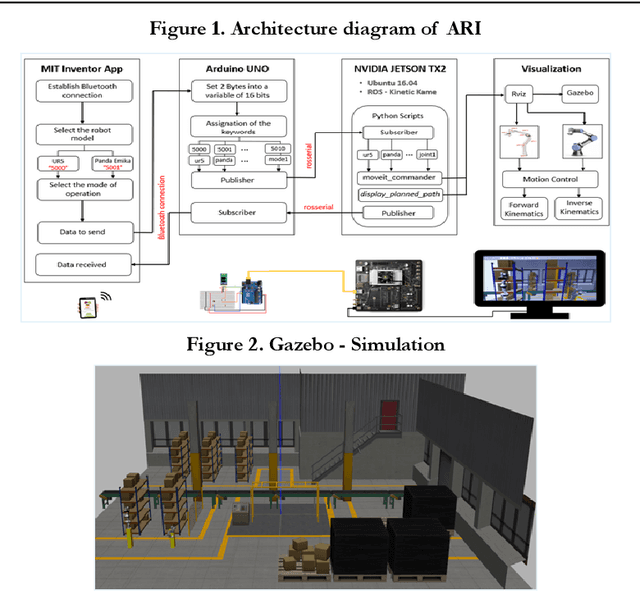
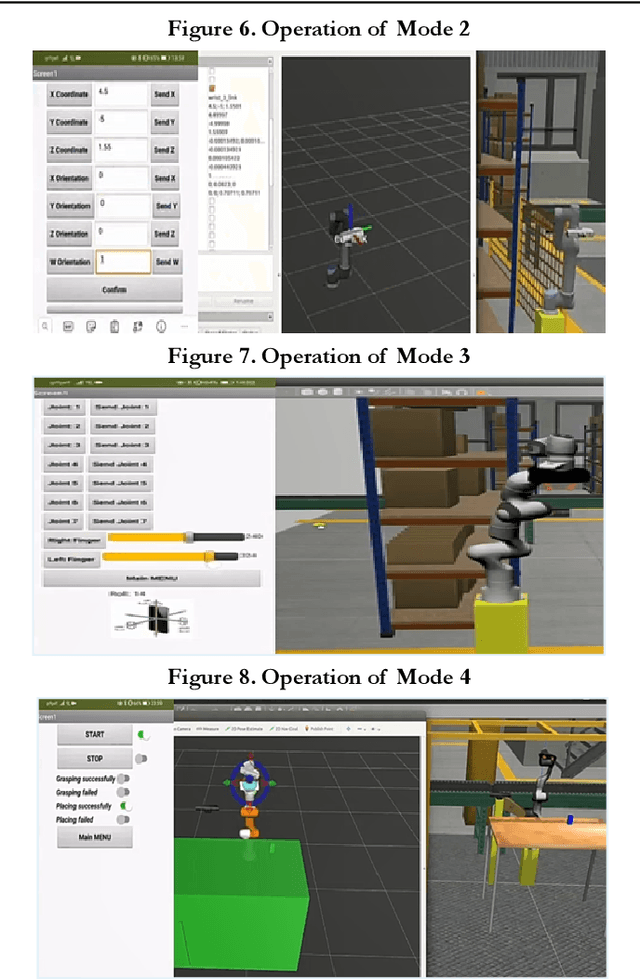
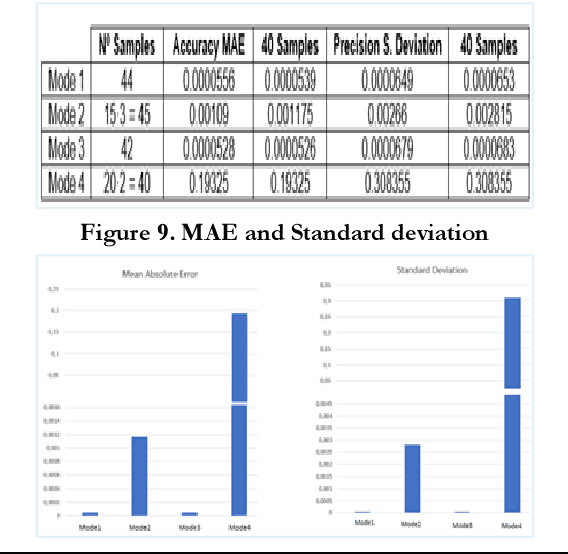
Purpose: Over the last few decades, the development of the hardware and software has enabled the application of advanced systems. In the robotics field, the UI design is an intriguing area to be explored due to the creation of devices with a wide range of functionalities in a reduced size. Moreover, the idea of using the same UI to control several systems arouses a great interest considering that this involves less learning effort and time for the users. Therefore, this paper will present a mobile application to control two industrial robots with four modes of operation. Design/methodology/approach: The smartphone was selected to be the interface due to its wide range of capabilities and the MIT Inventor App was used to create the application, whose environment is supported by Android smartphones. For the validation, ROS was used since it is a fundamental framework utilised in industrial robotics and the Arduino Uno was used to establish the data transmission between the smartphone and the board NVIDIA Jetson TX2. In MIT Inventor App, the graphical interface was created to visualize the options available in the app whereas two scripts in python were programmed to perform the simulations in ROS and carry out the tests. Findings: The results indicated that the use of the sliders to control the robots is more favourable than the Orientation Sensor due to the sensibility of the sensor and human limitations to hold the smartphone perfectly still. Another important finding was the limitations of the autonomous mode, in which the robot grabs an object. In this case, the configuration of the Kinect camera and the controllers has a significant impact on the success of the simulation. Finally, it was observed that the delay was appropriate despite the use of the Arduino UNO to transfer the data between the Smartphone and the Nvidia Jetson TX2.
Vision-based Vehicle Re-identification in Bridge Scenario using Flock Similarity
Mar 12, 2024


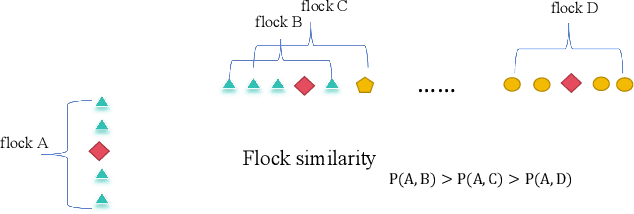
Due to the needs of road traffic flow monitoring and public safety management, video surveillance cameras are widely distributed in urban roads. However, the information captured directly by each camera is siloed, making it difficult to use it effectively. Vehicle re-identification refers to finding a vehicle that appears under one camera in another camera, which can correlate the information captured by multiple cameras. While license plate recognition plays an important role in some applications, there are some scenarios where re-identification method based on vehicle appearance are more suitable. The main challenge is that the data of vehicle appearance has the characteristics of high inter-class similarity and large intra-class differences. Therefore, it is difficult to accurately distinguish between different vehicles by relying only on vehicle appearance information. At this time, it is often necessary to introduce some extra information, such as spatio-temporal information. Nevertheless, the relative position of the vehicles rarely changes when passing through two adjacent cameras in the bridge scenario. In this paper, we present a vehicle re-identification method based on flock similarity, which improves the accuracy of vehicle re-identification by utilizing vehicle information adjacent to the target vehicle. When the relative position of the vehicles remains unchanged and flock size is appropriate, we obtain an average relative improvement of 204% on VeRi dataset in our experiments. Then, the effect of the magnitude of the relative position change of the vehicles as they pass through two cameras is discussed. We present two metrics that can be used to quantify the difference and establish a connection between them. Although this assumption is based on the bridge scenario, it is often true in other scenarios due to driving safety and camera location.
METAMAT 01: A semi-analytic Solution for Benchmarking Wave Propagation Simulations of homogeneous Absorbers in 1D/3D and 2D
Mar 06, 2024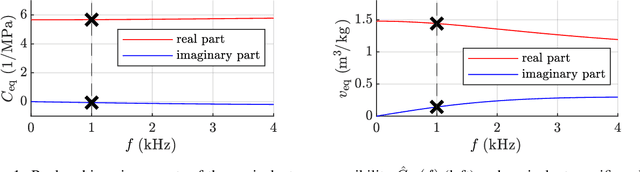

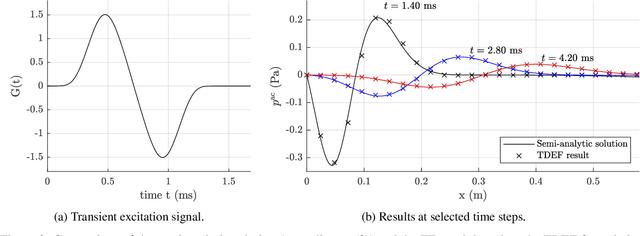
The development of acoustic simulation workflows in the time-domain description is essential for predicting the sound of aeroacoustic or other transient acoustic effects. A common practice for noise mitigation is using absorbers. The modeling of these acoustic absorbers is typically provided in the frequency domain. Several, methods established bridging this gap, investigating methods to model absorber in the time domain. Therefore, this short article, describes the analytic solution in time-domain for benchmarking absorber simulations with infinite 1D, 2D, and 3D domains. Connected to the analytic solution, a Matlab script is provided to easily obtain the reference solution. The reference codes are provided as benchmark solution in the EAA TCCA Benchmarking database as METAMAT 01.
MKF-ADS: A Multi-Knowledge Fused Anomaly Detection System for Automotive
Mar 07, 2024
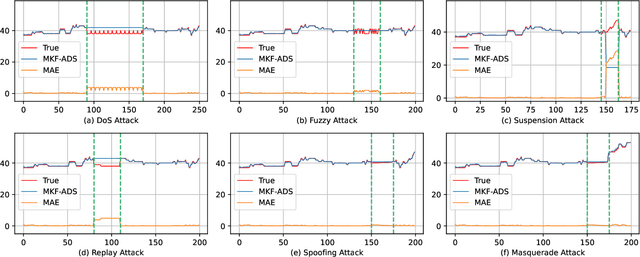
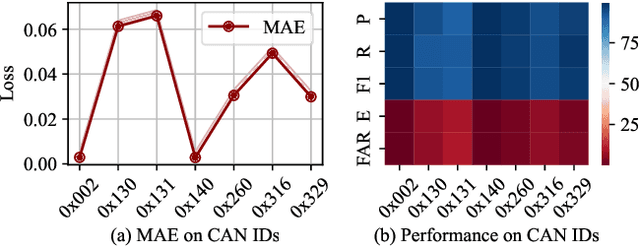
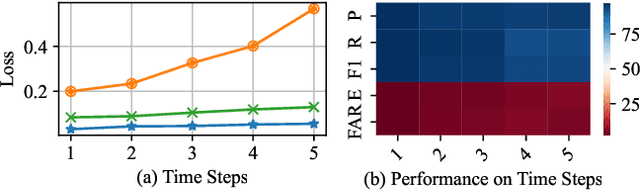
With the requirements of Intelligent Transport Systems (ITSs) for extensive connectivity of Electronic Control Units (ECUs) to the outside world, safety and security have become stringent problems. Intrusion detection systems (IDSs) are a crucial safety component in remediating Controller Area Network (CAN) bus vulnerabilities. However, supervised-based IDSs fail to identify complexity attacks and anomaly-based IDSs have higher false alarms owing to capability bottleneck. In this paper, we propose a novel multi-knowledge fused anomaly detection model, called MKF-IDS. Specifically, the method designs an integration framework, including spatial-temporal correlation with an attention mechanism (STcAM) module and patch sparse-transformer module (PatchST). The STcAM with fine-pruning uses one-dimensional convolution (Conv1D) to extract spatial features and subsequently utilizes the Bidirectional Long Short Term Memory (Bi-LSTM) to extract the temporal features, where the attention mechanism will focus on the important time steps. Meanwhile, the PatchST captures the combined long-time historical features from independent univariate time series. Finally, the proposed method is based on knowledge distillation to STcAM as a student model for learning intrinsic knowledge and cross the ability to mimic PatchST. In the detection phase, the MKF-ADS only deploys STcAM to maintain efficiency in a resource-limited IVN environment. Moreover, the redundant noisy signal is reduced with bit flip rate and boundary decision estimation. We conduct extensive experiments on six simulation attack scenarios across various CAN IDs and time steps, and two real attack scenarios, which present a competitive prediction and detection performance. Compared with the baseline in the same paradigm, the error rate and FAR are 2.62% and 2.41% and achieve a promising F1-score of 97.3%.
Automated Testing of Spatially-Dependent Environmental Hypotheses through Active Transfer Learning
Mar 07, 2024The efficient collection of samples is an important factor in outdoor information gathering applications on account of high sampling costs such as time, energy, and potential destruction to the environment. Utilization of available a-priori data can be a powerful tool for increasing efficiency. However, the relationships of this data with the quantity of interest are often not known ahead of time, limiting the ability to leverage this knowledge for improved planning efficiency. To this end, this work combines transfer learning and active learning through a Multi-Task Gaussian Process and an information-based objective function. Through this combination it can explore the space of hypothetical inter-quantity relationships and evaluate these hypotheses in real-time, allowing this new knowledge to be immediately exploited for future plans. The performance of the proposed method is evaluated against synthetic data and is shown to evaluate multiple hypotheses correctly. Its effectiveness is also demonstrated on real datasets. The technique is able to identify and leverage hypotheses which show a medium or strong correlation to reduce prediction error by a factor of 1.4--3.4 within the first 7 samples, and poor hypotheses are quickly identified and rejected eventually having no adverse effect.
Fine-Grained Pillar Feature Encoding Via Spatio-Temporal Virtual Grid for 3D Object Detection
Mar 11, 2024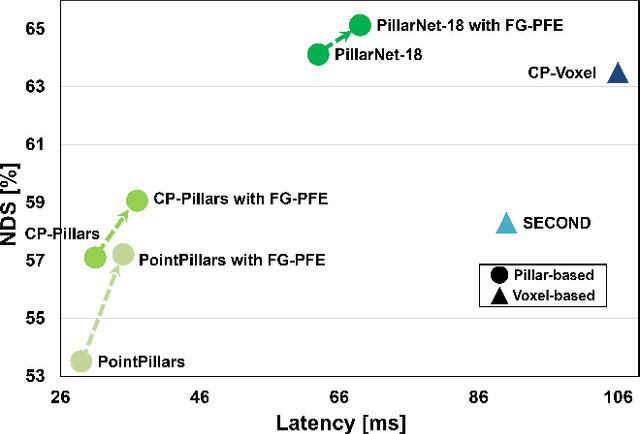
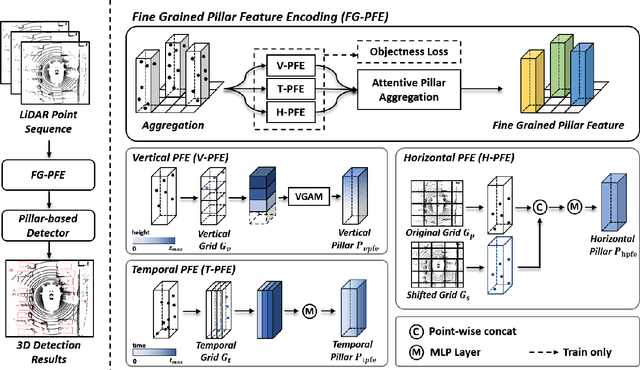
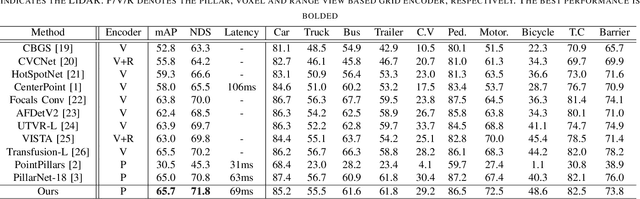
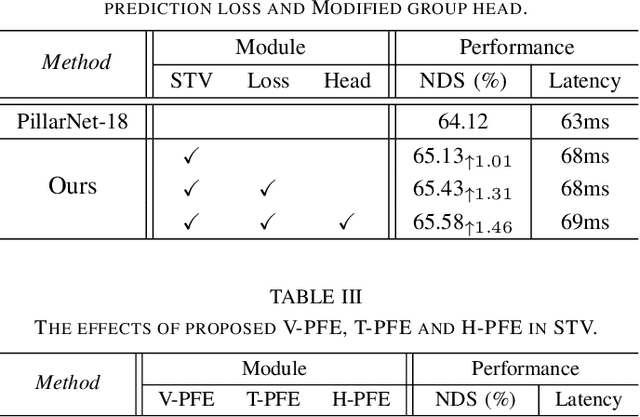
Developing high-performance, real-time architectures for LiDAR-based 3D object detectors is essential for the successful commercialization of autonomous vehicles. Pillar-based methods stand out as a practical choice for onboard deployment due to their computational efficiency. However, despite their efficiency, these methods can sometimes underperform compared to alternative point encoding techniques such as Voxel-encoding or PointNet++. We argue that current pillar-based methods have not sufficiently captured the fine-grained distributions of LiDAR points within each pillar structure. Consequently, there exists considerable room for improvement in pillar feature encoding. In this paper, we introduce a novel pillar encoding architecture referred to as Fine-Grained Pillar Feature Encoding (FG-PFE). FG-PFE utilizes Spatio-Temporal Virtual (STV) grids to capture the distribution of point clouds within each pillar across vertical, temporal, and horizontal dimensions. Through STV grids, points within each pillar are individually encoded using Vertical PFE (V-PFE), Temporal PFE (T-PFE), and Horizontal PFE (H-PFE). These encoded features are then aggregated through an Attentive Pillar Aggregation method. Our experiments conducted on the nuScenes dataset demonstrate that FG-PFE achieves significant performance improvements over baseline models such as PointPillar, CenterPoint-Pillar, and PillarNet, with only a minor increase in computational overhead.
Estimating Neural Network Performance through Sample-Wise Activation Patterns
Mar 11, 2024
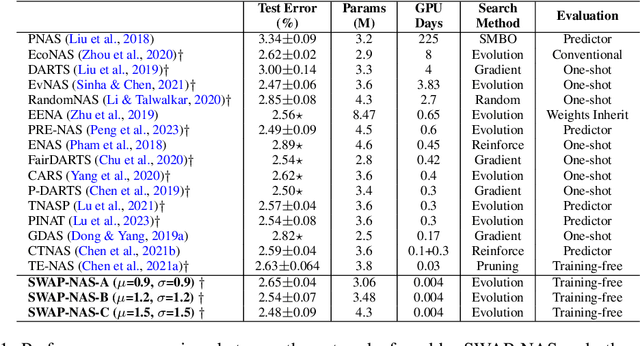

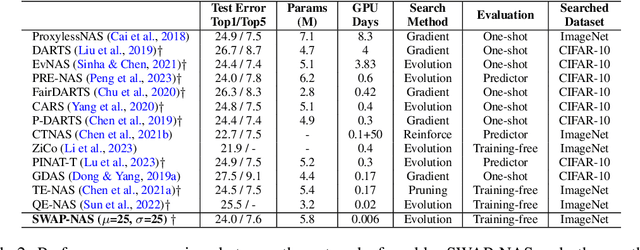
Training-free metrics (a.k.a. zero-cost proxies) are widely used to avoid resource-intensive neural network training, especially in Neural Architecture Search (NAS). Recent studies show that existing training-free metrics have several limitations, such as limited correlation and poor generalisation across different search spaces and tasks. Hence, we propose Sample-Wise Activation Patterns and its derivative, SWAP-Score, a novel high-performance training-free metric. It measures the expressivity of networks over a batch of input samples. The SWAP-Score is strongly correlated with ground-truth performance across various search spaces and tasks, outperforming 15 existing training-free metrics on NAS-Bench-101/201/301 and TransNAS-Bench-101. The SWAP-Score can be further enhanced by regularisation, which leads to even higher correlations in cell-based search space and enables model size control during the search. For example, Spearman's rank correlation coefficient between regularised SWAP-Score and CIFAR-100 validation accuracies on NAS-Bench-201 networks is 0.90, significantly higher than 0.80 from the second-best metric, NWOT. When integrated with an evolutionary algorithm for NAS, our SWAP-NAS achieves competitive performance on CIFAR-10 and ImageNet in approximately 6 minutes and 9 minutes of GPU time respectively.
Multiple Population Alternate Evolution Neural Architecture Search
Mar 11, 2024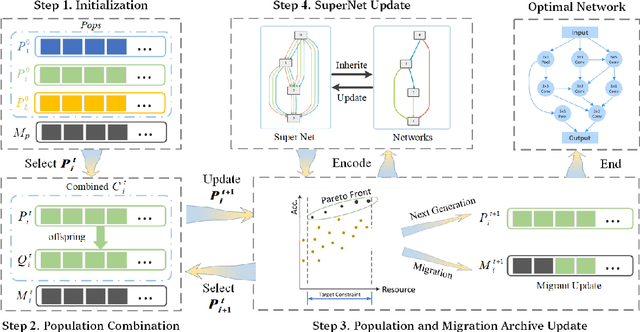
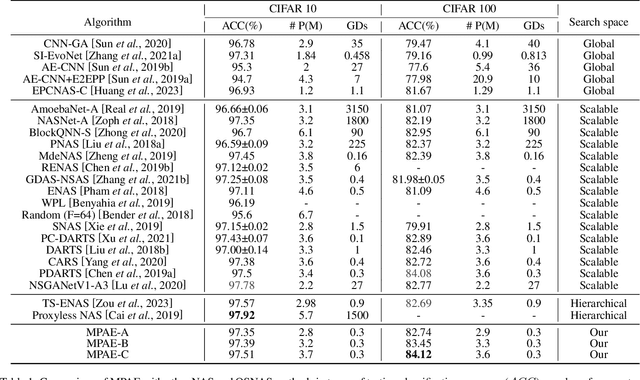
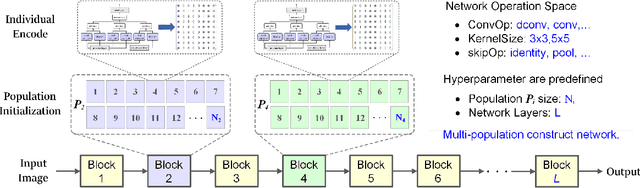
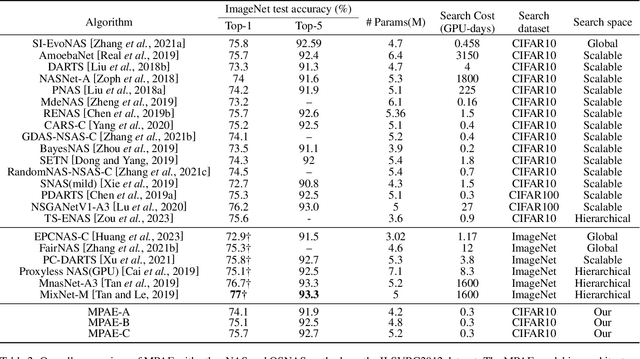
The effectiveness of Evolutionary Neural Architecture Search (ENAS) is influenced by the design of the search space. Nevertheless, common methods including the global search space, scalable search space and hierarchical search space have certain limitations. Specifically, the global search space requires a significant amount of computational resources and time, the scalable search space sacrifices the diversity of network structures and the hierarchical search space increases the search cost in exchange for network diversity. To address above limitation, we propose a novel paradigm of searching neural network architectures and design the Multiple Population Alternate Evolution Neural Architecture Search (MPAE), which can achieve module diversity with a smaller search cost. MPAE converts the search space into L interconnected units and sequentially searches the units, then the above search of the entire network be cycled several times to reduce the impact of previous units on subsequent units. To accelerate the population evolution process, we also propose the the population migration mechanism establishes an excellent migration archive and transfers the excellent knowledge and experience in the migration archive to new populations. The proposed method requires only 0.3 GPU days to search a neural network on the CIFAR dataset and achieves the state-of-the-art results.
Eliminating Warping Shakes for Unsupervised Online Video Stitching
Mar 11, 2024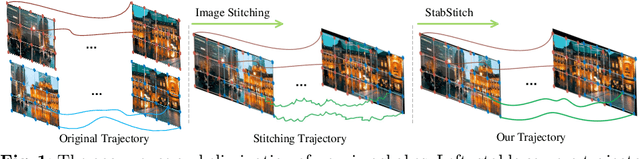

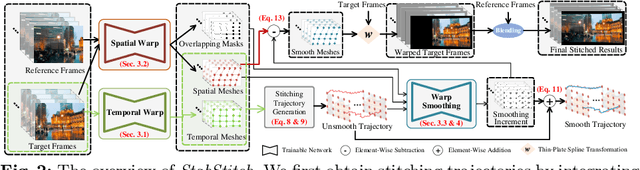

In this paper, we retarget video stitching to an emerging issue, named warping shake, when extending image stitching to video stitching. It unveils the temporal instability of warped content in non-overlapping regions, despite image stitching having endeavored to preserve the natural structures. Therefore, in most cases, even if the input videos to be stitched are stable, the stitched video will inevitably cause undesired warping shakes and affect the visual experience. To eliminate the shakes, we propose StabStitch to simultaneously realize video stitching and video stabilization in a unified unsupervised learning framework. Starting from the camera paths in video stabilization, we first derive the expression of stitching trajectories in video stitching by elaborately integrating spatial and temporal warps. Then a warp smoothing model is presented to optimize them with a comprehensive consideration regarding content alignment, trajectory smoothness, spatial consistency, and online collaboration. To establish an evaluation benchmark and train the learning framework, we build a video stitching dataset with a rich diversity in camera motions and scenes. Compared with existing stitching solutions, StabStitch exhibits significant superiority in scene robustness and inference speed in addition to stitching and stabilization performance, contributing to a robust and real-time online video stitching system. The code and dataset will be available at https://github.com/nie-lang/StabStitch.