 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-teacher knowledge distillation as an effective method for compressing ensembles of neural networks
Feb 14, 2023
Deep learning has contributed greatly to many successes in artificial intelligence in recent years. Today, it is possible to train models that have thousands of layers and hundreds of billions of parameters. Large-scale deep models have achieved great success, but the enormous computational complexity and gigantic storage requirements make it extremely difficult to implement them in real-time applications. On the other hand, the size of the dataset is still a real problem in many domains. Data are often missing, too expensive, or impossible to obtain for other reasons. Ensemble learning is partially a solution to the problem of small datasets and overfitting. However, ensemble learning in its basic version is associated with a linear increase in computational complexity. We analyzed the impact of the ensemble decision-fusion mechanism and checked various methods of sharing the decisions including voting algorithms. We used the modified knowledge distillation framework as a decision-fusion mechanism which allows in addition compressing of the entire ensemble model into a weight space of a single model. We showed that knowledge distillation can aggregate knowledge from multiple teachers in only one student model and, with the same computational complexity, obtain a better-performing model compared to a model trained in the standard manner. We have developed our own method for mimicking the responses of all teachers at the same time, simultaneously. We tested these solutions on several benchmark datasets. In the end, we presented a wide application use of the efficient multi-teacher knowledge distillation framework. In the first example, we used knowledge distillation to develop models that could automate corrosion detection on aircraft fuselage. The second example describes detection of smoke on observation cameras in order to counteract wildfires in forests.
DAMO-YOLO : A Report on Real-Time Object Detection Design
Dec 15, 2022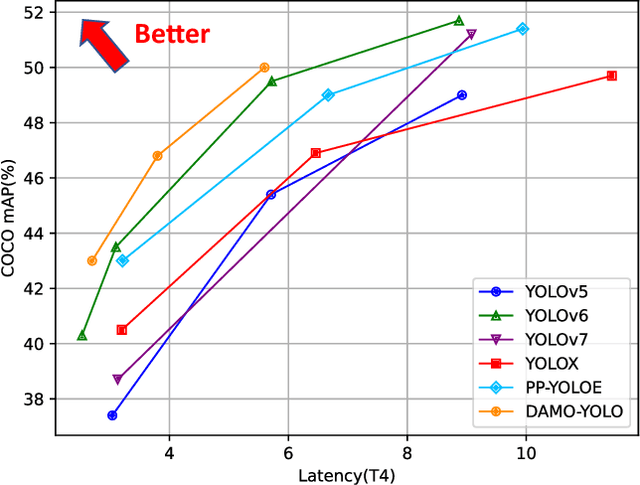
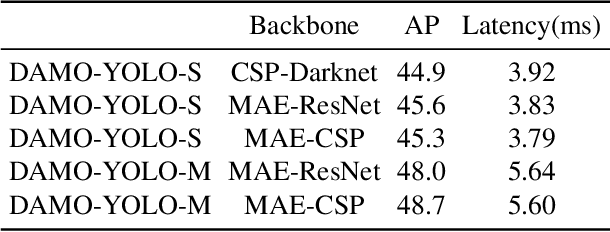
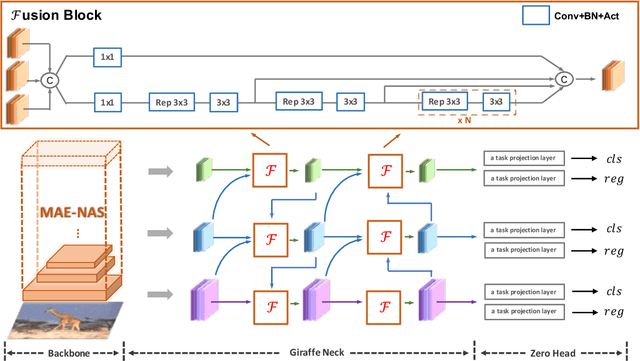
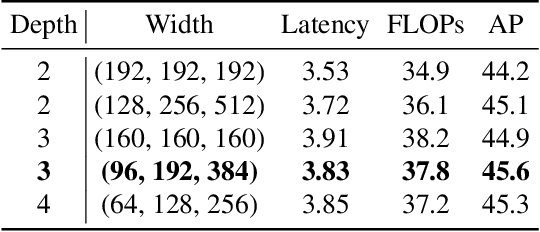
In this report, we present a fast and accurate object detection method dubbed DAMO-YOLO, which achieves higher performance than the state-of-the-art YOLO series. DAMO-YOLO is extended from YOLO with some new technologies, including Neural Architecture Search (NAS), efficient Reparameterized Generalized-FPN (RepGFPN), a lightweight head with AlignedOTA label assignment, and distillation enhancement. In particular, we use MAE-NAS, a method guided by the principle of maximum entropy, to search our detection backbone under the constraints of low latency and high performance, producing ResNet-like / CSP-like structures with spatial pyramid pooling and focus modules. In the design of necks and heads, we follow the rule of "large neck, small head". We import Generalized-FPN with accelerated queen-fusion to build the detector neck and upgrade its CSPNet with efficient layer aggregation networks (ELAN) and reparameterization. Then we investigate how detector head size affects detection performance and find that a heavy neck with only one task projection layer would yield better results. In addition, AlignedOTA is proposed to solve the misalignment problem in label assignment. And a distillation schema is introduced to improve performance to a higher level. Based on these new techs, we build a suite of models at various scales to meet the needs of different scenarios, i.e., DAMO-YOLO-Tiny/Small/Medium. They can achieve 43.0/46.8/50.0 mAPs on COCO with the latency of 2.78/3.83/5.62 ms on T4 GPUs respectively. The code is available at https://github.com/tinyvision/damo-yolo.
Finding Things in the Unknown: Semantic Object-Centric Exploration with an MAV
Feb 28, 2023
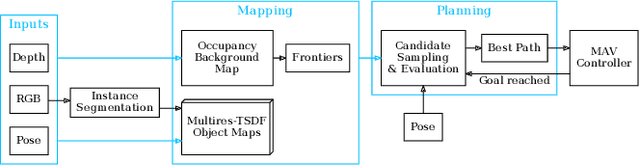
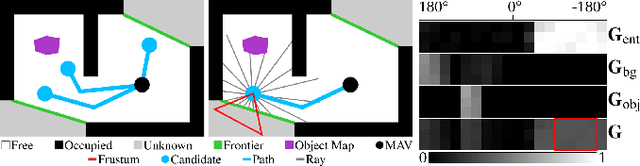

Exploration of unknown space with an autonomous mobile robot is a well-studied problem. In this work we broaden the scope of exploration, moving beyond the pure geometric goal of uncovering as much free space as possible. We believe that for many practical applications, exploration should be contextualised with semantic and object-level understanding of the environment for task-specific exploration. Here, we study the task of both finding specific objects in unknown space as well as reconstructing them to a target level of detail. We therefore extend our environment reconstruction to not only consist of a background map, but also object-level and semantically fused submaps. Importantly, we adapt our previous objective function of uncovering as much free space as possible in as little time as possible with two additional elements: first, we require a maximum observation distance of background surfaces to ensure target objects are not missed by image-based detectors because they are too small to be detected. Second, we require an even smaller maximum distance to the found objects in order to reconstruct them with the desired accuracy. We further created a Micro Aerial Vehicle (MAV) semantic exploration simulator based on Habitat in order to quantitatively demonstrate how our framework can be used to efficiently find specific objects as part of exploration. Finally, we showcase this capability can be deployed in real-world scenes involving our drone equipped with an Intel RealSense D455 RGB-D camera.
WISK: A Workload-aware Learned Index for Spatial Keyword Queries
Feb 28, 2023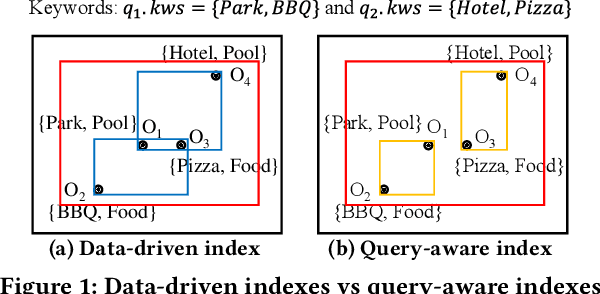
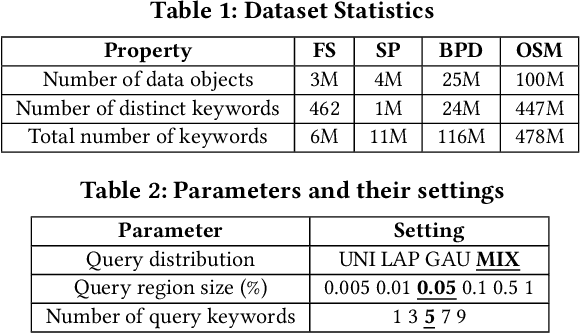
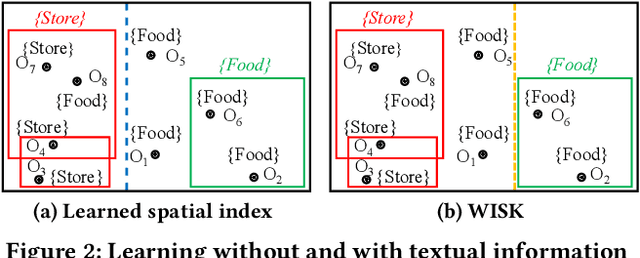
Spatial objects often come with textual information, such as Points of Interest (POIs) with their descriptions, which are referred to as geo-textual data. To retrieve such data, spatial keyword queries that take into account both spatial proximity and textual relevance have been extensively studied. Existing indexes designed for spatial keyword queries are mostly built based on the geo-textual data without considering the distribution of queries already received. However, previous studies have shown that utilizing the known query distribution can improve the index structure for future query processing. In this paper, we propose WISK, a learned index for spatial keyword queries, which self-adapts for optimizing querying costs given a query workload. One key challenge is how to utilize both structured spatial attributes and unstructured textual information during learning the index. We first divide the data objects into partitions, aiming to minimize the processing costs of the given query workload. We prove the NP-hardness of the partitioning problem and propose a machine learning model to find the optimal partitions. Then, to achieve more pruning power, we build a hierarchical structure based on the generated partitions in a bottom-up manner with a reinforcement learning-based approach. We conduct extensive experiments on real-world datasets and query workloads with various distributions, and the results show that WISK outperforms all competitors, achieving up to 8x speedup in querying time with comparable storage overhead.
Distributed Subweb Specifications for Traversing the Web
Feb 28, 2023
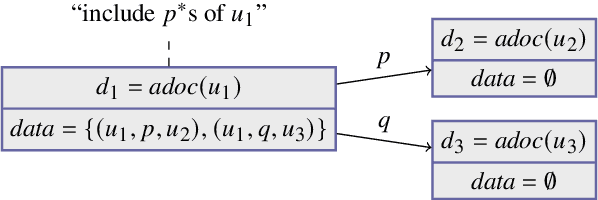
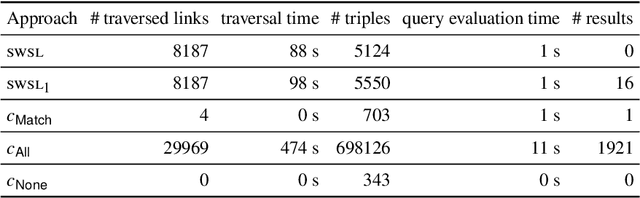
Link Traversal-based Query Processing (ltqp), in which a sparql query is evaluated over a web of documents rather than a single dataset, is often seen as a theoretically interesting yet impractical technique. However, in a time where the hypercentralization of data has increasingly come under scrutiny, a decentralized Web of Data with a simple document-based interface is appealing, as it enables data publishers to control their data and access rights. While ltqp allows evaluating complex queries over such webs, it suffers from performance issues (due to the high number of documents containing data) as well as information quality concerns (due to the many sources providing such documents). In existing ltqp approaches, the burden of finding sources to query is entirely in the hands of the data consumer. In this paper, we argue that to solve these issues, data publishers should also be able to suggest sources of interest and guide the data consumer towards relevant and trustworthy data. We introduce a theoretical framework that enables such guided link traversal and study its properties. We illustrate with a theoretic example that this can improve query results and reduce the number of network requests. We evaluate our proposal experimentally on a virtual linked web with specifications and indeed observe that not just the data quality but also the efficiency of querying improves. Under consideration in Theory and Practice of Logic Programming (TPLP).
KDEformer: Accelerating Transformers via Kernel Density Estimation
Feb 05, 2023


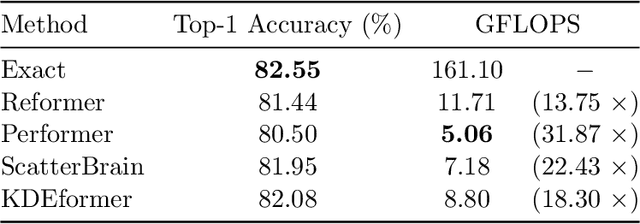
Dot-product attention mechanism plays a crucial role in modern deep architectures (e.g., Transformer) for sequence modeling, however, na\"ive exact computation of this model incurs quadratic time and memory complexities in sequence length, hindering the training of long-sequence models. Critical bottlenecks are due to the computation of partition functions in the denominator of softmax function as well as the multiplication of the softmax matrix with the matrix of values. Our key observation is that the former can be reduced to a variant of the kernel density estimation (KDE) problem, and an efficient KDE solver can be further utilized to accelerate the latter via subsampling-based fast matrix products. Our proposed KDEformer can approximate the attention in sub-quadratic time with provable spectral norm bounds, while all prior results merely provide entry-wise error bounds. Empirically, we verify that KDEformer outperforms other attention approximations in terms of accuracy, memory, and runtime on various pre-trained models. On BigGAN image generation, we achieve better generative scores than the exact computation with over $4\times$ speedup. For ImageNet classification with T2T-ViT, KDEformer shows over $18\times$ speedup while the accuracy drop is less than $0.5\%$.
A Unified Framework for Soft Threshold Pruning
Feb 25, 2023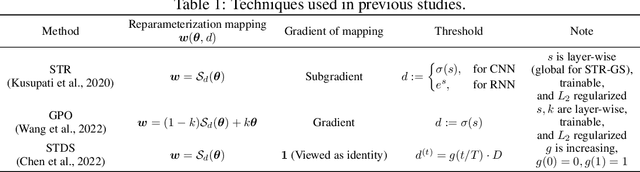
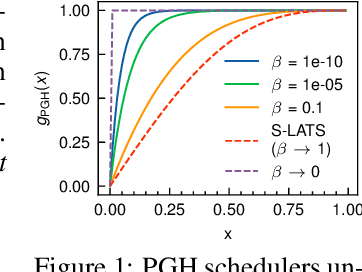

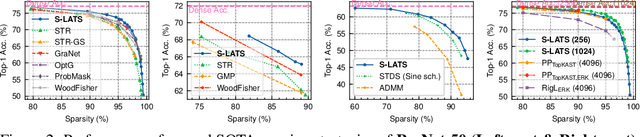
Soft threshold pruning is among the cutting-edge pruning methods with state-of-the-art performance. However, previous methods either perform aimless searching on the threshold scheduler or simply set the threshold trainable, lacking theoretical explanation from a unified perspective. In this work, we reformulate soft threshold pruning as an implicit optimization problem solved using the Iterative Shrinkage-Thresholding Algorithm (ISTA), a classic method from the fields of sparse recovery and compressed sensing. Under this theoretical framework, all threshold tuning strategies proposed in previous studies of soft threshold pruning are concluded as different styles of tuning $L_1$-regularization term. We further derive an optimal threshold scheduler through an in-depth study of threshold scheduling based on our framework. This scheduler keeps $L_1$-regularization coefficient stable, implying a time-invariant objective function from the perspective of optimization. In principle, the derived pruning algorithm could sparsify any mathematical model trained via SGD. We conduct extensive experiments and verify its state-of-the-art performance on both Artificial Neural Networks (ResNet-50 and MobileNet-V1) and Spiking Neural Networks (SEW ResNet-18) on ImageNet datasets. On the basis of this framework, we derive a family of pruning methods, including sparsify-during-training, early pruning, and pruning at initialization. The code is available at https://github.com/Yanqi-Chen/LATS.
DeepBrainPrint: A Novel Contrastive Framework for Brain MRI Re-Identification
Feb 25, 2023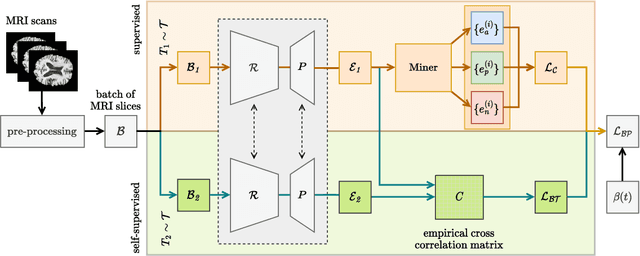
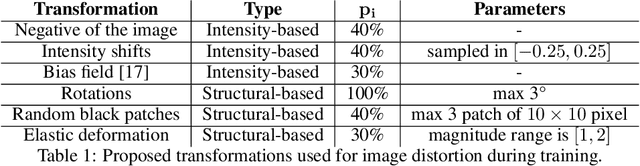
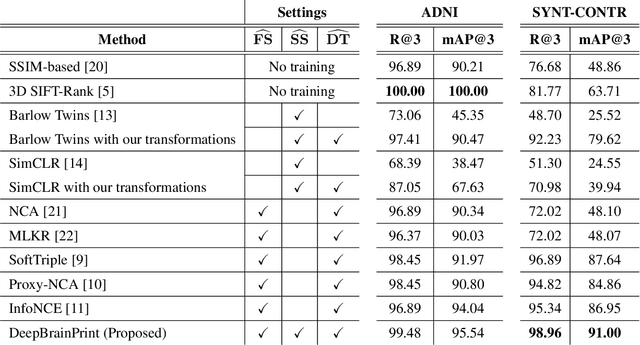
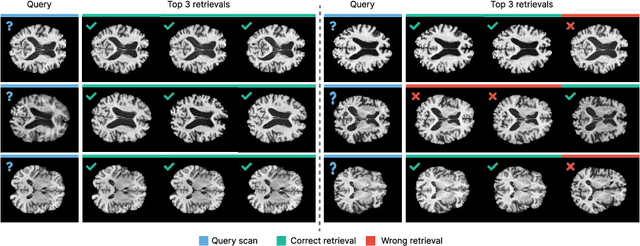
Recent advances in MRI have led to the creation of large datasets. With the increase in data volume, it has become difficult to locate previous scans of the same patient within these datasets (a process known as re-identification). To address this issue, we propose an AI-powered medical imaging retrieval framework called DeepBrainPrint, which is designed to retrieve brain MRI scans of the same patient. Our framework is a semi-self-supervised contrastive deep learning approach with three main innovations. First, we use a combination of self-supervised and supervised paradigms to create an effective brain fingerprint from MRI scans that can be used for real-time image retrieval. Second, we use a special weighting function to guide the training and improve model convergence. Third, we introduce new imaging transformations to improve retrieval robustness in the presence of intensity variations (i.e. different scan contrasts), and to account for age and disease progression in patients. We tested DeepBrainPrint on a large dataset of T1-weighted brain MRIs from the Alzheimer's Disease Neuroimaging Initiative (ADNI) and on a synthetic dataset designed to evaluate retrieval performance with different image modalities. Our results show that DeepBrainPrint outperforms previous methods, including simple similarity metrics and more advanced contrastive deep learning frameworks.
Feasibility and Transferability of Transfer Learning: A Mathematical Framework
Jan 27, 2023
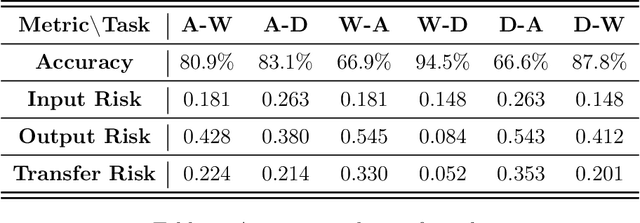
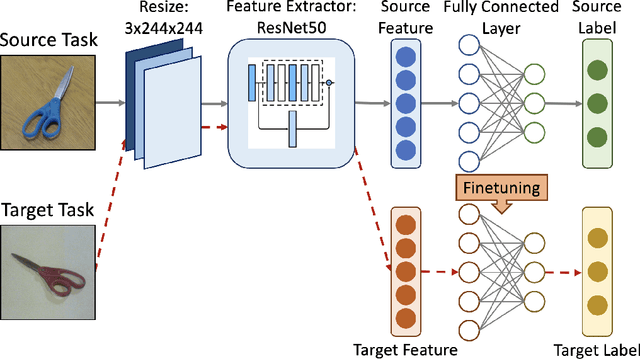
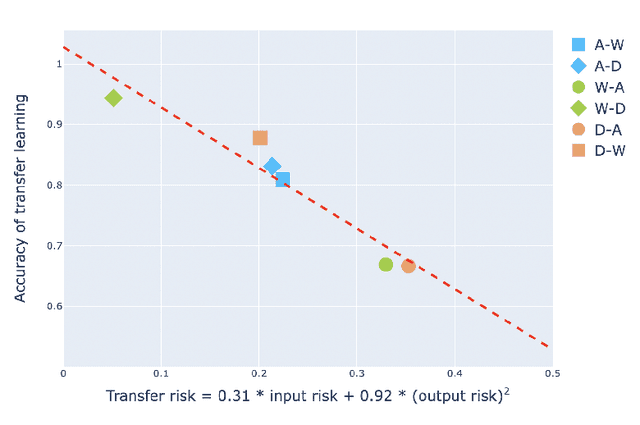
Transfer learning is an emerging and popular paradigm for utilizing existing knowledge from previous learning tasks to improve the performance of new ones. Despite its numerous empirical successes, theoretical analysis for transfer learning is limited. In this paper we build for the first time, to the best of our knowledge, a mathematical framework for the general procedure of transfer learning. Our unique reformulation of transfer learning as an optimization problem allows for the first time, analysis of its feasibility. Additionally, we propose a novel concept of transfer risk to evaluate transferability of transfer learning. Our numerical studies using the Office-31 dataset demonstrate the potential and benefits of incorporating transfer risk in the evaluation of transfer learning performance.
Koopman Operator Learning: Sharp Spectral Rates and Spurious Eigenvalues
Feb 03, 2023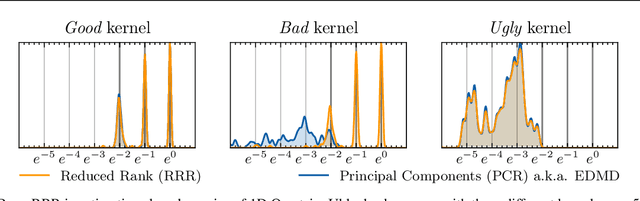
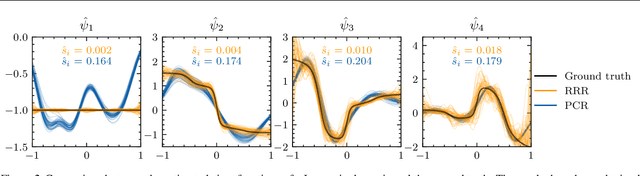
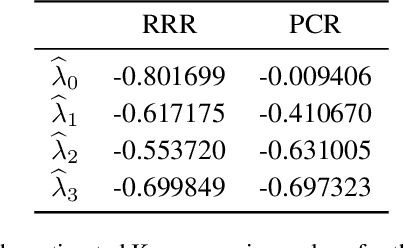
Non-linear dynamical systems can be handily described by the associated Koopman operator, whose action evolves every observable of the system forward in time. Learning the Koopman operator from data is enabled by a number of algorithms. In this work we present nonasymptotic learning bounds for the Koopman eigenvalues and eigenfunctions estimated by two popular algorithms: Extended Dynamic Mode Decomposition (EDMD) and Reduced Rank Regression (RRR). We focus on time-reversal-invariant Markov chains, implying that the Koopman operator is self-adjoint. This includes important examples of stochastic dynamical systems, notably Langevin dynamics. Our spectral learning bounds are driven by the simultaneous control of the operator norm risk of the estimators and a metric distortion associated to the corresponding eigenfunctions. Our analysis indicates that both algorithms have similar variance, but EDMD suffers from a larger bias which might be detrimental to its learning rate. We further argue that a large metric distortion may lead to spurious eigenvalues, a phenomenon which has been empirically observed, and note that metric distortion can be estimated from data. Numerical experiments complement the theoretical findings.