 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts
Mar 08, 2024
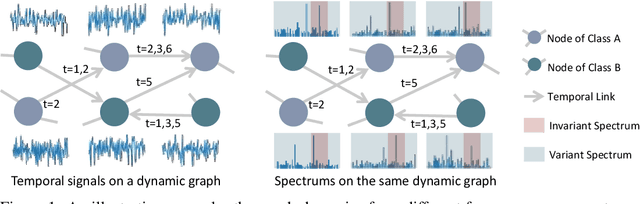
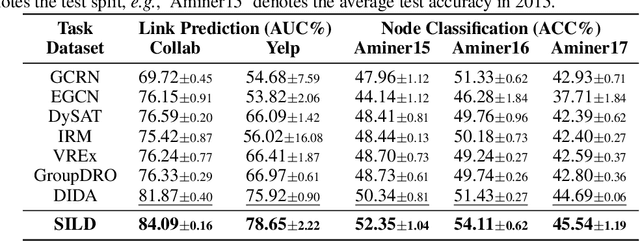
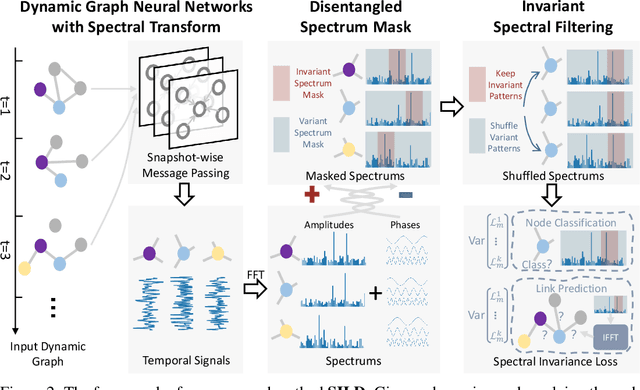
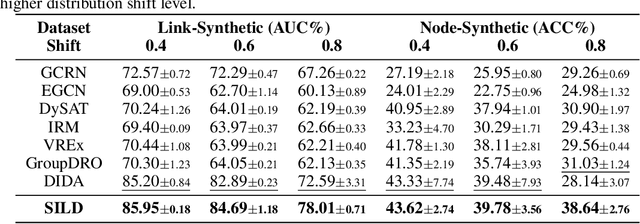
Dynamic graph neural networks (DyGNNs) currently struggle with handling distribution shifts that are inherent in dynamic graphs. Existing work on DyGNNs with out-of-distribution settings only focuses on the time domain, failing to handle cases involving distribution shifts in the spectral domain. In this paper, we discover that there exist cases with distribution shifts unobservable in the time domain while observable in the spectral domain, and propose to study distribution shifts on dynamic graphs in the spectral domain for the first time. However, this investigation poses two key challenges: i) it is non-trivial to capture different graph patterns that are driven by various frequency components entangled in the spectral domain; and ii) it remains unclear how to handle distribution shifts with the discovered spectral patterns. To address these challenges, we propose Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts (SILD), which can handle distribution shifts on dynamic graphs by capturing and utilizing invariant and variant spectral patterns. Specifically, we first design a DyGNN with Fourier transform to obtain the ego-graph trajectory spectrums, allowing the mixed dynamic graph patterns to be transformed into separate frequency components. We then develop a disentangled spectrum mask to filter graph dynamics from various frequency components and discover the invariant and variant spectral patterns. Finally, we propose invariant spectral filtering, which encourages the model to rely on invariant patterns for generalization under distribution shifts. Experimental results on synthetic and real-world dynamic graph datasets demonstrate the superiority of our method for both node classification and link prediction tasks under distribution shifts.
Prompt Selection and Augmentation for Few Examples Code Generation in Large Language Model and its Application in Robotics Control
Mar 11, 2024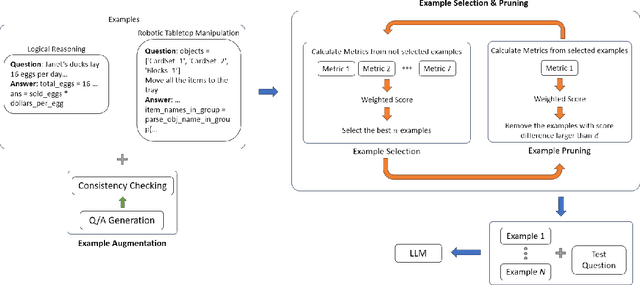

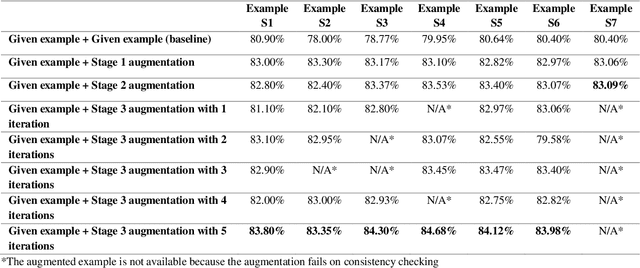
Few-shot prompting and step-by-step reasoning have enhanced the capabilities of Large Language Models (LLMs) in tackling complex tasks including code generation. In this paper, we introduce a prompt selection and augmentation algorithm aimed at improving mathematical reasoning and robot arm operations. Our approach incorporates a multi-stage example augmentation scheme combined with an example selection scheme. This algorithm improves LLM performance by selecting a set of examples that increase diversity, minimize redundancy, and increase relevance to the question. When combined with the Program-of-Thought prompting, our algorithm demonstrates an improvement in performance on the GSM8K and SVAMP benchmarks, with increases of 0.3% and 1.1% respectively. Furthermore, in simulated tabletop environments, our algorithm surpasses the Code-as-Policies approach by achieving a 3.4% increase in successful task completions and a decrease of over 70% in the number of examples used. Its ability to discard examples that contribute little to solving the problem reduces the inferencing time of an LLM-powered robotics system. This algorithm also offers important benefits for industrial process automation by streamlining the development and deployment process, reducing manual programming effort, and enhancing code reusability.
MambaMIL: Enhancing Long Sequence Modeling with Sequence Reordering in Computational Pathology
Mar 11, 2024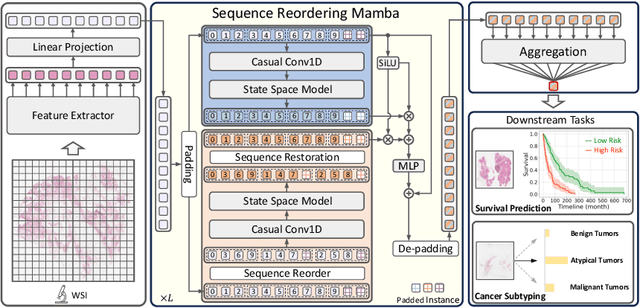
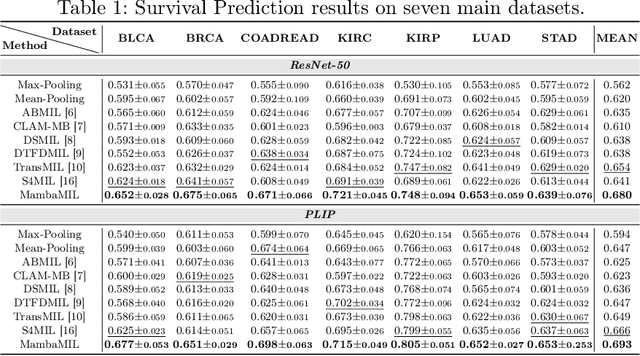
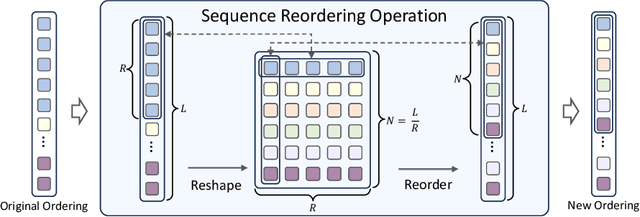
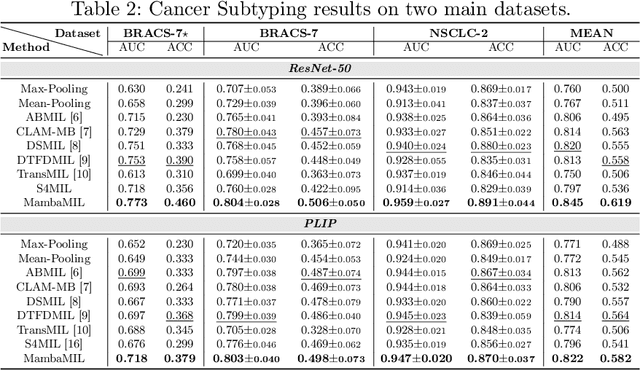
Multiple Instance Learning (MIL) has emerged as a dominant paradigm to extract discriminative feature representations within Whole Slide Images (WSIs) in computational pathology. Despite driving notable progress, existing MIL approaches suffer from limitations in facilitating comprehensive and efficient interactions among instances, as well as challenges related to time-consuming computations and overfitting. In this paper, we incorporate the Selective Scan Space State Sequential Model (Mamba) in Multiple Instance Learning (MIL) for long sequence modeling with linear complexity, termed as MambaMIL. By inheriting the capability of vanilla Mamba, MambaMIL demonstrates the ability to comprehensively understand and perceive long sequences of instances. Furthermore, we propose the Sequence Reordering Mamba (SR-Mamba) aware of the order and distribution of instances, which exploits the inherent valuable information embedded within the long sequences. With the SR-Mamba as the core component, MambaMIL can effectively capture more discriminative features and mitigate the challenges associated with overfitting and high computational overhead. Extensive experiments on two public challenging tasks across nine diverse datasets demonstrate that our proposed framework performs favorably against state-of-the-art MIL methods. The code is released at https://github.com/isyangshu/MambaMIL.
Confidence-Aware RGB-D Face Recognition via Virtual Depth Synthesis
Mar 11, 2024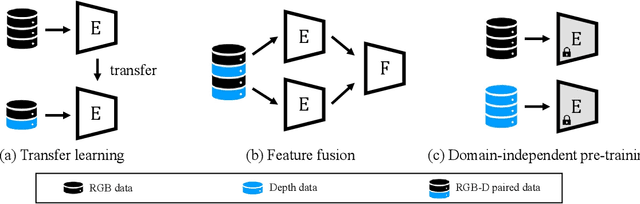
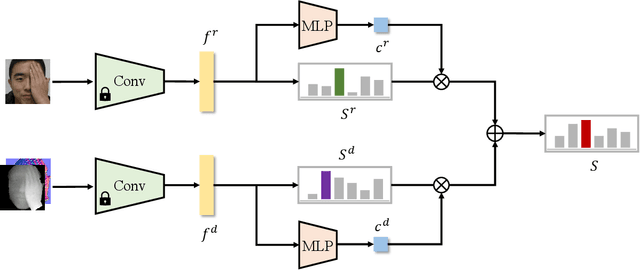
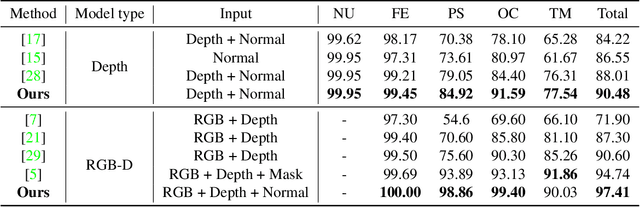
2D face recognition encounters challenges in unconstrained environments due to varying illumination, occlusion, and pose. Recent studies focus on RGB-D face recognition to improve robustness by incorporating depth information. However, collecting sufficient paired RGB-D training data is expensive and time-consuming, hindering wide deployment. In this work, we first construct a diverse depth dataset generated by 3D Morphable Models for depth model pre-training. Then, we propose a domain-independent pre-training framework that utilizes readily available pre-trained RGB and depth models to separately perform face recognition without needing additional paired data for retraining. To seamlessly integrate the two distinct networks and harness the complementary benefits of RGB and depth information for improved accuracy, we propose an innovative Adaptive Confidence Weighting (ACW). This mechanism is designed to learn confidence estimates for each modality to achieve modality fusion at the score level. Our method is simple and lightweight, only requiring ACW training beyond the backbone models. Experiments on multiple public RGB-D face recognition benchmarks demonstrate state-of-the-art performance surpassing previous methods based on depth estimation and feature fusion, validating the efficacy of our approach.
An Efficient Learning-based Solver Comparable to Metaheuristics for the Capacitated Arc Routing Problem
Mar 11, 2024
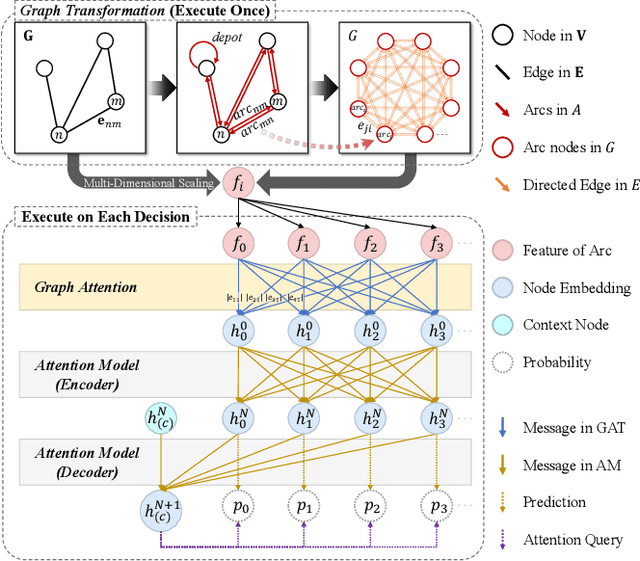
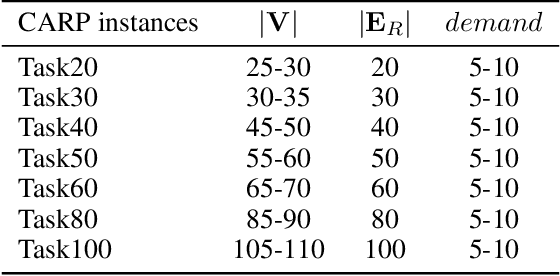
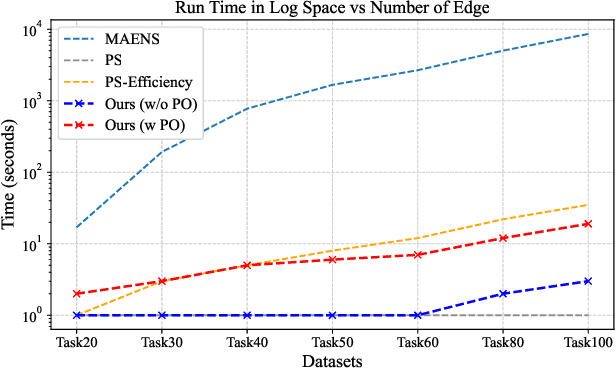
Recently, neural networks (NN) have made great strides in combinatorial optimization. However, they face challenges when solving the capacitated arc routing problem (CARP) which is to find the minimum-cost tour covering all required edges on a graph, while within capacity constraints. In tackling CARP, NN-based approaches tend to lag behind advanced metaheuristics, since they lack directed arc modeling and efficient learning methods tailored for complex CARP. In this paper, we introduce an NN-based solver to significantly narrow the gap with advanced metaheuristics while exhibiting superior efficiency. First, we propose the direction-aware attention model (DaAM) to incorporate directionality into the embedding process, facilitating more effective one-stage decision-making. Second, we design a supervised reinforcement learning scheme that involves supervised pre-training to establish a robust initial policy for subsequent reinforcement fine-tuning. It proves particularly valuable for solving CARP that has a higher complexity than the node routing problems (NRPs). Finally, a path optimization method is proposed to adjust the depot return positions within the path generated by DaAM. Experiments illustrate that our approach surpasses heuristics and achieves decision quality comparable to state-of-the-art metaheuristics for the first time while maintaining superior efficiency.
PCLD: Point Cloud Layerwise Diffusion for Adversarial Purification
Mar 11, 2024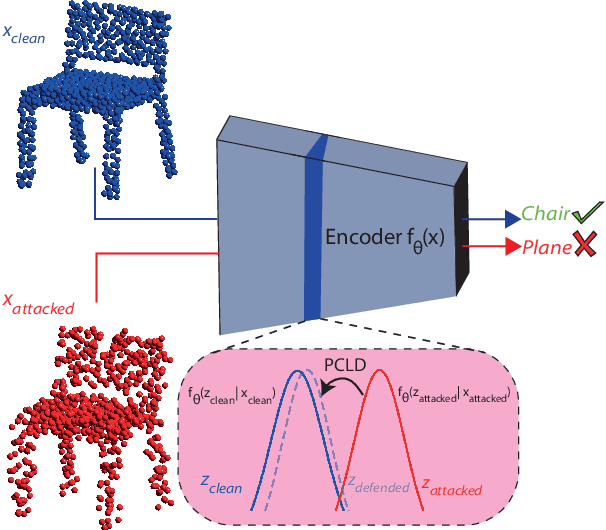
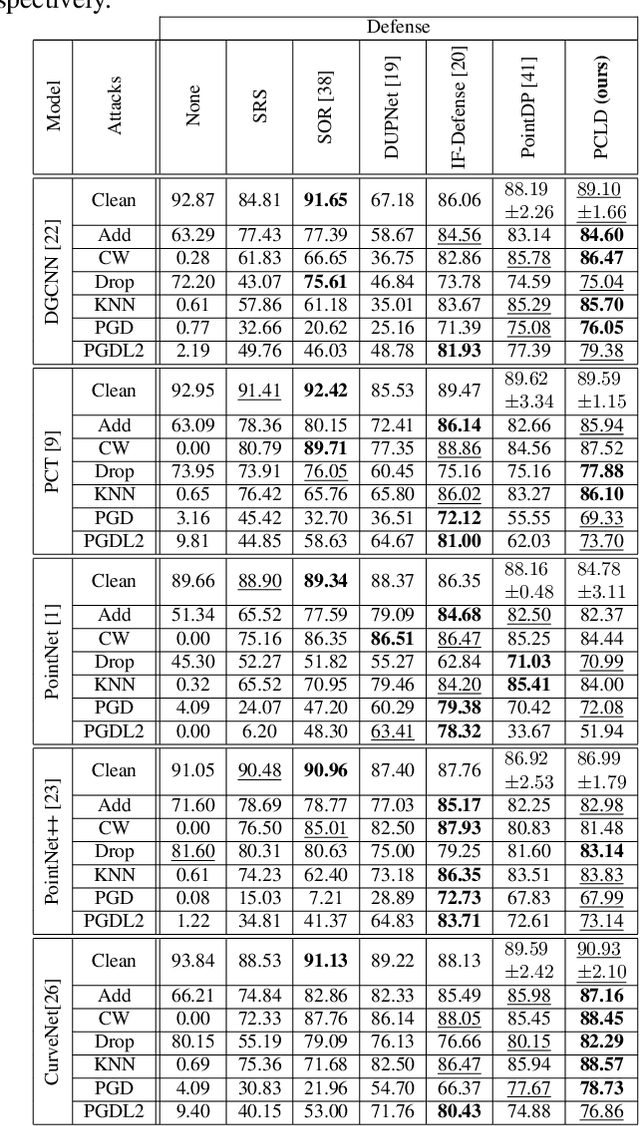
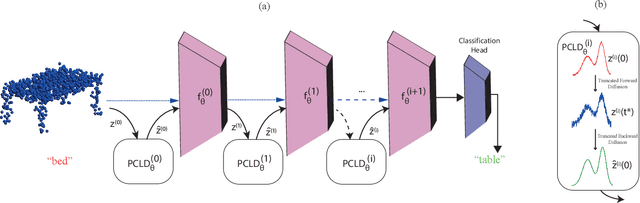
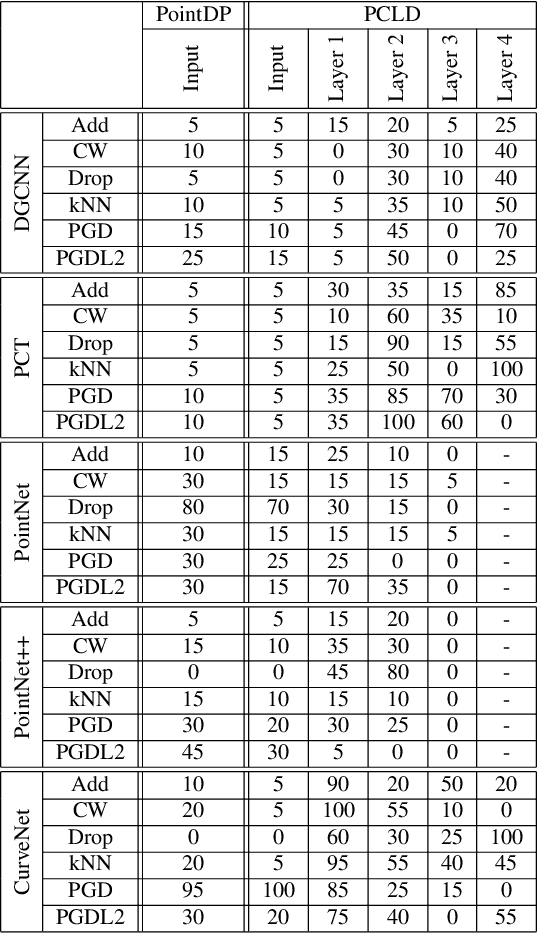
Point clouds are extensively employed in a variety of real-world applications such as robotics, autonomous driving and augmented reality. Despite the recent success of point cloud neural networks, especially for safety-critical tasks, it is essential to also ensure the robustness of the model. A typical way to assess a model's robustness is through adversarial attacks, where test-time examples are generated based on gradients to deceive the model. While many different defense mechanisms are studied in 2D, studies on 3D point clouds have been relatively limited in the academic field. Inspired from PointDP, which denoises the network inputs by diffusion, we propose Point Cloud Layerwise Diffusion (PCLD), a layerwise diffusion based 3D point cloud defense strategy. Unlike PointDP, we propagated the diffusion denoising after each layer to incrementally enhance the results. We apply our defense method to different types of commonly used point cloud models and adversarial attacks to evaluate its robustness. Our experiments demonstrate that the proposed defense method achieved results that are comparable to or surpass those of existing methodologies, establishing robustness through a novel technique. Code is available at https://github.com/batuceng/diffusion-layer-robustness-pc.
MedKP: Medical Dialogue with Knowledge Enhancement and Clinical Pathway Encoding
Mar 11, 2024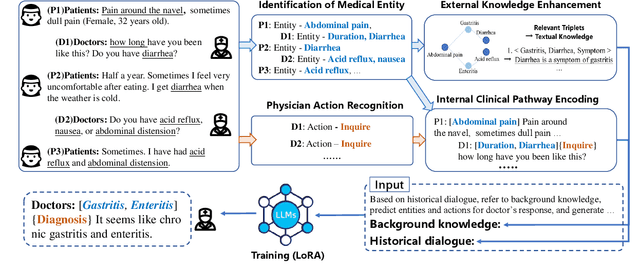
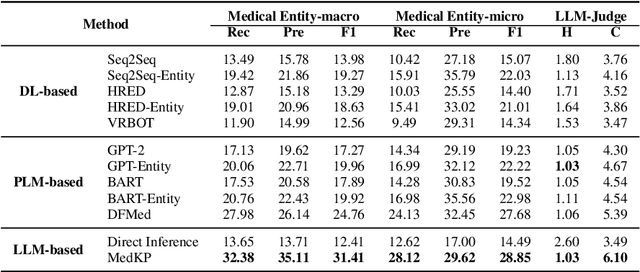

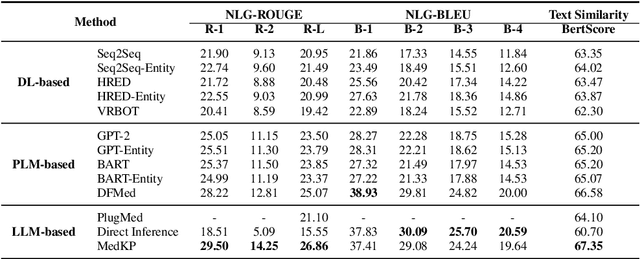
With appropriate data selection and training techniques, Large Language Models (LLMs) have demonstrated exceptional success in various medical examinations and multiple-choice questions. However, the application of LLMs in medical dialogue generation-a task more closely aligned with actual medical practice-has been less explored. This gap is attributed to the insufficient medical knowledge of LLMs, which leads to inaccuracies and hallucinated information in the generated medical responses. In this work, we introduce the Medical dialogue with Knowledge enhancement and clinical Pathway encoding (MedKP) framework, which integrates an external knowledge enhancement module through a medical knowledge graph and an internal clinical pathway encoding via medical entities and physician actions. Evaluated with comprehensive metrics, our experiments on two large-scale, real-world online medical consultation datasets (MedDG and KaMed) demonstrate that MedKP surpasses multiple baselines and mitigates the incidence of hallucinations, achieving a new state-of-the-art. Extensive ablation studies further reveal the effectiveness of each component of MedKP. This enhancement advances the development of reliable, automated medical consultation responses using LLMs, thereby broadening the potential accessibility of precise and real-time medical assistance.
Mastering Memory Tasks with World Models
Mar 07, 2024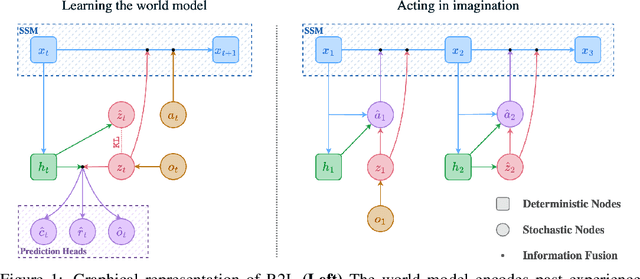

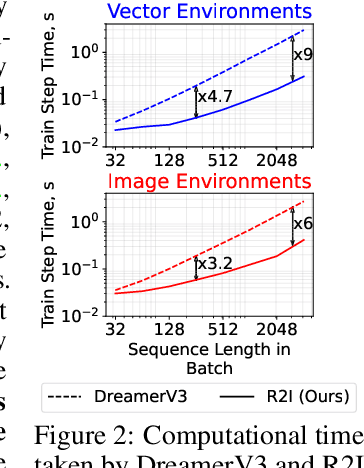
Current model-based reinforcement learning (MBRL) agents struggle with long-term dependencies. This limits their ability to effectively solve tasks involving extended time gaps between actions and outcomes, or tasks demanding the recalling of distant observations to inform current actions. To improve temporal coherence, we integrate a new family of state space models (SSMs) in world models of MBRL agents to present a new method, Recall to Imagine (R2I). This integration aims to enhance both long-term memory and long-horizon credit assignment. Through a diverse set of illustrative tasks, we systematically demonstrate that R2I not only establishes a new state-of-the-art for challenging memory and credit assignment RL tasks, such as BSuite and POPGym, but also showcases superhuman performance in the complex memory domain of Memory Maze. At the same time, it upholds comparable performance in classic RL tasks, such as Atari and DMC, suggesting the generality of our method. We also show that R2I is faster than the state-of-the-art MBRL method, DreamerV3, resulting in faster wall-time convergence.
CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
Mar 08, 2024
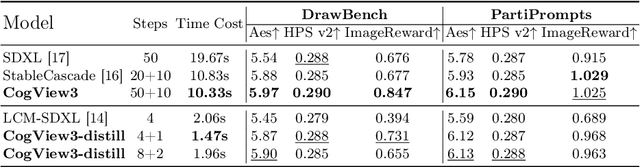

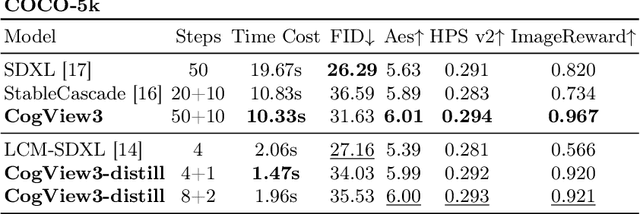
Recent advancements in text-to-image generative systems have been largely driven by diffusion models. However, single-stage text-to-image diffusion models still face challenges, in terms of computational efficiency and the refinement of image details. To tackle the issue, we propose CogView3, an innovative cascaded framework that enhances the performance of text-to-image diffusion. CogView3 is the first model implementing relay diffusion in the realm of text-to-image generation, executing the task by first creating low-resolution images and subsequently applying relay-based super-resolution. This methodology not only results in competitive text-to-image outputs but also greatly reduces both training and inference costs. Our experimental results demonstrate that CogView3 outperforms SDXL, the current state-of-the-art open-source text-to-image diffusion model, by 77.0\% in human evaluations, all while requiring only about 1/2 of the inference time. The distilled variant of CogView3 achieves comparable performance while only utilizing 1/10 of the inference time by SDXL.
Deep Backward and Galerkin Methods for the Finite State Master Equation
Mar 08, 2024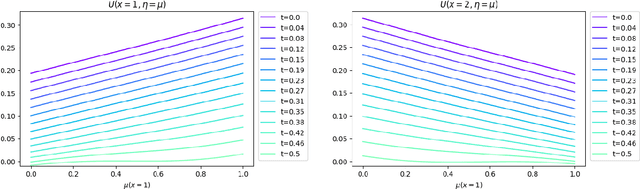
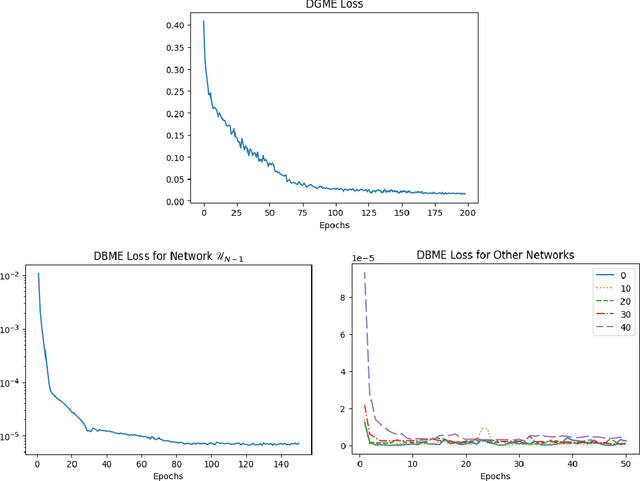
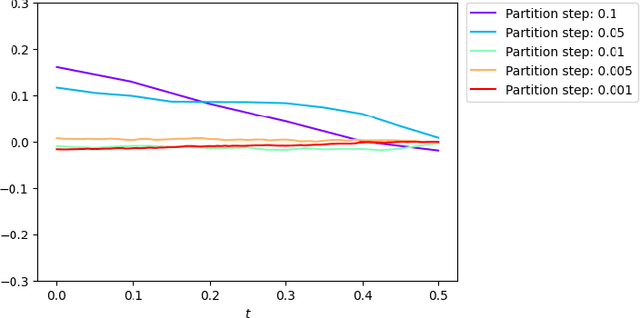
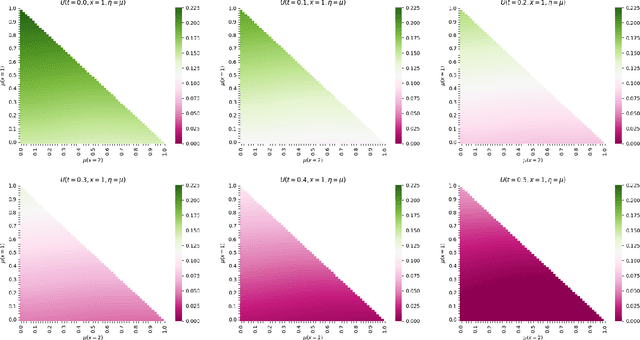
This paper proposes and analyzes two neural network methods to solve the master equation for finite-state mean field games (MFGs). Solving MFGs provides approximate Nash equilibria for stochastic, differential games with finite but large populations of agents. The master equation is a partial differential equation (PDE) whose solution characterizes MFG equilibria for any possible initial distribution. The first method we propose relies on backward induction in a time component while the second method directly tackles the PDE without discretizing time. For both approaches, we prove two types of results: there exist neural networks that make the algorithms' loss functions arbitrarily small, and conversely, if the losses are small, then the neural networks are good approximations of the master equation's solution. We conclude the paper with numerical experiments on benchmark problems from the literature up to dimension 15, and a comparison with solutions computed by a classical method for fixed initial distributions.