 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Guiding Energy-based Models via Contrastive Latent Variables
Mar 06, 2023
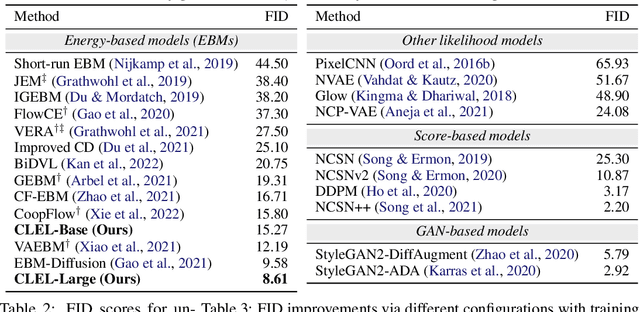


An energy-based model (EBM) is a popular generative framework that offers both explicit density and architectural flexibility, but training them is difficult since it is often unstable and time-consuming. In recent years, various training techniques have been developed, e.g., better divergence measures or stabilization in MCMC sampling, but there often exists a large gap between EBMs and other generative frameworks like GANs in terms of generation quality. In this paper, we propose a novel and effective framework for improving EBMs via contrastive representation learning (CRL). To be specific, we consider representations learned by contrastive methods as the true underlying latent variable. This contrastive latent variable could guide EBMs to understand the data structure better, so it can improve and accelerate EBM training significantly. To enable the joint training of EBM and CRL, we also design a new class of latent-variable EBMs for learning the joint density of data and the contrastive latent variable. Our experimental results demonstrate that our scheme achieves lower FID scores, compared to prior-art EBM methods (e.g., additionally using variational autoencoders or diffusion techniques), even with significantly faster and more memory-efficient training. We also show conditional and compositional generation abilities of our latent-variable EBMs as their additional benefits, even without explicit conditional training. The code is available at https://github.com/hankook/CLEL.
Joint On-Manifold Gravity and Accelerometer Intrinsics Estimation
Mar 06, 2023
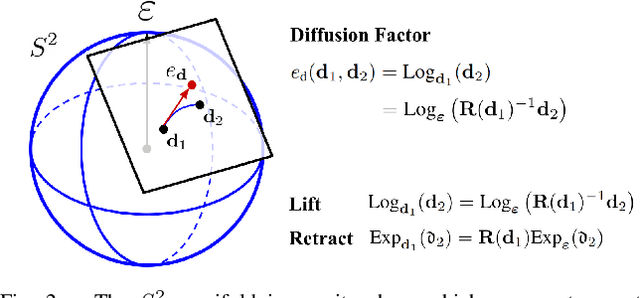
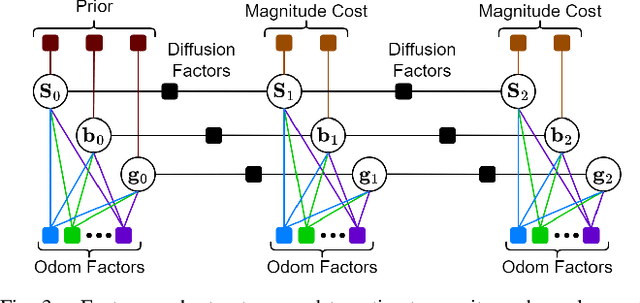
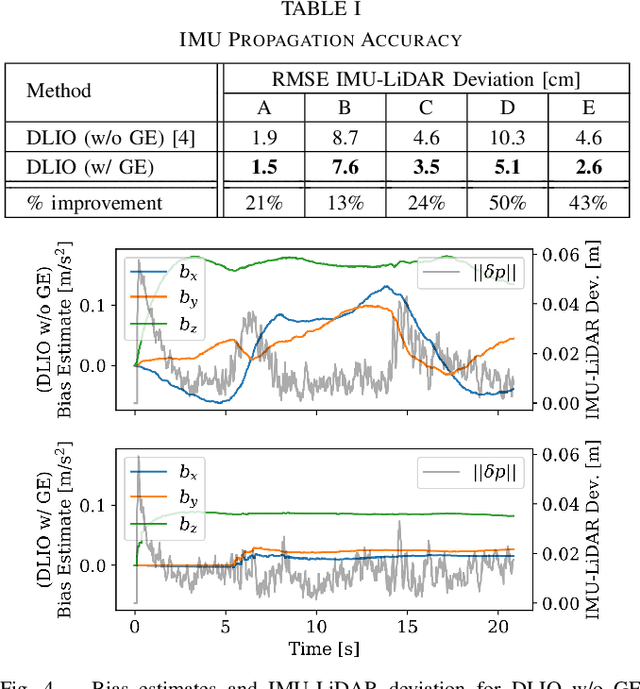
Aligning a robot's trajectory or map to the inertial frame is a critical capability that is often difficult to do accurately even though inertial measurement units (IMUs) can observe absolute roll and pitch with respect to gravity. Accelerometer biases and scale factor errors from the IMU's initial calibration are often the major source of inaccuracies when aligning the robot's odometry frame with the inertial frame, especially for low-grade IMUs. Practically, one would simultaneously estimate the true gravity vector, accelerometer biases, and scale factor to improve measurement quality but these quantities are not observable unless the IMU is sufficiently excited. While several methods estimate accelerometer bias and gravity, they do not explicitly address the observability issue nor do they estimate scale factor. We present a fixed-lag factor-graph-based estimator to address both of these issues. In addition to estimating accelerometer scale factor, our method mitigates limited observability by optimizing over a time window an order of magnitude larger than existing methods with significantly lower computational burden. The proposed method, which estimates accelerometer intrinsics and gravity separately from the other states, is enabled by a novel, velocity-agnostic measurement model for intrinsics and gravity, as well as a new method for gravity vector optimization on S2. Accurate IMU state prediction, gravity-alignment, and roll/pitch drift correction are experimentally demonstrated on public and self-collected datasets in diverse environments.
Benchmark of Data Preprocessing Methods for Imbalanced Classification
Mar 06, 2023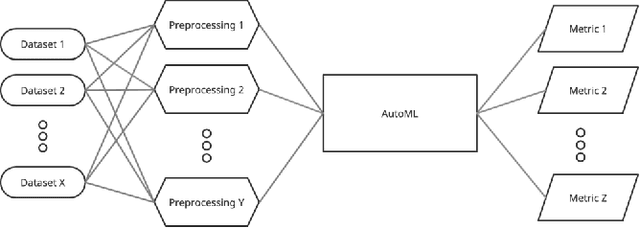
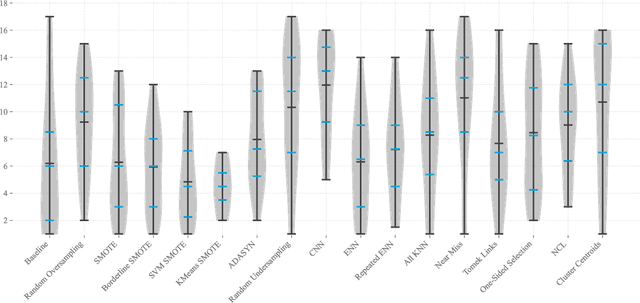
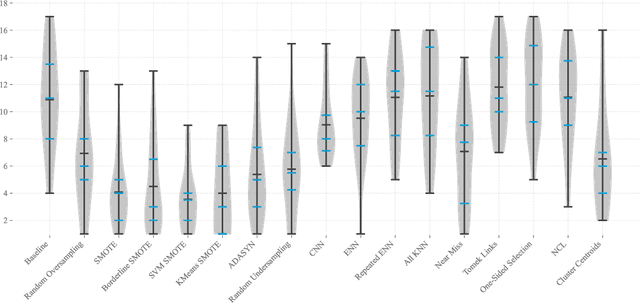
Severe class imbalance is one of the main conditions that make machine learning in cybersecurity difficult. A variety of dataset preprocessing methods have been introduced over the years. These methods modify the training dataset by oversampling, undersampling or a combination of both to improve the predictive performance of classifiers trained on this dataset. Although these methods are used in cybersecurity occasionally, a comprehensive, unbiased benchmark comparing their performance over a variety of cybersecurity problems is missing. This paper presents a benchmark of 16 preprocessing methods on six cybersecurity datasets together with 17 public imbalanced datasets from other domains. We test the methods under multiple hyperparameter configurations and use an AutoML system to train classifiers on the preprocessed datasets, which reduces potential bias from specific hyperparameter or classifier choices. Special consideration is also given to evaluating the methods using appropriate performance measures that are good proxies for practical performance in real-world cybersecurity systems. The main findings of our study are: 1) Most of the time, a data preprocessing method that improves classification performance exists. 2) Baseline approach of doing nothing outperformed a large portion of methods in the benchmark. 3) Oversampling methods generally outperform undersampling methods. 4) The most significant performance gains are brought by the standard SMOTE algorithm and more complicated methods provide mainly incremental improvements at the cost of often worse computational performance.
Gradual Test-Time Adaptation by Self-Training and Style Transfer
Aug 16, 2022
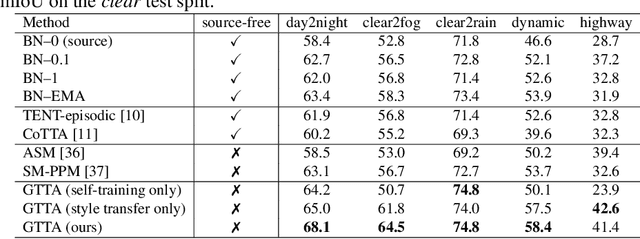
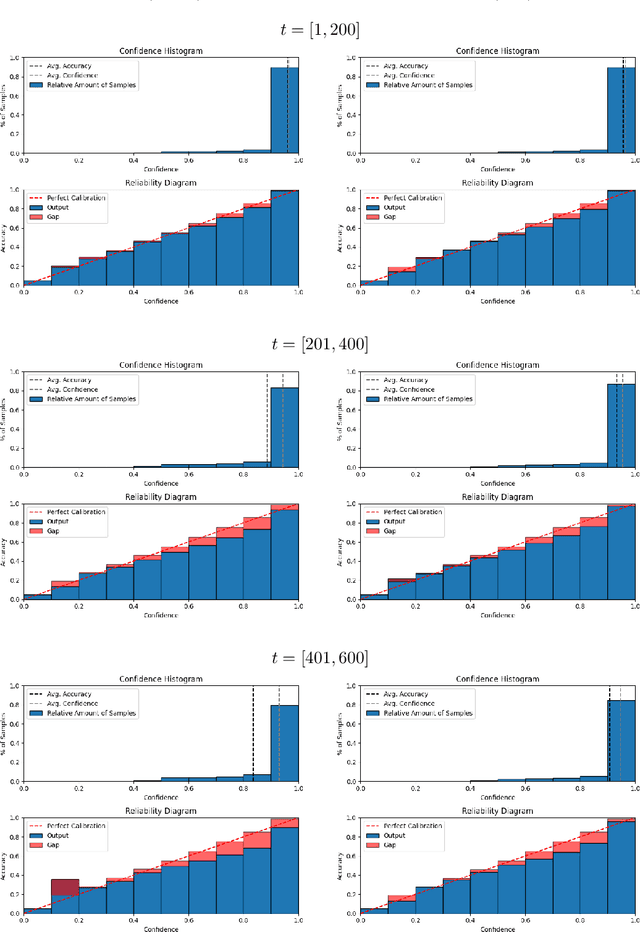
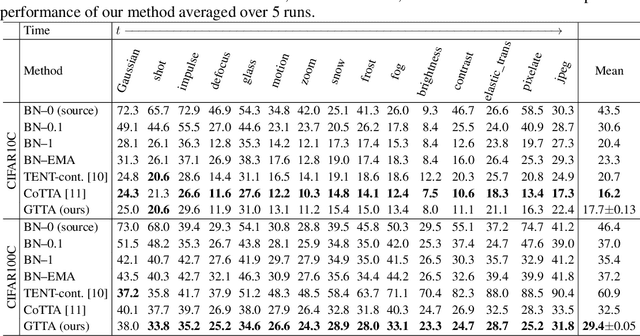
Domain shifts at test-time are inevitable in practice. Test-time adaptation addresses this problem by adapting the model during deployment. Recent work theoretically showed that self-training can be a strong method in the setting of gradual domain shifts. In this work we show the natural connection between gradual domain adaptation and test-time adaptation. We publish a new synthetic dataset called CarlaTTA that allows to explore gradual domain shifts during test-time and evaluate several methods in the area of unsupervised domain adaptation and test-time adaptation. We propose a new method GTTA that is based on self-training and style transfer. GTTA explicitly exploits gradual domain shifts and sets a new standard in this area. We further demonstrate the effectiveness of our method on the continual and gradual CIFAR10C, CIFAR100C, and ImageNet-C benchmark.
Deriving time-averaged active inference from control principles
Aug 22, 2022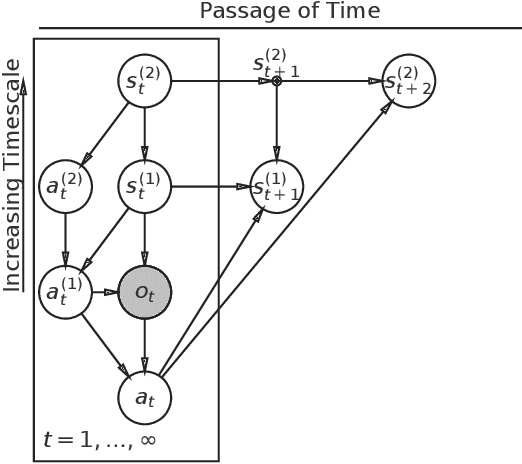

Active inference offers a principled account of behavior as minimizing average sensory surprise over time. Applications of active inference to control problems have heretofore tended to focus on finite-horizon or discounted-surprise problems, despite deriving from the infinite-horizon, average-surprise imperative of the free-energy principle. Here we derive an infinite-horizon, average-surprise formulation of active inference from optimal control principles. Our formulation returns to the roots of active inference in neuroanatomy and neurophysiology, formally reconnecting active inference to optimal feedback control. Our formulation provides a unified objective functional for sensorimotor control and allows for reference states to vary over time.
AsyncNeRF: Learning Large-scale Radiance Fields from Asynchronous RGB-D Sequences with Time-Pose Function
Nov 14, 2022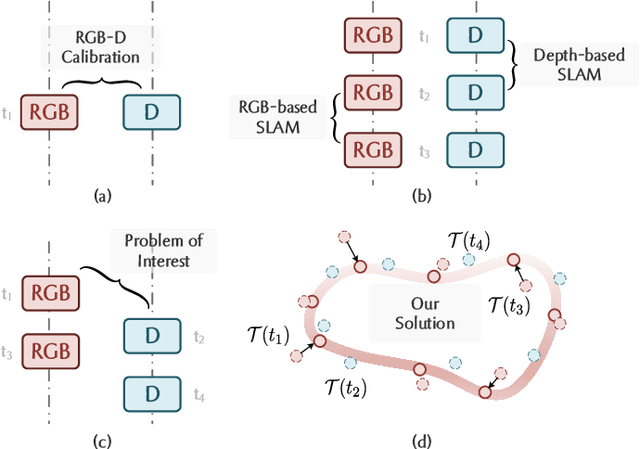
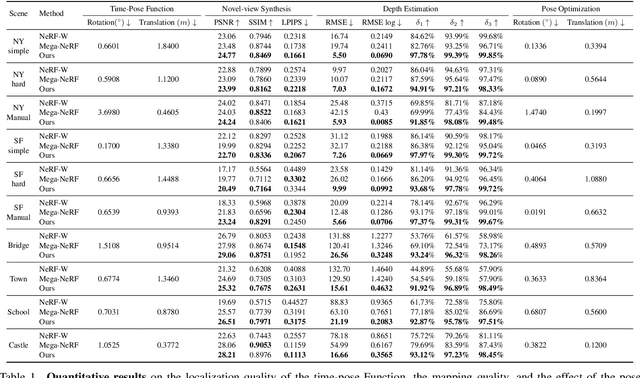
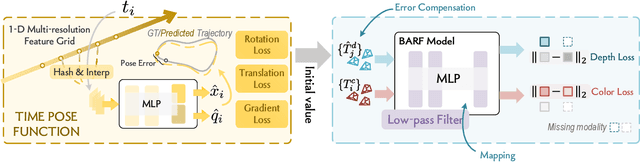
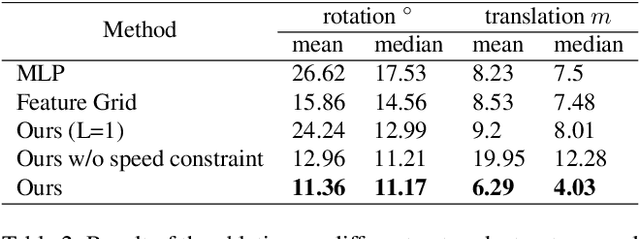
Large-scale radiance fields are promising mapping tools for smart transportation applications like autonomous driving or drone delivery. But for large-scale scenes, compact synchronized RGB-D cameras are not applicable due to limited sensing range, and using separate RGB and depth sensors inevitably leads to unsynchronized sequences. Inspired by the recent success of self-calibrating radiance field training methods that do not require known intrinsic or extrinsic parameters, we propose the first solution that self-calibrates the mismatch between RGB and depth frames. We leverage the important domain-specific fact that RGB and depth frames are actually sampled from the same trajectory and develop a novel implicit network called the time-pose function. Combining it with a large-scale radiance field leads to an architecture that cascades two implicit representation networks. To validate its effectiveness, we construct a diverse and photorealistic dataset that covers various RGB-D mismatch scenarios. Through a comprehensive benchmarking on this dataset, we demonstrate the flexibility of our method in different scenarios and superior performance over applicable prior counterparts. Codes, data, and models will be made publicly available.
Uzbek text summarization based on TF-IDF
Mar 01, 2023
The volume of information is increasing at an incredible rate with the rapid development of the Internet and electronic information services. Due to time constraints, we don't have the opportunity to read all this information. Even the task of analyzing textual data related to one field requires a lot of work. The text summarization task helps to solve these problems. This article presents an experiment on summarization task for Uzbek language, the methodology was based on text abstracting based on TF-IDF algorithm. Using this density function, semantically important parts of the text are extracted. We summarize the given text by applying the n-gram method to important parts of the whole text. The authors used a specially handcrafted corpus called "School corpus" to evaluate the performance of the proposed method. The results show that the proposed approach is effective in extracting summaries from Uzbek language text and can potentially be used in various applications such as information retrieval and natural language processing. Overall, this research contributes to the growing body of work on text summarization in under-resourced languages.
Efficient Path Planning In Manipulation Planning Problems by Actively Reusing Validation Effort
Mar 01, 2023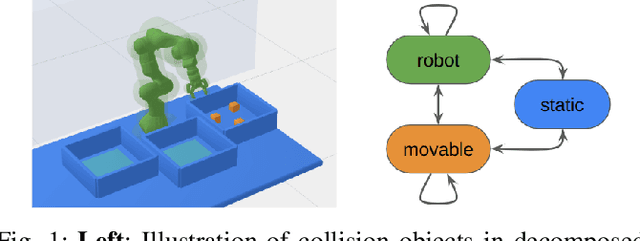
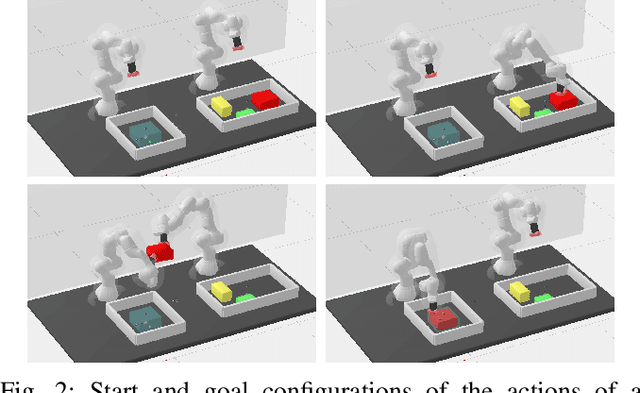

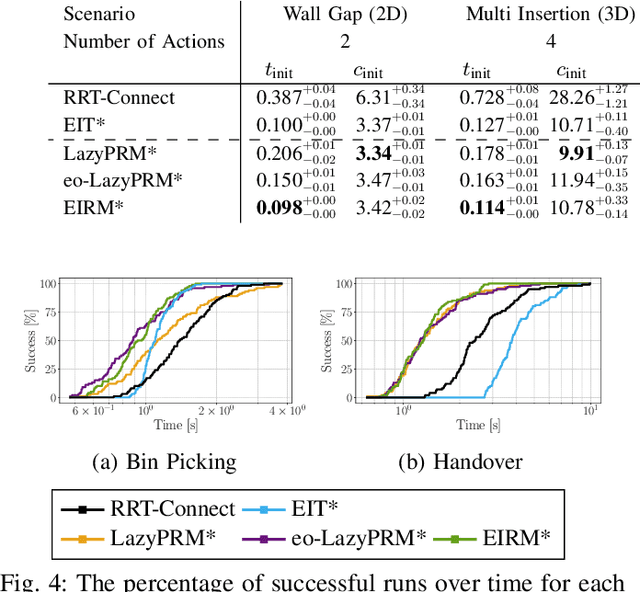
The path planning problems arising in manipulation planning and in task and motion planning settings are typically repetitive: the same manipulator moves in a space that only changes slightly. Despite this potential for reuse of information, few planners fully exploit the available information. To better enable this reuse, we decompose the collision checking into reusable, and non-reusable parts. We then treat the sequences of path planning problems in manipulation planning as a multiquery path planning problem. This allows the usage of planners that actively minimize planning effort over multiple queries, and by doing so, actively reuse previous knowledge. We implement this approach in EIRM* and effort ordered LazyPRM*, and benchmark it on multiple simulated robotic examples. Further, we show that the approach of decomposing collision checks additionally enables the reuse of the gained knowledge over multiple different instances of the same problem, i.e., in a multiquery manipulation planning scenario. The planners using the decomposed collision checking outperform the other planners in initial solution time by up to a factor of two while providing a similar solution quality.
ISBNet: a 3D Point Cloud Instance Segmentation Network with Instance-aware Sampling and Box-aware Dynamic Convolution
Mar 01, 2023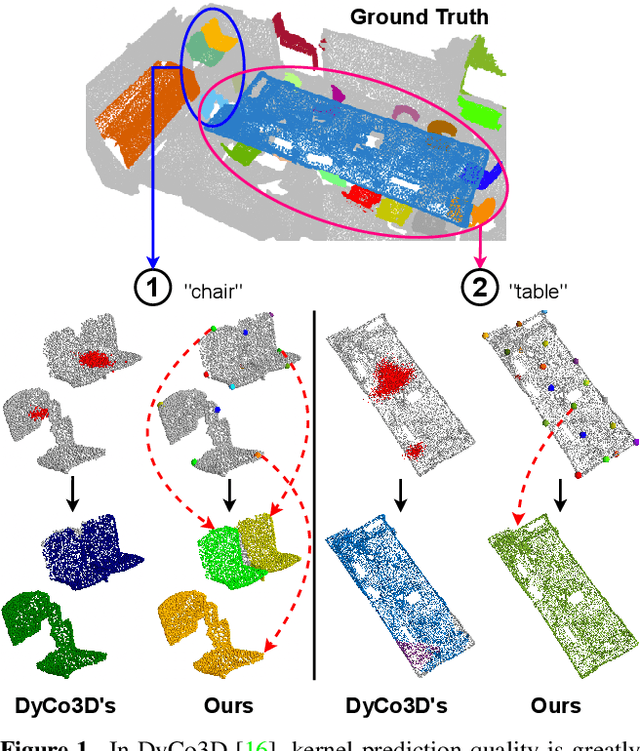
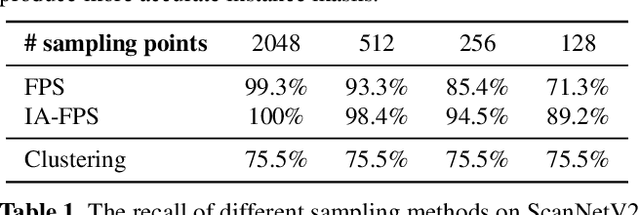
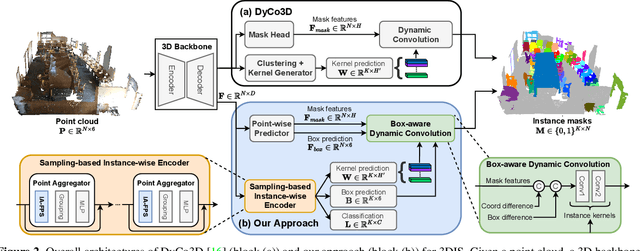
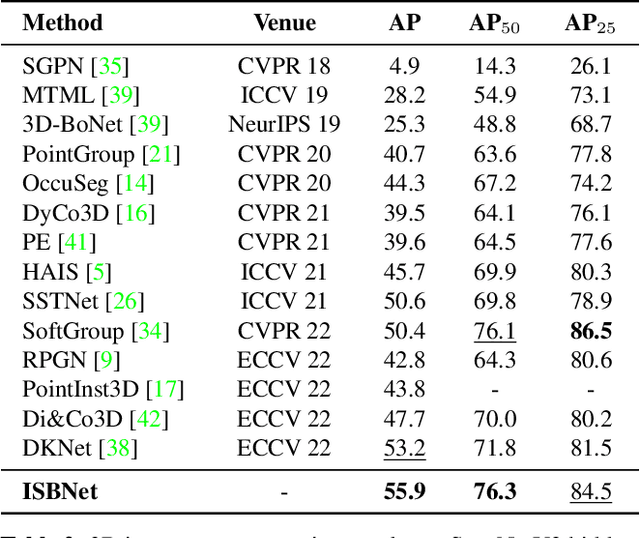
Existing 3D instance segmentation methods are predominated by the bottom-up design -- manually fine-tuned algorithm to group points into clusters followed by a refinement network. However, by relying on the quality of the clusters, these methods generate susceptible results when (1) nearby objects with the same semantic class are packed together, or (2) large objects with loosely connected regions. To address these limitations, we introduce ISBNet, a novel cluster-free method that represents instances as kernels and decodes instance masks via dynamic convolution. To efficiently generate high-recall and discriminative kernels, we propose a simple strategy named Instance-aware Farthest Point Sampling to sample candidates and leverage the local aggregation layer inspired by PointNet++ to encode candidate features. Moreover, we show that predicting and leveraging the 3D axis-aligned bounding boxes in the dynamic convolution further boosts performance. Our method set new state-of-the-art results on ScanNetV2 (55.9), S3DIS (60.8), and STPLS3D (49.2) in terms of AP and retains fast inference time (237ms per scene on ScanNetV2).
Ego-noise reduction of a mobile robot using noise spatial covariance matrix learning and minimum variance distortionless response
Mar 01, 2023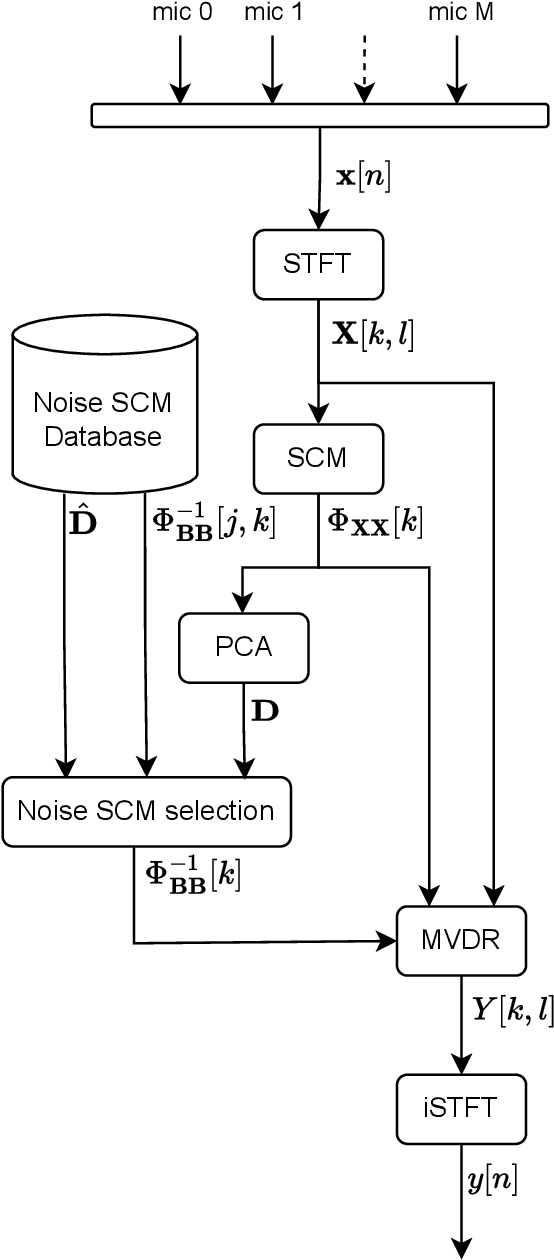


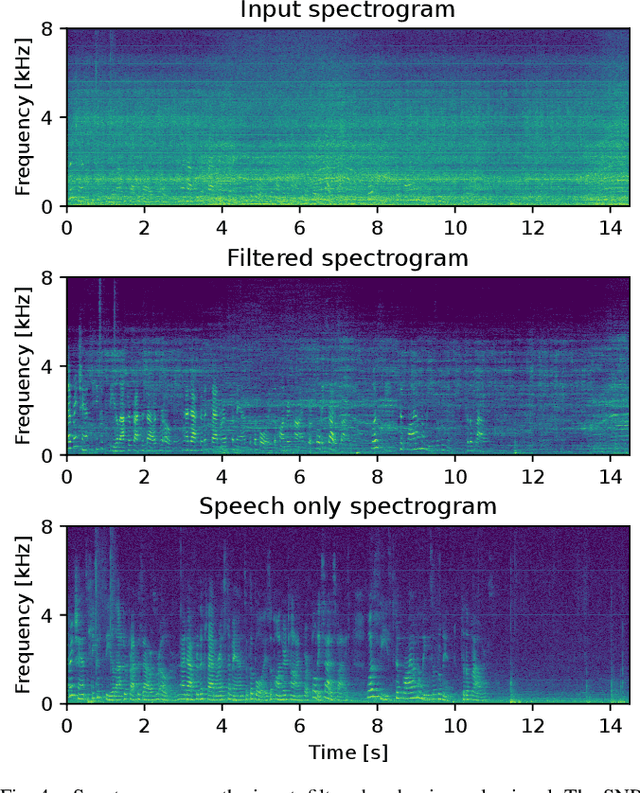
The performance of speech and events recognition systems significantly improved recently thanks to deep learning methods. However, some of these tasks remain challenging when algorithms are deployed on robots due to the unseen mechanical noise and electrical interference generated by their actuators while training the neural networks. Ego-noise reduction as a preprocessing step therefore can help solve this issue when using pre-trained speech and event recognition algorithms on robots. In this paper, we propose a new method to reduce ego-noise using only a microphone array and less than two minute of noise recordings. Using Principal Component Analysis (PCA), the best covariance matrix candidate is selected from a dictionary created online during calibration and used with the Minimum Variance Distortionless Response (MVDR) beamformer. Results show that the proposed method runs in real-time, improves the signal-to-distortion ratio (SDR) by up to 10 dB, decreases the word error rate (WER) by 55\% in some cases and increases the Average Precision (AP) of event detection by up to 0.2.