 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-Limited Waveforms with Minimum Time Broadening for the Nonlinear Schrödinger Channel
Jun 22, 2022
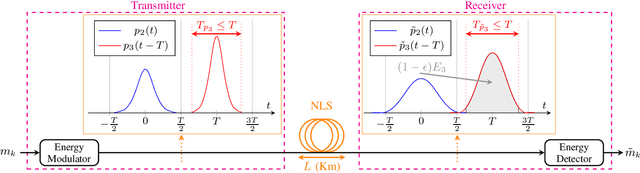
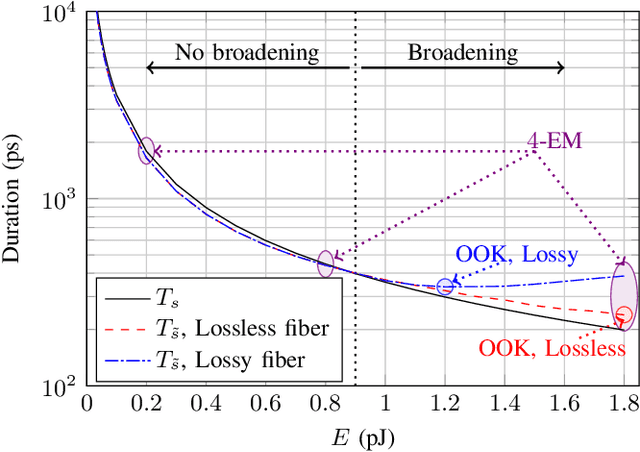
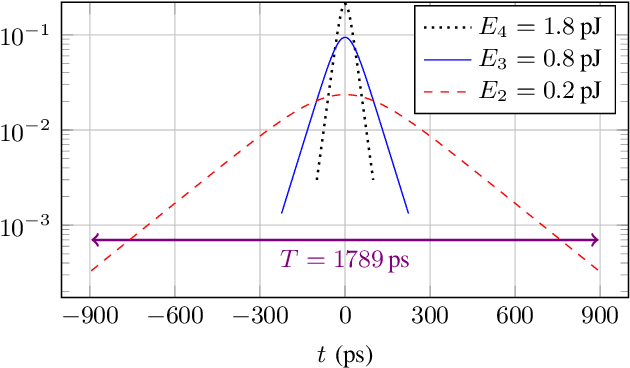
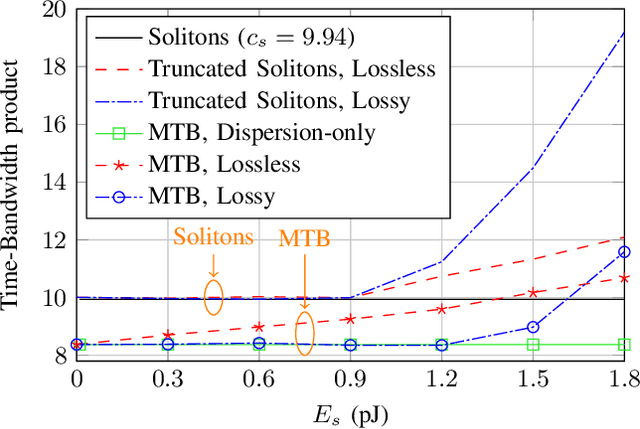
Simple fiber optic communication systems can be implemented using energy modulation of isolated time-limited pulses. Fundamental solitons are one possible solution for such pulses which offer a fundamental advantage: their shape is not affected by fiber disperison and nonlinearity. Furthermore, a simple energy detector can be used at the receiver to detect the transmitted information. However, systems based on energy modulation of solitons are not competitive in terms of data rates. This is partly due to the fact that the effective time duration of a soliton depends on its chosen amplitude. In this paper, we propose to replace fundamental solitons by new time-limited waveforms that can be detected using an energy detector, and that are immune to fiber distortions. Our proposed solution relies on the prolate spheroidal wave functions and a numerical optimization routine. Time-limited waveforms that undergo minimum time broadening along an optical fiber are obtained and shown to outperform fundamental solitons. In the case of binary transmission and a single span of fiber, we report rate increases of 33.8% and 12% over lossy and lossless fibers, respectively. Furthermore, we show that the transmission rate of the proposed system increases as the number of used energy levels increases, which is not the case for fundamental solitons due to their effective time-amplitude constraint. For example, rate increases of 164% and 70% over lossy and lossless fibers respectively are reported when using four energy levels.
DAVIS-Ag: A Synthetic Plant Dataset for Developing Domain-Inspired Active Vision in Agricultural Robots
Mar 10, 2023
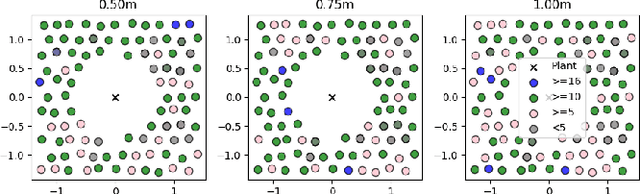

In agricultural environments, viewpoint planning can be a critical functionality for a robot with visual sensors to obtain informative observations of objects of interest (e.g., fruits) from complex structures of plant with random occlusions. Although recent studies on active vision have shown some potential for agricultural tasks, each model has been designed and validated on a unique environment that would not easily be replicated for benchmarking novel methods being developed later. In this paper, hence, we introduce a dataset for more extensive research on Domain-inspired Active VISion in Agriculture (DAVIS-Ag). To be specific, we utilized our open-source "AgML" framework and the 3D plant simulator of "Helios" to produce 502K RGB images from 30K dense spatial locations in 632 realistically synthesized orchards of strawberries, tomatoes, and grapes. In addition, useful labels are provided for each image, including (1) bounding boxes and (2) pixel-wise instance segmentations for all identifiable fruits, and also (3) pointers to other images that are reachable by an execution of action so as to simulate the active selection of viewpoint at each time step. Using DAVIS-Ag, we show the motivating examples in which performance of fruit detection for the same plant can significantly vary depending on the position and orientation of camera view primarily due to occlusions by other components such as leaves. Furthermore, we develop several baseline models to showcase the "usage" of data with one of agricultural active vision tasks--fruit search optimization--providing evaluation results against which future studies could benchmark their methodologies. For encouraging relevant research, our dataset is released online to be freely available at: https://github.com/ctyeong/DAVIS-Ag
A survey on automated detection and classification of acute leukemia and WBCs in microscopic blood cells
Mar 10, 2023Leukemia (blood cancer) is an unusual spread of White Blood Cells or Leukocytes (WBCs) in the bone marrow and blood. Pathologists can diagnose leukemia by looking at a person's blood sample under a microscope. They identify and categorize leukemia by counting various blood cells and morphological features. This technique is time-consuming for the prediction of leukemia. The pathologist's professional skills and experiences may be affecting this procedure, too. In computer vision, traditional machine learning and deep learning techniques are practical roadmaps that increase the accuracy and speed in diagnosing and classifying medical images such as microscopic blood cells. This paper provides a comprehensive analysis of the detection and classification of acute leukemia and WBCs in the microscopic blood cells. First, we have divided the previous works into six categories based on the output of the models. Then, we describe various steps of detection and classification of acute leukemia and WBCs, including Data Augmentation, Preprocessing, Segmentation, Feature Extraction, Feature Selection (Reduction), Classification, and focus on classification step in the methods. Finally, we divide automated detection and classification of acute leukemia and WBCs into three categories, including traditional, Deep Neural Network (DNN), and mixture (traditional and DNN) methods based on the type of classifier in the classification step and analyze them. The results of this study show that in the diagnosis and classification of acute leukemia and WBCs, the Support Vector Machine (SVM) classifier in traditional machine learning models and Convolutional Neural Network (CNN) classifier in deep learning models have widely employed. The performance metrics of the models that use these classifiers compared to the others model are higher.
Data-Efficient Training of CNNs and Transformers with Coresets: A Stability Perspective
Mar 10, 2023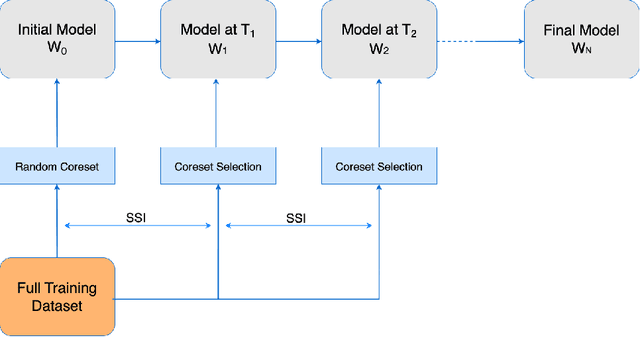

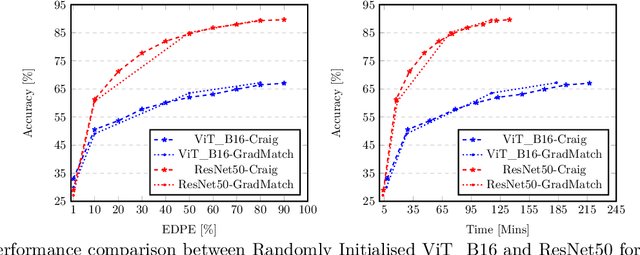
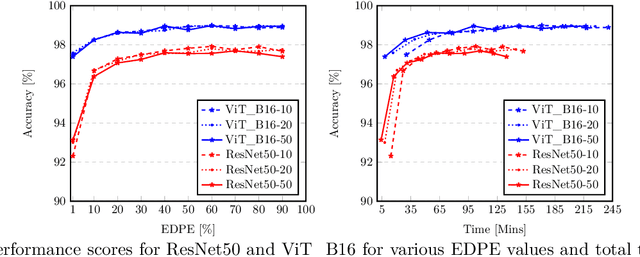
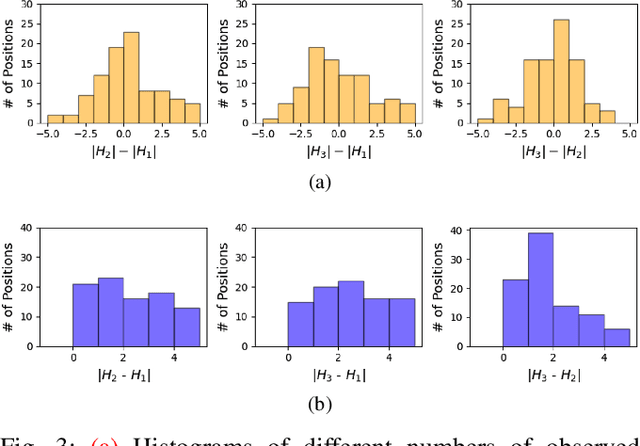
Coreset selection is among the most effective ways to reduce the training time of CNNs, however, only limited is known on how the resultant models will behave under variations of the coreset size, and choice of datasets and models. Moreover, given the recent paradigm shift towards transformer-based models, it is still an open question how coreset selection would impact their performance. There are several similar intriguing questions that need to be answered for a wide acceptance of coreset selection methods, and this paper attempts to answer some of these. We present a systematic benchmarking setup and perform a rigorous comparison of different coreset selection methods on CNNs and transformers. Our investigation reveals that under certain circumstances, random selection of subsets is more robust and stable when compared with the SOTA selection methods. We demonstrate that the conventional concept of uniform subset sampling across the various classes of the data is not the appropriate choice. Rather samples should be adaptively chosen based on the complexity of the data distribution for each class. Transformers are generally pretrained on large datasets, and we show that for certain target datasets, it helps to keep their performance stable at even very small coreset sizes. We further show that when no pretraining is done or when the pretrained transformer models are used with non-natural images (e.g. medical data), CNNs tend to generalize better than transformers at even very small coreset sizes. Lastly, we demonstrate that in the absence of the right pretraining, CNNs are better at learning the semantic coherence between spatially distant objects within an image, and these tend to outperform transformers at almost all choices of the coreset size.
ASAP: Accurate semantic segmentation for real time performance
Oct 04, 2022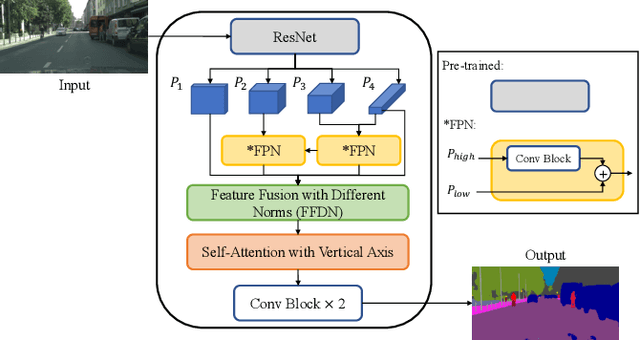
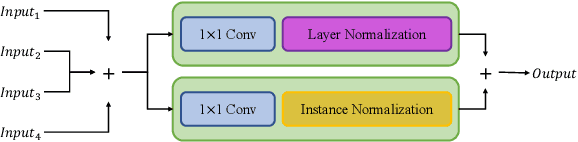
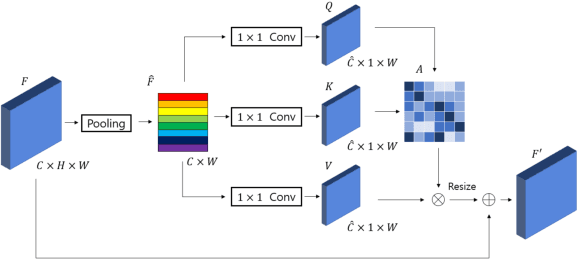

Feature fusion modules from encoder and self-attention module have been adopted in semantic segmentation. However, the computation of these modules is costly and has operational limitations in real-time environments. In addition, segmentation performance is limited in autonomous driving environments with a lot of contextual information perpendicular to the road surface, such as people, buildings, and general objects. In this paper, we propose an efficient feature fusion method, Feature Fusion with Different Norms (FFDN) that utilizes rich global context of multi-level scale and vertical pooling module before self-attention that preserves most contextual information while reducing the complexity of global context encoding in the vertical direction. By doing this, we could handle the properties of representation in global space and reduce additional computational cost. In addition, we analyze low performance in challenging cases including small and vertically featured objects. We achieve the mean Interaction of-union(mIoU) of 73.1 and the Frame Per Second(FPS) of 191, which are comparable results with state-of-the-arts on Cityscapes test datasets.
Simultaneous upper and lower bounds of American option prices with hedging via neural networks
Feb 24, 2023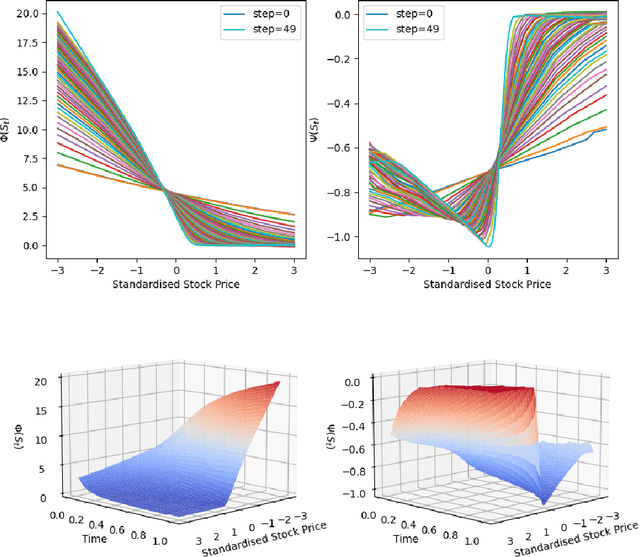
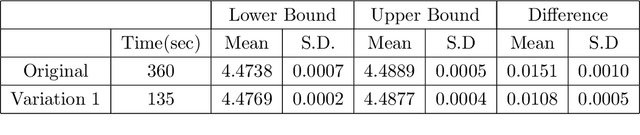
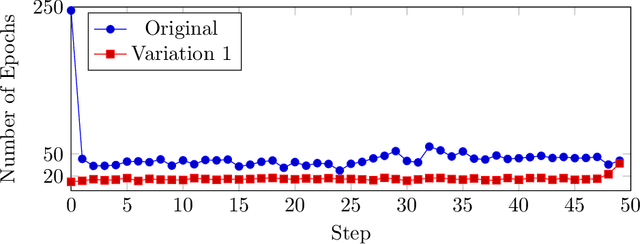
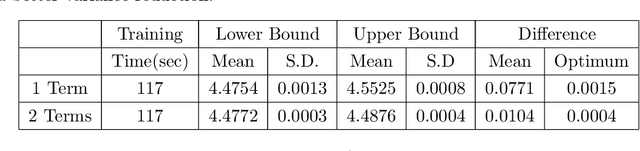
In this paper, we introduce two methods to solve the American-style option pricing problem and its dual form at the same time using neural networks. Without applying nested Monte Carlo, the first method uses a series of neural networks to simultaneously compute both the lower and upper bounds of the option price, and the second one accomplishes the same goal with one global network. The avoidance of extra simulations and the use of neural networks significantly reduce the computational complexity and allow us to price Bermudan options with frequent exercise opportunities in high dimensions, as illustrated by the provided numerical experiments. As a by-product, these methods also derive a hedging strategy for the option, which can also be used as a control variate for variance reduction.
Finding Regularized Competitive Equilibria of Heterogeneous Agent Macroeconomic Models with Reinforcement Learning
Feb 24, 2023
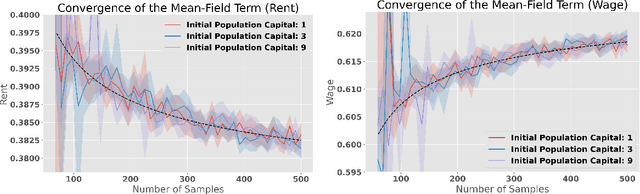
We study a heterogeneous agent macroeconomic model with an infinite number of households and firms competing in a labor market. Each household earns income and engages in consumption at each time step while aiming to maximize a concave utility subject to the underlying market conditions. The households aim to find the optimal saving strategy that maximizes their discounted cumulative utility given the market condition, while the firms determine the market conditions through maximizing corporate profit based on the household population behavior. The model captures a wide range of applications in macroeconomic studies, and we propose a data-driven reinforcement learning framework that finds the regularized competitive equilibrium of the model. The proposed algorithm enjoys theoretical guarantees in converging to the equilibrium of the market at a sub-linear rate.
A Reinforcement Learning Approach for Scheduling Problems With Improved Generalization Through Order Swapping
Mar 06, 2023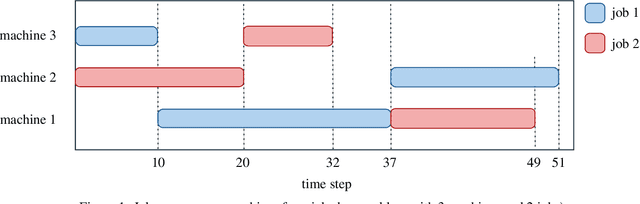
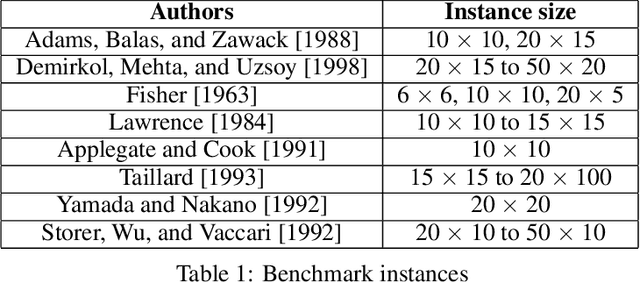
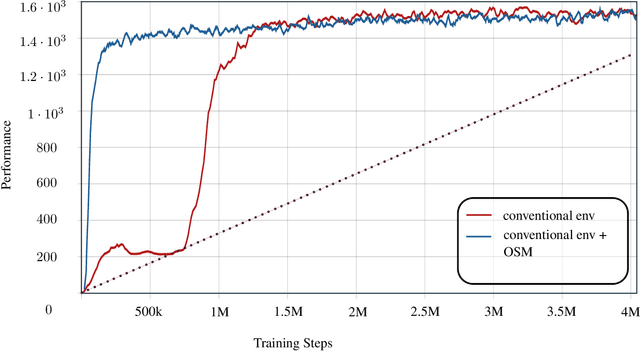
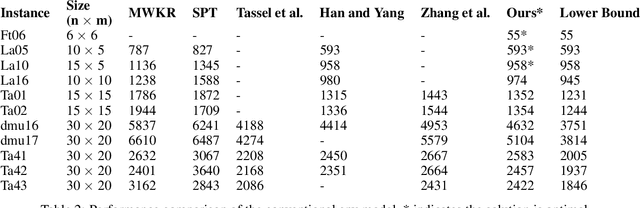
The scheduling of production resources (such as associating jobs to machines) plays a vital role for the manufacturing industry not only for saving energy but also for increasing the overall efficiency. Among the different job scheduling problems, the JSSP is addressed in this work. JSSP falls into the category of NP-hard COP, in which solving the problem through exhaustive search becomes unfeasible. Simple heuristics such as FIFO, LPT and metaheuristics such as Taboo search are often adopted to solve the problem by truncating the search space. The viability of the methods becomes inefficient for large problem sizes as it is either far from the optimum or time consuming. In recent years, the research towards using DRL to solve COP has gained interest and has shown promising results in terms of solution quality and computational efficiency. In this work, we provide an novel approach to solve the JSSP examining the objectives generalization and solution effectiveness using DRL. In particular, we employ the PPO algorithm that adopts the policy-gradient paradigm that is found to perform well in the constrained dispatching of jobs. We incorporated an OSM in the environment to achieve better generalized learning of the problem. The performance of the presented approach is analyzed in depth by using a set of available benchmark instances and comparing our results with the work of other groups.
Guiding Energy-based Models via Contrastive Latent Variables
Mar 06, 2023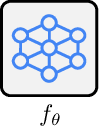


An energy-based model (EBM) is a popular generative framework that offers both explicit density and architectural flexibility, but training them is difficult since it is often unstable and time-consuming. In recent years, various training techniques have been developed, e.g., better divergence measures or stabilization in MCMC sampling, but there often exists a large gap between EBMs and other generative frameworks like GANs in terms of generation quality. In this paper, we propose a novel and effective framework for improving EBMs via contrastive representation learning (CRL). To be specific, we consider representations learned by contrastive methods as the true underlying latent variable. This contrastive latent variable could guide EBMs to understand the data structure better, so it can improve and accelerate EBM training significantly. To enable the joint training of EBM and CRL, we also design a new class of latent-variable EBMs for learning the joint density of data and the contrastive latent variable. Our experimental results demonstrate that our scheme achieves lower FID scores, compared to prior-art EBM methods (e.g., additionally using variational autoencoders or diffusion techniques), even with significantly faster and more memory-efficient training. We also show conditional and compositional generation abilities of our latent-variable EBMs as their additional benefits, even without explicit conditional training. The code is available at https://github.com/hankook/CLEL.
Joint On-Manifold Gravity and Accelerometer Intrinsics Estimation
Mar 06, 2023
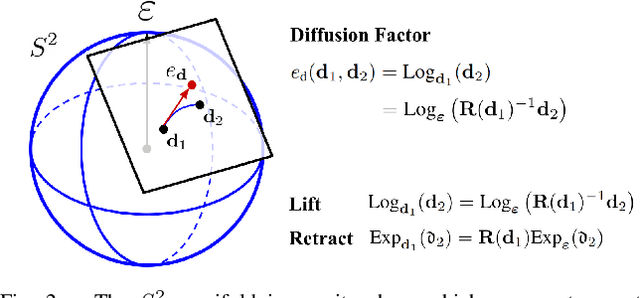
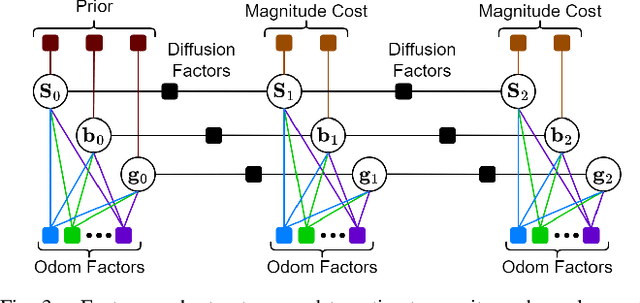
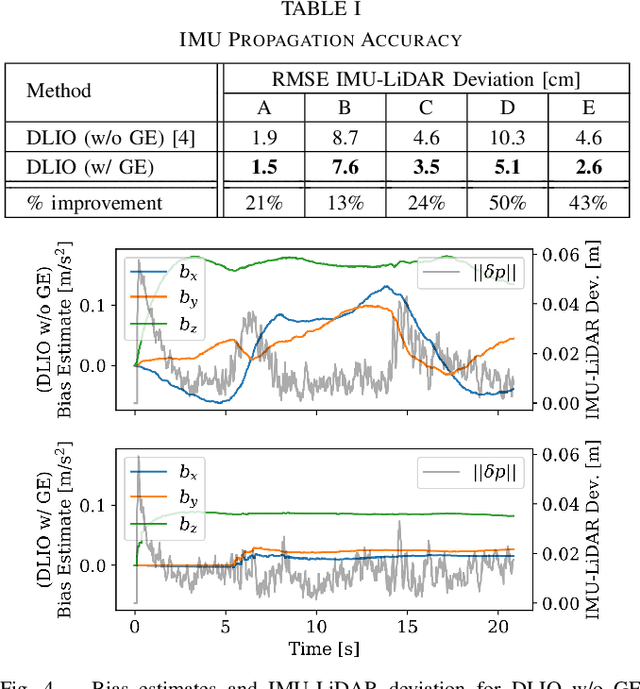
Aligning a robot's trajectory or map to the inertial frame is a critical capability that is often difficult to do accurately even though inertial measurement units (IMUs) can observe absolute roll and pitch with respect to gravity. Accelerometer biases and scale factor errors from the IMU's initial calibration are often the major source of inaccuracies when aligning the robot's odometry frame with the inertial frame, especially for low-grade IMUs. Practically, one would simultaneously estimate the true gravity vector, accelerometer biases, and scale factor to improve measurement quality but these quantities are not observable unless the IMU is sufficiently excited. While several methods estimate accelerometer bias and gravity, they do not explicitly address the observability issue nor do they estimate scale factor. We present a fixed-lag factor-graph-based estimator to address both of these issues. In addition to estimating accelerometer scale factor, our method mitigates limited observability by optimizing over a time window an order of magnitude larger than existing methods with significantly lower computational burden. The proposed method, which estimates accelerometer intrinsics and gravity separately from the other states, is enabled by a novel, velocity-agnostic measurement model for intrinsics and gravity, as well as a new method for gravity vector optimization on S2. Accurate IMU state prediction, gravity-alignment, and roll/pitch drift correction are experimentally demonstrated on public and self-collected datasets in diverse environments.