 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Membership Inference Attacks against Diffusion Models
Feb 07, 2023
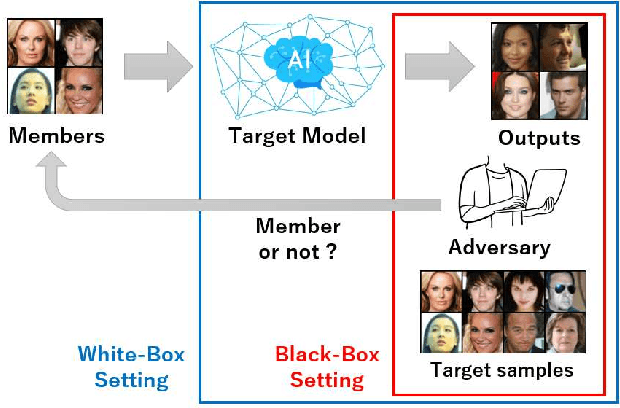
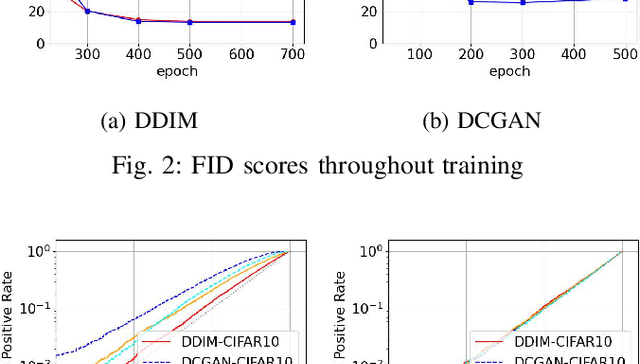
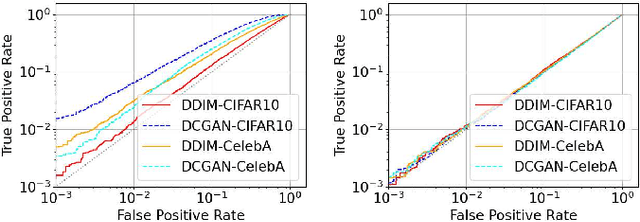
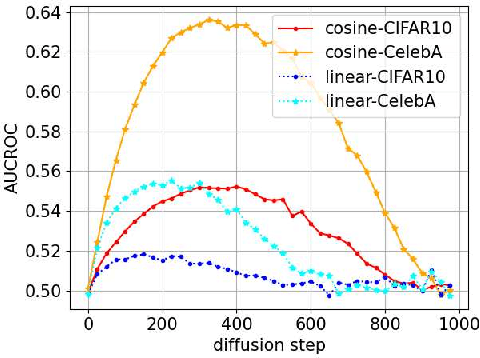
Diffusion models have attracted attention in recent years as innovative generative models. In this paper, we investigate whether a diffusion model is resistant to a membership inference attack, which evaluates the privacy leakage of a machine learning model. We primarily discuss the diffusion model from the standpoints of comparison with a generative adversarial network (GAN) as conventional models and hyperparameters unique to the diffusion model, i.e., time steps, sampling steps, and sampling variances. We conduct extensive experiments with DDIM as a diffusion model and DCGAN as a GAN on the CelebA and CIFAR-10 datasets in both white-box and black-box settings and then confirm if the diffusion model is comparably resistant to a membership inference attack as GAN. Next, we demonstrate that the impact of time steps is significant and intermediate steps in a noise schedule are the most vulnerable to the attack. We also found two key insights through further analysis. First, we identify that DDIM is vulnerable to the attack for small sample sizes instead of achieving a lower FID. Second, sampling steps in hyperparameters are important for resistance to the attack, whereas the impact of sampling variances is quite limited.
Online Reinforcement Learning with Uncertain Episode Lengths
Feb 07, 2023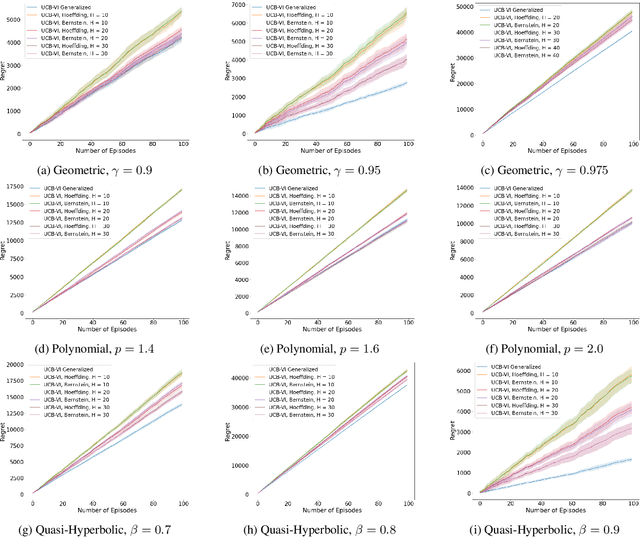
Existing episodic reinforcement algorithms assume that the length of an episode is fixed across time and known a priori. In this paper, we consider a general framework of episodic reinforcement learning when the length of each episode is drawn from a distribution. We first establish that this problem is equivalent to online reinforcement learning with general discounting where the learner is trying to optimize the expected discounted sum of rewards over an infinite horizon, but where the discounting function is not necessarily geometric. We show that minimizing regret with this new general discounting is equivalent to minimizing regret with uncertain episode lengths. We then design a reinforcement learning algorithm that minimizes regret with general discounting but acts for the setting with uncertain episode lengths. We instantiate our general bound for different types of discounting, including geometric and polynomial discounting. We also show that we can obtain similar regret bounds even when the uncertainty over the episode lengths is unknown, by estimating the unknown distribution over time. Finally, we compare our learning algorithms with existing value-iteration based episodic RL algorithms in a grid-world environment.
Multiscale Graph Neural Network Autoencoders for Interpretable Scientific Machine Learning
Feb 13, 2023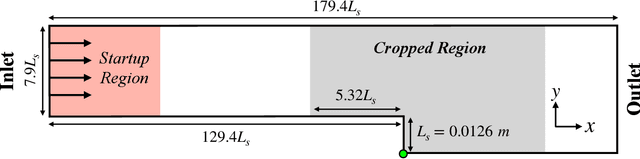
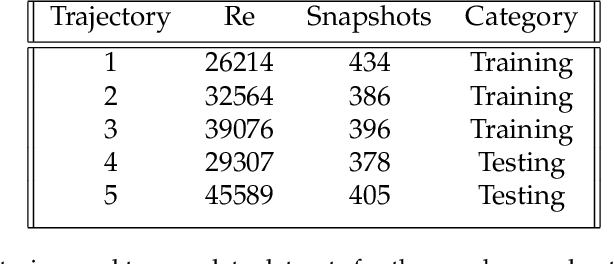
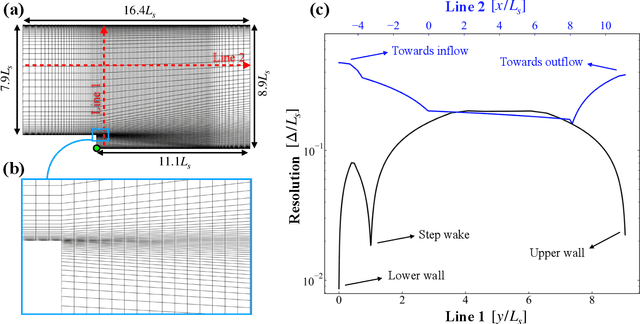
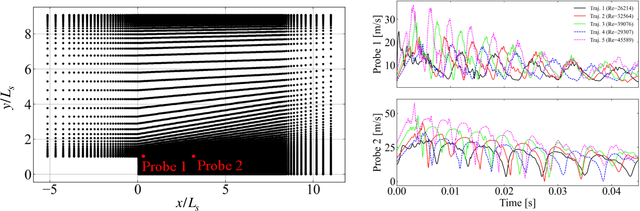
The goal of this work is to address two limitations in autoencoder-based models: latent space interpretability and compatibility with unstructured meshes. This is accomplished here with the development of a novel graph neural network (GNN) autoencoding architecture with demonstrations on complex fluid flow applications. To address the first goal of interpretability, the GNN autoencoder achieves reduction in the number nodes in the encoding stage through an adaptive graph reduction procedure. This reduction procedure essentially amounts to flowfield-conditioned node sampling and sensor identification, and produces interpretable latent graph representations tailored to the flowfield reconstruction task in the form of so-called masked fields. These masked fields allow the user to (a) visualize where in physical space a given latent graph is active, and (b) interpret the time-evolution of the latent graph connectivity in accordance with the time-evolution of unsteady flow features (e.g. recirculation zones, shear layers) in the domain. To address the goal of unstructured mesh compatibility, the autoencoding architecture utilizes a series of multi-scale message passing (MMP) layers, each of which models information exchange among node neighborhoods at various lengthscales. The MMP layer, which augments standard single-scale message passing with learnable coarsening operations, allows the decoder to more efficiently reconstruct the flowfield from the identified regions in the masked fields. Analysis of latent graphs produced by the autoencoder for various model settings are conducted using using unstructured snapshot data sourced from large-eddy simulations in a backward-facing step (BFS) flow configuration with an OpenFOAM-based flow solver at high Reynolds numbers.
Sparse Dimensionality Reduction Revisited
Feb 13, 2023The sparse Johnson-Lindenstrauss transform is one of the central techniques in dimensionality reduction. It supports embedding a set of $n$ points in $\mathbb{R}^d$ into $m=O(\varepsilon^{-2} \lg n)$ dimensions while preserving all pairwise distances to within $1 \pm \varepsilon$. Each input point $x$ is embedded to $Ax$, where $A$ is an $m \times d$ matrix having $s$ non-zeros per column, allowing for an embedding time of $O(s \|x\|_0)$. Since the sparsity of $A$ governs the embedding time, much work has gone into improving the sparsity $s$. The current state-of-the-art by Kane and Nelson (JACM'14) shows that $s = O(\varepsilon ^{-1} \lg n)$ suffices. This is almost matched by a lower bound of $s = \Omega(\varepsilon ^{-1} \lg n/\lg(1/\varepsilon))$ by Nelson and Nguyen (STOC'13). Previous work thus suggests that we have near-optimal embeddings. In this work, we revisit sparse embeddings and identify a loophole in the lower bound. Concretely, it requires $d \geq n$, which in many applications is unrealistic. We exploit this loophole to give a sparser embedding when $d = o(n)$, achieving $s = O(\varepsilon^{-1}(\lg n/\lg(1/\varepsilon)+\lg^{2/3}n \lg^{1/3} d))$. We also complement our analysis by strengthening the lower bound of Nelson and Nguyen to hold also when $d \ll n$, thereby matching the first term in our new sparsity upper bound. Finally, we also improve the sparsity of the best oblivious subspace embeddings for optimal embedding dimensionality.
The Hypervolume Indicator Hessian Matrix: Analytical Expression, Computational Time Complexity, and Sparsity
Nov 08, 2022

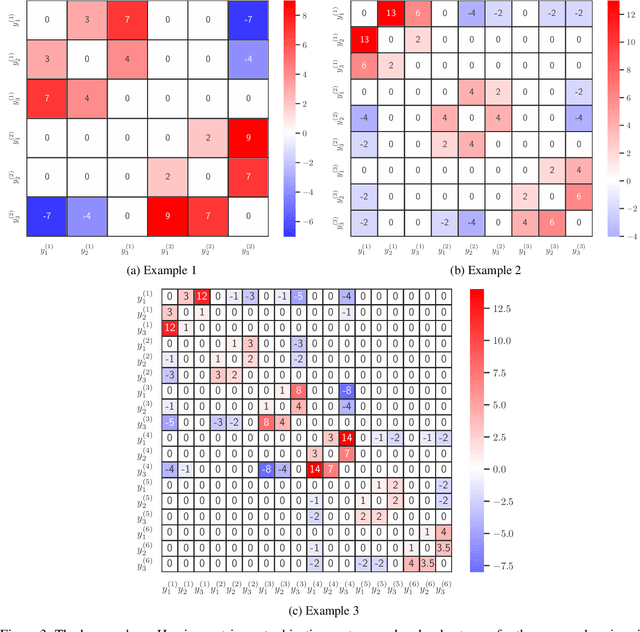
The problem of approximating the Pareto front of a multiobjective optimization problem can be reformulated as the problem of finding a set that maximizes the hypervolume indicator. This paper establishes the analytical expression of the Hessian matrix of the mapping from a (fixed size) collection of $n$ points in the $d$-dimensional decision space (or $m$ dimensional objective space) to the scalar hypervolume indicator value. To define the Hessian matrix, the input set is vectorized, and the matrix is derived by analytical differentiation of the mapping from a vectorized set to the hypervolume indicator. The Hessian matrix plays a crucial role in second-order methods, such as the Newton-Raphson optimization method, and it can be used for the verification of local optimal sets. So far, the full analytical expression was only established and analyzed for the relatively simple bi-objective case. This paper will derive the full expression for arbitrary dimensions ($m\geq2$ objective functions). For the practically important three-dimensional case, we also provide an asymptotically efficient algorithm with time complexity in $O(n\log n)$ for the exact computation of the Hessian Matrix' non-zero entries. We establish a sharp bound of $12m-6$ for the number of non-zero entries. Also, for the general $m$-dimensional case, a compact recursive analytical expression is established, and its algorithmic implementation is discussed. Also, for the general case, some sparsity results can be established; these results are implied by the recursive expression. To validate and illustrate the analytically derived algorithms and results, we provide a few numerical examples using Python and Mathematica implementations. Open-source implementations of the algorithms and testing data are made available as a supplement to this paper.
Adversarial Detection: Attacking Object Detection in Real Time
Sep 16, 2022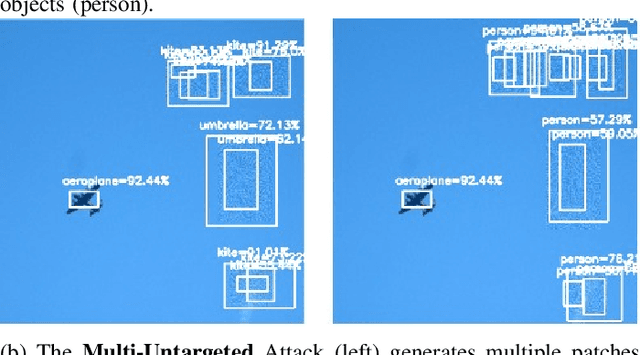

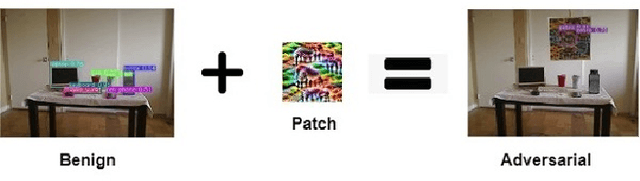
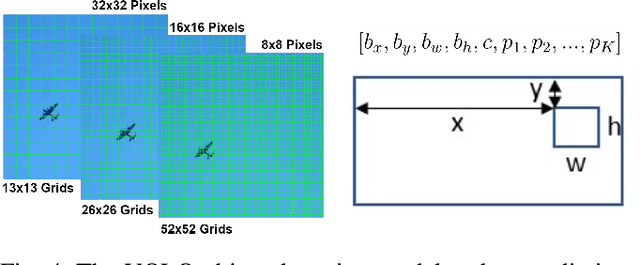
Intelligent robots rely on object detection models to perceive the environment. Following advances in deep learning security it has been revealed that object detection models are vulnerable to adversarial attacks. However, prior research primarily focuses on attacking static images or offline videos. Therefore, it is still unclear if such attacks could jeopardize real-world robotic applications in dynamic environments. This paper bridges this gap by presenting the first real-time online attack against object detection models. We devise three attacks that fabricate bounding boxes for nonexistent objects at desired locations. The attacks achieve a success rate of about 90% within about 20 iterations. The demo video is available at: https://youtu.be/zJZ1aNlXsMU.
Semi-unsupervised Learning for Time Series Classification
Jul 13, 2022


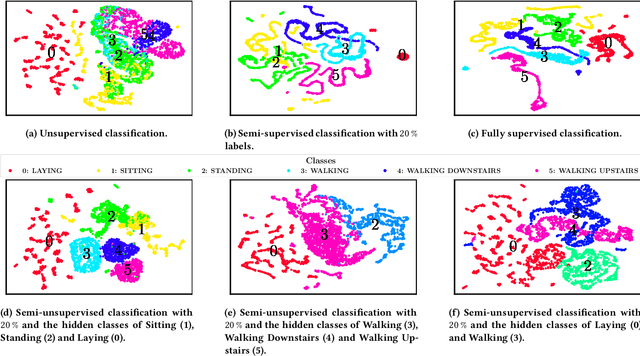
Time series are ubiquitous and therefore inherently hard to analyze and ultimately to label or cluster. With the rise of the Internet of Things (IoT) and its smart devices, data is collected in large amounts any given second. The collected data is rich in information, as one can detect accidents (e.g. cars) in real time, or assess injury/sickness over a given time span (e.g. health devices). Due to its chaotic nature and massive amounts of datapoints, timeseries are hard to label manually. Furthermore new classes within the data could emerge over time (contrary to e.g. handwritten digits), which would require relabeling the data. In this paper we present SuSL4TS, a deep generative Gaussian mixture model for semi-unsupervised learning, to classify time series data. With our approach we can alleviate manual labeling steps, since we can detect sparsely labeled classes (semi-supervised) and identify emerging classes hidden in the data (unsupervised). We demonstrate the efficacy of our approach with established time series classification datasets from different domains.
Sparse Bayesian Learning-Based 3D Spectrum Environment Map Construction-Sampling Optimization, Scenario-Dependent Dictionary Construction and Sparse Recovery
Feb 25, 2023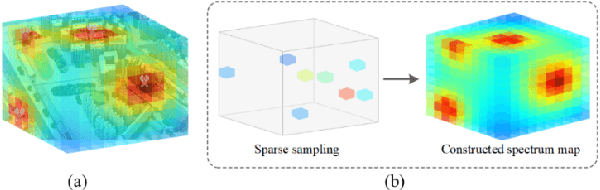
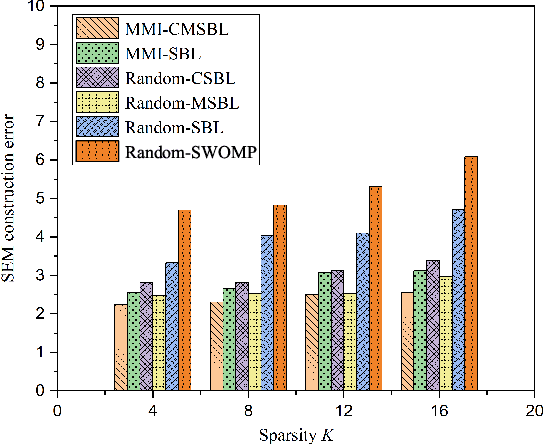
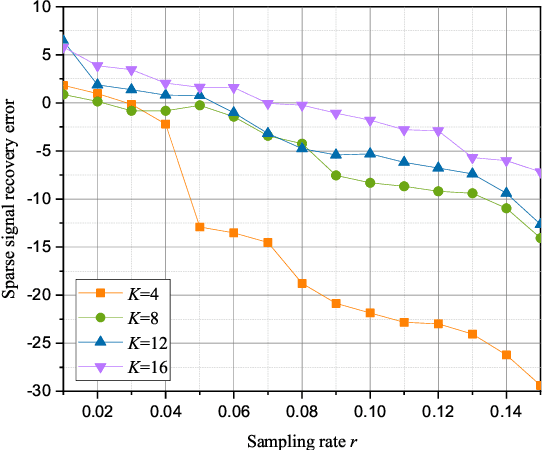

The spectrum environment map (SEM), which can visualize the information of invisible electromagnetic spectrum, is vital for monitoring, management, and security of spectrum resources in cognitive radio (CR) networks. In view of a limited number of spectrum sensors and constrained sampling time, this paper presents a new three-dimensional (3D) SEM construction scheme based on sparse Bayesian learning (SBL). Firstly, we construct a scenario-dependent channel dictionary matrix by considering the propagation characteristic of the interested scenario. To improve sampling efficiency, a maximum mutual information (MMI)-based optimization algorithm is developed for the layout of sampling sensors. Then, a maximum and minimum distance (MMD) clustering-based SBL algorithm is proposed to recover the spectrum data at the unsampled positions and construct the whole 3D SEM. We finally use the simulation data of the campus scenario to construct the 3D SEMs and compare the proposed method with the state-of-the-art. The recovery performance and the impact of different sparsity on the constructed SEMs are also analyzed. Numerical results show that the proposed scheme can reduce the required spectrum sensor number and has higher accuracy under the low sampling rate.
Kahramanmaras-Gaziantep, Turkiye Mw 7.8 Earthquake on February 6, 2023: Preliminary Report on Strong Ground Motion and Building Response Estimations
Feb 25, 2023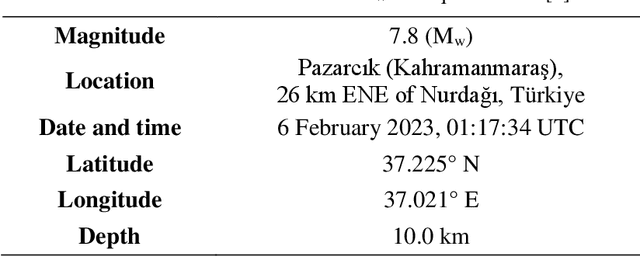
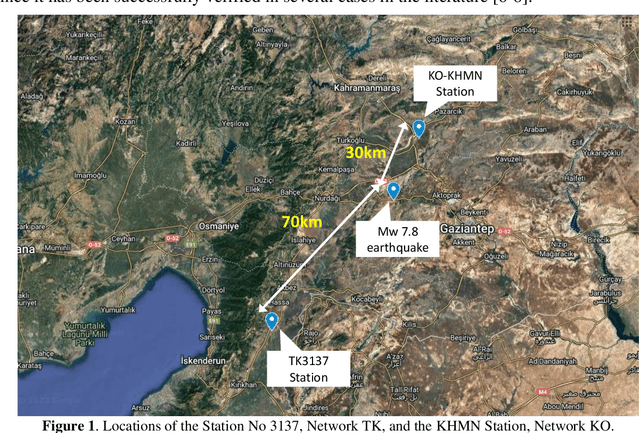
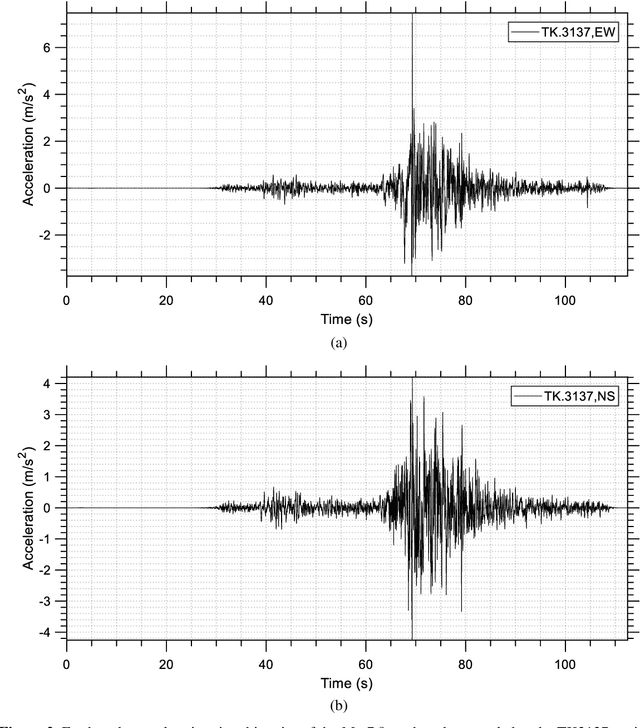
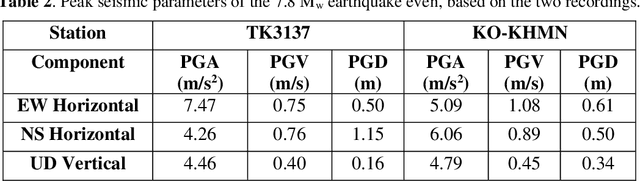
The effects on structures of the earthquake with magnitude 7.8 on the Richter scale (moment magnitude scale) which took place in Pazarcik, Kahramanmaras, Turkiye at 04:17 a.m. local time (01:17 UTC) on February 6, 2023, are investigated by processing suitable seismic records using the open-source software OpenSeismoMatlab. The earthquake had a maximum Mercalli intensity of XI (Extreme) and it was followed by a Mw 7.5 earthquake nine hours later, centered 95 km to the north-northeast from the first. Peak and cumulative seismic measures as well as elastic response spectra, constant ductility (or isoductile) response spectra, and incremental dynamic analysis curves were calculated for two representative earthquake records of the main event. Furthermore, the acceleration response spectra of a large set of records were compared to the acceleration design spectrum of the Turkish seismic code. Based on the study, it is concluded that the structures were overloaded far beyond their normal design levels. This, in combination with considerable vertical seismic components, was a contributing factor towards the collapse of many buildings in the region. Modifications of the Turkish seismic code are required so that higher spectral acceleration values can be prescribed, especially in earthquake-prone regions.
Efficient DMP generalization to time-varying targets, external signals and via-points
Dec 27, 2022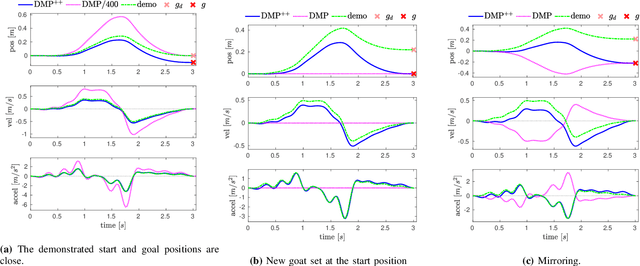
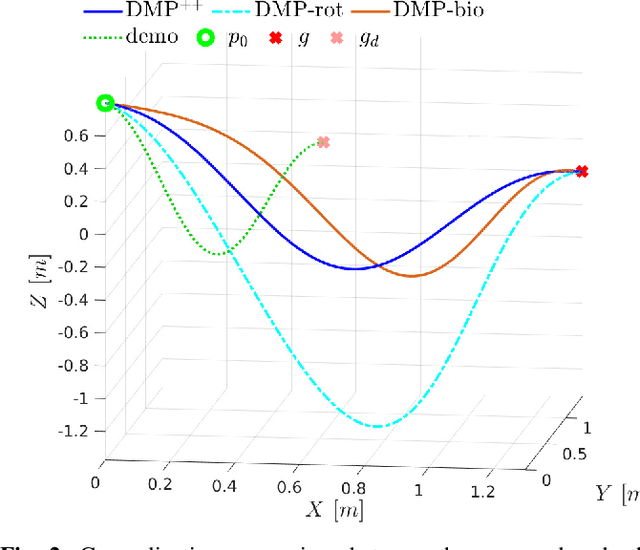
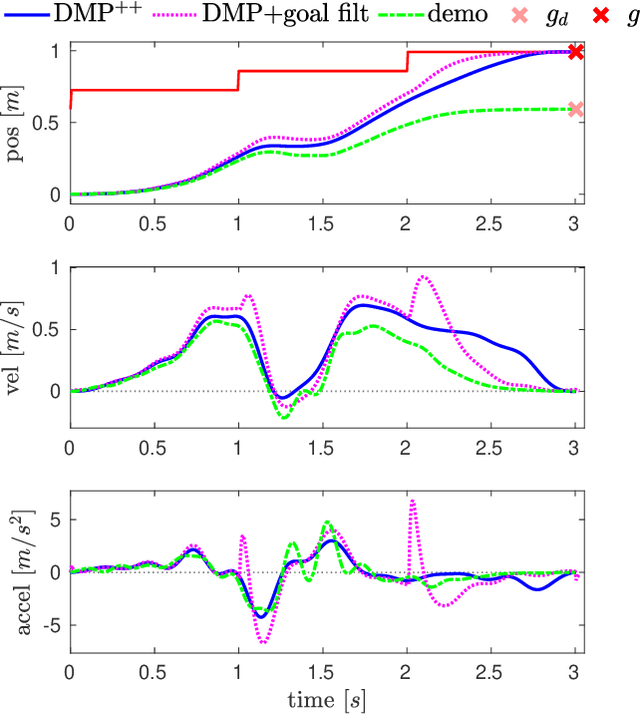
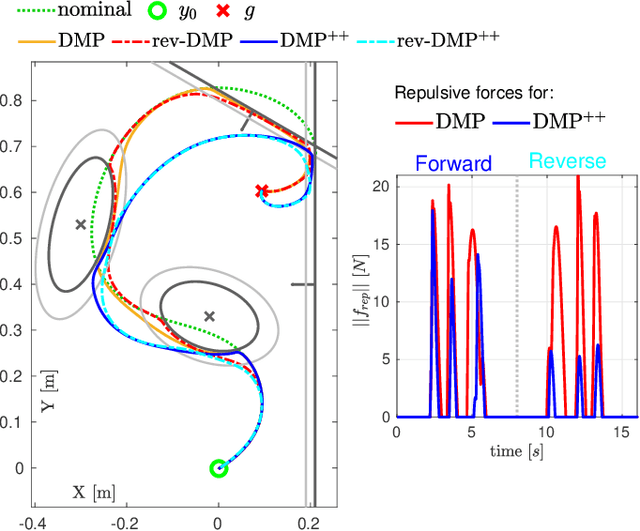
Dynamic Movement Primitives (DMP) have found remarkable applicability and success in various robotic tasks, which can be mainly attributed to their generalization and robustness properties. Nevertheless, their generalization is based only on the trajectory endpoints (initial and target position). Moreover, the spatial generalization of DMP is known to suffer from shortcomings like over-scaling and mirroring of the motion. In this work we propose a novel generalization scheme, based on optimizing online the DMP weights so that the acceleration profile and hence the underlying training trajectory pattern is preserved. This approach remedies the shortcomings of the classical DMP scaling and additionally allows the DMP to generalize also to intermediate points (via-points) and external signals (coupling terms), while preserving the training trajectory pattern. Extensive comparative simulations with the classical and other DMP variants are conducted, while experimental results validate the applicability and efficacy of the proposed method.