 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine Learning-Based Detection of Parkinson's Disease From Resting-State EEG: A Multi-Center Study
Mar 02, 2023

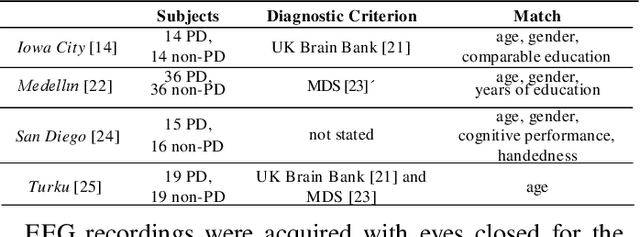


Resting-state EEG (rs-EEG) has been demonstrated to aid in Parkinson's disease (PD) diagnosis. In particular, the power spectral density (PSD) of low-frequency bands ({\delta} and {\theta}) and high-frequency bands ({\alpha} and \b{eta}) has been shown to be significantly different in patients with PD as compared to subjects without PD (non-PD). However, rs-EEG feature extraction and the interpretation thereof can be time-intensive and prone to examiner variability. Machine learning (ML) has the potential to automatize the analysis of rs-EEG recordings and provides a supportive tool for clinicians to ease their workload. In this work, we use rs-EEG recordings of 84 PD and 85 non-PD subjects pooled from four datasets obtained at different centers. We propose an end-to-end pipeline consisting of preprocessing, extraction of PSD features from clinically validated frequency bands, and feature selection before evaluating the classification ability of the features via ML algorithms to stratify between PD and non-PD subjects. Further, we evaluate the effect of feature harmonization, given the multi-center nature of the datasets. Our validation results show, on average, an improvement in PD detection ability (69.6% vs. 75.5% accuracy) by logistic regression when harmonizing the features and performing univariate feature selection (k = 202 features). Our final results show an average global accuracy of 72.2% with balanced accuracy results for all the centers included in the study: 60.6%, 68.7%, 77.7%, and 82.2%, respectively.
Grasping Core Rules of Time Series through Pure Models
Aug 15, 2022Time series underwent the transition from statistics to deep learning, as did many other machine learning fields. Although it appears that the accuracy has been increasing as the model is updated in a number of publicly available datasets, it typically only increases the scale by several times in exchange for a slight difference in accuracy. Through this experiment, we point out a different line of thinking, time series, especially long-term forecasting, may differ from other fields. It is not necessary to use extensive and complex models to grasp all aspects of time series, but to use pure models to grasp the core rules of time series changes. With this simple but effective idea, we created PureTS, a network with three pure linear layers that achieved state-of-the-art in 80% of the long sequence prediction tasks while being nearly the lightest model and having the fastest running speed. On this basis, we discuss the potential of pure linear layers in both phenomena and essence. The ability to understand the core law contributes to the high precision of long-distance prediction, and reasonable fluctuation prevents it from distorting the curve in multi-step prediction like mainstream deep learning models, which is summarized as a pure linear neural network that avoids over-fluctuating. Finally, we suggest the fundamental design standards for lightweight long-step time series tasks: input and output should try to have the same dimension, and the structure avoids fragmentation and complex operations.
HE-MAN -- Homomorphically Encrypted MAchine learning with oNnx models
Feb 16, 2023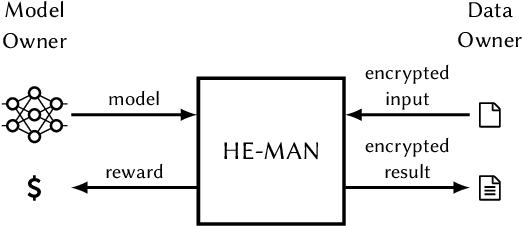
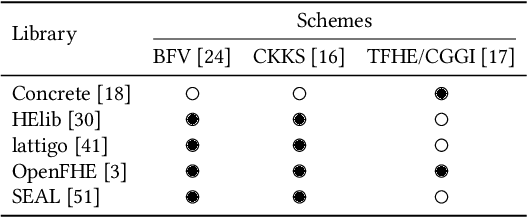
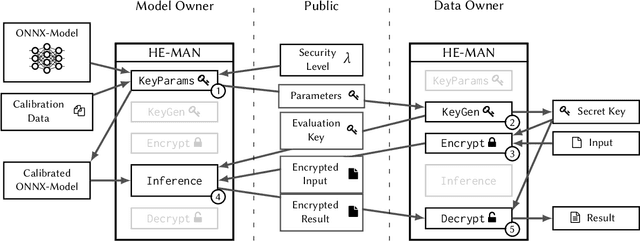

Machine learning (ML) algorithms are increasingly important for the success of products and services, especially considering the growing amount and availability of data. This also holds for areas handling sensitive data, e.g. applications processing medical data or facial images. However, people are reluctant to pass their personal sensitive data to a ML service provider. At the same time, service providers have a strong interest in protecting their intellectual property and therefore refrain from publicly sharing their ML model. Fully homomorphic encryption (FHE) is a promising technique to enable individuals using ML services without giving up privacy and protecting the ML model of service providers at the same time. Despite steady improvements, FHE is still hardly integrated in today's ML applications. We introduce HE-MAN, an open-source two-party machine learning toolset for privacy preserving inference with ONNX models and homomorphically encrypted data. Both the model and the input data do not have to be disclosed. HE-MAN abstracts cryptographic details away from the users, thus expertise in FHE is not required for either party. HE-MAN 's security relies on its underlying FHE schemes. For now, we integrate two different homomorphic encryption schemes, namely Concrete and TenSEAL. Compared to prior work, HE-MAN supports a broad range of ML models in ONNX format out of the box without sacrificing accuracy. We evaluate the performance of our implementation on different network architectures classifying handwritten digits and performing face recognition and report accuracy and latency of the homomorphically encrypted inference. Cryptographic parameters are automatically derived by the tools. We show that the accuracy of HE-MAN is on par with models using plaintext input while inference latency is several orders of magnitude higher compared to the plaintext case.
Exposure-Based Multi-Agent Inspection of a Tumbling Target Using Deep Reinforcement Learning
Feb 27, 2023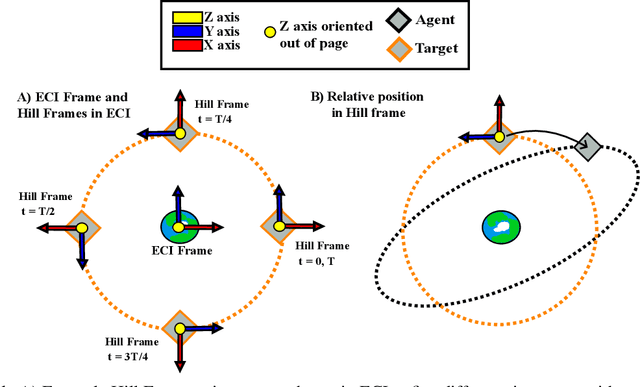

As space becomes more congested, on orbit inspection is an increasingly relevant activity whether to observe a defunct satellite for planning repairs or to de-orbit it. However, the task of on orbit inspection itself is challenging, typically requiring the careful coordination of multiple observer satellites. This is complicated by a highly nonlinear environment where the target may be unknown or moving unpredictably without time for continuous command and control from the ground. There is a need for autonomous, robust, decentralized solutions to the inspection task. To achieve this, we consider a hierarchical, learned approach for the decentralized planning of multi-agent inspection of a tumbling target. Our solution consists of two components: a viewpoint or high-level planner trained using deep reinforcement learning and a navigation planner handling point-to-point navigation between pre-specified viewpoints. We present a novel problem formulation and methodology that is suitable not only to reinforcement learning-derived robust policies, but extendable to unknown target geometries and higher fidelity information theoretic objectives received directly from sensor inputs. Operating under limited information, our trained multi-agent high-level policies successfully contextualize information within the global hierarchical environment and are correspondingly able to inspect over 90% of non-convex tumbling targets, even in the absence of additional agent attitude control.
Self-Supervised Pre-Training for Deep Image Prior-Based Robust PET Image Denoising
Feb 27, 2023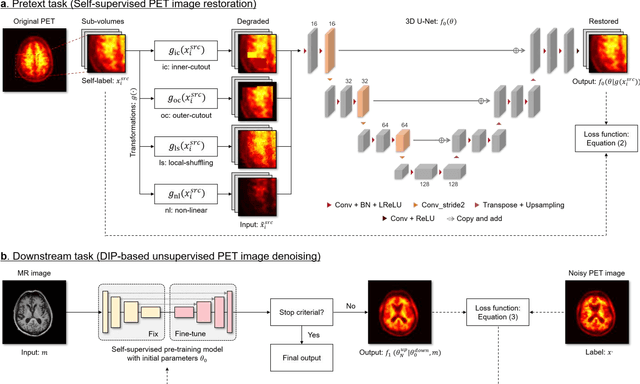
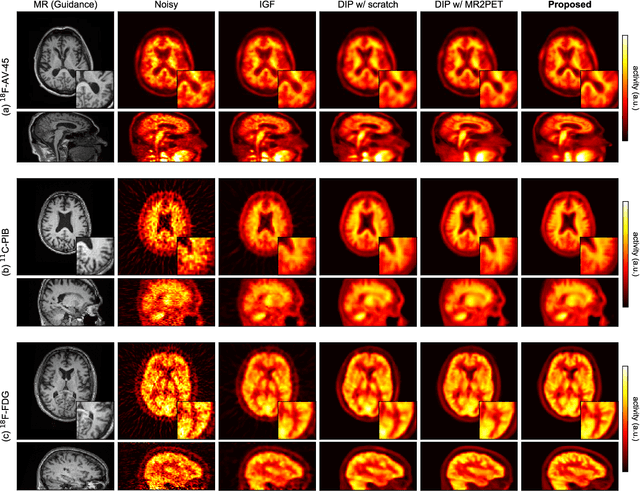
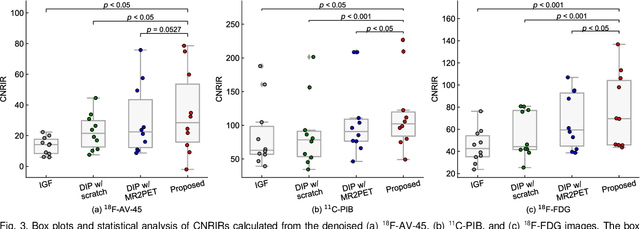

Deep image prior (DIP) has been successfully applied to positron emission tomography (PET) image restoration, enabling represent implicit prior using only convolutional neural network architecture without training dataset, whereas the general supervised approach requires massive low- and high-quality PET image pairs. To answer the increased need for PET imaging with DIP, it is indispensable to improve the performance of the underlying DIP itself. Here, we propose a self-supervised pre-training model to improve the DIP-based PET image denoising performance. Our proposed pre-training model acquires transferable and generalizable visual representations from only unlabeled PET images by restoring various degraded PET images in a self-supervised approach. We evaluated the proposed method using clinical brain PET data with various radioactive tracers ($^{18}$F-florbetapir, $^{11}$C-Pittsburgh compound-B, $^{18}$F-fluoro-2-deoxy-D-glucose, and $^{15}$O-CO$_{2}$) acquired from different PET scanners. The proposed method using the self-supervised pre-training model achieved robust and state-of-the-art denoising performance while retaining spatial details and quantification accuracy compared to other unsupervised methods and pre-training model. These results highlight the potential that the proposed method is particularly effective against rare diseases and probes and helps reduce the scan time or the radiotracer dose without affecting the patients.
FInC Flow: Fast and Invertible $k \times k$ Convolutions for Normalizing Flows
Jan 23, 2023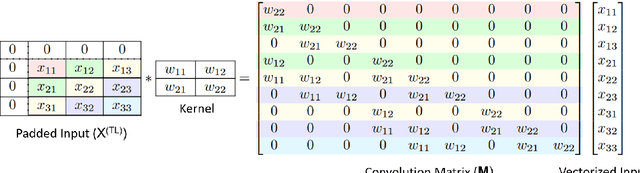

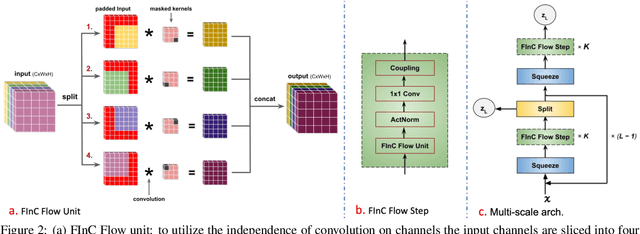
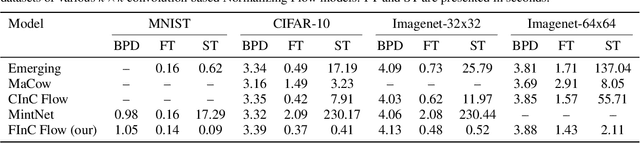
Invertible convolutions have been an essential element for building expressive normalizing flow-based generative models since their introduction in Glow. Several attempts have been made to design invertible $k \times k$ convolutions that are efficient in training and sampling passes. Though these attempts have improved the expressivity and sampling efficiency, they severely lagged behind Glow which used only $1 \times 1$ convolutions in terms of sampling time. Also, many of the approaches mask a large number of parameters of the underlying convolution, resulting in lower expressivity on a fixed run-time budget. We propose a $k \times k$ convolutional layer and Deep Normalizing Flow architecture which i.) has a fast parallel inversion algorithm with running time O$(n k^2)$ ($n$ is height and width of the input image and k is kernel size), ii.) masks the minimal amount of learnable parameters in a layer. iii.) gives better forward pass and sampling times comparable to other $k \times k$ convolution-based models on real-world benchmarks. We provide an implementation of the proposed parallel algorithm for sampling using our invertible convolutions on GPUs. Benchmarks on CIFAR-10, ImageNet, and CelebA datasets show comparable performance to previous works regarding bits per dimension while significantly improving the sampling time.
* accepted: VISAPP'23
Beyond Exponentially Fast Mixing in Average-Reward Reinforcement Learning via Multi-Level Monte Carlo Actor-Critic
Jan 28, 2023
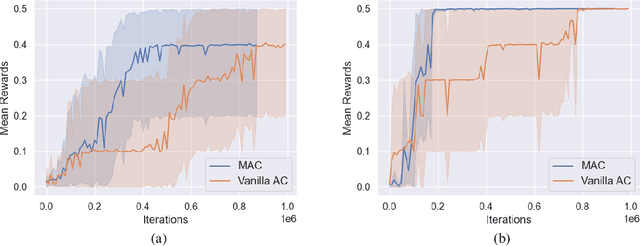

Many existing reinforcement learning (RL) methods employ stochastic gradient iteration on the back end, whose stability hinges upon a hypothesis that the data-generating process mixes exponentially fast with a rate parameter that appears in the step-size selection. Unfortunately, this assumption is violated for large state spaces or settings with sparse rewards, and the mixing time is unknown, making the step size inoperable. In this work, we propose an RL methodology attuned to the mixing time by employing a multi-level Monte Carlo estimator for the critic, the actor, and the average reward embedded within an actor-critic (AC) algorithm. This method, which we call \textbf{M}ulti-level \textbf{A}ctor-\textbf{C}ritic (MAC), is developed especially for infinite-horizon average-reward settings and neither relies on oracle knowledge of the mixing time in its parameter selection nor assumes its exponential decay; it, therefore, is readily applicable to applications with slower mixing times. Nonetheless, it achieves a convergence rate comparable to the state-of-the-art AC algorithms. We experimentally show that these alleviated restrictions on the technical conditions required for stability translate to superior performance in practice for RL problems with sparse rewards.
Real-Time Cattle Interaction Recognition via Triple-stream Network
Sep 06, 2022
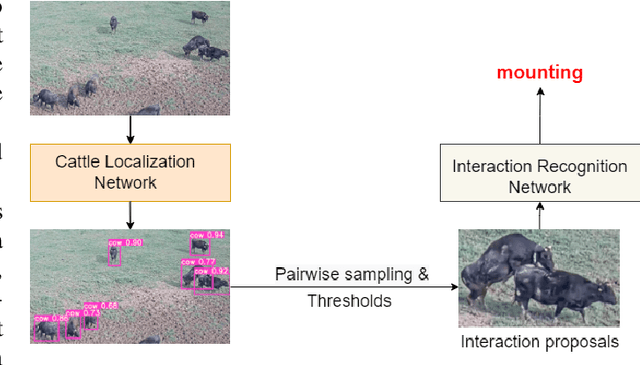
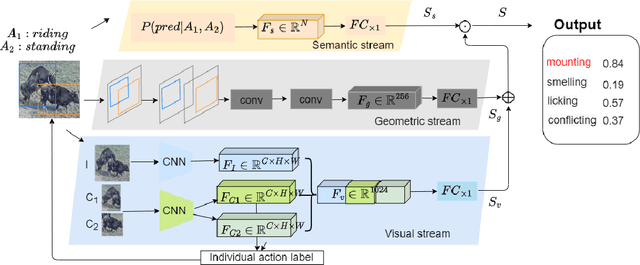
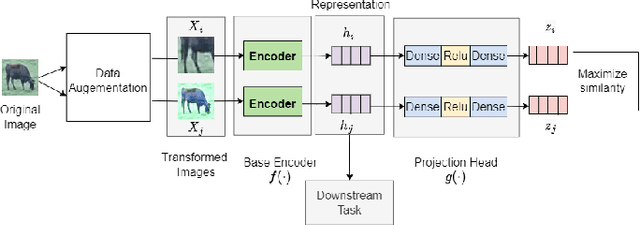
In stockbreeding of beef cattle, computer vision-based approaches have been widely employed to monitor cattle conditions (e.g. the physical, physiology, and health). To this end, the accurate and effective recognition of cattle action is a prerequisite. Generally, most existing models are confined to individual behavior that uses video-based methods to extract spatial-temporal features for recognizing the individual actions of each cattle. However, there is sociality among cattle and their interaction usually reflects important conditions, e.g. estrus, and also video-based method neglects the real-time capability of the model. Based on this, we tackle the challenging task of real-time recognizing interactions between cattle in a single frame in this paper. The pipeline of our method includes two main modules: Cattle Localization Network and Interaction Recognition Network. At every moment, cattle localization network outputs high-quality interaction proposals from every detected cattle and feeds them into the interaction recognition network with a triple-stream architecture. Such a triple-stream network allows us to fuse different features relevant to recognizing interactions. Specifically, the three kinds of features are a visual feature that extracts the appearance representation of interaction proposals, a geometric feature that reflects the spatial relationship between cattle, and a semantic feature that captures our prior knowledge of the relationship between the individual action and interaction of cattle. In addition, to solve the problem of insufficient quantity of labeled data, we pre-train the model based on self-supervised learning. Qualitative and quantitative evaluation evidences the performance of our framework as an effective method to recognize cattle interaction in real time.
Efficient XAI Techniques: A Taxonomic Survey
Feb 07, 2023
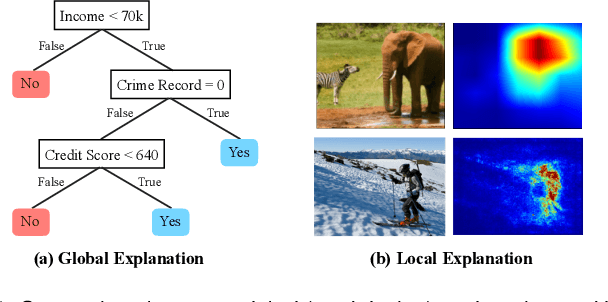
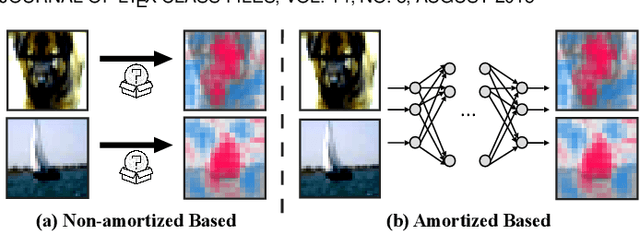
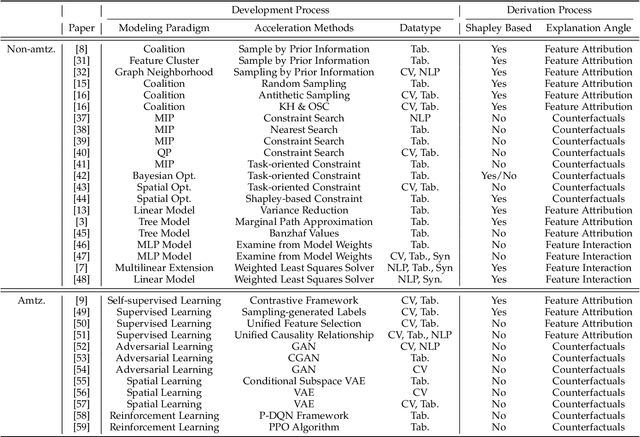
Recently, there has been a growing demand for the deployment of Explainable Artificial Intelligence (XAI) algorithms in real-world applications. However, traditional XAI methods typically suffer from a high computational complexity problem, which discourages the deployment of real-time systems to meet the time-demanding requirements of real-world scenarios. Although many approaches have been proposed to improve the efficiency of XAI methods, a comprehensive understanding of the achievements and challenges is still needed. To this end, in this paper we provide a review of efficient XAI. Specifically, we categorize existing techniques of XAI acceleration into efficient non-amortized and efficient amortized methods. The efficient non-amortized methods focus on data-centric or model-centric acceleration upon each individual instance. In contrast, amortized methods focus on learning a unified distribution of model explanations, following the predictive, generative, or reinforcement frameworks, to rapidly derive multiple model explanations. We also analyze the limitations of an efficient XAI pipeline from the perspectives of the training phase, the deployment phase, and the use scenarios. Finally, we summarize the challenges of deploying XAI acceleration methods to real-world scenarios, overcoming the trade-off between faithfulness and efficiency, and the selection of different acceleration methods.
Membership Inference Attacks against Diffusion Models
Feb 07, 2023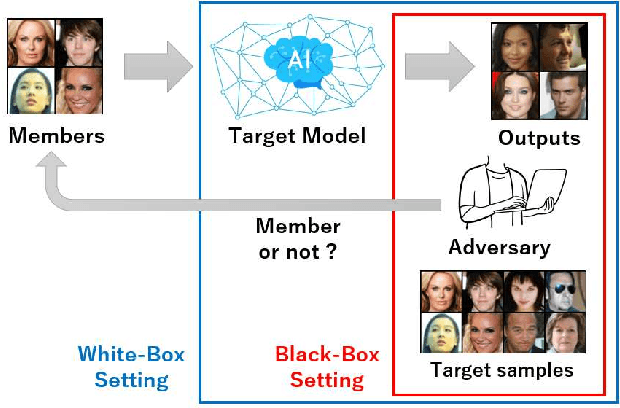
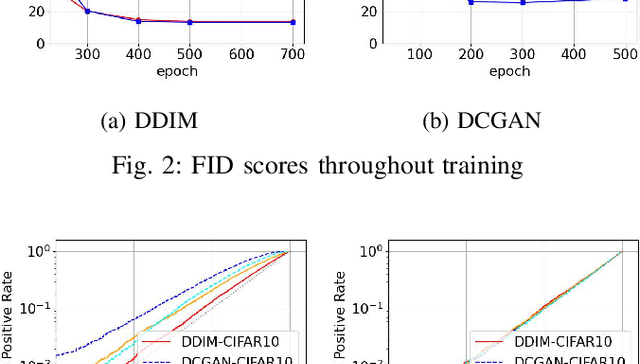
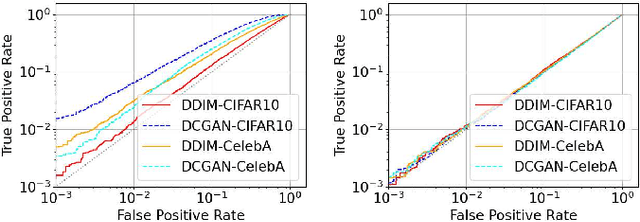
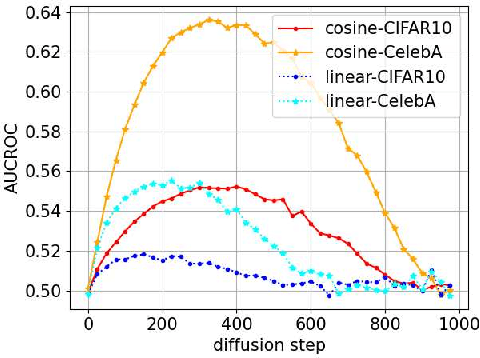
Diffusion models have attracted attention in recent years as innovative generative models. In this paper, we investigate whether a diffusion model is resistant to a membership inference attack, which evaluates the privacy leakage of a machine learning model. We primarily discuss the diffusion model from the standpoints of comparison with a generative adversarial network (GAN) as conventional models and hyperparameters unique to the diffusion model, i.e., time steps, sampling steps, and sampling variances. We conduct extensive experiments with DDIM as a diffusion model and DCGAN as a GAN on the CelebA and CIFAR-10 datasets in both white-box and black-box settings and then confirm if the diffusion model is comparably resistant to a membership inference attack as GAN. Next, we demonstrate that the impact of time steps is significant and intermediate steps in a noise schedule are the most vulnerable to the attack. We also found two key insights through further analysis. First, we identify that DDIM is vulnerable to the attack for small sample sizes instead of achieving a lower FID. Second, sampling steps in hyperparameters are important for resistance to the attack, whereas the impact of sampling variances is quite limited.