 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Redundancy Resolution Method for Free-Floating Underwater Manipulation
Feb 28, 2023


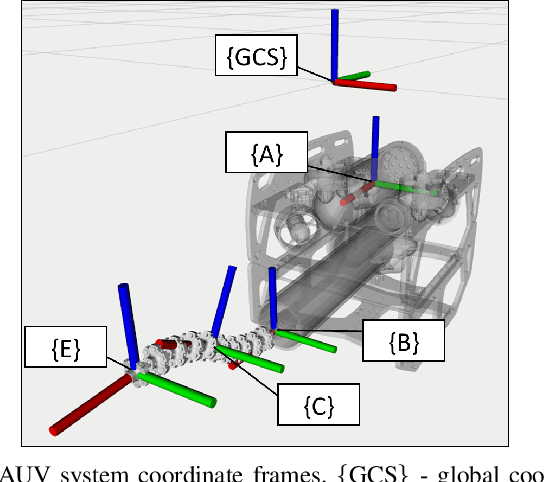
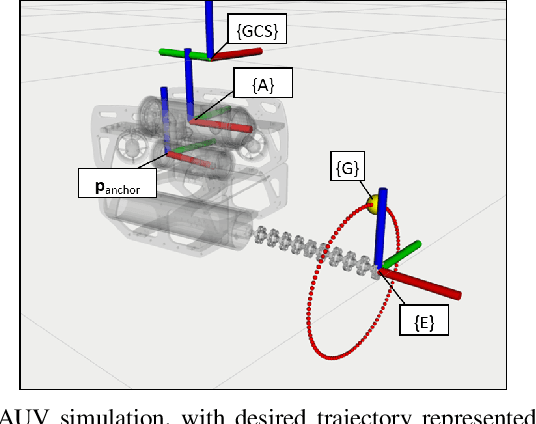
Underwater manipulation with free-floating autonomous underwater vehicles (AUVs) is an under-explored research area that this paper addresses. The open-source mechanical, electrical, and software designs of an AUV and continuum manipulator system are provided as a platform for performing this research. The underwater robot system has high degrees of freedom including the vehicle body motion and the manipulator joints. Therefore, when performing a manipulation task, the robot has many different potential trajectories which satisfy the task constraints, and this kinematic redundancy needs to be resolved. This paper provides a method for solving the redundancy problem. The relevant kinematic models are derived in order to build an algorithm to calculate desired joint velocities in real time. Different methods to optimize the algorithm for specific tasks are proposed, including a basic weighting method and a gradient projection method to optimize a user-defined objective function. Both simulation and experimental results are analyzed to assess the performance of this algorithm.
Embedded light-weight approach for safe landing in populated areas
Feb 28, 2023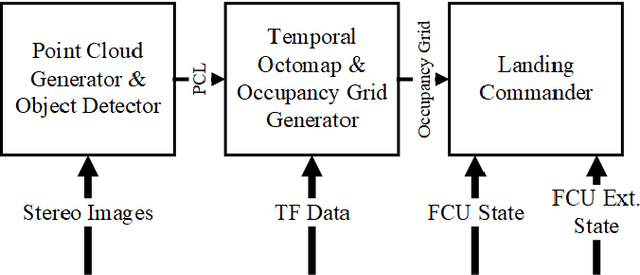


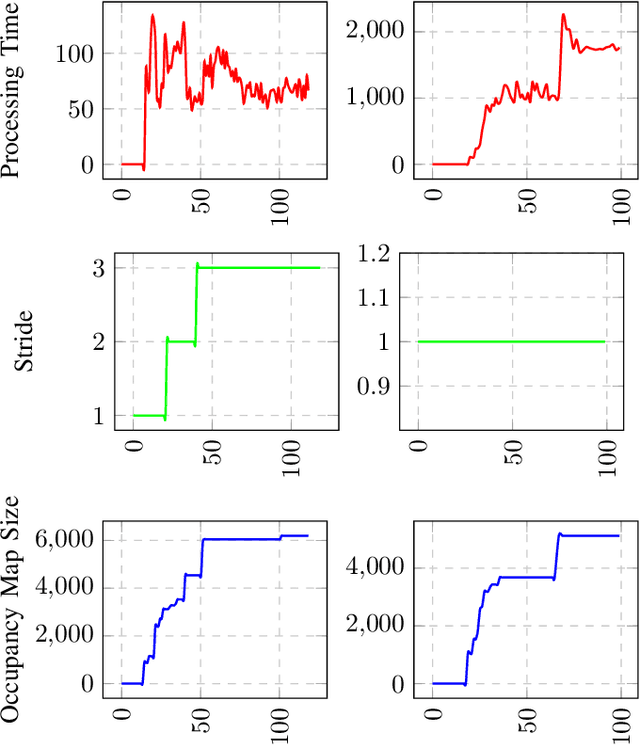
Landing safety is a challenge heavily engaging the research community recently, due to the increasing interest in applications availed by aerial vehicles. In this paper, we propose a landing safety pipeline based on state of the art object detectors and OctoMap. First, a point cloud of surface obstacles is generated, which is then inserted in an OctoMap. The unoccupied areas are identified, thus resulting to a list of safe landing points. Due to the low inference time achieved by state of the art object detectors and the efficient point cloud manipulation using OctoMap, it is feasible for our approach to deploy on low-weight embedded systems. The proposed pipeline has been evaluated in many simulation scenarios, varying in people density, number, and movement. Simulations were executed with an Nvidia Jetson Nano in the loop to confirm the pipeline's performance and robustness in a low computing power hardware. The experiments yielded promising results with a 95% success rate.
Interpretable and Intervenable Ultrasonography-based Machine Learning Models for Pediatric Appendicitis
Feb 28, 2023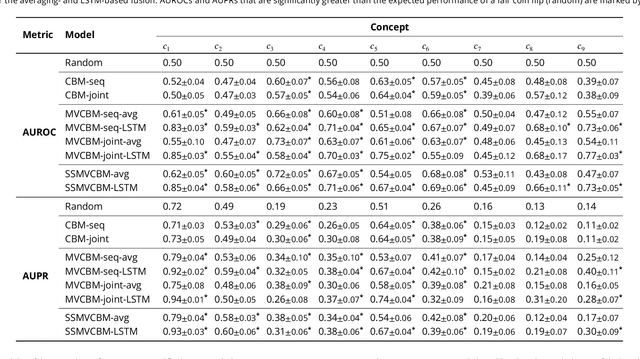
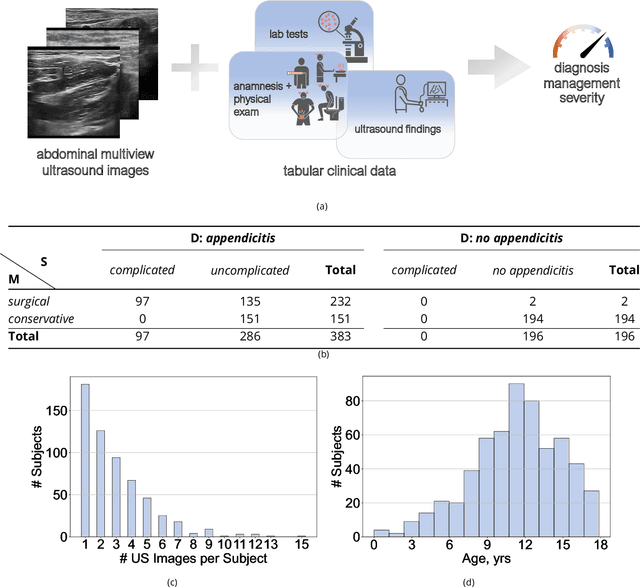
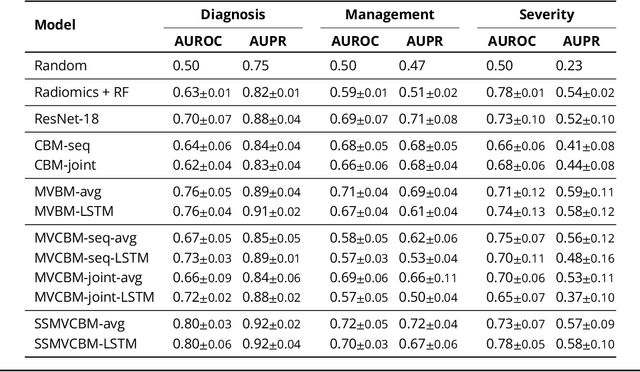
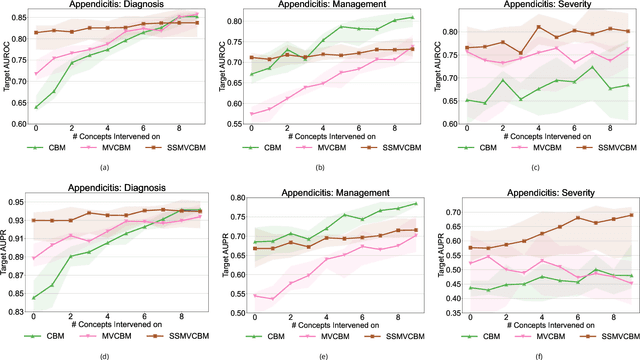
Appendicitis is among the most frequent reasons for pediatric abdominal surgeries. With recent advances in machine learning, data-driven decision support could help clinicians diagnose and manage patients while reducing the number of non-critical surgeries. Previous decision support systems for appendicitis focused on clinical, laboratory, scoring and computed tomography data, mainly ignoring abdominal ultrasound, a noninvasive and readily available diagnostic modality. To this end, we developed and validated interpretable machine learning models for predicting the diagnosis, management and severity of suspected appendicitis using ultrasound images. Our models were trained on a dataset comprising 579 pediatric patients with 1709 ultrasound images accompanied by clinical and laboratory data. Our methodological contribution is the generalization of concept bottleneck models to prediction problems with multiple views and incomplete concept sets. Notably, such models lend themselves to interpretation and interaction via high-level concepts understandable to clinicians without sacrificing performance or requiring time-consuming image annotation when deployed.
The Hypervolume Indicator Hessian Matrix: Analytical Expression, Computational Time Complexity, and Sparsity
Nov 15, 2022

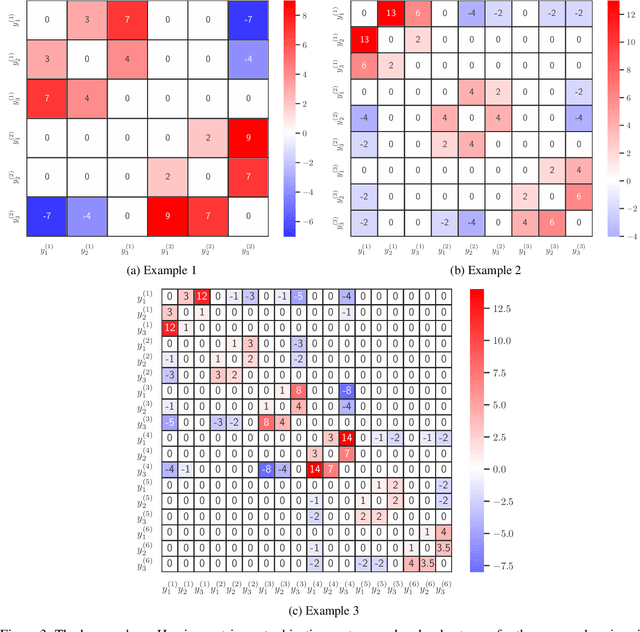
The problem of approximating the Pareto front of a multiobjective optimization problem can be reformulated as the problem of finding a set that maximizes the hypervolume indicator. This paper establishes the analytical expression of the Hessian matrix of the mapping from a (fixed size) collection of $n$ points in the $d$-dimensional decision space (or $m$ dimensional objective space) to the scalar hypervolume indicator value. To define the Hessian matrix, the input set is vectorized, and the matrix is derived by analytical differentiation of the mapping from a vectorized set to the hypervolume indicator. The Hessian matrix plays a crucial role in second-order methods, such as the Newton-Raphson optimization method, and it can be used for the verification of local optimal sets. So far, the full analytical expression was only established and analyzed for the relatively simple bi-objective case. This paper will derive the full expression for arbitrary dimensions ($m\geq2$ objective functions). For the practically important three-dimensional case, we also provide an asymptotically efficient algorithm with time complexity in $O(n\log n)$ for the exact computation of the Hessian Matrix' non-zero entries. We establish a sharp bound of $12m-6$ for the number of non-zero entries. Also, for the general $m$-dimensional case, a compact recursive analytical expression is established, and its algorithmic implementation is discussed. Also, for the general case, some sparsity results can be established; these results are implied by the recursive expression. To validate and illustrate the analytically derived algorithms and results, we provide a few numerical examples using Python and Mathematica implementations. Open-source implementations of the algorithms and testing data are made available as a supplement to this paper.
Self-Supervised Learning for Modeling Gamma-ray Variability in Blazars
Feb 15, 2023
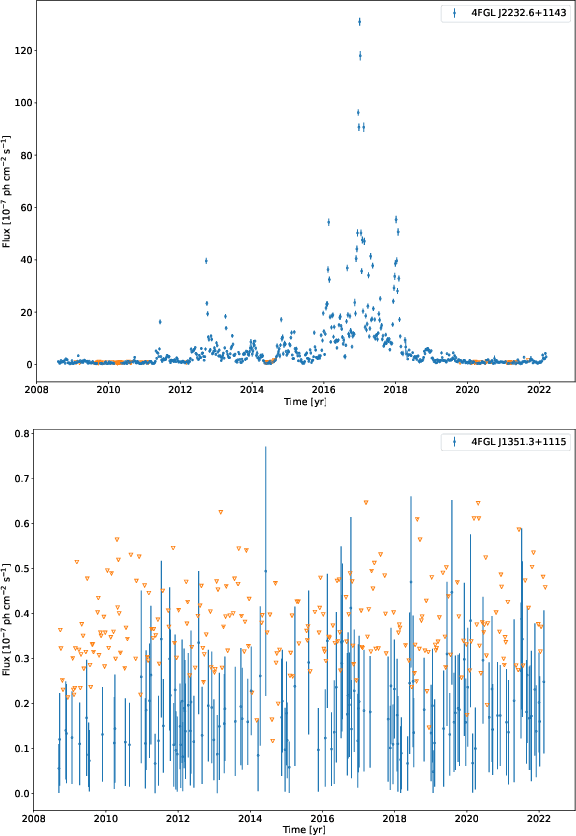
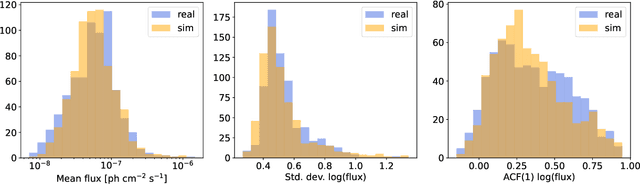
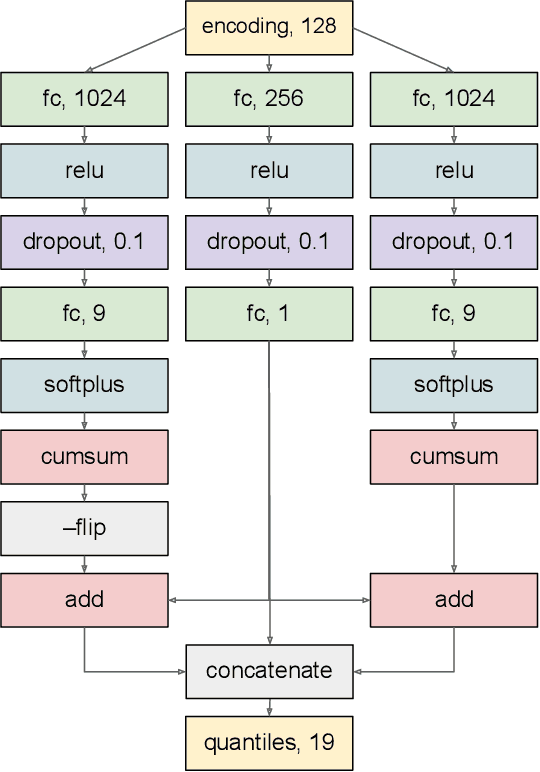
Blazars are active galactic nuclei with relativistic jets pointed almost directly at Earth. Blazars are characterized by strong, apparently stochastic flux variability at virtually all observed wavelengths and timescales, from minutes to years, the physical origin of which is still poorly understood. In the high-energy gamma-ray band, the Large Area Telescope aboard the Fermi space telescope (Fermi-LAT) has conducted regular monitoring of thousands of blazars since 2008. Deep learning can help uncover structure in gamma-ray blazars' complex variability patterns that traditional methods based on parametric statistical modeling or manual feature engineering may miss. In this work, we propose using a self-supervised Transformer encoder architecture to construct an effective representation of blazar gamma-ray variability. Measurement errors, upper limits, and missing data are accommodated using learned encodings. The model predicts a set of quantiles for the flux probability distribution at each time step, an architecture naturally suited for describing data generated by a stochastic process. As a proof of concept for how the model output can be analyzed to extract scientifically relevant information, a preliminary search for weekly-timescale time-reversal asymmetry in gamma-ray blazar light curves was conducted, finding no significant evidence for asymmetry.
Fast Blind Audio Copy-Move Detection and Localization Using Local Feature Tensors in Noise
Feb 15, 2023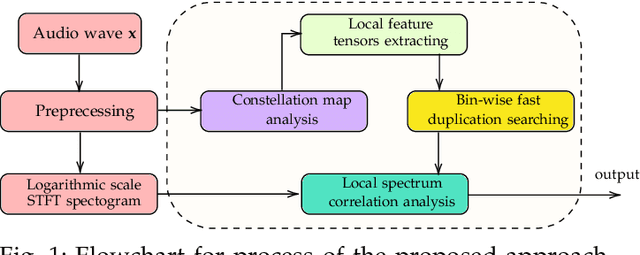
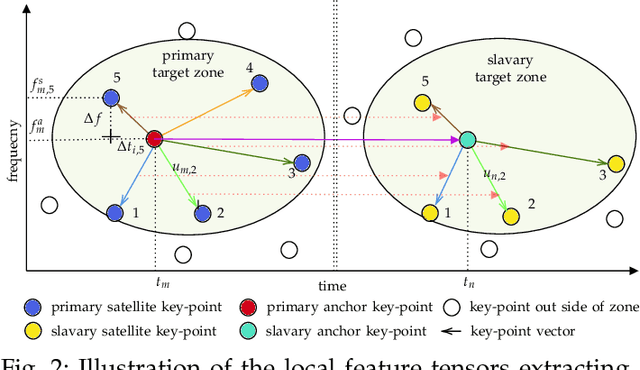
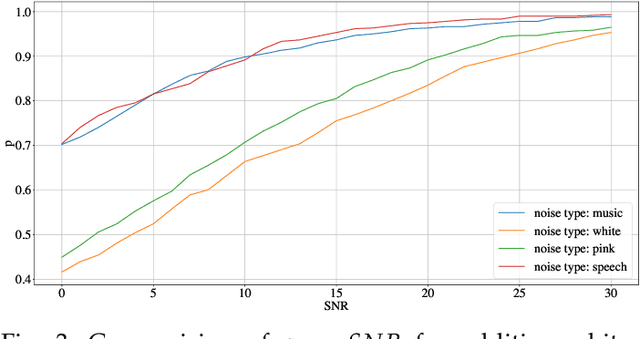
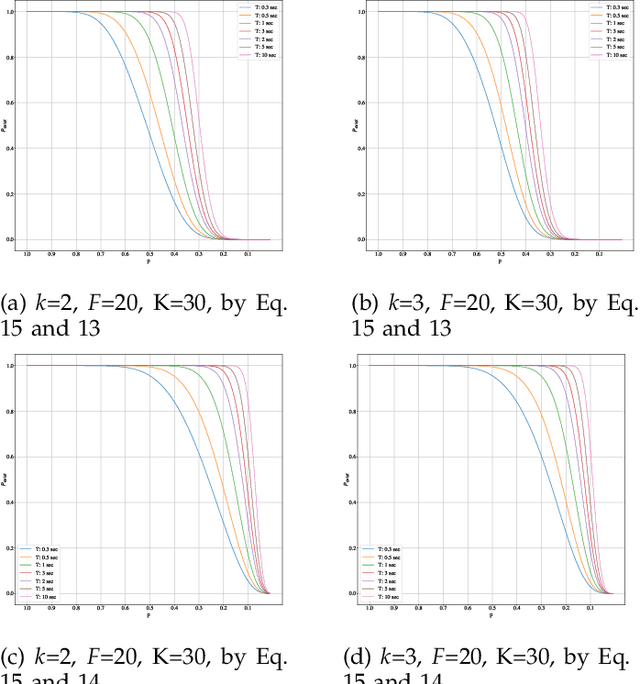
The increasing availability of audio editing software altering digital audios and their ease of use allows create forgeries at low cost. A copy-move forgery (CMF) is one of easiest and popular audio forgeries, which created by copying and pasting audio segments within the same audio, and potentially post-processing it. Three main approaches to audio copy-move detection exist nowadays: samples/frames comparison, acoustic features coherence searching and dynamic time warping. But these approaches will suffer from computational complexity and/or sensitive to noise and post-processing. In this paper, we propose a new local feature tensors-based copy-move detection algorithm that can be applied to transformed duplicates detection and localization problem to a special locality sensitive hash like procedure. The experimental results with massive online real-time audios datasets reveal that the proposed technique effectively determines and locating copy-move forgeries even on a forged speech segment are as short as fractional second. This method is also computational efficient and robust against the audios processed with severe nonlinear transformation, such as resampling, filtering, jsittering, compression and cropping, even contaminated with background noise and music. Hence, the proposed technique provides an efficient and reliable way of copy-move forgery detection that increases the credibility of audio in practical forensics applications
Feature-Based Time-Series Analysis in R using the theft Package
Aug 17, 2022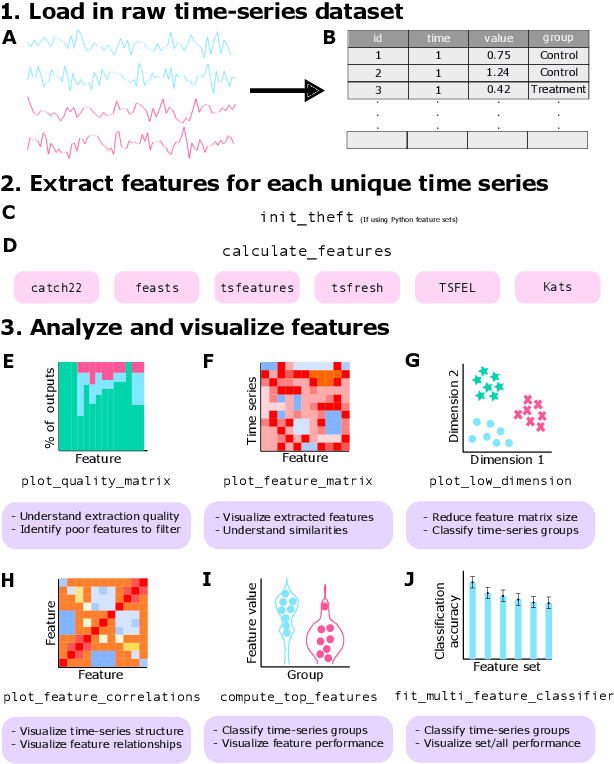
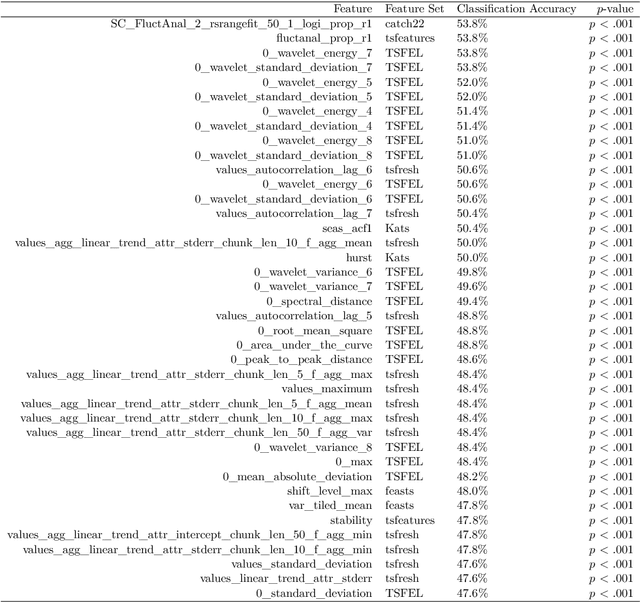
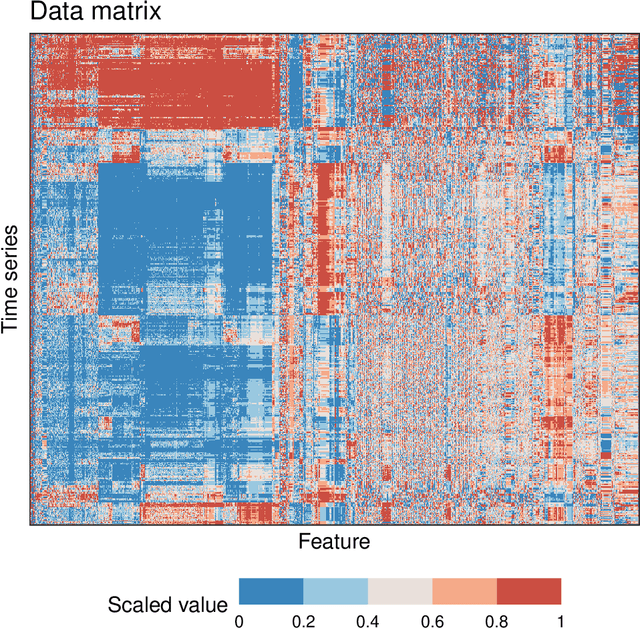
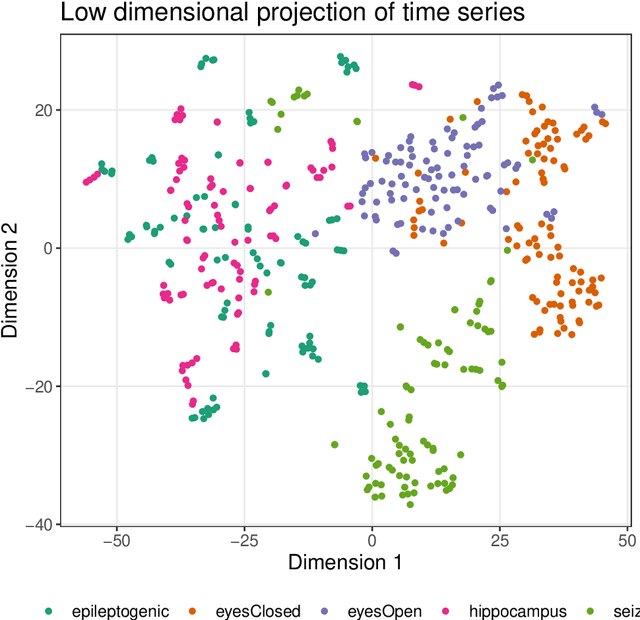
Time series are measured and analyzed across the sciences. One method of quantifying the structure of time series is by calculating a set of summary statistics or `features', and then representing a time series in terms of its properties as a feature vector. The resulting feature space is interpretable and informative, and enables conventional statistical learning approaches, including clustering, regression, and classification, to be applied to time-series datasets. Many open-source software packages for computing sets of time-series features exist across multiple programming languages, including catch22 (22 features: Matlab, R, Python, Julia), feasts (42 features: R), tsfeatures (63 features: R), Kats (40 features: Python), tsfresh (779 features: Python), and TSFEL (390 features: Python). However, there are several issues: (i) a singular access point to these packages is not currently available; (ii) to access all feature sets, users must be fluent in multiple languages; and (iii) these feature-extraction packages lack extensive accompanying methodological pipelines for performing feature-based time-series analysis, such as applications to time-series classification. Here we introduce a solution to these issues in an R software package called theft: Tools for Handling Extraction of Features from Time series. theft is a unified and extendable framework for computing features from the six open-source time-series feature sets listed above. It also includes a suite of functions for processing and interpreting the performance of extracted features, including extensive data-visualization templates, low-dimensional projections, and time-series classification operations. With an increasing volume and complexity of time-series datasets in the sciences and industry, theft provides a standardized framework for comprehensively quantifying and interpreting informative structure in time series.
On the Statistical Benefits of Temporal Difference Learning
Jan 30, 2023
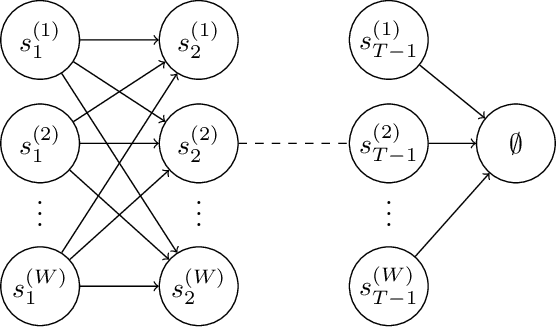
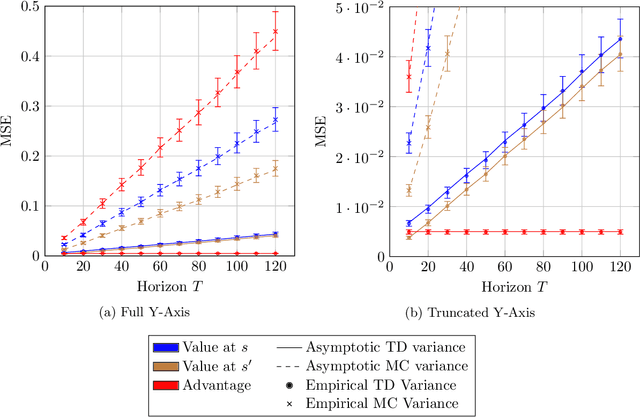
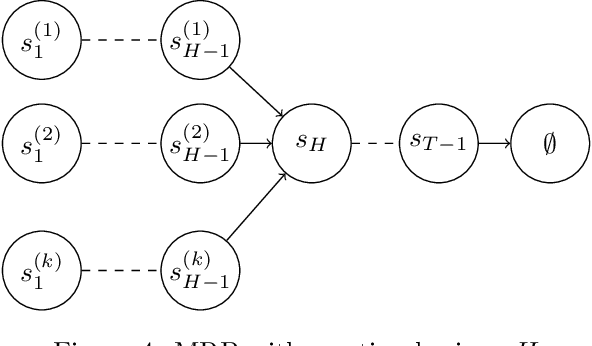
Given a dataset on actions and resulting long-term rewards, a direct estimation approach fits value functions that minimize prediction error on the training data. Temporal difference learning (TD) methods instead fit value functions by minimizing the degree of temporal inconsistency between estimates made at successive time-steps. Focusing on finite state Markov chains, we provide a crisp asymptotic theory of the statistical advantages of this approach. First, we show that an intuitive inverse trajectory pooling coefficient completely characterizes the percent reduction in mean-squared error of value estimates. Depending on problem structure, the reduction could be enormous or nonexistent. Next, we prove that there can be dramatic improvements in estimates of the difference in value-to-go for two states: TD's errors are bounded in terms of a novel measure - the problem's trajectory crossing time - which can be much smaller than the problem's time horizon.
Does Synthetic Data Generation of LLMs Help Clinical Text Mining?
Mar 08, 2023
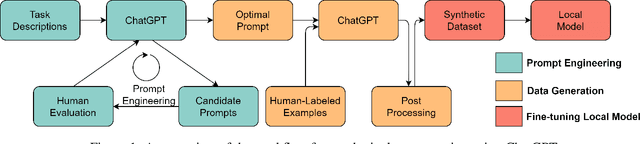
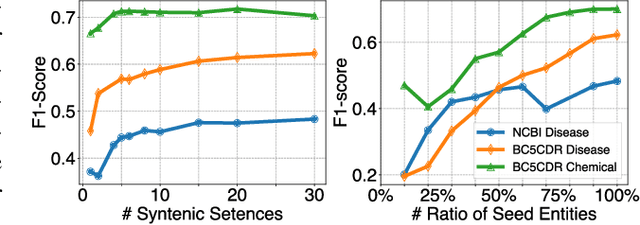

Recent advancements in large language models (LLMs) have led to the development of highly potent models like OpenAI's ChatGPT. These models have exhibited exceptional performance in a variety of tasks, such as question answering, essay composition, and code generation. However, their effectiveness in the healthcare sector remains uncertain. In this study, we seek to investigate the potential of ChatGPT to aid in clinical text mining by examining its ability to extract structured information from unstructured healthcare texts, with a focus on biological named entity recognition and relation extraction. However, our preliminary results indicate that employing ChatGPT directly for these tasks resulted in poor performance and raised privacy concerns associated with uploading patients' information to the ChatGPT API. To overcome these limitations, we propose a new training paradigm that involves generating a vast quantity of high-quality synthetic data with labels utilizing ChatGPT and fine-tuning a local model for the downstream task. Our method has resulted in significant improvements in the performance of downstream tasks, improving the F1-score from 23.37% to 63.99% for the named entity recognition task and from 75.86% to 83.59% for the relation extraction task. Furthermore, generating data using ChatGPT can significantly reduce the time and effort required for data collection and labeling, as well as mitigate data privacy concerns. In summary, the proposed framework presents a promising solution to enhance the applicability of LLM models to clinical text mining.
Feature Selection for Forecasting
Mar 08, 2023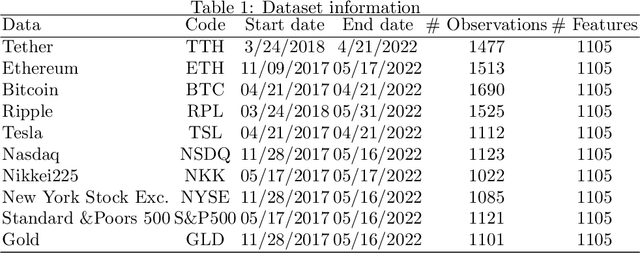
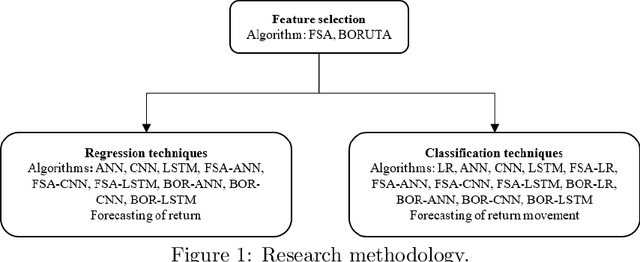


This work investigates the importance of feature selection for improving the forecasting performance of machine learning algorithms for financial data. Artificial neural networks (ANN), convolutional neural networks (CNN), long-short term memory (LSTM) networks, as well as linear models were applied for forecasting purposes. The Feature Selection with Annealing (FSA) algorithm was used to select the features from about 1000 possible predictors obtained from 26 technical indicators with specific periods and their lags. In addition to this, the Boruta feature selection algorithm was applied as a baseline feature selection method. The dependent variables consisted of daily logarithmic returns and daily trends of ten financial data sets, including cryptocurrency and different stocks. Experiments indicate that the FSA algorithm increased the performance of ML models regardless of the problem type. The FSA hybrid machine learning models showed better performance in 10 out of 10 data sets for regression and 8 out of 10 data sets for classification. None of the hybrid Boruta models outperformed the hybrid FSA models. However, the BORCNN model performance was comparable to the best model for 4 out of 10 data sets for regression estimates. BOR-LR and BOR-CNN models showed comparable performance with the best hybrid FSA models in 2 out of 10 datasets for classification. FSA was observed to improve the model performance in both better performance metrics as well as a decreased computation time by providing a lower dimensional input feature space.