 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Witscript 2: A System for Generating Improvised Jokes Without Wordplay
Feb 03, 2023

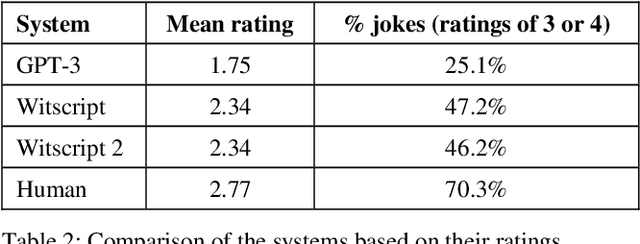
A previous paper presented Witscript, a system for generating conversational jokes that rely on wordplay. This paper extends that work by presenting Witscript 2, which uses a large language model to generate conversational jokes that rely on common sense instead of wordplay. Like Witscript, Witscript 2 is based on joke-writing algorithms created by an expert comedy writer. Human evaluators judged Witscript 2's responses to input sentences to be jokes 46% of the time, compared to 70% of the time for human-written responses. This is evidence that Witscript 2 represents another step toward giving a chatbot a humanlike sense of humor.
NVRadarNet: Real-Time Radar Obstacle and Free Space Detection for Autonomous Driving
Sep 29, 2022

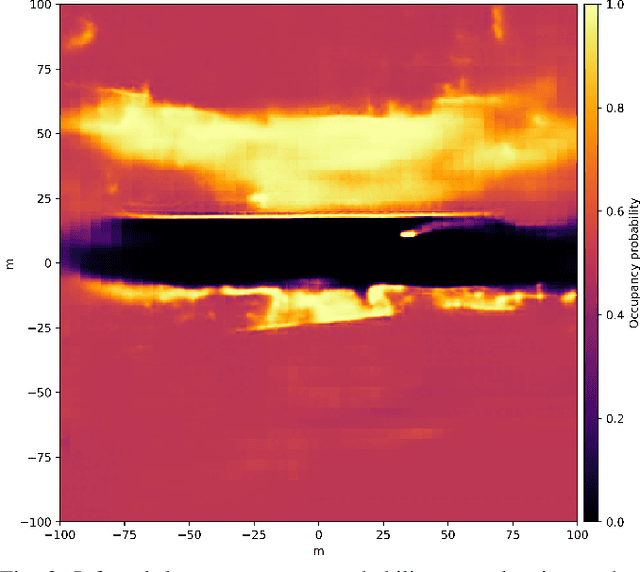

Detecting obstacles is crucial for safe and efficient autonomous driving. To this end, we present NVRadarNet, a deep neural network (DNN) that detects dynamic obstacles and drivable free space using automotive RADAR sensors. The network utilizes temporally accumulated data from multiple RADAR sensors to detect dynamic obstacles and compute their orientation in a top-down bird's-eye view (BEV). The network also regresses drivable free space to detect unclassified obstacles. Our DNN is the first of its kind to utilize sparse RADAR signals in order to perform obstacle and free space detection in real time from RADAR data only. The network has been successfully used for perception on our autonomous vehicles in real self-driving scenarios. The network runs faster than real time on an embedded GPU and shows good generalization across geographic regions.
Efficient Context Integration through Factorized Pyramidal Learning for Ultra-Lightweight Semantic Segmentation
Feb 23, 2023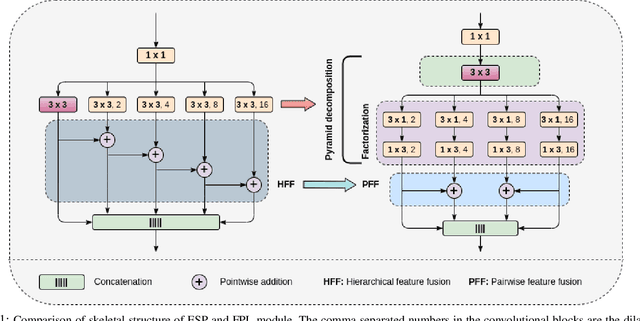
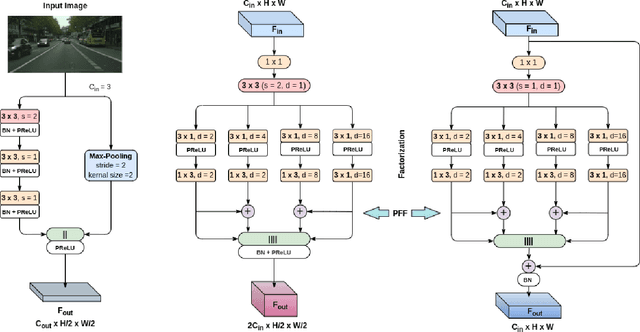
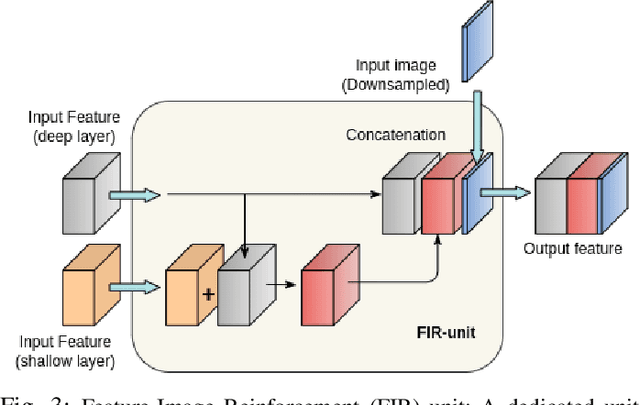
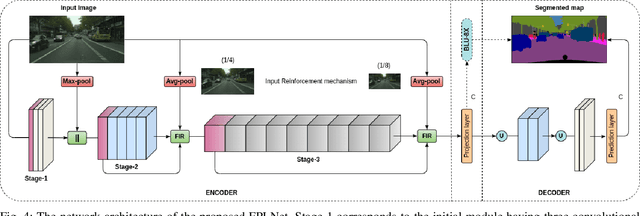
Semantic segmentation is a pixel-level prediction task to classify each pixel of the input image. Deep learning models, such as convolutional neural networks (CNNs), have been extremely successful in achieving excellent performances in this domain. However, mobile application, such as autonomous driving, demand real-time processing of incoming stream of images. Hence, achieving efficient architectures along with enhanced accuracy is of paramount importance. Since, accuracy and model size of CNNs are intrinsically contentious in nature, the challenge is to achieve a decent trade-off between accuracy and model size. To address this, we propose a novel Factorized Pyramidal Learning (FPL) module to aggregate rich contextual information in an efficient manner. On one hand, it uses a bank of convolutional filters with multiple dilation rates which leads to multi-scale context aggregation; crucial in achieving better accuracy. On the other hand, parameters are reduced by a careful factorization of the employed filters; crucial in achieving lightweight models. Moreover, we decompose the spatial pyramid into two stages which enables a simple and efficient feature fusion within the module to solve the notorious checkerboard effect. We also design a dedicated Feature-Image Reinforcement (FIR) unit to carry out the fusion operation of shallow and deep features with the downsampled versions of the input image. This gives an accuracy enhancement without increasing model parameters. Based on the FPL module and FIR unit, we propose an ultra-lightweight real-time network, called FPLNet, which achieves state-of-the-art accuracy-efficiency trade-off. More specifically, with only less than 0.5 million parameters, the proposed network achieves 66.93\% and 66.28\% mIoU on Cityscapes validation and test set, respectively. Moreover, FPLNet has a processing speed of 95.5 frames per second (FPS).
Prediction of a T-cell/MHC-I-based immune profile for colorectal liver metastases from CT images using ensemble learning
Mar 06, 2023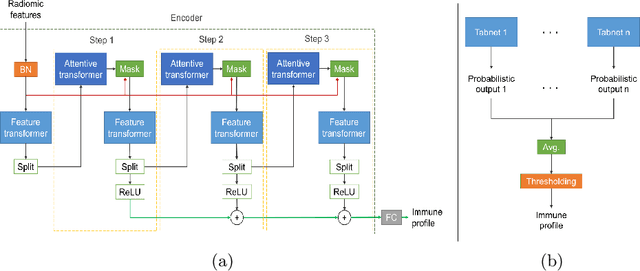
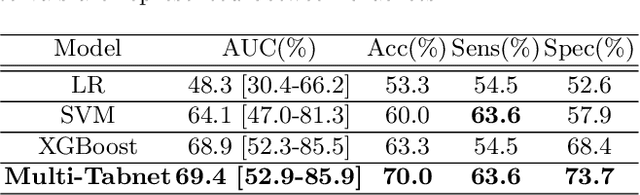
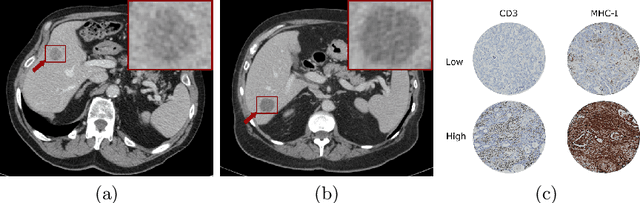
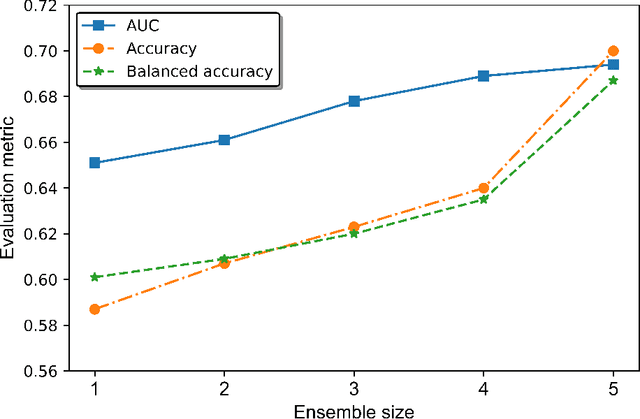
Colorectal cancer liver metastases (CLM) are the most common type of distant metastases originating from the abdomen and are characterized by a high recurrence rate after curative resection. It has been previously reported that CLM presenting a low cluster of differentiation 3 (CD3) positive T-cell infiltration density concurrent with a high major histocompatibility complex class I (MHC-I) expression were associated with poor clinical outcomes. In this study, we attempt to noninvasively predict whether a CLM exhibit the CD3LowMHCHigh immunological profile using preoperative CT images. To this end, we propose an ensemble network combining multiple Attentive Interpretable Tabular learning (TabNet) models, trained using CT-derived radiomic features. A total of 160 CLM were included in this study and randomly divided between a training set (n=130) and a hold-out test set (n=30). The proposed model yielded good prediction performance on the test set with an accuracy of 70.0% [95% confidence interval 53.6%-86.4%] and an area under the curve of 69.4% [52.9%-85.9%]. It also outperformed other off-the-shelf machine learning models. We finally demonstrated that the predicted immune profile was associated with a shorter disease-specific survival (p = .023) and time-to-recurrence (p = .020), showing the value of assessing the immune response.
A Survey on Incremental Update for Neural Recommender Systems
Mar 06, 2023Recommender Systems (RS) aim to provide personalized suggestions of items for users against consumer over-choice. Although extensive research has been conducted to address different aspects and challenges of RS, there still exists a gap between academic research and industrial applications. Specifically, most of the existing models still work in an offline manner, in which the recommender is trained on a large static training set and evaluated on a very restrictive testing set in a one-time process. RS will stay unchanged until the next batch retrain is performed. We frame such RS as Batch Update Recommender Systems (BURS). In reality, they have to face the challenges where RS are expected to be instantly updated with new data streaming in, and generate updated recommendations for current user activities based on the newly arrived data. We frame such RS as Incremental Update Recommender Systems (IURS). In this article, we offer a systematic survey of incremental update for neural recommender systems. We begin the survey by introducing key concepts and formulating the task of IURS. We then illustrate the challenges in IURS compared with traditional BURS. Afterwards, we detail the introduction of existing literature and evaluation issues. We conclude the survey by outlining some prominent open research issues in this area.
Knowledge-embedded meta-learning model for lift coefficient prediction of airfoils
Mar 06, 2023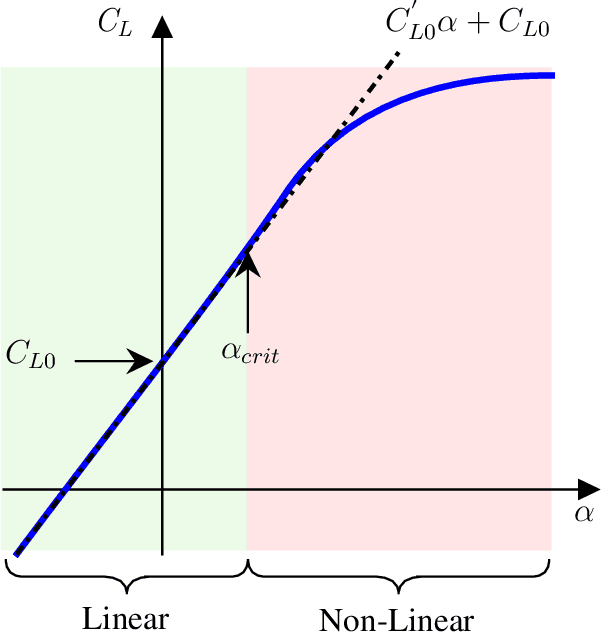
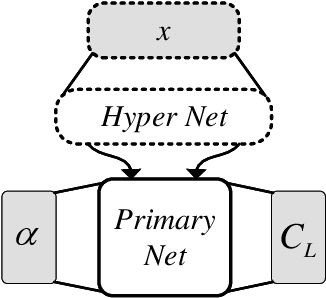
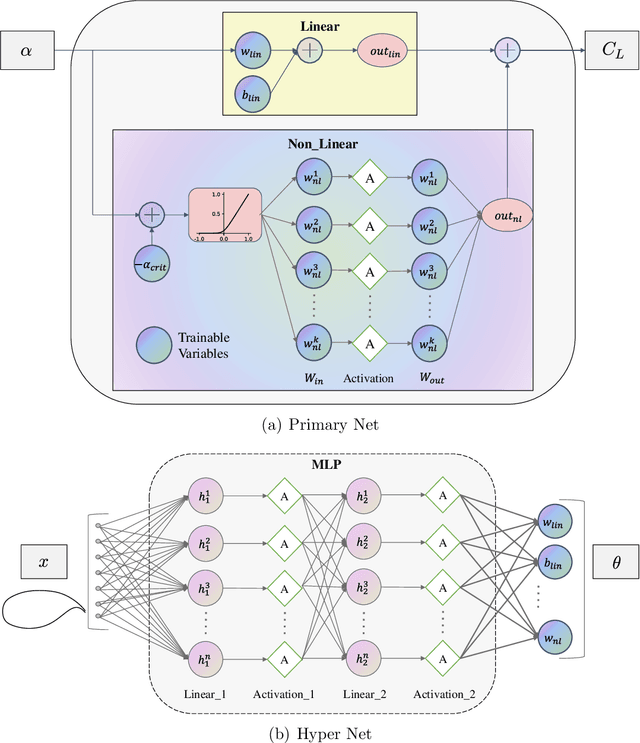
Aerodynamic performance evaluation is an important part of the aircraft aerodynamic design optimization process; however, traditional methods are costly and time-consuming. Despite the fact that various machine learning methods can achieve high accuracy, their application in engineering is still difficult due to their poor generalization performance and "black box" nature. In this paper, a knowledge-embedded meta learning model, which fully integrates data with the theoretical knowledge of the lift curve, is developed to obtain the lift coefficients of an arbitrary supercritical airfoil under various angle of attacks. In the proposed model, a primary network is responsible for representing the relationship between the lift and angle of attack, while the geometry information is encoded into a hyper network to predict the unknown parameters involved in the primary network. Specifically, three models with different architectures are trained to provide various interpretations. Compared to the ordinary neural network, our proposed model can exhibit better generalization capability with competitive prediction accuracy. Afterward, interpretable analysis is performed based on the Integrated Gradients and Saliency methods. Results show that the proposed model can tend to assess the influence of airfoil geometry to the physical characteristics. Furthermore, the exceptions and shortcomings caused by the proposed model are analysed and discussed in detail.
Optimizing L1 cache for embedded systems through grammatical evolution
Mar 06, 2023Nowadays, embedded systems are provided with cache memories that are large enough to influence in both performance and energy consumption as never occurred before in this kind of systems. In addition, the cache memory system has been identified as a component that improves those metrics by adapting its configuration according to the memory access patterns of the applications being run. However, given that cache memories have many parameters which may be set to a high number of different values, designers face to a wide and time-consuming exploration space. In this paper we propose an optimization framework based on Grammatical Evolution (GE) which is able to efficiently find the best cache configurations for a given set of benchmark applications. This metaheuristic allows an important reduction of the optimization runtime obtaining good results in a low number of generations. Besides, this reduction is also increased due to the efficient storage of evaluated caches. Moreover, we selected GE because the plasticity of the grammar eases the creation of phenotypes that form the call to the cache simulator required for the evaluation of the different configurations. Experimental results for the Mediabench suite show that our proposal is able to find cache configurations that obtain an average improvement of $62\%$ versus a real world baseline configuration.
An Online Algorithm for Chance Constrained Resource Allocation
Mar 06, 2023
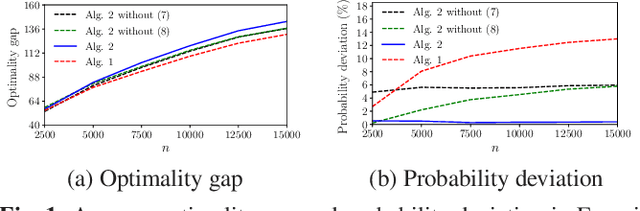
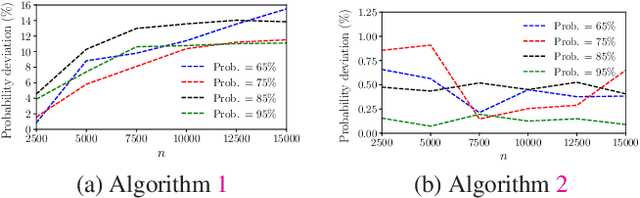
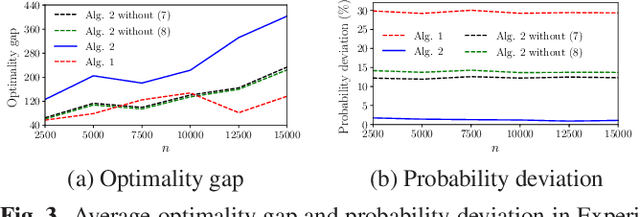
This paper studies the online stochastic resource allocation problem (RAP) with chance constraints. The online RAP is a 0-1 integer linear programming problem where the resource consumption coefficients are revealed column by column along with the corresponding revenue coefficients. When a column is revealed, the corresponding decision variables are determined instantaneously without future information. Moreover, in online applications, the resource consumption coefficients are often obtained by prediction. To model their uncertainties, we take the chance constraints into the consideration. To the best of our knowledge, this is the first time chance constraints are introduced in the online RAP problem. Assuming that the uncertain variables have known Gaussian distributions, the stochastic RAP can be transformed into a deterministic but nonlinear problem with integer second-order cone constraints. Next, we linearize this nonlinear problem and analyze the performance of vanilla online primal-dual algorithm for solving the linearized stochastic RAP. Under mild technical assumptions, the optimality gap and constraint violation are both on the order of $\sqrt{n}$. Then, to further improve the performance of the algorithm, several modified online primal-dual algorithms with heuristic corrections are proposed. Finally, extensive numerical experiments on both synthetic and real data demonstrate the applicability and effectiveness of our methods.
LongEval-Retrieval: French-English Dynamic Test Collection for Continuous Web Search Evaluation
Mar 06, 2023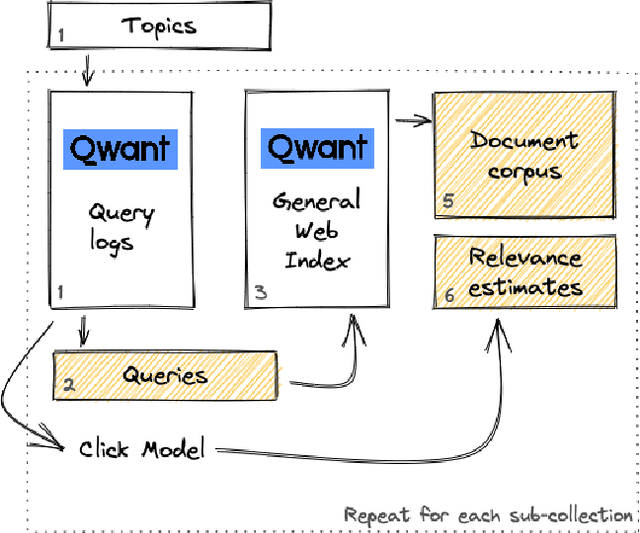


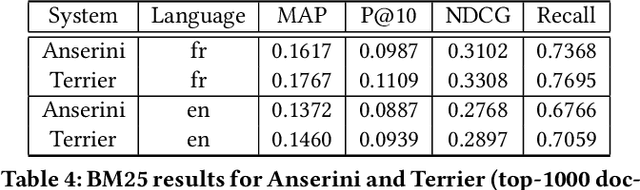
LongEval-Retrieval is a Web document retrieval benchmark that focuses on continuous retrieval evaluation. This test collection is intended to be used to study the temporal persistence of Information Retrieval systems and will be used as the test collection in the Longitudinal Evaluation of Model Performance Track (LongEval) at CLEF 2023. This benchmark simulates an evolving information system environment - such as the one a Web search engine operates in - where the document collection, the query distribution, and relevance all move continuously, while following the Cranfield paradigm for offline evaluation. To do that, we introduce the concept of a dynamic test collection that is composed of successive sub-collections each representing the state of an information system at a given time step. In LongEval-Retrieval, each sub-collection contains a set of queries, documents, and soft relevance assessments built from click models. The data comes from Qwant, a privacy-preserving Web search engine that primarily focuses on the French market. LongEval-Retrieval also provides a 'mirror' collection: it is initially constructed in the French language to benefit from the majority of Qwant's traffic, before being translated to English. This paper presents the creation process of LongEval-Retrieval and provides baseline runs and analysis.
EEG Synthetic Data Generation Using Probabilistic Diffusion Models
Mar 06, 2023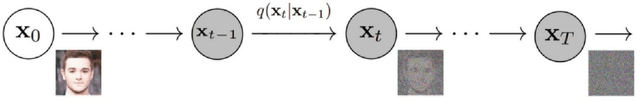
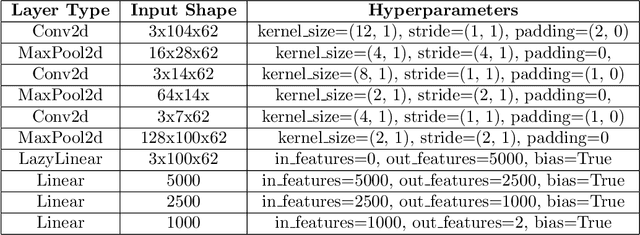
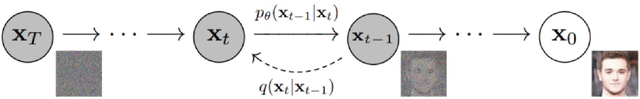
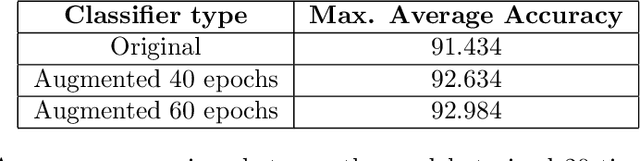
Electroencephalography (EEG) plays a significant role in the Brain Computer Interface (BCI) domain, due to its non-invasive nature, low cost, and ease of use, making it a highly desirable option for widespread adoption by the general public. This technology is commonly used in conjunction with deep learning techniques, the success of which is largely dependent on the quality and quantity of data used for training. To address the challenge of obtaining sufficient EEG data from individual participants while minimizing user effort and maintaining accuracy, this study proposes an advanced methodology for data augmentation: generating synthetic EEG data using denoising diffusion probabilistic models. The synthetic data are generated from electrode-frequency distribution maps (EFDMs) of emotionally labeled EEG recordings. To assess the validity of the synthetic data generated, both a qualitative and a quantitative comparison with real EEG data were successfully conducted. This study opens up the possibility for an open\textendash source accessible and versatile toolbox that can process and generate data in both time and frequency dimensions, regardless of the number of channels involved. Finally, the proposed methodology has potential implications for the broader field of neuroscience research by enabling the creation of large, publicly available synthetic EEG datasets without privacy concerns.