 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SurvSHAP(t): Time-dependent explanations of machine learning survival models
Aug 23, 2022

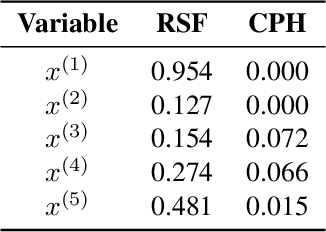
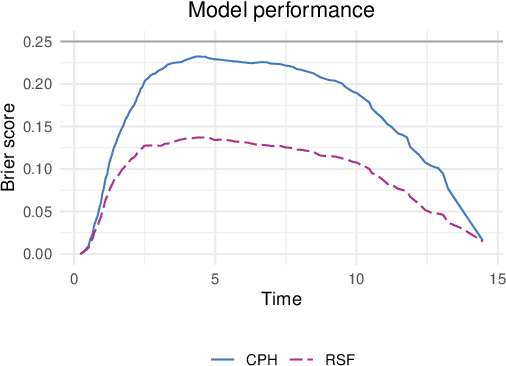

Machine and deep learning survival models demonstrate similar or even improved time-to-event prediction capabilities compared to classical statistical learning methods yet are too complex to be interpreted by humans. Several model-agnostic explanations are available to overcome this issue; however, none directly explain the survival function prediction. In this paper, we introduce SurvSHAP(t), the first time-dependent explanation that allows for interpreting survival black-box models. It is based on SHapley Additive exPlanations with solid theoretical foundations and a broad adoption among machine learning practitioners. The proposed methods aim to enhance precision diagnostics and support domain experts in making decisions. Experiments on synthetic and medical data confirm that SurvSHAP(t) can detect variables with a time-dependent effect, and its aggregation is a better determinant of the importance of variables for a prediction than SurvLIME. SurvSHAP(t) is model-agnostic and can be applied to all models with functional output. We provide an accessible implementation of time-dependent explanations in Python at http://github.com/MI2DataLab/survshap .
Extreme-Long-short Term Memory for Time-series Prediction
Oct 15, 2022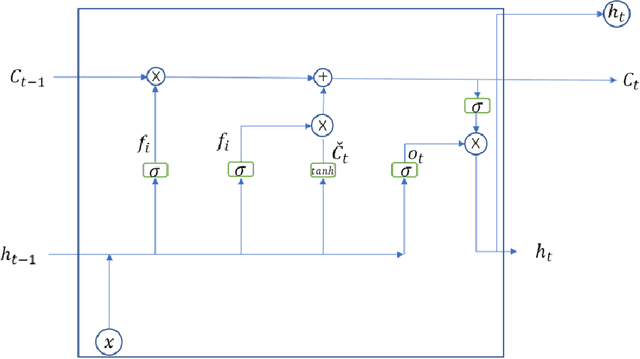
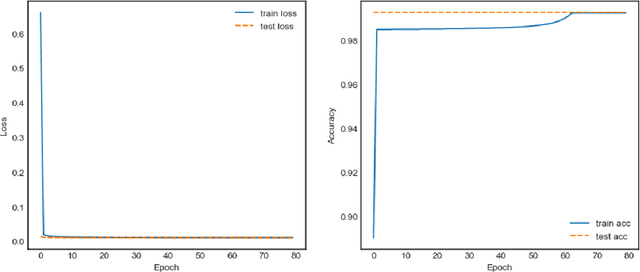
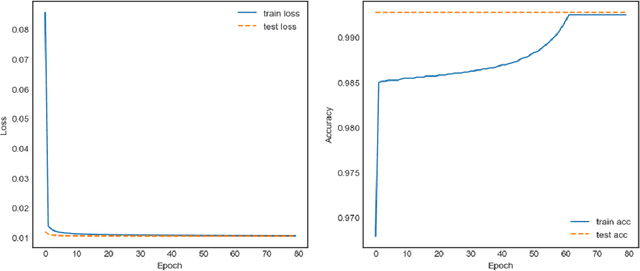
The emergence of Long Short-Term Memory (LSTM) solves the problems of vanishing gradient and exploding gradient in traditional Recurrent Neural Networks (RNN). LSTM, as a new type of RNN, has been widely used in various fields, such as text prediction, Wind Speed Forecast, depression prediction by EEG signals, etc. The results show that improving the efficiency of LSTM can help to improve the efficiency in other application areas. In this paper, we proposed an advanced LSTM algorithm, the Extreme Long Short-Term Memory (E-LSTM), which adds the inverse matrix part of Extreme Learning Machine (ELM) as a new "gate" into the structure of LSTM. This "gate" preprocess a portion of the data and involves the processed data in the cell update of the LSTM to obtain more accurate data with fewer training rounds, thus reducing the overall training time. In this research, the E-LSTM model is used for the text prediction task. Experimental results showed that the E-LSTM sometimes takes longer to perform a single training round, but when tested on a small data set, the new E-LSTM requires only 2 epochs to obtain the results of the 7th epoch traditional LSTM. Therefore, the E-LSTM retains the high accuracy of the traditional LSTM, whilst also improving the training speed and the overall efficiency of the LSTM.
Real-Time Reinforcement Learning for Vision-Based Robotics Utilizing Local and Remote Computers
Oct 05, 2022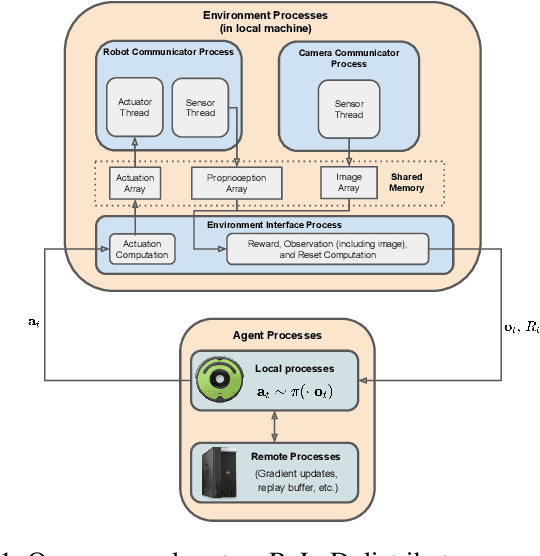
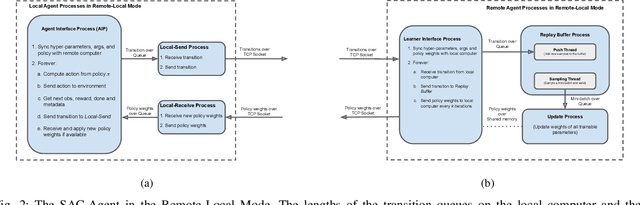
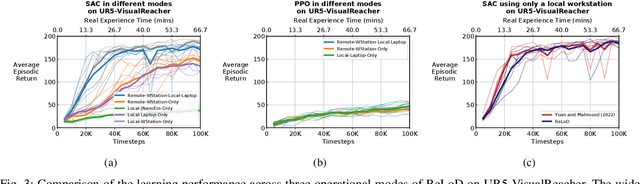
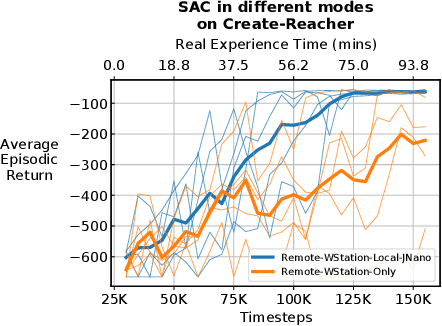
Real-time learning is crucial for robotic agents adapting to ever-changing, non-stationary environments. A common setup for a robotic agent is to have two different computers simultaneously: a resource-limited local computer tethered to the robot and a powerful remote computer connected wirelessly. Given such a setup, it is unclear to what extent the performance of a learning system can be affected by resource limitations and how to efficiently use the wirelessly connected powerful computer to compensate for any performance loss. In this paper, we implement a real-time learning system called the Remote-Local Distributed (ReLoD) system to distribute computations of two deep reinforcement learning (RL) algorithms, Soft Actor-Critic (SAC) and Proximal Policy Optimization (PPO), between a local and a remote computer. The performance of the system is evaluated on two vision-based control tasks developed using a robotic arm and a mobile robot. Our results show that SAC's performance degrades heavily on a resource-limited local computer. Strikingly, when all computations of the learning system are deployed on a remote workstation, SAC fails to compensate for the performance loss, indicating that, without careful consideration, using a powerful remote computer may not result in performance improvement. However, a carefully chosen distribution of computations of SAC consistently and substantially improves its performance on both tasks. On the other hand, the performance of PPO remains largely unaffected by the distribution of computations. In addition, when all computations happen solely on a powerful tethered computer, the performance of our system remains on par with an existing system that is well-tuned for using a single machine. ReLoD is the only publicly available system for real-time RL that applies to multiple robots for vision-based tasks.
Online Convex Optimization with Stochastic Constraints: Zero Constraint Violation and Bandit Feedback
Jan 26, 2023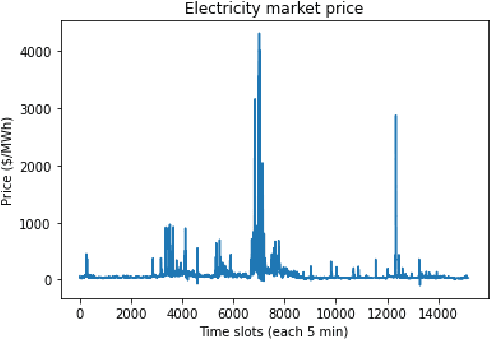
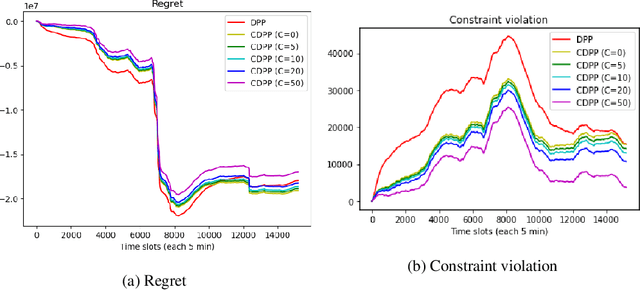
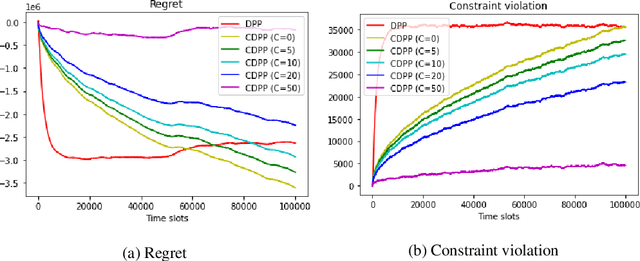
This paper studies online convex optimization with stochastic constraints. We propose a variant of the drift-plus-penalty algorithm that guarantees $O(\sqrt{T})$ expected regret and zero constraint violation, after a fixed number of iterations, which improves the vanilla drift-plus-penalty method with $O(\sqrt{T})$ constraint violation. Our algorithm is oblivious to the length of the time horizon $T$, in contrast to the vanilla drift-plus-penalty method. This is based on our novel drift lemma that provides time-varying bounds on the virtual queue drift and, as a result, leads to time-varying bounds on the expected virtual queue length. Moreover, we extend our framework to stochastic-constrained online convex optimization under two-point bandit feedback. We show that by adapting our algorithmic framework to the bandit feedback setting, we may still achieve $O(\sqrt{T})$ expected regret and zero constraint violation, improving upon the previous work for the case of identical constraint functions. Numerical results demonstrate our theoretical results.
Visual Exemplar Driven Task-Prompting for Unified Perception in Autonomous Driving
Mar 03, 2023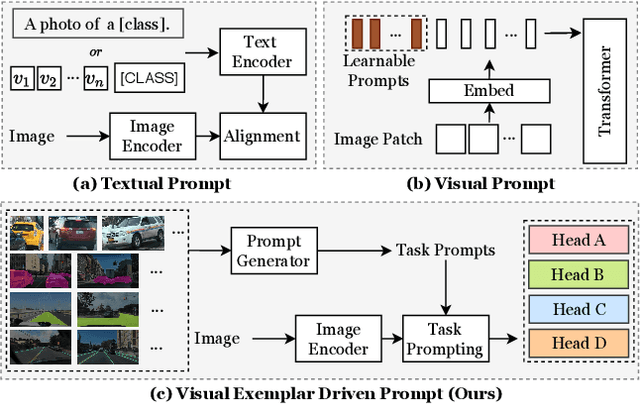
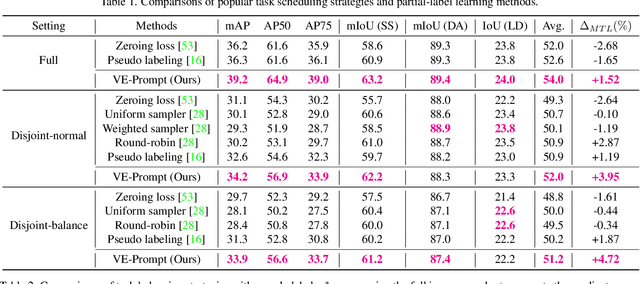
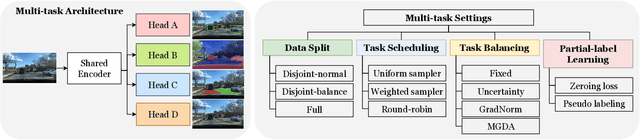
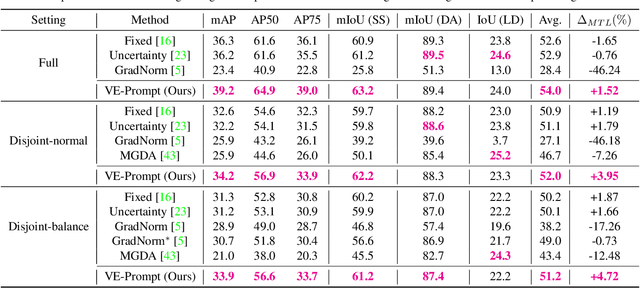
Multi-task learning has emerged as a powerful paradigm to solve a range of tasks simultaneously with good efficiency in both computation resources and inference time. However, these algorithms are designed for different tasks mostly not within the scope of autonomous driving, thus making it hard to compare multi-task methods in autonomous driving. Aiming to enable the comprehensive evaluation of present multi-task learning methods in autonomous driving, we extensively investigate the performance of popular multi-task methods on the large-scale driving dataset, which covers four common perception tasks, i.e., object detection, semantic segmentation, drivable area segmentation, and lane detection. We provide an in-depth analysis of current multi-task learning methods under different common settings and find out that the existing methods make progress but there is still a large performance gap compared with single-task baselines. To alleviate this dilemma in autonomous driving, we present an effective multi-task framework, VE-Prompt, which introduces visual exemplars via task-specific prompting to guide the model toward learning high-quality task-specific representations. Specifically, we generate visual exemplars based on bounding boxes and color-based markers, which provide accurate visual appearances of target categories and further mitigate the performance gap. Furthermore, we bridge transformer-based encoders and convolutional layers for efficient and accurate unified perception in autonomous driving. Comprehensive experimental results on the diverse self-driving dataset BDD100K show that the VE-Prompt improves the multi-task baseline and further surpasses single-task models.
Finding Things in the Unknown: Semantic Object-Centric Exploration with an MAV
Mar 03, 2023
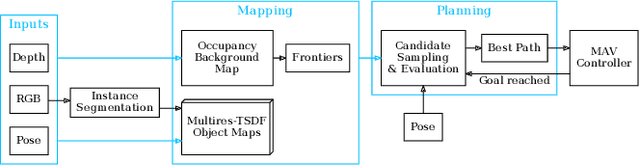
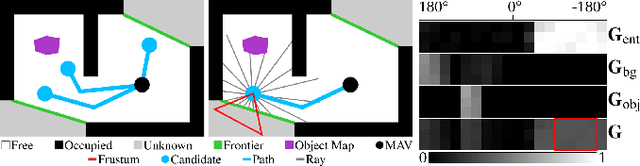

Exploration of unknown space with an autonomous mobile robot is a well-studied problem. In this work we broaden the scope of exploration, moving beyond the pure geometric goal of uncovering as much free space as possible. We believe that for many practical applications, exploration should be contextualised with semantic and object-level understanding of the environment for task-specific exploration. Here, we study the task of both finding specific objects in unknown space as well as reconstructing them to a target level of detail. We therefore extend our environment reconstruction to not only consist of a background map, but also object-level and semantically fused submaps. Importantly, we adapt our previous objective function of uncovering as much free space as possible in as little time as possible with two additional elements: first, we require a maximum observation distance of background surfaces to ensure target objects are not missed by image-based detectors because they are too small to be detected. Second, we require an even smaller maximum distance to the found objects in order to reconstruct them with the desired accuracy. We further created a Micro Aerial Vehicle (MAV) semantic exploration simulator based on Habitat in order to quantitatively demonstrate how our framework can be used to efficiently find specific objects as part of exploration. Finally, we showcase this capability can be deployed in real-world scenes involving our drone equipped with an Intel RealSense D455 RGB-D camera.
WESPER: Zero-shot and Realtime Whisper to Normal Voice Conversion for Whisper-based Speech Interactions
Mar 03, 2023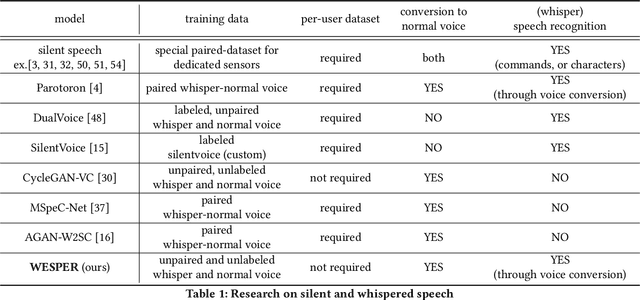
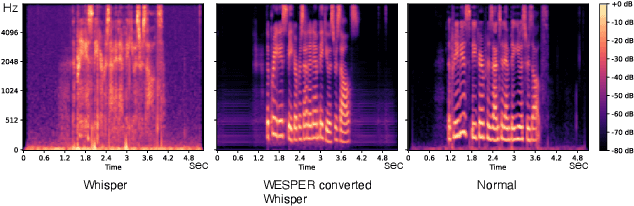

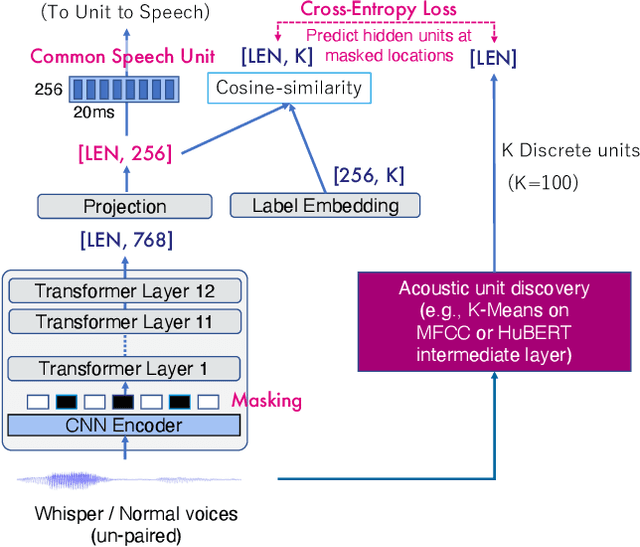
Recognizing whispered speech and converting it to normal speech creates many possibilities for speech interaction. Because the sound pressure of whispered speech is significantly lower than that of normal speech, it can be used as a semi-silent speech interaction in public places without being audible to others. Converting whispers to normal speech also improves the speech quality for people with speech or hearing impairments. However, conventional speech conversion techniques do not provide sufficient conversion quality or require speaker-dependent datasets consisting of pairs of whispered and normal speech utterances. To address these problems, we propose WESPER, a zero-shot, real-time whisper-to-normal speech conversion mechanism based on self-supervised learning. WESPER consists of a speech-to-unit (STU) encoder, which generates hidden speech units common to both whispered and normal speech, and a unit-to-speech (UTS) decoder, which reconstructs speech from the encoded speech units. Unlike the existing methods, this conversion is user-independent and does not require a paired dataset for whispered and normal speech. The UTS decoder can reconstruct speech in any target speaker's voice from speech units, and it requires only an unlabeled target speaker's speech data. We confirmed that the quality of the speech converted from a whisper was improved while preserving its natural prosody. Additionally, we confirmed the effectiveness of the proposed approach to perform speech reconstruction for people with speech or hearing disabilities. (project page: http://lab.rekimoto.org/projects/wesper )
* ACM CHI 2023 paper
Collaborative Learning with a Drone Orchestrator
Mar 03, 2023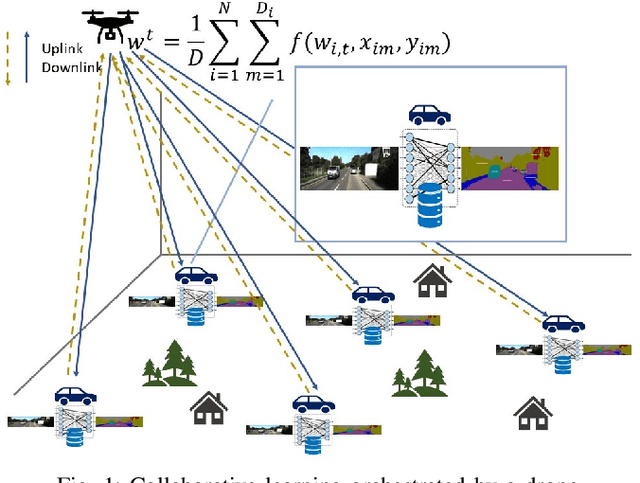
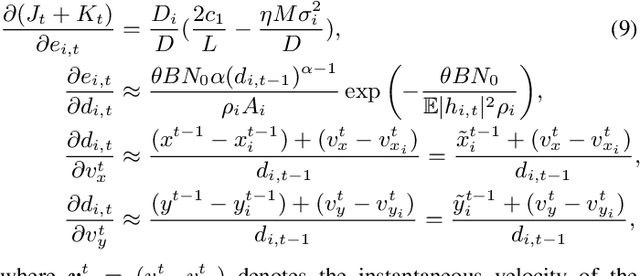
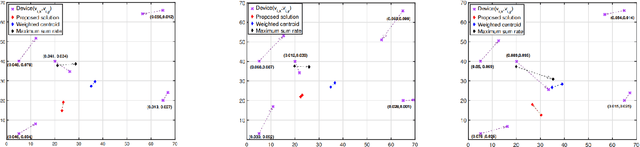
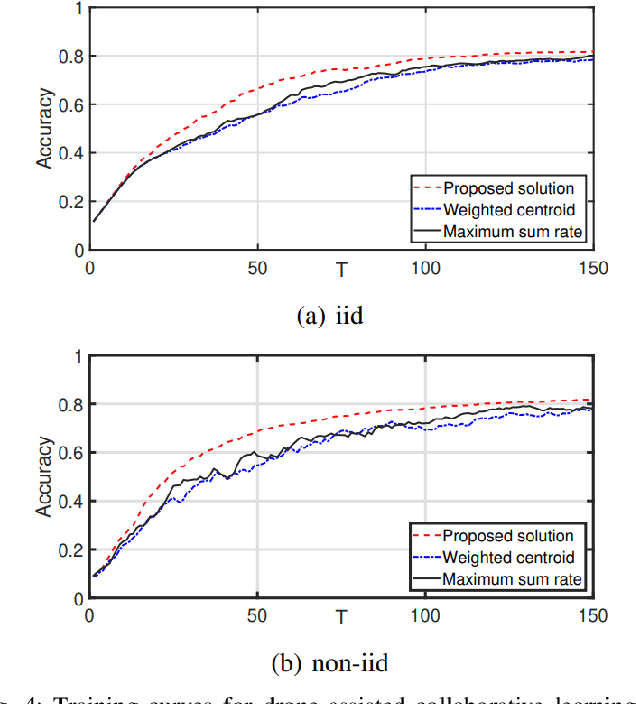
In this paper, the problem of drone-assisted collaborative learning is considered. In this scenario, swarm of intelligent wireless devices train a shared neural network (NN) model with the help of a drone. Using its sensors, each device records samples from its environment to gather a local dataset for training. The training data is severely heterogeneous as various devices have different amount of data and sensor noise level. The intelligent devices iteratively train the NN on their local datasets and exchange the model parameters with the drone for aggregation. For this system, the convergence rate of collaborative learning is derived while considering data heterogeneity, sensor noise levels, and communication errors, then, the drone trajectory that maximizes the final accuracy of the trained NN is obtained. The proposed trajectory optimization approach is aware of both the devices data characteristics (i.e., local dataset size and noise level) and their wireless channel conditions, and significantly improves the convergence rate and final accuracy in comparison with baselines that only consider data characteristics or channel conditions. Compared to state-of-the-art baselines, the proposed approach achieves an average 3.85% and 3.54% improvement in the final accuracy of the trained NN on benchmark datasets for image recognition and semantic segmentation tasks, respectively. Moreover, the proposed framework achieves a significant speedup in training, leading to an average 24% and 87% saving in the drone hovering time, communication overhead, and battery usage, respectively for these tasks.
Bi-parametric prostate MR image synthesis using pathology and sequence-conditioned stable diffusion
Mar 03, 2023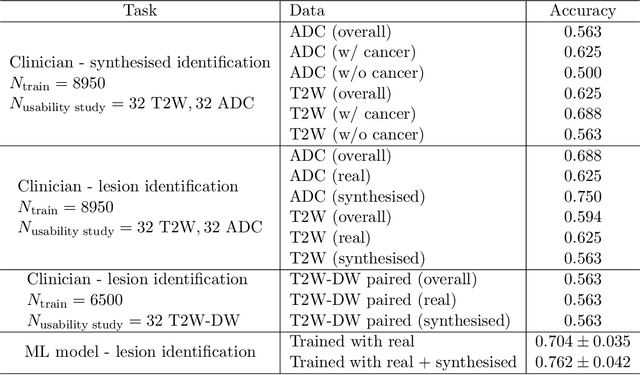

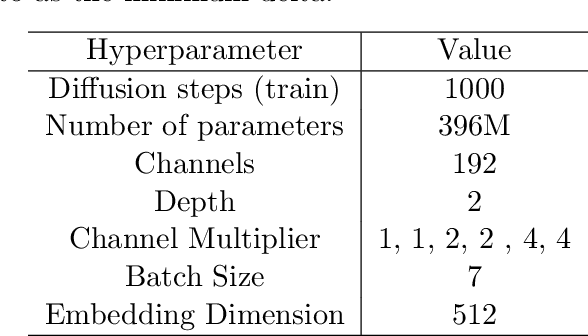
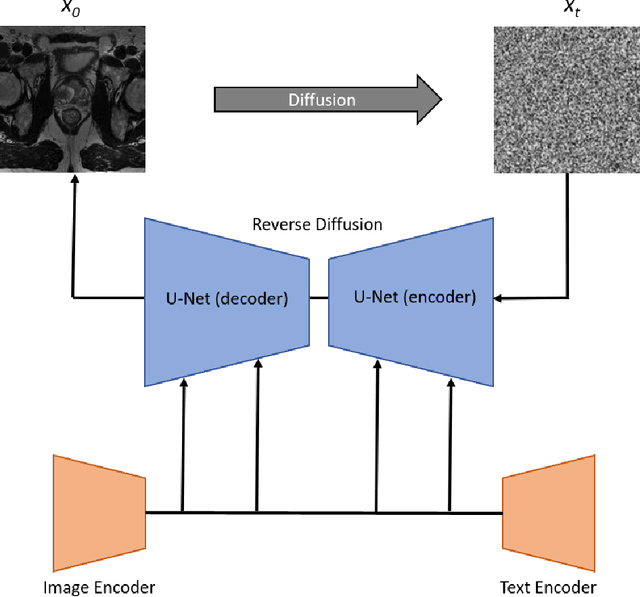
We propose an image synthesis mechanism for multi-sequence prostate MR images conditioned on text, to control lesion presence and sequence, as well as to generate paired bi-parametric images conditioned on images e.g. for generating diffusion-weighted MR from T2-weighted MR for paired data, which are two challenging tasks in pathological image synthesis. Our proposed mechanism utilises and builds upon the recent stable diffusion model by proposing image-based conditioning for paired data generation. We validate our method using 2D image slices from real suspected prostate cancer patients. The realism of the synthesised images is validated by means of a blind expert evaluation for identifying real versus fake images, where a radiologist with 4 years experience reading urological MR only achieves 59.4% accuracy across all tested sequences (where chance is 50%). For the first time, we evaluate the realism of the generated pathology by blind expert identification of the presence of suspected lesions, where we find that the clinician performs similarly for both real and synthesised images, with a 2.9 percentage point difference in lesion identification accuracy between real and synthesised images, demonstrating the potentials in radiological training purposes. Furthermore, we also show that a machine learning model, trained for lesion identification, shows better performance (76.2% vs 70.4%, statistically significant improvement) when trained with real data augmented by synthesised data as opposed to training with only real images, demonstrating usefulness for model training.
BSH-Det3D: Improving 3D Object Detection with BEV Shape Heatmap
Mar 03, 2023
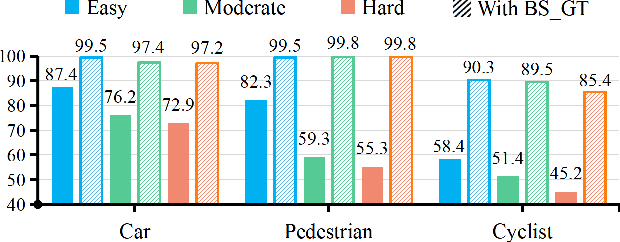
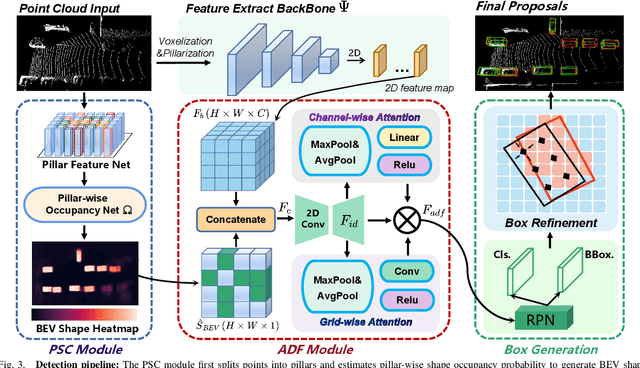
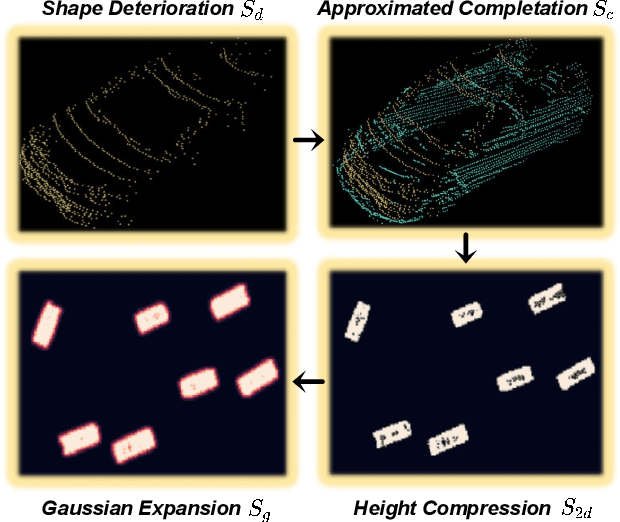
The progress of LiDAR-based 3D object detection has significantly enhanced developments in autonomous driving and robotics. However, due to the limitations of LiDAR sensors, object shapes suffer from deterioration in occluded and distant areas, which creates a fundamental challenge to 3D perception. Existing methods estimate specific 3D shapes and achieve remarkable performance. However, these methods rely on extensive computation and memory, causing imbalances between accuracy and real-time performance. To tackle this challenge, we propose a novel LiDAR-based 3D object detection model named BSH-Det3D, which applies an effective way to enhance spatial features by estimating complete shapes from a bird's eye view (BEV). Specifically, we design the Pillar-based Shape Completion (PSC) module to predict the probability of occupancy whether a pillar contains object shapes. The PSC module generates a BEV shape heatmap for each scene. After integrating with heatmaps, BSH-Det3D can provide additional information in shape deterioration areas and generate high-quality 3D proposals. We also design an attention-based densification fusion module (ADF) to adaptively associate the sparse features with heatmaps and raw points. The ADF module integrates the advantages of points and shapes knowledge with negligible overheads. Extensive experiments on the KITTI benchmark achieve state-of-the-art (SOTA) performance in terms of accuracy and speed, demonstrating the efficiency and flexibility of BSH-Det3D. The source code is available on https://github.com/mystorm16/BSH-Det3D.