 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Emerging Synergies Between Large Language Models and Machine Learning in Ecommerce Recommendations
Mar 12, 2024
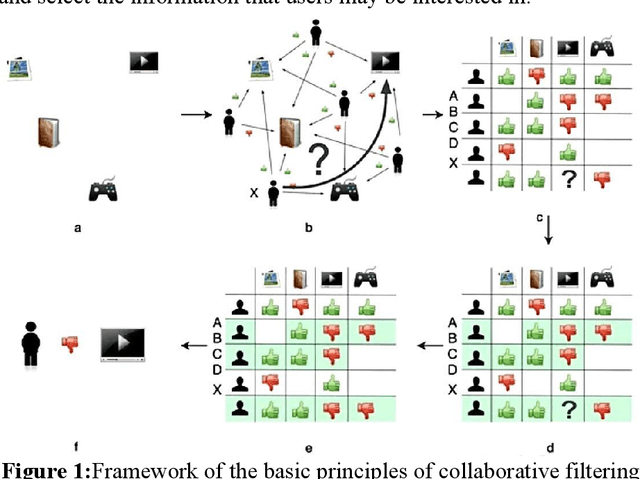

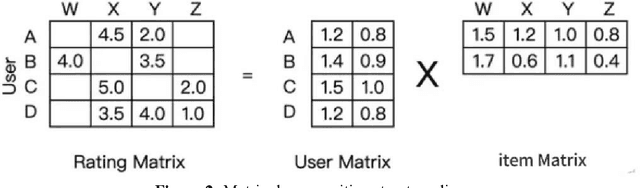
With the boom of e-commerce and web applications, recommender systems have become an important part of our daily lives, providing personalized recommendations based on the user's preferences. Although deep neural networks (DNNs) have made significant progress in improving recommendation systems by simulating the interaction between users and items and incorporating their textual information, these DNN-based approaches still have some limitations, such as the difficulty of effectively understanding users' interests and capturing textual information. It is not possible to generalize to different seen/unseen recommendation scenarios and reason about their predictions. At the same time, the emergence of large language models (LLMs), represented by ChatGPT and GPT-4, has revolutionized the fields of natural language processing (NLP) and artificial intelligence (AI) due to their superior capabilities in the basic tasks of language understanding and generation, and their impressive generalization and reasoning capabilities. As a result, recent research has sought to harness the power of LLM to improve recommendation systems. Given the rapid development of this research direction in the field of recommendation systems, there is an urgent need for a systematic review of existing LLM-driven recommendation systems for researchers and practitioners in related fields to gain insight into. More specifically, we first introduced a representative approach to learning user and item representations using LLM as a feature encoder. We then reviewed the latest advances in LLMs techniques for collaborative filtering enhanced recommendation systems from the three paradigms of pre-training, fine-tuning, and prompting. Finally, we had a comprehensive discussion on the future direction of this emerging field.
Continual All-in-One Adverse Weather Removal with Knowledge Replay on a Unified Network Structure
Mar 12, 2024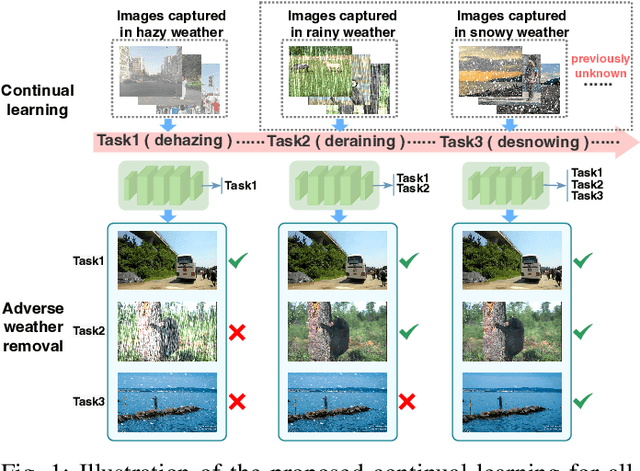
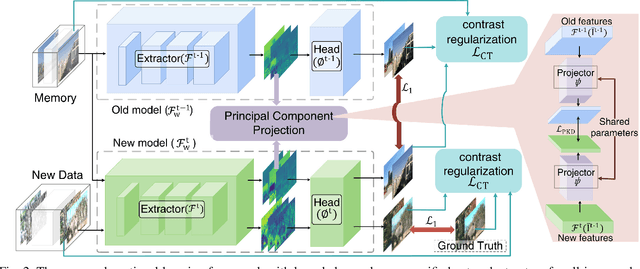
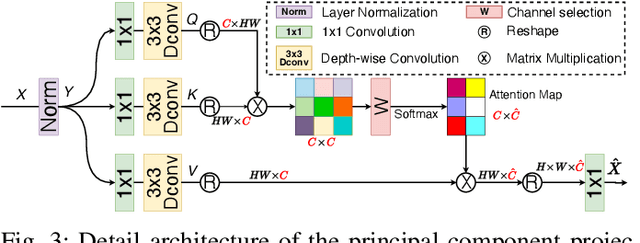

In real-world applications, image degeneration caused by adverse weather is always complex and changes with different weather conditions from days and seasons. Systems in real-world environments constantly encounter adverse weather conditions that are not previously observed. Therefore, it practically requires adverse weather removal models to continually learn from incrementally collected data reflecting various degeneration types. Existing adverse weather removal approaches, for either single or multiple adverse weathers, are mainly designed for a static learning paradigm, which assumes that the data of all types of degenerations to handle can be finely collected at one time before a single-phase learning process. They thus cannot directly handle the incremental learning requirements. To address this issue, we made the earliest effort to investigate the continual all-in-one adverse weather removal task, in a setting closer to real-world applications. Specifically, we develop a novel continual learning framework with effective knowledge replay (KR) on a unified network structure. Equipped with a principal component projection and an effective knowledge distillation mechanism, the proposed KR techniques are tailored for the all-in-one weather removal task. It considers the characteristics of the image restoration task with multiple degenerations in continual learning, and the knowledge for different degenerations can be shared and accumulated in the unified network structure. Extensive experimental results demonstrate the effectiveness of the proposed method to deal with this challenging task, which performs competitively to existing dedicated or joint training image restoration methods. Our code is available at https://github.com/xiaojihh/CL_all-in-one.
Calibrating Multi-modal Representations: A Pursuit of Group Robustness without Annotations
Mar 12, 2024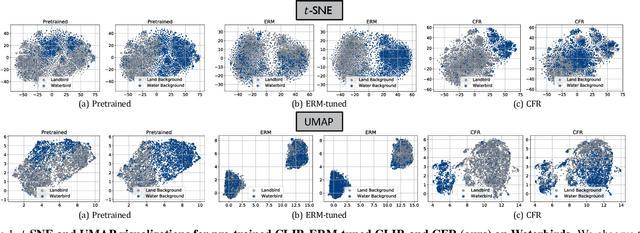
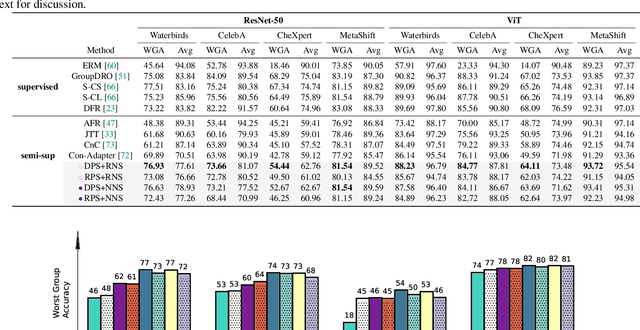
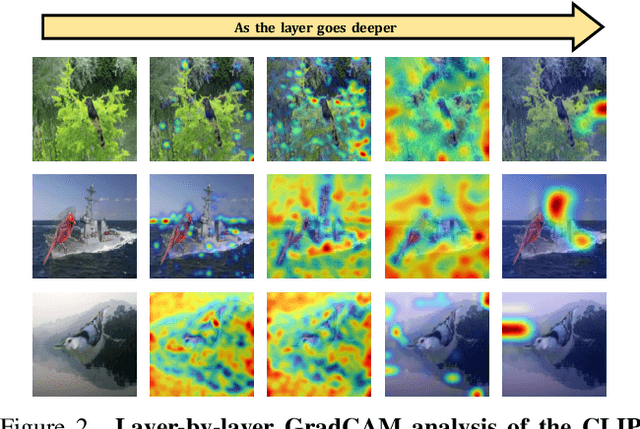
Fine-tuning pre-trained vision-language models, like CLIP, has yielded success on diverse downstream tasks. However, several pain points persist for this paradigm: (i) directly tuning entire pre-trained models becomes both time-intensive and computationally costly. Additionally, these tuned models tend to become highly specialized, limiting their practicality for real-world deployment; (ii) recent studies indicate that pre-trained vision-language classifiers may overly depend on spurious features -- patterns that correlate with the target in training data, but are not related to the true labeling function; and (iii) existing studies on mitigating the reliance on spurious features, largely based on the assumption that we can identify such features, does not provide definitive assurance for real-world applications. As a piloting study, this work focuses on exploring mitigating the reliance on spurious features for CLIP without using any group annotation. To this end, we systematically study the existence of spurious correlation on CLIP and CILP+ERM. We first, following recent work on Deep Feature Reweighting (DFR), verify that last-layer retraining can greatly improve group robustness on pretrained CLIP. In view of them, we advocate a lightweight representation calibration method for fine-tuning CLIP, by first generating a calibration set using the pretrained CLIP, and then calibrating representations of samples within this set through contrastive learning, all without the need for group labels. Extensive experiments and in-depth visualizations on several benchmarks validate the effectiveness of our proposals, largely reducing reliance and significantly boosting the model generalization.
Accelerated Inference and Reduced Forgetting: The Dual Benefits of Early-Exit Networks in Continual Learning
Mar 12, 2024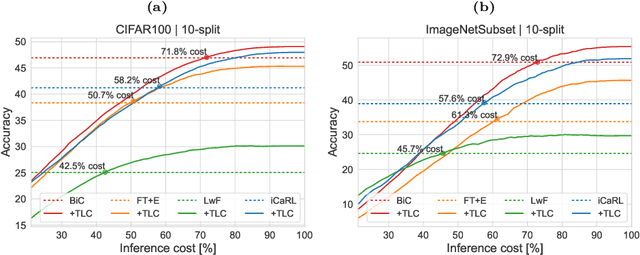
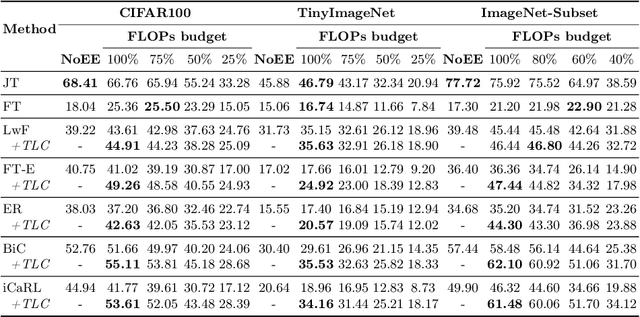
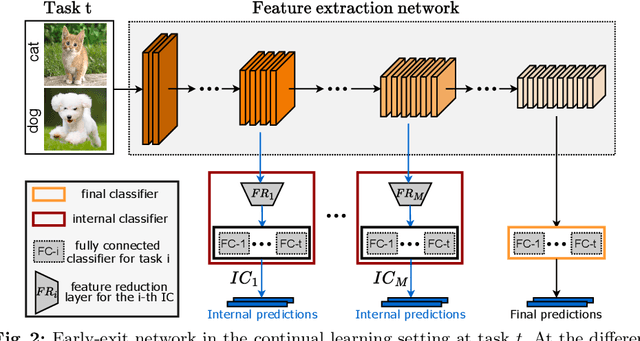
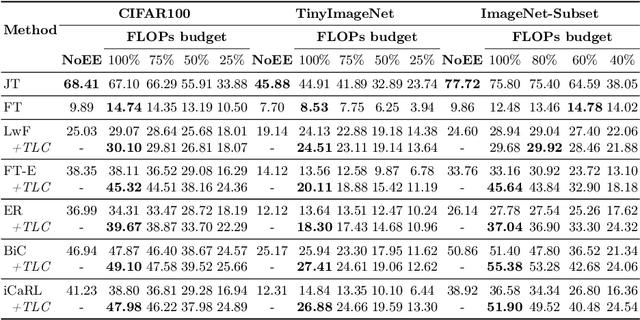
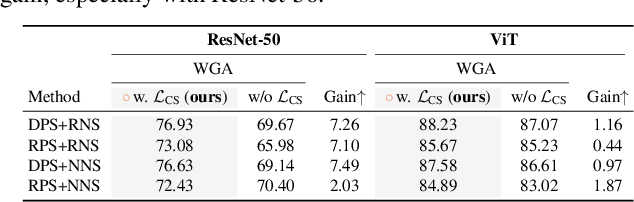
Driven by the demand for energy-efficient employment of deep neural networks, early-exit methods have experienced a notable increase in research attention. These strategies allow for swift predictions by making decisions early in the network, thereby conserving computation time and resources. However, so far the early-exit networks have only been developed for stationary data distributions, which restricts their application in real-world scenarios with continuous non-stationary data. This study aims to explore the continual learning of the early-exit networks. We adapt existing continual learning methods to fit with early-exit architectures and investigate their behavior in the continual setting. We notice that early network layers exhibit reduced forgetting and can outperform standard networks even when using significantly fewer resources. Furthermore, we analyze the impact of task-recency bias on early-exit inference and propose Task-wise Logits Correction (TLC), a simple method that equalizes this bias and improves the network performance for every given compute budget in the class-incremental setting. We assess the accuracy and computational cost of various continual learning techniques enhanced with early-exits and TLC across standard class-incremental learning benchmarks such as 10 split CIFAR100 and ImageNetSubset and show that TLC can achieve the accuracy of the standard methods using less than 70\% of their computations. Moreover, at full computational budget, our method outperforms the accuracy of the standard counterparts by up to 15 percentage points. Our research underscores the inherent synergy between early-exit networks and continual learning, emphasizing their practical utility in resource-constrained environments.
AutoEval Done Right: Using Synthetic Data for Model Evaluation
Mar 09, 2024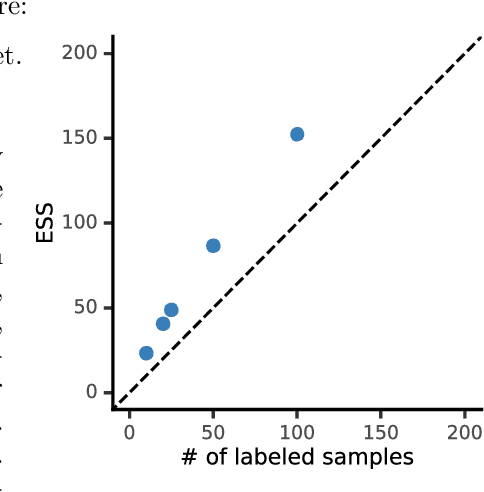
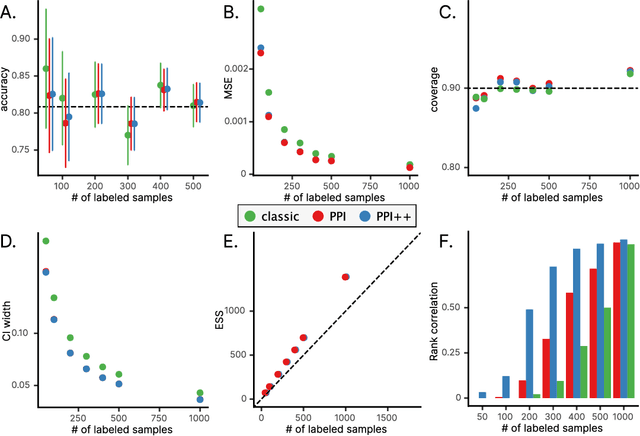
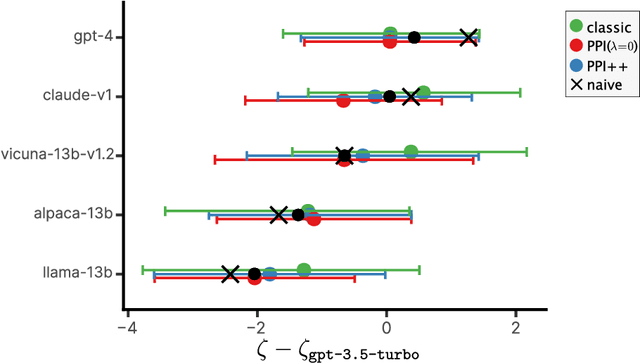
The evaluation of machine learning models using human-labeled validation data can be expensive and time-consuming. AI-labeled synthetic data can be used to decrease the number of human annotations required for this purpose in a process called autoevaluation. We suggest efficient and statistically principled algorithms for this purpose that improve sample efficiency while remaining unbiased. These algorithms increase the effective human-labeled sample size by up to 50% on experiments with GPT-4.
Robust MITL planning under uncertain navigation times
Mar 06, 2024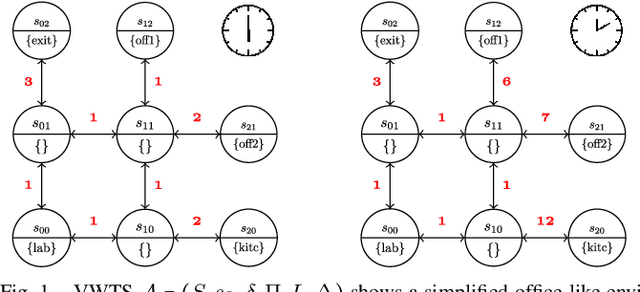
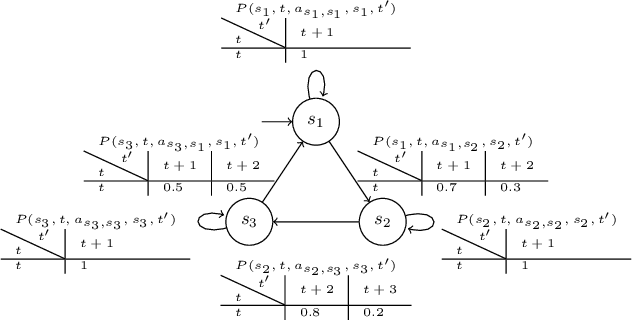
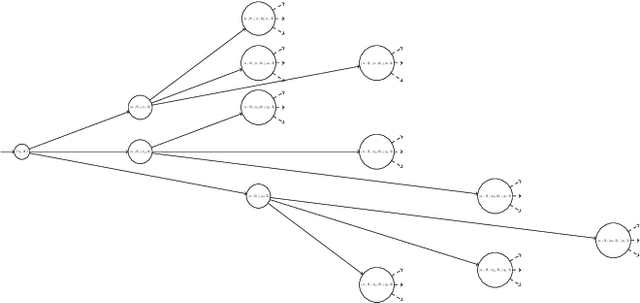
In environments like offices, the duration of a robot's navigation between two locations may vary over time. For instance, reaching a kitchen may take more time during lunchtime since the corridors are crowded with people heading the same way. In this work, we address the problem of routing in such environments with tasks expressed in Metric Interval Temporal Logic (MITL) - a rich robot task specification language that allows us to capture explicit time requirements. Our objective is to find a strategy that maximizes the temporal robustness of the robot's MITL task. As the first step towards a solution, we define a Mixed-integer linear programming approach to solving the task planning problem over a Varying Weighted Transition System, where navigation durations are deterministic but vary depending on the time of day. Then, we apply this planner to optimize for MITL temporal robustness in Markov Decision Processes, where the navigation durations between physical locations are uncertain, but the time-dependent distribution over possible delays is known. Finally, we develop a receding horizon planner for Markov Decision Processes that preserves guarantees over MITL temporal robustness. We show the scalability of our planning algorithms in simulations of robotic tasks.
RF-Flashlight Testbed for Verification of Real-Time Geofencing of EESS Radiometers and Millimeter-Wave Ground-to-Satellite Propagation Models
Feb 28, 2024A simple 'RF-flashlight' (or ground to satellite) interference testbed is proposed to experimentally verify real-time geofencing (RTG) for protecting passive Earth Exploration Satellite Services (EESS) radiometer measurements from 5G or 6G mm-wave transmissions, and ground to satellite propagation models used in the interference modeling of this spectrum coexistence scenario. RTG is a stronger EESS protection mechanism than the current methodology recommended by the ITU based on a worst-case interference threshold while simultaneously enabling dynamic spectrum sharing and coexistence with 5G or 6G wireless networks. Similarly, verifying more sophisticated RF propagation models that include ground topology, buildings, and non-line-of-sight paths will provide better estimates of interference than the current ITU line-of-sight model and, thus, a more reliable basis for establishing a consensus among the spectrum stakeholders.
Blockchain-Enabled Variational Information Bottleneck for IoT Networks
Mar 10, 2024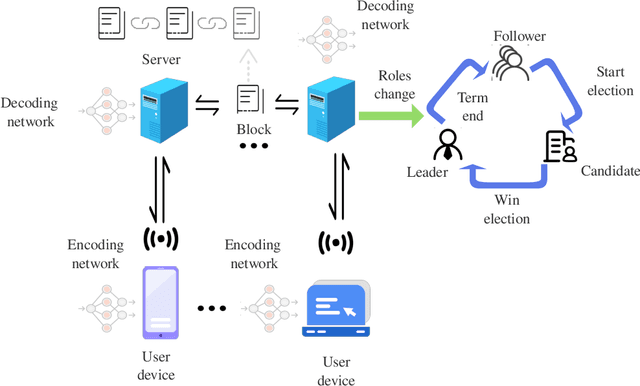
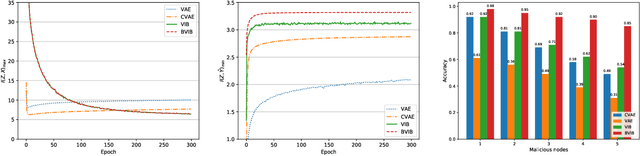
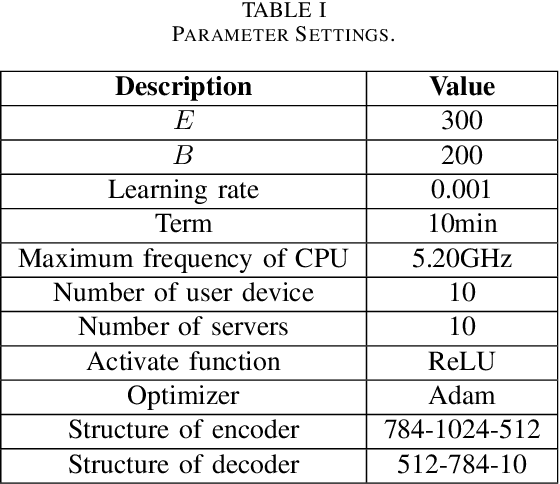
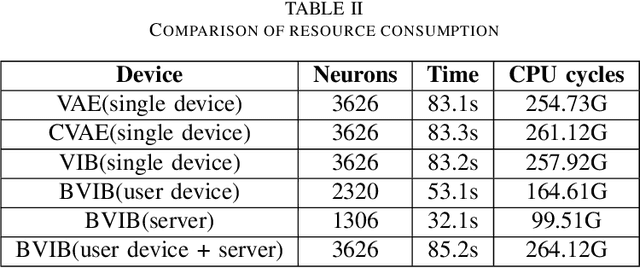
In Internet of Things (IoT) networks, the amount of data sensed by user devices may be huge, resulting in the serious network congestion. To solve this problem, intelligent data compression is critical. The variational information bottleneck (VIB) approach, combined with machine learning, can be employed to train the encoder and decoder, so that the required transmission data size can be reduced significantly. However, VIB suffers from the computing burden and network insecurity. In this paper, we propose a blockchain-enabled VIB (BVIB) approach to relieve the computing burden while guaranteeing network security. Extensive simulations conducted by Python and C++ demonstrate that BVIB outperforms VIB by 36%, 22% and 57% in terms of time and CPU cycles cost, mutual information, and accuracy under attack, respectively.
Enhancing Mean-Reverting Time Series Prediction with Gaussian Processes: Functional and Augmented Data Structures in Financial Forecasting
Feb 23, 2024
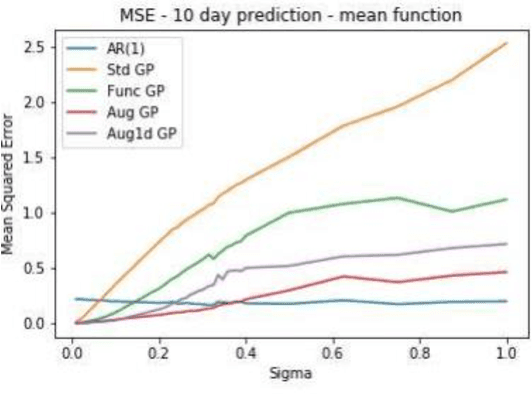
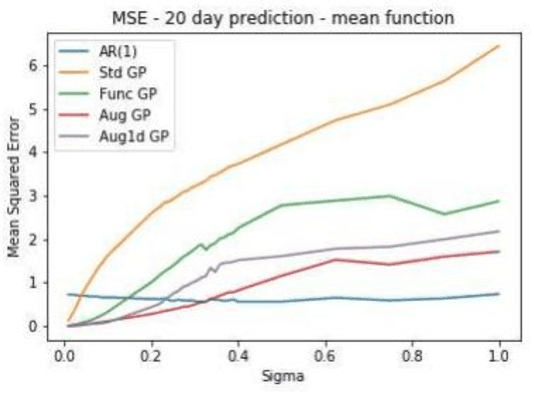
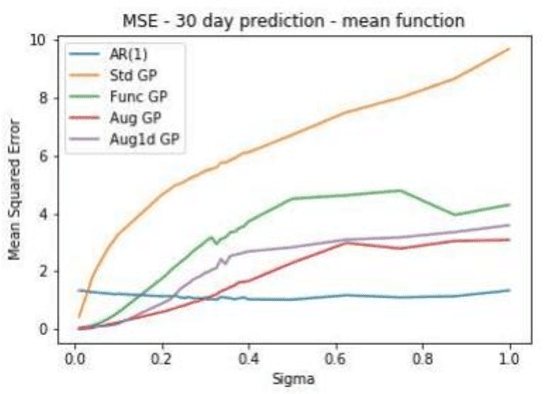
In this paper, we explore the application of Gaussian Processes (GPs) for predicting mean-reverting time series with an underlying structure, using relatively unexplored functional and augmented data structures. While many conventional forecasting methods concentrate on the short-term dynamics of time series data, GPs offer the potential to forecast not just the average prediction but the entire probability distribution over a future trajectory. This is particularly beneficial in financial contexts, where accurate predictions alone may not suffice if incorrect volatility assessments lead to capital losses. Moreover, in trade selection, GPs allow for the forecasting of multiple Sharpe ratios adjusted for transaction costs, aiding in decision-making. The functional data representation utilized in this study enables longer-term predictions by leveraging information from previous years, even as the forecast moves away from the current year's training data. Additionally, the augmented representation enriches the training set by incorporating multiple targets for future points in time, facilitating long-term predictions. Our implementation closely aligns with the methodology outlined in, which assessed effectiveness on commodity futures. However, our testing methodology differs. Instead of real data, we employ simulated data with similar characteristics. We construct a testing environment to evaluate both data representations and models under conditions of increasing noise, fat tails, and inappropriate kernels-conditions commonly encountered in practice. By simulating data, we can compare our forecast distribution over time against a full simulation of the actual distribution of our test set, thereby reducing the inherent uncertainty in testing time series models on real data. We enable feature prediction through augmentation and employ sub-sampling to ensure the feasibility of GPs.
Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts
Mar 08, 2024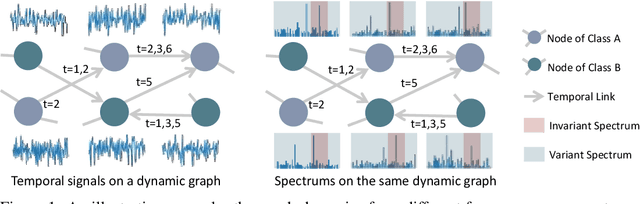
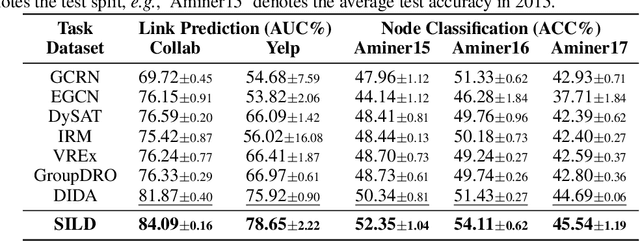
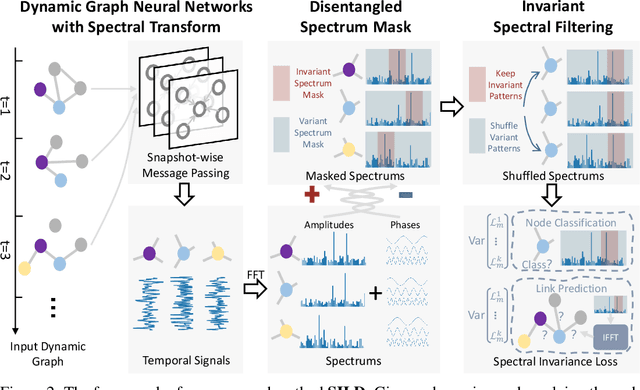
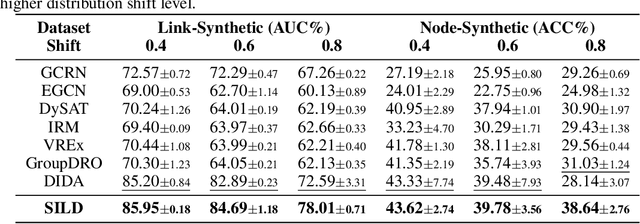
Dynamic graph neural networks (DyGNNs) currently struggle with handling distribution shifts that are inherent in dynamic graphs. Existing work on DyGNNs with out-of-distribution settings only focuses on the time domain, failing to handle cases involving distribution shifts in the spectral domain. In this paper, we discover that there exist cases with distribution shifts unobservable in the time domain while observable in the spectral domain, and propose to study distribution shifts on dynamic graphs in the spectral domain for the first time. However, this investigation poses two key challenges: i) it is non-trivial to capture different graph patterns that are driven by various frequency components entangled in the spectral domain; and ii) it remains unclear how to handle distribution shifts with the discovered spectral patterns. To address these challenges, we propose Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts (SILD), which can handle distribution shifts on dynamic graphs by capturing and utilizing invariant and variant spectral patterns. Specifically, we first design a DyGNN with Fourier transform to obtain the ego-graph trajectory spectrums, allowing the mixed dynamic graph patterns to be transformed into separate frequency components. We then develop a disentangled spectrum mask to filter graph dynamics from various frequency components and discover the invariant and variant spectral patterns. Finally, we propose invariant spectral filtering, which encourages the model to rely on invariant patterns for generalization under distribution shifts. Experimental results on synthetic and real-world dynamic graph datasets demonstrate the superiority of our method for both node classification and link prediction tasks under distribution shifts.