 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Dynamic Graph Embeddings with Neural Controlled Differential Equations
Feb 22, 2023
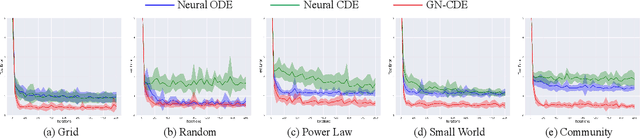

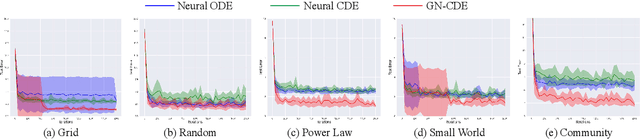

This paper focuses on representation learning for dynamic graphs with temporal interactions. A fundamental issue is that both the graph structure and the nodes own their own dynamics, and their blending induces intractable complexity in the temporal evolution over graphs. Drawing inspiration from the recent process of physical dynamic models in deep neural networks, we propose Graph Neural Controlled Differential Equation (GN-CDE) model, a generic differential model for dynamic graphs that characterise the continuously dynamic evolution of node embedding trajectories with a neural network parameterised vector field and the derivatives of interactions w.r.t. time. Our framework exhibits several desirable characteristics, including the ability to express dynamics on evolving graphs without integration by segments, the capability to calibrate trajectories with subsequent data, and robustness to missing observations. Empirical evaluation on a range of dynamic graph representation learning tasks demonstrates the superiority of our proposed approach compared to the baselines.
A Novel Vector-Field-Based Motion Planning for 3D Nonholonomic Robots
Feb 22, 2023
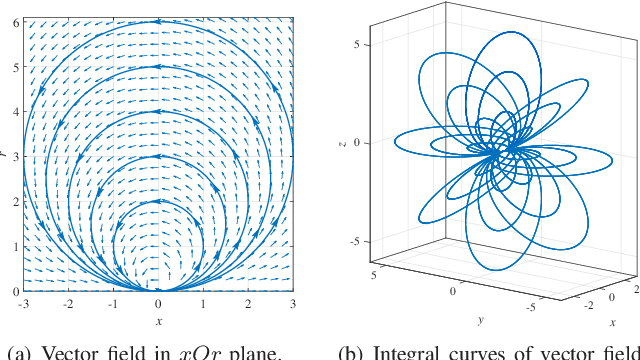
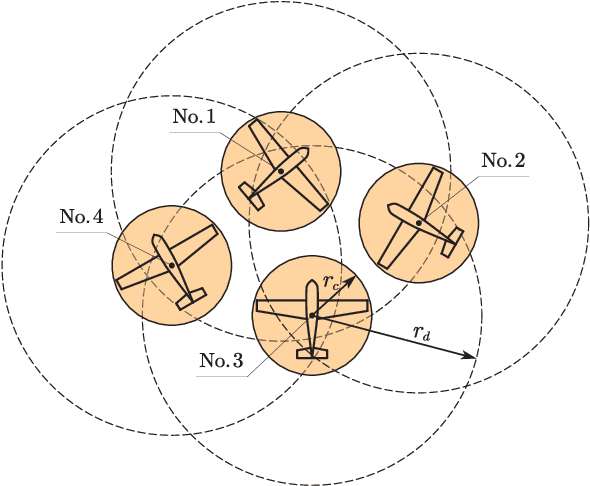
This paper focuses on the motion planning for mobile robots in 3D, which are modelled by 6-DOF rigid body systems with nonholonomic constraints. We not only specify the target position, but also bring in the requirement of the heading direction at the terminal time, which gives rise to a new and more challenging 3D motion planning problem. The proposed planning algorithm involves a novel velocity vector field (VF) over the workspace, and by following the VF, the robot can be navigated to the destination with the specified heading direction. In order to circumvent potential collisions with obstacles and other robots, a composite VF is presented by composing the navigation VF and an additional VF tangential to the boundary of the dangerous area. Moreover, we propose a priority-based algorithm to deal with the motion coupling among multiple robots. Finally, numerical simulations are conducted to verify the theoretical results.
FOSI: Hybrid First and Second Order Optimization
Feb 23, 2023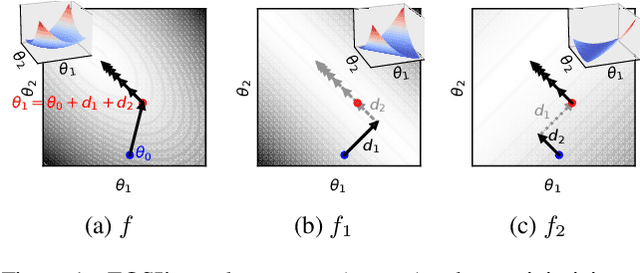
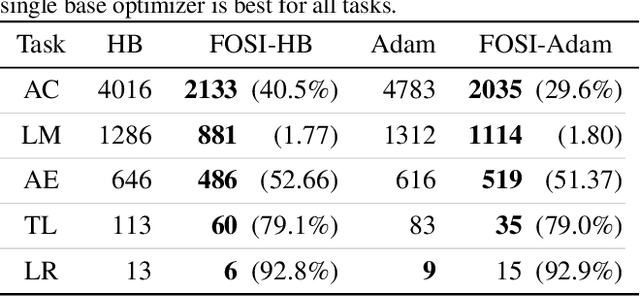
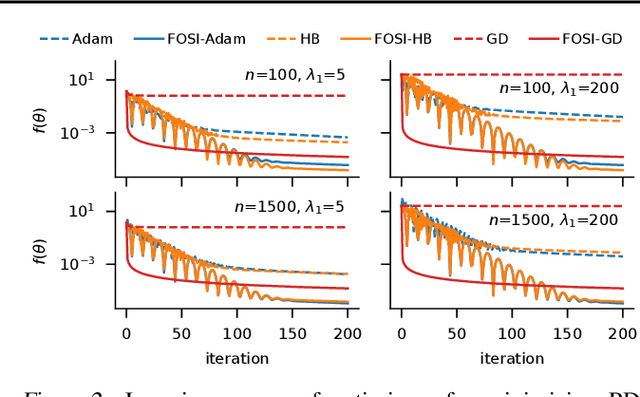

Though second-order optimization methods are highly effective, popular approaches in machine learning such as SGD and Adam use only first-order information due to the difficulty of computing curvature in high dimensions. We present FOSI, a novel meta-algorithm that improves the performance of any first-order optimizer by efficiently incorporating second-order information during the optimization process. In each iteration, FOSI implicitly splits the function into two quadratic functions defined on orthogonal subspaces, then uses a second-order method to minimize the first, and the base optimizer to minimize the other. Our analysis of FOSI's preconditioner and effective Hessian proves that FOSI improves the condition number for a large family of optimizers. Our empirical evaluation demonstrates that FOSI improves the convergence rate and optimization time of GD, Heavy-Ball, and Adam when applied to several deep neural networks training tasks such as audio classification, transfer learning, and object classification and when applied to convex functions.
CP+: Camera Poses Augmentation with Large-scale LiDAR Maps
Feb 23, 2023
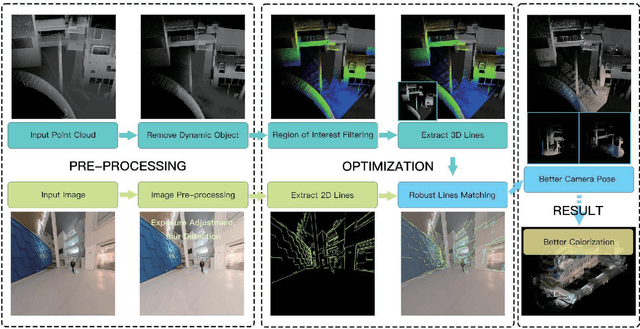
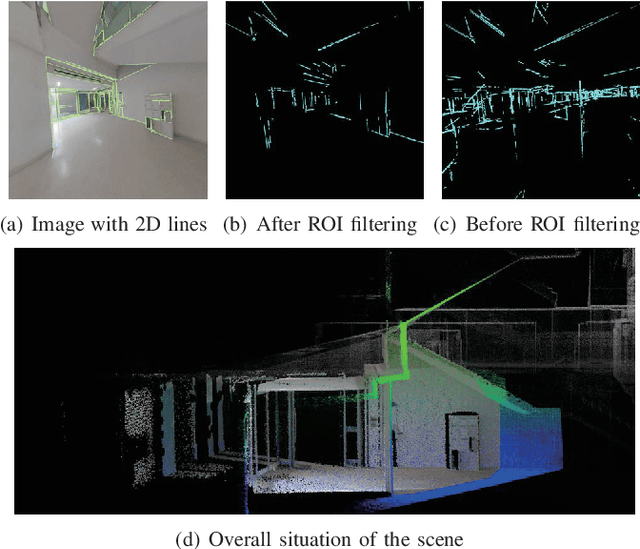

Large-scale colored point clouds have many advantages in navigation or scene display. Relying on cameras and LiDARs, which are now widely used in reconstruction tasks, it is possible to obtain such colored point clouds. However, the information from these two kinds of sensors is not well fused in many existing frameworks, resulting in poor colorization results, thus resulting in inaccurate camera poses and damaged point colorization results. We propose a novel framework called Camera Pose Augmentation (CP+) to improve the camera poses and align them directly with the LiDAR-based point cloud. Initial coarse camera poses are given by LiDAR-Inertial or LiDAR-Inertial-Visual Odometry with approximate extrinsic parameters and time synchronization. The key steps to improve the alignment of the images consist of selecting a point cloud corresponding to a region of interest in each camera view, extracting reliable edge features from this point cloud, and deriving 2D-3D line correspondences which are used towards iterative minimization of the re-projection error.
Generalization of Auto-Regressive Hidden Markov Models to Non-Linear Dynamics and Non-Euclidean Observation Space
Feb 23, 2023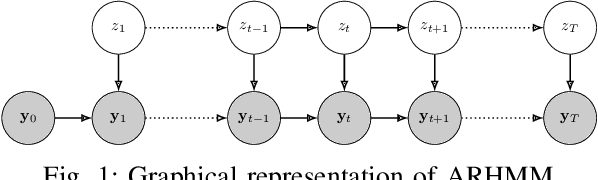
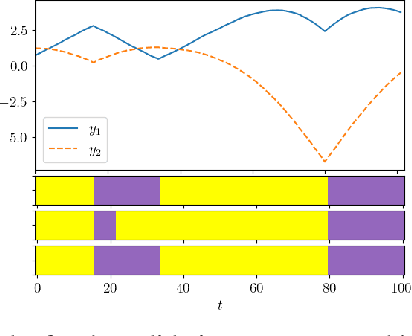
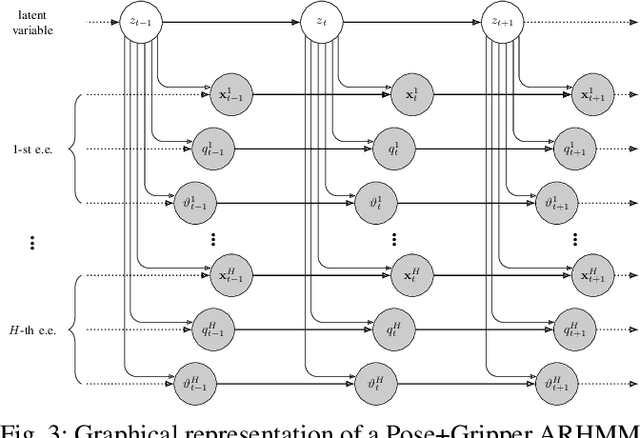
Latent variable models are widely used to perform unsupervised segmentation of time series in different context such as robotics, speech recognition, and economics. One of the most widely used latent variable model is the Auto-Regressive Hidden Markov Model (ARHMM), which combines a latent mode governed by a Markov chain dynamics with a linear Auto-Regressive dynamics of the observed state. In this work, we propose two generalizations of the ARHMM. First, we propose a more general AR dynamics in Cartesian space, described as a linear combination of non-linear basis functions. Second, we propose a linear dynamics in unit quaternion space, in order to properly describe orientations. These extensions allow to describe more complex dynamics of the observed state. Although this extension is proposed for the ARHMM, it can be easily extended to other latent variable models with AR dynamics in the observed space, such as Auto-Regressive Hidden semi-Markov Models.
Frequency bin-wise single channel speech presence probability estimation using multiple DNNs
Feb 23, 2023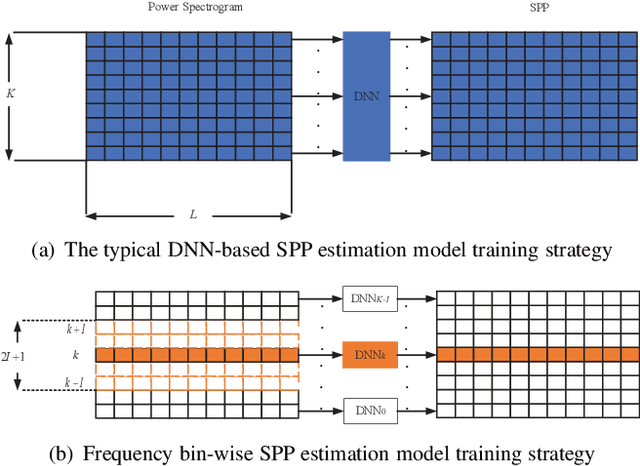
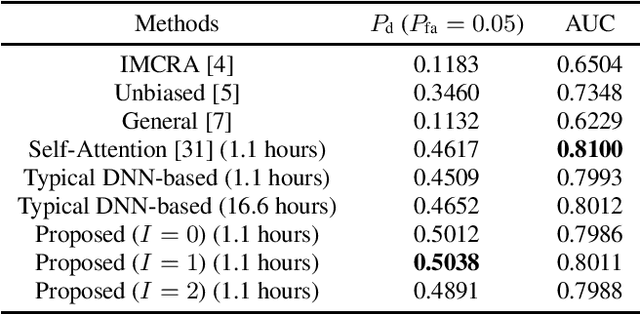
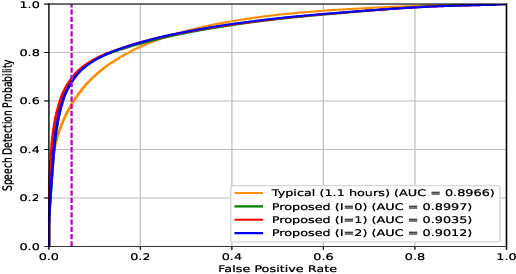
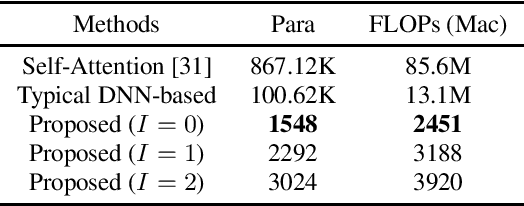
In this work, we propose a frequency bin-wise method to estimate the single-channel speech presence probability (SPP) with multiple deep neural networks (DNNs) in the short-time Fourier transform domain. Since all frequency bins are typically considered simultaneously as input features for conventional DNN-based SPP estimators, high model complexity is inevitable. To reduce the model complexity and the requirements on the training data, we take a single frequency bin and some of its neighboring frequency bins into account to train separate gate recurrent units. In addition, the noisy speech and the a posteriori probability SPP representation are used to train our model. The experiments were performed on the Deep Noise Suppression challenge dataset. The experimental results show that the speech detection accuracy can be improved when we employ the frequency bin-wise model. Finally, we also demonstrate that our proposed method outperforms most of the state-of-the-art SPP estimation methods in terms of speech detection accuracy and model complexity.
Communication-Efficient Distributed Estimation and Inference for Cox's Model
Feb 23, 2023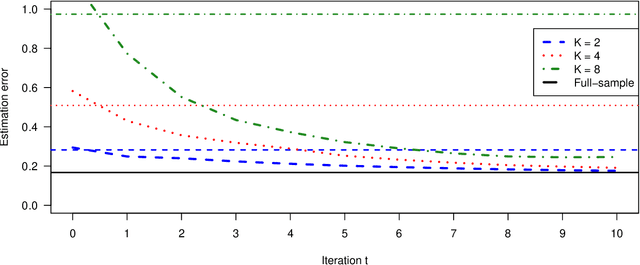

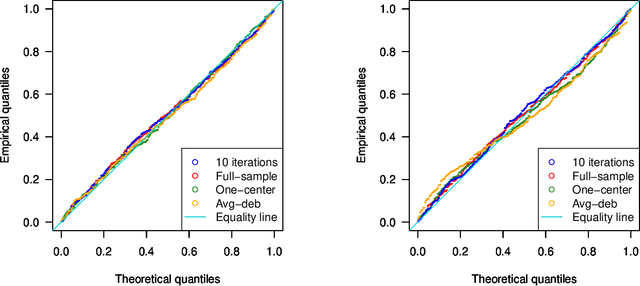
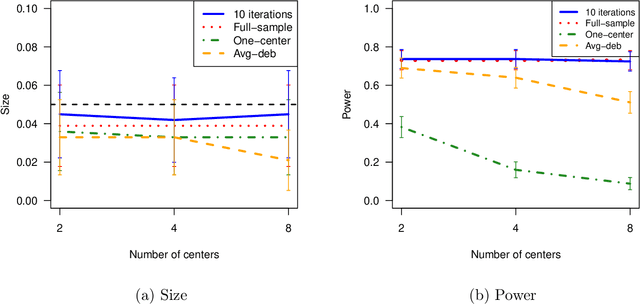
Motivated by multi-center biomedical studies that cannot share individual data due to privacy and ownership concerns, we develop communication-efficient iterative distributed algorithms for estimation and inference in the high-dimensional sparse Cox proportional hazards model. We demonstrate that our estimator, even with a relatively small number of iterations, achieves the same convergence rate as the ideal full-sample estimator under very mild conditions. To construct confidence intervals for linear combinations of high-dimensional hazard regression coefficients, we introduce a novel debiased method, establish central limit theorems, and provide consistent variance estimators that yield asymptotically valid distributed confidence intervals. In addition, we provide valid and powerful distributed hypothesis tests for any coordinate element based on a decorrelated score test. We allow time-dependent covariates as well as censored survival times. Extensive numerical experiments on both simulated and real data lend further support to our theory and demonstrate that our communication-efficient distributed estimators, confidence intervals, and hypothesis tests improve upon alternative methods.
On the Generalization Ability of Retrieval-Enhanced Transformers
Feb 23, 2023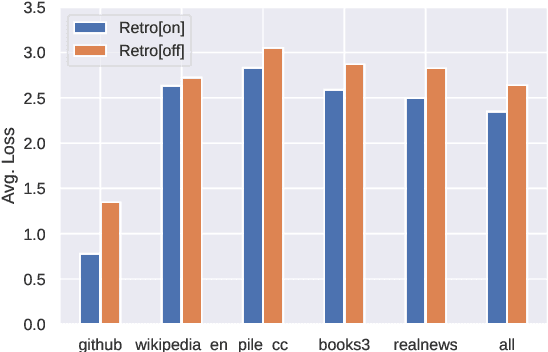
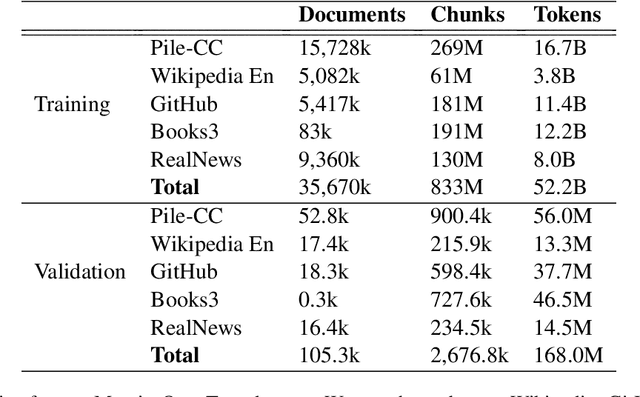
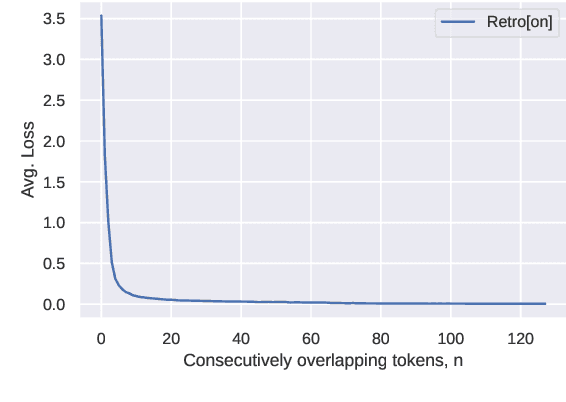
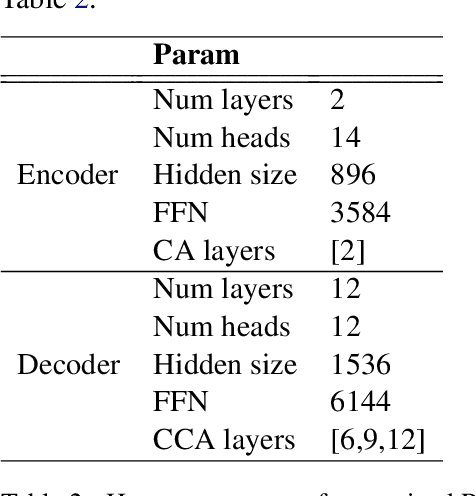
Recent work on the Retrieval-Enhanced Transformer (RETRO) model has shown that off-loading memory from trainable weights to a retrieval database can significantly improve language modeling and match the performance of non-retrieval models that are an order of magnitude larger in size. It has been suggested that at least some of this performance gain is due to non-trivial generalization based on both model weights and retrieval. In this paper, we try to better understand the relative contributions of these two components. We find that the performance gains from retrieval largely originate from overlapping tokens between the database and the test data, suggesting less non-trivial generalization than previously assumed. More generally, our results point to the challenges of evaluating the generalization of retrieval-augmented language models such as RETRO, as even limited token overlap may significantly decrease test-time loss. We release our code and model at https://github.com/TobiasNorlund/retro
Intermittently Observable Markov Decision Processes
Feb 23, 2023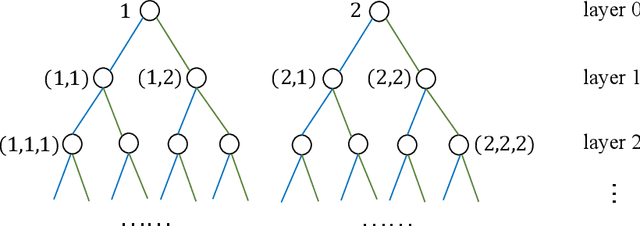
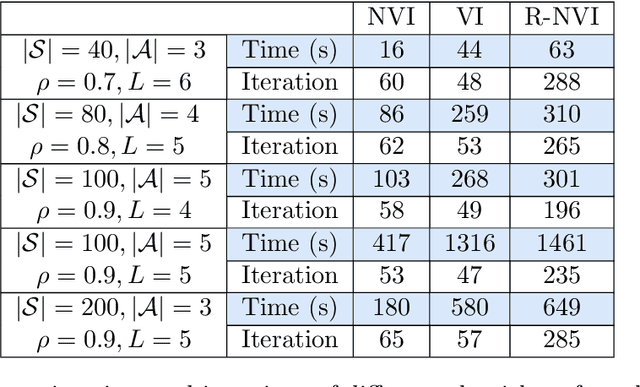
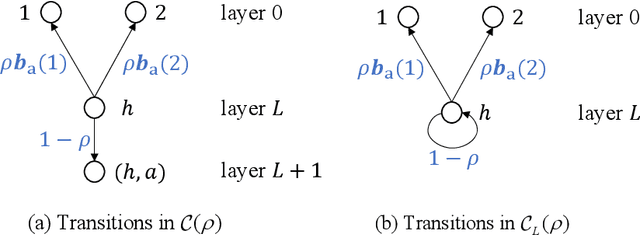
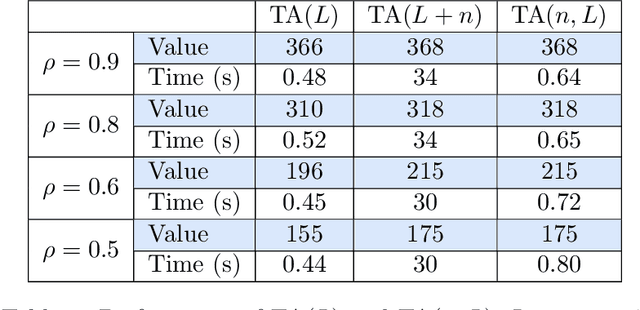
This paper investigates MDPs with intermittent state information. We consider a scenario where the controller perceives the state information of the process via an unreliable communication channel. The transmissions of state information over the whole time horizon are modeled as a Bernoulli lossy process. Hence, the problem is finding an optimal policy for selecting actions in the presence of state information losses. We first formulate the problem as a belief MDP to establish structural results. The effect of state information losses on the expected total discounted reward is studied systematically. Then, we reformulate the problem as a tree MDP whose state space is organized in a tree structure. Two finite-state approximations to the tree MDP are developed to find near-optimal policies efficiently. Finally, we put forth a nested value iteration algorithm for the finite-state approximations, which is proved to be faster than standard value iteration. Numerical results demonstrate the effectiveness of our methods.
Regularized Graph Structure Learning with Semantic Knowledge for Multi-variates Time-Series Forecasting
Oct 12, 2022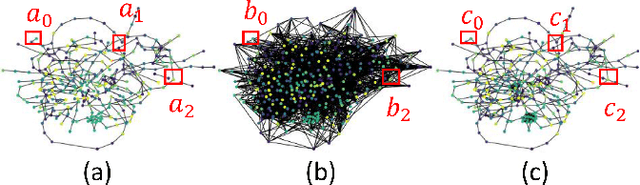
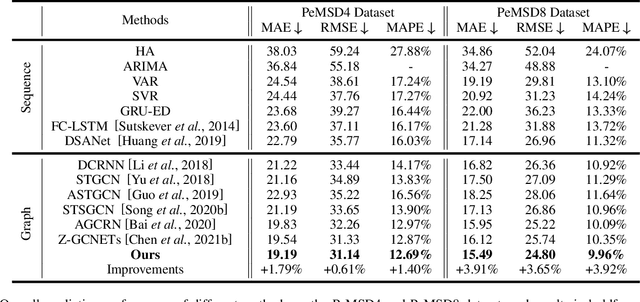
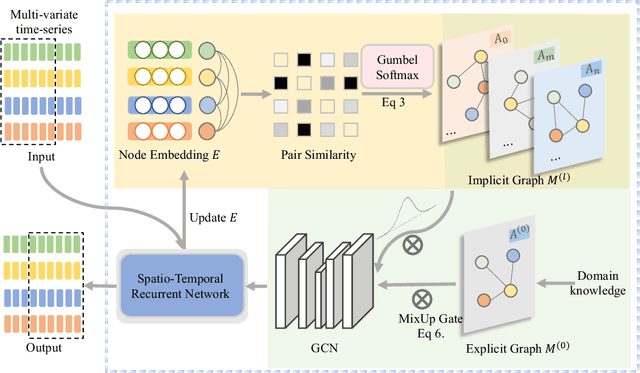
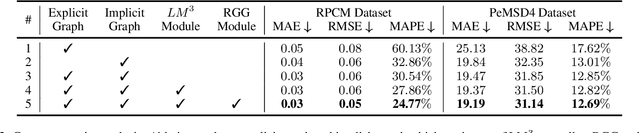
Multivariate time-series forecasting is a critical task for many applications, and graph time-series network is widely studied due to its capability to capture the spatial-temporal correlation simultaneously. However, most existing works focus more on learning with the explicit prior graph structure, while ignoring potential information from the implicit graph structure, yielding incomplete structure modeling. Some recent works attempt to learn the intrinsic or implicit graph structure directly while lacking a way to combine explicit prior structure with implicit structure together. In this paper, we propose Regularized Graph Structure Learning (RGSL) model to incorporate both explicit prior structure and implicit structure together, and learn the forecasting deep networks along with the graph structure. RGSL consists of two innovative modules. First, we derive an implicit dense similarity matrix through node embedding, and learn the sparse graph structure using the Regularized Graph Generation (RGG) based on the Gumbel Softmax trick. Second, we propose a Laplacian Matrix Mixed-up Module (LM3) to fuse the explicit graph and implicit graph together. We conduct experiments on three real-word datasets. Results show that the proposed RGSL model outperforms existing graph forecasting algorithms with a notable margin, while learning meaningful graph structure simultaneously. Our code and models are made publicly available at https://github.com/alipay/RGSL.git.