 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Lumos: Heterogeneity-aware Federated Graph Learning over Decentralized Devices
Mar 01, 2023
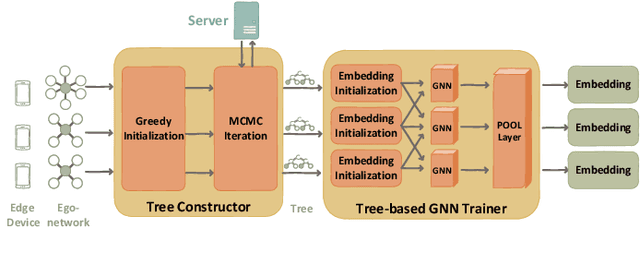
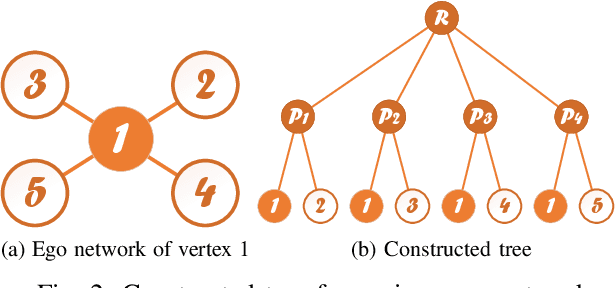
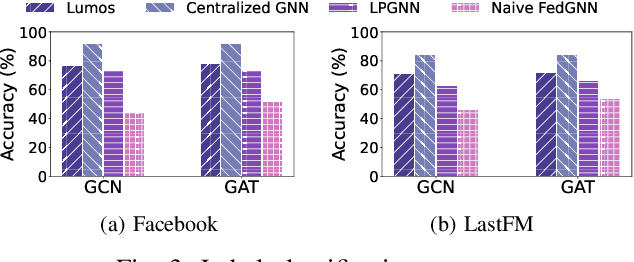
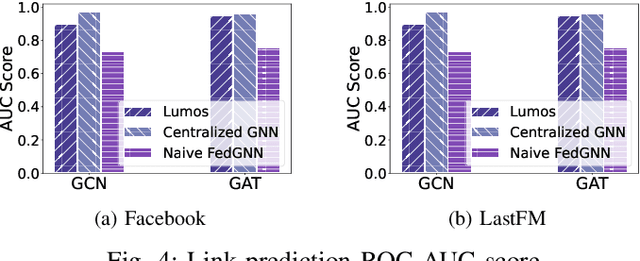
Graph neural networks (GNN) have been widely deployed in real-world networked applications and systems due to their capability to handle graph-structured data. However, the growing awareness of data privacy severely challenges the traditional centralized model training paradigm, where a server holds all the graph information. Federated learning is an emerging collaborative computing paradigm that allows model training without data centralization. Existing federated GNN studies mainly focus on systems where clients hold distinctive graphs or sub-graphs. The practical node-level federated situation, where each client is only aware of its direct neighbors, has yet to be studied. In this paper, we propose the first federated GNN framework called Lumos that supports supervised and unsupervised learning with feature and degree protection on node-level federated graphs. We first design a tree constructor to improve the representation capability given the limited structural information. We further present a Monte Carlo Markov Chain-based algorithm to mitigate the workload imbalance caused by degree heterogeneity with theoretically-guaranteed performance. Based on the constructed tree for each client, a decentralized tree-based GNN trainer is proposed to support versatile training. Extensive experiments demonstrate that Lumos outperforms the baseline with significantly higher accuracy and greatly reduced communication cost and training time.
Speeding Up EfficientNet: Selecting Update Blocks of Convolutional Neural Networks using Genetic Algorithm in Transfer Learning
Mar 01, 2023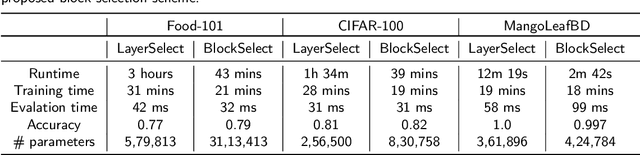
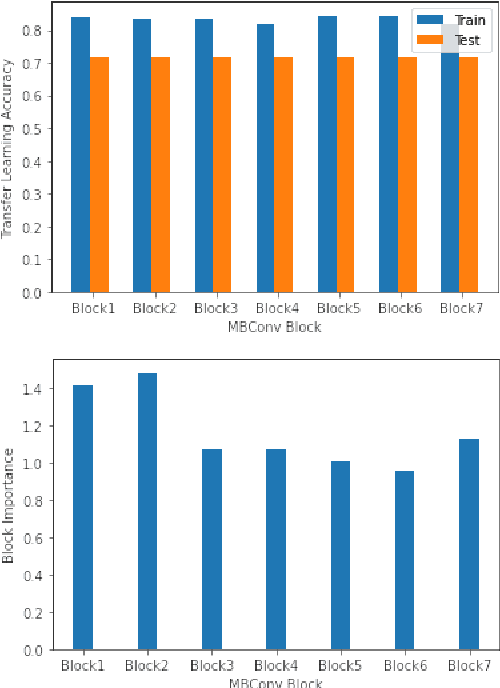
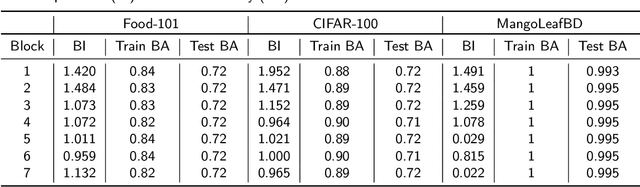
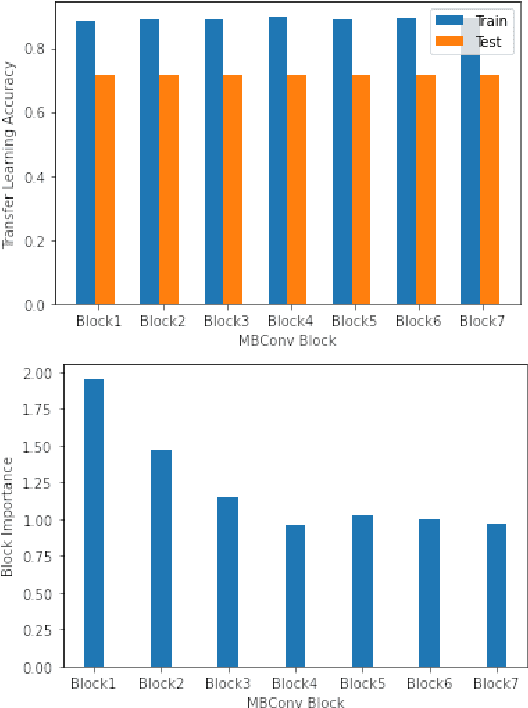
The performance of convolutional neural networks (CNN) depends heavily on their architectures. Transfer learning performance of a CNN relies quite strongly on selection of its trainable layers. Selecting the most effective update layers for a certain target dataset often requires expert knowledge on CNN architecture which many practitioners do not posses. General users prefer to use an available architecture (e.g. GoogleNet, ResNet, EfficientNet etc.) that is developed by domain experts. With the ever-growing number of layers, it is increasingly becoming quite difficult and cumbersome to handpick the update layers. Therefore, in this paper we explore the application of genetic algorithm to mitigate this problem. The convolutional layers of popular pretrained networks are often grouped into modules that constitute their building blocks. We devise a genetic algorithm to select blocks of layers for updating the parameters. By experimenting with EfficientNetB0 pre-trained on ImageNet and using Food-101, CIFAR-100 and MangoLeafBD as target datasets, we show that our algorithm yields similar or better results than the baseline in terms of accuracy, and requires lower training and evaluation time due to learning less number of parameters. We also devise a metric called block importance to measure efficacy of each block as update block and analyze the importance of the blocks selected by our algorithm.
Soft Prompt Guided Joint Learning for Cross-Domain Sentiment Analysis
Mar 01, 2023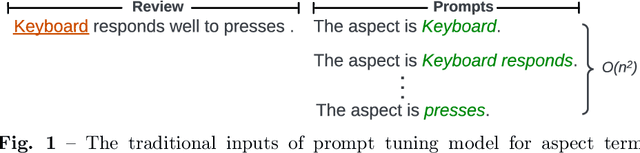

Aspect term extraction is a fundamental task in fine-grained sentiment analysis, which aims at detecting customer's opinion targets from reviews on product or service. The traditional supervised models can achieve promising results with annotated datasets, however, the performance dramatically decreases when they are applied to the task of cross-domain aspect term extraction. Existing cross-domain transfer learning methods either directly inject linguistic features into Language models, making it difficult to transfer linguistic knowledge to target domain, or rely on the fixed predefined prompts, which is time-consuming to construct the prompts over all potential aspect term spans. To resolve the limitations, we propose a soft prompt-based joint learning method for cross domain aspect term extraction in this paper. Specifically, by incorporating external linguistic features, the proposed method learn domain-invariant representations between source and target domains via multiple objectives, which bridges the gap between domains with varied distributions of aspect terms. Further, the proposed method interpolates a set of transferable soft prompts consisted of multiple learnable vectors that are beneficial to detect aspect terms in target domain. Extensive experiments are conducted on the benchmark datasets and the experimental results demonstrate the effectiveness of the proposed method for cross-domain aspect terms extraction.
HelixSurf: A Robust and Efficient Neural Implicit Surface Learning of Indoor Scenes with Iterative Intertwined Regularization
Mar 01, 2023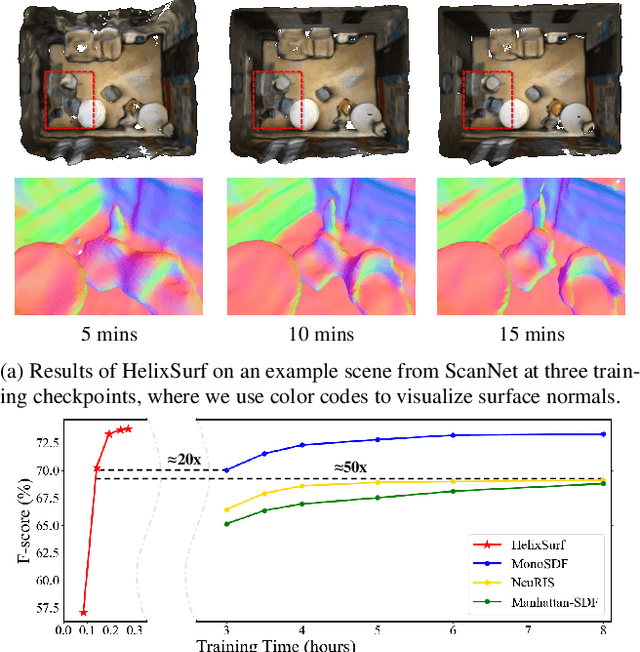
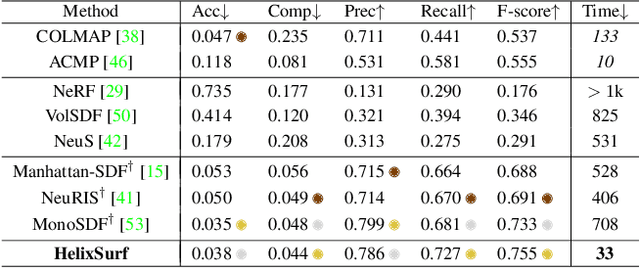
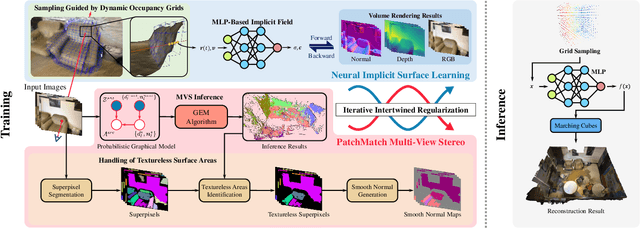
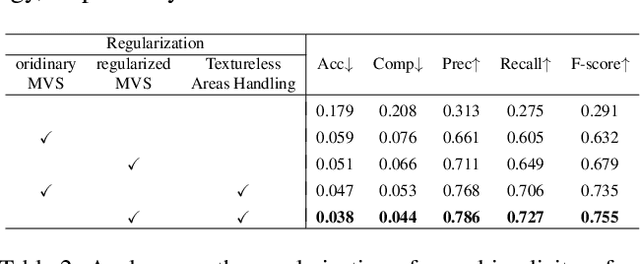
Recovery of an underlying scene geometry from multiview images stands as a long-time challenge in computer vision research. The recent promise leverages neural implicit surface learning and differentiable volume rendering, and achieves both the recovery of scene geometry and synthesis of novel views, where deep priors of neural models are used as an inductive smoothness bias. While promising for object-level surfaces, these methods suffer when coping with complex scene surfaces. In the meanwhile, traditional multi-view stereo can recover the geometry of scenes with rich textures, by globally optimizing the local, pixel-wise correspondences across multiple views. We are thus motivated to make use of the complementary benefits from the two strategies, and propose a method termed Helix-shaped neural implicit Surface learning or HelixSurf; HelixSurf uses the intermediate prediction from one strategy as the guidance to regularize the learning of the other one, and conducts such intertwined regularization iteratively during the learning process. We also propose an efficient scheme for differentiable volume rendering in HelixSurf. Experiments on surface reconstruction of indoor scenes show that our method compares favorably with existing methods and is orders of magnitude faster, even when some of existing methods are assisted with auxiliary training data. The source code is available at https://github.com/Gorilla-Lab-SCUT/HelixSurf.
Koopman Operator Learning: Sharp Spectral Rates and Spurious Eigenvalues
Feb 07, 2023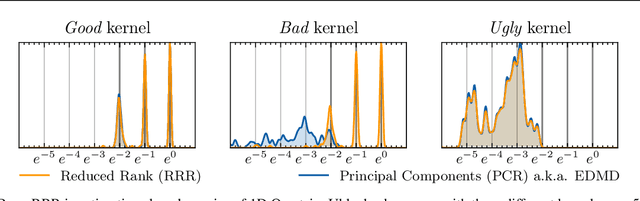
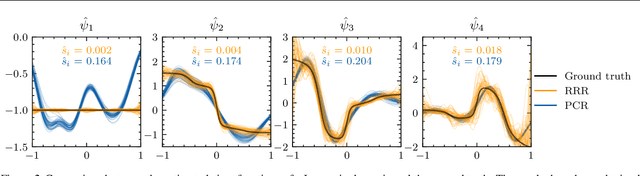
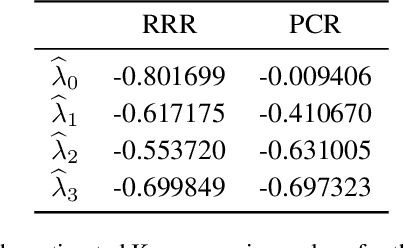
Non-linear dynamical systems can be handily described by the associated Koopman operator, whose action evolves every observable of the system forward in time. Learning the Koopman operator from data is enabled by a number of algorithms. In this work we present nonasymptotic learning bounds for the Koopman eigenvalues and eigenfunctions estimated by two popular algorithms: Extended Dynamic Mode Decomposition (EDMD) and Reduced Rank Regression (RRR). We focus on time-reversal-invariant Markov chains, implying that the Koopman operator is self-adjoint. This includes important examples of stochastic dynamical systems, notably Langevin dynamics. Our spectral learning bounds are driven by the simultaneous control of the operator norm risk of the estimators and a metric distortion associated to the corresponding eigenfunctions. Our analysis indicates that both algorithms have similar variance, but EDMD suffers from a larger bias which might be detrimental to its learning rate. We further argue that a large metric distortion may lead to spurious eigenvalues, a phenomenon which has been empirically observed, and note that metric distortion can be estimated from data. Numerical experiments complement the theoretical findings.
Uplink Joint Positioning and Synchronization in Cell-Free Deployments with Radio Stripes
Feb 07, 2023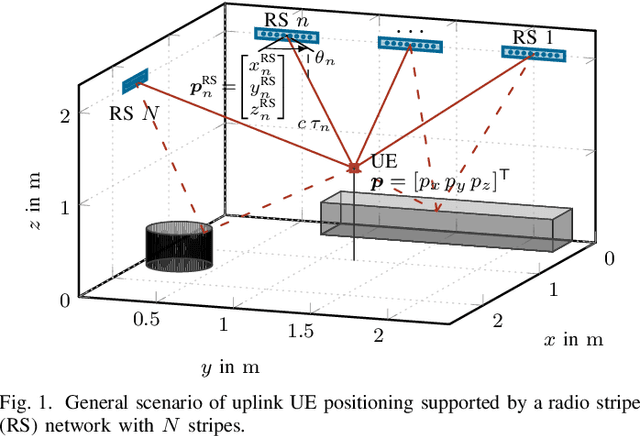
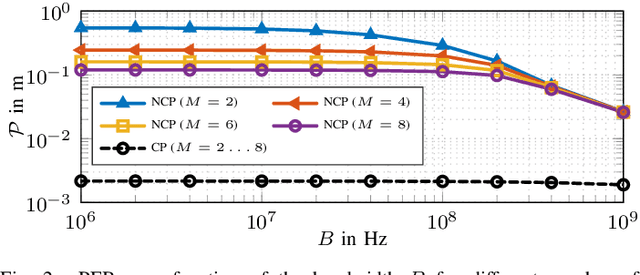
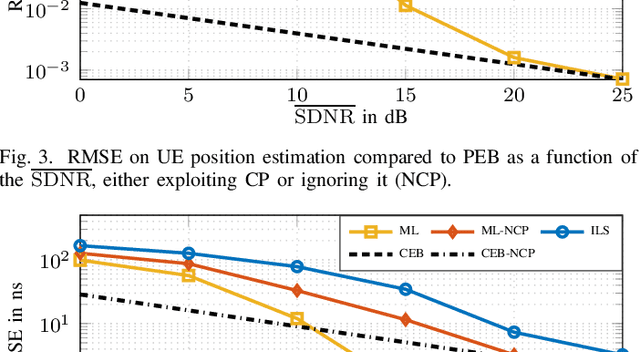
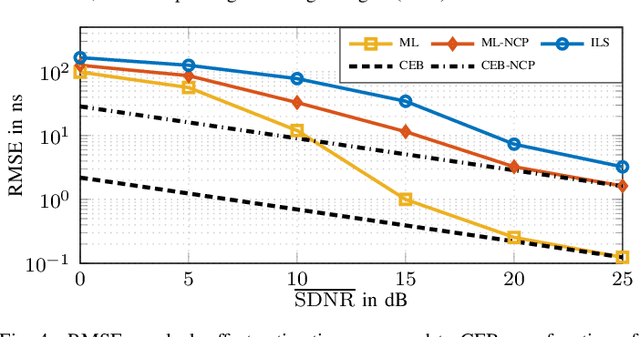
Radio stripes (RSs) is an emerging technology in beyond 5G and 6G wireless networks to support the deployment of cell-free architectures. In this paper, we investigate the potential use of RSs to enable joint positioning and synchronization in the uplink channel at sub-6 GHz bands. The considered scenario consists of a single-antenna user equipment (UE) that communicates with a network of multiple-antenna RSs distributed over a wide area. The UE is assumed to be unsynchronized to the RSs network, while individual RSs are time- and phase-synchronized. We formulate the problem of joint estimation of position, clock offset, and phase offset of the UE and derive the corresponding maximum-likelihood (ML) estimator, both with and without exploiting carrier phase information. To gain fundamental insights into the achievable performance, we also conduct a Fisher information analysis and inspect the theoretical lower bounds numerically. Simulation results demonstrate that promising positioning and synchronization performance can be obtained in cell-free architectures supported by RSs, revealing at the same time the benefits of carrier phase exploitation through phase-synchronized RSs.
Deep Convolutional Neural Network for Plume Rise Measurements in Industrial Environments
Feb 15, 2023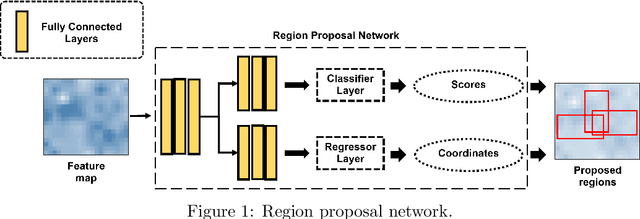
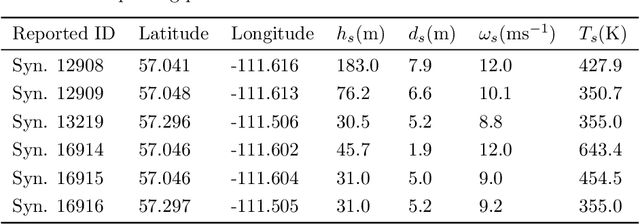
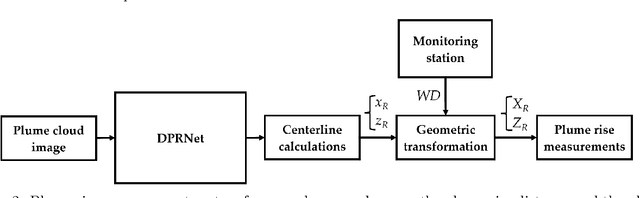
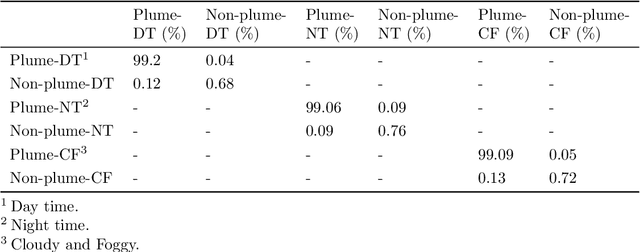
The estimation of plume cloud height is essential for air-quality transport models, local environmental assessment cases, and global climate models. When pollutants are released by a smokestack, plume rise is the constant height at which the plume cloud is carried downwind as its momentum dissipates and the temperatures of the plume cloud and the ambient equalize. Although different parameterizations and equations are used in most air quality models to predict plume rise, verification of these parameterizations has been limited in the past three decades. Beyond validation, there is also value in real-time measurement of plume rise to improve the accuracy of air quality forecasting. In this paper, we propose a low-cost measurement technology that can monitor smokestack plumes and make long-term, real-time measurements of plume rise, improving predictability. To do this, a two-stage method is developed based on deep convolutional neural networks. In the first stage, an improved Mask R-CNN is applied to detect the plume cloud borders and distinguish the plume from its background and other objects. This proposed model is called Deep Plume Rise Net (DPRNet). In the second stage, a geometric transformation phase is applied through the wind direction information from a nearby monitoring station to obtain real-life measurements of different parameters. Finally, the plume cloud boundaries are obtained to calculate the plume rise. Various images with different atmospheric conditions, including day, night, cloudy, and foggy, have been selected for DPRNet training algorithm. Obtained results show the proposed method outperforms widely-used networks in plume cloud border detection and recognition.
Self-Supervised Temporal Graph learning with Temporal and Structural Intensity Alignment
Feb 15, 2023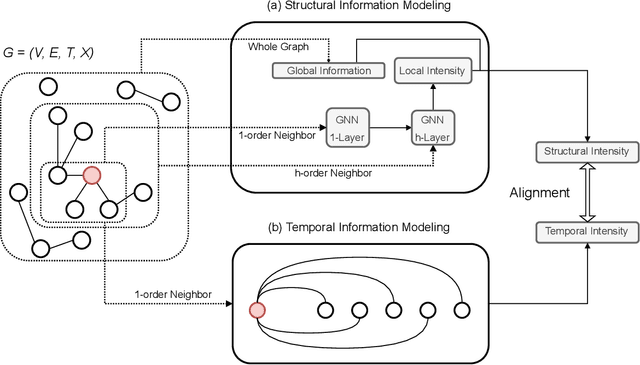
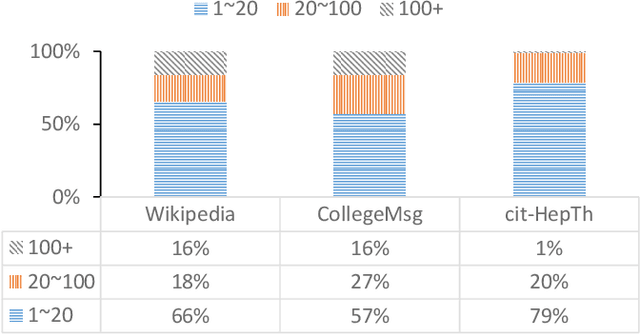
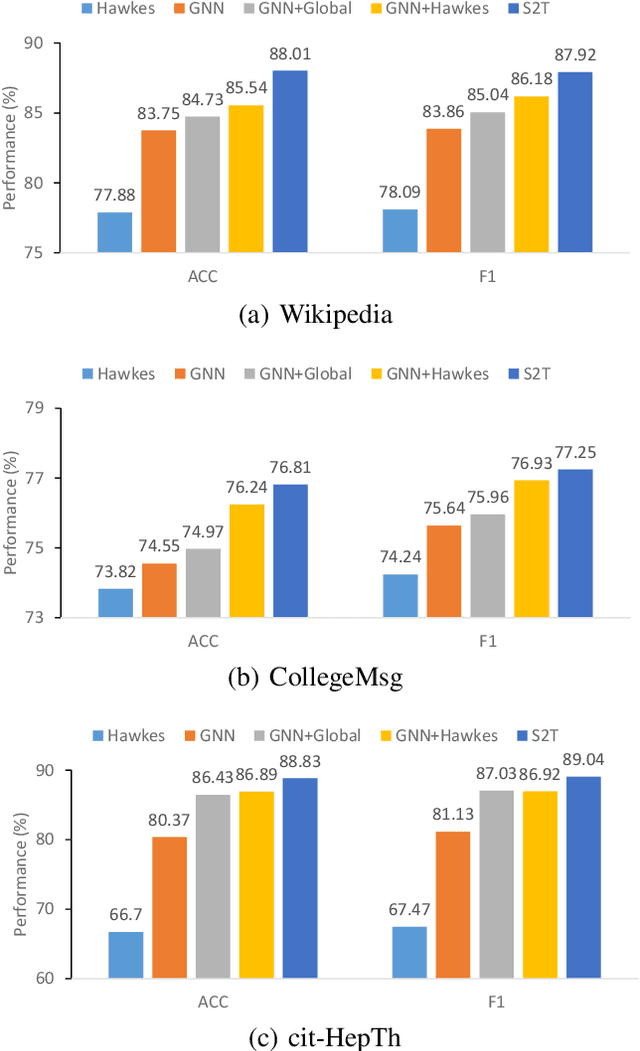
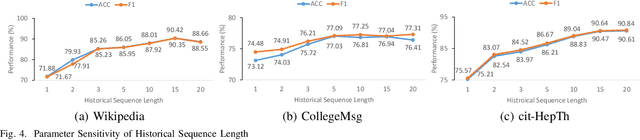
Temporal graph learning aims to generate high-quality representations for graph-based tasks along with dynamic information, which has recently drawn increasing attention. Unlike the static graph, a temporal graph is usually organized in the form of node interaction sequences over continuous time instead of an adjacency matrix. Most temporal graph learning methods model current interactions by combining historical information over time. However, such methods merely consider the first-order temporal information while ignoring the important high-order structural information, leading to sub-optimal performance. To solve this issue, by extracting both temporal and structural information to learn more informative node representations, we propose a self-supervised method termed S2T for temporal graph learning. Note that the first-order temporal information and the high-order structural information are combined in different ways by the initial node representations to calculate two conditional intensities, respectively. Then the alignment loss is introduced to optimize the node representations to be more informative by narrowing the gap between the two intensities. Concretely, besides modeling temporal information using historical neighbor sequences, we further consider the structural information from both local and global levels. At the local level, we generate structural intensity by aggregating features from the high-order neighbor sequences. At the global level, a global representation is generated based on all nodes to adjust the structural intensity according to the active statuses on different nodes. Extensive experiments demonstrate that the proposed method S2T achieves at most 10.13% performance improvement compared with the state-of-the-art competitors on several datasets.
Single Motion Diffusion
Feb 12, 2023
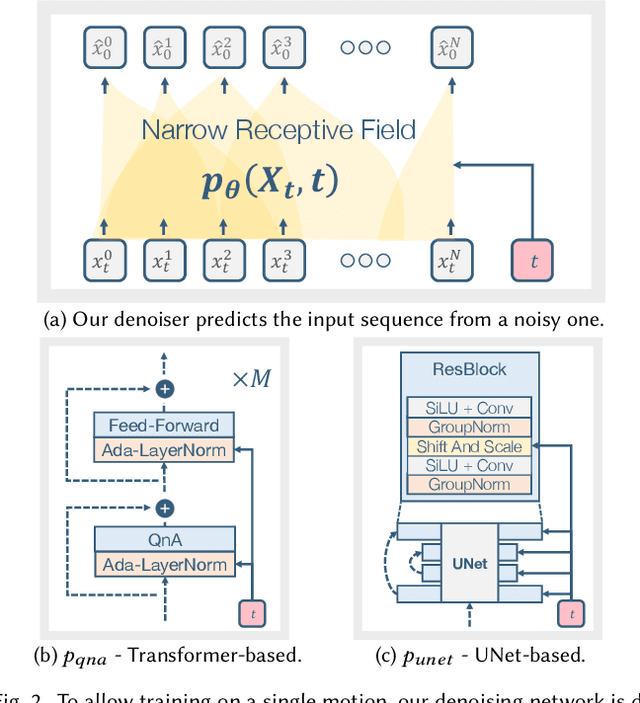
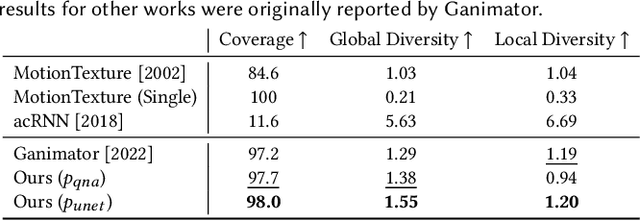
Synthesizing realistic animations of humans, animals, and even imaginary creatures, has long been a goal for artists and computer graphics professionals. Compared to the imaging domain, which is rich with large available datasets, the number of data instances for the motion domain is limited, particularly for the animation of animals and exotic creatures (e.g., dragons), which have unique skeletons and motion patterns. In this work, we present a Single Motion Diffusion Model, dubbed SinMDM, a model designed to learn the internal motifs of a single motion sequence with arbitrary topology and synthesize motions of arbitrary length that are faithful to them. We harness the power of diffusion models and present a denoising network designed specifically for the task of learning from a single input motion. Our transformer-based architecture avoids overfitting by using local attention layers that narrow the receptive field, and encourages motion diversity by using relative positional embedding. SinMDM can be applied in a variety of contexts, including spatial and temporal in-betweening, motion expansion, style transfer, and crowd animation. Our results show that SinMDM outperforms existing methods both in quality and time-space efficiency. Moreover, while current approaches require additional training for different applications, our work facilitates these applications at inference time. Our code and trained models are available at https://sinmdm.github.io/SinMDM-page.
Digital Twin Tracking Dataset (DTTD): A New RGB+Depth 3D Dataset for Longer-Range Object Tracking Applications
Feb 12, 2023


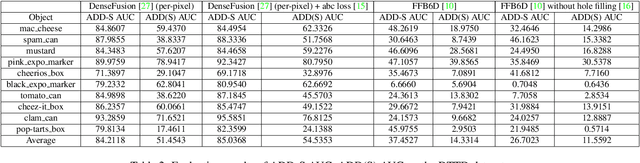
Digital twin is a problem of augmenting real objects with their digital counterparts. It can underpin a wide range of applications in augmented reality (AR), autonomy, and UI/UX. A critical component in a good digital twin system is real-time, accurate 3D object tracking. Most existing works solve 3D object tracking through the lens of robotic grasping, employ older generations of depth sensors, and measure performance metrics that may not apply to other digital twin applications such as in AR. In this work, we create a novel RGB-D dataset, called Digital-Twin Tracking Dataset (DTTD), to enable further research of the problem and extend potential solutions towards longer ranges and mm localization accuracy. To reduce point cloud noise from the input source, we select the latest Microsoft Azure Kinect as the state-of-the-art time-of-flight (ToF) camera. In total, 103 scenes of 10 common off-the-shelf objects with rich textures are recorded, with each frame annotated with a per-pixel semantic segmentation and ground-truth object poses provided by a commercial motion capturing system. Through experiments, we demonstrate that DTTD can help researchers develop future object tracking methods and analyze new challenges. We provide the dataset, data generation, annotation, and model evaluation pipeline as open source code at: https://github.com/augcog/DTTDv1.