 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TTT-UCDR: Test-time Training for Universal Cross-Domain Retrieval
Aug 19, 2022
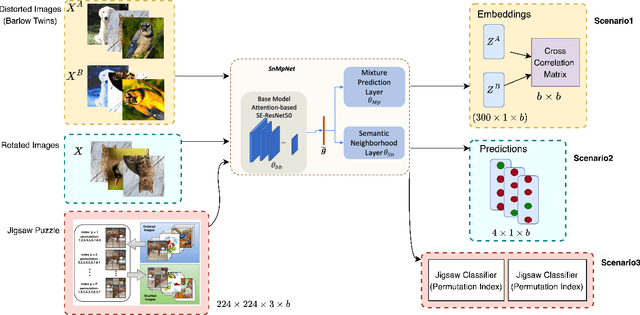
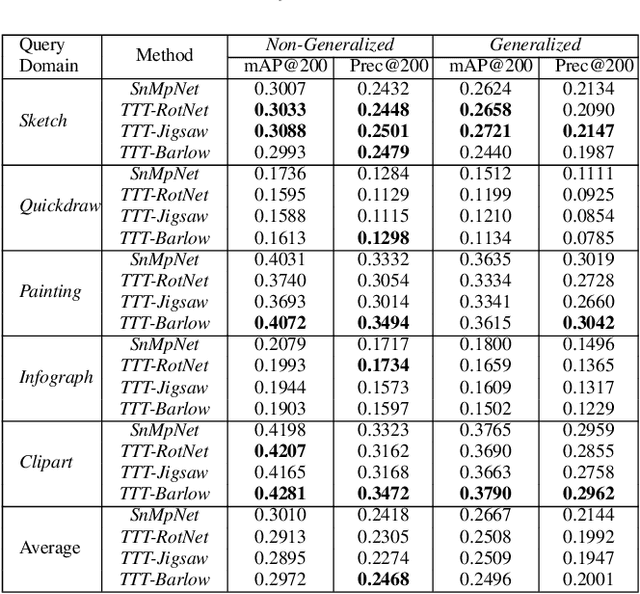
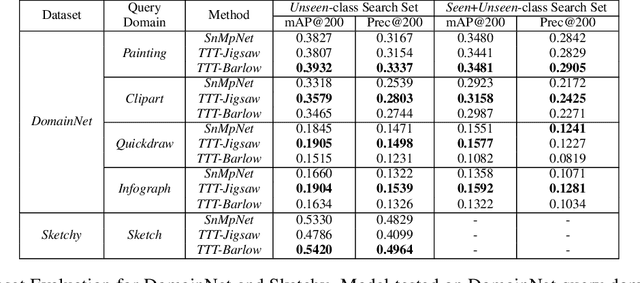
Image retrieval is a niche problem in computer vision curated towards finding similar images in a database using a query. In this work, for the first time in literature, we employ test-time training techniques for adapting to distribution shifts under Universal Cross-Domain Retrieval (UCDR). Test-time training has previously been shown to reduce generalization error for image classification, domain adaptation, semantic segmentation, and zero-shot sketch-based image retrieval (ZS-SBIR). In UCDR, in addition to the semantic shift of unknown categories present in ZS-SBIR, the presence of unknown domains leads to even higher distribution shifts. To bridge this domain gap, we use self-supervision through 3 different losses - Barlow Twins, Jigsaw Puzzle and RotNet on a pretrained network at test-time. This simple approach leads to improvements on UCDR benchmarks and also improves model robustness under a challenging cross-dataset generalization setting.
Abstracting Imperfect Information Away from Two-Player Zero-Sum Games
Jan 22, 2023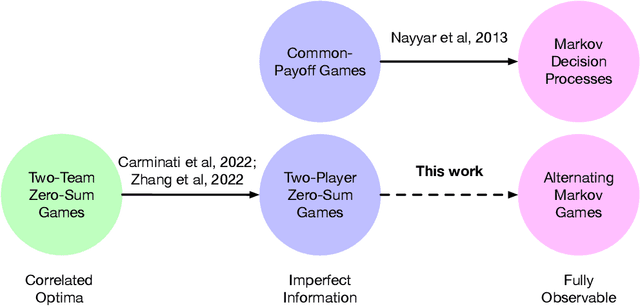
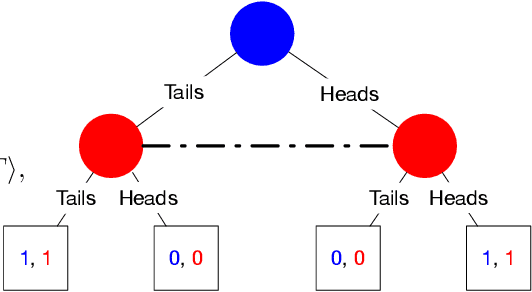
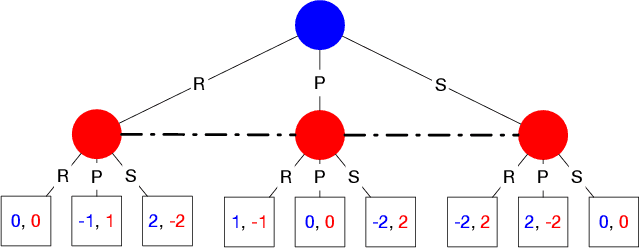
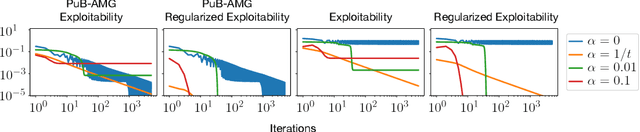
In their seminal work, Nayyar et al. (2013) showed that imperfect information can be abstracted away from common-payoff games by having players publicly announce their policies as they play. This insight underpins sound solvers and decision-time planning algorithms for common-payoff games. Unfortunately, a naive application of the same insight to two-player zero-sum games fails because Nash equilibria of the game with public policy announcements may not correspond to Nash equilibria of the original game. As a consequence, existing sound decision-time planning algorithms require complicated additional mechanisms that have unappealing properties. The main contribution of this work is showing that certain regularized equilibria do not possess the aforementioned non-correspondence problem -- thus, computing them can be treated as perfect information problems. Because these regularized equilibria can be made arbitrarily close to Nash equilibria, our result opens the door to a new perspective on solving two-player zero-sum games and, in particular, yields a simplified framework for decision-time planning in two-player zero-sum games, void of the unappealing properties that plague existing decision-time planning approaches.
Intra-operative Brain Tumor Detection with Deep Learning-Optimized Hyperspectral Imaging
Feb 06, 2023
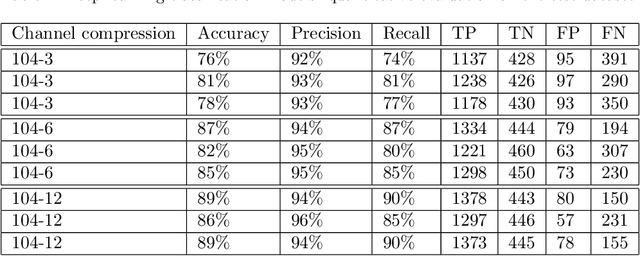
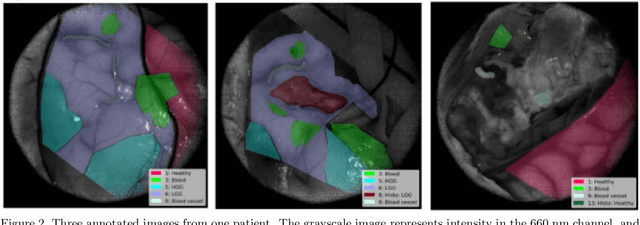
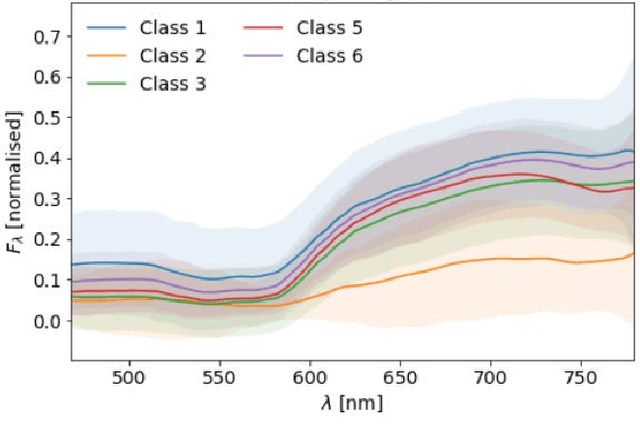
Surgery for gliomas (intrinsic brain tumors), especially when low-grade, is challenging due to the infiltrative nature of the lesion. Currently, no real-time, intra-operative, label-free and wide-field tool is available to assist and guide the surgeon to find the relevant demarcations for these tumors. While marker-based methods exist for the high-grade glioma case, there is no convenient solution available for the low-grade case; thus, marker-free optical techniques represent an attractive option. Although RGB imaging is a standard tool in surgical microscopes, it does not contain sufficient information for tissue differentiation. We leverage the richer information from hyperspectral imaging (HSI), acquired with a snapscan camera in the 468-787 nm range, coupled to a surgical microscope, to build a deep-learning-based diagnostic tool for cancer resection with potential for intra-operative guidance. However, the main limitation of the HSI snapscan camera is the image acquisition time, limiting its widespread deployment in the operation theater. Here, we investigate the effect of HSI channel reduction and pre-selection to scope the design space for the development of cheaper and faster sensors. Neural networks are used to identify the most important spectral channels for tumor tissue differentiation, optimizing the trade-off between the number of channels and precision to enable real-time intra-surgical application. We evaluate the performance of our method on a clinical dataset that was acquired during surgery on five patients. By demonstrating the possibility to efficiently detect low-grade glioma, these results can lead to better cancer resection demarcations, potentially improving treatment effectiveness and patient outcome.
Self-Supervised Contrastive Pre-Training For Time Series via Time-Frequency Consistency
Jun 17, 2022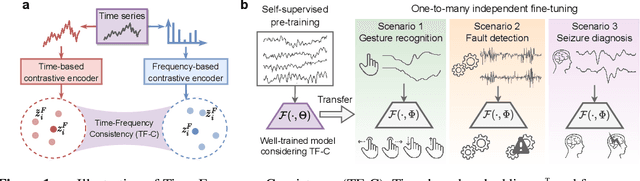
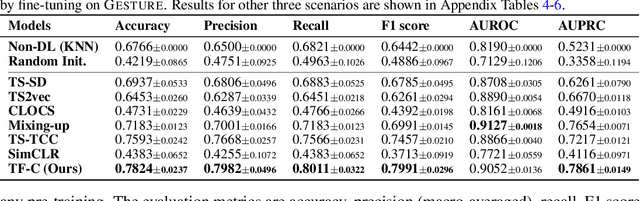
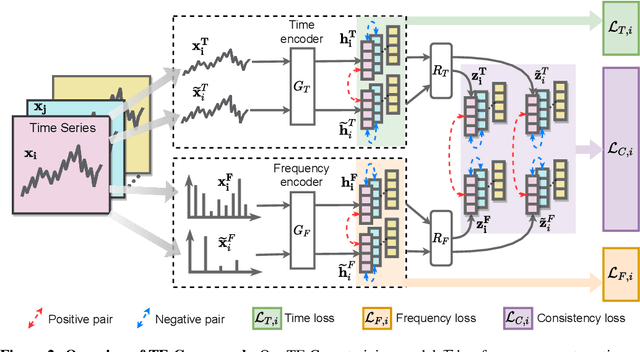
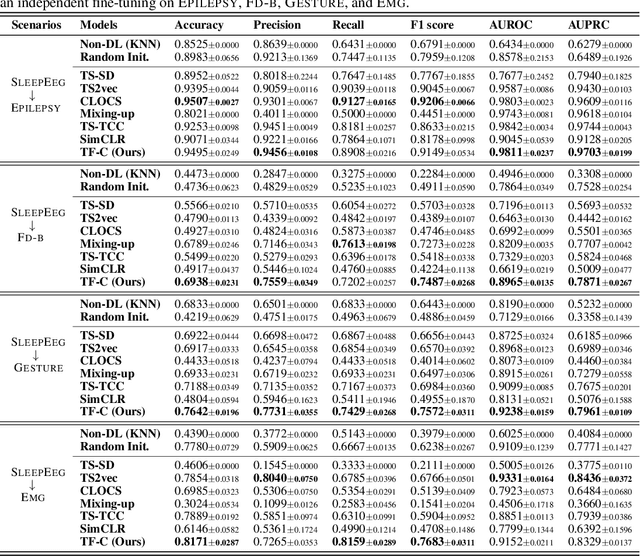
Pre-training on time series poses a unique challenge due to the potential mismatch between pre-training and target domains, such as shifts in temporal dynamics, fast-evolving trends, and long-range and short cyclic effects, which can lead to poor downstream performance. While domain adaptation methods can mitigate these shifts, most methods need examples directly from the target domain, making them suboptimal for pre-training. To address this challenge, methods need to accommodate target domains with different temporal dynamics and be capable of doing so without seeing any target examples during pre-training. Relative to other modalities, in time series, we expect that time-based and frequency-based representations of the same example are located close together in the time-frequency space. To this end, we posit that time-frequency consistency (TF-C) -- embedding a time-based neighborhood of a particular example close to its frequency-based neighborhood and back -- is desirable for pre-training. Motivated by TF-C, we define a decomposable pre-training model, where the self-supervised signal is provided by the distance between time and frequency components, each individually trained by contrastive estimation. We evaluate the new method on eight datasets, including electrodiagnostic testing, human activity recognition, mechanical fault detection, and physical status monitoring. Experiments against eight state-of-the-art methods show that TF-C outperforms baselines by 15.4% (F1 score) on average in one-to-one settings (e.g., fine-tuning an EEG-pretrained model on EMG data) and by up to 8.4% (F1 score) in challenging one-to-many settings, reflecting the breadth of scenarios that arise in real-world applications. The source code and datasets are available at https: //anonymous.4open.science/r/TFC-pretraining-6B07.
Grasping Core Rules of Time Series through Pure Models
Aug 15, 2022Time series underwent the transition from statistics to deep learning, as did many other machine learning fields. Although it appears that the accuracy has been increasing as the model is updated in a number of publicly available datasets, it typically only increases the scale by several times in exchange for a slight difference in accuracy. Through this experiment, we point out a different line of thinking, time series, especially long-term forecasting, may differ from other fields. It is not necessary to use extensive and complex models to grasp all aspects of time series, but to use pure models to grasp the core rules of time series changes. With this simple but effective idea, we created PureTS, a network with three pure linear layers that achieved state-of-the-art in 80% of the long sequence prediction tasks while being nearly the lightest model and having the fastest running speed. On this basis, we discuss the potential of pure linear layers in both phenomena and essence. The ability to understand the core law contributes to the high precision of long-distance prediction, and reasonable fluctuation prevents it from distorting the curve in multi-step prediction like mainstream deep learning models, which is summarized as a pure linear neural network that avoids over-fluctuating. Finally, we suggest the fundamental design standards for lightweight long-step time series tasks: input and output should try to have the same dimension, and the structure avoids fragmentation and complex operations.
2D-Empowered 3D Object Detection on the Edge
Feb 18, 2023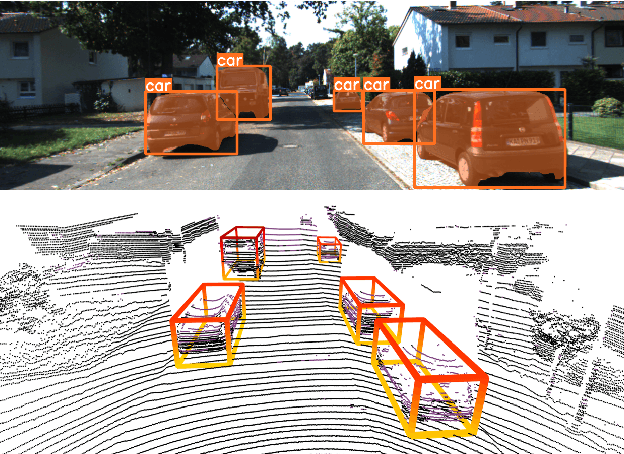
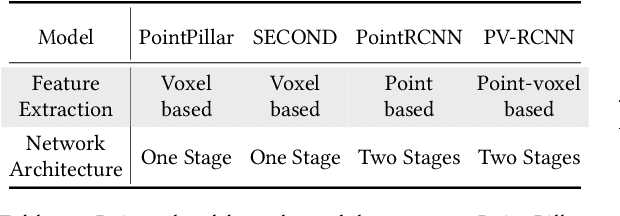
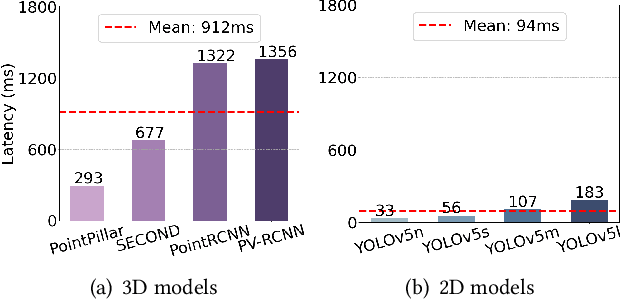
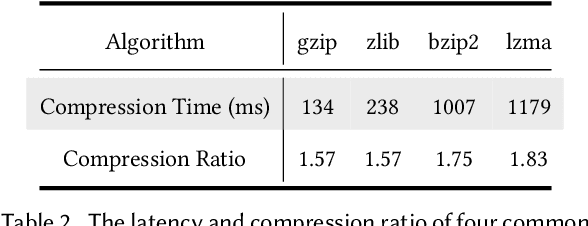
3D object detection has a pivotal role in a wide range of applications, most notably autonomous driving and robotics. These applications are commonly deployed on edge devices to promptly interact with the environment, and often require near real-time response. With limited computation power, it is challenging to execute 3D detection on the edge using highly complex neural networks. Common approaches such as offloading to the cloud brings latency overheads due to the large amount of 3D point cloud data during transmission. To resolve the tension between wimpy edge devices and compute-intensive inference workloads, we explore the possibility of transforming fast 2D detection results to extrapolate 3D bounding boxes. To this end, we present Moby, a novel system that demonstrates the feasibility and potential of our approach. Our main contributions are two-fold: First, we design a 2D-to-3D transformation pipeline that takes as input the point cloud data from LiDAR and 2D bounding boxes from camera that are captured at exactly the same time, and generate 3D bounding boxes efficiently and accurately based on detection results of the previous frames without running 3D detectors. Second, we design a frame offloading scheduler that dynamically launches a 3D detection when the error of 2D-to-3D transformation accumulates to a certain level, so the subsequent transformations can draw upon the latest 3D detection results with better accuracy. Extensive evaluation on NVIDIA Jetson TX2 with the autonomous driving dataset KITTI and real-world 4G/LTE traces shows that, Moby reduces the end-to-end latency by up to 91.9% with mild accuracy drop compared to baselines. Further, Moby shows excellent energy efficiency by saving power consumption and memory footprint up to 75.7% and 48.1%, respectively.
Time-Varying ALIP Model and Robust Foot-Placement Control for Underactuated Bipedal Robot Walking on a Swaying Rigid Surface
Oct 24, 2022
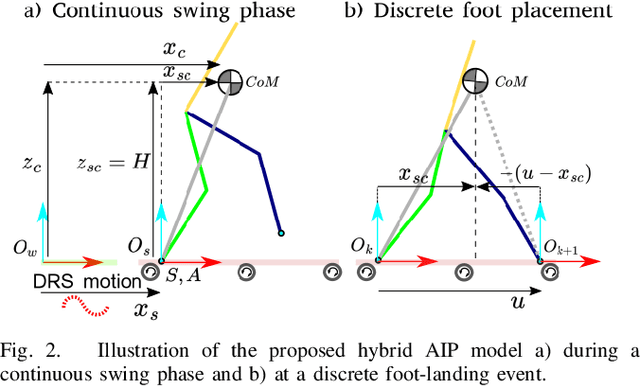
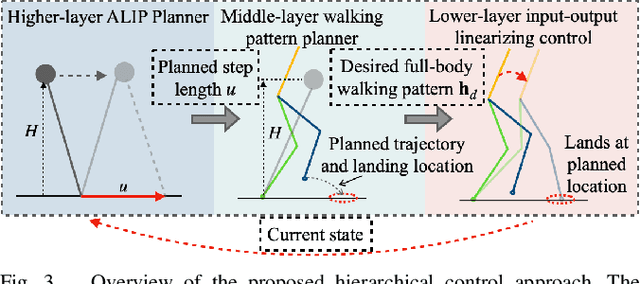
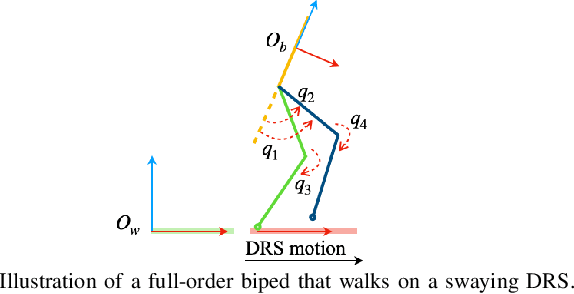
Controller design for bipedal walking on dynamic rigid surfaces (DRSes), which are rigid surfaces moving in the inertial frame (e.g., ships and airplanes), remains largely uninvestigated. This paper introduces a hierarchical control approach that achieves stable underactuated bipedal robot walking on a horizontally oscillating DRS. The highest layer of our approach is a real-time motion planner that generates desired global behaviors (i.e., the center of mass trajectories and footstep locations) by stabilizing a reduced-order robot model. One key novelty of this layer is the derivation of the reduced-order model by analytically extending the angular momentum based linear inverted pendulum (ALIP) model from stationary to horizontally moving surfaces. The other novelty is the development of a discrete-time foot-placement controller that exponentially stabilizes the hybrid, linear, time-varying ALIP model. The middle layer of the proposed approach is a walking pattern generator that translates the desired global behaviors into the robot's full-body reference trajectories for all directly actuated degrees of freedom. The lowest layer is an input-output linearizing controller that exponentially tracks those full-body reference trajectories based on the full-order, hybrid, nonlinear robot dynamics. Simulations of planar underactuated bipedal walking on a swaying DRS confirm that the proposed framework ensures the walking stability under different DRS motions and gait types.
A Constant-per-Iteration Likelihood Ratio Test for Online Changepoint Detection for Exponential Family Models
Feb 09, 2023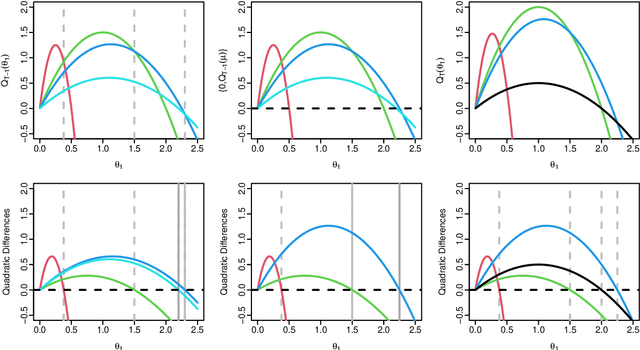
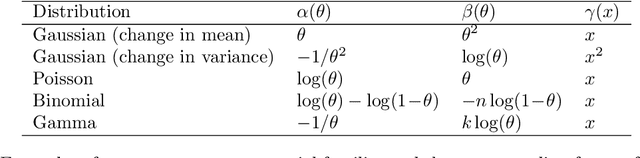
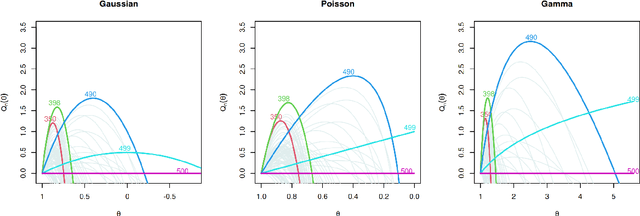
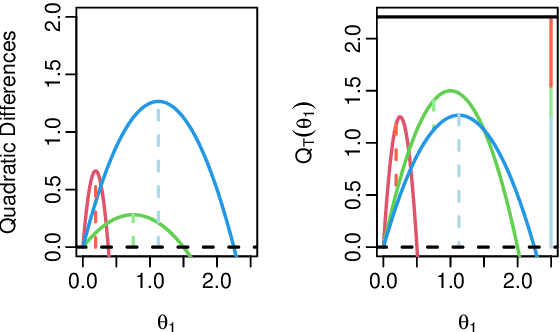
Online changepoint detection algorithms that are based on likelihood-ratio tests have been shown to have excellent statistical properties. However, a simple online implementation is computationally infeasible as, at time $T$, it involves considering $O(T)$ possible locations for the change. Recently, the FOCuS algorithm has been introduced for detecting changes in mean in Gaussian data that decreases the per-iteration cost to $O(\log T)$. This is possible by using pruning ideas, which reduce the set of changepoint locations that need to be considered at time $T$ to approximately $\log T$. We show that if one wishes to perform the likelihood ratio test for a different one-parameter exponential family model, then exactly the same pruning rule can be used, and again one need only consider approximately $\log T$ locations at iteration $T$. Furthermore, we show how we can adaptively perform the maximisation step of the algorithm so that we need only maximise the test statistic over a small subset of these possible locations. Empirical results show that the resulting online algorithm, which can detect changes under a wide range of models, has a constant-per-iteration cost on average.
Calibrating the Rigged Lottery: Making All Tickets Reliable
Mar 01, 2023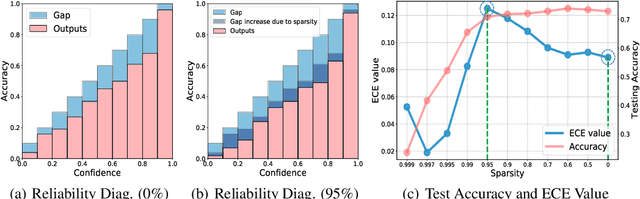
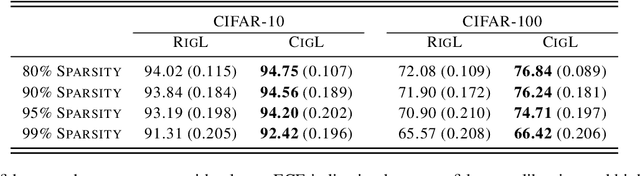
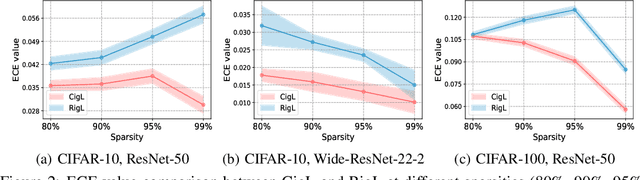
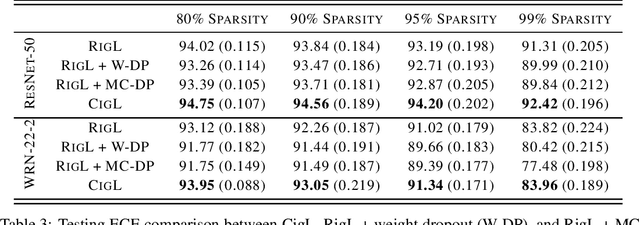
Although sparse training has been successfully used in various resource-limited deep learning tasks to save memory, accelerate training, and reduce inference time, the reliability of the produced sparse models remains unexplored. Previous research has shown that deep neural networks tend to be over-confident, and we find that sparse training exacerbates this problem. Therefore, calibrating the sparse models is crucial for reliable prediction and decision-making. In this paper, we propose a new sparse training method to produce sparse models with improved confidence calibration. In contrast to previous research that uses only one mask to control the sparse topology, our method utilizes two masks, including a deterministic mask and a random mask. The former efficiently searches and activates important weights by exploiting the magnitude of weights and gradients. While the latter brings better exploration and finds more appropriate weight values by random updates. Theoretically, we prove our method can be viewed as a hierarchical variational approximation of a probabilistic deep Gaussian process. Extensive experiments on multiple datasets, model architectures, and sparsities show that our method reduces ECE values by up to 47.8\% and simultaneously maintains or even improves accuracy with only a slight increase in computation and storage burden.
Lumos: Heterogeneity-aware Federated Graph Learning over Decentralized Devices
Mar 01, 2023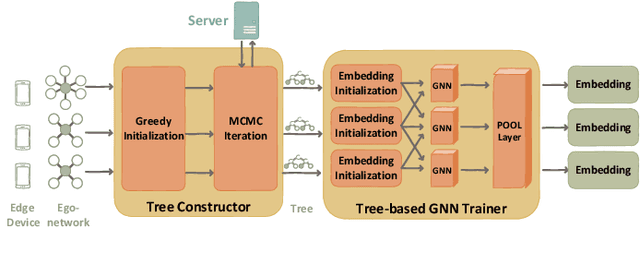
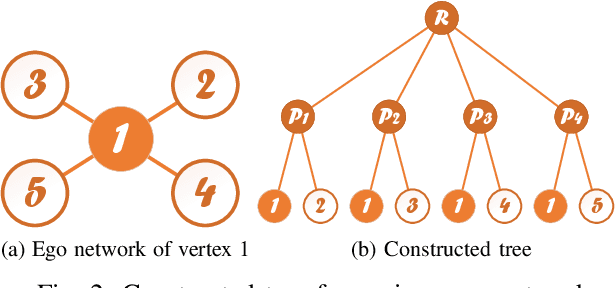
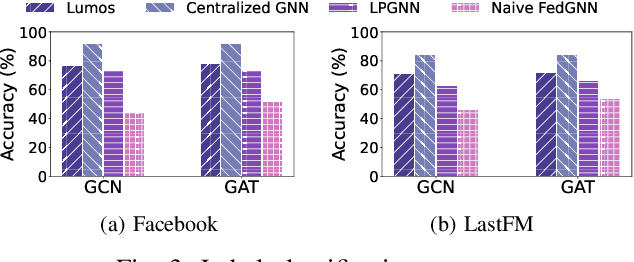
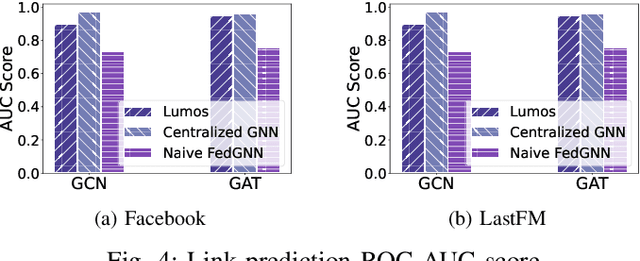
Graph neural networks (GNN) have been widely deployed in real-world networked applications and systems due to their capability to handle graph-structured data. However, the growing awareness of data privacy severely challenges the traditional centralized model training paradigm, where a server holds all the graph information. Federated learning is an emerging collaborative computing paradigm that allows model training without data centralization. Existing federated GNN studies mainly focus on systems where clients hold distinctive graphs or sub-graphs. The practical node-level federated situation, where each client is only aware of its direct neighbors, has yet to be studied. In this paper, we propose the first federated GNN framework called Lumos that supports supervised and unsupervised learning with feature and degree protection on node-level federated graphs. We first design a tree constructor to improve the representation capability given the limited structural information. We further present a Monte Carlo Markov Chain-based algorithm to mitigate the workload imbalance caused by degree heterogeneity with theoretically-guaranteed performance. Based on the constructed tree for each client, a decentralized tree-based GNN trainer is proposed to support versatile training. Extensive experiments demonstrate that Lumos outperforms the baseline with significantly higher accuracy and greatly reduced communication cost and training time.