 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Regularized Graph Structure Learning with Semantic Knowledge for Multi-variates Time-Series Forecasting
Oct 12, 2022
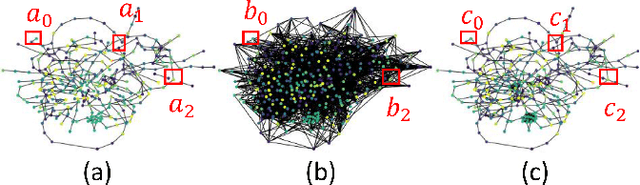
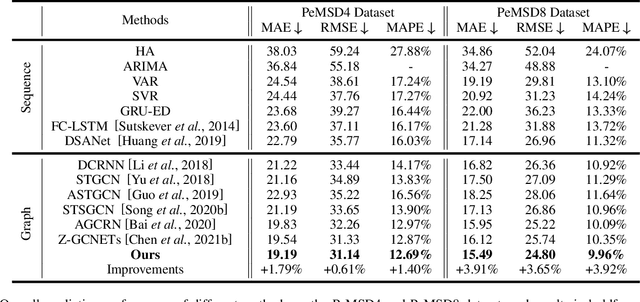
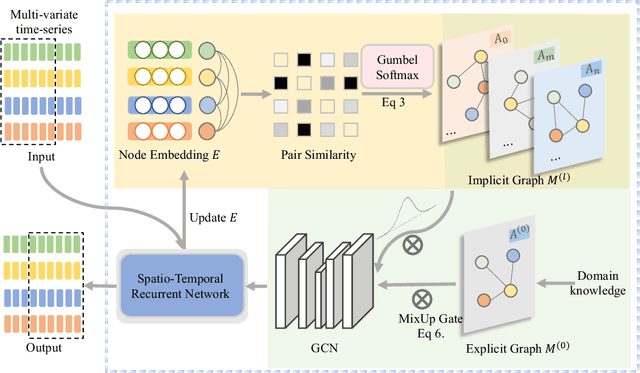
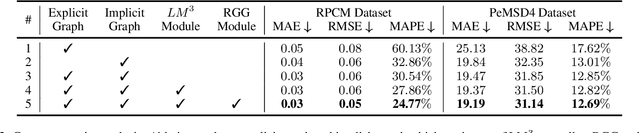
Multivariate time-series forecasting is a critical task for many applications, and graph time-series network is widely studied due to its capability to capture the spatial-temporal correlation simultaneously. However, most existing works focus more on learning with the explicit prior graph structure, while ignoring potential information from the implicit graph structure, yielding incomplete structure modeling. Some recent works attempt to learn the intrinsic or implicit graph structure directly while lacking a way to combine explicit prior structure with implicit structure together. In this paper, we propose Regularized Graph Structure Learning (RGSL) model to incorporate both explicit prior structure and implicit structure together, and learn the forecasting deep networks along with the graph structure. RGSL consists of two innovative modules. First, we derive an implicit dense similarity matrix through node embedding, and learn the sparse graph structure using the Regularized Graph Generation (RGG) based on the Gumbel Softmax trick. Second, we propose a Laplacian Matrix Mixed-up Module (LM3) to fuse the explicit graph and implicit graph together. We conduct experiments on three real-word datasets. Results show that the proposed RGSL model outperforms existing graph forecasting algorithms with a notable margin, while learning meaningful graph structure simultaneously. Our code and models are made publicly available at https://github.com/alipay/RGSL.git.
V-Cloak: Intelligibility-, Naturalness- & Timbre-Preserving Real-Time Voice Anonymization
Oct 27, 2022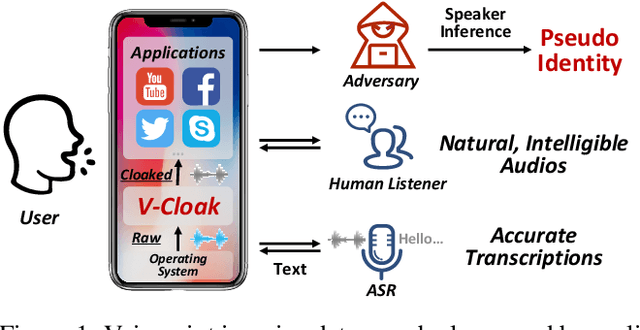

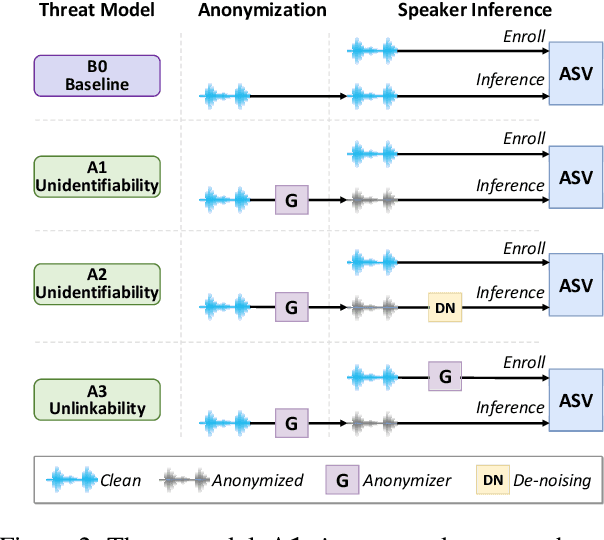
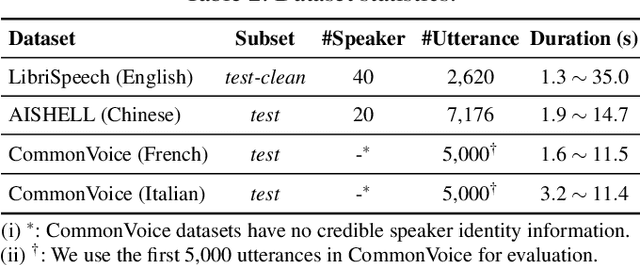
Voice data generated on instant messaging or social media applications contains unique user voiceprints that may be abused by malicious adversaries for identity inference or identity theft. Existing voice anonymization techniques, e.g., signal processing and voice conversion/synthesis, suffer from degradation of perceptual quality. In this paper, we develop a voice anonymization system, named V-Cloak, which attains real-time voice anonymization while preserving the intelligibility, naturalness and timbre of the audio. Our designed anonymizer features a one-shot generative model that modulates the features of the original audio at different frequency levels. We train the anonymizer with a carefully-designed loss function. Apart from the anonymity loss, we further incorporate the intelligibility loss and the psychoacoustics-based naturalness loss. The anonymizer can realize untargeted and targeted anonymization to achieve the anonymity goals of unidentifiability and unlinkability. We have conducted extensive experiments on four datasets, i.e., LibriSpeech (English), AISHELL (Chinese), CommonVoice (French) and CommonVoice (Italian), five Automatic Speaker Verification (ASV) systems (including two DNN-based, two statistical and one commercial ASV), and eleven Automatic Speech Recognition (ASR) systems (for different languages). Experiment results confirm that V-Cloak outperforms five baselines in terms of anonymity performance. We also demonstrate that V-Cloak trained only on the VoxCeleb1 dataset against ECAPA-TDNN ASV and DeepSpeech2 ASR has transferable anonymity against other ASVs and cross-language intelligibility for other ASRs. Furthermore, we verify the robustness of V-Cloak against various de-noising techniques and adaptive attacks. Hopefully, V-Cloak may provide a cloak for us in a prism world.
Square-root regret bounds for continuous-time episodic Markov decision processes
Oct 03, 2022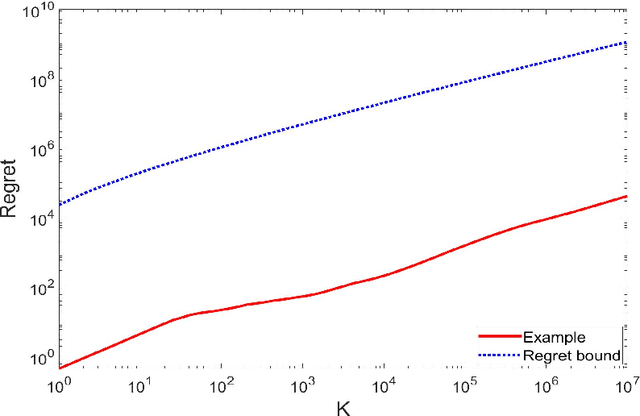
We study reinforcement learning for continuous-time Markov decision processes (MDPs) in the finite-horizon episodic setting. We present a learning algorithm based on the methods of value iteration and upper confidence bound. We derive an upper bound on the worst-case expected regret for the proposed algorithm, and establish a worst-case lower bound, both bounds are of the order of square-root on the number of episodes. Finally, we conduct simulation experiments to illustrate the performance of our algorithm.
Dynamic Time-Alignment of Dimensional Annotations of Emotion using Recurrent Neural Networks
Sep 21, 2022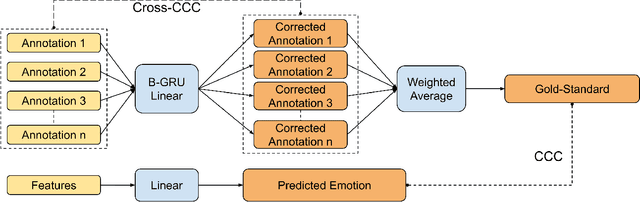


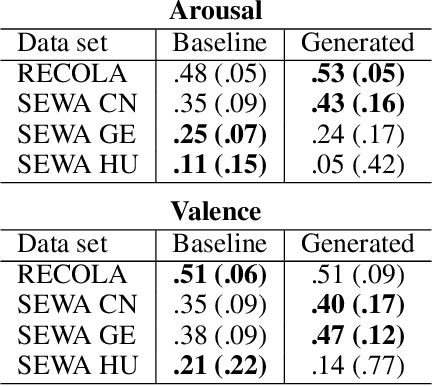
Most automatic emotion recognition systems exploit time-continuous annotations of emotion to provide fine-grained descriptions of spontaneous expressions as observed in real-life interactions. As emotion is rather subjective, its annotation is usually performed by several annotators who provide a trace for a given dimension, i.e. a time-continuous series describing a dimension such as arousal or valence. However, annotations of the same expression are rarely consistent between annotators, either in time or in value, which adds bias and delay in the trace that is used to learn predictive models of emotion. We therefore propose a method that can dynamically compensate inconsistencies across annotations and synchronise the traces with the corresponding acoustic features using Recurrent Neural Networks. Experimental evaluations were carried on several emotion data sets that include Chinese, French, German, and Hungarian participants who interacted remotely in either noise-free conditions or in-the-wild. The results show that our method can significantly increase inter-annotator agreement, as well as correlation between traces and audio features, for both arousal and valence. In addition, improvements are obtained in the automatic prediction of these dimensions using simple light-weight models, especially for valence in noise-free conditions, and arousal for recordings captured in-the-wild.
Intra-operative Brain Tumor Detection with Deep Learning-Optimized Hyperspectral Imaging
Feb 06, 2023
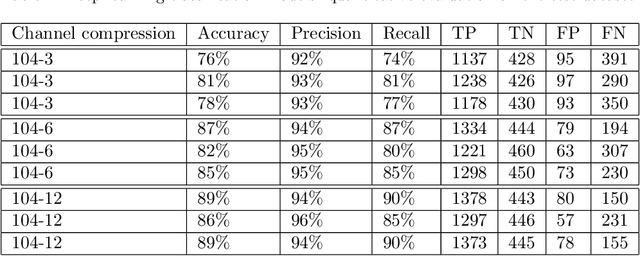
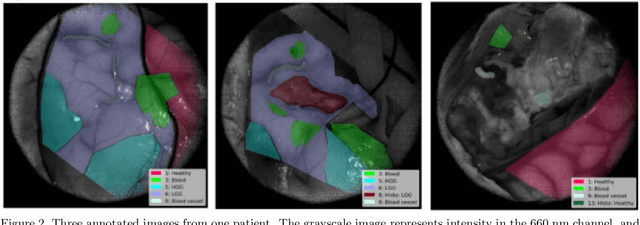
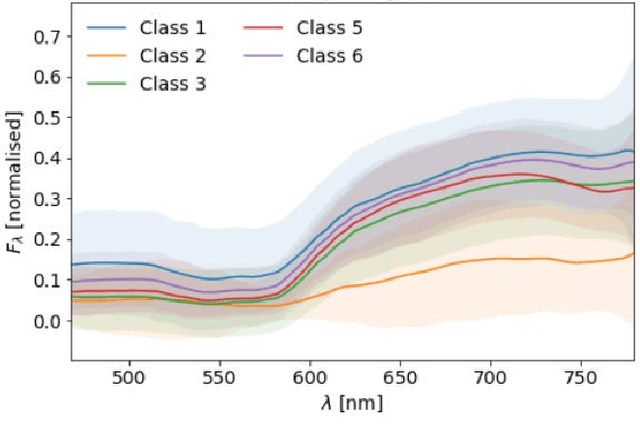
Surgery for gliomas (intrinsic brain tumors), especially when low-grade, is challenging due to the infiltrative nature of the lesion. Currently, no real-time, intra-operative, label-free and wide-field tool is available to assist and guide the surgeon to find the relevant demarcations for these tumors. While marker-based methods exist for the high-grade glioma case, there is no convenient solution available for the low-grade case; thus, marker-free optical techniques represent an attractive option. Although RGB imaging is a standard tool in surgical microscopes, it does not contain sufficient information for tissue differentiation. We leverage the richer information from hyperspectral imaging (HSI), acquired with a snapscan camera in the 468-787 nm range, coupled to a surgical microscope, to build a deep-learning-based diagnostic tool for cancer resection with potential for intra-operative guidance. However, the main limitation of the HSI snapscan camera is the image acquisition time, limiting its widespread deployment in the operation theater. Here, we investigate the effect of HSI channel reduction and pre-selection to scope the design space for the development of cheaper and faster sensors. Neural networks are used to identify the most important spectral channels for tumor tissue differentiation, optimizing the trade-off between the number of channels and precision to enable real-time intra-surgical application. We evaluate the performance of our method on a clinical dataset that was acquired during surgery on five patients. By demonstrating the possibility to efficiently detect low-grade glioma, these results can lead to better cancer resection demarcations, potentially improving treatment effectiveness and patient outcome.
Revisiting Weighted Strategy for Non-stationary Parametric Bandits
Mar 05, 2023
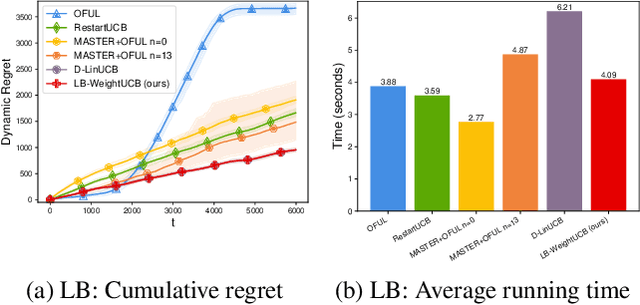
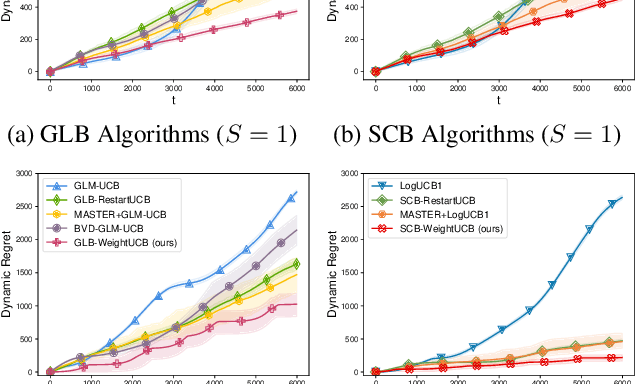
Non-stationary parametric bandits have attracted much attention recently. There are three principled ways to deal with non-stationarity, including sliding-window, weighted, and restart strategies. As many non-stationary environments exhibit gradual drifting patterns, the weighted strategy is commonly adopted in real-world applications. However, previous theoretical studies show that its analysis is more involved and the algorithms are either computationally less efficient or statistically suboptimal. This paper revisits the weighted strategy for non-stationary parametric bandits. In linear bandits (LB), we discover that this undesirable feature is due to an inadequate regret analysis, which results in an overly complex algorithm design. We propose a refined analysis framework, which simplifies the derivation and importantly produces a simpler weight-based algorithm that is as efficient as window/restart-based algorithms while retaining the same regret as previous studies. Furthermore, our new framework can be used to improve regret bounds of other parametric bandits, including Generalized Linear Bandits (GLB) and Self-Concordant Bandits (SCB). For example, we develop a simple weighted GLB algorithm with an $\widetilde{O}(k_\mu^{\frac{5}{4}} c_\mu^{-\frac{3}{4}} d^{\frac{3}{4}} P_T^{\frac{1}{4}}T^{\frac{3}{4}})$ regret, improving the $\widetilde{O}(k_\mu^{2} c_\mu^{-1}d^{\frac{9}{10}} P_T^{\frac{1}{5}}T^{\frac{4}{5}})$ bound in prior work, where $k_\mu$ and $c_\mu$ characterize the reward model's nonlinearity, $P_T$ measures the non-stationarity, $d$ and $T$ denote the dimension and time horizon.
Understanding Bugs in Multi-Language Deep Learning Frameworks
Mar 05, 2023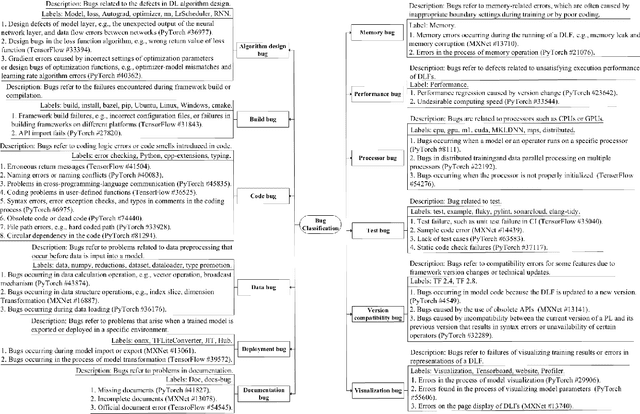
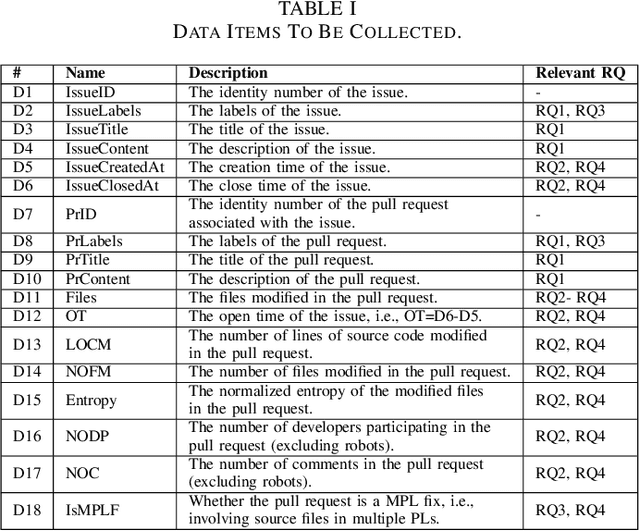
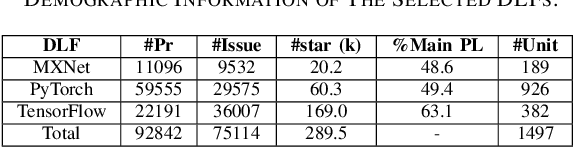
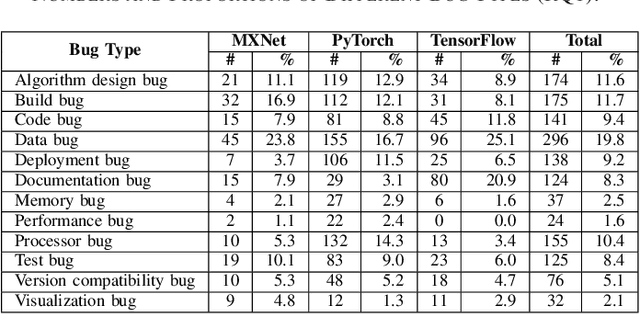
Deep learning frameworks (DLFs) have been playing an increasingly important role in this intelligence age since they act as a basic infrastructure for an increasingly wide range of AIbased applications. Meanwhile, as multi-programming-language (MPL) software systems, DLFs are inevitably suffering from bugs caused by the use of multiple programming languages (PLs). Hence, it is of paramount significance to understand the bugs (especially the bugs involving multiple PLs, i.e., MPL bugs) of DLFs, which can provide a foundation for preventing, detecting, and resolving bugs in the development of DLFs. To this end, we manually analyzed 1497 bugs in three MPL DLFs, namely MXNet, PyTorch, and TensorFlow. First, we classified bugs in these DLFs into 12 types (e.g., algorithm design bugs and memory bugs) according to their bug labels and characteristics. Second, we further explored the impacts of different bug types on the development of DLFs, and found that deployment bugs and memory bugs negatively impact the development of DLFs in different aspects the most. Third, we found that 28.6%, 31.4%, and 16.0% of bugs in MXNet, PyTorch, and TensorFlow are MPL bugs, respectively; the PL combination of Python and C/C++ is most used in fixing more than 92% MPL bugs in all DLFs. Finally, the code change complexity of MPL bug fixes is significantly greater than that of single-programming-language (SPL) bug fixes in all the three DLFs, while in PyTorch MPL bug fixes have longer open time and greater communication complexity than SPL bug fixes. These results provide insights for bug management in DLFs.
Frequency-domain Blind Quality Assessment of Blurred and Blocking-artefact Images using Gaussian Process Regression model
Mar 05, 2023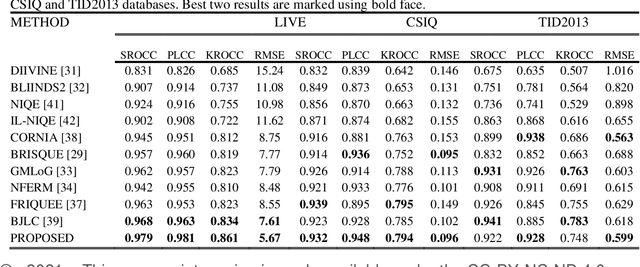
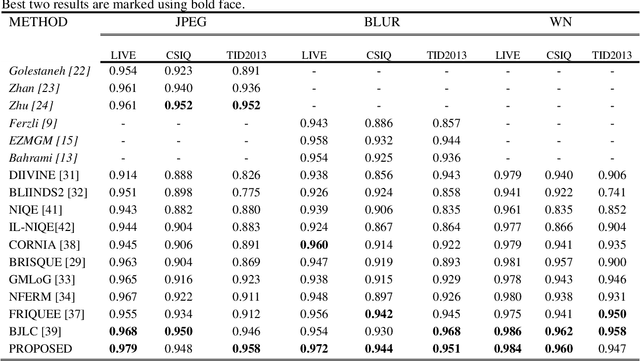

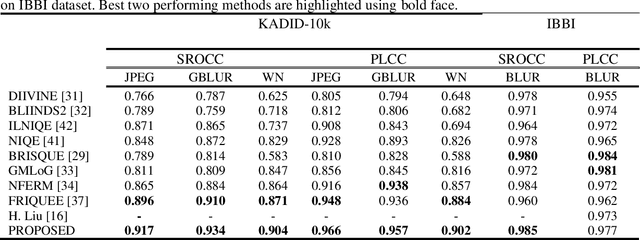
Most of the standard image and video codecs are block-based and depending upon the compression ratio the compressed images/videos suffer from different distortions. At low ratios, blurriness is observed and as compression increases blocking artifacts occur. Generally, in order to reduce blockiness, images are low-pass filtered which leads to more blurriness. Also, in bokeh mode images they are commonly seen: blurriness as a result of intentional blurred background while blocking artifact and global blurriness arising due to compression. Therefore, such visual media suffer from both blockiness and blurriness distortions. Along with this, noise is also commonly encountered distortion. Most of the existing works on quality assessment quantify these distortions individually. This paper proposes a methodology to blindly measure overall quality of an image suffering from these distortions, individually as well as jointly. This is achieved by considering the sum of absolute values of low and high-frequency Discrete Frequency Transform (DFT) coefficients defined as sum magnitudes. The number of blocks lying in specific ranges of sum magnitudes including zero-valued AC coefficients and mean of 100 maximum and 100 minimum values of these sum magnitudes are used as feature vectors. These features are then fed to the Machine Learning (ML) based Gaussian Process Regression (GPR) model, which quantifies the image quality. The simulation results show that the proposed method can estimate the quality of images distorted with the blockiness, blurriness, noise and their combinations. It is relatively fast compared to many state-of-art methods, and therefore is suitable for real-time quality monitoring applications.
A Constant-per-Iteration Likelihood Ratio Test for Online Changepoint Detection for Exponential Family Models
Feb 09, 2023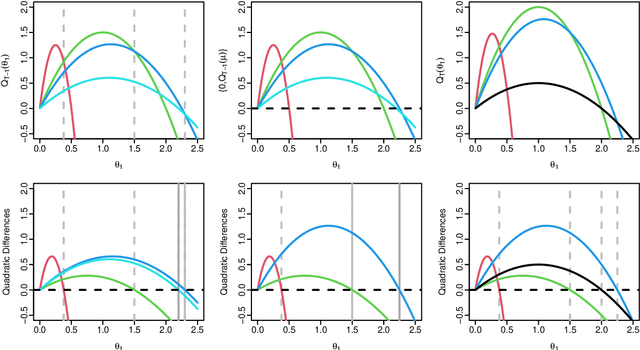
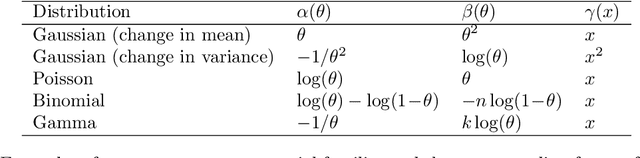
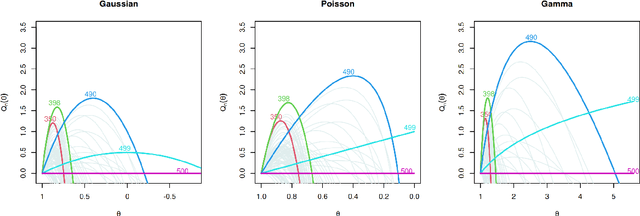
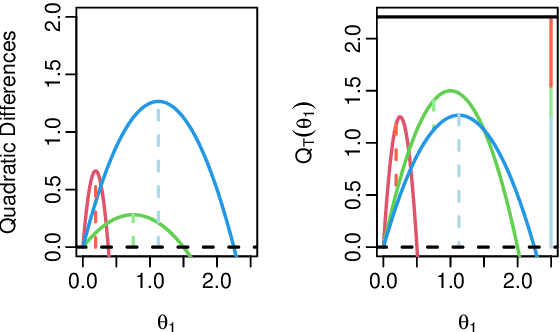
Online changepoint detection algorithms that are based on likelihood-ratio tests have been shown to have excellent statistical properties. However, a simple online implementation is computationally infeasible as, at time $T$, it involves considering $O(T)$ possible locations for the change. Recently, the FOCuS algorithm has been introduced for detecting changes in mean in Gaussian data that decreases the per-iteration cost to $O(\log T)$. This is possible by using pruning ideas, which reduce the set of changepoint locations that need to be considered at time $T$ to approximately $\log T$. We show that if one wishes to perform the likelihood ratio test for a different one-parameter exponential family model, then exactly the same pruning rule can be used, and again one need only consider approximately $\log T$ locations at iteration $T$. Furthermore, we show how we can adaptively perform the maximisation step of the algorithm so that we need only maximise the test statistic over a small subset of these possible locations. Empirical results show that the resulting online algorithm, which can detect changes under a wide range of models, has a constant-per-iteration cost on average.
Time-rEversed diffusioN tEnsor Transformer: A new TENET of Few-Shot Object Detection
Oct 30, 2022In this paper, we tackle the challenging problem of Few-shot Object Detection. Existing FSOD pipelines (i) use average-pooled representations that result in information loss; and/or (ii) discard position information that can help detect object instances. Consequently, such pipelines are sensitive to large intra-class appearance and geometric variations between support and query images. To address these drawbacks, we propose a Time-rEversed diffusioN tEnsor Transformer (TENET), which i) forms high-order tensor representations that capture multi-way feature occurrences that are highly discriminative, and ii) uses a transformer that dynamically extracts correlations between the query image and the entire support set, instead of a single average-pooled support embedding. We also propose a Transformer Relation Head (TRH), equipped with higher-order representations, which encodes correlations between query regions and the entire support set, while being sensitive to the positional variability of object instances. Our model achieves state-of-the-art results on PASCAL VOC, FSOD, and COCO.