 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhanced Sampling of Configuration and Path Space in a Generalized Ensemble by Shooting Point Exchange
Feb 17, 2023

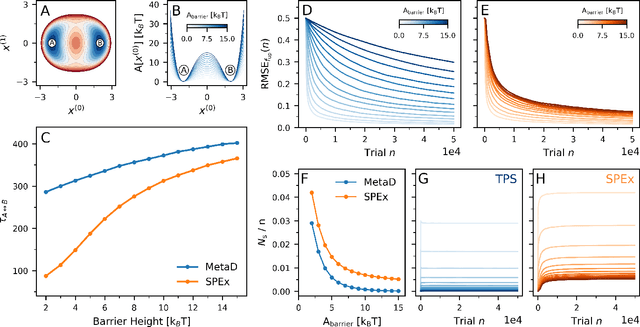
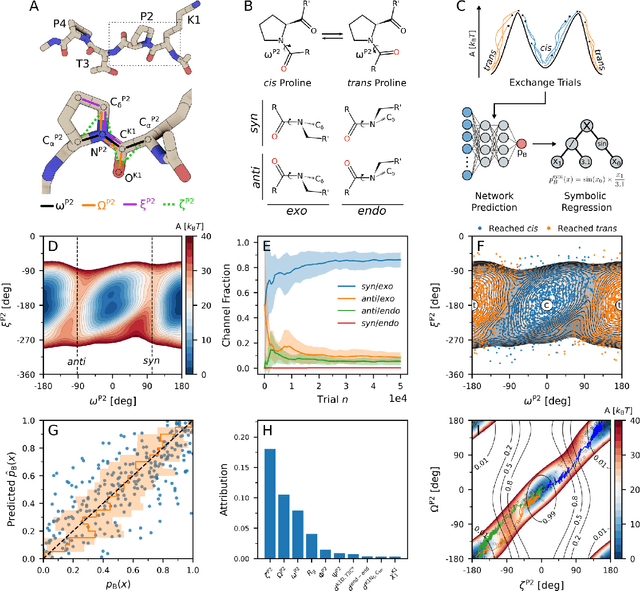
The computer simulation of many molecular processes is complicated by long time scales caused by rare transitions between long-lived states. Here, we propose a new approach to simulate such rare events, which combines transition path sampling with enhanced exploration of configuration space. The method relies on exchange moves between configuration and trajectory space, carried out based on a generalized ensemble. This scheme substantially enhances the efficiency of the transition path sampling simulations, particularly for systems with multiple transition channels, and yields information on thermodynamics, kinetics and reaction coordinates of molecular processes without distorting their dynamics. The method is illustrated using the isomerization of proline in the KPTP tetrapeptide.
Multi-Modal Interaction Control of Ultrasound Scanning Robots with Safe Human Guidance and Contact Recovery
Feb 11, 2023
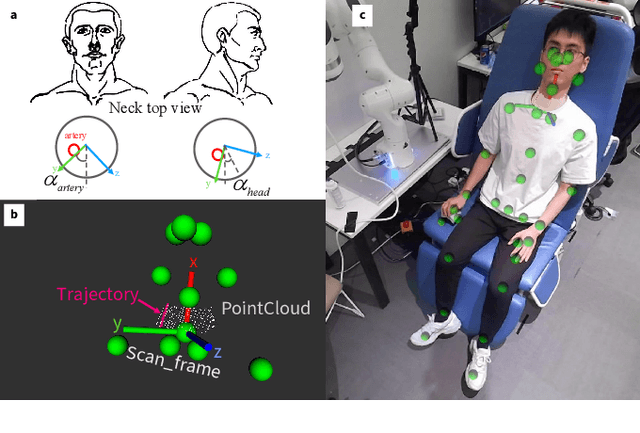
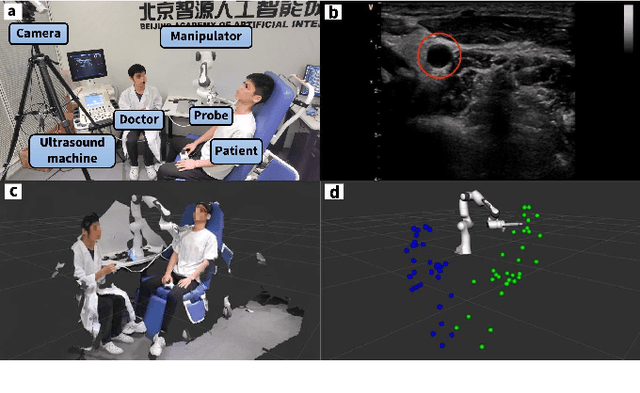
Ultrasound scanning robots enable the automatic imaging of a patient's internal organs by maintaining close contact between the ultrasound probe and the patient's body during a scanning procedure. Comprehensive, high-quality ultrasound scans are essential for providing the patient with an accurate diagnosis and effective treatment plan. An ultrasound scanning robot usually works in a doctor-robot co-existing environment, hence both efficiency and safety during the collaboration should be considered. In this paper, we propose a novel multi-modal control scheme for ultrasound scanning robots, in which three interaction modes are integrated into a single control input. Specifically, the scanning mode drives the robot to track a time-varying trajectory on the patient's body under the desired impedance model; the recovery mode allows the robot to actively recontact the body whenever physical contact between the ultrasound probe and the patient's body is lost; the human-guided mode renders the robot passive such that the doctor can safely intervene to manually reposition the probe. The integration of multiple modes allows the doctor to intervene safely at any time during the task and also maximizes the robot's autonomous scanning ability. The performance of the robot is validated on a collaborative scanning task of a carotid artery examination.
Link prediction with continuous-time classical and quantum walks
Aug 23, 2022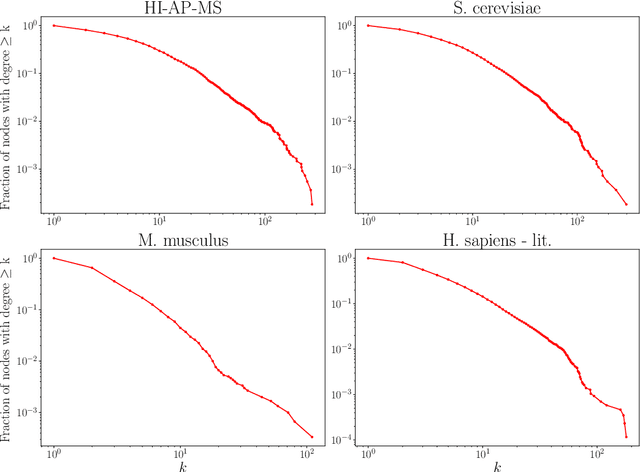
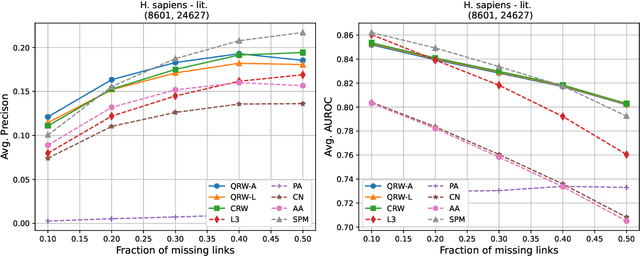
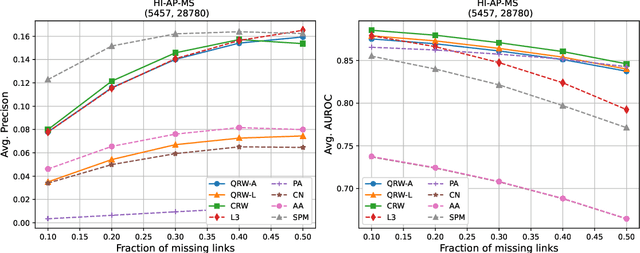
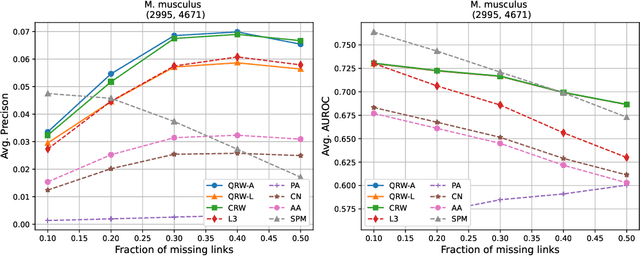
Protein-protein interaction (PPI) networks consist of the physical and/or functional interactions between the proteins of an organism. Since the biophysical and high-throughput methods used to form PPI networks are expensive, time-consuming, and often contain inaccuracies, the resulting networks are usually incomplete. In order to infer missing interactions in these networks, we propose a novel class of link prediction methods based on continuous-time classical and quantum random walks. In the case of quantum walks, we examine the usage of both the network adjacency and Laplacian matrices for controlling the walk dynamics. We define a score function based on the corresponding transition probabilities and perform tests on four real-world PPI datasets. Our results show that continuous-time classical random walks and quantum walks using the network adjacency matrix can successfully predict missing protein-protein interactions, with performance rivalling the state of the art.
Calibrating the Rigged Lottery: Making All Tickets Reliable
Mar 01, 2023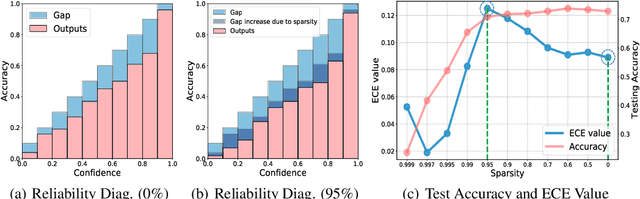
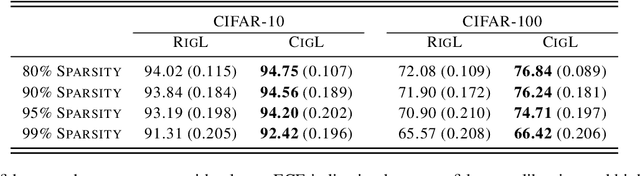
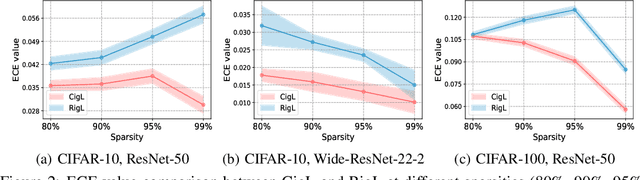
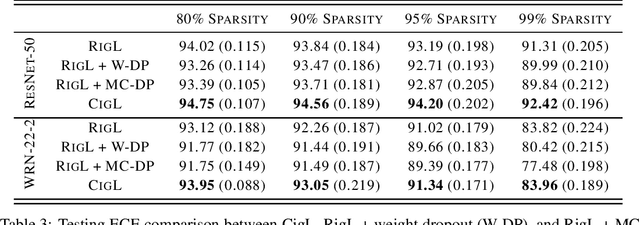
Although sparse training has been successfully used in various resource-limited deep learning tasks to save memory, accelerate training, and reduce inference time, the reliability of the produced sparse models remains unexplored. Previous research has shown that deep neural networks tend to be over-confident, and we find that sparse training exacerbates this problem. Therefore, calibrating the sparse models is crucial for reliable prediction and decision-making. In this paper, we propose a new sparse training method to produce sparse models with improved confidence calibration. In contrast to previous research that uses only one mask to control the sparse topology, our method utilizes two masks, including a deterministic mask and a random mask. The former efficiently searches and activates important weights by exploiting the magnitude of weights and gradients. While the latter brings better exploration and finds more appropriate weight values by random updates. Theoretically, we prove our method can be viewed as a hierarchical variational approximation of a probabilistic deep Gaussian process. Extensive experiments on multiple datasets, model architectures, and sparsities show that our method reduces ECE values by up to 47.8\% and simultaneously maintains or even improves accuracy with only a slight increase in computation and storage burden.
Lumos: Heterogeneity-aware Federated Graph Learning over Decentralized Devices
Mar 01, 2023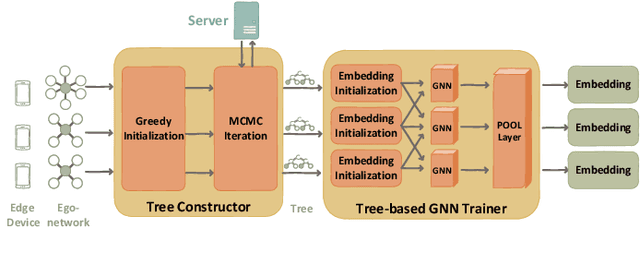
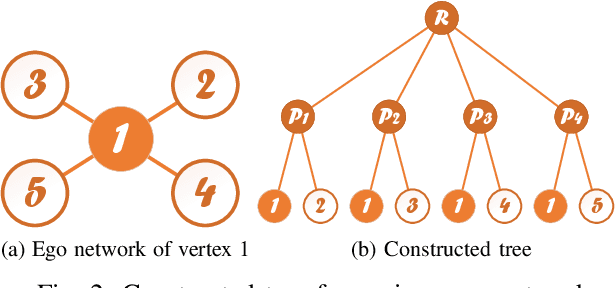
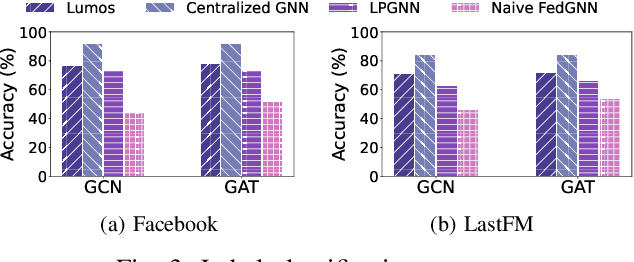
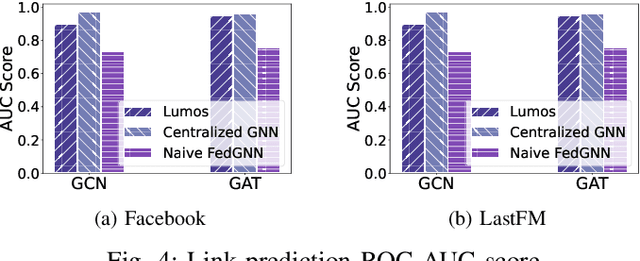
Graph neural networks (GNN) have been widely deployed in real-world networked applications and systems due to their capability to handle graph-structured data. However, the growing awareness of data privacy severely challenges the traditional centralized model training paradigm, where a server holds all the graph information. Federated learning is an emerging collaborative computing paradigm that allows model training without data centralization. Existing federated GNN studies mainly focus on systems where clients hold distinctive graphs or sub-graphs. The practical node-level federated situation, where each client is only aware of its direct neighbors, has yet to be studied. In this paper, we propose the first federated GNN framework called Lumos that supports supervised and unsupervised learning with feature and degree protection on node-level federated graphs. We first design a tree constructor to improve the representation capability given the limited structural information. We further present a Monte Carlo Markov Chain-based algorithm to mitigate the workload imbalance caused by degree heterogeneity with theoretically-guaranteed performance. Based on the constructed tree for each client, a decentralized tree-based GNN trainer is proposed to support versatile training. Extensive experiments demonstrate that Lumos outperforms the baseline with significantly higher accuracy and greatly reduced communication cost and training time.
Speeding Up EfficientNet: Selecting Update Blocks of Convolutional Neural Networks using Genetic Algorithm in Transfer Learning
Mar 01, 2023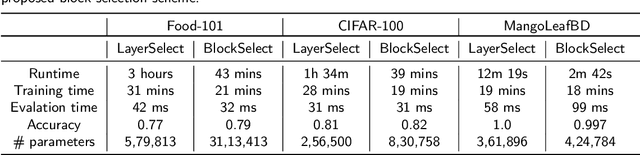
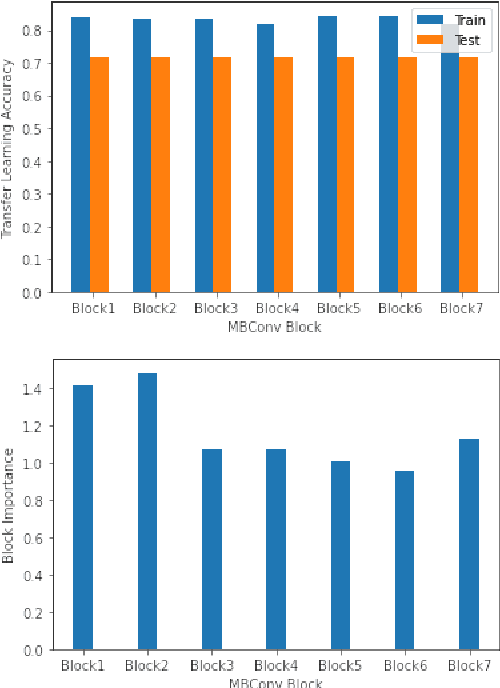
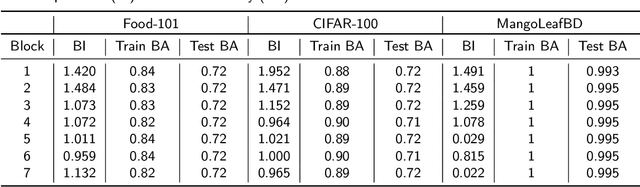
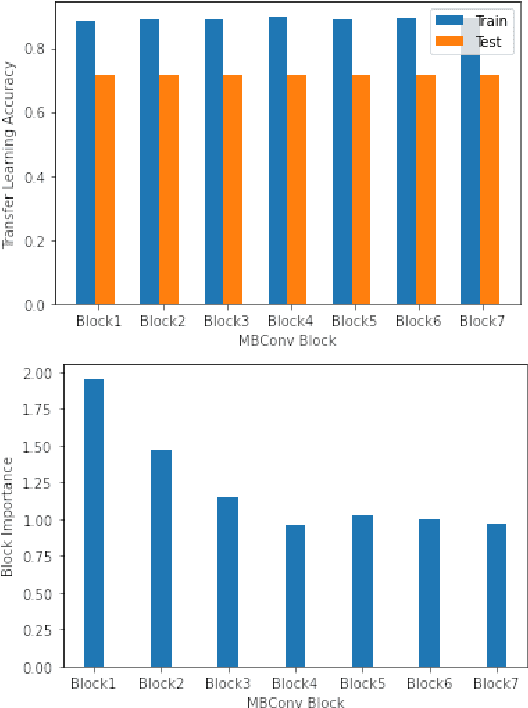
The performance of convolutional neural networks (CNN) depends heavily on their architectures. Transfer learning performance of a CNN relies quite strongly on selection of its trainable layers. Selecting the most effective update layers for a certain target dataset often requires expert knowledge on CNN architecture which many practitioners do not posses. General users prefer to use an available architecture (e.g. GoogleNet, ResNet, EfficientNet etc.) that is developed by domain experts. With the ever-growing number of layers, it is increasingly becoming quite difficult and cumbersome to handpick the update layers. Therefore, in this paper we explore the application of genetic algorithm to mitigate this problem. The convolutional layers of popular pretrained networks are often grouped into modules that constitute their building blocks. We devise a genetic algorithm to select blocks of layers for updating the parameters. By experimenting with EfficientNetB0 pre-trained on ImageNet and using Food-101, CIFAR-100 and MangoLeafBD as target datasets, we show that our algorithm yields similar or better results than the baseline in terms of accuracy, and requires lower training and evaluation time due to learning less number of parameters. We also devise a metric called block importance to measure efficacy of each block as update block and analyze the importance of the blocks selected by our algorithm.
Soft Prompt Guided Joint Learning for Cross-Domain Sentiment Analysis
Mar 01, 2023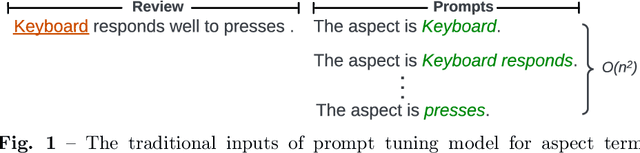
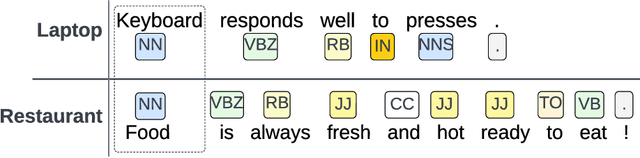

Aspect term extraction is a fundamental task in fine-grained sentiment analysis, which aims at detecting customer's opinion targets from reviews on product or service. The traditional supervised models can achieve promising results with annotated datasets, however, the performance dramatically decreases when they are applied to the task of cross-domain aspect term extraction. Existing cross-domain transfer learning methods either directly inject linguistic features into Language models, making it difficult to transfer linguistic knowledge to target domain, or rely on the fixed predefined prompts, which is time-consuming to construct the prompts over all potential aspect term spans. To resolve the limitations, we propose a soft prompt-based joint learning method for cross domain aspect term extraction in this paper. Specifically, by incorporating external linguistic features, the proposed method learn domain-invariant representations between source and target domains via multiple objectives, which bridges the gap between domains with varied distributions of aspect terms. Further, the proposed method interpolates a set of transferable soft prompts consisted of multiple learnable vectors that are beneficial to detect aspect terms in target domain. Extensive experiments are conducted on the benchmark datasets and the experimental results demonstrate the effectiveness of the proposed method for cross-domain aspect terms extraction.
HelixSurf: A Robust and Efficient Neural Implicit Surface Learning of Indoor Scenes with Iterative Intertwined Regularization
Mar 01, 2023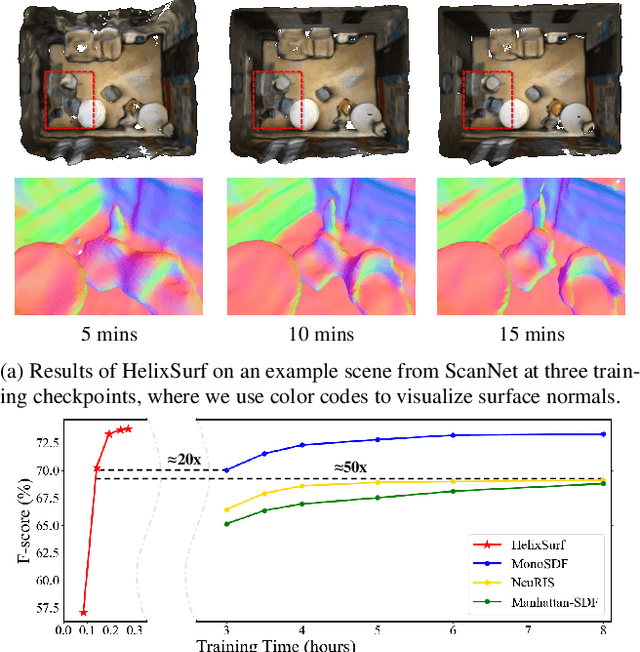
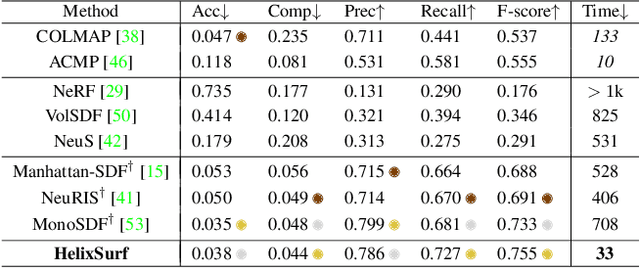
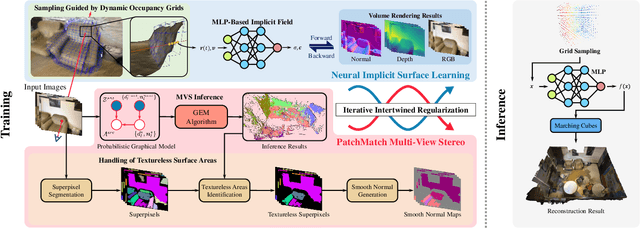
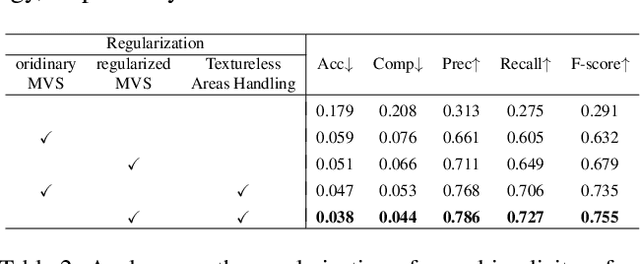
Recovery of an underlying scene geometry from multiview images stands as a long-time challenge in computer vision research. The recent promise leverages neural implicit surface learning and differentiable volume rendering, and achieves both the recovery of scene geometry and synthesis of novel views, where deep priors of neural models are used as an inductive smoothness bias. While promising for object-level surfaces, these methods suffer when coping with complex scene surfaces. In the meanwhile, traditional multi-view stereo can recover the geometry of scenes with rich textures, by globally optimizing the local, pixel-wise correspondences across multiple views. We are thus motivated to make use of the complementary benefits from the two strategies, and propose a method termed Helix-shaped neural implicit Surface learning or HelixSurf; HelixSurf uses the intermediate prediction from one strategy as the guidance to regularize the learning of the other one, and conducts such intertwined regularization iteratively during the learning process. We also propose an efficient scheme for differentiable volume rendering in HelixSurf. Experiments on surface reconstruction of indoor scenes show that our method compares favorably with existing methods and is orders of magnitude faster, even when some of existing methods are assisted with auxiliary training data. The source code is available at https://github.com/Gorilla-Lab-SCUT/HelixSurf.
2D-Empowered 3D Object Detection on the Edge
Feb 18, 2023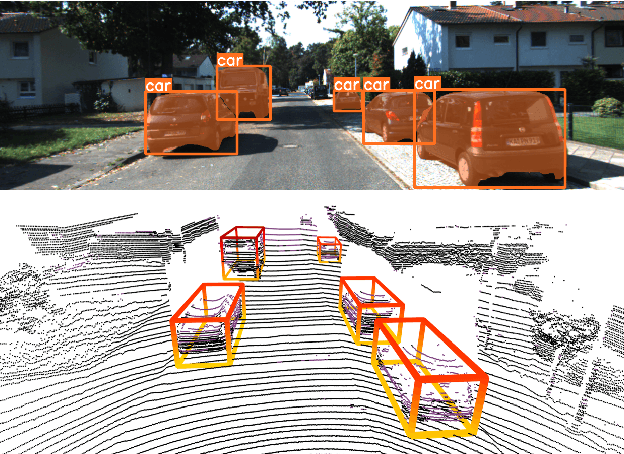
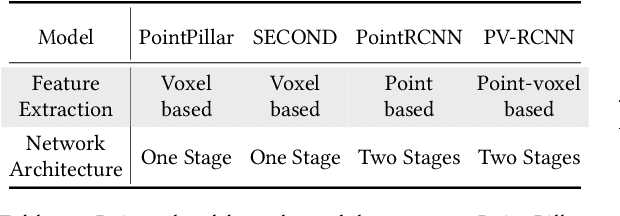
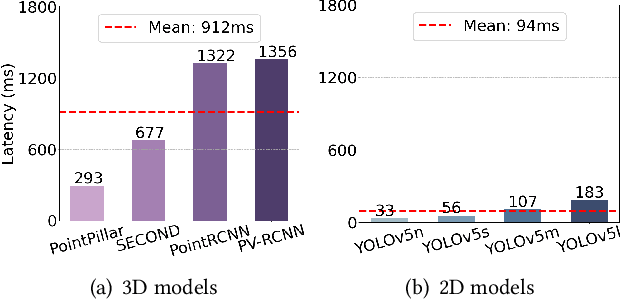
3D object detection has a pivotal role in a wide range of applications, most notably autonomous driving and robotics. These applications are commonly deployed on edge devices to promptly interact with the environment, and often require near real-time response. With limited computation power, it is challenging to execute 3D detection on the edge using highly complex neural networks. Common approaches such as offloading to the cloud brings latency overheads due to the large amount of 3D point cloud data during transmission. To resolve the tension between wimpy edge devices and compute-intensive inference workloads, we explore the possibility of transforming fast 2D detection results to extrapolate 3D bounding boxes. To this end, we present Moby, a novel system that demonstrates the feasibility and potential of our approach. Our main contributions are two-fold: First, we design a 2D-to-3D transformation pipeline that takes as input the point cloud data from LiDAR and 2D bounding boxes from camera that are captured at exactly the same time, and generate 3D bounding boxes efficiently and accurately based on detection results of the previous frames without running 3D detectors. Second, we design a frame offloading scheduler that dynamically launches a 3D detection when the error of 2D-to-3D transformation accumulates to a certain level, so the subsequent transformations can draw upon the latest 3D detection results with better accuracy. Extensive evaluation on NVIDIA Jetson TX2 with the autonomous driving dataset KITTI and real-world 4G/LTE traces shows that, Moby reduces the end-to-end latency by up to 91.9% with mild accuracy drop compared to baselines. Further, Moby shows excellent energy efficiency by saving power consumption and memory footprint up to 75.7% and 48.1%, respectively.
Polynomial-Time Reachability for LTI Systems with Two-Level Lattice Neural Network Controllers
Sep 20, 2022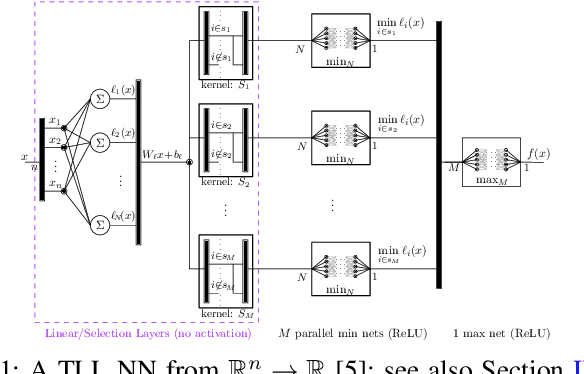
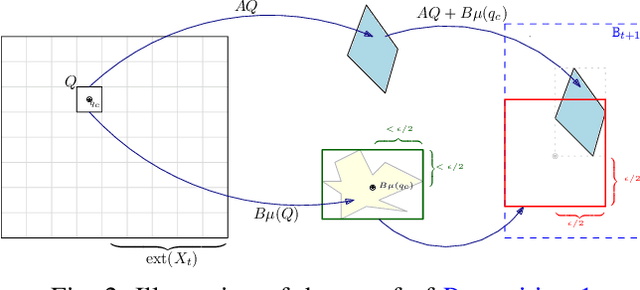
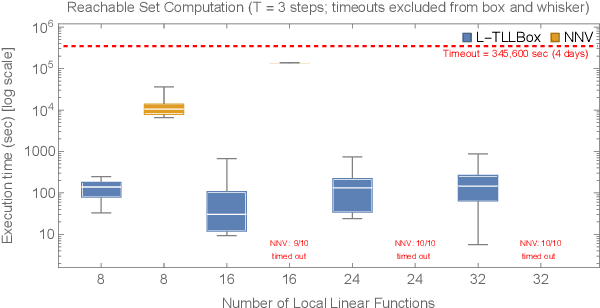
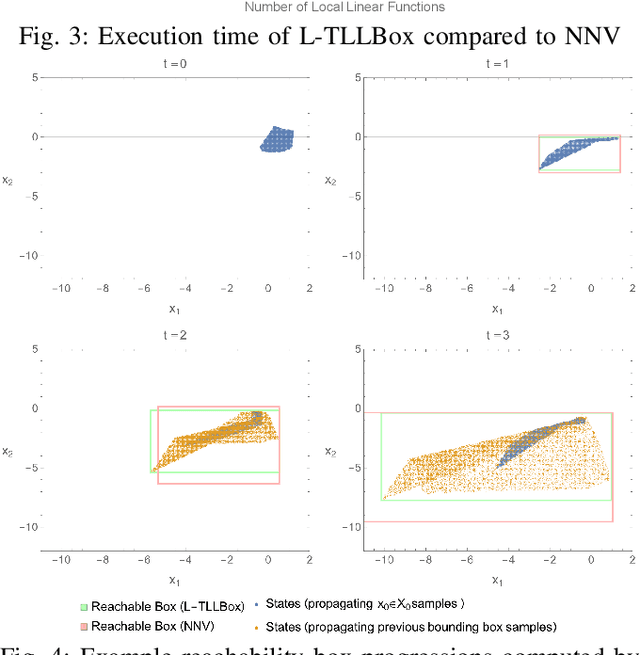
In this paper, we consider the computational complexity of bounding the reachable set of a Linear Time-Invariant (LTI) system controlled by a Rectified Linear Unit (ReLU) Two-Level Lattice (TLL) Neural Network (NN) controller. In particular, we show that for such a system and controller, it is possible to compute the exact one-step reachable set in polynomial time in the size of the size of the TLL NN controller (number of neurons). Additionally, we show that it is possible to obtain a tight bounding box of the reachable set via two polynomial-time methods: one with polynomial complexity in the size of the TLL and the other with polynomial complexity in the Lipschitz constant of the controller and other problem parameters. Crucially, the smaller of the two can be decided in polynomial time for non-degenerate TLL NNs. Finally, we propose a pragmatic algorithm that adaptively combines the benefits of (semi-)exact reachability and approximate reachability, which we call L-TLLBox. We evaluate L-TLLBox with an empirical comparison to a state-of-the-art NN controller reachability tool. In these experiments, L-TLLBox was able to complete reachability analysis as much as 5000x faster than this tool on the same network/system, while producing reach boxes that were from 0.08 to 1.42 times the area.