 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ProbPNN: Enhancing Deep Probabilistic Forecasting with Statistical Information
Feb 06, 2023
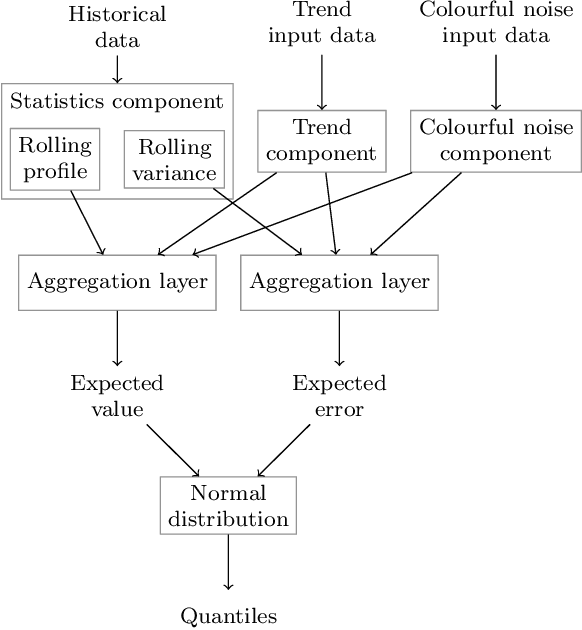
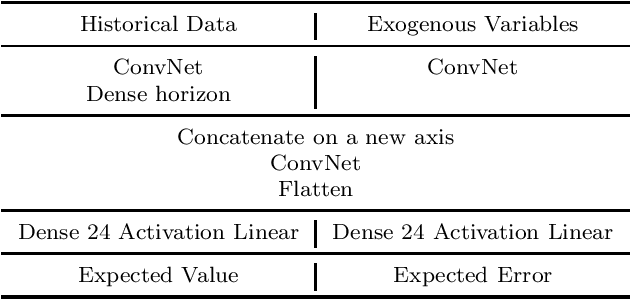

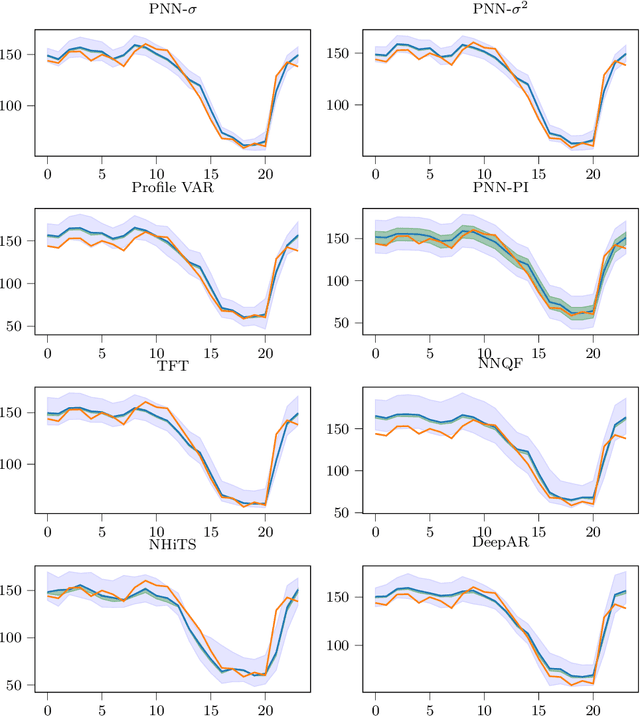
Probabilistic forecasts are essential for various downstream applications such as business development, traffic planning, and electrical grid balancing. Many of these probabilistic forecasts are performed on time series data that contain calendar-driven periodicities. However, existing probabilistic forecasting methods do not explicitly take these periodicities into account. Therefore, in the present paper, we introduce a deep learning-based method that considers these calendar-driven periodicities explicitly. The present paper, thus, has a twofold contribution: First, we apply statistical methods that use calendar-driven prior knowledge to create rolling statistics and combine them with neural networks to provide better probabilistic forecasts. Second, we benchmark ProbPNN with state-of-the-art benchmarks by comparing the achieved normalised continuous ranked probability score (nCRPS) and normalised Pinball Loss (nPL) on two data sets containing in total more than 1000 time series. The results of the benchmarks show that using statistical forecasting components improves the probabilistic forecast performance and that ProbPNN outperforms other deep learning forecasting methods whilst requiring less computation costs.
Urine Dataset having eight particles classes
Feb 22, 2023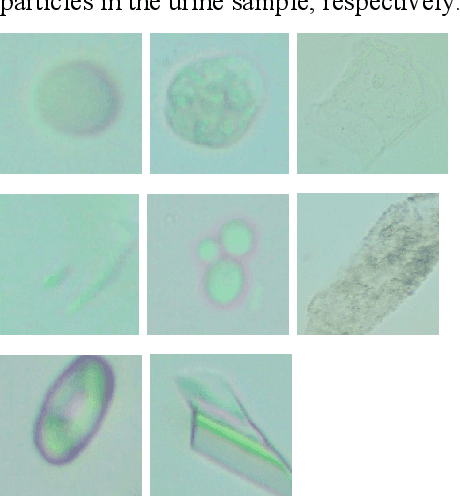

Urine sediment examination (USE) is one of the main tests used in the evaluation of diseases such as kidney, urinary, metabolic, and diabetes and to determine the density and number of various cells in the urine. USE's manual microscopy is a labor-intensive and time-consuming, imprecise, subjective process. Recently, automatic analysis of urine sediment has become inevitable in the medical field. In this study, we propose a dataset that can be used by artificial intelligence techniques to automatically identify particles in urine sediment images. The data set consists of 8509 particle images obtained by examining the particles in the urine sediment obtained from 409 patients from the Biochemistry Clinics of Elazig Fethi Sekin Central Hospital. Particle images are collected in 8 classes in total and these are Erythrocyte, Leukocyte, Epithelial, Bacteria, Yeast, Cylinders, Crystals, and others (sperm, etc.).
Invariant Target Detection in Images through the Normalized 2-D Correlation Technique
Feb 22, 2023

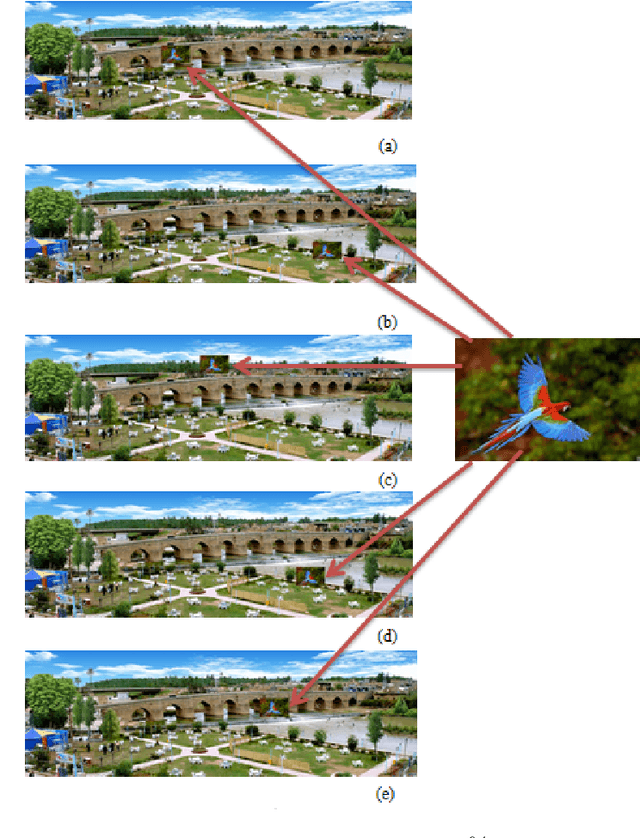

The normalized 2-D correlation technique is a robust method for detecting targets in images due to its ability to remain invariant under rotation, translation, and scaling. This paper examines the impact of translation, and scaling on target identification in images. The results indicate a high level of accuracy in detecting targets, even when they are exhibit variations in location and size. The results indicate that the similarity between the image and the two used targets improves as the resize ratio increases. All statistical estimators demonstrate a strong similarity between the original and extracted targets. The elapsed time for all scenarios falls within the range (44.75-44.85), (37.48-37.73) seconds for bird and children targets respectively, and the correlation coefficient displays stable relationships with values that fall within the range of (0.90-0.98) and (0.87-0.93) for bird and children targets respectively.
Heterogeneous Neuronal and Synaptic Dynamics for Spike-Efficient Unsupervised Learning: Theory and Design Principles
Feb 22, 2023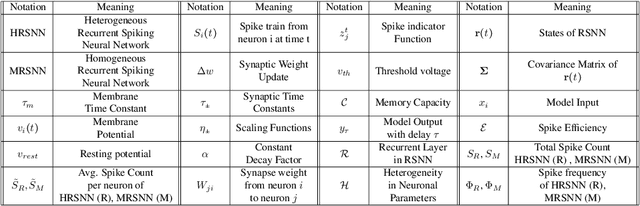
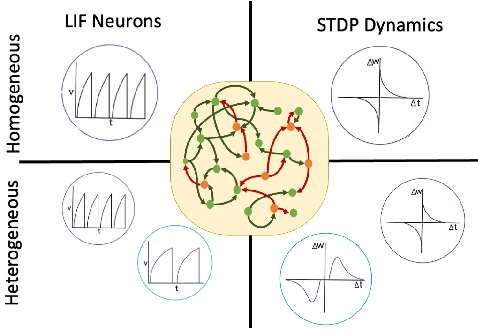

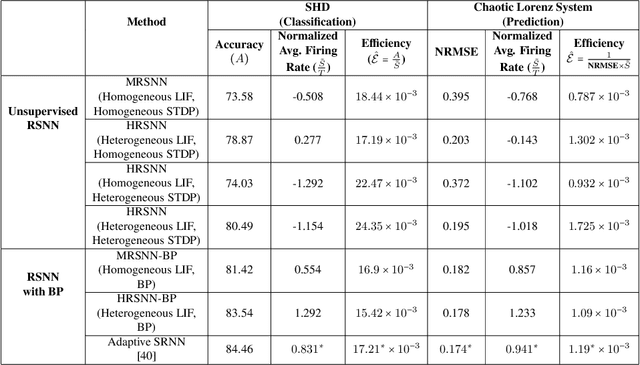
This paper shows that the heterogeneity in neuronal and synaptic dynamics reduces the spiking activity of a Recurrent Spiking Neural Network (RSNN) while improving prediction performance, enabling spike-efficient (unsupervised) learning. We analytically show that the diversity in neurons' integration/relaxation dynamics improves an RSNN's ability to learn more distinct input patterns (higher memory capacity), leading to improved classification and prediction performance. We further prove that heterogeneous Spike-Timing-Dependent-Plasticity (STDP) dynamics of synapses reduce spiking activity but preserve memory capacity. The analytical results motivate Heterogeneous RSNN design using Bayesian optimization to determine heterogeneity in neurons and synapses to improve $\mathcal{E}$, defined as the ratio of spiking activity and memory capacity. The empirical results on time series classification and prediction tasks show that optimized HRSNN increases performance and reduces spiking activity compared to a homogeneous RSNN.
* Paper Published in ICLR 2023 (https://openreview.net/forum?id=QIRtAqoXwj)
Securing IoT Communication using Physical Sensor Data -- Graph Layer Security with Federated Multi-Agent Deep Reinforcement Learning
Feb 24, 2023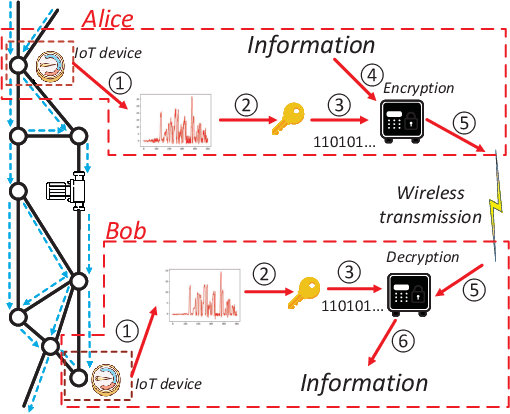
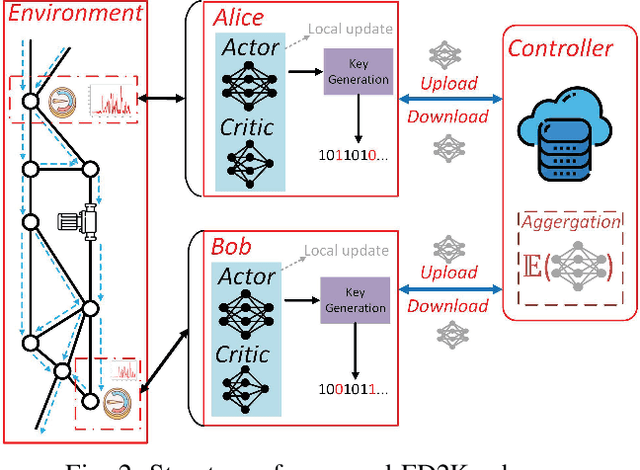
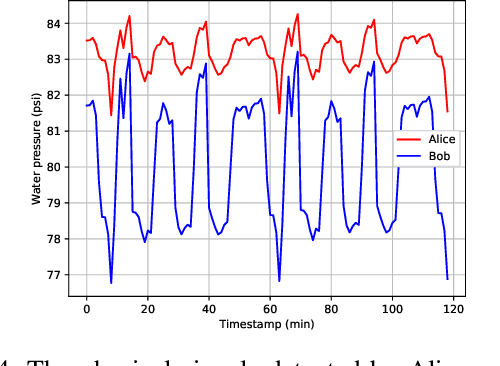
Internet-of-Things (IoT) devices are often used to transmit physical sensor data over digital wireless channels. Traditional Physical Layer Security (PLS)-based cryptography approaches rely on accurate channel estimation and information exchange for key generation, which irrevocably ties key quality with digital channel estimation quality. Recently, we proposed a new concept called Graph Layer Security (GLS), where digital keys are derived from physical sensor readings. The sensor readings between legitimate users are correlated through a common background infrastructure environment (e.g., a common water distribution network or electric grid). The challenge for GLS has been how to achieve distributed key generation. This paper presents a Federated multi-agent Deep reinforcement learning-assisted Distributed Key generation scheme (FD2K), which fully exploits the common features of physical dynamics to establish secret key between legitimate users. We present for the first time initial experimental results of GLS with federated learning, achieving considerable security performance in terms of key agreement rate (KAR), and key randomness.
A DeepONet Multi-Fidelity Approach for Residual Learning in Reduced Order Modeling
Feb 24, 2023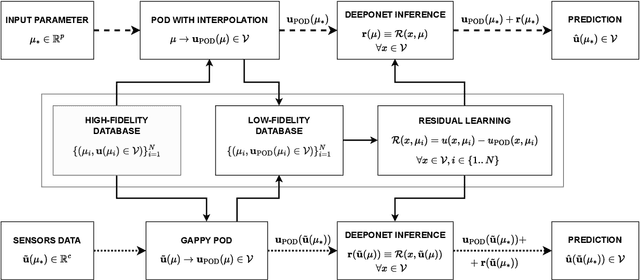
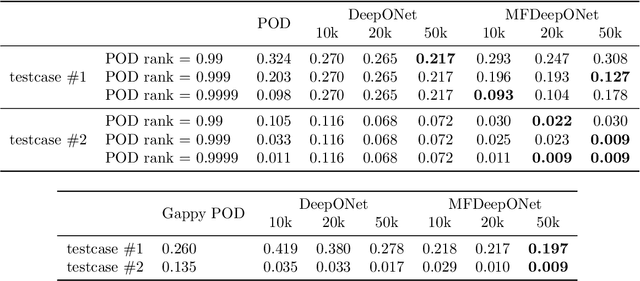
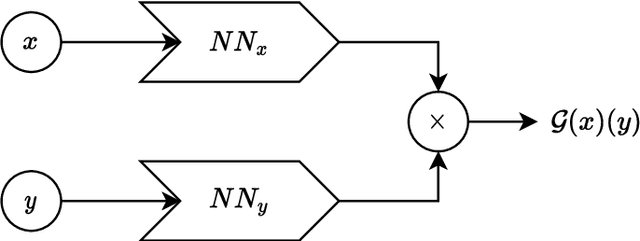
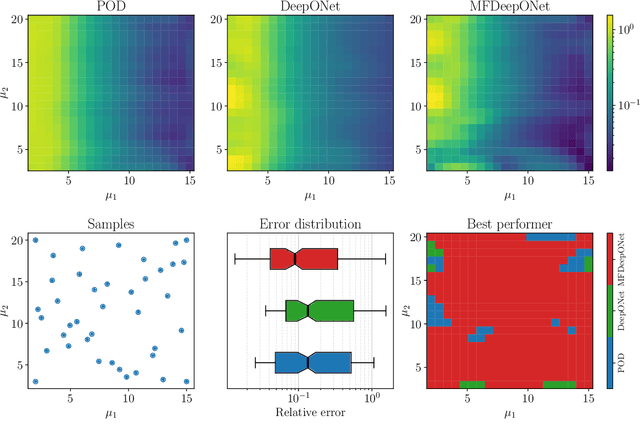
In the present work, we introduce a novel approach to enhance the precision of reduced order models by exploiting a multi-fidelity perspective and DeepONets. Reduced models provide a real-time numerical approximation by simplifying the original model. The error introduced by such operation is usually neglected and sacrificed in order to reach a fast computation. We propose to couple the model reduction to a machine learning residual learning, such that the above-mentioned error can be learnt by a neural network and inferred for new predictions. We emphasize that the framework maximizes the exploitation of the high-fidelity information, using it for building the reduced order model and for learning the residual. In this work we explore the integration of proper orthogonal decomposition (POD), and gappy POD for sensors data, with the recent DeepONet architecture. Numerical investigations for a parametric benchmark function and a nonlinear parametric Navier-Stokes problem are presented.
Fast-Image2Point: Towards Real-Time Point Cloud Reconstruction of a Single Image using 3D Supervision
Sep 20, 2022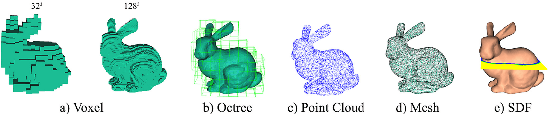
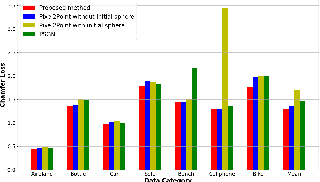
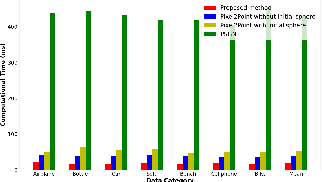
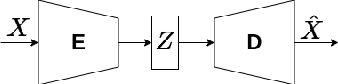
A key question in the problem of 3D reconstruction is how to train a machine or a robot to model 3D objects. Many tasks like navigation in real-time systems such as autonomous vehicles directly depend on this problem. These systems usually have limited computational power. Despite considerable progress in 3D reconstruction systems in recent years, applying them to real-time systems such as navigation systems in autonomous vehicles is still challenging due to the high complexity and computational demand of the existing methods. This study addresses current problems in reconstructing objects displayed in a single-view image in a faster (real-time) fashion. To this end, a simple yet powerful deep neural framework is developed. The proposed framework consists of two components: the feature extractor module and the 3D generator module. We use point cloud representation for the output of our reconstruction module. The ShapeNet dataset is utilized to compare the method with the existing results in terms of computation time and accuracy. Simulations demonstrate the superior performance of the proposed method. Index Terms-Real-time 3D reconstruction, single-view reconstruction, supervised learning, deep neural network
How Does Data Freshness Affect Real-time Supervised Learning?
Aug 15, 2022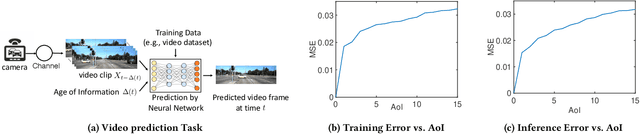
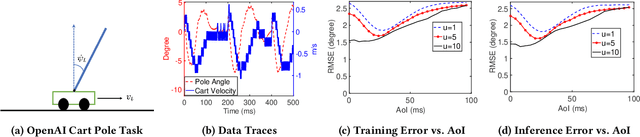
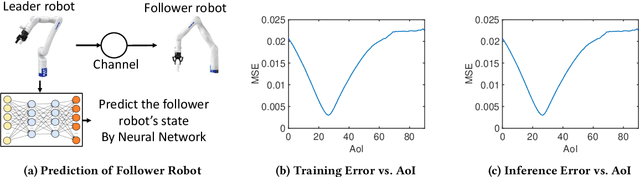
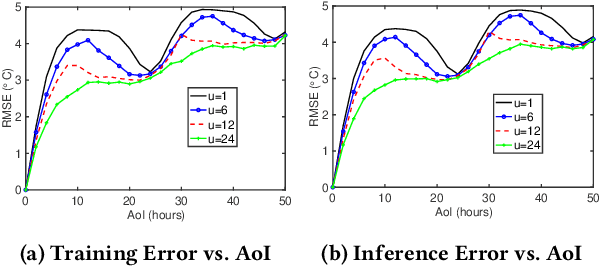
In this paper, we analyze the impact of data freshness on real-time supervised learning, where a neural network is trained to infer a time-varying target (e.g., the position of the vehicle in front) based on features (e.g., video frames) observed at a sensing node (e.g., camera or lidar). One might expect that the performance of real-time supervised learning degrades monotonically as the feature becomes stale. Using an information-theoretic analysis, we show that this is true if the feature and target data sequence can be closely approximated as a Markov chain; it is not true if the data sequence is far from Markovian. Hence, the prediction error of real-time supervised learning is a function of the Age of Information (AoI), where the function could be non-monotonic. Several experiments are conducted to illustrate the monotonic and non-monotonic behaviors of the prediction error. To minimize the inference error in real-time, we propose a new "selection-from-buffer" model for sending the features, which is more general than the "generate-at-will" model used in earlier studies. By using Gittins and Whittle indices, low-complexity scheduling strategies are developed to minimize the inference error, where a new connection between the Gittins index theory and Age of Information (AoI) minimization is discovered. These scheduling results hold (i) for minimizing general AoI functions (monotonic or non-monotonic) and (ii) for general feature transmission time distributions. Data-driven evaluations are presented to illustrate the benefits of the proposed scheduling algorithms.
A Pilot Study on Teacher-Facing Real-Time Classroom Game Dashboards
Oct 17, 2022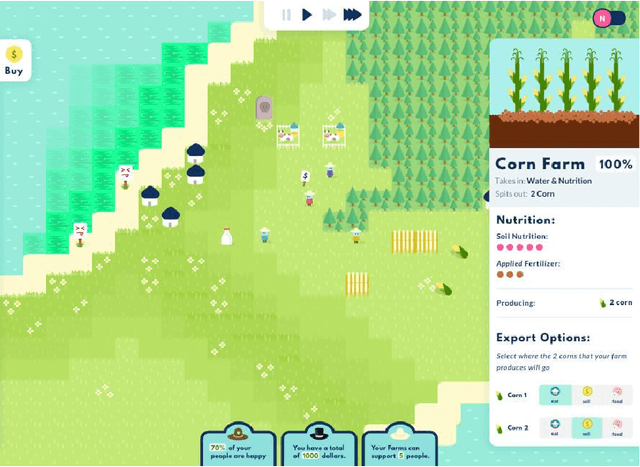
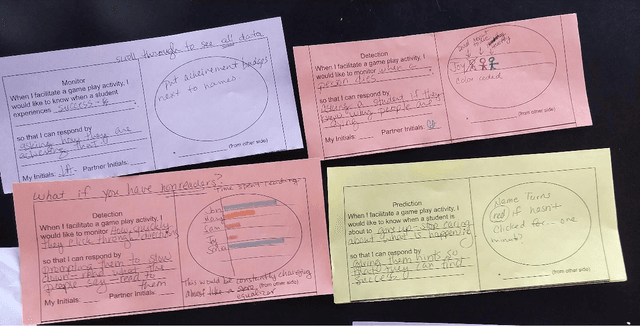
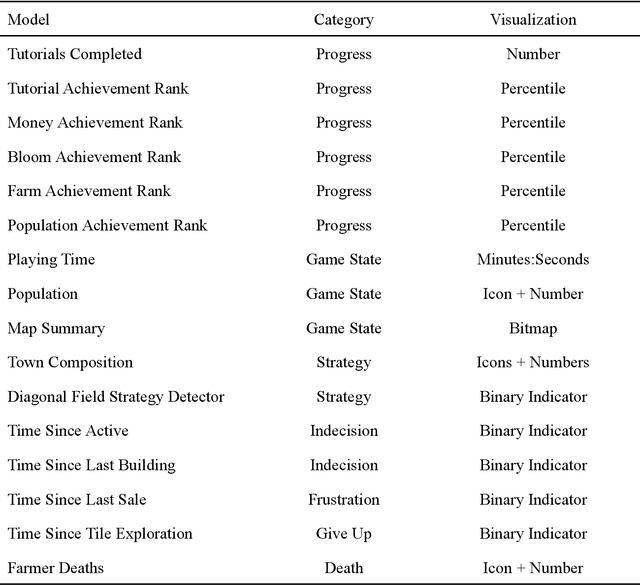
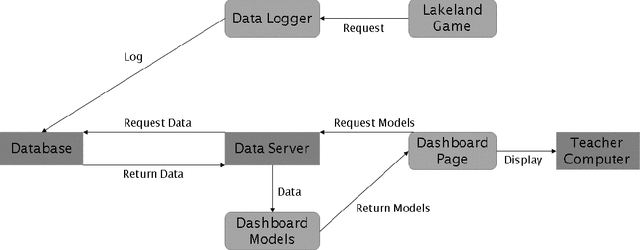
Educational games are an increasingly popular teaching tool in modern classrooms. However, the development of complementary tools for teachers facilitating classroom gameplay is lacking. We present the results of a participatory design process for a teacher-facing, real-time game data dashboard. This two-phase process included a workshop to elicit teachers' requirements for such a tool, and a pilot study of our dashboard prototype. We analyze post-gameplay survey and interview data to understand teachers' experiences with the tool in terms of evidence of co-design, feasibility, and effectiveness. Our results indicate the participatory design yielded a tool both useful for and usable by teachers within the context of a real class gameplay session. We advocate for the continued development of data-driven teacher tools to improve the effectiveness of games deployed in the classroom.
B$^3$RTDP: A Belief Branch and Bound Real-Time Dynamic Programming Approach to Solving POMDPs
Oct 22, 2022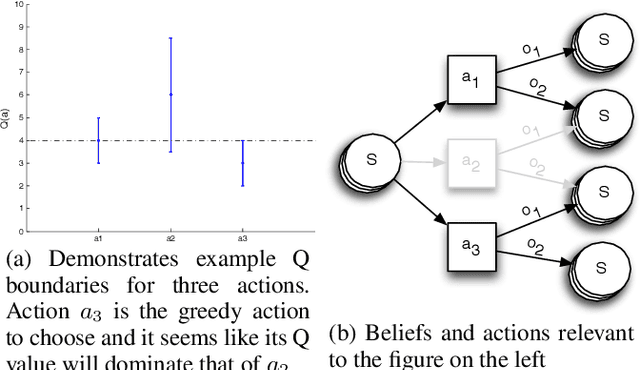
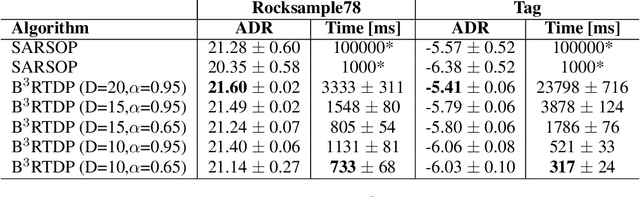
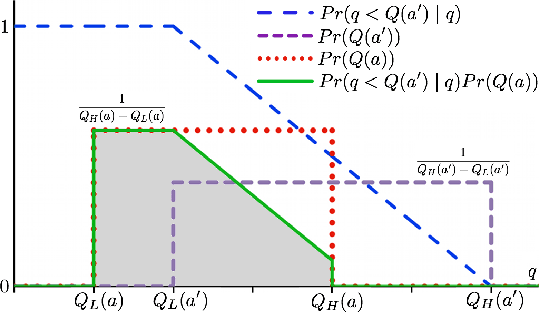
Partially Observable Markov Decision Processes (POMDPs) offer a promising world representation for autonomous agents, as they can model both transitional and perceptual uncertainties. Calculating the optimal solution to POMDP problems can be computationally expensive as they require reasoning over the (possibly infinite) space of beliefs. Several approaches have been proposed to overcome this difficulty, such as discretizing the belief space, point-based belief sampling, and Monte Carlo tree search. The Real-Time Dynamic Programming approach of the RTDP-Bel algorithm approximates the value function by storing it in a hashtable with discretized belief keys. We propose an extension to the RTDP-Bel algorithm which we call Belief Branch and Bound RTDP (B$^3$RTDP). Our algorithm uses a bounded value function representation and takes advantage of this in two novel ways: a search-bounding technique based on action selection convergence probabilities, and a method for leveraging early action convergence called the \textit{Convergence Frontier}. Lastly, we empirically demonstrate that B$^3$RTDP can achieve greater returns in less time than the state-of-the-art SARSOP solver on known POMDP problems.