 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Differentiable Signed Distance Representation for Continuous Collision Avoidance in Optimization-Based Motion Planning
Feb 20, 2023
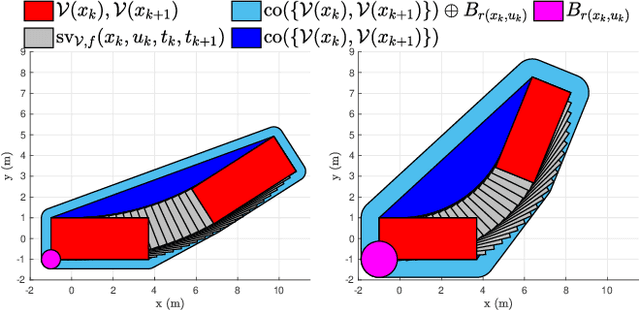
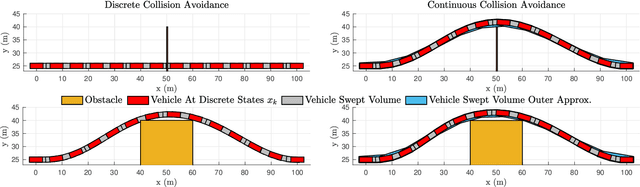
This paper proposes a new set of conditions for exactly representing collision avoidance constraints within optimization-based motion planning algorithms. The conditions are continuously differentiable and therefore suitable for use with standard nonlinear optimization solvers. The method represents convex shapes using a support function representation and is therefore quite general. For collision avoidance involving polyhedral or ellipsoidal shapes, the proposed method introduces fewer variables and constraints than existing approaches. Additionally the proposed method can be used to rigorously ensure continuous collision avoidance as the vehicle transitions between the discrete poses determined by the motion planning algorithm. Numerical examples demonstrate how this can be used to prevent problems of corner cutting and passing through obstacles which can occur when collision avoidance is only enforced at discrete time steps.
* 8 pages, 2 figures, accepted for publication at IEEE Conference on Decision and Control, 2022
Two-stream Decoder Feature Normality Estimating Network for Industrial Anomaly Detection
Feb 20, 2023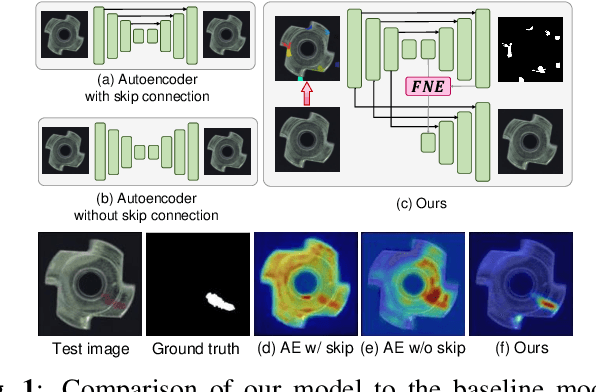

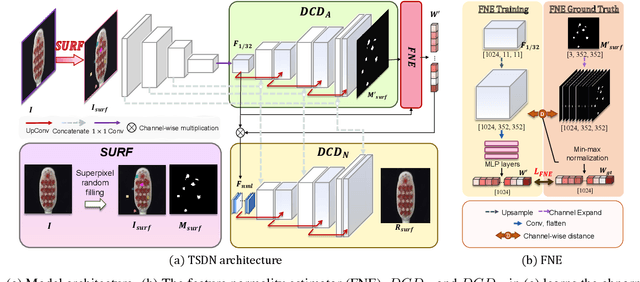
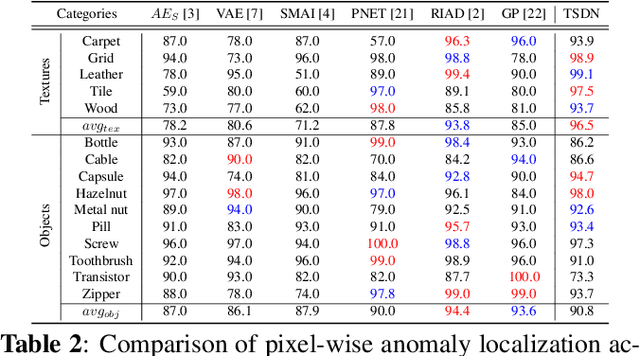
Image reconstruction-based anomaly detection has recently been in the spotlight because of the difficulty of constructing anomaly datasets. These approaches work by learning to model normal features without seeing abnormal samples during training and then discriminating anomalies at test time based on the reconstructive errors. However, these models have limitations in reconstructing the abnormal samples due to their indiscriminate conveyance of features. Moreover, these approaches are not explicitly optimized for distinguishable anomalies. To address these problems, we propose a two-stream decoder network (TSDN), designed to learn both normal and abnormal features. Additionally, we propose a feature normality estimator (FNE) to eliminate abnormal features and prevent high-quality reconstruction of abnormal regions. Evaluation on a standard benchmark demonstrated performance better than state-of-the-art models.
How Does Data Freshness Affect Real-time Supervised Learning?
Aug 15, 2022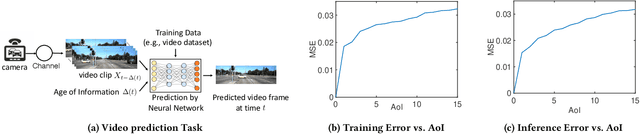
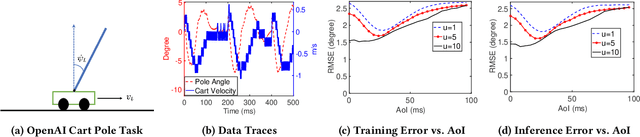
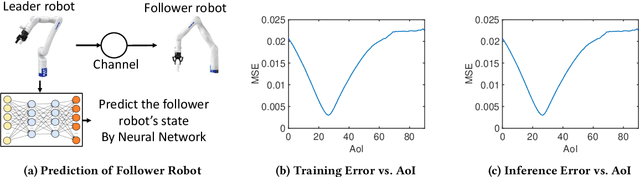
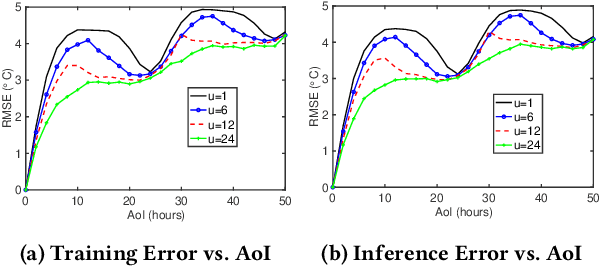
In this paper, we analyze the impact of data freshness on real-time supervised learning, where a neural network is trained to infer a time-varying target (e.g., the position of the vehicle in front) based on features (e.g., video frames) observed at a sensing node (e.g., camera or lidar). One might expect that the performance of real-time supervised learning degrades monotonically as the feature becomes stale. Using an information-theoretic analysis, we show that this is true if the feature and target data sequence can be closely approximated as a Markov chain; it is not true if the data sequence is far from Markovian. Hence, the prediction error of real-time supervised learning is a function of the Age of Information (AoI), where the function could be non-monotonic. Several experiments are conducted to illustrate the monotonic and non-monotonic behaviors of the prediction error. To minimize the inference error in real-time, we propose a new "selection-from-buffer" model for sending the features, which is more general than the "generate-at-will" model used in earlier studies. By using Gittins and Whittle indices, low-complexity scheduling strategies are developed to minimize the inference error, where a new connection between the Gittins index theory and Age of Information (AoI) minimization is discovered. These scheduling results hold (i) for minimizing general AoI functions (monotonic or non-monotonic) and (ii) for general feature transmission time distributions. Data-driven evaluations are presented to illustrate the benefits of the proposed scheduling algorithms.
Fast-Image2Point: Towards Real-Time Point Cloud Reconstruction of a Single Image using 3D Supervision
Sep 20, 2022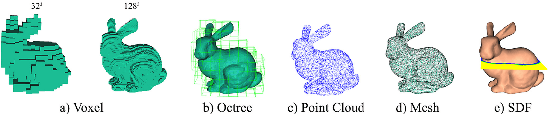
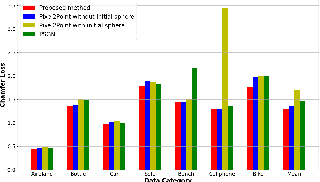
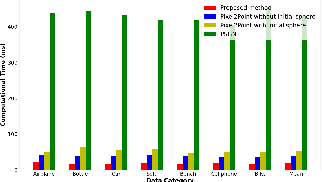
A key question in the problem of 3D reconstruction is how to train a machine or a robot to model 3D objects. Many tasks like navigation in real-time systems such as autonomous vehicles directly depend on this problem. These systems usually have limited computational power. Despite considerable progress in 3D reconstruction systems in recent years, applying them to real-time systems such as navigation systems in autonomous vehicles is still challenging due to the high complexity and computational demand of the existing methods. This study addresses current problems in reconstructing objects displayed in a single-view image in a faster (real-time) fashion. To this end, a simple yet powerful deep neural framework is developed. The proposed framework consists of two components: the feature extractor module and the 3D generator module. We use point cloud representation for the output of our reconstruction module. The ShapeNet dataset is utilized to compare the method with the existing results in terms of computation time and accuracy. Simulations demonstrate the superior performance of the proposed method. Index Terms-Real-time 3D reconstruction, single-view reconstruction, supervised learning, deep neural network
User Study for Improving Tools for Bible Translation
Feb 01, 2023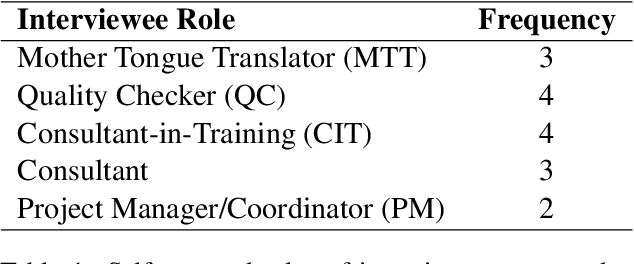
Technology has increasingly become an integral part of the Bible translation process. Over time, both the translation process and relevant technology have evolved greatly. More recently, the field of Natural Language Processing (NLP) has made great progress in solving some problems previously thought impenetrable. Through this study we endeavor to better understand and communicate about a segment of the current landscape of the Bible translation process as it relates to technology and identify pertinent issues. We conduct several interviews with individuals working in different levels of the Bible translation process from multiple organizations to identify gaps and bottlenecks where technology (including recent advances in AI) could potentially play a pivotal role in reducing translation time and improving overall quality.
Enhancing Fairness in AI-based Travel Demand Forecasting Models
Mar 03, 2023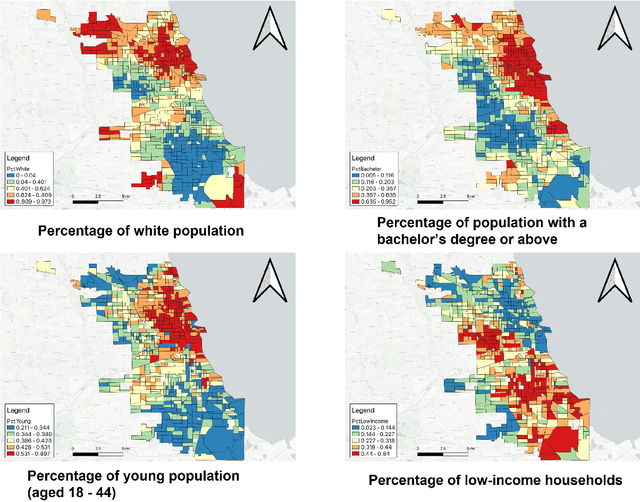


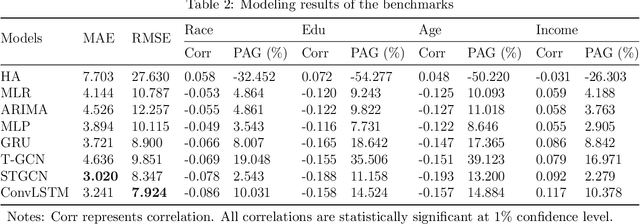
Artificial Intelligence (AI) and machine learning have been increasingly adopted for forecasting real-time travel demand. These AI-based travel demand forecasting models, though generate highly-accurate predictions, may produce prediction biases and thus raise fairness issues. Using such models for decision-making, we may develop transportation policies that could exacerbate social inequalities. However, limited studies have been focused on addressing the fairness issues of AI-based travel demand forecasting models. Therefore, in this study, we propose a novel methodology to develop fairness-aware travel demand forecasting models, which are highly accurate and fair. Specifically, we add a fairness regularization term, i.e., the correlation between prediction accuracy and the protected attribute such as race or income, into the loss function of the travel demand forecasting model. We include an interactive weight coefficient to both accuracy loss term and fairness loss term. The travel demand forecasting models can thus simultaneously account for prediction accuracy and fairness. An empirical analysis is conducted using real-world ridesourcing-trip data in Chicago. Results show that our proposed methodology effectively addresses the accuracy-fairness trade-off. It can significantly enhance fairness for multiple protected attributes (i.e., race, education, age and income) by only sacrificing a small accuracy drop. This study provides transportation professionals a new type of decision-support tool to achieve fair and accurate travel demand forecasting.
Quantifying the LiDAR Sim-to-Real Domain Shift: A Detailed Investigation Using Object Detectors and Analyzing Point Clouds at Target-Level
Mar 03, 2023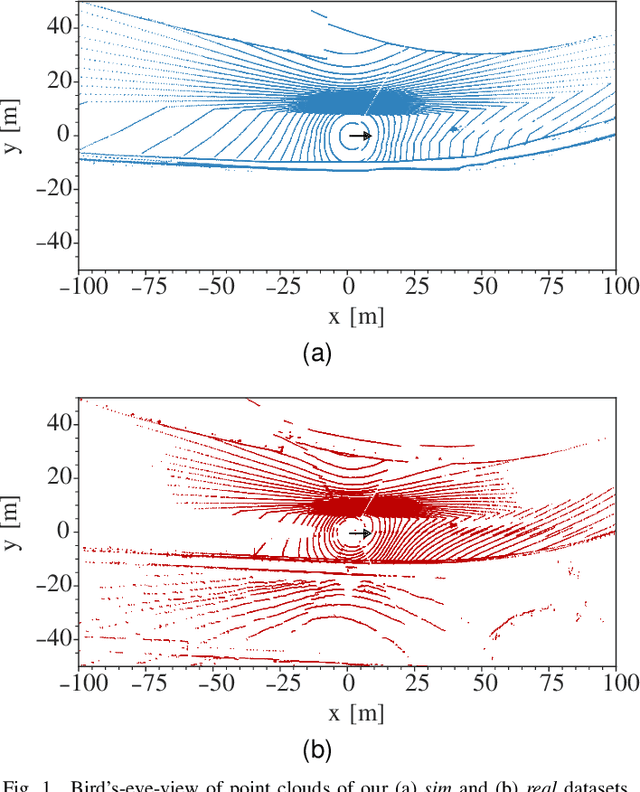

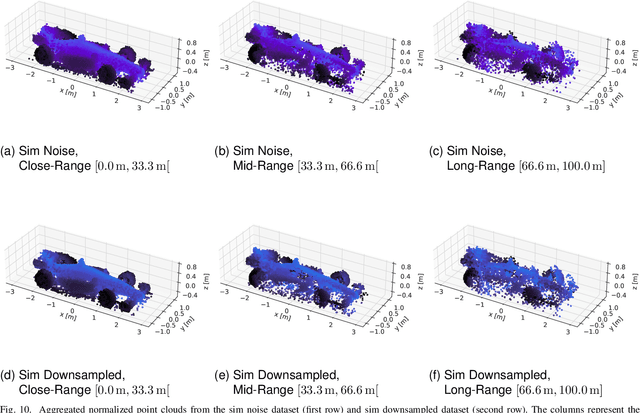
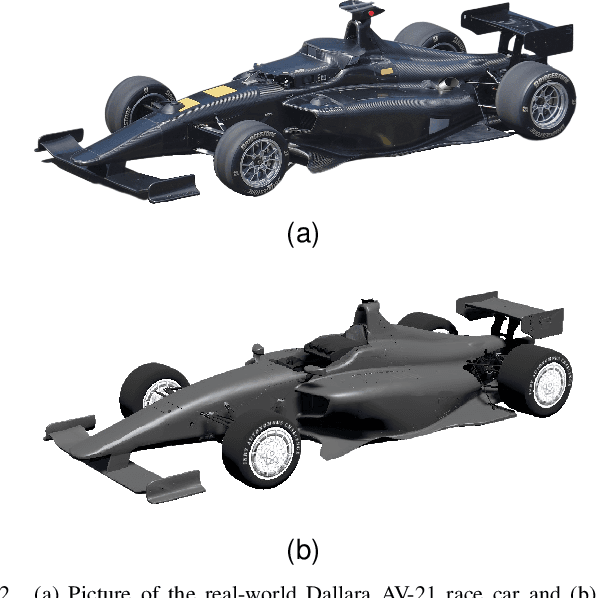
LiDAR object detection algorithms based on neural networks for autonomous driving require large amounts of data for training, validation, and testing. As real-world data collection and labeling are time-consuming and expensive, simulation-based synthetic data generation is a viable alternative. However, using simulated data for the training of neural networks leads to a domain shift of training and testing data due to differences in scenes, scenarios, and distributions. In this work, we quantify the sim-to-real domain shift by means of LiDAR object detectors trained with a new scenario-identical real-world and simulated dataset. In addition, we answer the questions of how well the simulated data resembles the real-world data and how well object detectors trained on simulated data perform on real-world data. Further, we analyze point clouds at the target-level by comparing real-world and simulated point clouds within the 3D bounding boxes of the targets. Our experiments show that a significant sim-to-real domain shift exists even for our scenario-identical datasets. This domain shift amounts to an average precision reduction of around 14 % for object detectors trained with simulated data. Additional experiments reveal that this domain shift can be lowered by introducing a simple noise model in simulation. We further show that a simple downsampling method to model real-world physics does not influence the performance of the object detectors.
APIContext2Com: Code Comment Generation by Incorporating Pre-Defined API Documentation
Mar 03, 2023
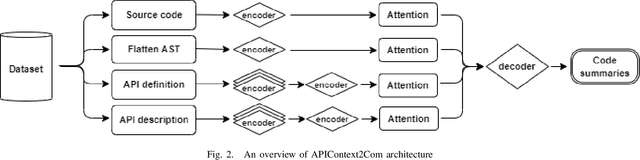
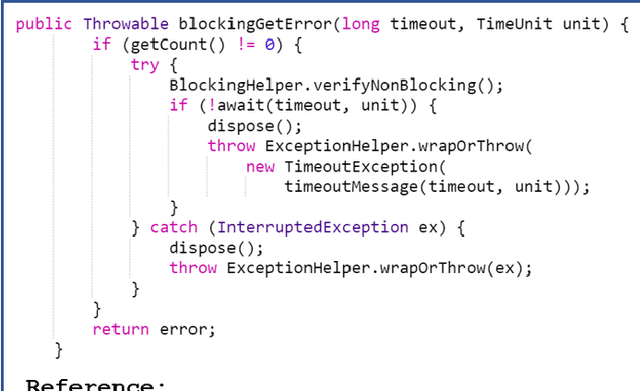
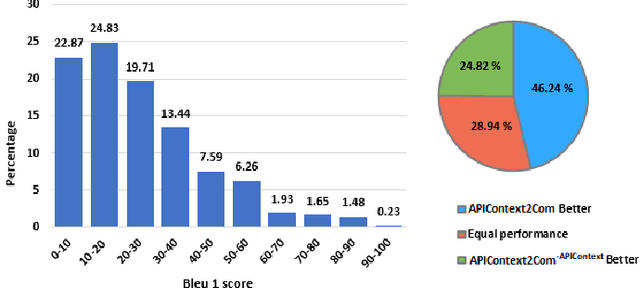
Code comments are significantly helpful in comprehending software programs and also aid developers to save a great deal of time in software maintenance. Code comment generation aims to automatically predict comments in natural language given a code snippet. Several works investigate the effect of integrating external knowledge on the quality of generated comments. In this study, we propose a solution, namely APIContext2Com, to improve the effectiveness of generated comments by incorporating the pre-defined Application Programming Interface (API) context. The API context includes the definition and description of the pre-defined APIs that are used within the code snippets. As the detailed API information expresses the functionality of a code snippet, it can be helpful in better generating the code summary. We introduce a seq-2-seq encoder-decoder neural network model with different sets of multiple encoders to effectively transform distinct inputs into target comments. A ranking mechanism is also developed to exclude non-informative APIs, so that we can filter out unrelated APIs. We evaluate our approach using the Java dataset from CodeSearchNet. The findings reveal that the proposed model improves the best baseline by 1.88 (8.24 %), 2.16 (17.58 %), 1.38 (18.3 %), 0.73 (14.17 %), 1.58 (14.98 %) and 1.9 (6.92 %) for BLEU1, BLEU2, BLEU3, BLEU4, METEOR, ROUGE-L respectively. Human evaluation and ablation studies confirm the quality of the generated comments and the effect of architecture and ranking APIs.
DynGFN: Bayesian Dynamic Causal Discovery using Generative Flow Networks
Feb 08, 2023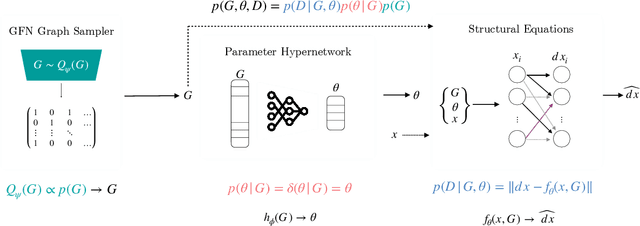
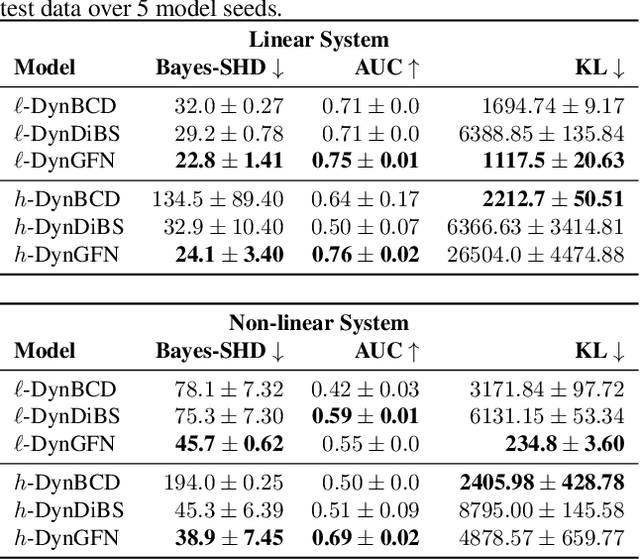


Learning the causal structure of observable variables is a central focus for scientific discovery. Bayesian causal discovery methods tackle this problem by learning a posterior over the set of admissible graphs given our priors and observations. Existing methods primarily consider observations from static systems and assume the underlying causal structure takes the form of a directed acyclic graph (DAG). In settings with dynamic feedback mechanisms that regulate the trajectories of individual variables, this acyclicity assumption fails unless we account for time. We focus on learning Bayesian posteriors over cyclic graphs and treat causal discovery as a problem of sparse identification of a dynamical system. This imposes a natural temporal causal order between variables and captures cyclic feedback loops through time. Under this lens, we propose a new framework for Bayesian causal discovery for dynamical systems and present a novel generative flow network architecture (DynGFN) tailored for this task. Our results indicate that DynGFN learns posteriors that better encapsulate the distributions over admissible cyclic causal structures compared to counterpart state-of-the-art approaches.
A Pilot Study on Teacher-Facing Real-Time Classroom Game Dashboards
Oct 17, 2022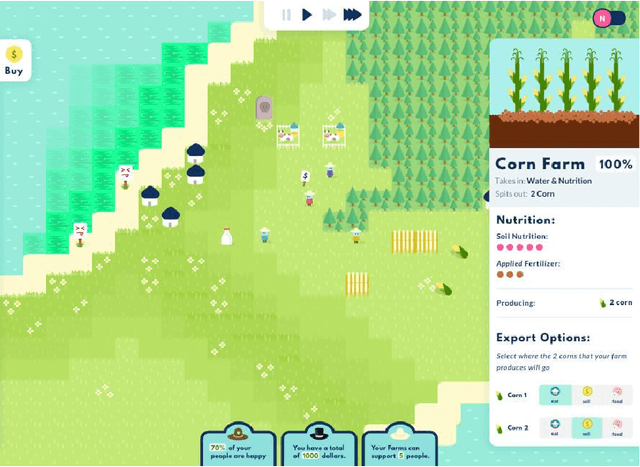
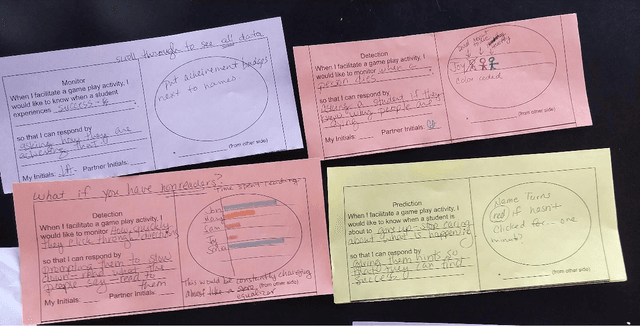
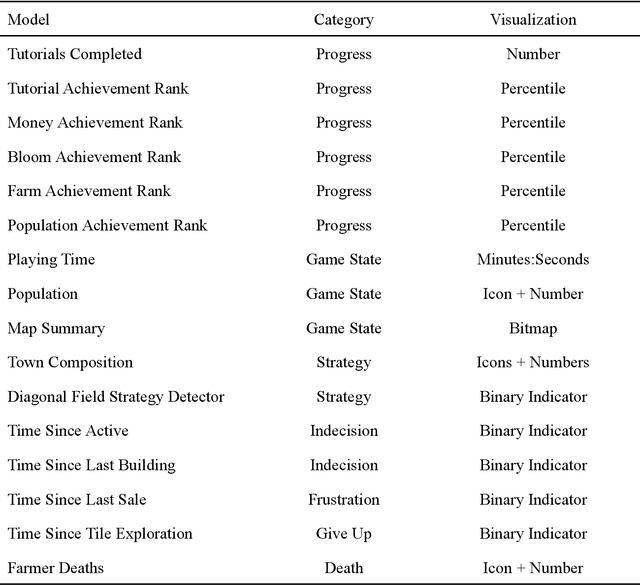
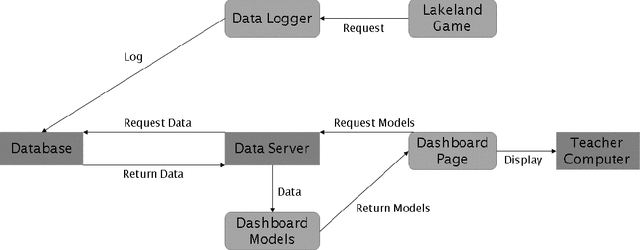
Educational games are an increasingly popular teaching tool in modern classrooms. However, the development of complementary tools for teachers facilitating classroom gameplay is lacking. We present the results of a participatory design process for a teacher-facing, real-time game data dashboard. This two-phase process included a workshop to elicit teachers' requirements for such a tool, and a pilot study of our dashboard prototype. We analyze post-gameplay survey and interview data to understand teachers' experiences with the tool in terms of evidence of co-design, feasibility, and effectiveness. Our results indicate the participatory design yielded a tool both useful for and usable by teachers within the context of a real class gameplay session. We advocate for the continued development of data-driven teacher tools to improve the effectiveness of games deployed in the classroom.