 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Why (and When) does Local SGD Generalize Better than SGD?
Mar 02, 2023
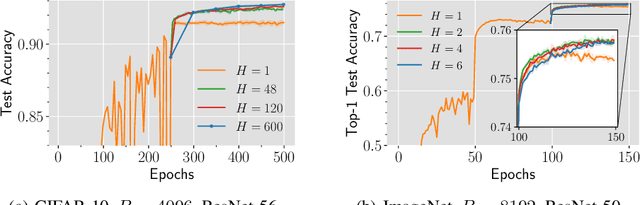
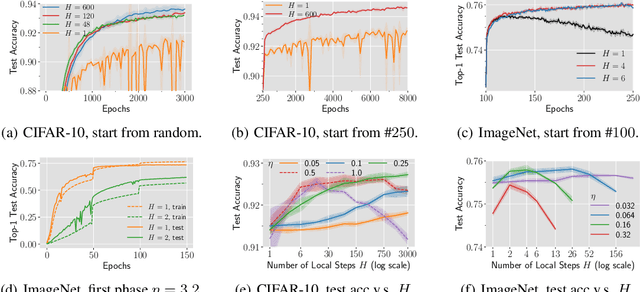
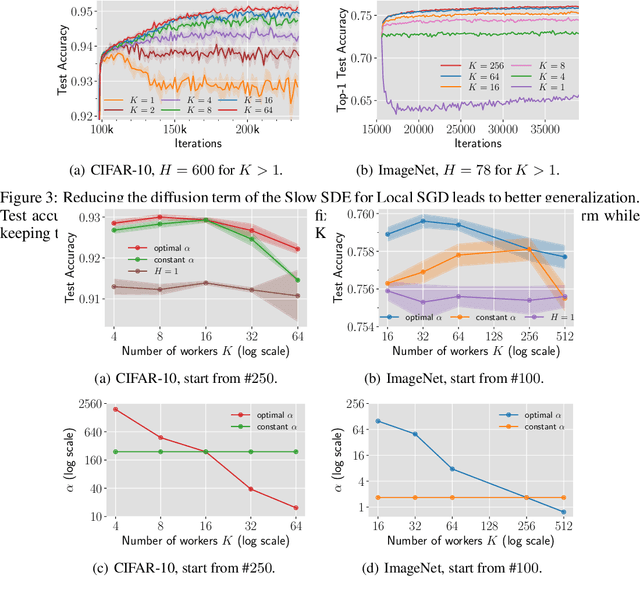
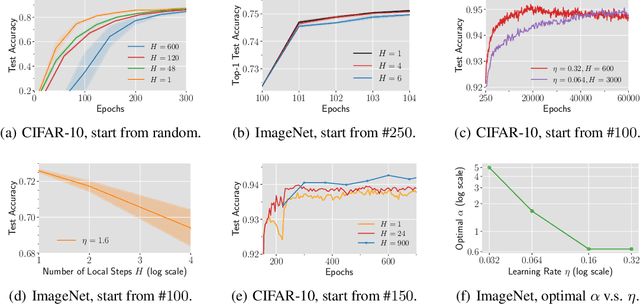
Local SGD is a communication-efficient variant of SGD for large-scale training, where multiple GPUs perform SGD independently and average the model parameters periodically. It has been recently observed that Local SGD can not only achieve the design goal of reducing the communication overhead but also lead to higher test accuracy than the corresponding SGD baseline (Lin et al., 2020b), though the training regimes for this to happen are still in debate (Ortiz et al., 2021). This paper aims to understand why (and when) Local SGD generalizes better based on Stochastic Differential Equation (SDE) approximation. The main contributions of this paper include (i) the derivation of an SDE that captures the long-term behavior of Local SGD in the small learning rate regime, showing how noise drives the iterate to drift and diffuse after it has reached close to the manifold of local minima, (ii) a comparison between the SDEs of Local SGD and SGD, showing that Local SGD induces a stronger drift term that can result in a stronger effect of regularization, e.g., a faster reduction of sharpness, and (iii) empirical evidence validating that having a small learning rate and long enough training time enables the generalization improvement over SGD but removing either of the two conditions leads to no improvement.
AugNet: Dynamic Test-Time Augmentation via Differentiable Functions
Dec 09, 2022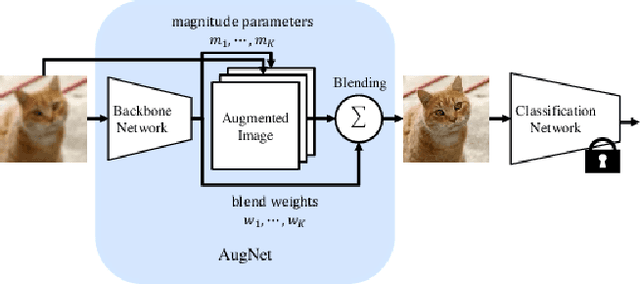
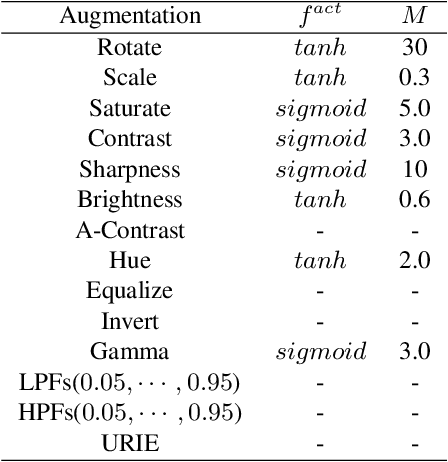
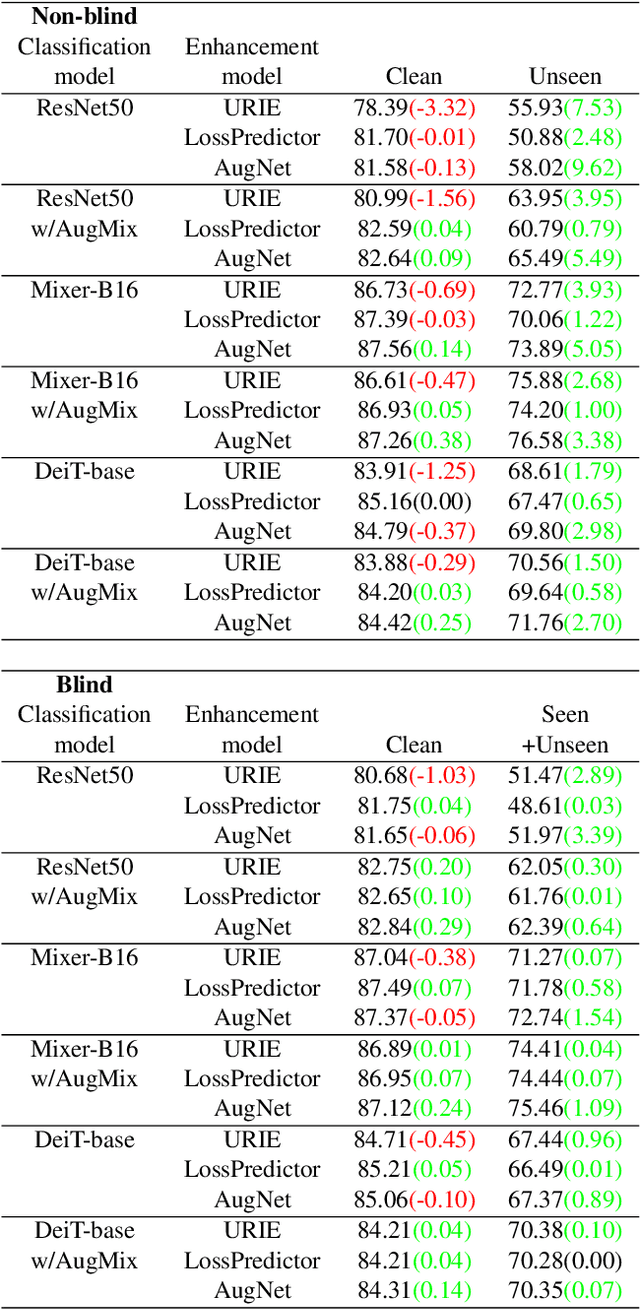
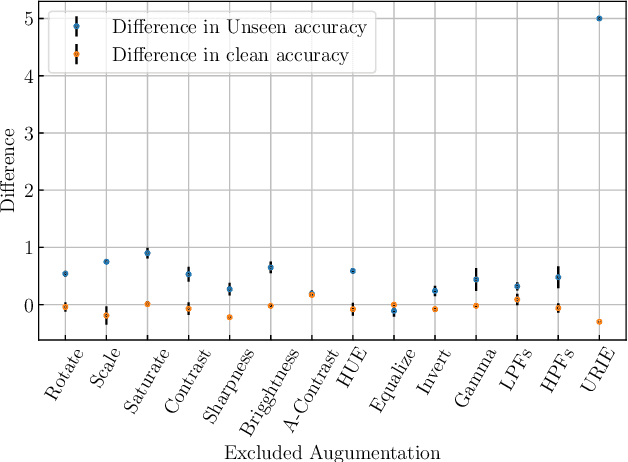
Distribution shifts, which often occur in the real world, degrade the accuracy of deep learning systems, and thus improving robustness is essential for practical applications. To improve robustness, we study an image enhancement method that generates recognition-friendly images without retraining the recognition model. We propose a novel image enhancement method, AugNet, which is based on differentiable data augmentation techniques and generates a blended image from many augmented images to improve the recognition accuracy under distribution shifts. In addition to standard data augmentations, AugNet can also incorporate deep neural network-based image transformation, which further improves the robustness. Because AugNet is composed of differentiable functions, AugNet can be directly trained with the classification loss of the recognition model. AugNet is evaluated on widely used image recognition datasets using various classification models, including Vision Transformer and MLP-Mixer. AugNet improves the robustness with almost no reduction in classification accuracy for clean images, which is a better result than the existing methods. Furthermore, we show that interpretation of distribution shifts using AugNet and retraining based on that interpretation can greatly improve robustness.
VA-DepthNet: A Variational Approach to Single Image Depth Prediction
Feb 15, 2023
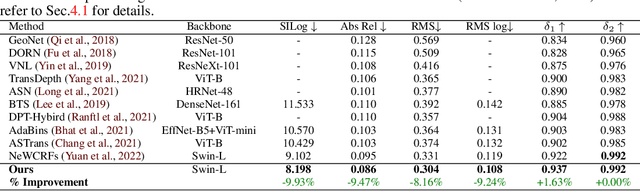
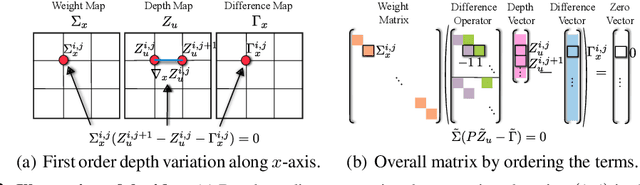

We introduce VA-DepthNet, a simple, effective, and accurate deep neural network approach for the single-image depth prediction (SIDP) problem. The proposed approach advocates using classical first-order variational constraints for this problem. While state-of-the-art deep neural network methods for SIDP learn the scene depth from images in a supervised setting, they often overlook the invaluable invariances and priors in the rigid scene space, such as the regularity of the scene. The paper's main contribution is to reveal the benefit of classical and well-founded variational constraints in the neural network design for the SIDP task. It is shown that imposing first-order variational constraints in the scene space together with popular encoder-decoder-based network architecture design provides excellent results for the supervised SIDP task. The imposed first-order variational constraint makes the network aware of the depth gradient in the scene space, i.e., regularity. The paper demonstrates the usefulness of the proposed approach via extensive evaluation and ablation analysis over several benchmark datasets, such as KITTI, NYU Depth V2, and SUN RGB-D. The VA-DepthNet at test time shows considerable improvements in depth prediction accuracy compared to the prior art and is accurate also at high-frequency regions in the scene space. At the time of writing this paper, our method -- labeled as VA-DepthNet, when tested on the KITTI depth-prediction evaluation set benchmarks, shows state-of-the-art results, and is the top-performing published approach.
Time-Limited Waveforms with Minimum Time Broadening for the Nonlinear Schrödinger Channel
Jun 22, 2022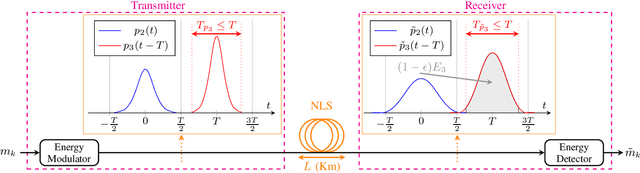
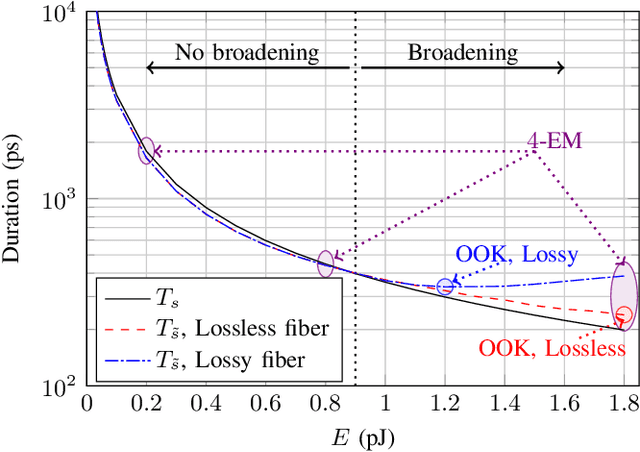
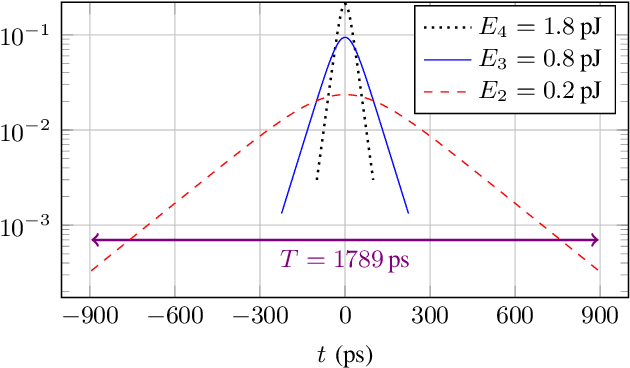
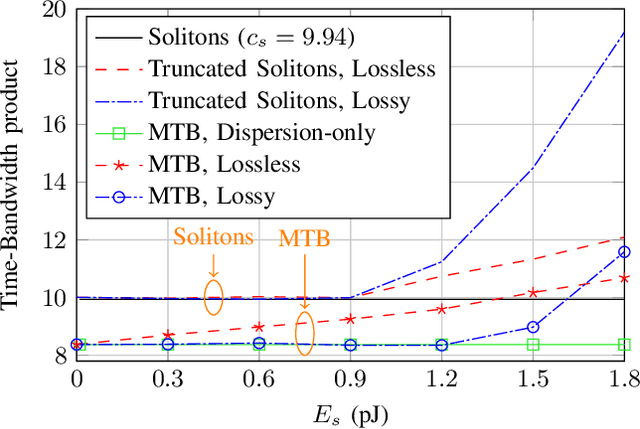
Simple fiber optic communication systems can be implemented using energy modulation of isolated time-limited pulses. Fundamental solitons are one possible solution for such pulses which offer a fundamental advantage: their shape is not affected by fiber disperison and nonlinearity. Furthermore, a simple energy detector can be used at the receiver to detect the transmitted information. However, systems based on energy modulation of solitons are not competitive in terms of data rates. This is partly due to the fact that the effective time duration of a soliton depends on its chosen amplitude. In this paper, we propose to replace fundamental solitons by new time-limited waveforms that can be detected using an energy detector, and that are immune to fiber distortions. Our proposed solution relies on the prolate spheroidal wave functions and a numerical optimization routine. Time-limited waveforms that undergo minimum time broadening along an optical fiber are obtained and shown to outperform fundamental solitons. In the case of binary transmission and a single span of fiber, we report rate increases of 33.8% and 12% over lossy and lossless fibers, respectively. Furthermore, we show that the transmission rate of the proposed system increases as the number of used energy levels increases, which is not the case for fundamental solitons due to their effective time-amplitude constraint. For example, rate increases of 164% and 70% over lossy and lossless fibers respectively are reported when using four energy levels.
Efficient Enumeration of Markov Equivalent DAGs
Jan 28, 2023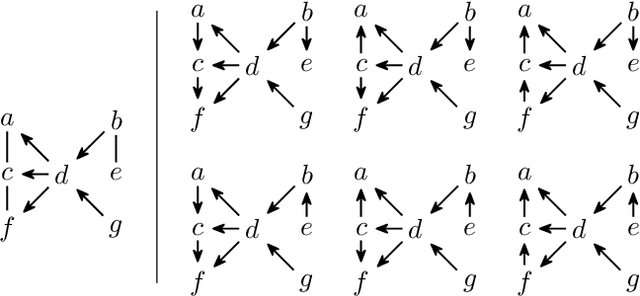
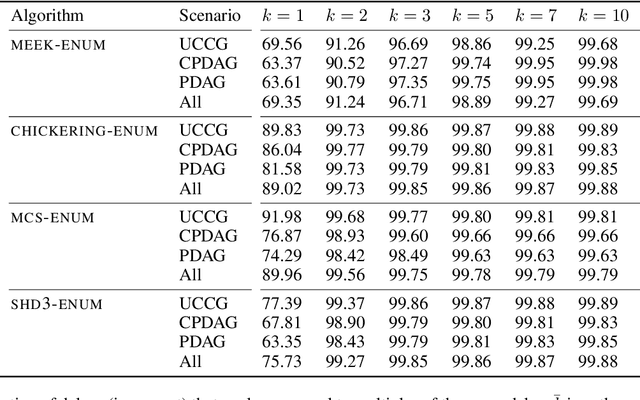
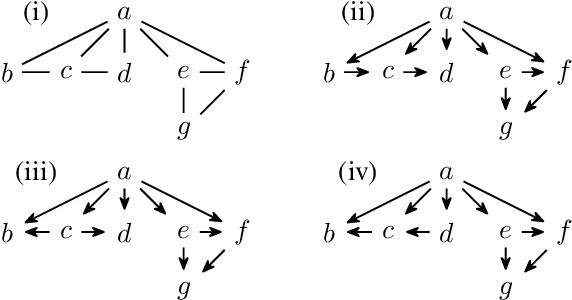
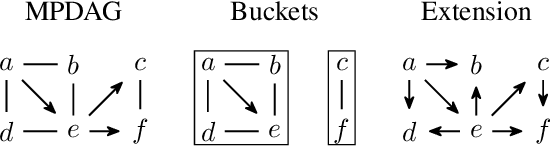
Enumerating the directed acyclic graphs (DAGs) of a Markov equivalence class (MEC) is an important primitive in causal analysis. The central resource from the perspective of computational complexity is the delay, that is, the time an algorithm that lists all members of the class requires between two consecutive outputs. Commonly used algorithms for this task utilize the rules proposed by Meek (1995) or the transformational characterization by Chickering (1995), both resulting in superlinear delay. In this paper, we present the first linear-time delay algorithm. On the theoretical side, we show that our algorithm can be generalized to enumerate DAGs represented by models that incorporate background knowledge, such as MPDAGs; on the practical side, we provide an efficient implementation and evaluate it in a series of experiments. Complementary to the linear-time delay algorithm, we also provide intriguing insights into Markov equivalence itself: All members of an MEC can be enumerated such that two successive DAGs have structural Hamming distance at most three.
Approximate Extraction of Late-Time Returns via Morphological Component Analysis
Aug 11, 2022
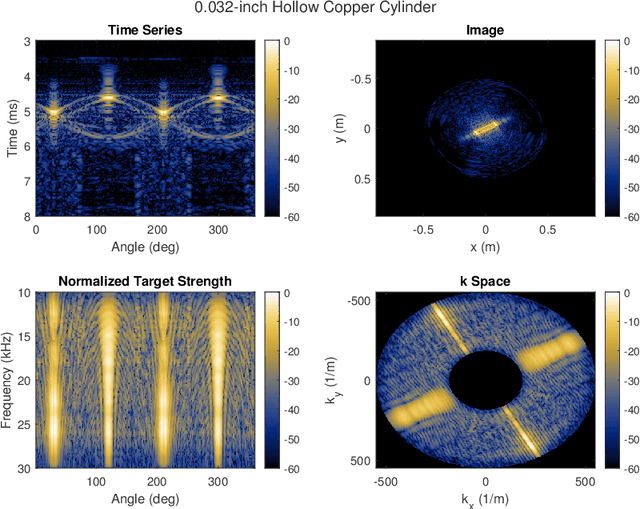
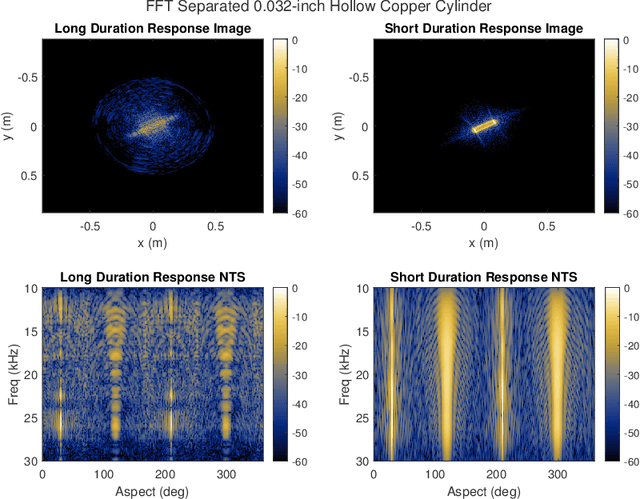
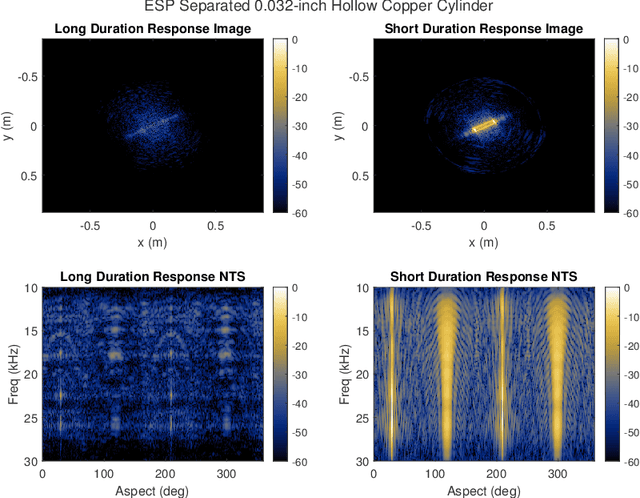
A fundamental challenge in acoustic data processing is to separate a measured time series into relevant phenomenological components. A given measurement is typically assumed to be an additive mixture of myriad signals plus noise whose separation forms an ill-posed inverse problem. In the setting of sensing elastic objects using active sonar, we wish to separate the early-time returns (e.g., returns from the object's exterior geometry) from late-time returns caused by elastic or compressional wave coupling. Under the framework of Morphological Component Analysis (MCA), we compare two separation models using the short-duration and long-duration responses as a proxy for early-time and late-time returns. Results are computed for Stanton's elastic cylinder model as well as on experimental data taken from an in-Air circular Synthetic Aperture Sonar (AirSAS) system, whose separated time series are formed into imagery. We find that MCA can be used to separate early and late-time responses in both cases without the use of time-gating. The separation process is demonstrated to be robust to noise and compatible with AirSAS image reconstruction. The best separation results are obtained with a flexible, but computationally intensive, frame based signal model, while a faster Fourier Transform based method is shown to have competitive performance.
ONE PIECE: One Patchwork In Effectively Combined Extraction for grasp
Mar 06, 2023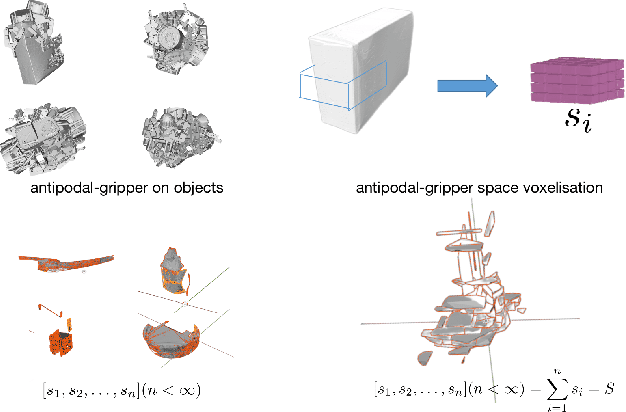

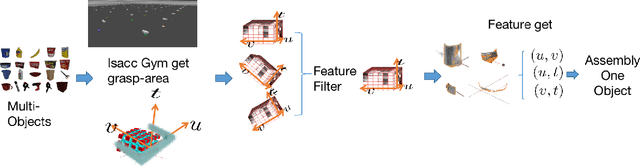
For grasp network algorithms, generating grasp datasets for a large number of 3D objects is a crucial task. However, generating grasp datasets for hundreds of objects can be very slow and consume a lot of storage resources, which hinders algorithm iteration and promotion. For point cloud grasp network algorithms, the network input is essentially the internal point cloud of the grasp area that intersects with the object in the gripper coordinate system. Due to the existence of a large number of completely consistent gripper area point clouds based on the gripper coordinate system in the grasp dataset generated for hundreds of objects, it is possible to remove the consistent gripper area point clouds from many objects and assemble them into a single object to generate the grasp dataset, thus replacing the enormous workload of generating grasp datasets for hundreds of objects. We propose a new approach to map the repetitive features of a large number of objects onto a finite set.To this end, we propose a method for extracting the gripper area point cloud that intersects with the object from the simulator and design a gripper feature filter to remove the shape-repeated gripper space area point clouds, and then assemble them into a single object. The experimental results show that the time required to generate the new object grasp dataset is greatly reduced compared to generating the grasp dataset for hundreds of objects, and it performs well in real machine grasping experiments. We will release the data and tools after the paper is accepted.
q-Learning in Continuous Time
Jul 02, 2022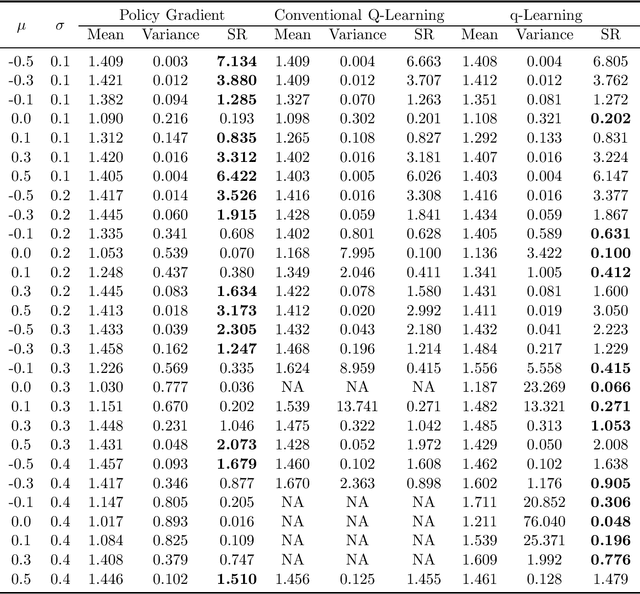
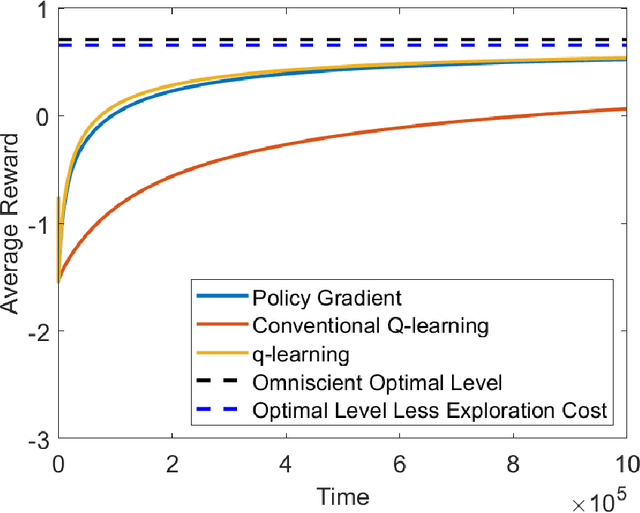
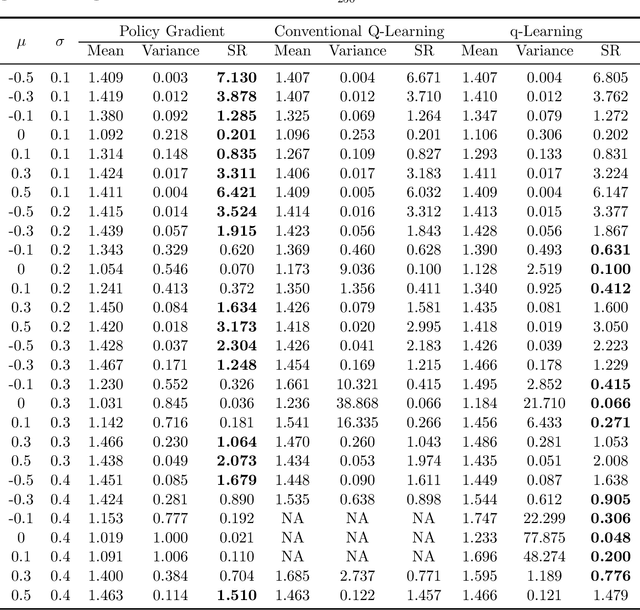
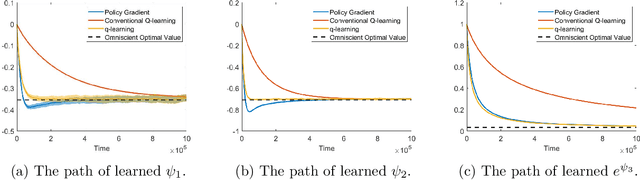
We study the continuous-time counterpart of Q-learning for reinforcement learning (RL) under the entropy-regularized, exploratory diffusion process formulation introduced by Wang et al. (2020) As the conventional (big) Q-function collapses in continuous time, we consider its first-order approximation and coin the term "(little) q-function". This function is related to the instantaneous advantage rate function as well as the Hamiltonian. We develop a "q-learning" theory around the q-function that is independent of time discretization. Given a stochastic policy, we jointly characterize the associated q-function and value function by martingale conditions of certain stochastic processes. We then apply the theory to devise different actor-critic algorithms for solving underlying RL problems, depending on whether or not the density function of the Gibbs measure generated from the q-function can be computed explicitly. One of our algorithms interprets the well-known Q-learning algorithm SARSA, and another recovers a policy gradient (PG) based continuous-time algorithm proposed in Jia and Zhou (2021). Finally, we conduct simulation experiments to compare the performance of our algorithms with those of PG-based algorithms in Jia and Zhou (2021) and time-discretized conventional Q-learning algorithms.
A Kubernetes-Based Edge Architecture for Controlling the Trajectory of a Resource-Constrained Aerial Robot by Enabling Model Predictive Control
Jan 31, 2023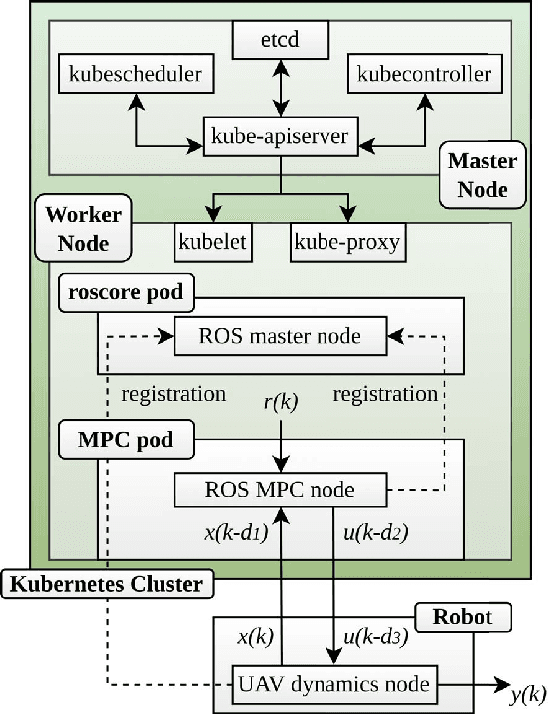

In recent years, cloud and edge architectures have gained tremendous focus for offloading computationally heavy applications. From machine learning and Internet of Thing (IOT) to industrial procedures and robotics, cloud computing have been used extensively for data processing and storage purposes, thanks to its "infinite" resources. On the other hand, cloud computing is characterized by long time delays due to the long distance between the cloud servers and the machine requesting the resources. In contrast, edge computing provides almost real-time services since edge servers are located significantly closer to the source of data. This capability sets edge computing as an ideal option for real-time applications, like high level control, for resource-constrained platforms. In order to utilize the edge resources, several technologies, with basic ones as containers and orchestrators like Kubernetes, have been developed to provide an environment with many features, based on each application's requirements. In this context, this works presents the implementation and evaluation of a novel edge architecture based on Kubernetes orchestration for controlling the trajectory of a resource-constrained Unmanned Aerial Vehicle (UAV) by enabling Model Predictive Control (MPC).
* 6 pages, 6 figures, conference article, CSCC 2022
Deep Learning Enabled Time-Lapse 3D Cell Analysis
Aug 17, 2022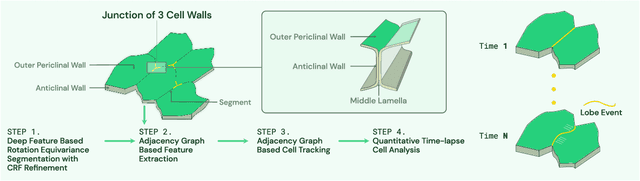
This paper presents a method for time-lapse 3D cell analysis. Specifically, we consider the problem of accurately localizing and quantitatively analyzing sub-cellular features, and for tracking individual cells from time-lapse 3D confocal cell image stacks. The heterogeneity of cells and the volume of multi-dimensional images presents a major challenge for fully automated analysis of morphogenesis and development of cells. This paper is motivated by the pavement cell growth process, and building a quantitative morphogenesis model. We propose a deep feature based segmentation method to accurately detect and label each cell region. An adjacency graph based method is used to extract sub-cellular features of the segmented cells. Finally, the robust graph based tracking algorithm using multiple cell features is proposed for associating cells at different time instances. Extensive experiment results are provided and demonstrate the robustness of the proposed method. The code is available on Github and the method is available as a service through the BisQue portal.