 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Legendre-Gauss Pseudospectral Collocation Method for Trajectory Optimization in Second Order Systems
Feb 17, 2023
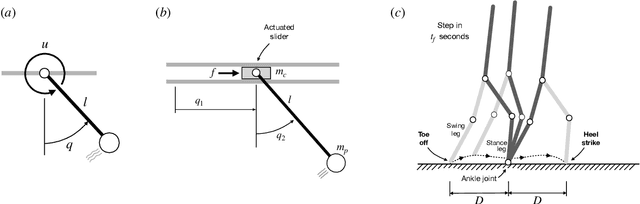
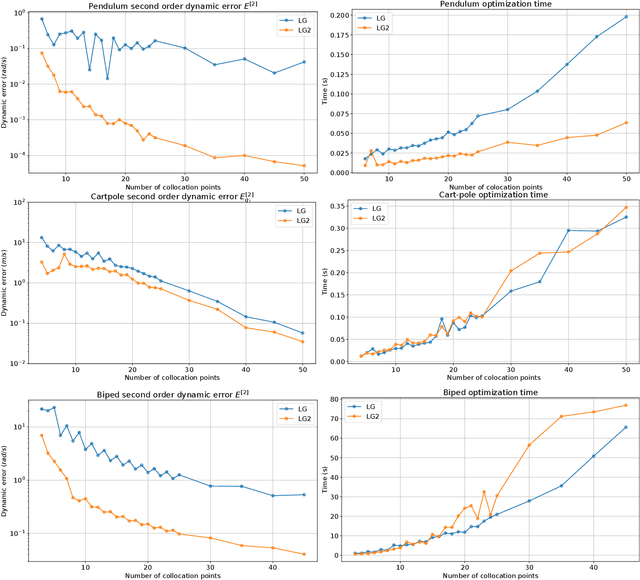
Pseudospectral collocation methods have proven to be powerful tools to solve optimal control problems. While these methods generally assume the dynamics is given in the first order form $\dot{x} = f (x, u, t)$, where x is the state and u is the control vector, robotic systems are typically governed by second order ODEs of the form $\ddot{q} = g(q, \dot{q}, u, t)$, where q is the configuration. To convert the second order ODE into a first order one, the usual approach is to introduce a velocity variable v and impose its coincidence with the time derivative of q. Lobatto methods grant this constraint by construction, as their polynomials describing the trajectory for v are the time derivatives of those for q, but the same cannot be said for the Gauss and Radau methods. This is problematic for such methods, as then they cannot guarantee that $\ddot{q} = g(q, \dot{q}, u, t)$ at the collocation points. On their negative side, Lobatto methods cannot be used to solve initial value problems, as given the values of u at the collocation points they generate an overconstrained system of equations for the states. In this paper, we propose a Legendre-Gauss collocation method that retains the advantages of the usual Lobatto, Gauss, and Radau methods, while avoiding their shortcomings. The collocation scheme we propose is applicable to solve initial value problems, preserves the consistency between the polynomials for v and q, and ensures that $\ddot{q} = g(q, \dot{q}, u, t)$ at the collocation points.
* 6 pages, 2 figures, published at 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
A New Baseline for GreenAI: Finding the Optimal Sub-Network via Layer and Channel Pruning
Feb 17, 2023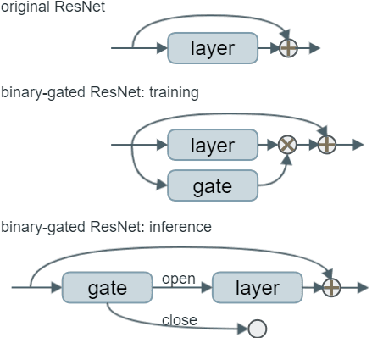
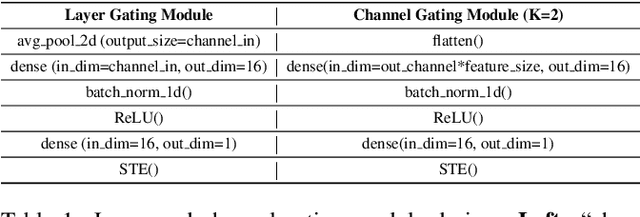
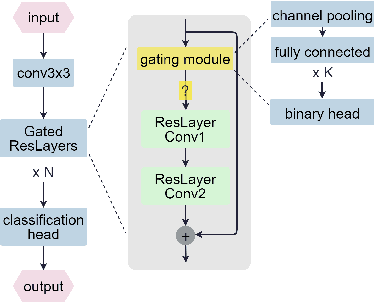
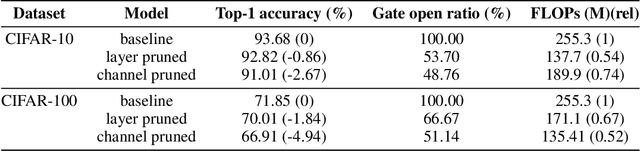
The concept of Green AI has been gaining attention within the deep learning community given the recent trend of ever larger and more complex neural network models. Some large models have billions of parameters causing the training time to take up to hundreds of GPU/TPU-days. The estimated energy consumption can be comparable to the annual total energy consumption of a standard household. Existing solutions to reduce the computational burden usually involve pruning the network parameters, however, they often create extra overhead either by iterative training and fine-tuning for static pruning or repeated computation of a dynamic pruning graph. We propose a new parameter pruning strategy that finds the effective group of lightweight sub-networks that minimizes the energy cost while maintaining comparable performances to the full network on given downstream tasks. Our proposed pruning scheme is green-oriented, such that the scheme only requires one-off training to discover the optimal static sub-networks by dynamic pruning methods. The pruning scheme consists of a lightweight, differentiable, and binarized gating module and novel loss functions to uncover sub-networks with user-defined sparsity. Our method enables pruning and training simultaneously, which saves energy in both the training and inference phases and avoids extra computational overhead from gating modules at inference time. Our results on CIFAR-10 and CIFAR-100 suggest that our scheme can remove ~50% of connections in deep networks with <1% reduction in classification accuracy. Compared to other related pruning methods, our method has a lower accuracy drop for equivalent reductions in computational costs.
Feature-Based Time-Series Analysis in R using the theft Package
Aug 17, 2022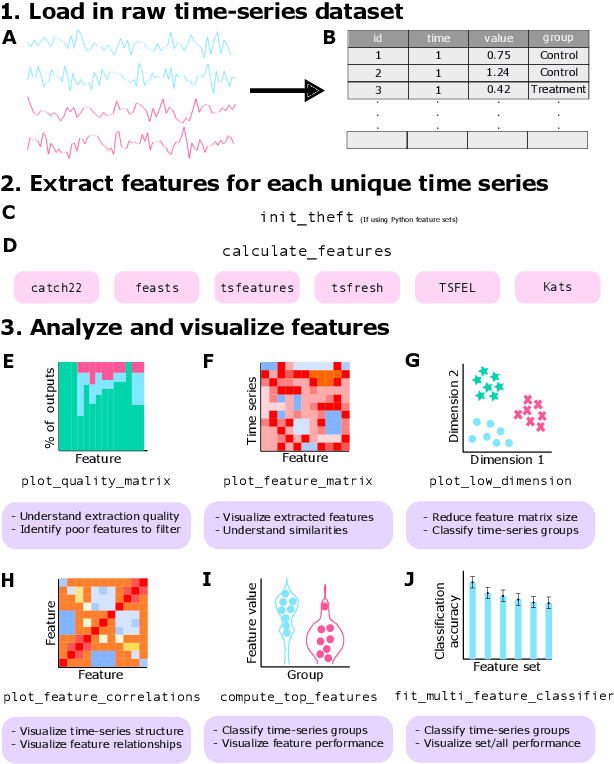
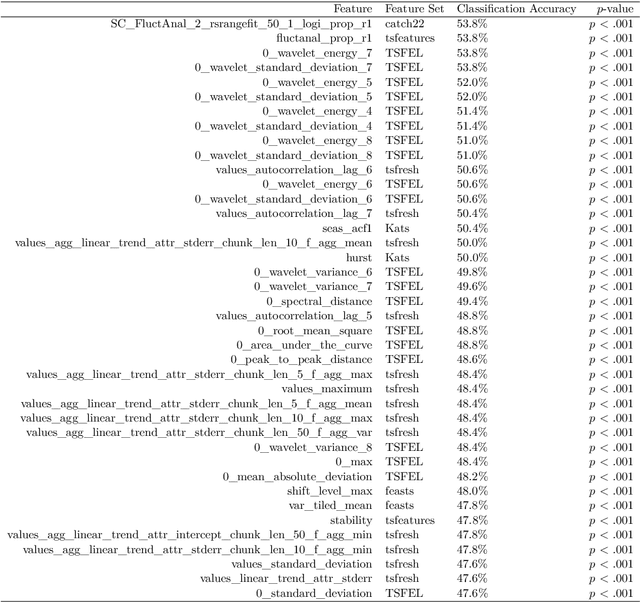
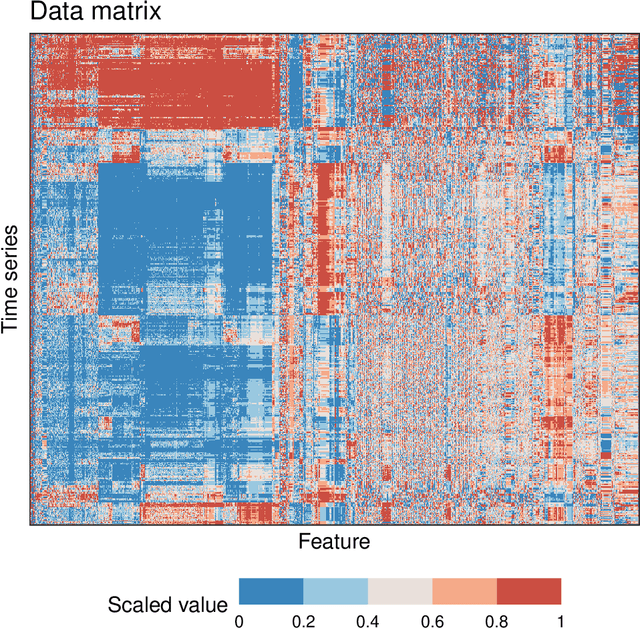
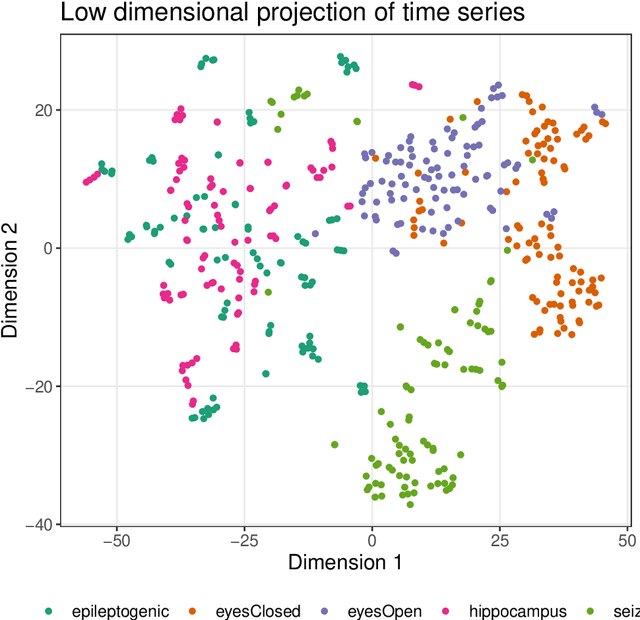
Time series are measured and analyzed across the sciences. One method of quantifying the structure of time series is by calculating a set of summary statistics or `features', and then representing a time series in terms of its properties as a feature vector. The resulting feature space is interpretable and informative, and enables conventional statistical learning approaches, including clustering, regression, and classification, to be applied to time-series datasets. Many open-source software packages for computing sets of time-series features exist across multiple programming languages, including catch22 (22 features: Matlab, R, Python, Julia), feasts (42 features: R), tsfeatures (63 features: R), Kats (40 features: Python), tsfresh (779 features: Python), and TSFEL (390 features: Python). However, there are several issues: (i) a singular access point to these packages is not currently available; (ii) to access all feature sets, users must be fluent in multiple languages; and (iii) these feature-extraction packages lack extensive accompanying methodological pipelines for performing feature-based time-series analysis, such as applications to time-series classification. Here we introduce a solution to these issues in an R software package called theft: Tools for Handling Extraction of Features from Time series. theft is a unified and extendable framework for computing features from the six open-source time-series feature sets listed above. It also includes a suite of functions for processing and interpreting the performance of extracted features, including extensive data-visualization templates, low-dimensional projections, and time-series classification operations. With an increasing volume and complexity of time-series datasets in the sciences and industry, theft provides a standardized framework for comprehensively quantifying and interpreting informative structure in time series.
Traffic State Estimation with Anisotropic Gaussian Processes from Vehicle Trajectories
Mar 04, 2023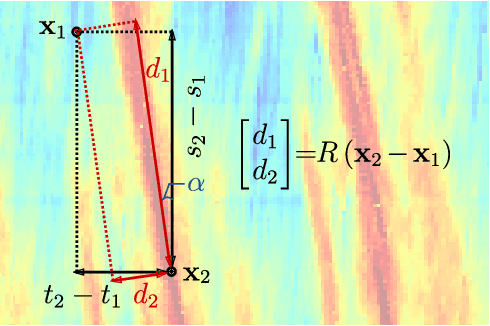
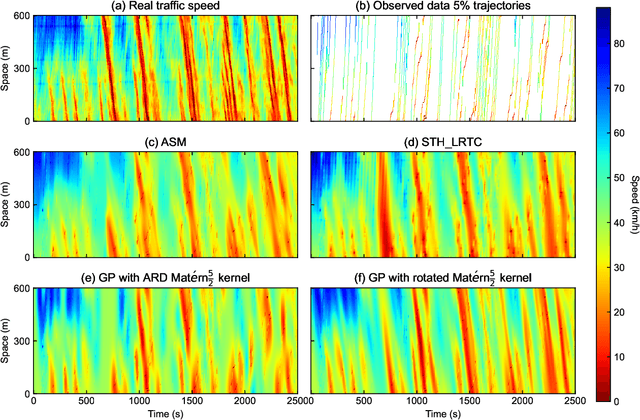
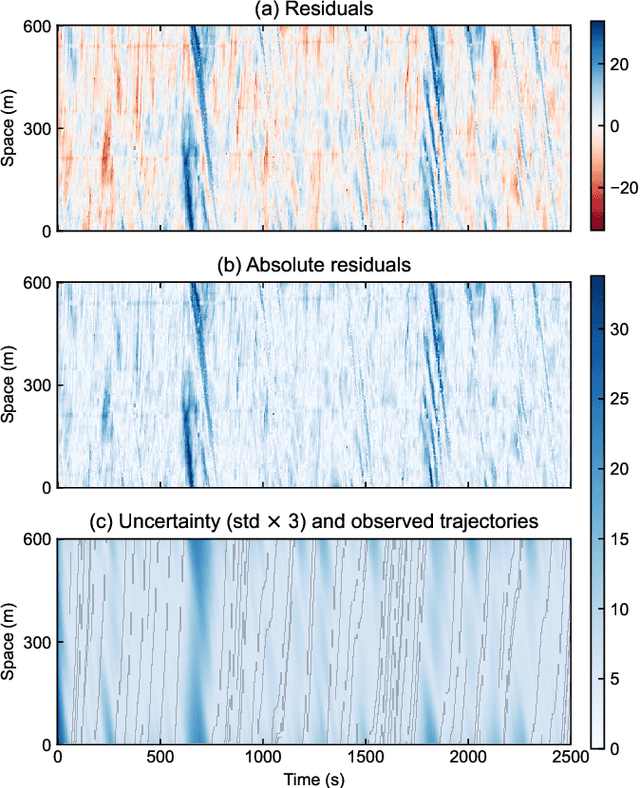
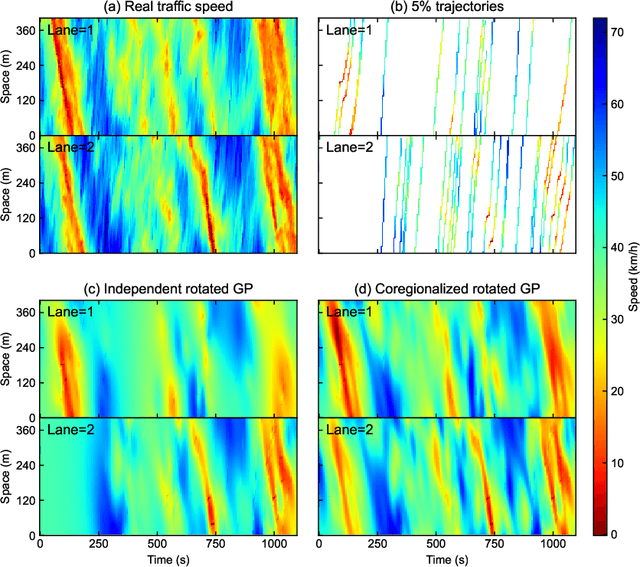
Accurately monitoring road traffic state and speed is crucial for various applications, including travel time prediction, traffic control, and traffic safety. However, the lack of sensors often results in incomplete traffic state data, making it challenging to obtain reliable information for decision-making. This paper proposes a novel method for imputing traffic state data using Gaussian processes (GP) to address this issue. We propose a kernel rotation re-parametrization scheme that transforms a standard isotropic GP kernel into an anisotropic kernel, which can better model the propagation of traffic waves in traffic flow data. This method can be applied to impute traffic state data from fixed sensors or probe vehicles. Moreover, the rotated GP method provides statistical uncertainty quantification for the imputed traffic state, making it more reliable. We also extend our approach to a multi-output GP, which allows for simultaneously estimating the traffic state for multiple lanes. We evaluate our method using real-world traffic data from the Next Generation simulation (NGSIM) and HighD programs. Considering current and future mixed traffic of connected vehicles (CVs) and human-driven vehicles (HVs), we experiment with the traffic state estimation scheme from 5% to 50% available trajectories, mimicking different CV penetration rates in a mixed traffic environment. Results show that our method outperforms state-of-the-art methods in terms of estimation accuracy, efficiency, and robustness.
Improving the quality of dental crown using a Transformer-based method
Mar 04, 2023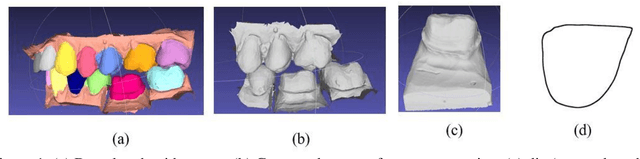
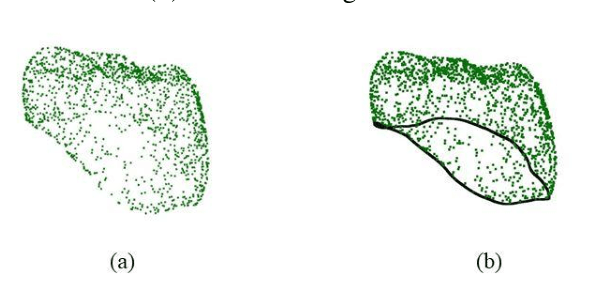

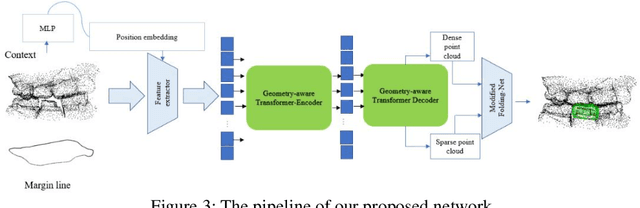
Designing a synthetic crown is a time-consuming, inconsistent, and labor-intensive process. In this work, we present a fully automatic method that not only learns human design dental crowns, but also improves the consistency, functionality, and esthetic of the crowns. Following success in point cloud completion using the transformer-based network, we tackle the problem of the crown generation as a point-cloud completion around a prepared tooth. To this end, we use a geometry-aware transformer to generate dental crowns. Our main contribution is to add a margin line information to the network, as the accuracy of generating a precise margin line directly,determines whether the designed crown and prepared tooth are closely matched to allowappropriateadhesion.Using our ground truth crown, we can extract the margin line as a spline and sample the spline into 1000 points. We feed the obtained margin line along with two neighbor teeth of the prepared tooth and three closest teeth in the opposing jaw. We also add the margin line points to our ground truth crown to increase the resolution at the margin line. Our experimental results show an improvement in the quality of the designed crown when considering the actual context composed of the prepared tooth along with the margin line compared with a crown generated in an empty space as was done by other studies in the literature.
Fixed-point quantization aware training for on-device keyword-spotting
Mar 04, 2023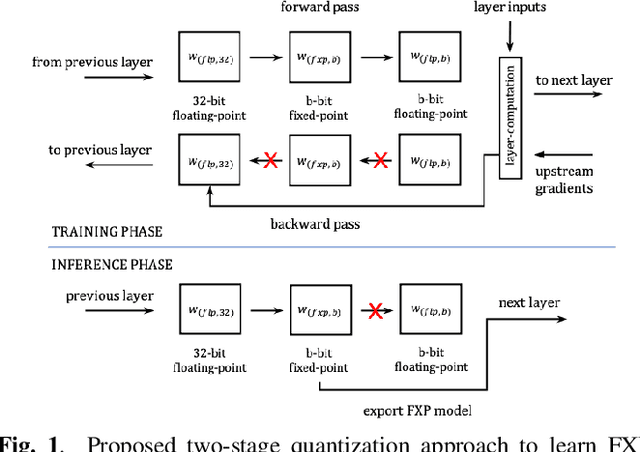

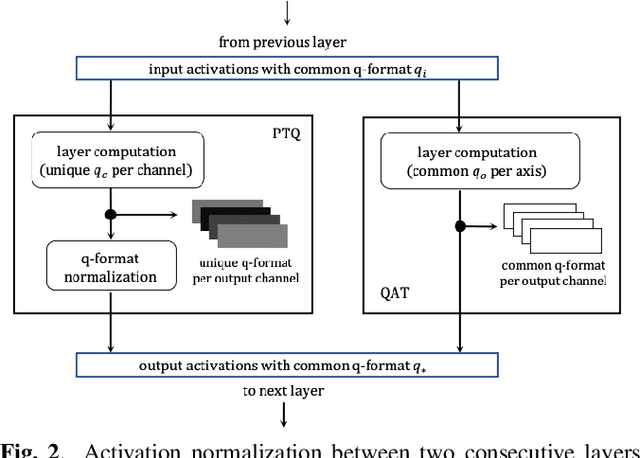
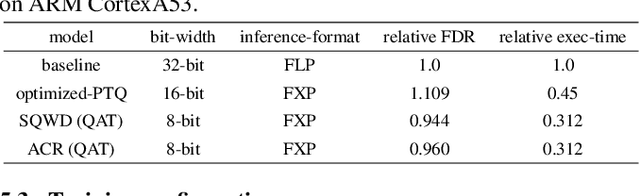
Fixed-point (FXP) inference has proven suitable for embedded devices with limited computational resources, and yet model training is continually performed in floating-point (FLP). FXP training has not been fully explored and the non-trivial conversion from FLP to FXP presents unavoidable performance drop. We propose a novel method to train and obtain FXP convolutional keyword-spotting (KWS) models. We combine our methodology with two quantization-aware-training (QAT) techniques - squashed weight distribution and absolute cosine regularization for model parameters, and propose techniques for extending QAT over transient variables, otherwise neglected by previous paradigms. Experimental results on the Google Speech Commands v2 dataset show that we can reduce model precision up to 4-bit with no loss in accuracy. Furthermore, on an in-house KWS dataset, we show that our 8-bit FXP-QAT models have a 4-6% improvement in relative false discovery rate at fixed false reject rate compared to full precision FLP models. During inference we argue that FXP-QAT eliminates q-format normalization and enables the use of low-bit accumulators while maximizing SIMD throughput to reduce user perceived latency. We demonstrate that we can reduce execution time by 68% without compromising KWS model's predictive performance or requiring model architectural changes. Our work provides novel findings that aid future research in this area and enable accurate and efficient models.
* 5 pages, 3 figures, 4 tables
ASAP: Accurate semantic segmentation for real time performance
Oct 04, 2022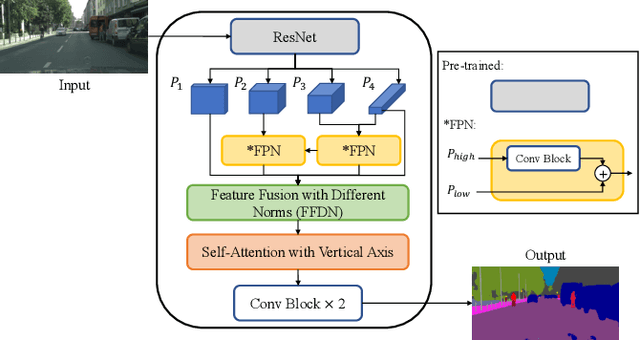
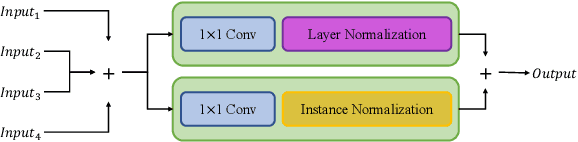
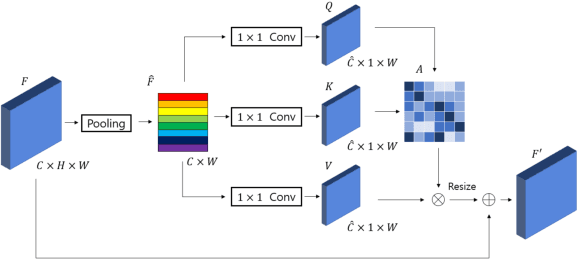

Feature fusion modules from encoder and self-attention module have been adopted in semantic segmentation. However, the computation of these modules is costly and has operational limitations in real-time environments. In addition, segmentation performance is limited in autonomous driving environments with a lot of contextual information perpendicular to the road surface, such as people, buildings, and general objects. In this paper, we propose an efficient feature fusion method, Feature Fusion with Different Norms (FFDN) that utilizes rich global context of multi-level scale and vertical pooling module before self-attention that preserves most contextual information while reducing the complexity of global context encoding in the vertical direction. By doing this, we could handle the properties of representation in global space and reduce additional computational cost. In addition, we analyze low performance in challenging cases including small and vertically featured objects. We achieve the mean Interaction of-union(mIoU) of 73.1 and the Frame Per Second(FPS) of 191, which are comparable results with state-of-the-arts on Cityscapes test datasets.
Spatio-Temporal Graph Neural Networks: A Survey
Jan 25, 2023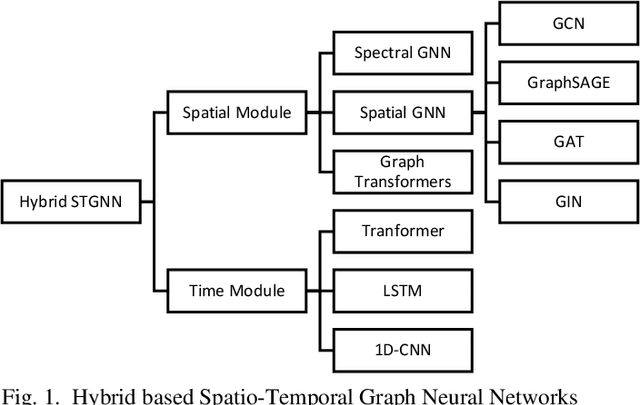
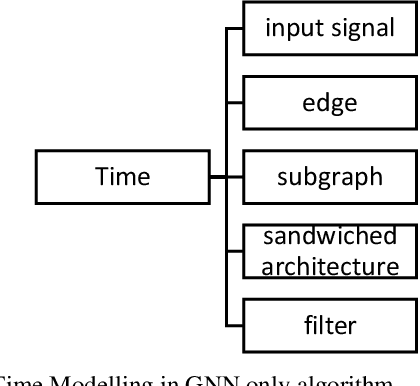
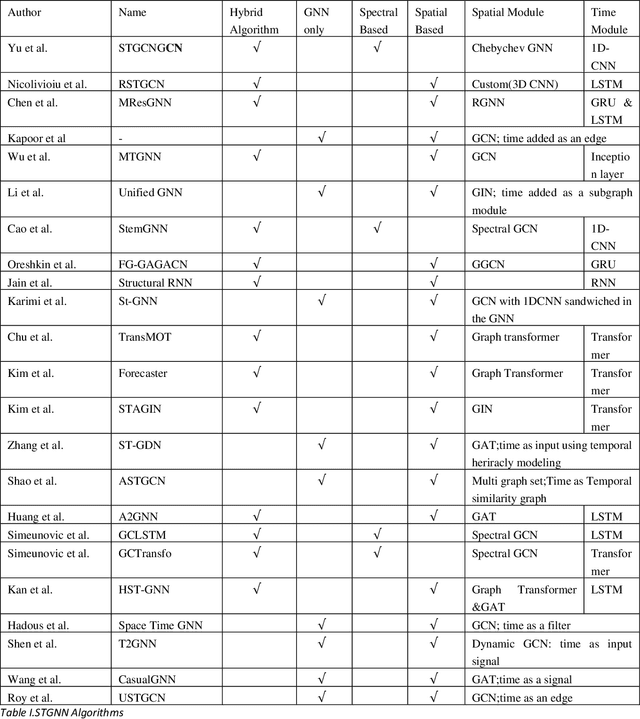
Graph Neural Networks have gained huge interest in the past few years. These powerful algorithms expanded deep learning models to non-Euclidean space and were able to achieve state of art performance in various applications including recommender systems and social networks. However, this performance is based on static graph structures assumption which limits the Graph Neural Networks performance when the data varies with time. Temporal Graph Neural Networks are extension of Graph Neural Networks that takes the time factor into account. Recently, various Temporal Graph Neural Network algorithms were proposed and achieved superior performance compared to other deep learning algorithms in several time dependent applications. This survey discusses interesting topics related to Spatio temporal Graph Neural Networks, including algorithms, application, and open challenges.
Learned Interferometric Imaging for the SPIDER Instrument
Jan 24, 2023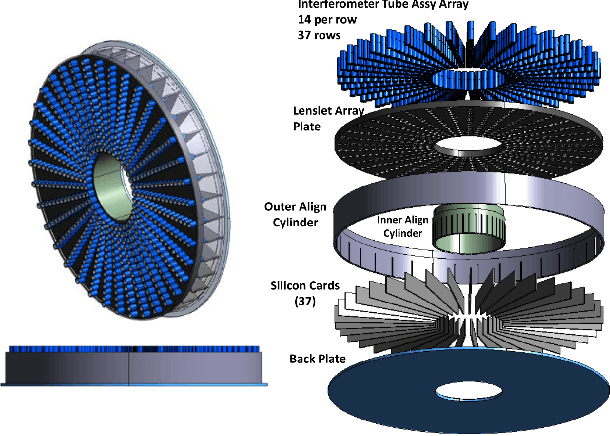

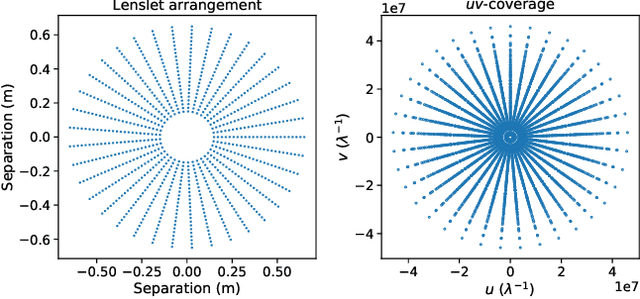
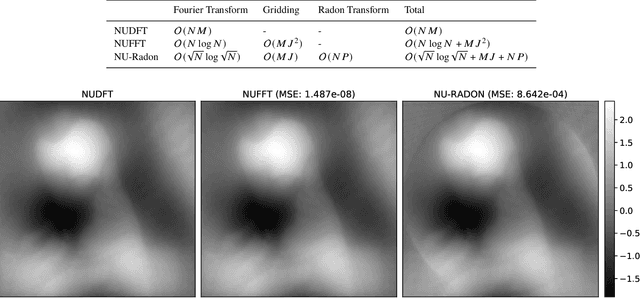
The Segmented Planar Imaging Detector for Electro-Optical Reconnaissance (SPIDER) is an optical interferometric imaging device that aims to offer an alternative to the large space telescope designs of today with reduced size, weight and power consumption. This is achieved through interferometric imaging. State-of-the-art methods for reconstructing images from interferometric measurements adopt proximal optimization techniques, which are computationally expensive and require handcrafted priors. In this work we present two data-driven approaches for reconstructing images from measurements made by the SPIDER instrument. These approaches use deep learning to learn prior information from training data, increasing the reconstruction quality, and significantly reducing the computation time required to recover images by orders of magnitude. Reconstruction time is reduced to ${\sim} 10$ milliseconds, opening up the possibility of real-time imaging with SPIDER for the first time. Furthermore, we show that these methods can also be applied in domains where training data is scarce, such as astronomical imaging, by leveraging transfer learning from domains where plenty of training data are available.
Searching Transferable Mixed-Precision Quantization Policy through Large Margin Regularization
Feb 14, 2023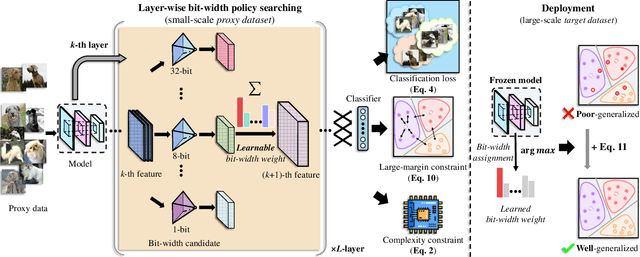
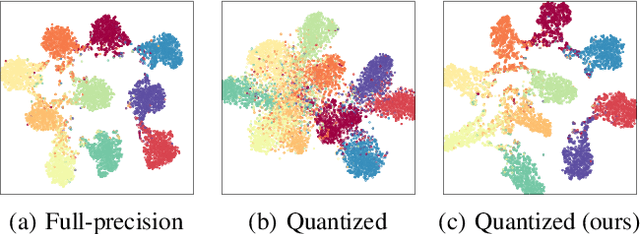
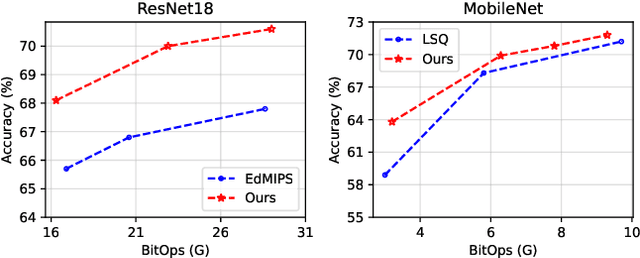
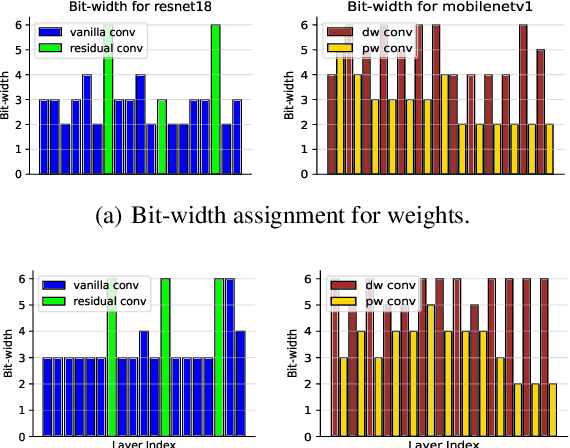
Mixed-precision quantization (MPQ) suffers from time-consuming policy search process (i.e., the bit-width assignment for each layer) on large-scale datasets (e.g., ISLVRC-2012), which heavily limits its practicability in real-world deployment scenarios. In this paper, we propose to search the effective MPQ policy by using a small proxy dataset for the model trained on a large-scale one. It breaks the routine that requires a consistent dataset at model training and MPQ policy search time, which can improve the MPQ searching efficiency significantly. However, the discrepant data distributions bring difficulties in searching for such a transferable MPQ policy. Motivated by the observation that quantization narrows the class margin and blurs the decision boundary, we search the policy that guarantees a general and dataset-independent property: discriminability of feature representations. Namely, we seek the policy that can robustly keep the intra-class compactness and inter-class separation. Our method offers several advantages, i.e., high proxy data utilization, no extra hyper-parameter tuning for approximating the relationship between full-precision and quantized model and high searching efficiency. We search high-quality MPQ policies with the proxy dataset that has only 4% of the data scale compared to the large-scale target dataset, achieving the same accuracy as searching directly on the latter, and improving the MPQ searching efficiency by up to 300 times.