 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast 3D Volumetric Image Reconstruction from 2D MRI Slices by Parallel Processing
Mar 16, 2023
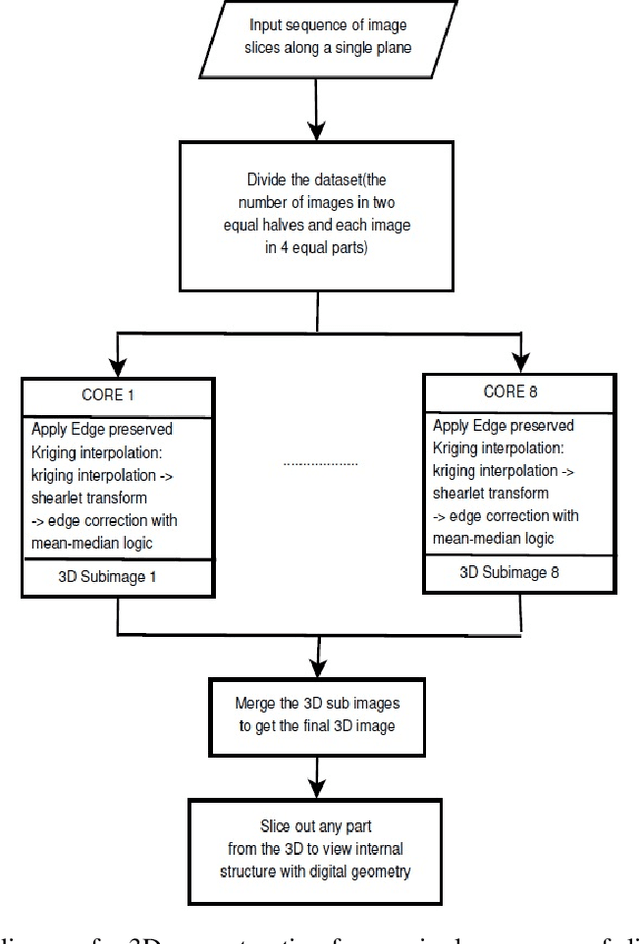
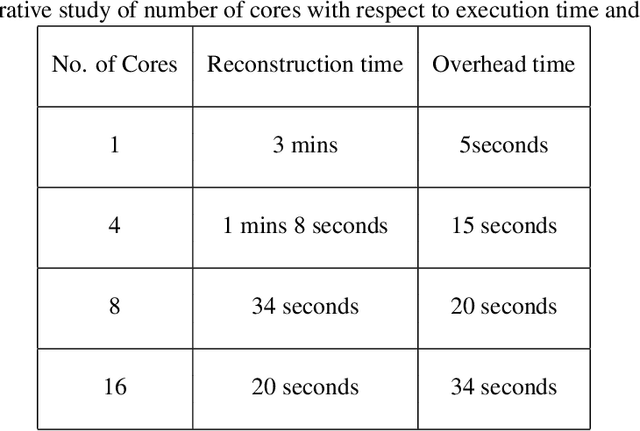
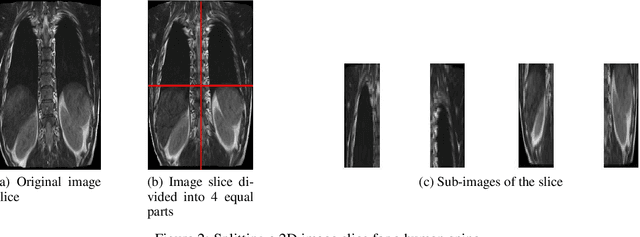
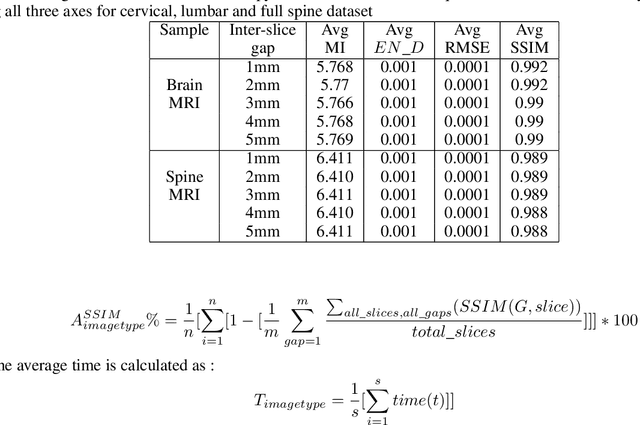
Magnetic Resonance Imaging (MRI) is a technology for non-invasive imaging of anatomical features in detail. It can help in functional analysis of organs of a specimen but it is very costly. In this work, methods for (i) virtual three-dimensional (3D) reconstruction from a single sequence of two-dimensional (2D) slices of MR images of a human spine and brain along a single axis, and (ii) generation of missing inter-slice data are proposed. Our approach helps in preserving the edges, shape, size, as well as the internal tissue structures of the object being captured. The sequence of original 2D slices along a single axis is divided into smaller equal sub-parts which are then reconstructed using edge preserved kriging interpolation to predict the missing slice information. In order to speed up the process of interpolation, we have used multiprocessing by carrying out the initial interpolation on parallel cores. From the 3D matrix thus formed, shearlet transform is applied to estimate the edges considering the 2D blocks along the $Z$ axis, and to minimize the blurring effect using a proposed mean-median logic. Finally, for visualization, the sub-matrices are merged into a final 3D matrix. Next, the newly formed 3D matrix is split up into voxels and marching cubes method is applied to get the approximate 3D image for viewing. To the best of our knowledge it is a first of its kind approach based on kriging interpolation and multiprocessing for 3D reconstruction from 2D slices, and approximately 98.89\% accuracy is achieved with respect to similarity metrics for image comparison. The time required for reconstruction has also been reduced by approximately 70\% with multiprocessing even for a large input data set compared to that with single core processing.
Event-based Human Pose Tracking by Spiking Spatiotemporal Transformer
Mar 16, 2023
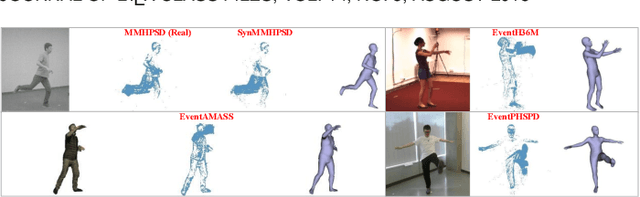

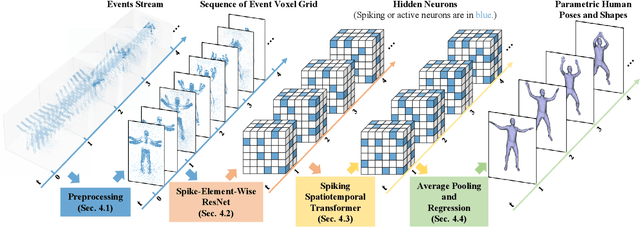
Event camera, as an emerging biologically-inspired vision sensor for capturing motion dynamics, presents new potential for 3D human pose tracking, or video-based 3D human pose estimation. However, existing works in pose tracking either require the presence of additional gray-scale images to establish a solid starting pose, or ignore the temporal dependencies all together by collapsing segments of event streams to form static image frames. Meanwhile, although the effectiveness of Artificial Neural Networks (ANNs, a.k.a. dense deep learning) has been showcased in many event-based tasks, the use of ANNs tends to neglect the fact that compared to the dense frame-based image sequences, the occurrence of events from an event camera is spatiotemporally much sparser. Motivated by the above mentioned issues, we present in this paper a dedicated end-to-end \textit{sparse deep learning} approach for event-based pose tracking: 1) to our knowledge this is the first time that 3D human pose tracking is obtained from events only, thus eliminating the need of accessing to any frame-based images as part of input; 2) our approach is based entirely upon the framework of Spiking Neural Networks (SNNs), which consists of Spike-Element-Wise (SEW) ResNet and our proposed spiking spatiotemporal transformer; 3) a large-scale synthetic dataset is constructed that features a broad and diverse set of annotated 3D human motions, as well as longer hours of event stream data, named SynEventHPD. Empirical experiments demonstrate the superiority of our approach in both performance and efficiency measures. For example, with comparable performance to the state-of-the-art ANNs counterparts, our approach achieves a computation reduction of 20\% in FLOPS. Our implementation is made available at https://github.com/JimmyZou/HumanPoseTracking_SNN and dataset will be released upon paper acceptance.
Spatio-Temporal Attention Network for Persistent Monitoring of Multiple Mobile Targets
Mar 11, 2023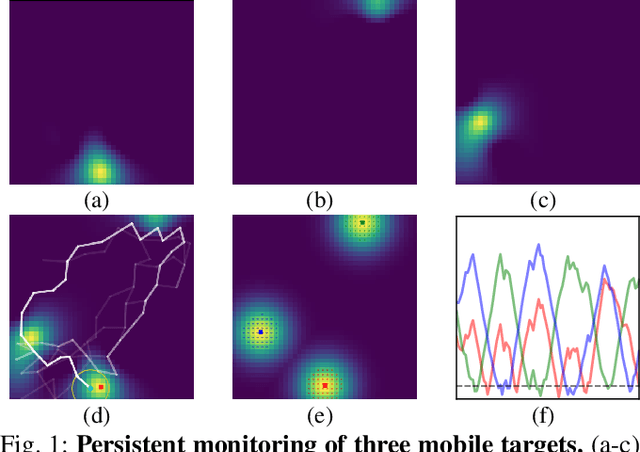
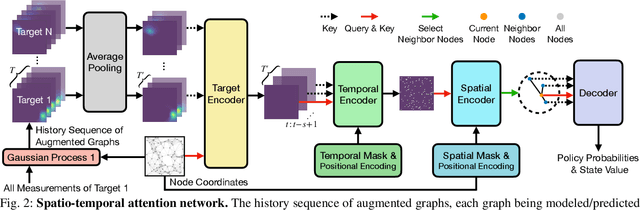
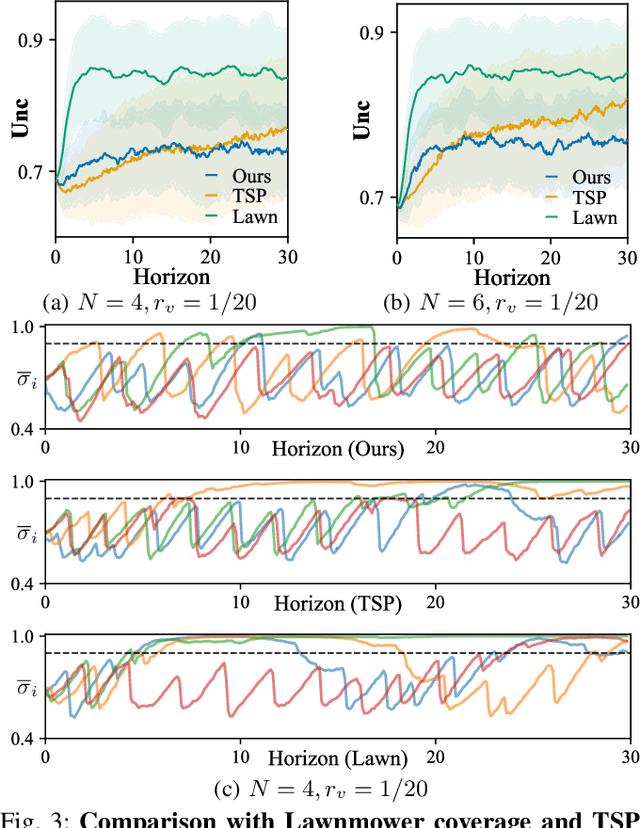
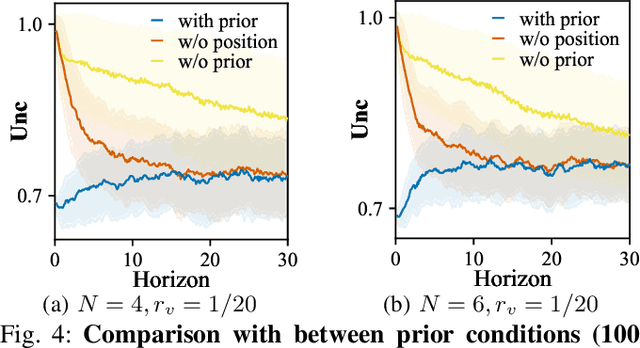
This work focuses on the persistent monitoring problem, where a set of targets moving based on an unknown model must be monitored by an autonomous mobile robot with a limited sensing range. To keep each target's position estimate as accurate as possible, the robot needs to adaptively plan its path to (re-)visit all the targets and update its belief from measurements collected along the way. In doing so, the main challenge is to strike a balance between exploitation, i.e., re-visiting previously-located targets, and exploration, i.e., finding new targets or re-acquiring lost ones. Encouraged by recent advances in deep reinforcement learning, we introduce an attention-based neural solution to the persistent monitoring problem, where the agent can learn the inter-dependencies between targets, i.e., their spatial and temporal correlations, conditioned on past measurements. This endows the agent with the ability to determine which target, time, and location to attend to across multiple scales, which we show also helps relax the usual limitations of a finite target set. We experimentally demonstrate that our method outperforms other baselines in terms of number of targets visits and average estimation error in complex environments. Finally, we implement and validate our model in a drone-based simulation experiment to monitor mobile ground targets in a high-fidelity simulator.
VCSE: Time-Domain Visual-Contextual Speaker Extraction Network
Oct 09, 2022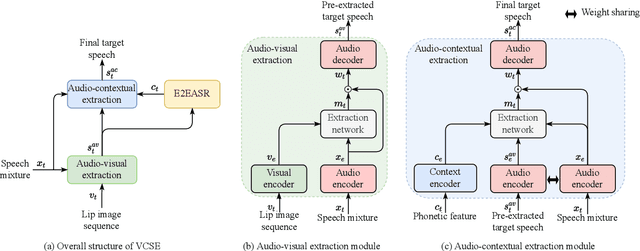
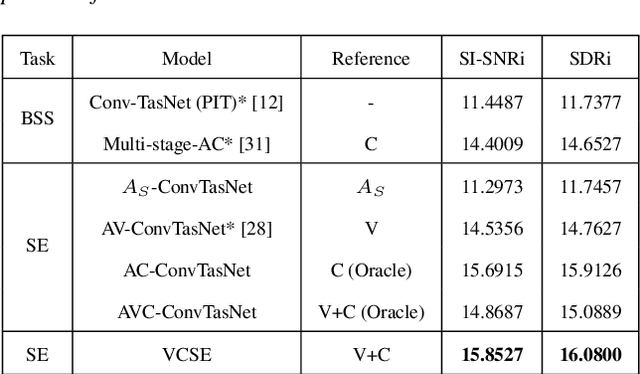
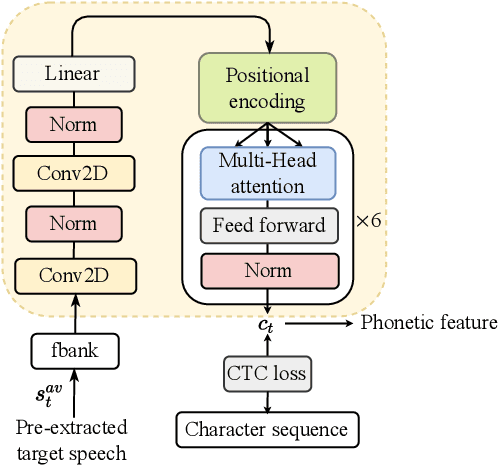
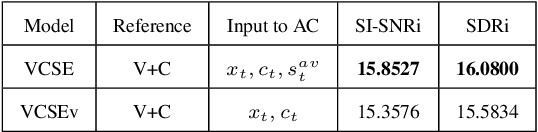
Speaker extraction seeks to extract the target speech in a multi-talker scenario given an auxiliary reference. Such reference can be auditory, i.e., a pre-recorded speech, visual, i.e., lip movements, or contextual, i.e., phonetic sequence. References in different modalities provide distinct and complementary information that could be fused to form top-down attention on the target speaker. Previous studies have introduced visual and contextual modalities in a single model. In this paper, we propose a two-stage time-domain visual-contextual speaker extraction network named VCSE, which incorporates visual and self-enrolled contextual cues stage by stage to take full advantage of every modality. In the first stage, we pre-extract a target speech with visual cues and estimate the underlying phonetic sequence. In the second stage, we refine the pre-extracted target speech with the self-enrolled contextual cues. Experimental results on the real-world Lip Reading Sentences 3 (LRS3) database demonstrate that our proposed VCSE network consistently outperforms other state-of-the-art baselines.
Achieving mouse-level strategic evasion performance using real-time computational planning
Nov 04, 2022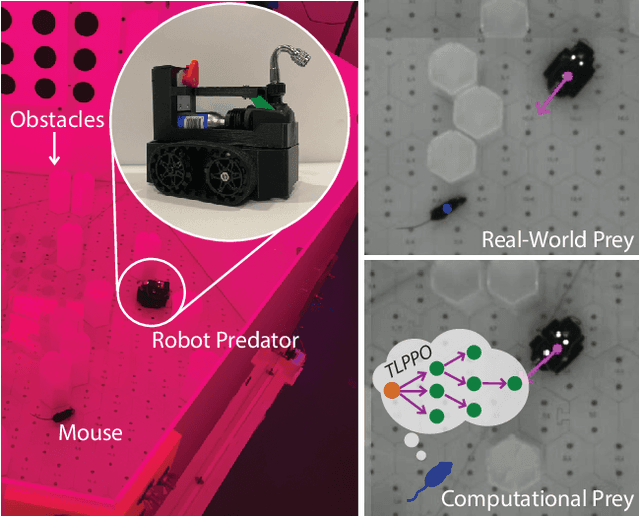
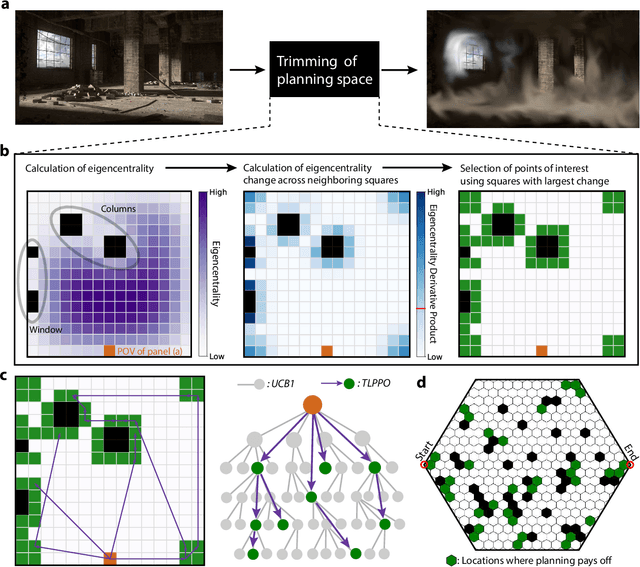
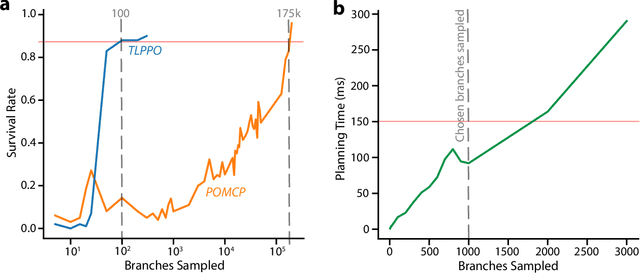
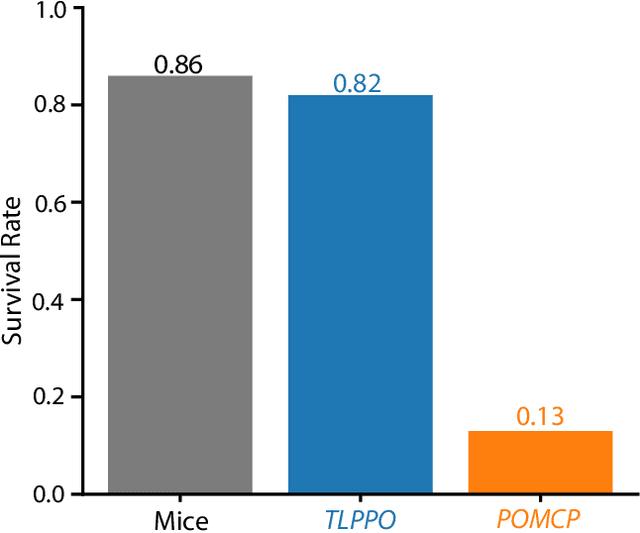
Planning is an extraordinary ability in which the brain imagines and then enacts evaluated possible futures. Using traditional planning models, computer scientists have attempted to replicate this capacity with some level of success but ultimately face a reoccurring limitation: as the plan grows in steps, the number of different possible futures makes it intractable to determine the right sequence of actions to reach a goal state. Based on prior theoretical work on how the ecology of an animal governs the value of spatial planning, we developed a more efficient biologically-inspired planning algorithm, TLPPO. This algorithm allows us to achieve mouselevel predator evasion performance with orders of magnitude less computation than a widespread algorithm for planning in the situations of partial observability that typify predator-prey interactions. We compared the performance of a real-time agent using TLPPO against the performance of live mice, all tasked with evading a robot predator. We anticipate these results will be helpful to planning algorithm users and developers, as well as to areas of neuroscience where robot-animal interaction can provide a useful approach to studying the basis of complex behaviors.
DCSF: Deep Convolutional Set Functions for Classification of Asynchronous Time Series
Aug 24, 2022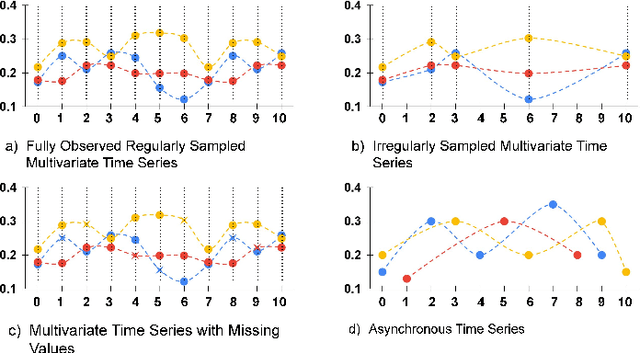
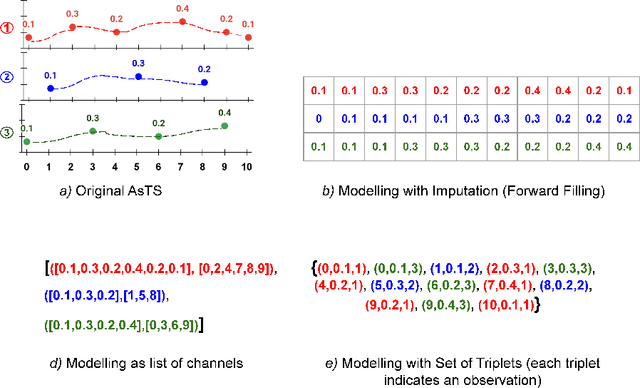

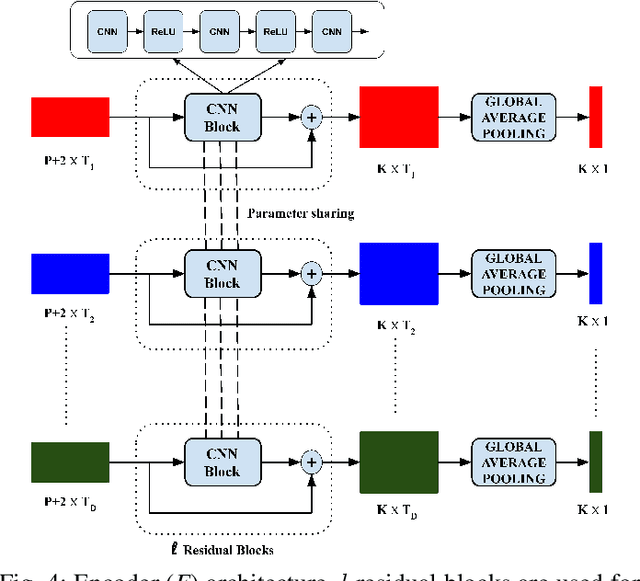
Asynchronous Time Series is a multivariate time series where all the channels are observed asynchronously-independently, making the time series extremely sparse when aligning them. We often observe this effect in applications with complex observation processes, such as health care, climate science, and astronomy, to name a few. Because of the asynchronous nature, they pose a significant challenge to deep learning architectures, which presume that the time series presented to them are regularly sampled, fully observed, and aligned with respect to time. This paper proposes a novel framework, that we call Deep Convolutional Set Functions (DCSF), which is highly scalable and memory efficient, for the asynchronous time series classification task. With the recent advancements in deep set learning architectures, we introduce a model that is invariant to the order in which time series' channels are presented to it. We explore convolutional neural networks, which are well researched for the closely related problem-classification of regularly sampled and fully observed time series, for encoding the set elements. We evaluate DCSF for AsTS classification, and online (per time point) AsTS classification. Our extensive experiments on multiple real-world and synthetic datasets verify that the suggested model performs substantially better than a range of state-of-the-art models in terms of accuracy and run time.
Distortion Minimization with Age of Information and Cost Constraints
Mar 01, 2023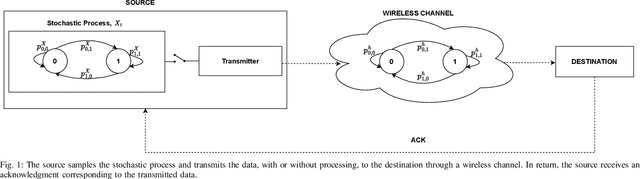
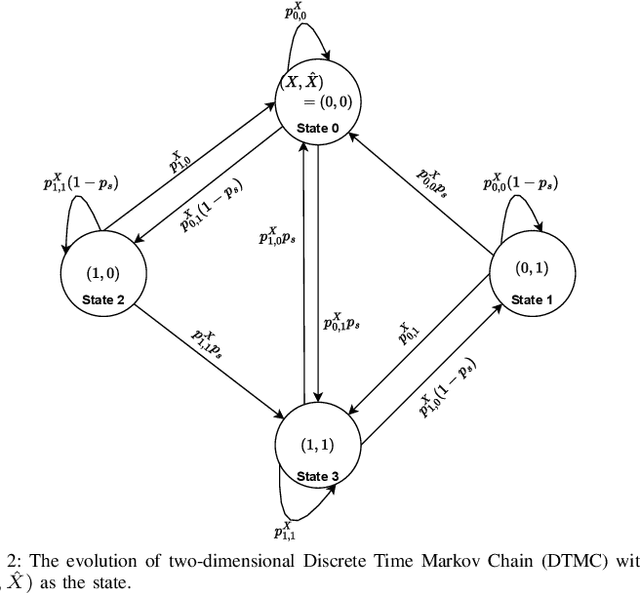
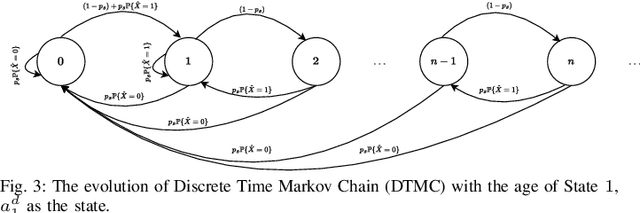
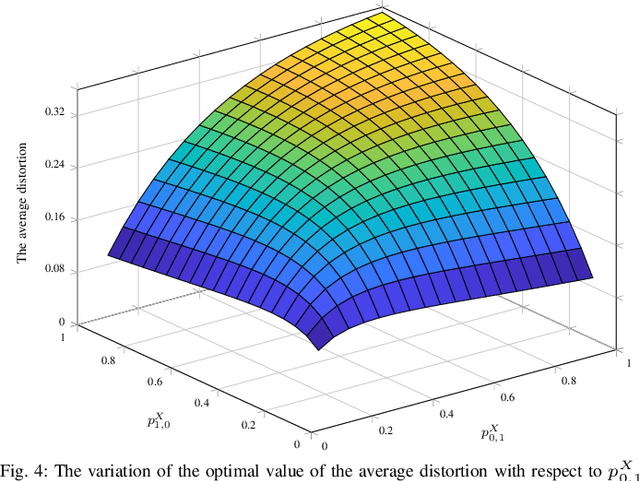
We consider a source monitoring a stochastic process with a transmitter to transmit timely information through a wireless ON/OFF channel to a destination. We assume that once the source samples the data, the sampled data has to be processed to identify the state of the stochastic process. The processing can take place either at the source before transmission or after transmission at the destination. The objective is to minimize the distortion while keeping the age of information (AoI) that measures the timeliness of information under a certain threshold. We use a stationary randomized policy (SRP) framework to solve the formulated problem. We show that the two-dimensional discrete-time Markov chain considering the AoI and instantaneous distortion as the state is lumpable and we obtain the expression for the expected AoI under the SRP.
PCF: ECAPA-TDNN with Progressive Channel Fusion for Speaker Verification
Mar 01, 2023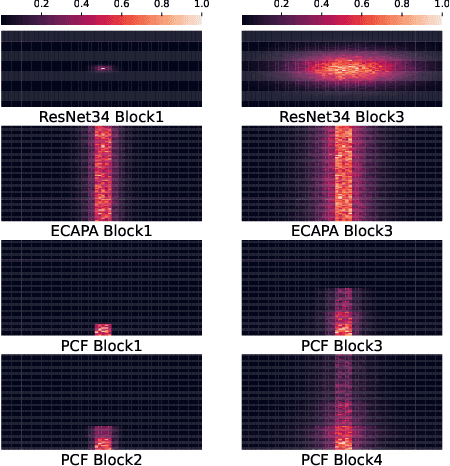
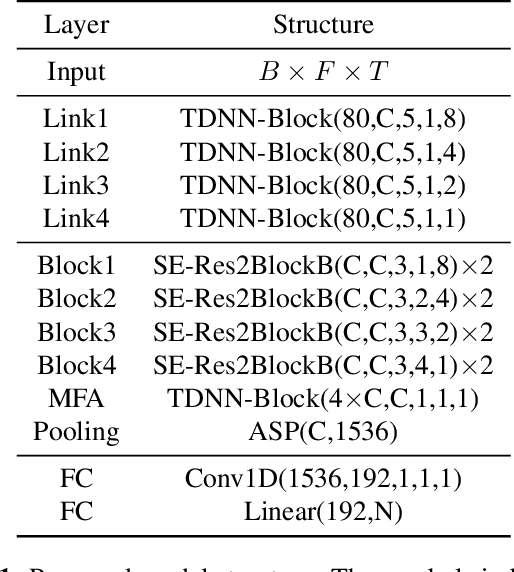
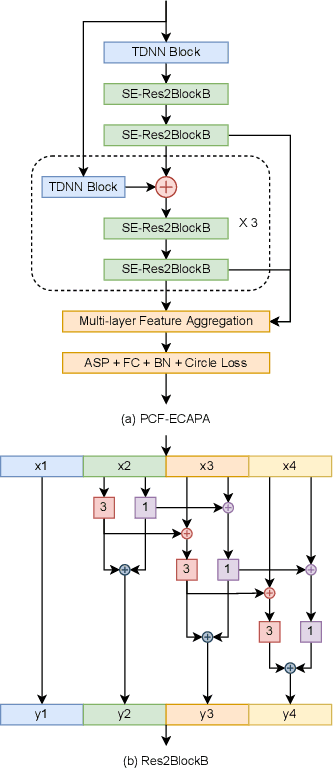
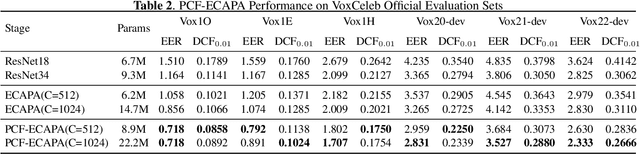
ECAPA-TDNN is currently the most popular TDNN-series model for speaker verification, which refreshed the state-of-the-art(SOTA) performance of TDNN models. However, one-dimensional convolution has a global receptive field over the feature channel. It destroys the time-frequency relevance of the spectrogram. Besides, as ECAPA-TDNN only has five layers, a much shallower structure compared to ResNet restricts the capability to generate deep representations. To further improve ECAPA-TDNN, we propose a progressive channel fusion strategy that splits the spectrogram across the feature channel and gradually expands the receptive field through the network. Secondly, we enlarge the model by extending the depth and adding branches. Our proposed model achieves EER with 0.718 and minDCF(0.01) with 0.0858 on vox1o, relatively improved 16.1\% and 19.5\% compared with ECAPA-TDNN-large.
Reentry Risk and Safety Assessment of Spacecraft Debris Based on Machine Learning
Feb 21, 2023
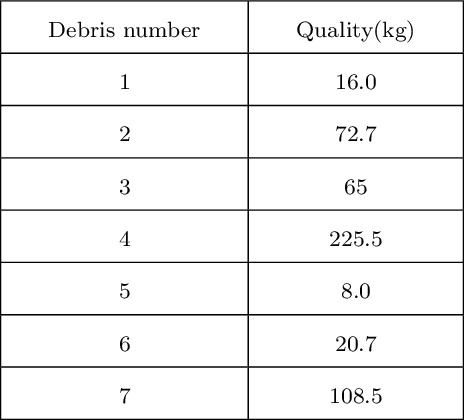
Uncontrolled spacecraft will disintegrate and generate a large amount of debris in the reentry process, and ablative debris may cause potential risks to the safety of human life and property on the ground. Therefore, predicting the landing points of spacecraft debris and forecasting the degree of risk of debris to human life and property is very important. In view that it is difficult to predict the process of reentry process and the reentry point in advance, and the debris generated from reentry disintegration may cause ground damage for the uncontrolled space vehicle on expiration of service. In this paper, we adopt the object-oriented approach to consider the spacecraft and its disintegrated components as consisting of simple basic geometric models, and introduce three machine learning models: the support vector regression (SVR), decision tree regression (DTR) and multilayer perceptron (MLP) to predict the velocity, longitude and latitude of spacecraft debris landing points for the first time. Then, we compare the prediction accuracy of the three models. Furthermore, we define the reentry risk and the degree of danger, and we calculate the risk level for each spacecraft debris and make warnings accordingly. The experimental results show that the proposed method can obtain high accuracy prediction results in at least 15 seconds and make safety level warning more real-time.
Understanding and Unifying Fourteen Attribution Methods with Taylor Interactions
Mar 06, 2023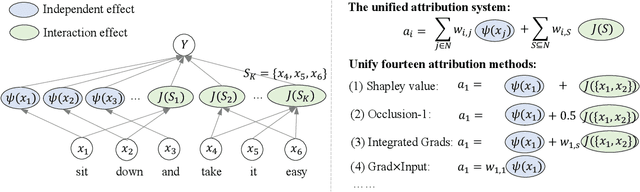
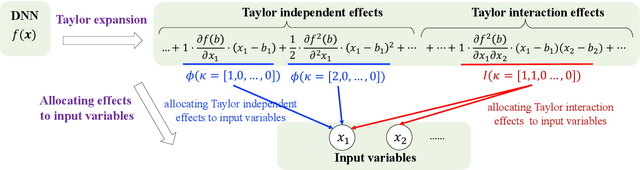
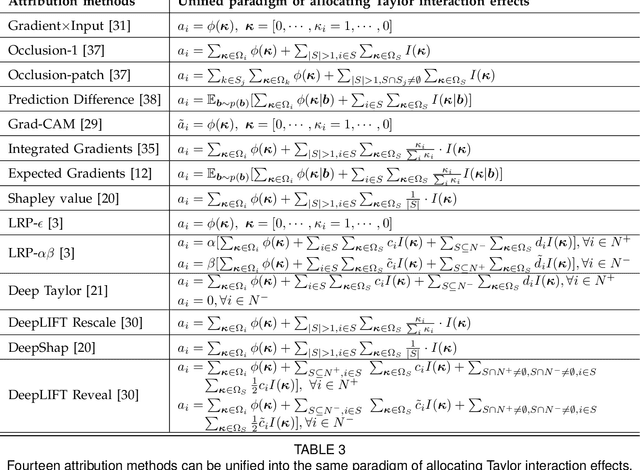
Various attribution methods have been developed to explain deep neural networks (DNNs) by inferring the attribution/importance/contribution score of each input variable to the final output. However, existing attribution methods are often built upon different heuristics. There remains a lack of a unified theoretical understanding of why these methods are effective and how they are related. To this end, for the first time, we formulate core mechanisms of fourteen attribution methods, which were designed on different heuristics, into the same mathematical system, i.e., the system of Taylor interactions. Specifically, we prove that attribution scores estimated by fourteen attribution methods can all be reformulated as the weighted sum of two types of effects, i.e., independent effects of each individual input variable and interaction effects between input variables. The essential difference among the fourteen attribution methods mainly lies in the weights of allocating different effects. Based on the above findings, we propose three principles for a fair allocation of effects to evaluate the faithfulness of the fourteen attribution methods.