 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Dual-Tier Adaptive One-Class Classification IDS for Emerging Cyberthreats
Mar 17, 2024
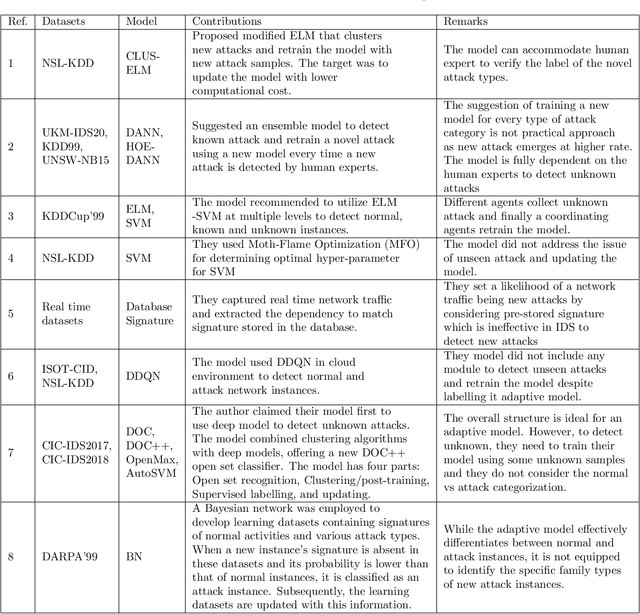
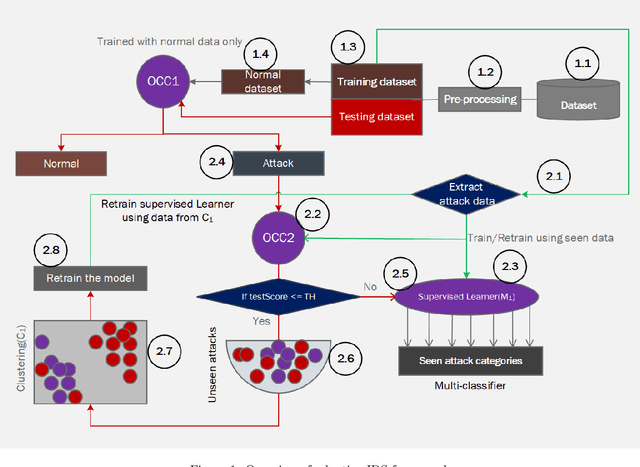
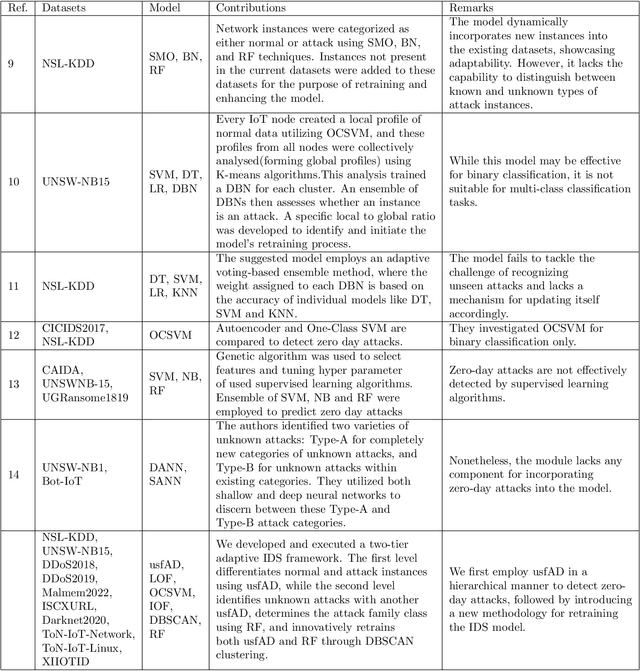
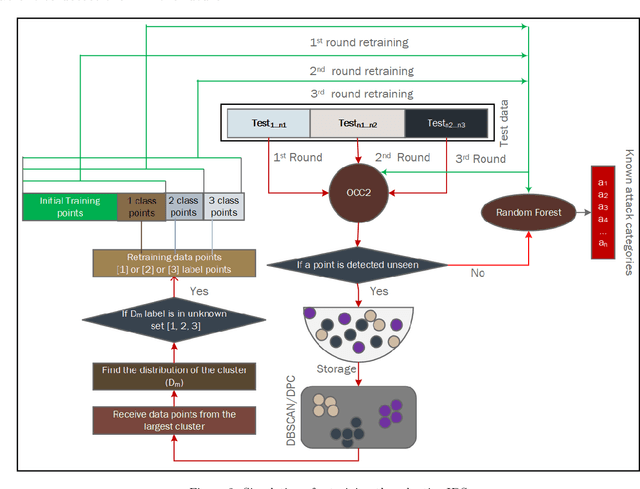
In today's digital age, our dependence on IoT (Internet of Things) and IIoT (Industrial IoT) systems has grown immensely, which facilitates sensitive activities such as banking transactions and personal, enterprise data, and legal document exchanges. Cyberattackers consistently exploit weak security measures and tools. The Network Intrusion Detection System (IDS) acts as a primary tool against such cyber threats. However, machine learning-based IDSs, when trained on specific attack patterns, often misclassify new emerging cyberattacks. Further, the limited availability of attack instances for training a supervised learner and the ever-evolving nature of cyber threats further complicate the matter. This emphasizes the need for an adaptable IDS framework capable of recognizing and learning from unfamiliar/unseen attacks over time. In this research, we propose a one-class classification-driven IDS system structured on two tiers. The first tier distinguishes between normal activities and attacks/threats, while the second tier determines if the detected attack is known or unknown. Within this second tier, we also embed a multi-classification mechanism coupled with a clustering algorithm. This model not only identifies unseen attacks but also uses them for retraining them by clustering unseen attacks. This enables our model to be future-proofed, capable of evolving with emerging threat patterns. Leveraging one-class classifiers (OCC) at the first level, our approach bypasses the need for attack samples, addressing data imbalance and zero-day attack concerns and OCC at the second level can effectively separate unknown attacks from the known attacks. Our methodology and evaluations indicate that the presented framework exhibits promising potential for real-world deployments.
Learning-Based Pricing and Matching for Two-Sided Queues
Mar 17, 2024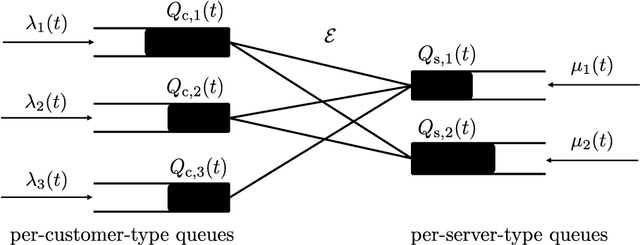
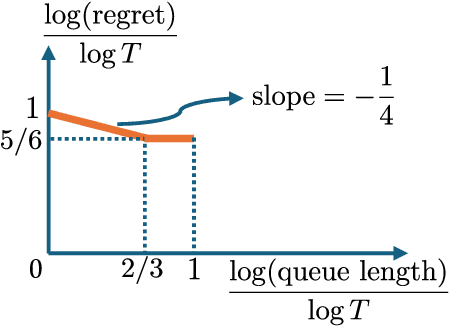

We consider a dynamic system with multiple types of customers and servers. Each type of waiting customer or server joins a separate queue, forming a bipartite graph with customer-side queues and server-side queues. The platform can match the servers and customers if their types are compatible. The matched pairs then leave the system. The platform will charge a customer a price according to their type when they arrive and will pay a server a price according to their type. The arrival rate of each queue is determined by the price according to some unknown demand or supply functions. Our goal is to design pricing and matching algorithms to maximize the profit of the platform with unknown demand and supply functions, while keeping queue lengths of both customers and servers below a predetermined threshold. This system can be used to model two-sided markets such as ride-sharing markets with passengers and drivers. The difficulties of the problem include simultaneous learning and decision making, and the tradeoff between maximizing profit and minimizing queue length. We use a longest-queue-first matching algorithm and propose a learning-based pricing algorithm, which combines gradient-free stochastic projected gradient ascent with bisection search. We prove that our proposed algorithm yields a sublinear regret $\tilde{O}(T^{5/6})$ and queue-length bound $\tilde{O}(T^{2/3})$, where $T$ is the time horizon. We further establish a tradeoff between the regret bound and the queue-length bound: $\tilde{O}(T^{1-\gamma/4})$ versus $\tilde{O}(T^{\gamma})$ for $\gamma \in (0, 2/3].$
Is Data All That Matters? The Role of Control Frequency for Learning-Based Sampled-Data Control of Uncertain Systems
Mar 14, 2024Learning models or control policies from data has become a powerful tool to improve the performance of uncertain systems. While a strong focus has been placed on increasing the amount and quality of data to improve performance, data can never fully eliminate uncertainty, making feedback necessary to ensure stability and performance. We show that the control frequency at which the input is recalculated is a crucial design parameter, yet it has hardly been considered before. We address this gap by combining probabilistic model learning and sampled-data control. We use Gaussian processes (GPs) to learn a continuous-time model and compute a corresponding discrete-time controller. The result is an uncertain sampled-data control system, for which we derive robust stability conditions. We formulate semidefinite programs to compute the minimum control frequency required for stability and to optimize performance. As a result, our approach enables us to study the effect of both control frequency and data on stability and closed-loop performance. We show in numerical simulations of a quadrotor that performance can be improved by increasing either the amount of data or the control frequency, and that we can trade off one for the other. For example, by increasing the control frequency by 33%, we can reduce the number of data points by half while still achieving similar performance.
Data is all you need: Finetuning LLMs for Chip Design via an Automated design-data augmentation framework
Mar 17, 2024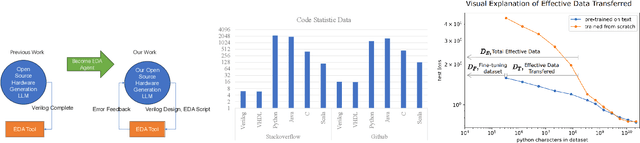
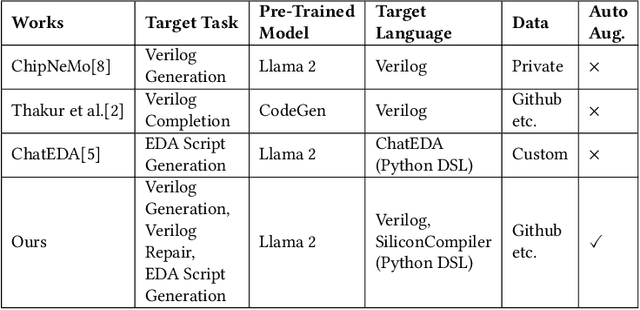
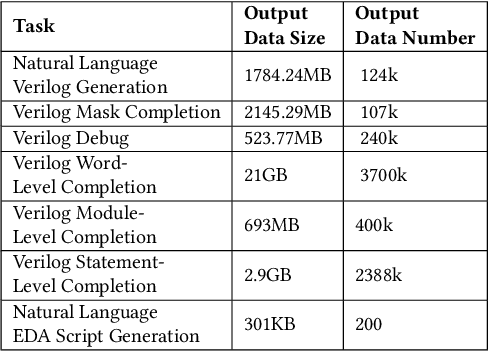
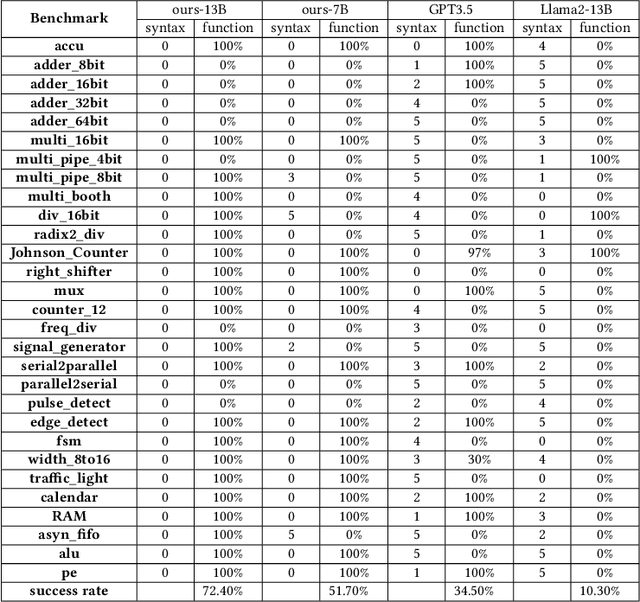
Recent advances in large language models have demonstrated their potential for automated generation of hardware description language (HDL) code from high-level prompts. Researchers have utilized fine-tuning to enhance the ability of these large language models (LLMs) in the field of Chip Design. However, the lack of Verilog data hinders further improvement in the quality of Verilog generation by LLMs. Additionally, the absence of a Verilog and Electronic Design Automation (EDA) script data augmentation framework significantly increases the time required to prepare the training dataset for LLM trainers. This paper proposes an automated design-data augmentation framework, which generates high-volume and high-quality natural language aligned with Verilog and EDA scripts. For Verilog generation, it translates Verilog files to an abstract syntax tree and then maps nodes to natural language with a predefined template. For Verilog repair, it uses predefined rules to generate the wrong verilog file and then pairs EDA Tool feedback with the right and wrong verilog file. For EDA Script generation, it uses existing LLM(GPT-3.5) to obtain the description of the Script. To evaluate the effectiveness of our data augmentation method, we finetune Llama2-13B and Llama2-7B models using the dataset generated by our augmentation framework. The results demonstrate a significant improvement in the Verilog generation tasks with LLMs. Moreover, the accuracy of Verilog generation surpasses that of the current state-of-the-art open-source Verilog generation model, increasing from 58.8% to 70.6% with the same benchmark. Our 13B model (ChipGPT-FT) has a pass rate improvement compared with GPT-3.5 in Verilog generation and outperforms in EDA script (i.e., SiliconCompiler) generation with only 200 EDA script data.
Brain-on-Switch: Towards Advanced Intelligent Network Data Plane via NN-Driven Traffic Analysis at Line-Speed
Mar 17, 2024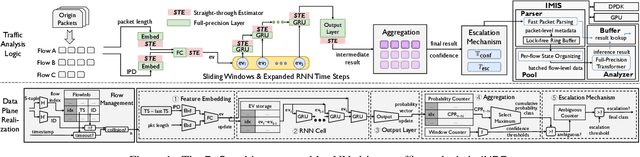
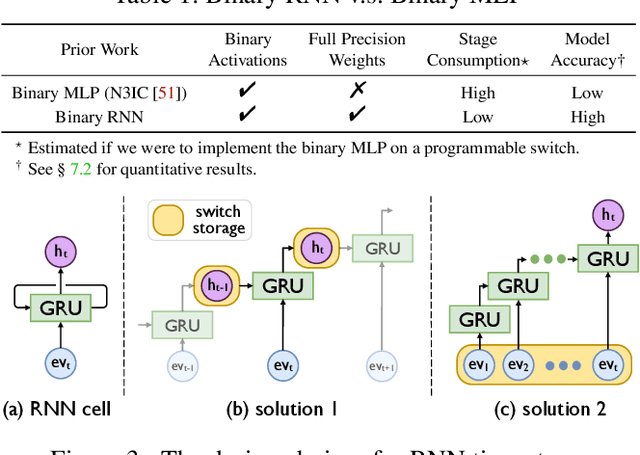
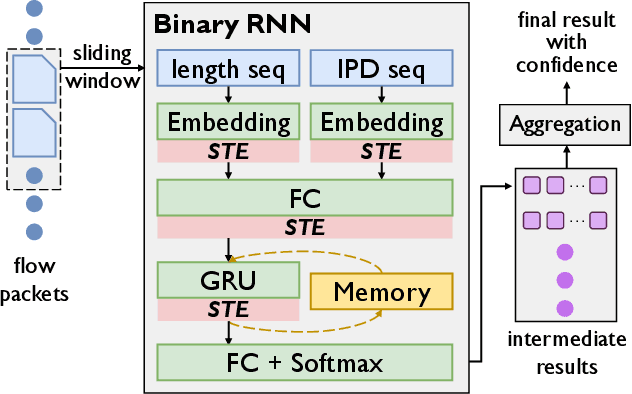
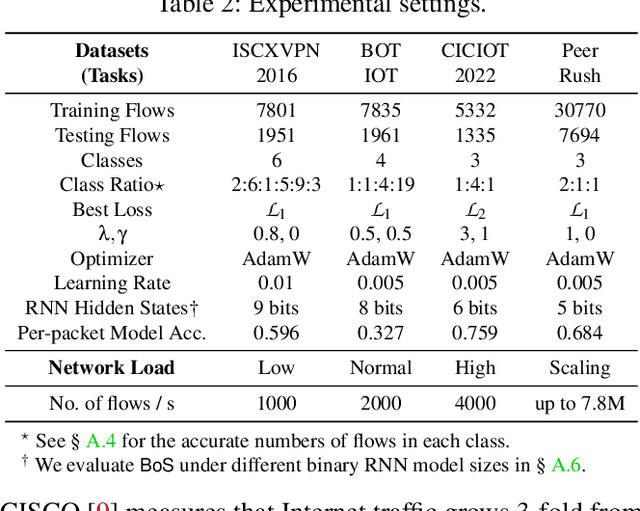
The emerging programmable networks sparked significant research on Intelligent Network Data Plane (INDP), which achieves learning-based traffic analysis at line-speed. Prior art in INDP focus on deploying tree/forest models on the data plane. We observe a fundamental limitation in tree-based INDP approaches: although it is possible to represent even larger tree/forest tables on the data plane, the flow features that are computable on the data plane are fundamentally limited by hardware constraints. In this paper, we present BoS to push the boundaries of INDP by enabling Neural Network (NN) driven traffic analysis at line-speed. Many types of NNs (such as Recurrent Neural Network (RNN), and transformers) that are designed to work with sequential data have advantages over tree-based models, because they can take raw network data as input without complex feature computations on the fly. However, the challenge is significant: the recurrent computation scheme used in RNN inference is fundamentally different from the match-action paradigm used on the network data plane. BoS addresses this challenge by (i) designing a novel data plane friendly RNN architecture that can execute unlimited RNN time steps with limited data plane stages, effectively achieving line-speed RNN inference; and (ii) complementing the on-switch RNN model with an off-switch transformer-based traffic analysis module to further boost the overall performance. We implement a prototype of BoS using a P4 programmable switch as our data plane, and extensively evaluate it over multiple traffic analysis tasks. The results show that BoS outperforms state-of-the-art in both analysis accuracy and scalability.
A learning-based solution approach to the application placement problem in mobile edge computing under uncertainty
Mar 17, 2024

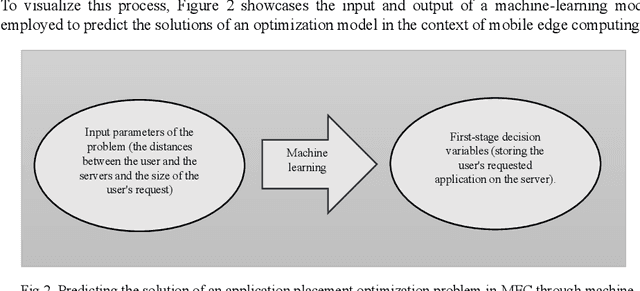
Placing applications in mobile edge computing servers presents a complex challenge involving many servers, users, and their requests. Existing algorithms take a long time to solve high-dimensional problems with significant uncertainty scenarios. Therefore, an efficient approach is required to maximize the quality of service while considering all technical constraints. One of these approaches is machine learning, which emulates optimal solutions for application placement in edge servers. Machine learning models are expected to learn how to allocate user requests to servers based on the spatial positions of users and servers. In this study, the problem is formulated as a two-stage stochastic programming. A sufficient amount of training records is generated by varying parameters such as user locations, their request rates, and solving the optimization model. Then, based on the distance features of each user from the available servers and their request rates, machine learning models generate decision variables for the first stage of the stochastic optimization model, which is the user-to-server request allocation, and are employed as independent decision agents that reliably mimic the optimization model. Support Vector Machines (SVM) and Multi-layer Perceptron (MLP) are used in this research to achieve practical decisions from the stochastic optimization models. The performance of each model has shown an execution effectiveness of over 80%. This research aims to provide a more efficient approach for tackling high-dimensional problems and scenarios with uncertainties in mobile edge computing by leveraging machine learning models for optimal decision-making in request allocation to edge servers. These results suggest that machine-learning models can significantly improve solution times compared to conventional approaches.
Confidence-Aware RGB-D Face Recognition via Virtual Depth Synthesis
Mar 16, 2024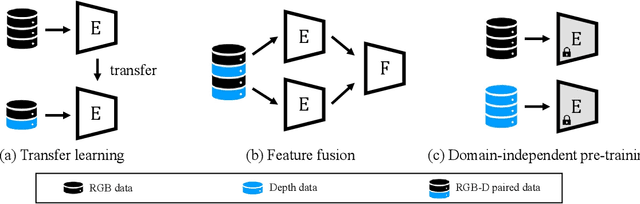
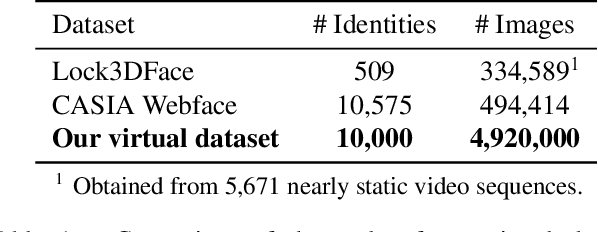
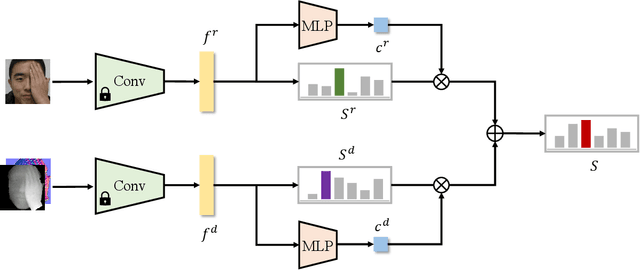
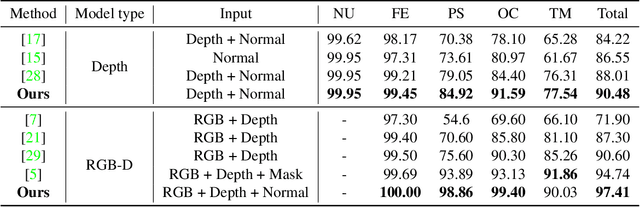
2D face recognition encounters challenges in unconstrained environments due to varying illumination, occlusion, and pose. Recent studies focus on RGB-D face recognition to improve robustness by incorporating depth information. However, collecting sufficient paired RGB-D training data is expensive and time-consuming, hindering wide deployment. In this work, we first construct a diverse depth dataset generated by 3D Morphable Models for depth model pre-training. Then, we propose a domain-independent pre-training framework that utilizes readily available pre-trained RGB and depth models to separately perform face recognition without needing additional paired data for retraining. To seamlessly integrate the two distinct networks and harness the complementary benefits of RGB and depth information for improved accuracy, we propose an innovative Adaptive Confidence Weighting (ACW). This mechanism is designed to learn confidence estimates for each modality to achieve modality fusion at the score level. Our method is simple and lightweight, only requiring ACW training beyond the backbone models. Experiments on multiple public RGB-D face recognition benchmarks demonstrate state-of-the-art performance surpassing previous methods based on depth estimation and feature fusion, validating the efficacy of our approach.
View-Centric Multi-Object Tracking with Homographic Matching in Moving UAV
Mar 16, 2024
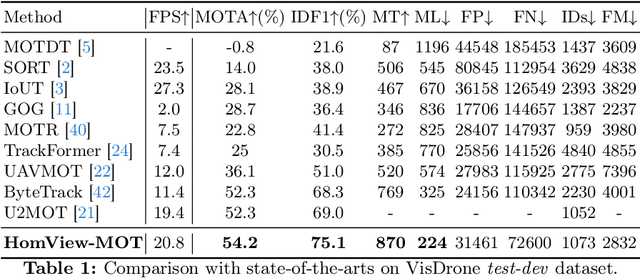
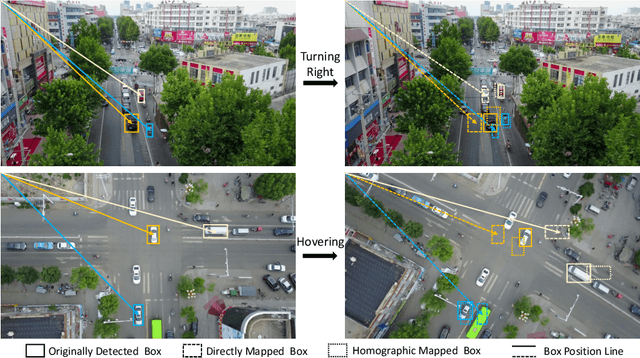
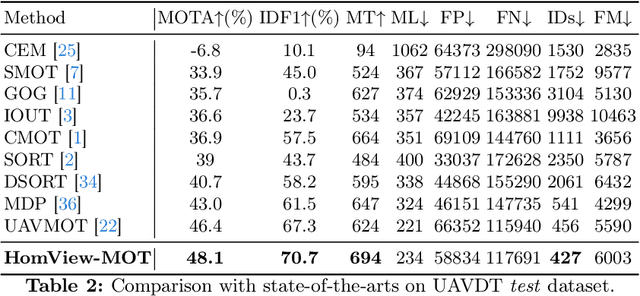
In this paper, we address the challenge of multi-object tracking (MOT) in moving Unmanned Aerial Vehicle (UAV) scenarios, where irregular flight trajectories, such as hovering, turning left/right, and moving up/down, lead to significantly greater complexity compared to fixed-camera MOT. Specifically, changes in the scene background not only render traditional frame-to-frame object IOU association methods ineffective but also introduce significant view shifts in the objects, which complicates tracking. To overcome these issues, we propose a novel universal HomView-MOT framework, which for the first time, harnesses the view Homography inherent in changing scenes to solve MOT challenges in moving environments, incorporating Homographic Matching and View-Centric concepts. We introduce a Fast Homography Estimation (FHE) algorithm for rapid computation of Homography matrices between video frames, enabling object View-Centric ID Learning (VCIL) and leveraging multi-view Homography to learn cross-view ID features. Concurrently, our Homographic Matching Filter (HMF) maps object bounding boxes from different frames onto a common view plane for a more realistic physical IOU association. Extensive experiments have proven that these innovations allow HomView-MOT to achieve state-of-the-art performance on prominent UAV MOT datasets VisDrone and UAVDT.
Anomaly Detection Based on Isolation Mechanisms: A Survey
Mar 16, 2024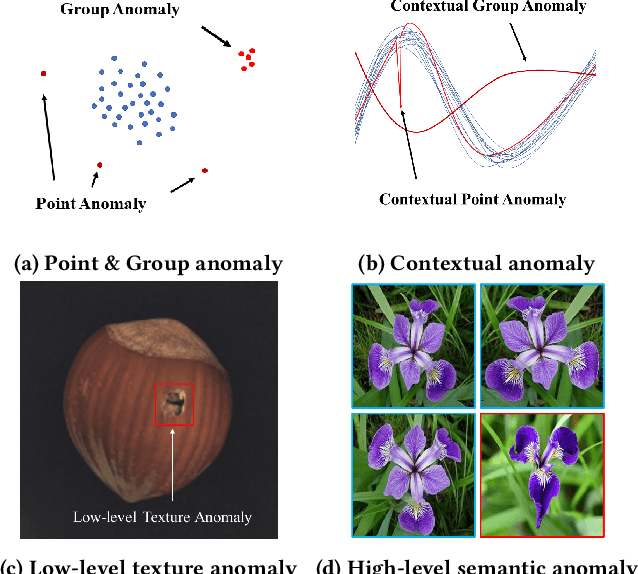
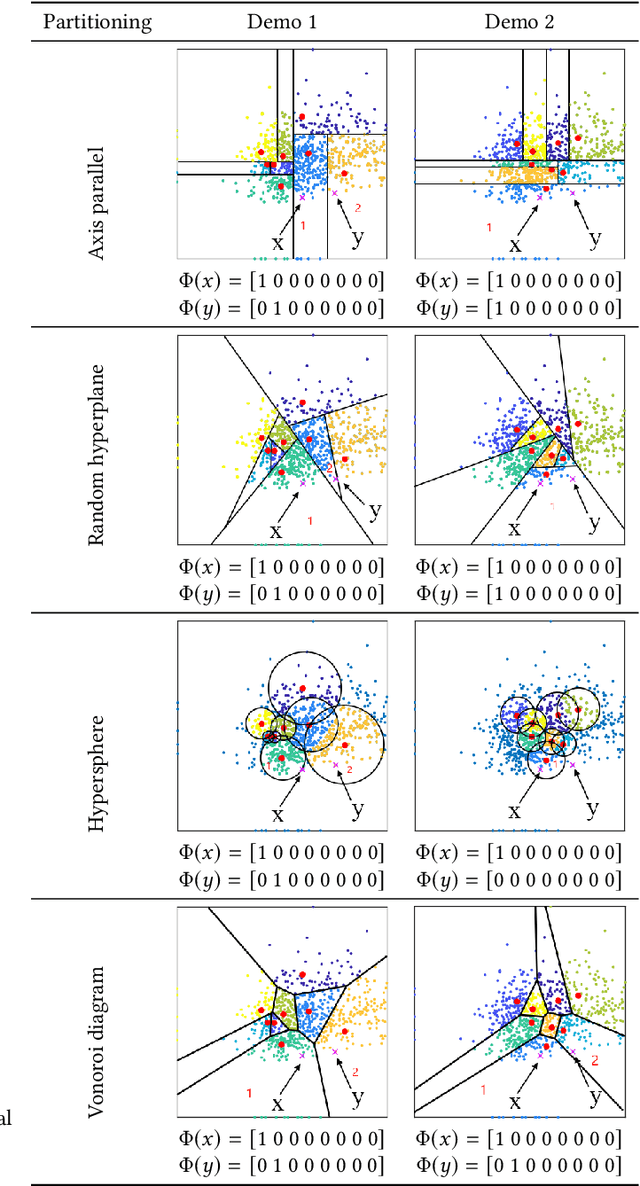
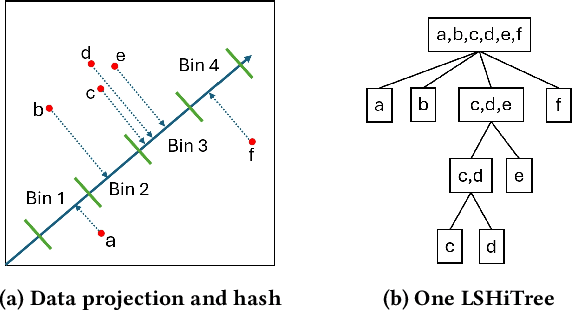

Anomaly detection is a longstanding and active research area that has many applications in domains such as finance, security, and manufacturing. However, the efficiency and performance of anomaly detection algorithms are challenged by the large-scale, high-dimensional, and heterogeneous data that are prevalent in the era of big data. Isolation-based unsupervised anomaly detection is a novel and effective approach for identifying anomalies in data. It relies on the idea that anomalies are few and different from normal instances, and thus can be easily isolated by random partitioning. Isolation-based methods have several advantages over existing methods, such as low computational complexity, low memory usage, high scalability, robustness to noise and irrelevant features, and no need for prior knowledge or heavy parameter tuning. In this survey, we review the state-of-the-art isolation-based anomaly detection methods, including their data partitioning strategies, anomaly score functions, and algorithmic details. We also discuss some extensions and applications of isolation-based methods in different scenarios, such as detecting anomalies in streaming data, time series, trajectory, and image datasets. Finally, we identify some open challenges and future directions for isolation-based anomaly detection research.
CORN: Contact-based Object Representation for Nonprehensile Manipulation of General Unseen Objects
Mar 16, 2024


Nonprehensile manipulation is essential for manipulating objects that are too thin, large, or otherwise ungraspable in the wild. To sidestep the difficulty of contact modeling in conventional modeling-based approaches, reinforcement learning (RL) has recently emerged as a promising alternative. However, previous RL approaches either lack the ability to generalize over diverse object shapes, or use simple action primitives that limit the diversity of robot motions. Furthermore, using RL over diverse object geometry is challenging due to the high cost of training a policy that takes in high-dimensional sensory inputs. We propose a novel contact-based object representation and pretraining pipeline to tackle this. To enable massively parallel training, we leverage a lightweight patch-based transformer architecture for our encoder that processes point clouds, thus scaling our training across thousands of environments. Compared to learning from scratch, or other shape representation baselines, our representation facilitates both time- and data-efficient learning. We validate the efficacy of our overall system by zero-shot transferring the trained policy to novel real-world objects. Code and videos are available at https://sites.google.com/view/contact-non-prehensile.