 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LooperGP: A Loopable Sequence Model for Live Coding Performance using GuitarPro Tablature
Mar 03, 2023

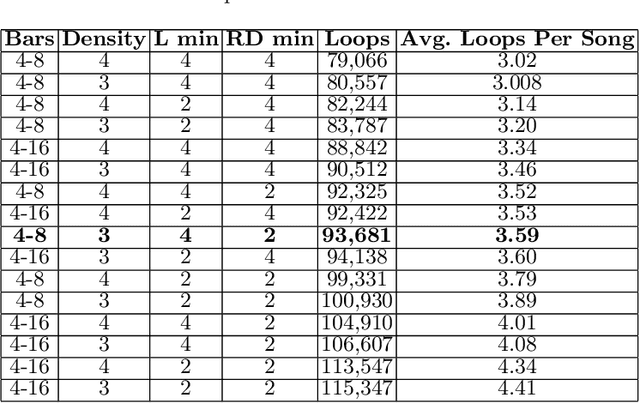


Despite their impressive offline results, deep learning models for symbolic music generation are not widely used in live performances due to a deficit of musically meaningful control parameters and a lack of structured musical form in their outputs. To address these issues we introduce LooperGP, a method for steering a Transformer-XL model towards generating loopable musical phrases of a specified number of bars and time signature, enabling a tool for live coding performances. We show that by training LooperGP on a dataset of 93,681 musical loops extracted from the DadaGP dataset, we are able to steer its generative output towards generating 3x as many loopable phrases as our baseline. In a subjective listening test conducted by 31 participants, LooperGP loops achieved positive median ratings in originality, musical coherence and loop smoothness, demonstrating its potential as a performance tool.
* The Version of Record of this contribution is published in Proceedings of EvoMUSART: International Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar) 2023
Real-Time Dense Field Phase-to-Space Simulation of Imaging through Atmospheric Turbulence
Oct 13, 2022
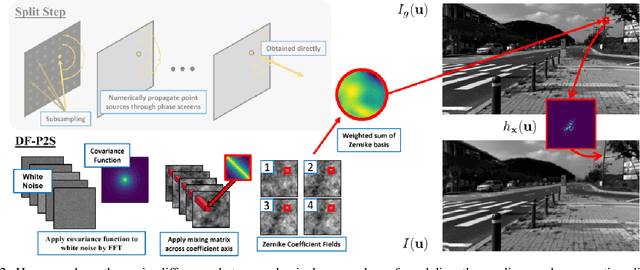
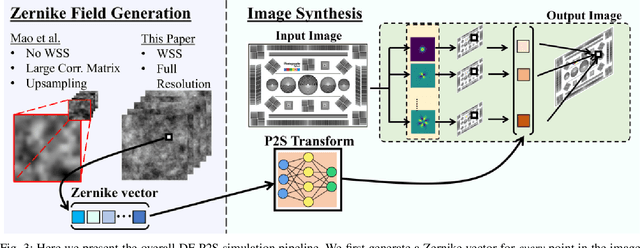
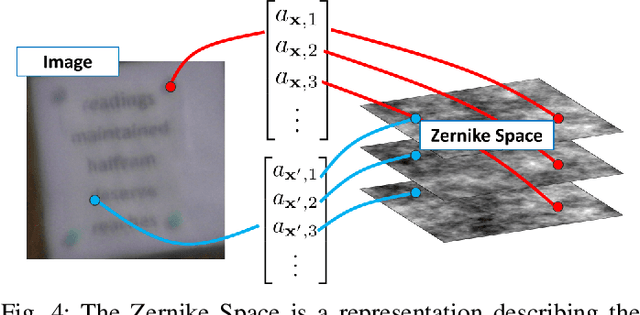
Numerical simulation of atmospheric turbulence is one of the biggest bottlenecks in developing computational techniques for solving the inverse problem in long-range imaging. The classical split-step method is based upon numerical wave propagation which splits the propagation path into many segments and propagates every pixel in each segment individually via the Fresnel integral. This repeated evaluation becomes increasingly time-consuming for larger images. As a result, the split-step simulation is often done only on a sparse grid of points followed by an interpolation to the other pixels. Even so, the computation is expensive for real-time applications. In this paper, we present a new simulation method that enables \emph{real-time} processing over a \emph{dense} grid of points. Building upon the recently developed multi-aperture model and the phase-to-space transform, we overcome the memory bottleneck in drawing random samples from the Zernike correlation tensor. We show that the cross-correlation of the Zernike modes has an insignificant contribution to the statistics of the random samples. By approximating these cross-correlation blocks in the Zernike tensor, we restore the homogeneity of the tensor which then enables Fourier-based random sampling. On a $512\times512$ image, the new simulator achieves 0.025 seconds per frame over a dense field. On a $3840 \times 2160$ image which would have taken 13 hours to simulate using the split-step method, the new simulator can run at approximately 60 seconds per frame.
MetaGrad: Adaptive Gradient Quantization with Hypernetworks
Mar 04, 2023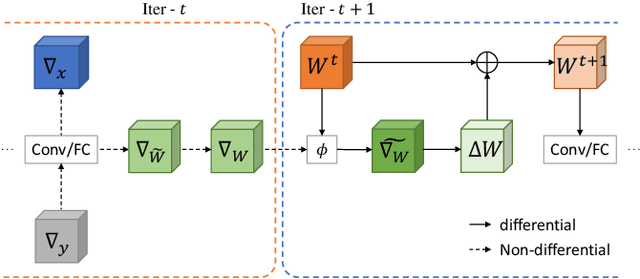
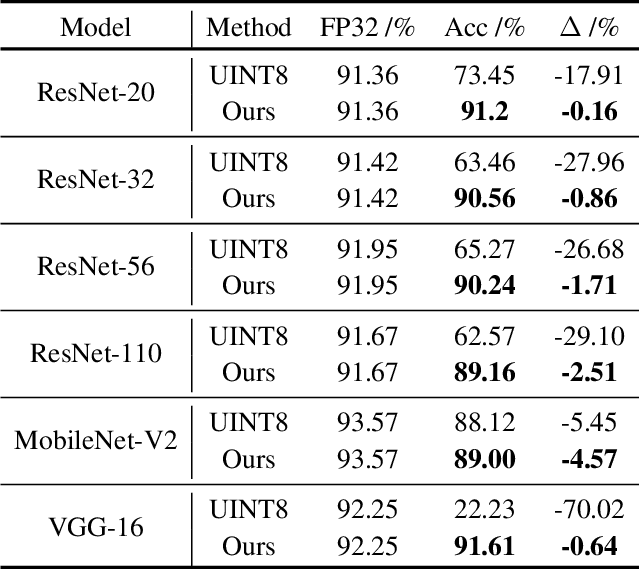
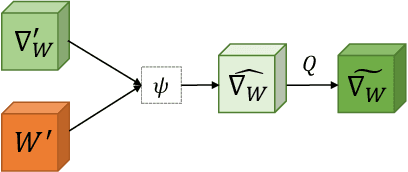
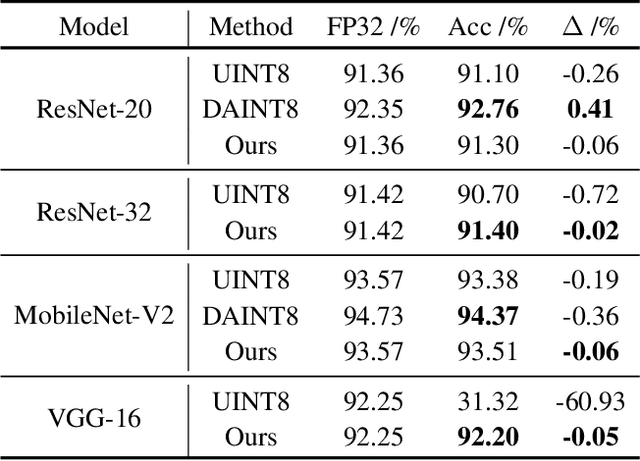
A popular track of network compression approach is Quantization aware Training (QAT), which accelerates the forward pass during the neural network training and inference. However, not much prior efforts have been made to quantize and accelerate the backward pass during training, even though that contributes around half of the training time. This can be partly attributed to the fact that errors of low-precision gradients during backward cannot be amortized by the training objective as in the QAT setting. In this work, we propose to solve this problem by incorporating the gradients into the computation graph of the next training iteration via a hypernetwork. Various experiments on CIFAR-10 dataset with different CNN network architectures demonstrate that our hypernetwork-based approach can effectively reduce the negative effect of gradient quantization noise and successfully quantizes the gradients to INT4 with only 0.64 accuracy drop for VGG-16 on CIFAR-10.
Diffusion Models Generate Images Like Painters: an Analytical Theory of Outline First, Details Later
Mar 04, 2023

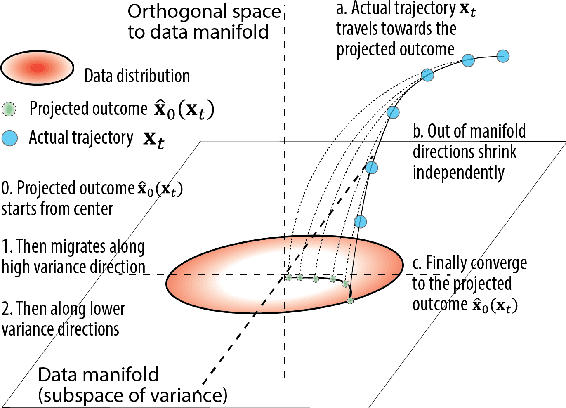
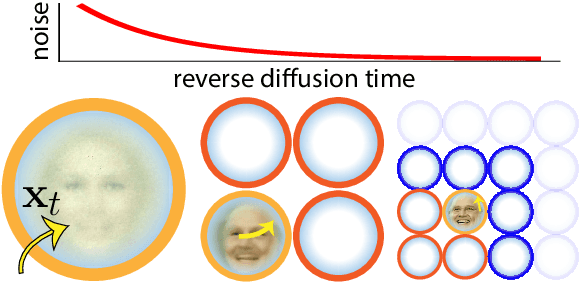
How do diffusion generative models convert pure noise into meaningful images? We argue that generation involves first committing to an outline, and then to finer and finer details. The corresponding reverse diffusion process can be modeled by dynamics on a (time-dependent) high-dimensional landscape full of Gaussian-like modes, which makes the following predictions: (i) individual trajectories tend to be very low-dimensional; (ii) scene elements that vary more within training data tend to emerge earlier; and (iii) early perturbations substantially change image content more often than late perturbations. We show that the behavior of a variety of trained unconditional and conditional diffusion models like Stable Diffusion is consistent with these predictions. Finally, we use our theory to search for the latent image manifold of diffusion models, and propose a new way to generate interpretable image variations. Our viewpoint suggests generation by GANs and diffusion models have unexpected similarities.
FQP 2.0: Industry Trend Analysis via Hierarchical Financial Data
Mar 05, 2023


Analyzing trends across industries is critical to maintaining a healthy and stable economy. Previous research has mainly analyzed official statistics, which are more accurate but not necessarily real-time. In this paper, we propose a method for analyzing industry trends using stock market data. The difficulty of this task is that the raw data is relatively noisy, which affects the accuracy of statistical analysis. In addition, textual data for industry analysis needs to be better understood through language models. For this reason, we introduce the method of industry trend analysis from two perspectives of explicit analysis and implicit analysis. For the explicit analysis, we introduce a hierarchical data (industry and listed company) analysis method to reduce the impact of noise. For implicit analysis, we further pre-train GPT-2 to analyze industry trends with current affairs background as input, making full use of the knowledge learned in the pre-training corpus. We conduct experiments based on the proposed method and achieve good industry trend analysis results.
Prompt-Based Learning for Thread Structure Prediction in Cybersecurity Forums
Mar 05, 2023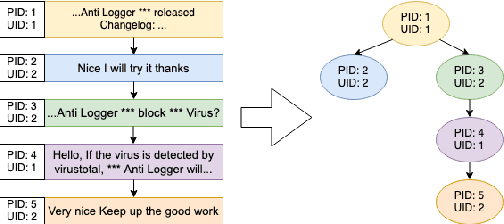
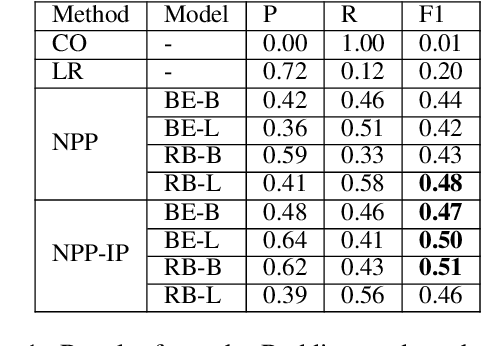
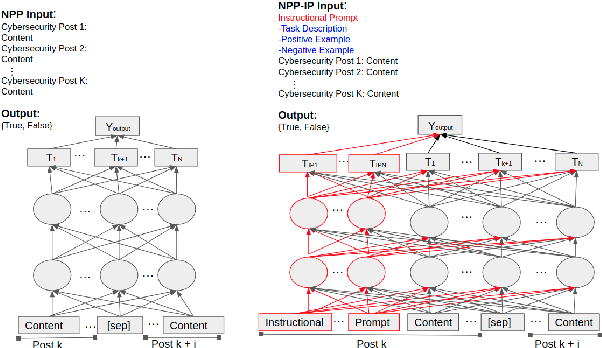
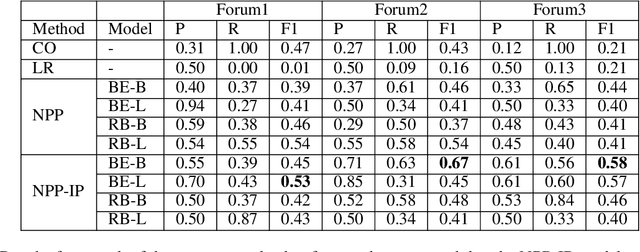
With recent trends indicating cyber crimes increasing in both frequency and cost, it is imperative to develop new methods that leverage data-rich hacker forums to assist in combating ever evolving cyber threats. Defining interactions within these forums is critical as it facilitates identifying highly skilled users, which can improve prediction of novel threats and future cyber attacks. We propose a method called Next Paragraph Prediction with Instructional Prompting (NPP-IP) to predict thread structures while grounded on the context around posts. This is the first time to apply an instructional prompting approach to the cybersecurity domain. We evaluate our NPP-IP with the Reddit dataset and Hacker Forums dataset that has posts and thread structures of real hacker forums' threads, and compare our method's performance with existing methods. The experimental evaluation shows that our proposed method can predict the thread structure significantly better than existing methods allowing for better social network prediction based on forum interactions.
Millimeter Wave Wireless Communication Assisted Three-Dimensional Simultaneous Localization and Mapping
Mar 05, 2023
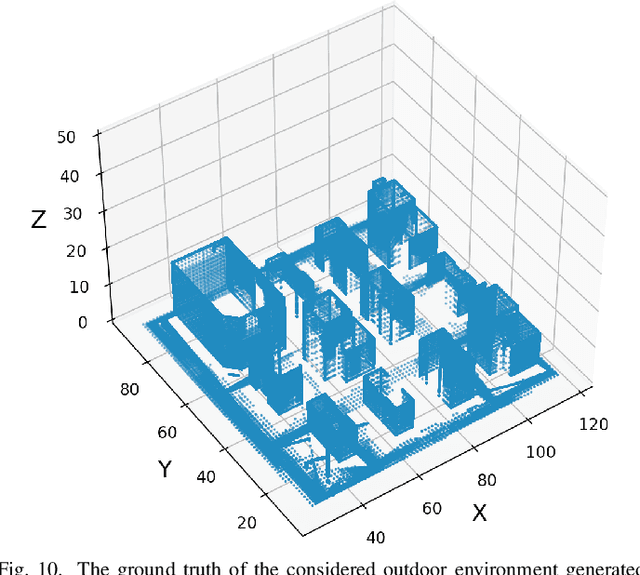
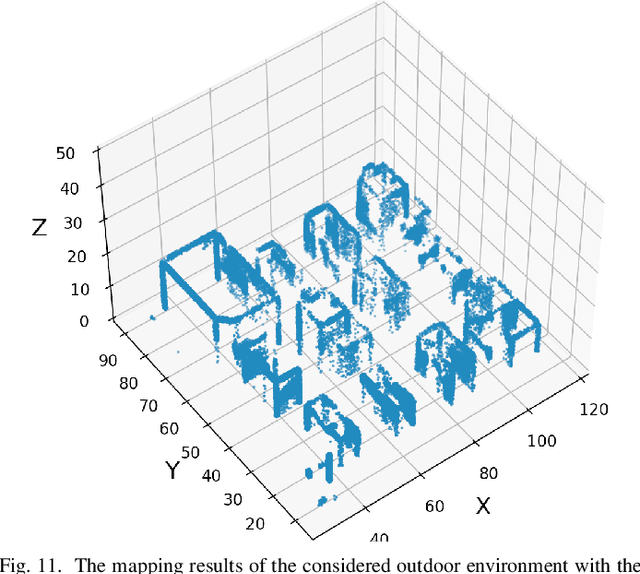
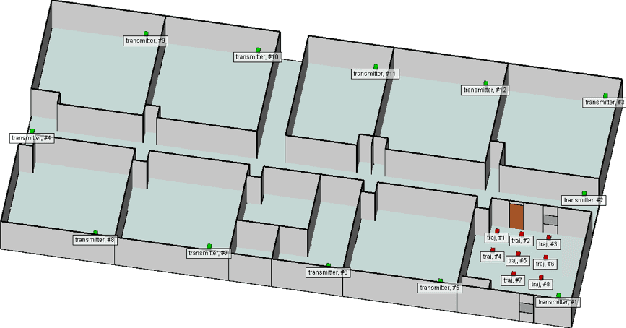
In this paper, we study the three-dimensional (3D) simultaneous localization and mapping (SLAM) problem in complex outdoor and indoor environments based only on millimeter-wave (mmWave) wireless communication signals. Firstly, we propose a deep-learning based mapping (DLM) algorithm that can leverage the reflections point on the first-order none line-of-sight (NLOS) communications links (CLs) to build the 3D point cloud map of the environment. Specifically, we design a classification neural network to identify the first-order NLOS CL and theoretically calculate the geometric coordinates of the reflection points on it. Secondly, we take the advantage of both the inertial measurement unit and the beam-squint assisted localization method to realize real-time and precise localizations. Then, combining the DLM and the adopted localization algorithm, we develop the communication-based SLAM (C-SLAM) framework that can carry out SLAM without any prior knowledge of the environment. Moreover, extensive simulations of both complex outdoor and indoor environments validate the effectiveness of our approach.
MITFAS: Mutual Information based Temporal Feature Alignment and Sampling for Aerial Video Action Recognition
Mar 05, 2023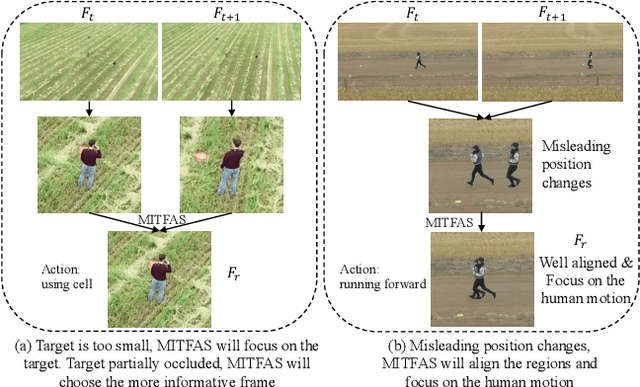
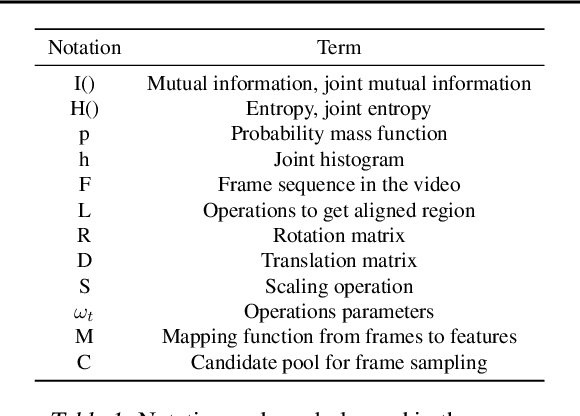
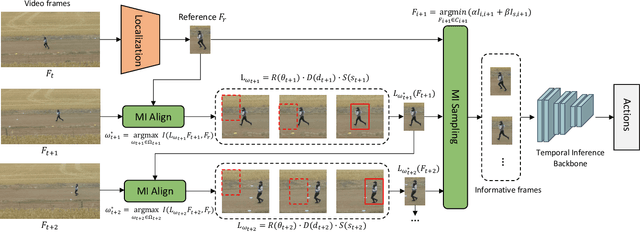
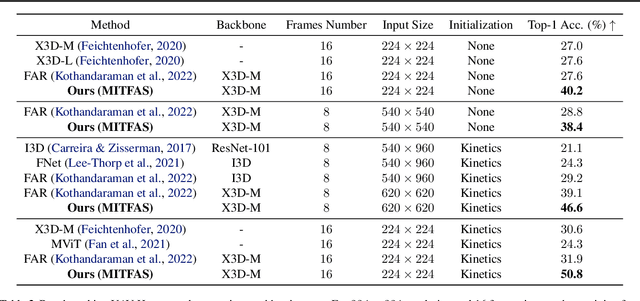
We present a novel approach for action recognition in UAV videos. Our formulation is designed to handle occlusion and viewpoint changes caused by the movement of a UAV. We use the concept of mutual information to compute and align the regions corresponding to human action or motion in the temporal domain. This enables our recognition model to learn from the key features associated with the motion. We also propose a novel frame sampling method that uses joint mutual information to acquire the most informative frame sequence in UAV videos. We have integrated our approach with X3D and evaluated the performance on multiple datasets. In practice, we achieve 18.9% improvement in Top-1 accuracy over current state-of-the-art methods on UAV-Human(Li et al., 2021), 7.3% improvement on Drone-Action(Perera et al., 2019), and 7.16% improvement on NEC Drones(Choi et al., 2020). We will release the code at the time of publication
Speech Enhancement for Virtual Meetings on Cellular Networks
Feb 02, 2023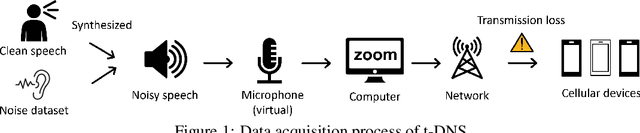
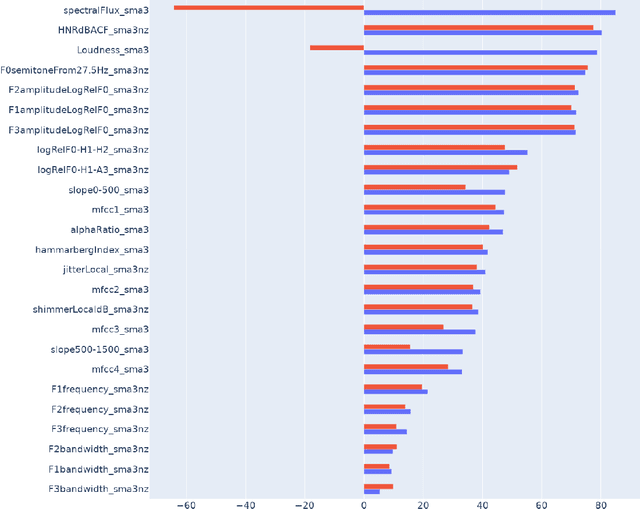
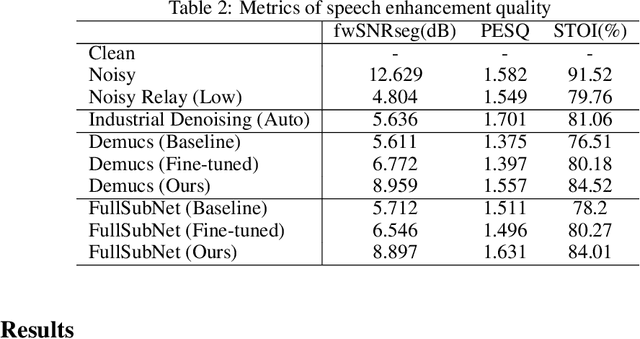
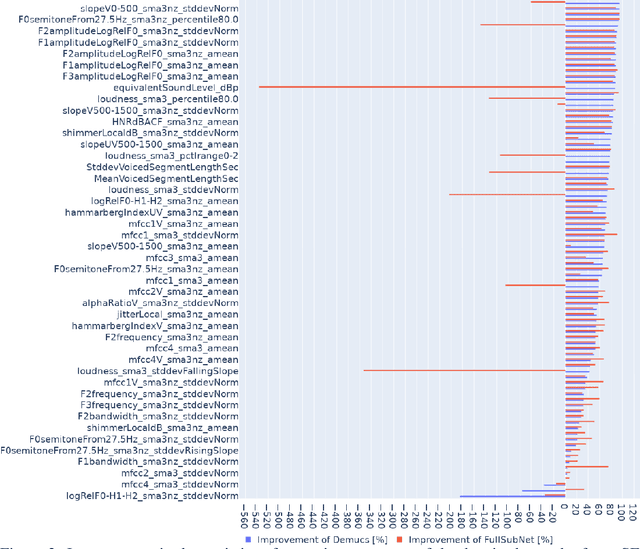
We study speech enhancement using deep learning (DL) for virtual meetings on cellular devices, where transmitted speech has background noise and transmission loss that affects speech quality. Since the Deep Noise Suppression (DNS) Challenge dataset does not contain practical disturbance, we collect a transmitted DNS (t-DNS) dataset using Zoom Meetings over T-Mobile network. We select two baseline models: Demucs and FullSubNet. The Demucs is an end-to-end model that takes time-domain inputs and outputs time-domain denoised speech, and the FullSubNet takes time-frequency-domain inputs and outputs the energy ratio of the target speech in the inputs. The goal of this project is to enhance the speech transmitted over the cellular networks using deep learning models.
Towards Unsupervised Learning based Denoising of Cyber Physical System Data to Mitigate Security Concerns
Mar 13, 2023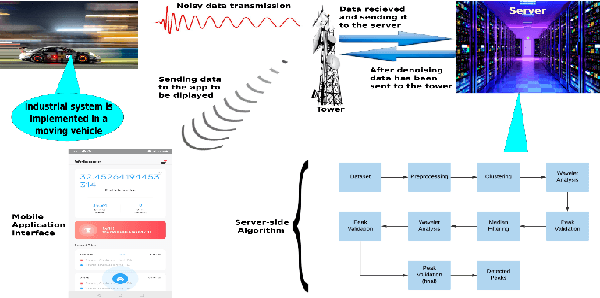
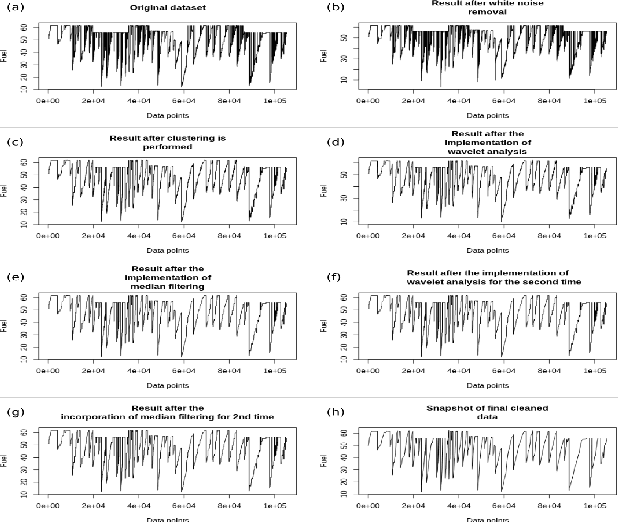
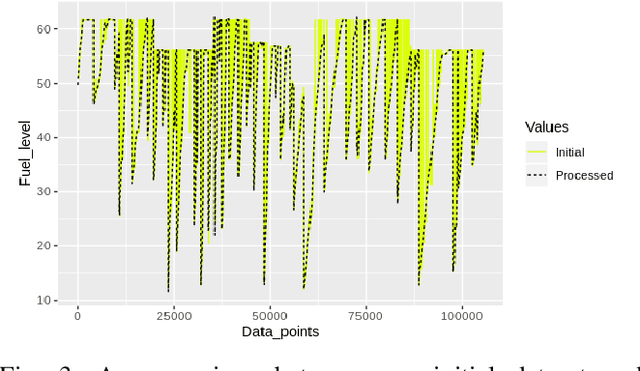
A dataset, collected under an industrial setting, often contains a significant portion of noises. In many cases, using trivial filters is not enough to retrieve useful information i.e., accurate value without the noise. One such data is time-series sensor readings collected from moving vehicles containing fuel information. Due to the noisy dynamics and mobile environment, the sensor readings can be very noisy. Denoising such a dataset is a prerequisite for any useful application and security issues. Security is a primitive concern in present vehicular schemes. The server side for retrieving the fuel information can be easily hacked. Providing the accurate and noise free fuel information via vehicular networks become crutial. Therefore, it has led us to develop a system that can remove noise and keep the original value. The system is also helpful for vehicle industry, fuel station, and power-plant station that require fuel. In this work, we have only considered the value of fuel level, and we have come up with a unique solution to filter out the noise of high magnitudes using several algorithms such as interpolation, extrapolation, spectral clustering, agglomerative clustering, wavelet analysis, and median filtering. We have also employed peak detection and peak validation algorithms to detect fuel refill and consumption in charge-discharge cycles. We have used the R-squared metric to evaluate our model, and it is 98 percent In most cases, the difference between detected value and real value remains within the range of 1L.